Les traductions sont fournies par des outils de traduction automatique. En cas de conflit entre le contenu d'une traduction et celui de la version originale en anglais, la version anglaise prévaudra.
AWS Architecture recommandée pour la prévision de la demande de nouveaux produits
Lorsque vous adaptez votre pipeline d'IA/ML à plusieurs produits et régions, il est recommandé de suivre les meilleures pratiques en matière d'opérations d'apprentissage automatique (MLOps) en matière de reproductibilité, de fiabilité et d'évolutivité. Pour plus d'informations, consultez la section MLOpsImplémentation dans la documentation Amazon SageMaker AI. L'image suivante montre un exemple d' AWS architecture permettant de mettre en œuvre un modèle de machine learning qui prévoit la demande de lancements de nouveaux produits.
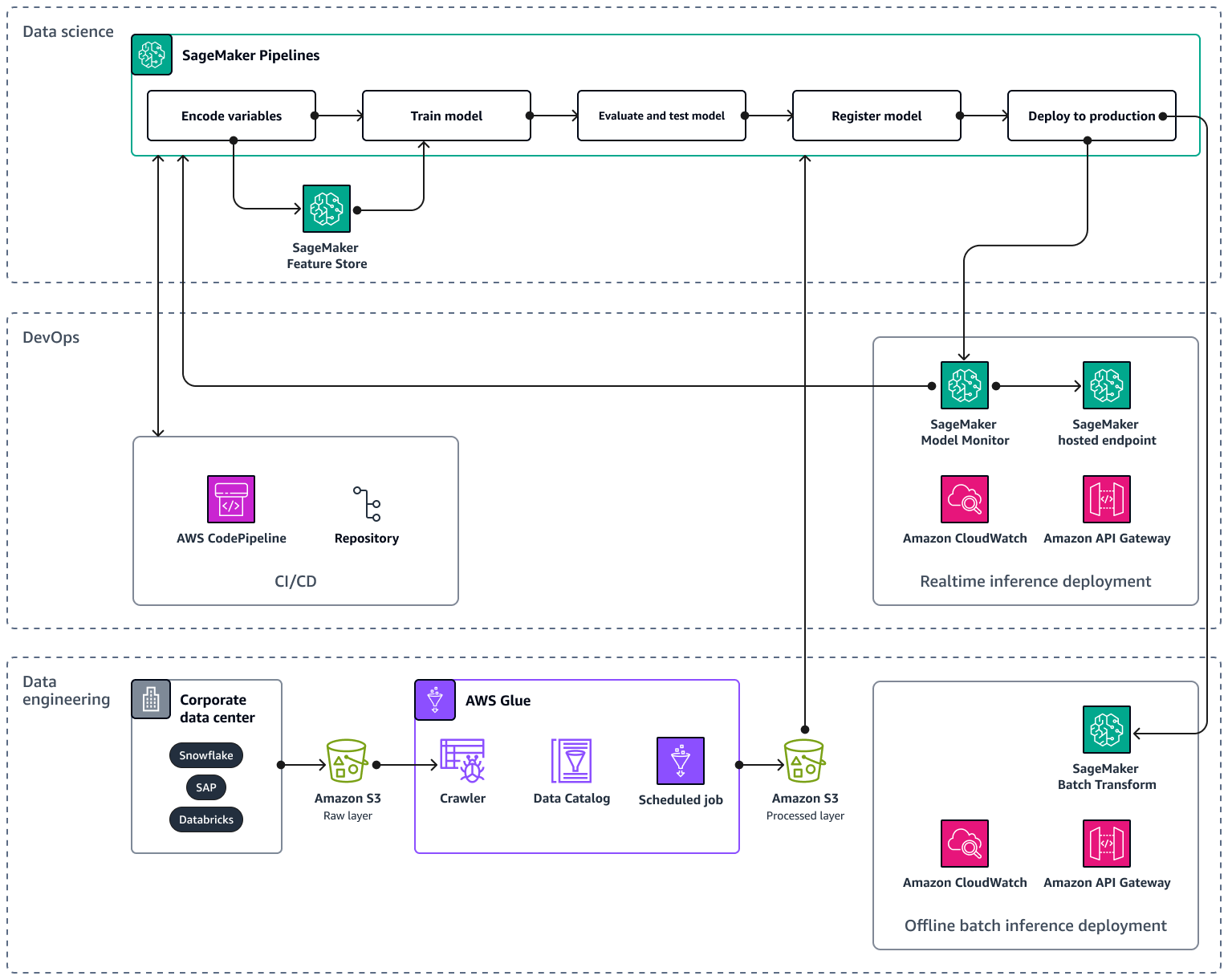
L'exemple d' AWS architecture comprend trois couches : ingénierie des données et science des données. DevOps
La couche d'ingénierie des données se concentre sur l'ingestion de données provenant de sources de données d'entreprise en utilisant AWS Gluepuis en stockant les données de manière rentable dans Amazon Simple Storage Service (Amazon S3). AWS Glue est un ETL service sans serveur entièrement géré qui vous aide à classer, nettoyer, transformer et transférer de manière fiable des données entre différents magasins de données. Amazon S3 est un service de stockage d'objets qui offre évolutivité, disponibilité des données, sécurité et performances. La couche d'ingénierie des données montre également le déploiement de l'inférence par lots hors ligne à l'aide de la transformation par lots dans Amazon SageMaker AI. La transformation par lots obtient les données d'entrée d'Amazon S3 et les envoie dans une ou plusieurs HTTP requêtes via Amazon API Gateway au modèle de pipeline d'inférence. Amazon API Gateway est un service entièrement géré qui vous aide à créer, publier, gérer, surveiller et sécuriser APIs à n'importe quelle échelle. Enfin, la couche d'ingénierie des données montre l'utilisation d'Amazon CloudWatch, un service qui donne une visibilité sur les performances du système et vous aide à définir des alarmes, à réagir automatiquement aux changements et à obtenir une vue unifiée de l'état de santé opérationnel. CloudWatch stocke les fichiers journaux dans un compartiment Amazon S3 que vous spécifiez.
La DevOps couche utilise API Gateway et Amazon SageMaker AI Model Monitor pour le déploiement d'inférences en temps réel. CloudWatch Model Monitor vous aide à configurer un système de déclenchement automatique d'alertes pour les écarts de qualité du modèle, tels que la dérive des données et les anomalies. Amazon CloudWatch Logs collecte les fichiers journaux à partir de Model Monitor et vous avertit lorsque la qualité de votre modèle atteint certains seuils, que vous avez prédéfinis. La DevOps couche montre également l'utilisation de AWS CodePipelinepour automatiser les pipelines de distribution de code.
La couche de science des données montre l'utilisation d'Amazon SageMaker AI Pipelines et d'Amazon SageMaker AI Feature Store pour gérer le cycle de vie de l'apprentissage automatique. SageMaker AI Pipelines est un service d'orchestration de flux de travail spécialement conçu qui vous aide à automatiser toutes les phases du ML, du prétraitement des données à la surveillance des modèles. Grâce à une interface utilisateur intuitive et à PythonSDK, vous pouvez gérer des pipelines de machine end-to-end learning répétables à grande échelle. L'intégration native à plusieurs vous Services AWS permet de personnaliser le cycle de vie du machine learning en fonction de vos MLOps besoins. Feature Store est un référentiel entièrement géré et spécialement conçu pour stocker, partager et gérer les fonctionnalités des modèles de machine learning. Les fonctionnalités sont des entrées dans les modèles ML, et elles sont utilisées lors de l'entraînement et de l'inférence.
