Les traductions sont fournies par des outils de traduction automatique. En cas de conflit entre le contenu d'une traduction et celui de la version originale en anglais, la version anglaise prévaudra.
Mettre en œuvre la reprise après sinistre entre régions avec AWS DMS et Amazon Aurora
Mark Hudson, Amazon Web Services
Récapitulatif
Les catastrophes naturelles ou provoquées par l'homme peuvent survenir à tout moment et avoir un impact sur la disponibilité des services et des charges de travail exécutés dans une région AWS donnée. Pour atténuer les risques, vous devez développer un plan de reprise après sinistre (DR) qui intègre les fonctionnalités interrégionales intégrées des services AWS. Pour les services AWS qui ne fournissent pas par nature de fonctionnalités interrégionales, le plan de reprise après sinistre doit également fournir une solution pour gérer leur basculement entre les régions AWS.
Ce modèle vous guide tout au long d'une configuration de reprise après sinistre impliquant deux clusters de bases de données Amazon Aurora compatibles Edition dans une même région. Pour répondre aux exigences de reprise après sinistre, les clusters de bases de données sont configurés pour utiliser la fonctionnalité de base de données globale Amazon Aurora, avec une seule base de données couvrant plusieurs régions AWS. Une tâche AWS Database Migration Service (AWS DMS) réplique les données entre les clusters de la région locale. Cependant, AWS DMS ne prend actuellement pas en charge le basculement des tâches entre les régions. Ce modèle inclut les étapes nécessaires pour contourner cette limitation et configurer AWS DMS de manière indépendante dans les deux régions.
Conditions préalables et limitations
Prérequis
Certaines régions AWS principales et secondaires prenant en charge les bases de données mondiales Amazon Aurora.
Deux clusters de bases de données Amazon Aurora compatibles Edition indépendants regroupés dans un seul compte dans la région principale.
Classe d'instance de base de données db.r5 ou supérieure (recommandé).
Une tâche AWS DMS dans la région principale effectuant une réplication continue entre les clusters de bases de données existants.
Ressources de la région DR en place pour répondre aux exigences relatives à la création d'instances de base de données. Pour plus d'informations, consultez la section Utilisation d'une instance de base de données dans un VPC.
Limites
Pour obtenir la liste complète des limites des bases de données mondiales Amazon Aurora, consultez Limitations des bases de données mondiales Amazon Aurora.
Versions du produit
Édition compatible avec Amazon Aurora MySQL 5.7 ou 8.0. Pour plus d'informations, consultez les versions d'Amazon Aurora.
Architecture
Pile technologique cible
Cluster de bases de données mondial Amazon Aurora MySQL Compatible Edition
AWS DMS
Architecture cible
Le schéma suivant montre une base de données globale pour deux régions AWS, l'une avec les bases de données principales et de rapport et la réplication AWS DMS, et l'autre avec les bases de données principales et de rapports secondaires.
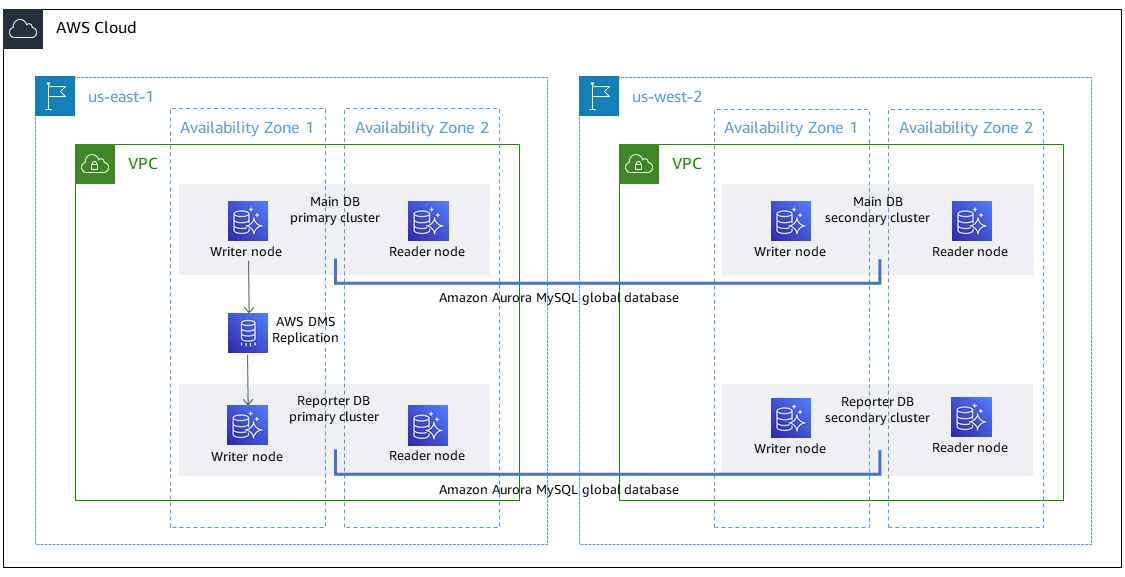
Automatisation et mise à l'échelle
Vous pouvez utiliser AWS CloudFormation pour créer l'infrastructure requise dans la région secondaire, telle que le cloud privé virtuel (VPC), les sous-réseaux et les groupes de paramètres. Vous pouvez également utiliser AWS CloudFormation pour créer les clusters secondaires dans la région DR et les ajouter à la base de données globale. Si vous avez utilisé des CloudFormation modèles pour créer les clusters de base de données dans la région principale, vous pouvez les mettre à jour ou les compléter avec un modèle supplémentaire pour créer la ressource de base de données globale. Pour plus d'informations, consultez Création d'un cluster de base de données Amazon Aurora avec deux instances de base de données et Création d'un cluster de base de données global pour Aurora MySQL.
Enfin, vous pouvez créer les tâches AWS DMS dans les régions principale et secondaire en utilisant les événements CloudFormation After Failover et Failback. Pour de plus amples informations, veuillez consulter AWS::DMS::ReplicationTask
Outils
Amazon Aurora est un moteur de base de données relationnelle entièrement géré compatible avec MySQL et PostgreSQL. Ce modèle utilise Amazon Aurora MySQL Compatible Edition.
Les bases de données mondiales Amazon Aurora sont conçues pour les applications distribuées dans le monde entier. Une seule base de données mondiale Amazon Aurora peut couvrir plusieurs régions AWS. Il réplique vos données sans aucun impact sur les performances de la base de données. Il permet également des lectures locales rapides avec une faible latence dans chaque région et assure la reprise après sinistre en cas de panne à l'échelle de la région.
AWS DMS permet une migration ponctuelle ou une réplication continue. Une tâche de réplication continue permet de synchroniser vos bases de données source et cible. Une fois configurée, la tâche de réplication en cours applique en permanence les modifications de source à la cible avec une latence minimale. Toutes les fonctionnalités d'AWS DMS, telles que la validation des données et les transformations, sont disponibles pour toutes les tâches de réplication.
Épopées
| Tâche | Description | Compétences requises |
|---|---|---|
Modifiez le groupe de paramètres du cluster de base de données. | Dans le groupe de paramètres du cluster de bases de données existant, activez la journalisation binaire au niveau des lignes en définissant le AWS DMS nécessite une journalisation binaire au niveau des lignes pour les bases de données compatibles MySQL lors de la réplication continue ou de la capture des données modifiées (CDC). Pour plus d'informations, consultez Utilisation d'une base de données compatible avec MySQL gérée par AWS comme source pour AWS DMS. | Administrateur AWS |
Mettez à jour la période de conservation des journaux binaires de la base de données. | À l'aide d'un client MySQL installé sur l'appareil de votre utilisateur final ou d'une instance Amazon Elastic Compute Cloud (Amazon EC2), exécutez la procédure stockée suivante fournie par Amazon Relational Database Service (Amazon RDS) sur le nœud d'écriture du cluster de base de données principal,
Confirmez le réglage en exécutant la commande suivante.
Les bases de données compatibles MySQL gérées par AWS purgent les journaux binaires dès que possible. Par conséquent, la période de conservation doit être suffisamment longue pour garantir que les journaux ne sont pas purgés avant l'exécution de la tâche AWS DMS. Une valeur de 24 heures est généralement suffisante, mais elle doit être basée sur le temps nécessaire pour configurer la tâche AWS DMS dans la région DR. | DBA |
| Tâche | Description | Compétences requises |
|---|---|---|
Enregistrez l'ARN de la tâche AWS DMS. | Utilisez l'Amazon Resource Name (ARN) pour obtenir le nom de la tâche AWS DMS pour une utilisation ultérieure. Pour récupérer l'ARN de la tâche AWS DMS, affichez la tâche dans la console ou exécutez la commande suivante.
Un ARN ressemble à ce qui suit.
Les caractères situés après le dernier deux-points correspondent au nom de la tâche utilisé lors d'une étape ultérieure. | Administrateur AWS |
Modifiez la tâche AWS DMS existante pour enregistrer le point de contrôle. | AWS DMS crée des points de contrôle contenant des informations afin que le moteur de réplication connaisse le point de reprise du flux de modifications. Pour enregistrer les informations relatives aux points de contrôle, effectuez les opérations suivantes dans la console :
| Administrateur AWS |
Validez les informations du point de contrôle. | À l'aide d'un client MySQL connecté au point de terminaison du rédacteur du cluster, interrogez la nouvelle table de métadonnées dans le cluster de base de données rapporteur pour vérifier qu'elle existe et qu'elle contient les informations sur l'état de réplication. Exécutez la commande suivante.
Le nom de la tâche issu de l'ARN doit se trouver dans ce tableau dans la | DBA |
| Tâche | Description | Compétences requises |
|---|---|---|
Créez une infrastructure de base dans la région DR. | Créez les composants de base nécessaires à la création et à l'accès aux clusters Amazon Aurora :
Assurez-vous que la configuration des deux groupes de paramètres correspond à celle de la région principale. | Administrateur AWS |
Ajoutez la région DR aux deux clusters Amazon Aurora. | Ajoutez une région secondaire (la région DR) aux clusters Amazon Aurora principaux et déclarants. Pour plus d'informations, consultez Ajouter une région AWS à une base de données mondiale Amazon Aurora. | Administrateur AWS |
| Tâche | Description | Compétences requises |
|---|---|---|
Arrêtez la tâche AWS DMS. | La tâche AWS DMS dans la région principale ne fonctionnera pas correctement après le basculement et doit être arrêtée pour éviter les erreurs. | Administrateur AWS |
Effectuez un basculement géré. | Effectuez un basculement géré du cluster de base de données principal vers la région DR. Pour obtenir des instructions, consultez la section Réalisation de basculements planifiés gérés pour les bases de données mondiales Amazon Aurora. Une fois le basculement sur le cluster de base de données principal terminé, effectuez la même activité sur le cluster de bases de données rapporteur. | Administrateur AWS, DBA |
Chargez les données dans la base de données principale. | Insérez les données de test dans le nœud d'écriture de la base de données principale du cluster de bases de données DR. Ces données seront utilisées pour valider le bon fonctionnement de la réplication. | DBA |
Créez l'instance de réplication AWS DMS. | Pour créer l'instance de réplication AWS DMS dans la région DR, consultez Création d'une instance de réplication. | Administrateur AWS, DBA |
Créez les points de terminaison source et cible AWS DMS. | Pour créer les points de terminaison source et cible AWS DMS dans la région DR, consultez Création de points de terminaison source et cible. La source doit pointer vers l'instance d'écriture du cluster de base de données principal. La cible doit pointer vers l'instance d'écriture du cluster de base de données rapporteur. | Administrateur AWS, DBA |
Obtenez le point de contrôle de réplication. | Pour obtenir le point de contrôle de réplication, utilisez un client MySQL pour interroger la table de métadonnées en exécutant la commande suivante sur le nœud d'écriture du cluster de base de données rapporteur dans la région DR.
Dans le tableau, recherchez la valeur task_name qui correspond à l'ARN de la tâche AWS DMS qui existe dans la région principale que vous avez obtenue lors du deuxième épisode épique. | DBA |
Créez une tâche AWS DMS. | À l'aide de la console, créez une tâche AWS DMS dans la région DR. Dans la tâche, spécifiez une méthode de migration consistant à répliquer uniquement les modifications de données. Pour plus d'informations, consultez la section Création d'une tâche.
Définissez le paramètre Démarrer la tâche de migration d'AWS DMS sur Automatiquement lors de la création. | Administrateur AWS, DBA |
Enregistrez l'ARN de la tâche AWS DMS. | Utilisez l'ARN pour obtenir le nom de la tâche AWS DMS pour une utilisation ultérieure. Pour récupérer l'ARN de la tâche AWS DMS, exécutez la commande suivante.
| Administrateur AWS, DBA |
Validez les données répliquées. | Interrogez le cluster de base de données rapporteur dans la région DR pour confirmer que les données de test que vous avez chargées dans le cluster de base de données principal ont été répliquées. | DBA |
| Tâche | Description | Compétences requises |
|---|---|---|
Arrêtez la tâche AWS DMS. | La tâche AWS DMS dans la région DR ne fonctionnera pas correctement après le failback et doit être arrêtée pour éviter les erreurs. | Administrateur AWS |
Effectuez un retour en arrière géré. | Replacez le cluster de base de données principal dans la région principale. Pour obtenir des instructions, consultez la section Réalisation de basculements planifiés gérés pour les bases de données mondiales Amazon Aurora. Une fois le retour sur le cluster de base de données principal terminé, effectuez la même activité sur le cluster de base de données rapporteur. | Administrateur AWS, DBA |
Obtenez le point de contrôle de réplication. | Pour obtenir le point de contrôle de réplication, utilisez un client MySQL pour interroger la table de métadonnées en exécutant la commande suivante sur le nœud d'écriture du cluster de base de données rapporteur dans la région DR.
Dans le tableau, trouvez la | DBA |
Mettez à jour les points de terminaison source et cible d'AWS DMS. | Une fois les clusters de base de données défaillants, vérifiez les clusters de la région principale pour déterminer quels nœuds sont les instances d'écriture. Vérifiez ensuite que les points de terminaison source et cible AWS DMS existants dans la région principale pointent vers les instances du rédacteur. Si ce n'est pas le cas, mettez à jour les points de terminaison avec les noms DNS (Domain Name System) de l'instance du rédacteur. | Administrateur AWS |
Créez une tâche AWS DMS. | À l'aide de la console, créez une tâche AWS DMS dans la région principale. Dans la tâche, spécifiez une méthode de migration consistant à répliquer uniquement les modifications de données. Pour plus d'informations, consultez la section Création d'une tâche.
| Administrateur AWS, DBA |
Enregistrez la tâche AWS DMS Amazon Resource Name (ARN). | Utilisez l'ARN pour obtenir le nom de la tâche AWS DMS pour une utilisation ultérieure. Pour récupérer l'ARN de la tâche AWS DMS, exécutez la commande suivante :
Le nom de la tâche sera nécessaire lors de l'exécution d'un autre basculement géré ou lors d'un scénario de reprise après sinistre. | Administrateur AWS, DBA |
Supprimez les tâches AWS DMS. | Supprimez la tâche AWS DMS d'origine (actuellement arrêtée) dans la région principale et la tâche AWS DMS existante (actuellement arrêtée) dans la région secondaire. | Administrateur AWS |
Ressources connexes
Informations supplémentaires
Les bases de données mondiales Amazon Aurora sont utilisées dans cet exemple pour la reprise après sinistre car elles fournissent un objectif de temps de restauration (RTO) effectif de 1 seconde et un objectif de point de reprise (RPO) inférieur à 1 minute, tous deux inférieurs aux solutions répliquées traditionnelles et idéaux pour les scénarios de reprise après sinistre.
Les bases de données mondiales Amazon Aurora offrent de nombreux autres avantages, notamment les suivants :
Lectures globales avec latence locale — Les consommateurs du monde entier peuvent accéder aux informations d'une région locale, avec une latence locale.
Clusters de base de données Amazon Aurora secondaires évolutifs : les clusters secondaires peuvent être mis à l'échelle indépendamment, ce qui permet d'ajouter jusqu'à 16 répliques en lecture seule.
Réplication rapide des clusters de base de données Amazon Aurora principaux vers les clusters secondaires : la réplication a peu d'impact sur les performances du cluster principal. Elle se produit au niveau de la couche de stockage, avec des latences de réplication entre régions généralement inférieures à une seconde.
Ce modèle utilise également AWS DMS pour la réplication. Les bases de données Amazon Aurora permettent de créer des répliques en lecture, ce qui peut simplifier le processus de réplication et la configuration de la reprise après sinistre. Cependant, AWS DMS est souvent utilisé pour effectuer une réplication lorsque des transformations de données sont requises ou lorsque la base de données cible nécessite des index supplémentaires que la base de données source ne possède pas.
