Étape 2 : Préparer les données
Une fois que vous disposez des données brutes, vous devez gérer les complications, telles que les données manquantes, et vous assurer que vous préparez les données pour les modèles de prévision qui rendent le mieux compte de l'interprétation voulue.
Comment gérer les données manquantes
La présence de valeurs manquantes dans les données brutes est un phénomène courant dans les problèmes de prévision réels. Une valeur manquante dans une série temporelle signifie que la vraie valeur correspondante à chaque moment avec la fréquence spécifiée n'est pas disponible pour un traitement ultérieur. Les valeurs peuvent être marquées comme manquantes pour plusieurs raisons.
Les valeurs manquantes peuvent être dues à l'absence de transaction ou à d'éventuelles erreurs de mesure (par exemple, parce qu'un service qui contrôlait certaines données ne fonctionnait pas correctement ou parce que la mesure ne pouvait pas s'effectuer correctement). Le principal exemple de ce dernier point dans l'étude de cas sur le commerce de détail est une rupture de stock dans la prévision de la demande, ce qui signifie que la demande ne correspond pas aux ventes de ce jour-là.
Des effets similaires peuvent survenir dans des scénarios de cloud computing lorsqu'un service a atteint une limite (par exemple, quand les instances Amazon EC2
Les valeurs manquantes peuvent également être insérées par les composants de traitement des caractéristiques, afin d'assurer une longueur égale des séries temporelles avec un remplissage. Si elles sont suffisamment répandues, les valeurs manquantes peuvent avoir un impact significatif sur la précision d'un modèle.
Exemple 1
Le remplissage consiste à ajouter des valeurs normalisées aux entrées manquantes dans votre jeu de données. Dans la figure suivante, les différentes stratégies de traitement des valeurs manquantes dans Amazon Forecast — remplissage avant, intermédiaire, en amont et futur — sont illustrées pour l'élément 2 dans un jeu de données de trois éléments.
Amazon Forecast prend en charge le remplissage à la fois pour la série temporelle cible et la série temporelle associée. La date de début globale est définie comme la date de début la plus proche des dates de début de tous les éléments de votre jeu de données. Dans l'exemple ci-dessous, la date de début globale correspond à l'article 1. De même, la date de fin globale est définie comme la dernière date de fin de la série temporelle pour tous les articles, qui se produit pour l'article 2.
Le remplissage avant complète toutes les valeurs depuis le début de la série temporelle donnée jusqu'à la date de début globale. Au moment de la publication de ce document, Amazon Forecast n'active aucun remplissage avant et permet à toutes les séries temporelles de commencer à des moments différents. Le remplissage intermédiaire indique les valeurs qui ont été renseignées au milieu de la série temporelle (par exemple, entre les dates de début et de fin des éléments), et le remplissage en amont à partir de la dernière date de cette série temporelle jusqu'à la date de fin globale.
Pour la série temporelle cible, les méthodes de remplissage intermédiaire et en amont ont une logique de remplissage par défaut de zéro. Le remplissage futur (qui s'applique uniquement à la série temporelle associée) complète toute valeur manquante entre la date de fin globale des articles et l'horizon de prévision spécifié par le client. Les valeurs futures sont requises pour utiliser le jeu de données de séries temporelles associé avec Prophet et DeepAr+, et facultatives pour CNN-QR.
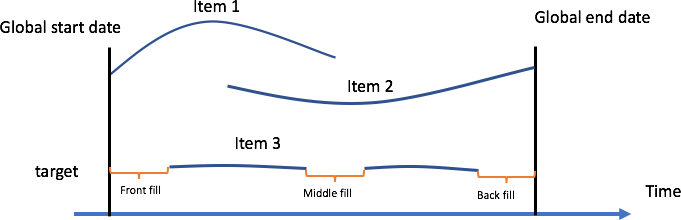
Stratégies de gestion des valeurs manquantes dans Amazon Forecast
Dans la figure précédente, la date de début globale indique la date de début la plus ancienne parmi les dates de début de tous les articles, et la date de fin globale indique la date de fin la plus récente par rapport aux dates de fin de tous les articles. L'horizon de prévision est la période sur laquelle Forecast fournit des prévisions pour la valeur cible.
Il s'agit d'un scénario courant dans l'étude sur le commerce de détail qui représente des ventes nulles pour les données transactionnelles relatives aux articles disponibles. Ces valeurs sont traitées comme de vrais zéros et utilisées dans le composant d'évaluation des métriques. Amazon Forecast permet à l'utilisateur d'identifier les valeurs réellement manquantes et de les coder sous forme de nombres (NaN) à traiter par les algorithmes. Ce document examine ensuite pourquoi ces deux cas diffèrent et quand chacun d'eux est utile.
Dans l'étude de cas sur le commerce de détail, l'information selon laquelle un détaillant a vendu zéro unité d'un article disponible diffère de l'information selon laquelle zéro unité d'un article indisponible est vendue, soit dans les périodes hors de son existence (par exemple, avant son lancement ou après l'arrêt de sa production), soit dans les périodes dans son existence (par exemple, partiellement en rupture de stock, ou lorsqu'il n'y avait pas de données de vente enregistrées pour cette plage de temps). Le remplissage à zéro par défaut est applicable dans ce premier cas. Dans ce dernier cas, même si la valeur cible correspondante est généralement nulle, des informations supplémentaires sont transmises par la valeur marquée comme manquante. La bonne pratique consiste à conserver les informations indiquant qu'il manquait des données et à ne pas les supprimer. Consultez l'exemple suivant pour comprendre pourquoi il est important de conserver les informations.
Amazon Forecast prend en charge des logiques de remplissage supplémentaires basées sur la valeur, la moyenne, la médiane, le minimum et le maximum. Pour les séries temporelles associées (par exemple, prix ou promotion), aucune valeur par défaut n'est spécifiée pour les méthodes de remplissage intermédiaires, en amont ou futures, car la logique des valeurs manquantes correcte varie en fonction du type d'attribut et du cas d'utilisation. La logique de remplissage prise en charge pour les séries temporelles associées inclut le zéro, la valeur, la moyenne, la médiane, le minimum et le maximum.
Pour effectuer le remplissage des valeurs manquantes, spécifiez les types de remplissage à mettre en œuvre lorsque vous appelez l'opération CreatePredictor. La logique de remplissage est spécifiée dans les objets FeaturizationMethod. Par exemple, pour coder une valeur qui ne représente pas des ventes nulles d'un produit indisponible dans la série temporelle cible, marquez une valeur comme réellement manquante en définissant le type de remplissage égal à NaN. Contrairement au remplissage par zéro, les valeurs codées avec la valeur NaN sont traitées comme réellement manquantes et ne sont pas utilisées dans le composant d'évaluation de la métrique.

L'effet du remplissage par 0 par rapport au remplissage par NaN sur les prévisions pour le même article
Dans la figure précédente, dans le graphique de gauche, les valeurs situées à gauche de la ligne noire verticale sont remplies de 0, ce qui donne lieu à une prévision sous-biaisée (à droite de la ligne noire verticale). Dans le graphique de droite, ces valeurs sont marquées comme NaN, ce qui permet d'obtenir des prévisions appropriées.
Exemple 2
La figure précédente illustre l'importance de gérer correctement les valeurs manquantes pour un modèle spatial à états linéaires, tel qu'ARIMA ou ETS. Celui-ci trace la prévision de la demande pour un article qui est partiellement en rupture de stock. La zone d'entraînement est affichée dans le graphique de gauche en vert, la plage de prédiction dans le panneau de droite en rouge et la véritable cible en noir. Les prévisions médianes, p10 et p90, sont indiquées respectivement sur la ligne rouge et dans la région ombrée. La partie inférieure montre les articles en rupture de stock (80 % des données) marqués en rouge. Dans le graphique de gauche, les zones en rupture de stock sont ignorées et remplies par 0.
Les modèles de prévision supposent donc qu'il y a beaucoup de zéros à prévoir et que, par conséquent, les prévisions sont trop basses. Dans le graphique de droite, les zones en rupture de stock sont traitées comme de véritables observations manquantes, et la demande devient incertaine dans la région en rupture de stock. Les valeurs manquantes pour les articles en rupture de stock étant correctement marquées comme NaN, vous ne constatez aucun sous-biais dans la plage de prévision de ce graphique. Amazon Forecast comble ces lacunes en matière de données, vous permettant ainsi de gérer correctement les données manquantes, sans avoir à modifier explicitement toutes leurs données d'entrée.
Concepts d'organisation de fonction de séries temporelles associées
Amazon Forecast permet aux utilisateurs de saisir des données associées afin d'améliorer la précision de certains modèles de prévision pris en charge. Ces données peuvent être de deux types : des séries temporelles associées ou des métadonnées d'éléments statiques.
Note
Les métadonnées et les données associées sont appelées fonctions en machine learning, et covariables en statistiques.
Les séries temporelles connexes sont des séries temporelles qui ont une certaine corrélation avec la valeur cible, et qui devraient apporter une certaine force statistique à la prévision sur la valeur cible. En effet, elles fournissent une explication en termes intuitifs. Consultez Amazon Forecast: predicting time-series at scale
Dans Amazon Forecast, vous pouvez ajouter deux types de séries temporelles associées : des séries temporelles historiques et des séries temporelles prospectives. Les séries temporelles liées à l'historique contiennent des points de données jusqu'à l'horizon de prévision, et ne contiennent pas de points de données dans l'horizon de prévision futur. Les séries temporelles liées à l'avenir contiennent des points de données jusqu'à et dans l'horizon de la prévision.
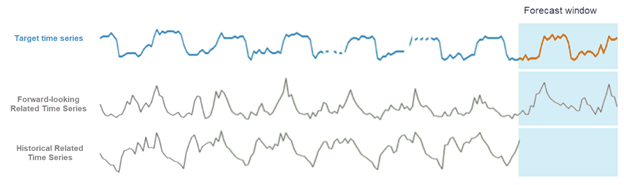
Différentes approches concernant l'utilisation de séries temporelles associées avec Amazon Forecast
Exemple 3
La figure suivante montre un exemple d'utilisation de séries temporelles associées pour prédire la demande future d'un livre populaire. La ligne bleue représente la demande dans la série temporelle cible. Le prix est indiqué par la ligne verte. La ligne verticale représente la date de début des prévisions, et les prévisions relatives aux deux quantiles sont affichées à droite de la ligne verticale.
Cet exemple utilise une série temporelle associée prospective qui s'aligne sur la série temporelle cible au niveau de granularité de la prévision, et qui est connue à tout moment (ou la plupart du temps) dans le futur et dans la plage de la date de début de la prévision à la date de début de la prévision incrémentée par l'horizon de la prévision (date de fin de la prévision).
La figure suivante montre également que le prix est une caractéristique appropriée à utiliser, puisque vous pouvez voir des corrélations entre une baisse du prix et une augmentation des ventes du produit. Les séries temporelles associées peuvent être fournies à Amazon Forecast par le biais d'un fichier CSV distinct, contenant la référence de l'article, l'horodatage et les valeurs des séries temporelles associées (dans ce cas, le prix).
Amazon Forecast prend en charge les méthodes d'agrégation, telles que la moyenne et la somme pour les séries temporelles cibles, mais pas pour les séries temporelles associées. Par exemple, il est peu judicieux d'additionner un prix quotidien et un prix hebdomadaire, et il en va de même pour les promotions quotidiennes.
Amazon Forecast peut intégrer automatiquement des informations sur la météo et les vacances dans un modèle en incluant des jeux de données de fonctionnalités intégrés (consultez SupplementaryFeature). Les informations météorologiques et les jours fériés peuvent avoir une incidence significative sur la demande du commerce de détail.
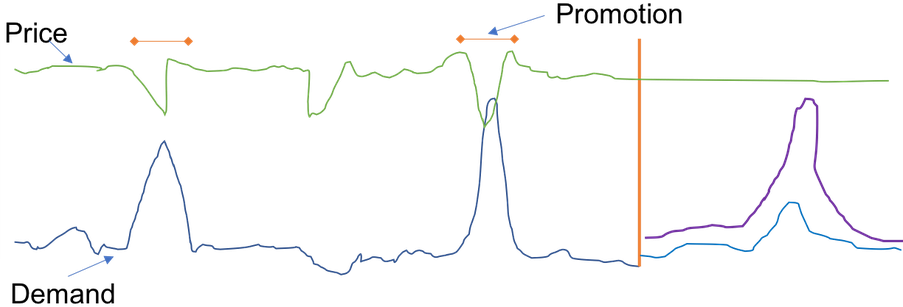
Les ventes d'un article donné (en bleu, à gauche de la ligne rouge verticale)
Les métadonnées des articles, également connues sous le nom de variables catégoriques, sont d'autres caractéristiques utiles qui peuvent être introduites dans Amazon Forecast. Consultez Amazon Forecast: predicting time-series at scale
