Terjemahan disediakan oleh mesin penerjemah. Jika konten terjemahan yang diberikan bertentangan dengan versi bahasa Inggris aslinya, utamakan versi bahasa Inggris.
AWS Arsitektur yang direkomendasikan untuk peramalan permintaan produk baru
Saat Anda menskalakan pipeline AI/ML Anda ke beberapa produk dan wilayah, Anda disarankan untuk mengikuti praktik terbaik operasi pembelajaran mesin (MLOps) untuk reproduktifitas, keandalan, dan skalabilitas. Untuk informasi selengkapnya, lihat Menerapkan MLOps dalam dokumentasi Amazon SageMaker AI. Gambar berikut menunjukkan contoh AWS arsitektur untuk mengimplementasikan model ML yang memperkirakan permintaan untuk pengenalan produk baru.
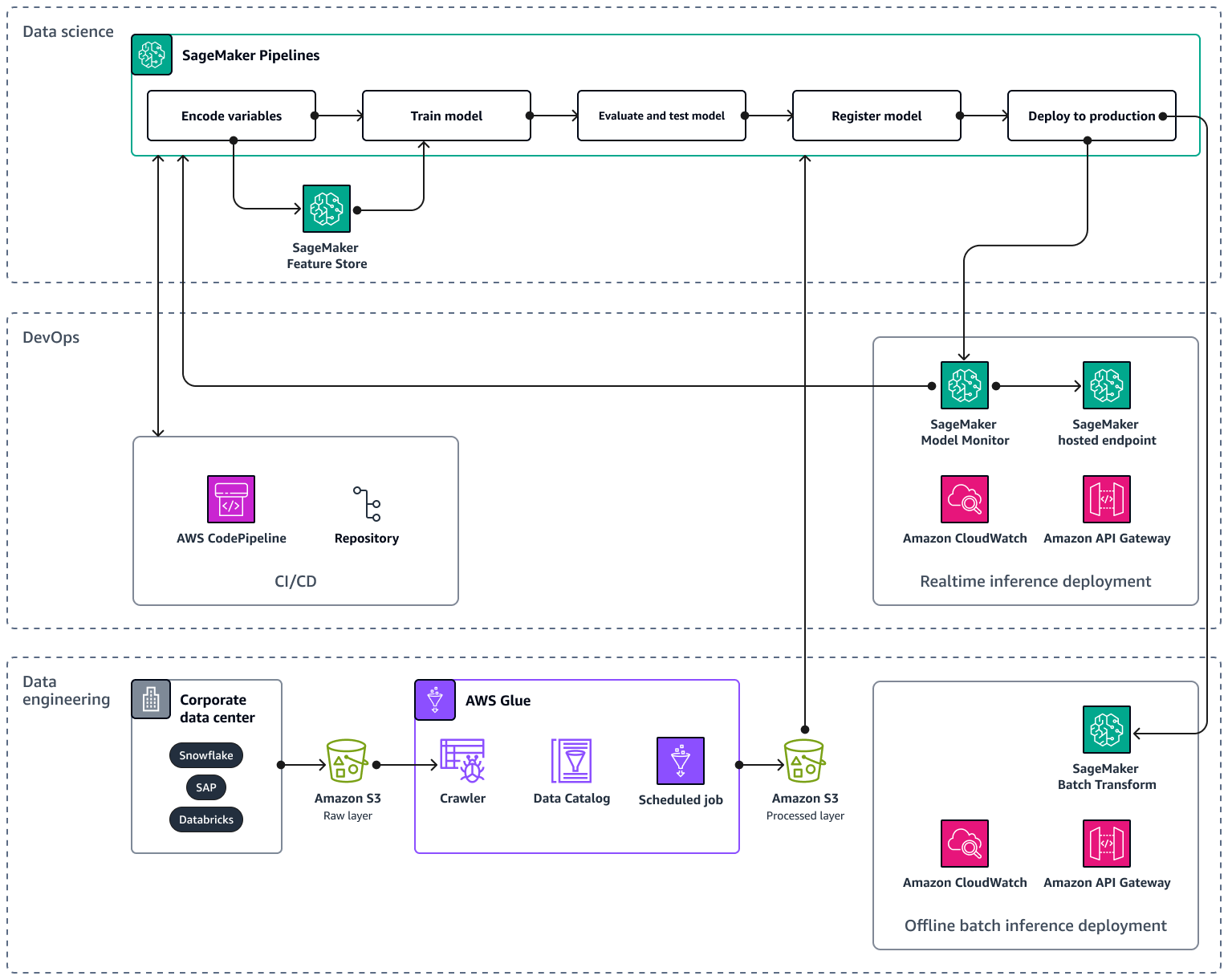
Contoh AWS arsitektur terdiri dari tiga lapisan: Rekayasa data DevOps, dan Ilmu data.
Lapisan rekayasa data berfokus pada pengambilan data dari sumber data perusahaan dengan menggunakan AWS Gluedan kemudian menyimpan data dengan cara yang hemat biaya di Amazon Simple Storage Service (Amazon S3). AWS Glue adalah ETL layanan tanpa server yang dikelola sepenuhnya yang membantu Anda mengkategorikan, membersihkan, mengubah, dan mentransfer data dengan andal antara berbagai penyimpanan data. Amazon S3 adalah layanan penyimpanan objek yang menawarkan skalabilitas, ketersediaan data, keamanan, dan kinerja. Lapisan rekayasa data juga menunjukkan penyebaran inferensi batch offline dengan menggunakan transformasi batch di Amazon SageMaker AI. Transformasi batch memperoleh data input dari Amazon S3 dan mengirimkannya dalam satu atau HTTP beberapa permintaan melalui APIAmazon Gateway ke model pipeline inferensi. Amazon API Gateway adalah layanan terkelola penuh yang membantu Anda membuat, menerbitkan, memelihara, memantau, dan mengamankan APIs dalam skala apa pun. Terakhir, lapisan rekayasa data menunjukkan penggunaan Amazon CloudWatch, layanan yang memberikan visibilitas ke kinerja seluruh sistem dan membantu Anda mengatur alarm, bereaksi secara otomatis terhadap perubahan, dan mendapatkan pandangan terpadu tentang kesehatan operasional. CloudWatch menyimpan file log ke bucket Amazon S3 yang Anda tentukan.
DevOps Lapisan ini menggunakan API Gateway, CloudWatch, dan Amazon SageMaker AI Model Monitor untuk penyebaran inferensi waktu nyata. Model Monitor membantu Anda menyiapkan sistem pemicu peringatan otomatis untuk penyimpangan dalam kualitas model, seperti penyimpangan data dan anomali. Amazon CloudWatch Logs mengumpulkan file log dari Model Monitor dan memberi tahu Anda saat kualitas model mencapai ambang batas tertentu, yang telah Anda tetapkan sebelumnya. DevOps Lapisan ini juga menunjukkan penggunaan AWS CodePipelineuntuk mengotomatisasi pipa pengiriman kode.
Lapisan ilmu data menunjukkan penggunaan Amazon SageMaker AI Pipelines dan Amazon SageMaker AI Feature Store untuk mengelola siklus hidup pembelajaran mesin. SageMaker AI Pipelines adalah layanan orkestrasi alur kerja yang dibuat khusus yang membantu Anda mengotomatiskan semua fase ML, mulai dari pemrosesan awal data hingga pemantauan model. Dengan UI dan Python yang intuitifSDK, Anda dapat mengelola pipeline end-to-end ML berulang dalam skala besar. Integrasi native dengan beberapa Layanan AWS membantu Anda menyesuaikan siklus hidup ML berdasarkan kebutuhan AndaMLOps. Feature Store adalah repositori yang dikelola sepenuhnya dan dibuat khusus untuk menyimpan, berbagi, dan mengelola fitur untuk model ML. Fitur adalah input untuk model ML, dan mereka digunakan selama pelatihan dan inferensi.
