Terjemahan disediakan oleh mesin penerjemah. Jika konten terjemahan yang diberikan bertentangan dengan versi bahasa Inggris aslinya, utamakan versi bahasa Inggris.
Model Monitor FAQs
Lihat berikut ini FAQs untuk informasi selengkapnya tentang Amazon SageMaker Model Monitor.
T: Bagaimana Model Monitor dan SageMaker Clarify membantu pelanggan memantau perilaku model?
Pelanggan dapat memantau perilaku model sepanjang empat dimensi - Kualitas data, kualitas Model, penyimpangan Bias, dan penyimpangan Atribusi Fitur melalui Amazon SageMaker Model Monitor dan Clarify. SageMaker Model Monitor
T: Apa yang terjadi di latar belakang saat monitor Model Sagemaker diaktifkan?
Amazon SageMaker Model Monitor mengotomatiskan pemantauan model sehingga mengurangi kebutuhan untuk memantau model secara manual atau membuat perkakas tambahan apa pun. Untuk mengotomatiskan proses, Model Monitor memberi Anda kemampuan untuk membuat serangkaian statistik dasar dan kendala menggunakan data yang digunakan untuk melatih model Anda, lalu mengatur jadwal untuk memantau prediksi yang dibuat pada titik akhir Anda. Model Monitor menggunakan aturan untuk mendeteksi penyimpangan dalam model Anda dan memberi tahu Anda ketika itu terjadi. Langkah-langkah berikut menjelaskan apa yang terjadi ketika Anda mengaktifkan pemantauan model:
-
Aktifkan pemantauan model: Untuk titik akhir real-time, Anda harus mengaktifkan titik akhir untuk menangkap data dari permintaan yang masuk ke model ML yang diterapkan dan prediksi model yang dihasilkan. Untuk pekerjaan transformasi batch, aktifkan pengambilan data dari input dan output transformasi batch.
-
Pekerjaan pemrosesan dasar: Anda kemudian membuat garis dasar dari kumpulan data yang digunakan untuk melatih model. Garis dasar menghitung metrik dan menyarankan batasan untuk metrik. Misalnya, skor recall untuk model tidak boleh mundur dan turun di bawah 0,571, atau skor presisi tidak boleh turun di bawah 1,0. Prediksi real-time atau batch dari model Anda dibandingkan dengan batasan dan dilaporkan sebagai pelanggaran jika berada di luar nilai yang dibatasi.
-
Pekerjaan pemantauan: Kemudian, Anda membuat jadwal pemantauan yang menentukan data apa yang akan dikumpulkan, seberapa sering mengumpulkannya, bagaimana menganalisisnya, dan laporan mana yang akan dihasilkan.
-
Gabungkan pekerjaan: Ini hanya berlaku jika Anda memanfaatkan Amazon SageMaker Ground Truth. Model Monitor membandingkan prediksi yang dibuat model Anda dengan label Ground Truth untuk mengukur kualitas model. Agar ini berfungsi, Anda secara berkala memberi label data yang diambil oleh pekerjaan endpoint atau batch transform Anda dan mengunggahnya ke Amazon S3.
Setelah Anda membuat dan mengunggah label Ground Truth, sertakan lokasi label sebagai parameter saat Anda membuat pekerjaan pemantauan.
Saat Anda menggunakan Model Monitor untuk memantau pekerjaan transformasi batch alih-alih titik akhir real-time, alih-alih menerima permintaan ke titik akhir dan melacak prediksi, Model Monitor memantau input dan output inferensi. Dalam jadwal Model Monitor, pelanggan memberikan jumlah dan jenis instance yang akan digunakan dalam pekerjaan pemrosesan. Sumber daya ini tetap dicadangkan sampai jadwal dihapus terlepas dari status eksekusi saat ini.
T: Apa itu Pengambilan Data, mengapa diperlukan, dan bagaimana cara mengaktifkannya?
Untuk mencatat input ke titik akhir model dan output inferensi dari model yang diterapkan ke Amazon S3, Anda dapat mengaktifkan fitur yang disebut Pengambilan Data. Untuk detail selengkapnya tentang cara mengaktifkannya untuk pekerjaan endpoint dan batch transform real-time, lihat Menangkap data dari titik akhir waktu nyata dan Menangkap data dari pekerjaan transformasi batch.
T: Apakah mengaktifkan Pengambilan Data berdampak pada kinerja titik akhir waktu nyata?
Pengambilan Data terjadi secara asinkron tanpa memengaruhi lalu lintas produksi. Setelah Anda mengaktifkan pengambilan data, maka payload permintaan dan respons, bersama dengan beberapa data meta tambahan, disimpan di lokasi Amazon S3 yang Anda tentukan di. DataCaptureConfig Perhatikan bahwa mungkin ada penundaan dalam penyebaran data yang diambil ke Amazon S3.
Anda juga dapat melihat data yang diambil dengan mencantumkan file penangkapan data yang disimpan di Amazon S3. Format jalur Amazon S3 adalah: s3:///{endpoint-name}/{variant-name}/yyyy/mm/dd/hh/filename.jsonl Amazon S3 Data Capture harus berada di wilayah yang sama dengan jadwal Monitor Model. Anda juga harus memastikan bahwa nama kolom untuk dataset dasar hanya memiliki huruf kecil dan garis bawah () _ sebagai satu-satunya pemisah.
T: Mengapa Ground Truth diperlukan untuk pemantauan model?
Label Ground Truth diperlukan oleh fitur Model Monitor berikut:
-
Pemantauan kualitas model membandingkan prediksi yang dibuat model Anda dengan label Ground Truth untuk mengukur kualitas model.
-
Pemantauan bias model memantau prediksi bias. Salah satu cara bias dapat diperkenalkan dalam model ML yang diterapkan adalah ketika data yang digunakan dalam pelatihan berbeda dari data yang digunakan untuk menghasilkan prediksi. Ini terutama diucapkan jika data yang digunakan untuk pelatihan berubah dari waktu ke waktu (seperti tingkat hipotek yang berfluktuasi), dan prediksi model tidak seakurat kecuali model dilatih ulang dengan data yang diperbarui. Misalnya, model untuk memprediksi harga rumah dapat menjadi bias jika tingkat hipotek yang digunakan untuk melatih model berbeda dari tingkat hipotek dunia nyata saat ini.
T: Untuk pelanggan yang memanfaatkan Ground Truth untuk pelabelan, apa langkah yang dapat saya ambil untuk memantau kualitas model?
Pemantauan kualitas model membandingkan prediksi yang dibuat model Anda dengan label Ground Truth untuk mengukur kualitas model. Agar ini berfungsi, Anda secara berkala memberi label data yang diambil oleh pekerjaan endpoint atau batch transform Anda dan mengunggahnya ke Amazon S3. Selain menangkap, eksekusi pemantauan bias model juga membutuhkan data Ground Truth. Dalam kasus penggunaan nyata, data Ground Truth harus dikumpulkan dan diunggah secara teratur ke lokasi Amazon S3 yang ditentukan. Untuk mencocokkan label Ground Truth dengan data prediksi yang diambil, harus ada pengidentifikasi unik untuk setiap rekaman dalam kumpulan data. Untuk struktur setiap catatan untuk data Ground Truth, lihat Ingest Ground Truth Labels dan Merge Them With Predictions.
Contoh kode berikut dapat digunakan untuk menghasilkan data Ground Truth buatan untuk dataset tabular.
import random def ground_truth_with_id(inference_id): random.seed(inference_id) # to get consistent results rand = random.random() # format required by the merge container return { "groundTruthData": { "data": "1" if rand < 0.7 else "0", # randomly generate positive labels 70% of the time "encoding": "CSV", }, "eventMetadata": { "eventId": str(inference_id), }, "eventVersion": "0", } def upload_ground_truth(upload_time): records = [ground_truth_with_id(i) for i in range(test_dataset_size)] fake_records = [json.dumps(r) for r in records] data_to_upload = "\n".join(fake_records) target_s3_uri = f"{ground_truth_upload_path}/{upload_time:%Y/%m/%d/%H/%M%S}.jsonl" print(f"Uploading {len(fake_records)} records to", target_s3_uri) S3Uploader.upload_string_as_file_body(data_to_upload, target_s3_uri) # Generate data for the last hour upload_ground_truth(datetime.utcnow() - timedelta(hours=1)) # Generate data once a hour def generate_fake_ground_truth(terminate_event): upload_ground_truth(datetime.utcnow()) for _ in range(0, 60): time.sleep(60) if terminate_event.is_set(): break ground_truth_thread = WorkerThread(do_run=generate_fake_ground_truth) ground_truth_thread.start()
Contoh kode berikut menunjukkan cara menghasilkan lalu lintas buatan untuk dikirim ke titik akhir model. Perhatikan inferenceId atribut yang digunakan di atas untuk memanggil. Jika ini ada, ini digunakan untuk bergabung dengan data Ground Truth (jika tidak, eventId digunakan).
import threading class WorkerThread(threading.Thread): def __init__(self, do_run, *args, **kwargs): super(WorkerThread, self).__init__(*args, **kwargs) self.__do_run = do_run self.__terminate_event = threading.Event() def terminate(self): self.__terminate_event.set() def run(self): while not self.__terminate_event.is_set(): self.__do_run(self.__terminate_event) def invoke_endpoint(terminate_event): with open(test_dataset, "r") as f: i = 0 for row in f: payload = row.rstrip("\n") response = sagemaker_runtime_client.invoke_endpoint( EndpointName=endpoint_name, ContentType="text/csv", Body=payload, InferenceId=str(i), # unique ID per row ) i += 1 response["Body"].read() time.sleep(1) if terminate_event.is_set(): break # Keep invoking the endpoint with test data invoke_endpoint_thread = WorkerThread(do_run=invoke_endpoint) invoke_endpoint_thread.start()
Anda harus mengunggah data Ground Truth ke bucket Amazon S3 yang memiliki format jalur yang sama dengan data yang diambil, yaitu dalam format berikut: s3://<bucket>/<prefix>/yyyy/mm/dd/hh
catatan
Tanggal di jalur ini adalah tanggal ketika label Ground Truth dikumpulkan. Itu tidak harus cocok dengan tanggal ketika inferensi dibuat.
T: Bagaimana pelanggan dapat menyesuaikan jadwal pemantauan?
Selain menggunakan mekanisme pemantauan bawaan, Anda dapat membuat jadwal dan prosedur pemantauan kustom Anda sendiri menggunakan skrip pra-pemrosesan dan pasca-pemrosesan, atau dengan menggunakan atau membangun wadah Anda sendiri. Penting untuk dicatat bahwa skrip pra-pemrosesan dan pasca-pemrosesan hanya berfungsi dengan data dan pekerjaan berkualitas model.
Amazon SageMaker AI menyediakan kemampuan bagi Anda untuk memantau dan mengevaluasi data yang diamati oleh titik akhir model. Untuk ini, Anda harus membuat garis dasar yang dengannya Anda membandingkan lalu lintas waktu nyata. Setelah baseline siap, buat jadwal untuk terus mengevaluasi dan membandingkan dengan baseline. Saat membuat jadwal, Anda dapat memberikan skrip pra-pemrosesan dan pasca-pemrosesan.
Contoh berikut menunjukkan bagaimana Anda dapat menyesuaikan jadwal pemantauan dengan skrip pra-pemrosesan dan pasca-pemrosesan.
import boto3, osfrom sagemaker import get_execution_role, Sessionfrom sagemaker.model_monitor import CronExpressionGenerator, DefaultModelMonitor # Upload pre and postprocessor scripts session = Session() bucket = boto3.Session().resource("s3").Bucket(session.default_bucket()) prefix = "demo-sagemaker-model-monitor" pre_processor_script = bucket.Object(os.path.join(prefix, "preprocessor.py")).upload_file("preprocessor.py") post_processor_script = bucket.Object(os.path.join(prefix, "postprocessor.py")).upload_file("postprocessor.py") # Get execution role role = get_execution_role() # can be an empty string # Instance type instance_type = "instance-type" # instance_type = "ml.m5.xlarge" # Example # Create a monitoring schedule with pre and post-processing my_default_monitor = DefaultModelMonitor( role=role, instance_count=1, instance_type=instance_type, volume_size_in_gb=20, max_runtime_in_seconds=3600, ) s3_report_path = "s3://{}/{}".format(bucket, "reports") monitor_schedule_name = "monitor-schedule-name" endpoint_name = "endpoint-name" my_default_monitor.create_monitoring_schedule( post_analytics_processor_script=post_processor_script, record_preprocessor_script=pre_processor_script, monitor_schedule_name=monitor_schedule_name, # use endpoint_input for real-time endpoint endpoint_input=endpoint_name, # or use batch_transform_input for batch transform jobs # batch_transform_input=batch_transform_name, output_s3_uri=s3_report_path, statistics=my_default_monitor.baseline_statistics(), constraints=my_default_monitor.suggested_constraints(), schedule_cron_expression=CronExpressionGenerator.hourly(), enable_cloudwatch_metrics=True, )
T: Apa sajakah skenario atau kasus penggunaan di mana saya dapat memanfaatkan skrip pra-pemrosesan?
Anda dapat menggunakan skrip pra-pemrosesan saat Anda perlu mengubah input ke monitor model Anda. Pertimbangkan contoh berikut:
-
Skrip pra-pemrosesan untuk transformasi data.
Misalkan output model Anda adalah array:
[1.0, 2.1]. Wadah Model Monitor hanya berfungsi dengan struktur JSON tabular atau pipih, seperti.{“prediction0”: 1.0, “prediction1” : 2.1}Anda dapat menggunakan skrip pra-pemrosesan seperti contoh berikut untuk mengubah array menjadi struktur JSON yang benar.def preprocess_handler(inference_record): input_data = inference_record.endpoint_input.data output_data = inference_record.endpoint_output.data.rstrip("\n") data = output_data + "," + input_data return { str(i).zfill(20) : d for i, d in enumerate(data.split(",")) } -
Kecualikan catatan tertentu dari perhitungan metrik Model Monitor.
Misalkan model Anda memiliki fitur opsional dan Anda gunakan
-1untuk menunjukkan bahwa fitur opsional memiliki nilai yang hilang. Jika Anda memiliki monitor kualitas data, Anda mungkin ingin menghapus-1dari array nilai input sehingga tidak termasuk dalam perhitungan metrik monitor. Anda dapat menggunakan skrip seperti berikut ini untuk menghapus nilai-nilai tersebut.def preprocess_handler(inference_record): input_data = inference_record.endpoint_input.data return {i : None if x == -1 else x for i, x in enumerate(input_data.split(","))} -
Menerapkan strategi pengambilan sampel khusus.
Anda juga dapat menerapkan strategi pengambilan sampel khusus dalam skrip pra-pemrosesan Anda. Untuk melakukan ini, konfigurasikan wadah pra-bangun pihak pertama Model Monitor untuk mengabaikan persentase catatan sesuai dengan laju pengambilan sampel yang Anda tentukan. Dalam contoh berikut, handler mengambil sampel 10% dari catatan dengan mengembalikan catatan dalam 10% panggilan handler dan daftar kosong sebaliknya.
import random def preprocess_handler(inference_record): # we set up a sampling rate of 0.1 if random.random() > 0.1: # return an empty list return [] input_data = inference_record.endpoint_input.data return {i : None if x == -1 else x for i, x in enumerate(input_data.split(","))} -
Gunakan pencatatan khusus.
Anda dapat mencatat informasi apa pun yang Anda butuhkan dari skrip Anda ke Amazon CloudWatch. Ini dapat berguna saat men-debug skrip pra-pemrosesan Anda jika terjadi kesalahan. Contoh berikut menunjukkan cara menggunakan
preprocess_handlerantarmuka untuk log ke CloudWatch.def preprocess_handler(inference_record, logger): logger.info(f"I'm a processing record: {inference_record}") logger.debug(f"I'm debugging a processing record: {inference_record}") logger.warning(f"I'm processing record with missing value: {inference_record}") logger.error(f"I'm a processing record with bad value: {inference_record}") return inference_record
catatan
Ketika skrip pra-pemrosesan dijalankan pada data transformasi batch, tipe input tidak selalu CapturedData objek. Untuk data CSV, tipenya adalah string. Untuk data JSON, tipenya adalah kamus Python.
T: Kapan saya bisa memanfaatkan skrip pasca-pemrosesan?
Anda dapat memanfaatkan skrip pasca-pemrosesan sebagai ekstensi setelah menjalankan pemantauan yang berhasil. Berikut ini adalah contoh sederhana, tetapi Anda dapat melakukan atau memanggil fungsi bisnis apa pun yang perlu Anda lakukan setelah pemantauan berhasil dijalankan.
def postprocess_handler(): print("Hello from the post-processing script!")
T: Kapan saya harus mempertimbangkan untuk membawa wadah saya sendiri untuk pemantauan model?
SageMaker AI menyediakan wadah pra-bangun untuk menganalisis data yang diambil dari titik akhir atau pekerjaan transformasi batch untuk kumpulan data tabel. Namun, ada skenario di mana Anda mungkin perlu membuat kontainer Anda sendiri. Pertimbangkan skenario berikut:
-
Anda memiliki persyaratan peraturan dan kepatuhan untuk hanya menggunakan wadah yang dibuat dan dipelihara secara internal di organisasi Anda.
-
Jika Anda ingin menyertakan beberapa pustaka pihak ketiga, Anda dapat menempatkan
requirements.txtfile di direktori lokal dan mereferensikannya menggunakansource_dirparameter di estimator SageMaker AI, yang memungkinkan penginstalan pustaka saat run-time. Namun, jika Anda memiliki banyak pustaka atau dependensi yang meningkatkan waktu instalasi saat menjalankan pekerjaan pelatihan, Anda mungkin ingin memanfaatkan BYOC. -
Lingkungan Anda tidak memaksa konektivitas internet (atau Silo), yang mencegah pengunduhan paket.
-
Anda ingin memantau data yang ada dalam format data selain tabel, seperti kasus penggunaan NLP atau CV.
-
Bila Anda memerlukan metrik pemantauan tambahan daripada yang didukung oleh Model Monitor.
T: Saya memiliki model NLP dan CV. Bagaimana cara memonitornya untuk penyimpangan data?
Wadah prebuilt Amazon SageMaker AI mendukung kumpulan data tabular. Jika Anda ingin memantau model NLP dan CV, Anda dapat membawa wadah Anda sendiri dengan memanfaatkan titik ekstensi yang disediakan oleh Model Monitor. Untuk detail selengkapnya tentang persyaratan, lihat Membawa wadah Anda sendiri. Berikut adalah beberapa contoh :
-
Untuk penjelasan rinci tentang cara menggunakan Model Monitor untuk kasus penggunaan visi komputer, lihat Mendeteksi dan Menganalisis prediksi yang salah
. -
Untuk skenario di mana Model Monitor dapat dimanfaatkan untuk kasus penggunaan NLP, lihat Mendeteksi penyimpangan data NLP menggunakan
Monitor Model Amazon kustom. SageMaker
T: Saya ingin menghapus titik akhir model yang Model Monitor diaktifkan, tetapi saya tidak dapat melakukannya karena jadwal pemantauan masih aktif. Apa yang harus saya lakukan?
Jika Anda ingin menghapus titik akhir inferensi yang dihosting di SageMaker AI yang mengaktifkan Model Monitor, pertama-tama Anda harus menghapus jadwal pemantauan model (dengan DeleteMonitoringScheduleCLI atau API). Kemudian, hapus titik akhir.
T: Apakah SageMaker Model Monitor menghitung metrik dan statistik untuk input?
Model Monitor menghitung metrik dan statistik untuk output, bukan input.
T: Apakah SageMaker Model Monitor mendukung titik akhir multi-model?
Tidak, Model Monitor hanya mendukung titik akhir yang menampung satu model dan tidak mendukung pemantauan titik akhir multi-model.
T: Apakah SageMaker Model Monitor menyediakan data pemantauan tentang kontainer individu dalam pipa inferensi?
Model Monitor mendukung pemantauan saluran inferensi, tetapi menangkap dan menganalisis data dilakukan untuk seluruh pipa, bukan untuk kontainer individu dalam pipa.
T: Apa yang dapat saya lakukan untuk mencegah dampak permintaan inferensi saat pengambilan data disiapkan?
Untuk mencegah dampak pada permintaan inferensi, Data Capture berhenti menangkap permintaan pada tingkat penggunaan disk yang tinggi. Disarankan agar penggunaan disk Anda tetap di bawah 75% untuk memastikan pengambilan data terus menangkap permintaan.
T: Dapatkah Pengambilan Data Amazon S3 berada di AWS wilayah yang berbeda dari wilayah tempat jadwal pemantauan diatur?
Tidak, Amazon S3 Data Capture harus berada di wilayah yang sama dengan jadwal pemantauan.
T: Apa itu baseline, dan bagaimana cara membuatnya? Bisakah saya membuat baseline khusus?
Sebuah baseline digunakan sebagai referensi untuk membandingkan prediksi real-time atau batch dari model. Ini menghitung statistik dan metrik bersama dengan kendala pada mereka. Selama pemantauan, semua ini digunakan bersama untuk mengidentifikasi pelanggaran.
Untuk menggunakan solusi default Amazon SageMaker Model Monitor, Anda dapat memanfaatkan Amazon SageMaker Python
Hasil pekerjaan dasar adalah dua file: statistics.json dan. constraints.json Skema untuk statistik dan skema untuk kendala berisi skema file masing-masing. Anda dapat meninjau kendala yang dihasilkan dan memodifikasinya sebelum menggunakannya untuk pemantauan. Berdasarkan pemahaman Anda tentang masalah domain dan bisnis, Anda dapat membuat kendala lebih agresif, atau melonggarkannya untuk mengontrol jumlah dan sifat pelanggaran.
T: Apa pedoman untuk membuat dataset dasar?
Persyaratan utama untuk segala jenis pemantauan adalah memiliki dataset dasar yang digunakan untuk menghitung metrik dan kendala. Biasanya, ini adalah kumpulan data pelatihan yang digunakan oleh model, tetapi dalam beberapa kasus Anda mungkin memilih untuk menggunakan beberapa kumpulan data referensi lainnya.
Nama kolom dari dataset dasar harus kompatibel dengan Spark. Untuk menjaga kompatibilitas maksimum antara Spark, CSV, JSON dan parket disarankan untuk hanya menggunakan huruf kecil, dan hanya digunakan sebagai pemisah. _ Karakter khusus termasuk “ ” dapat menyebabkan masalah.
T: Apa StartTimeOffset dan EndTimeOffset parameternya, dan kapan digunakan?
Ketika Amazon SageMaker Ground Truth diperlukan untuk memantau pekerjaan seperti kualitas model, Anda perlu memastikan bahwa pekerjaan pemantauan hanya menggunakan data yang Ground Truth tersedia. Parameter start_time_offset dan end_time_offset parameter EndpointInputstart_time_offset danend_time_offset. Parameter ini perlu ditentukan dalam format durasi ISO 8601
-
Jika hasil Ground Truth Anda tiba 3 hari setelah prediksi dibuat, atur
start_time_offset="-P3D"danend_time_offset="-P1D", yaitu 3 hari dan 1 hari masing-masing. -
Jika hasil Ground Truth tiba 6 jam setelah prediksi dan Anda memiliki jadwal per jam, atur
start_time_offset="-PT6H"danend_time_offset="-PT1H", yaitu 6 jam 1 jam.
T: Dapatkah saya menjalankan pekerjaan pemantauan 'sesuai permintaan'?
Ya, Anda dapat menjalankan pekerjaan pemantauan 'sesuai permintaan' dengan menjalankan pekerjaan Pemrosesan. SageMaker Untuk Transformasi Batch, Pipelines memiliki MonitorBatchTransformStep
T: Bagaimana cara menyiapkan Model Monitor?
Anda dapat mengatur Model Monitor dengan cara berikut:
-
Amazon SageMaker AI Python SDK
— Ada modul Model Monitor yang berisi kelas dan fungsi yang membantu dalam menyarankan garis dasar, membuat jadwal pemantauan, dan banyak lagi. Lihat contoh notebook Amazon SageMaker Model Monitor untuk notebook terperinci yang memanfaatkan SageMaker AI Python SDK untuk menyiapkan Model Monitor. -
Pipa — Pipa terintegrasi dengan Model Monitor melalui QualityCheck Langkah dan. ClarifyCheckStep APIs Anda dapat membuat pipeline SageMaker AI yang berisi langkah-langkah ini dan yang dapat digunakan untuk menjalankan pekerjaan pemantauan sesuai permintaan setiap kali pipeline dijalankan.
-
Amazon SageMaker Studio Classic - Anda dapat membuat jadwal pemantauan kualitas data atau model bersama dengan bias model dan jadwal penjelasan langsung dari UI dengan memilih titik akhir dari daftar titik akhir model yang diterapkan. Jadwal untuk jenis pemantauan lainnya dapat dibuat dengan memilih tab yang relevan di UI.
-
SageMaker Dasbor Model — Anda dapat mengaktifkan pemantauan pada titik akhir dengan memilih model yang telah diterapkan ke titik akhir. Pada tangkapan layar konsol SageMaker AI berikut, model bernama
group1telah dipilih dari bagian Model di dasbor Model. Di halaman ini, Anda dapat membuat jadwal pemantauan, dan Anda dapat mengedit, mengaktifkan, atau menonaktifkan jadwal pemantauan dan peringatan yang ada. Untuk panduan langkah demi langkah tentang cara melihat peringatan dan jadwal monitor model, lihat Lihat jadwal dan peringatan Monitor Model.
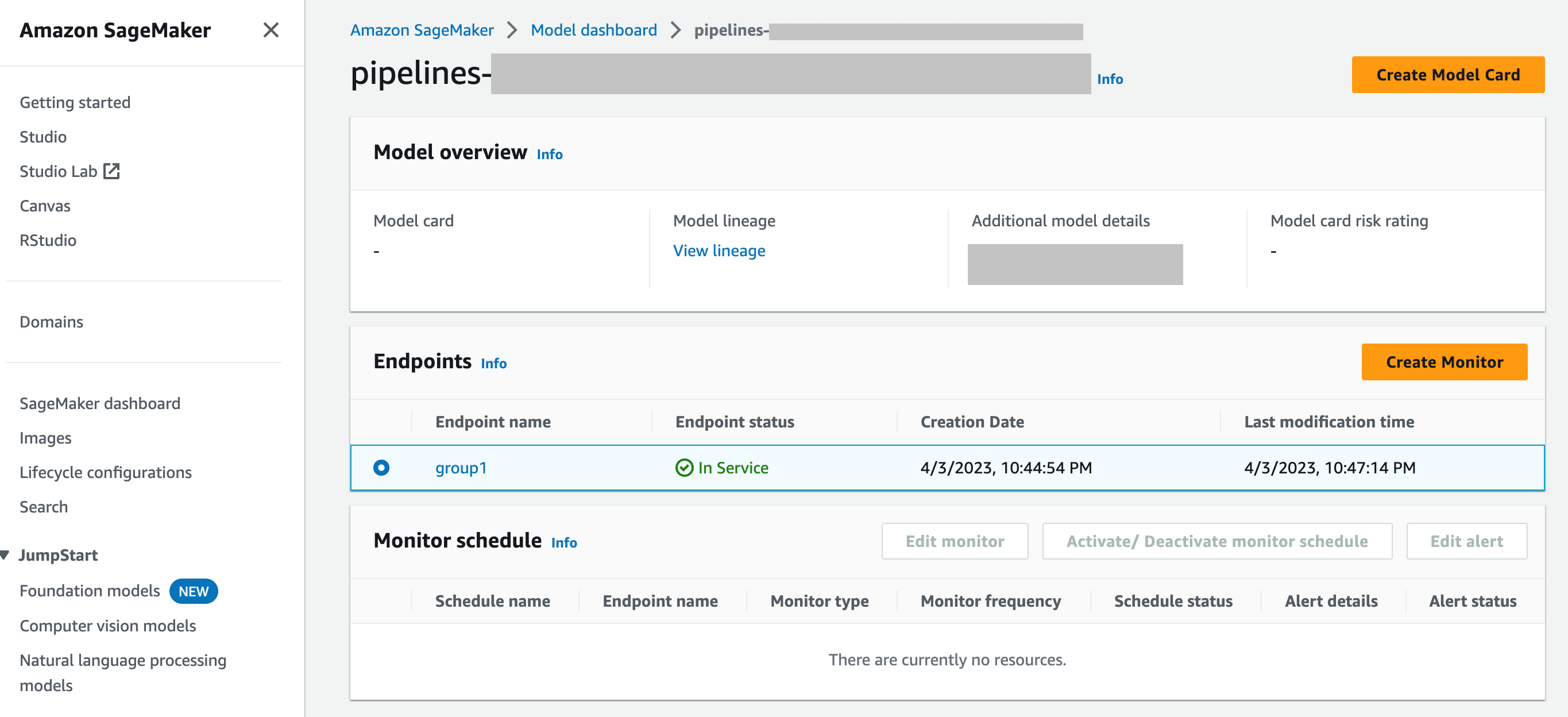
T: Bagaimana Model Monitor Berintegrasi dengan Dasbor SageMaker Model
SageMaker Dasbor Model memberi Anda pemantauan terpadu di semua model Anda dengan memberikan peringatan otomatis tentang penyimpangan dari perilaku yang diharapkan dan pemecahan masalah untuk memeriksa model dan menganalisis faktor-faktor yang memengaruhi kinerja model dari waktu ke waktu.
