Le traduzioni sono generate tramite traduzione automatica. In caso di conflitto tra il contenuto di una traduzione e la versione originale in Inglese, quest'ultima prevarrà.
AWS Architettura consigliata per la previsione della domanda di nuovi prodotti
Quando si ridimensiona la pipeline di AI/ML su più prodotti e aree geografiche, si consiglia di seguire le migliori pratiche relative alle operazioni di apprendimento automatico (MLOps) per la riproducibilità, l'affidabilità e la scalabilità. Per ulteriori informazioni, consulta Implementazione MLOps nella documentazione di Amazon SageMaker AI. L'immagine seguente mostra un esempio di AWS architettura per l'implementazione di un modello ML che prevede la domanda per il lancio di nuovi prodotti.
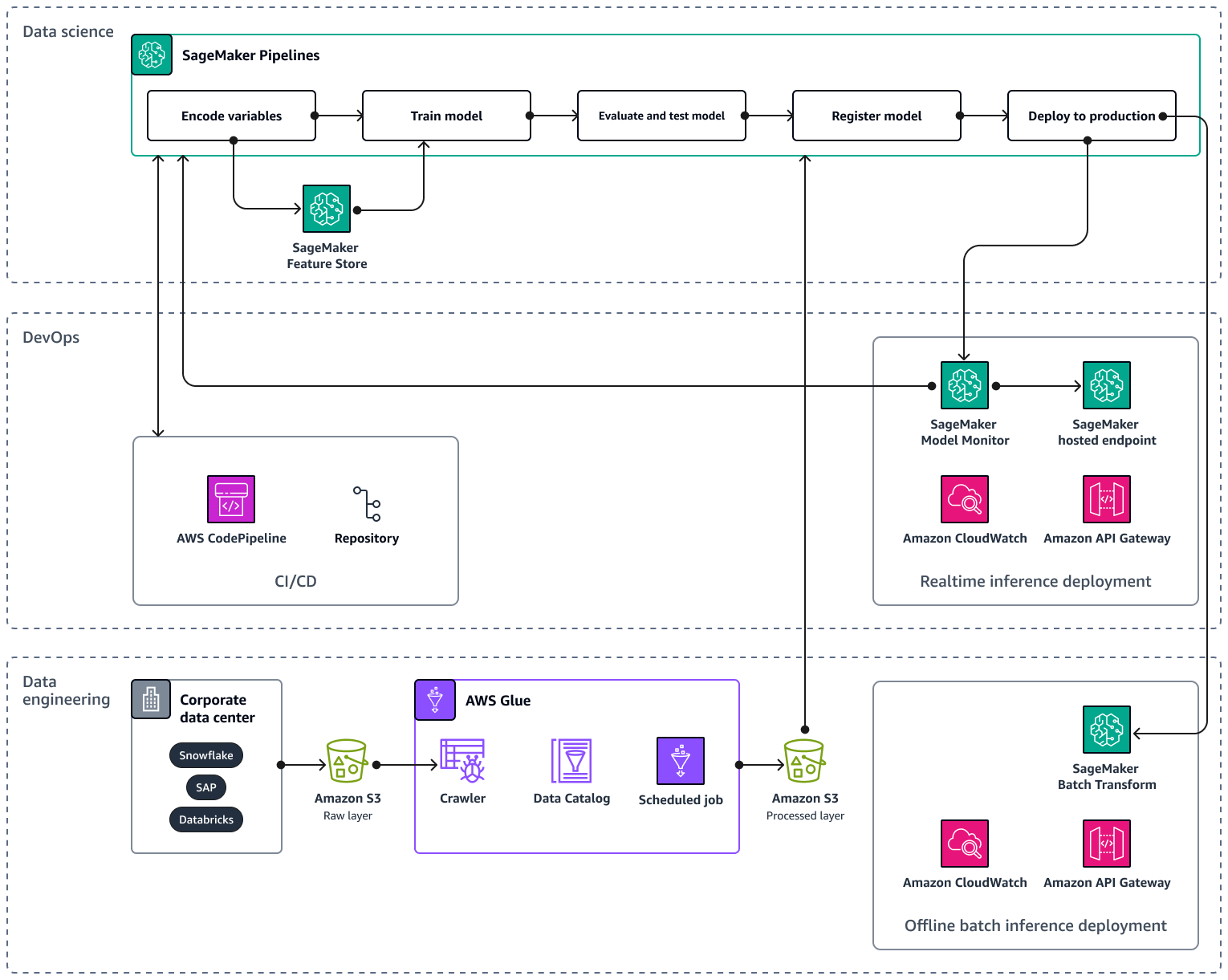
L' AWS architettura di esempio è composta da tre livelli: ingegneria dei dati e scienza dei dati. DevOps
Il livello di ingegneria dei dati si concentra sull'acquisizione di dati da fonti di dati aziendali utilizzando AWS Gluee quindi archiviando i dati in modo conveniente in Amazon Simple Storage Service (Amazon S3). AWS Glueè un ETL servizio serverless completamente gestito che ti aiuta a classificare, pulire, trasformare e trasferire in modo affidabile i dati tra diversi archivi di dati. Amazon S3 è un servizio di storage di oggetti che offre scalabilità, disponibilità dei dati, sicurezza e prestazioni. Il livello di ingegneria dei dati mostra anche la distribuzione offline dell'inferenza in batch utilizzando la trasformazione in batch in Amazon SageMaker AI. La trasformazione in batch ottiene i dati di input da Amazon S3 e li invia in una o HTTP più richieste tramite APIAmazon Gateway al modello di pipeline di inferenza. Amazon API Gateway è un servizio completamente gestito che ti aiuta a creare, pubblicare, mantenere, monitorare e proteggere APIs su qualsiasi scala. Infine, il livello di ingegneria dei dati mostra l'uso di Amazon CloudWatch, un servizio che offre visibilità sulle prestazioni a livello di sistema e ti aiuta a impostare allarmi, reagire automaticamente ai cambiamenti e ottenere una visione unificata dello stato operativo. CloudWatch archivia i file di log in un bucket Amazon S3 specificato dall'utente.
Il DevOps livello utilizza API Gateway e Amazon SageMaker AI Model Monitor per la distribuzione dell'inferenza in tempo reale. CloudWatch Model Monitor ti aiuta a configurare un sistema automatico di attivazione degli avvisi per le deviazioni nella qualità del modello, come la deriva dei dati e le anomalie. Amazon CloudWatch Logs raccoglie i file di log da Model Monitor e ti avvisa quando la qualità del tuo modello raggiunge determinate soglie, da te preimpostate. Il DevOps livello mostra anche l'utilizzo di per automatizzare le pipeline di distribuzione del codice. AWS CodePipeline
Il livello di scienza dei dati mostra l'uso di Amazon SageMaker AI Pipelines e Amazon SageMaker AI Feature Store per gestire il ciclo di vita dell'apprendimento automatico. SageMaker AI Pipelines è un servizio di orchestrazione del flusso di lavoro creato appositamente che ti aiuta ad automatizzare tutte le fasi del machine learning, dalla preelaborazione dei dati al monitoraggio dei modelli. Con un'interfaccia utente intuitiva e PythonSDK, puoi gestire pipeline end-to-end ML ripetibili su larga scala. L'integrazione nativa con multiple ti Servizi AWS aiuta a personalizzare il ciclo di vita ML in base alle tue esigenze. MLOps Feature Store è un repository completamente gestito e creato appositamente per archiviare, condividere e gestire le funzionalità per i modelli ML. Le funzionalità sono input per i modelli ML e vengono utilizzate durante l'addestramento e l'inferenza.
