DynamoDB でのデバイスステータス更新のモニタリング
このユースケースでは、DynamoDB を使用して、DynamoDB 内でデバイスのステータスの更新 (またはデバイスのステータスの変更) をモニタリングする方法について説明しています。
ユースケース
IoT のユースケース (スマートファクトリーなど) では、多くのデバイスをオペレーターがモニタリングする必要があり、オペレーターはステータスやログをモニタリングシステムに定期的に送信します。デバイスに問題が発生すると、デバイスのステータスが [正常] から [警告] に変わります。デバイスの異常な動作の重大度やタイプによって、さまざまなログレベルまたはステータスがあります。その後、システムはデバイスをチェックするオペレーターを割り当て、オペレーターは必要に応じて問題を上司にエスカレーションします。
このシステムの典型的なアクセスパターンには次のものがあります。
-
デバイスのログエントリを作成する
-
特定のデバイスステータスのすべてのログを取得し、最新のログを最初に表示する
-
2 つの日付間の特定のオペレーターのすべてのログを取得する
-
特定のスーパーバイザーのエスカレーションされたログをすべて取得する
-
特定のスーパーバイザーの特定のデバイスステータスに関するすべてのエスカレーションログを取得
-
特定の日付における特定のスーパーバイザーの特定のデバイスステータスを含むすべてのエスカレーションされたログを取得する
エンティティ関係図
これは、デバイスステータスの更新をモニタリングするために使用するエンティティ関係図 (ERD) です。

アクセスパターン
デバイスのステータス更新をモニタリングする方法について説明します。
-
createLogEntryForSpecificDevice -
getLogsForSpecificDevice -
getWarningLogsForSpecificDevice -
getLogsForOperatorBetweenTwoDates -
getEscalatedLogsForSupervisor -
getEscalatedLogsWithSpecificStatusForSupervisor -
getEscalatedLogsWithSpecificStatusForSupervisorForDate
スキーマ設計の進化
ステップ 1: アクセスパターン 1 (createLogEntryForSpecificDevice) と 2 (getLogsForSpecificDevice) に対処する
デバイス追跡システムのスケーリングの単位は、個々のデバイスです。このシステムでは、deviceID はデバイスを一意に識別します。これにより、deviceID がパーティションキーの適切な候補となります。各デバイスは定期的に (例えば 5 分おきに) 情報を追跡システムに送信します。この順序によって、日付が論理的なソート基準となり、したがってソートキーになります。この場合のサンプルデータは次のようになります。

特定のデバイスのログエントリを取得するには、パーティションキー DeviceID="d#12345" を使用してクエリオペレーションを実行します。
ステップ 2: アクセスパターン 3 (getWarningLogsForSpecificDevice) に対処する
State は非キー属性であるため、現在のスキーマでアクセスパターン 3 に対処するにはフィルター式が必要になります。DynamoDB では、フィルター式はキー条件式を使用してデータを読み取った後に適用されます。例えば、d#12345 の警告ログを取得する場合、パーティションキー DeviceID="d#12345" を使用したクエリオペレーションは、上記のテーブルから 4 つの項目を読み取り、警告ステータスなしで 1 つの項目をフィルターで除外します。このアプローチは大規模な場合は効率的ではありません。フィルター式は、除外される項目の割合が低い場合や、クエリの実行頻度が低い場合に、クエリ対象の項目を除外するのに適した方法です。ただし、テーブルから多くの項目が取得され、その大半の項目がフィルターで除外される場合は、より効率的に実行されるようにテーブル設計を進化させ続けることができます。
複合ソートキーを使用して、このアクセスパターンを処理する方法を変更してみましょう。ソートキーを State#Date に変更したサンプルデータを DeviceStateLog_3.jsonState、#、および Date から構成されます。この例では、# は区切り文字として使用されています。これで、データは次のようになります。
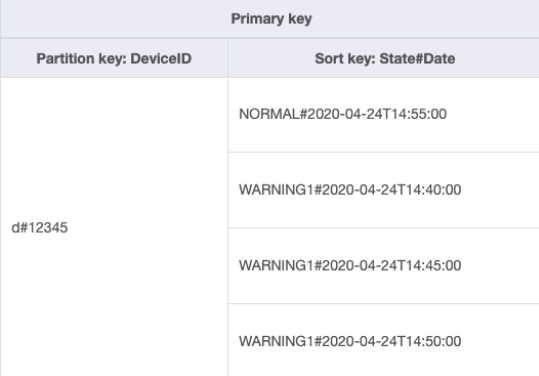
デバイスの警告ログのみを取得する場合は、このスキーマの方がクエリの対象が絞り込まれます。クエリのキー条件にはパーティションキー DeviceID="d#12345" とソートキー State#Date begins_with
“WARNING” が使用されます。このクエリは、警告ステータスの関連する 3 つの項目のみを読み取ります。
ステップ 3: アクセスパターン 4 (getLogsForOperatorBetweenTwoDates) に対処する
Operator 属性がサンプルデータとともに DeviceStateLog テーブルに追加された DeviceStateLog_4.json

Operator は現在パーティションキーではないため、OperatorID に基づいてこのテーブルのキーと値を直接検索する方法はありません。OperatorID にグローバルセカンダリインデックスを使用して新しい項目コレクションを作成する必要があります。アクセスパターンでは日付に基づく検索が必要なため、日付がグローバルセカンダリインデックス (GSI) のソートキー属性になります。GSI は現在次のようになっています。
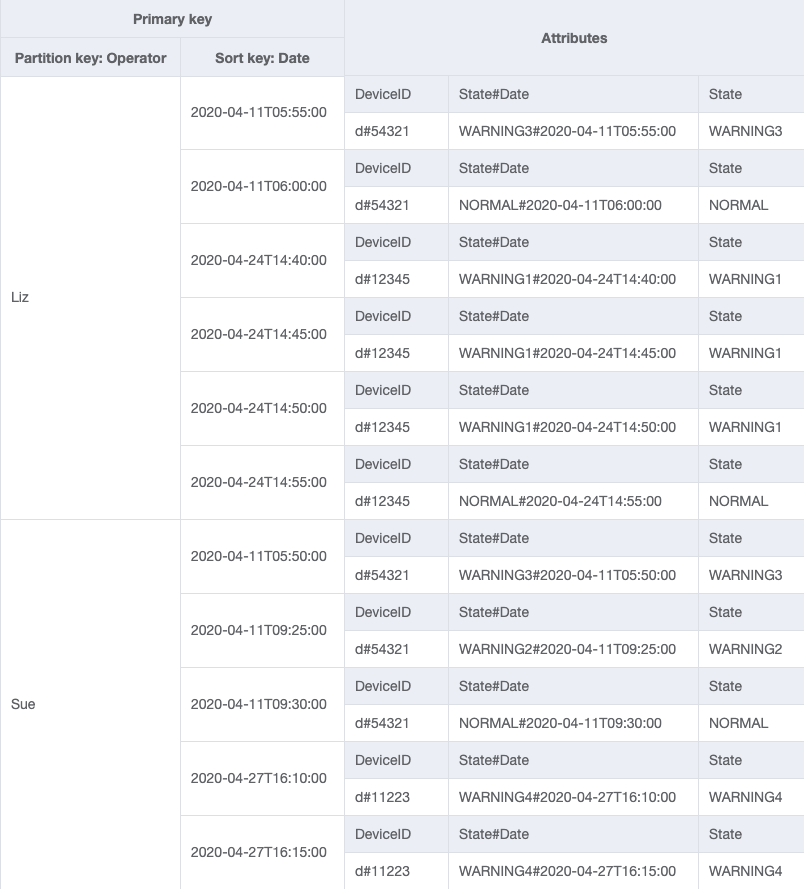
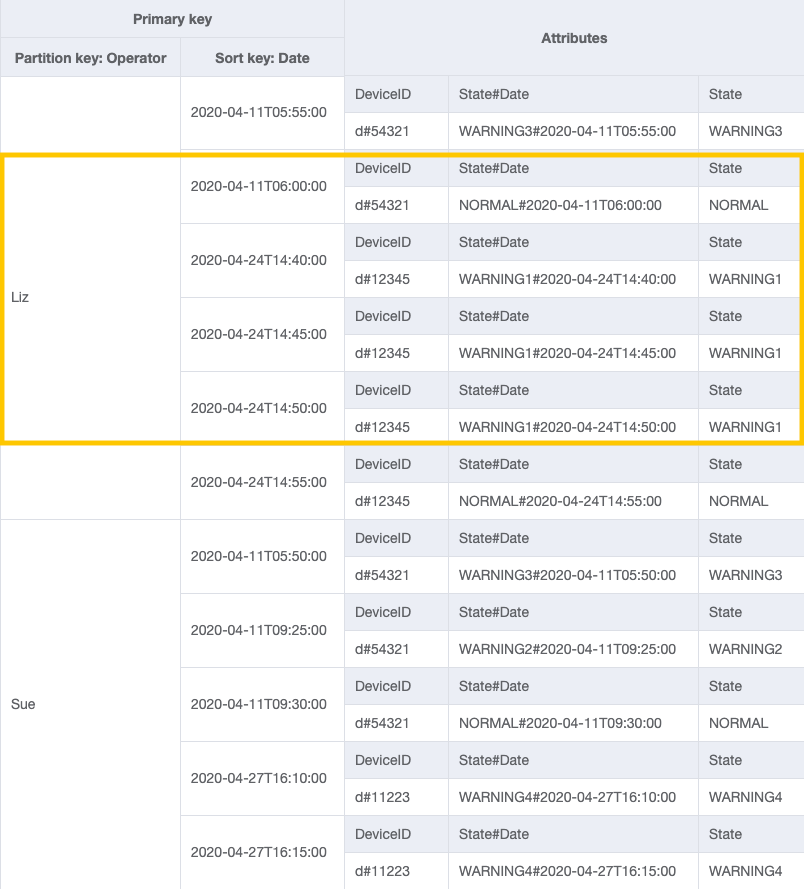
アクセスパターン 4 (getLogsForOperatorBetweenTwoDates) の場合、2020-04-11T05:58:00 と 2020-04-24T14:50:00 の間のパーティションキー OperatorID=Liz とソートキー Date を使用してこの GSI をクエリできます。
ステップ 4: アクセスパターン 5 (getEscalatedLogsForSupervisor)、6 (getEscalatedLogsWithSpecificStatusForSupervisor)、および 7 (getEscalatedLogsWithSpecificStatusForSupervisorForDate) に対処する
スパースインデックスを使用して、これらのアクセスパターンに対処します。
グローバルセカンダリインデックスはデフォルトではスパースであるため、インデックスのプライマリキー属性を含むベーステーブルの項目だけが実際にインデックスに表示されます。これは、モデル化するアクセスパターンに関係のない項目を除外するもう 1 つの方法です。
EscalatedTo 属性がサンプルデータとともに DeviceStateLog テーブルに追加された DeviceStateLog_6.json

これで、EscalatedTo がパーティションキー、State#Date がソートキーである新しい GSI を作成できるようになりました。EscalatedTo 属性と State#Date 属性の両方を持つ項目のみがインデックスに表示されることに注意してください。

その他のアクセスパターンは、以下のようにまとめられています。
すべてのアクセスパターンと各アクセスパターンにスキーマ設計で対処する方法を次の表にまとめています。
| アクセスパターン | ベーステーブル/GSI/LSI | Operation | パーティションキー値 | ソートキー値 | その他の条件/フィルター |
|---|---|---|---|---|---|
| createLogEntryForSpecificDevice | ベーステーブル | PutItem | DeviceID=deviceId | State#Date=state#date | |
| getLogsForSpecificDevice | ベーステーブル | クエリ | DeviceID=deviceId | State#Date begins_with "state1#" | ScanIndexForward = False |
| getWarningLogsForSpecificDevice | ベーステーブル | クエリ | DeviceID=deviceId | State#Date begins_with "WARNING" | |
| getLogsForOperatorBetweenTwoDates | GSI-1 | クエリ | Operator=operatorName | Date between date1 and date2 | |
| getEscalatedLogsForSupervisor | GSI-2 | クエリ | EscalatedTo=supervisorName | ||
| getEscalatedLogsWithSpecificStatusForSupervisor | GSI-2 | クエリ | EscalatedTo=supervisorName | State#Date begins_with "state1#" | |
| getEscalatedLogsWithSpecificStatusForSupervisorForDate | GSI-2 | クエリ | EscalatedTo=supervisorName | State#Date begins_with "state1#date1" |
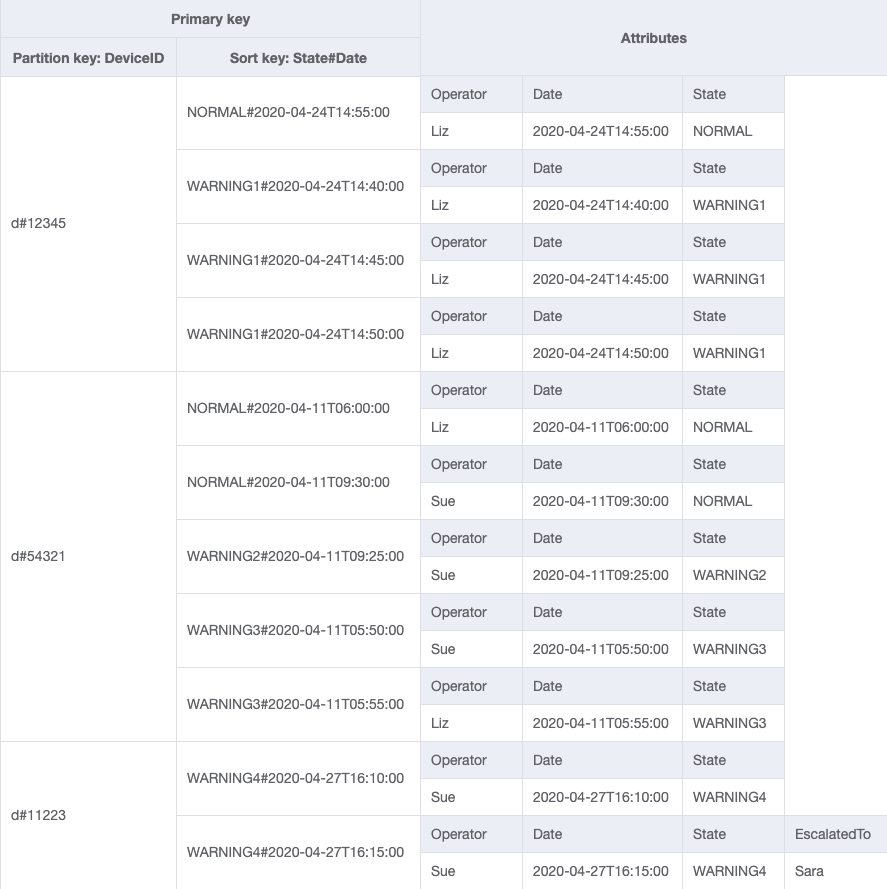
最終スキーマ
最終的なスキーマ設計は次のとおりです。このスキーマ設計を JSON ファイルとしてダウンロードするには、GitHub の DynamoDB の例
ベーステーブル
GSI-1

GSI-2

このスキーマ設計での NoSQL Workbench の使用
この最終スキーマを、DynamoDB のデータモデリング、データ視覚化、クエリ開発機能を提供するビジュアルツールである NoSQL Workbench にインポートして、新しいプロジェクトを詳しく調べたり編集したりできます。使用を開始するには、次の手順に従います。
-
NoSQL Workbench をダウンロードします。詳細については、「DynamoDB 用の NoSQL Workbench のダウンロード」を参照してください。
-
上記の JSON スキーマファイルをダウンロードします。このファイルは既に NoSQL Workbench モデル形式になっています。
-
JSON スキーマファイルを NoSQL Workbench にインポートします。詳細については、「既存のデータモデルのインポート」を参照してください。
-
NOSQL Workbench にインポートしたら、データモデルを編集できます。詳細については、「既存のデータモデルの編集」を参照してください。
-
データモデルの視覚化、サンプルデータの追加、CSV ファイルからのサンプルデータのインポートを行うには、NoSQL Workbench のデータビジュアライザー機能を使用します。
