翻訳は機械翻訳により提供されています。提供された翻訳内容と英語版の間で齟齬、不一致または矛盾がある場合、英語版が優先します。
Amazon EMR クラスターを作成して使用する方法を理解する
このトピックでは、クラスターに作業を送信する方法、データが処理される方法、処理中のクラスターの状態の変化など、Amazon EMR クラスターの概要を示します。
クラスターとノードに慣れる
Amazon EMR の中心的なコンポーネントは、クラスターです。クラスターは、Amazon Elastic Compute Cloud (Amazon EC2) インスタンスの集合です。クラスター内の各インスタンスは、ノードと呼ばれます。各ノードには、クラスター内にロールがあり、ノードタイプと呼ばれます。また、Amazon EMR は、各ノードタイプにさまざまなソフトウェアコンポーネントをインストールし、Apache Hadoop などの分散型アプリケーションでのロールを各ノードに付与します。
Amazon EMR のノードタイプは、次のとおりです。
-
プライマリノード: 処理を行うために他のノード間でのデータおよびタスクの分散を調整するソフトウェアコンポーネントを実行することで、クラスターを管理するノードです。プライマリノードは、タスクのステータスを追跡し、クラスターの状態を監視します。すべてのクラスターにはプライマリノードがあり、プライマリノードのみで 1 つのノードクラスターを作成できます。
-
コアノード: タスクを実行し、クラスター上の Hadoop Distributed File System (HDFS) にデータを保存するソフトウェアコンポーネントを持つノードです。マルチノードクラスターには、少なくとも 1 つのコアノードがあります。
-
タスクノード: タスクを実行するのみで、HDFS にデータを保存しないソフトウェアコンポーネントを持つノードです。タスクノードはオプションです。
クラスターへのワークの送信
Amazon EMR でクラスターを実行する場合、行う必要があるワークを指定する方法についてはいくつかのオプションがあります。
-
クラスターの作成時にステップとして指定する関数で実行するワークの、完全な定義を提供します。これは、通常、一定量のデータを処理し処理が完了したときに終了するクラスターに対して実行されます。
-
長時間稼働クラスターを作成し、Amazon EMR コンソール、Amazon EMR API、または AWS CLI を使用してステップを送信します。ステップには、1 つ以上のジョブが含まれている場合があります。詳細については、「作業を Amazon EMR クラスターに送信する」を参照してください。
-
クラスターを作成し、SSH を使用してプライマリノードや必要に応じて他のノードに接続して、インストール済みアプリケーションが提供するインターフェイスを使用します。これにより、スクリプト化を使用するか、インタラクティブにタスクを実行し、クエリを送信します。詳細については、「Amazon EMR リリースガイド」を参照してください。
データの処理
クラスターを起動するとき、データ処理の必要に合わせてインストールするフレームワークとアプリケーションを選択します。Amazon EMR クラスターでデータを処理するには、インストールされたアプリケーションにジョブまたはクエリを直接送信するか、クラスターでステップを実行することもできます。
アプリケーションへのジョブの直接送信
Amazon EMR クラスターにインストールされたソフトウェアを使用し、直接ジョブを送信して操作できます。これを行うには、通常安全な接続経由でプライマリノードに接続し、クラスターで直接実行されるソフトウェアに使用できるインターフェイスとツールにアクセスします。詳細については、「Amazon EMR クラスターに接続する」を参照してください。
ステップの実行によるデータの処理
Amazon EMR クラスターには、1 つ以上のステップを順番に並べて送信できます。各ステップは、クラスターにインストールされたソフトウェアにより処理するためのデータを操作する指示が含まれる作業単位です。
4 つのステップを使用した処理の例を次に示します。
-
処理のために入力データセットを送信する
-
Pig プログラムを使用して、最初のステップの出力を処理する。
-
Hive プログラムを使用して 2 番目の入力データセットを処理する
-
出力データセットを書き込む
通常、Amazon EMR でデータを処理する場合、入力とは、選択した基になるファイルシステム (Amazon S3 や HDFS など) にファイルとして保存されるデータのことです。このデータは、処理シーケンスの次のステップに移動します。最後のステップで、指定された場所 (Amazon S3 バケットなど) に出力データが書き込まれます。
ステップは、次の順序で実行されます。
-
リクエストが送信され、ステップの処理が開始されます。
-
すべてのステップの状態が [PENDING (保留中)] になります。
-
シーケンスの最初のステップが開始されると、その状態が [RUNNING (実行中)] に変わります。他のステップは、[PENDING (保留中)] 状態のままです。
-
最初のステップが完了すると、その状態が [COMPLETED (完了済み)] に変わります。
-
シーケンスの次のステップが開始され、その状態が [RUNNING (実行中)] に変わります。完了すると、その状態が [COMPLETED (完了済み)] に変わります。
-
すべてのステップが完了し、処理が終了するまで、ステップごとにこのパターンが繰り返されます。
次の図に、ステップが処理される際のステップシーケンスと状態の変化を示します。

ステップが処理に失敗した場合、その状態は [FAILED] (失敗) に変わります。ステップごとに、次に実行する処理を指定できます。デフォルトでは、シーケンスの残りのステップはすべて [CANCELLED] (キャンセル済み) に設定され、前のステップが失敗した場合は実行されません。エラーを無視し、残りのステップを続行するか、ただちにクラスターを終了する選択ができます。
次の図に、処理中にステップが失敗した場合のステップシーケンスと状態のデフォルトの変化を示します。

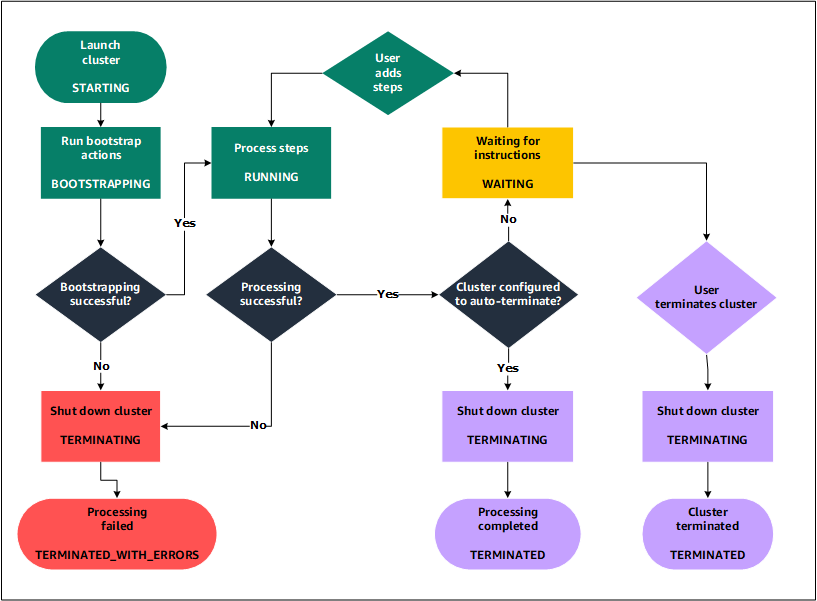
クラスターライフサイクルについて
成功した Amazon EMR クラスターは次のプロセスに従います。
-
最初に、Amazon EMR は指定に従って、各インスタンスのクラスターで EC2 インスタンスをプロビジョニングします。詳細については、「Amazon EMR クラスターハードウェアとネットワークを設定する」を参照してください。Amazon EMR は、すべてのインスタンスに対して、Amazon EMR 用のデフォルト AMI または指定するカスタム Amazon Linux AMI を使用します。詳細については、「カスタム AMI を使用して Amazon EMR クラスター設定の柔軟性を高める」を参照してください。このフェーズの間、クラスターの状態は
STARTINGです。 -
各インスタンスで指定したブートストラップアクションが Amazon EMR によって実行されます。ブートストラップアクションを使用してカスタムアプリケーションをインストールし、必要なカスタマイズを実行できます。詳細については、「Amazon EMR クラスターで追加のソフトウェアをインストールするブートストラップアクションを作成する」を参照してください。このフェーズの間、クラスターの状態は
BOOTSTRAPPINGです。 -
Amazon EMR は、Hive、Hadoop、Spark など、クラスターの作成時に指定するネイティブアプリケーションをインストールします。
-
ブートストラップアクションが正常に完了し、ネイティブアプリケーションがインストールされると、クラスターの状態は
RUNNINGになります。この時点で、クラスターインスタンスに接続できます。クラスターは、クラスターの作成時に指定されたステップを順番に実行します。前のステップの完了後に実行される追加のステップを送信できます。詳細については、「作業を Amazon EMR クラスターに送信する」を参照してください。 -
ステップが正常に実行されると、クラスターは
WAITING状態になります。最後のステップの完了後に自動終了するようクラスターが設定されている場合は、TERMINATING状態になり、次にTERMINATED状態になります。クラスターが待機するように設定されている場合は、不要になったときに手動でシャットダウンする必要があります。クラスターを手動でシャットダウンすると、クラスターはTERMINATING状態になり、次にTERMINATED状態になります。
クラスターのライフサイクル中にエラーが発生すると、削除保護を有効にしていない限り、Amazon EMR はクラスターとそのすべてのインスタンスを終了させます。エラーのためにクラスターが終了した場合、そのクラスターに保存されているデータは削除され、クラスターの状態は TERMINATED_WITH_ERRORS に設定されます。削除保護を有効にした場合、クラスターからデータを取得し、削除保護を解除してクラスターを終了できます。詳細については、「Amazon EMR クラスターを誤ったシャットダウンから保護するための終了保護の使用」を参照してください。
次の図は、クラスターのライフサイクルと、ライフサイクルの各ステージが特定のクラスターの状態にどのようにマッピングされるかを表しています。