기계 번역으로 제공되는 번역입니다. 제공된 번역과 원본 영어의 내용이 상충하는 경우에는 영어 버전이 우선합니다.
Model Monitor FAQ
Amazon SageMaker Model Monitoror에 대한 자세한 내용은 다음 FAQ를 참조하세요.
Q: Model Monitor와 SageMaker Clarify는 고객이 모델 동작을 모니터링하는 데 어떤 도움을 주나요?
고객은 Amazon SageMaker Model Monitor와 SageMaker Clarify를 통해 데이터 품질, 모델 품질, 바이어스 드리프트, 특징 속성 드리프트의 4가지 차원에 걸쳐 모델 동작을 모니터링할 수 있습니다. Model Monitor
Q: Sagemaker Model Monitor가 활성화되면 백그라운드에서 어떤 일이 일어나나요?
Amazon SageMaker Model Monitor는 모델 모니터링을 자동화해주므로 모델을 수동으로 모니터링하거나 별도의 도구를 구축할 필요가 줄어듭니다. Model Monitor는 프로세스를 자동화하기 위해 모델 훈련에 투입되었던 데이터를 사용하여 기준 통계 및 제약 조건 세트를 생성한 다음, 사용자의 엔드포인트에서 이루어진 예측을 모니터링하기 위한 일정을 설정할 수 있는 기능을 제공합니다. Model Monitor는 규칙을 사용하여 모델의 드리프트를 감지하고, 드리프트가 발생하면 사용자에게 알려줍니다. 다음 단계는 모델 모니터링을 활성화했을 때 발생하는 상황을 설명합니다.
-
모델 모니터링 활성화: 실시간 엔드포인트인 경우, 사용자는 배포된 ML 모델로 들어오는 요청의 데이터와 모델 예측의 결과 데이터를 캡처할 수 있도록 엔드포인트를 활성화해야 합니다. 배치 변환 작업인 경우, 해당 배치 변환 입력 및 출력의 데이터 캡처를 활성화하세요.
-
기준 처리 작업: 그 다음에는 해당 모델을 훈련하는 데 사용된 데이터세트를 바탕으로 기준을 생성합니다. 기준은 지표를 계산한 다음 지표에 대한 제약 조건을 제안합니다. 예를 들어, 모델의 재현율 점수가 0.571 미만으로 저하되거나 정밀도 점수가 1.0 미만으로 떨어지지 않아야 합니다. 해당 모델이 수행하는 실시간 또는 배치 예측은 제약 조건과 비교되며, 제약 조건의 값을 벗어나는 경우에는 위반으로 보고됩니다.
-
모니터링 작업: 그리고 모니터링 일정을 생성한 다음 수집할 데이터의 종류, 수집 빈도, 분석 방법 및 생성할 보고서를 지정합니다.
-
병합 작업: 이는 사용자가 Amazon SageMaker Ground Truth를 활용하는 경우에만 적용됩니다. Model Monitor는 모델의 품질을 측정하기 위해 해당 모델이 수행한 예측과 Ground Truth 레이블을 비교하게 됩니다. 이렇게 하려면, 엔드포인트에서 캡처된 데이터 또는 배치 변환 작업에 주기적으로 레이블을 지정한 다음 이를 Amazon S3에 업로드해야 합니다.
Ground Truth 레이블을 생성하여 업로드를 마쳤다면, 모니터링 작업을 생성하는 단계에서 해당 레이블의 위치를 매개변수로 포함시킵니다.
Model Monitor를 사용하여 실시간 엔드포인트가 아닌 배치 변환 작업을 모니터링하는 경우, Model Monitor는 엔드포인트에 대한 요청을 수신하고 예측을 추적하는 대신에 추론 입력 및 출력을 모니터링합니다. Model Monitor 일정에서 고객은 처리 작업에 사용할 인스턴스의 개수와 유형을 제공합니다. 이러한 리소스는 현재 실행 상태에 관계없이 해당 일정이 삭제될 때까지는 예약된 상태로 유지됩니다.
Q: Data Capture란 무엇이며, 왜 필요하며, 활성화하려면 어떻게 해야 하나요?
모델 엔드포인트로 들어오는 입력과 Amazon S3에 배포된 모델의 추론 출력을 기록하기 위해 Data Capture라는 특징을 활성화할 수 있습니다. 실시간 엔드포인트 및 배치 변환 작업 용도로 이 특징을 활성화하는 방법에 대한 자세한 내용은 Capture data from real-time endpoint 및 Capture data from batch transform job를 참조하세요.
Q: Data Capture를 활성화하면 실시간 엔드포인트의 성능에 영향을 미치나요?
Data Capture는 프로덕션 트래픽에 영향을 주지 않고 비동기적으로 이루어집니다. 데이터 캡처를 이미 활성화한 상태라면, 요청 및 응답 페이로드는 사용자가 DataCaptureConfig에서 지정한 Amazon S3 위치에 일부 추가 메타데이터와 함께 저장되게 됩니다. 참고로, 캡처된 데이터가 Amazon S3로 전파되기까지는 지연이 있을 수 있습니다.
캡처된 데이터는 Amazon S3에 저장된 데이터 캡처 파일을 나열하는 방식으로도 볼 수 있습니다. 해당 Amazon S3 경로의 형식은 s3:///{endpoint-name}/{variant-name}/yyyy/mm/dd/hh/filename.jsonl입니다. Amazon S3 Data Capture는 Model Monitor 일정과 동일한 리전에 있어야 합니다. 또한 기준 데이터세트의 열 이름에는 소문자만 포함되어야 하며 구분자로는 밑줄(_)만 사용해야 합니다.
Q: 모델 모니터링에 Ground Truth가 필요한 이유는 무엇인가요?
다음과 같은 Model Monitor의 특징에는 Ground Truth 레이블이 필수입니다.
-
모델 품질 모니터링은 모델의 품질을 측정하기 위해 해당 모델이 수행한 예측과 Ground Truth 레이블을 비교하게 됩니다.
-
모델 편향 모니터링은 예측의 편향을 모니터링합니다. 배포된 ML 모델에 편향이 발생할 수 있는 한 가지 가능성은 훈련에 사용되는 데이터가 예측 생성을 위해 사용되는 데이터와 다른 경우입니다. 이는 훈련에 사용되는 데이터가 시간이 지남에 따라 변화하는 경우(예: 모기지 금리 변동)에 특히 두드러지며, 이 때 모델 예측은 업데이트된 데이터로 모델을 재훈련하지 않는 한 이전처럼 정확하지 않게 됩니다. 예를 들어, 주택 가격 예측을 위한 모델에서 해당 모델의 훈련에 사용된 모기지 금리가 가장 최근의 실제 모기지 금리와 다를 경우, 예측이 편향될 수 있습니다.
Q: 레이블링에 Ground Truth를 활용하는 고객의 경우, 모델 품질을 모니터링하기 위해서는 어떤 단계를 거쳐야 하나요?
모델 품질 모니터링은 모델의 품질을 측정하기 위해 해당 모델이 수행한 예측과 Ground Truth 레이블을 비교하게 됩니다. 이렇게 하려면 엔드포인트에서 캡처한 데이터 또는 배치 변환 작업에 주기적으로 레이블을 지정하고 Amazon S3에 업로드해야 합니다. 모델 편향 모니터링의 실행 시에는 캡처 이외에 Ground Truth 데이터도 필요합니다. 실제 사용 사례에서는 Ground Truth 데이터를 정기적으로 수집하여 지정된 Amazon S3 위치에 업로드해야 합니다. Ground Truth 레이블을 캡처된 예측 데이터와 일치시키려면, 해당 데이터세트 내의 개별 레코드마다 고유한 식별자가 있어야 합니다. Ground Truth 데이터에 대한 각각의 레코드 구조는 Ingest Ground Truth Labels and Merge Them With Predictions을 참조하세요.
다음 코드 예제는 테이블 형식 데이터세트에 대한 인공 Ground Truth 데이터를 생성하는 데 사용할 수 있습니다.
import random def ground_truth_with_id(inference_id): random.seed(inference_id) # to get consistent results rand = random.random() # format required by the merge container return { "groundTruthData": { "data": "1" if rand < 0.7 else "0", # randomly generate positive labels 70% of the time "encoding": "CSV", }, "eventMetadata": { "eventId": str(inference_id), }, "eventVersion": "0", } def upload_ground_truth(upload_time): records = [ground_truth_with_id(i) for i in range(test_dataset_size)] fake_records = [json.dumps(r) for r in records] data_to_upload = "\n".join(fake_records) target_s3_uri = f"{ground_truth_upload_path}/{upload_time:%Y/%m/%d/%H/%M%S}.jsonl" print(f"Uploading {len(fake_records)} records to", target_s3_uri) S3Uploader.upload_string_as_file_body(data_to_upload, target_s3_uri) # Generate data for the last hour upload_ground_truth(datetime.utcnow() - timedelta(hours=1)) # Generate data once a hour def generate_fake_ground_truth(terminate_event): upload_ground_truth(datetime.utcnow()) for _ in range(0, 60): time.sleep(60) if terminate_event.is_set(): break ground_truth_thread = WorkerThread(do_run=generate_fake_ground_truth) ground_truth_thread.start()
다음 코드 예제는 인위적인 트래픽을 생성하여 모델 엔드포인트로 전송하는 방법을 보여줍니다. 위에서 호출할 때 사용한 inferenceId속성에 주목하세요. 이 값이 있으면 Ground Truth 데이터와 조인하는 용도로 사용됩니다.그렇지 않으면 eventId가 사용됩니다.
import threading class WorkerThread(threading.Thread): def __init__(self, do_run, *args, **kwargs): super(WorkerThread, self).__init__(*args, **kwargs) self.__do_run = do_run self.__terminate_event = threading.Event() def terminate(self): self.__terminate_event.set() def run(self): while not self.__terminate_event.is_set(): self.__do_run(self.__terminate_event) def invoke_endpoint(terminate_event): with open(test_dataset, "r") as f: i = 0 for row in f: payload = row.rstrip("\n") response = sagemaker_runtime_client.invoke_endpoint( EndpointName=endpoint_name, ContentType="text/csv", Body=payload, InferenceId=str(i), # unique ID per row ) i += 1 response["Body"].read() time.sleep(1) if terminate_event.is_set(): break # Keep invoking the endpoint with test data invoke_endpoint_thread = WorkerThread(do_run=invoke_endpoint) invoke_endpoint_thread.start()
Ground Truth 데이터를 Amazon S3 버킷에 업로드할 때는 반드시 캡처된 데이터와 경로 형식이 동일해야 합니다.이 경로의 형식은 다음과 같습니다.s3://<bucket>/<prefix>/yyyy/mm/dd/hh
참고
이 경로의 날짜는 Ground Truth 레이블이 수집된 날짜에 해당합니다. 추론이 생성된 날짜와는 일치하지 않아도 됩니다.
Q: 고객이 모니터링 일정을 사용자 지정하려면 어떻게 해야 하나요?
내장된 모니터링 메커니즘을 사용하는 방법 외에도, 사전 처리 및 사후 처리 스크립트를 사용하거나 자체 컨테이너를 사용 또는 빌드함으로써 자체적인 사용자 지정 모니터링 일정과 절차를 생성할 수 있습니다. 사전 처리 및 사후 처리 스크립트는 데이터 품질과 모델 품질 작업에서만 작동한다는 점에 반드시 유의해야 합니다.
Amazon SageMaker AI는 모델 엔드포인트에서 관찰된 데이터를 모니터링하고 평가할 수 있는 기능을 제공합니다. 이를 위해서는 실시간 트래픽을 대상으로 비교를 수행할 기준을 만들어야 합니다. 기준이 준비되면, 해당 기준을 대상으로 지속적인 평가와 비교가 이루어질 수 있도록 일정을 설정하세요. 일정을 생성할 때는 사전 처리 및 사후 처리 스크립트를 제공할 수 있습니다.
다음 예제는 사전 처리 스크립트와 사후 처리 스크립트를 사용하여 모니터링 일정을 사용자 지정하는 방법을 보여줍니다.
import boto3, osfrom sagemaker import get_execution_role, Sessionfrom sagemaker.model_monitor import CronExpressionGenerator, DefaultModelMonitor # Upload pre and postprocessor scripts session = Session() bucket = boto3.Session().resource("s3").Bucket(session.default_bucket()) prefix = "demo-sagemaker-model-monitor" pre_processor_script = bucket.Object(os.path.join(prefix, "preprocessor.py")).upload_file("preprocessor.py") post_processor_script = bucket.Object(os.path.join(prefix, "postprocessor.py")).upload_file("postprocessor.py") # Get execution role role = get_execution_role() # can be an empty string # Instance type instance_type = "instance-type" # instance_type = "ml.m5.xlarge" # Example # Create a monitoring schedule with pre and post-processing my_default_monitor = DefaultModelMonitor( role=role, instance_count=1, instance_type=instance_type, volume_size_in_gb=20, max_runtime_in_seconds=3600, ) s3_report_path = "s3://{}/{}".format(bucket, "reports") monitor_schedule_name = "monitor-schedule-name" endpoint_name = "endpoint-name" my_default_monitor.create_monitoring_schedule( post_analytics_processor_script=post_processor_script, record_preprocessor_script=pre_processor_script, monitor_schedule_name=monitor_schedule_name, # use endpoint_input for real-time endpoint endpoint_input=endpoint_name, # or use batch_transform_input for batch transform jobs # batch_transform_input=batch_transform_name, output_s3_uri=s3_report_path, statistics=my_default_monitor.baseline_statistics(), constraints=my_default_monitor.suggested_constraints(), schedule_cron_expression=CronExpressionGenerator.hourly(), enable_cloudwatch_metrics=True, )
Q: 사전 처리 스크립트를 활용할 수 있는 시나리오 또는 사용 사례에는 어떤 것이 있나요?
모델 모니터에 대한 입력을 변환해야 하는 경우 사전 처리 스크립트를 사용할 수 있습니다. 다음 예제 시나리오를 검토해보세요.
-
데이터 변환을 위한 사전 처리 스크립트.
모델의 출력이
[1.0, 2.1]배열이라고 가정해 보겠습니다. Model Monitor 컨테이너는{“prediction0”: 1.0, “prediction1” : 2.1}와 같은 형태의 테이블 형식 또는 평면화된 JSON 구조에서만 작동합니다. 해당 배열은 다음 예제와 같은 사전 처리 스크립트를 사용하여 올바른 JSON 구조로 변환이 가능합니다.def preprocess_handler(inference_record): input_data = inference_record.endpoint_input.data output_data = inference_record.endpoint_output.data.rstrip("\n") data = output_data + "," + input_data return { str(i).zfill(20) : d for i, d in enumerate(data.split(",")) } -
Model Monitor의 지표 계산에서 특정 레코드를 제외합니다.
작업 중인 모델에 선택사항 특징이 있는데, 해당 선택사항 특징에 누락된 값이 있음을 나타내기 위해
-1을 사용했다고 가정해 보겠습니다. 데이터 품질 모니터가 있는 경우, 입력 값 배열에서-1을 제거하여 모니터의 지표 계산에 포함되지 않도록 하는 것이 좋습니다. 다음과 같은 스크립트를 사용하여 이러한 값을 제거할 수 있습니다.def preprocess_handler(inference_record): input_data = inference_record.endpoint_input.data return {i : None if x == -1 else x for i, x in enumerate(input_data.split(","))} -
사용자 지정 샘플링 전략을 적용합니다.
사전 처리 스크립트에 사용자 지정 샘플링 전략을 적용할 수도 있습니다. 이렇게 하려면, Model Monitor의 사전 구축된 자사 컨테이너를 구성하여 사용자가 지정한 샘플링 속도에 따라 해당 레코드의 백분율을 무시하도록 하세요. 다음 예제에서 핸들러는 핸들러 호출의 10%에서 레코드를 반환하고 나머지에 대해서는 빈 목록을 반환함으로써 레코드의 10%를 샘플링합니다.
import random def preprocess_handler(inference_record): # we set up a sampling rate of 0.1 if random.random() > 0.1: # return an empty list return [] input_data = inference_record.endpoint_input.data return {i : None if x == -1 else x for i, x in enumerate(input_data.split(","))} -
사용자 지정 로깅을 사용합니다.
해당 스크립트에서 필요한 모든 정보를 Amazon CloudWatch에 기록할 수 있습니다. 이는 오류 발생 시 사전 처리 스크립트를 디버깅할 때 유용할 수 있습니다. 다음 예제는 CloudWatch로 기록하기 위해
preprocess_handler인터페이스를 사용하는 방법을 보여줍니다.def preprocess_handler(inference_record, logger): logger.info(f"I'm a processing record: {inference_record}") logger.debug(f"I'm debugging a processing record: {inference_record}") logger.warning(f"I'm processing record with missing value: {inference_record}") logger.error(f"I'm a processing record with bad value: {inference_record}") return inference_record
참고
배치 변환 데이터에 대해 사전 처리 스크립트를 실행할 때 입력 유형이 항상 CapturedData객체가 되는 것은 아닙니다. CSV 데이터의 경우, 유형은 문자열입니다. JSON 데이터의 경우, 유형은 Python 사전입니다.
Q: 사후 처리 스크립트는 언제 활용할 수 있나요?
모니터링이 성공적으로 실행되면 사후 처리 스크립트를 확장의 형태로 활용할 수 있습니다. 간단한 예제는 다음과 같지만, 모니터링이 성공적으로 실행된 후에는 수행되어야 하는 어떤 비즈니스 함수든 수행하거나 호출할 수 있습니다.
def postprocess_handler(): print("Hello from the post-processing script!")
Q: 모델 모니터링을 위해 자체 컨테이너를 가져오는 것을 고려해야 하는 것은 언제인가요?
SageMaker AI는 테이블 형식 데이터 세트에 대한 엔드포인트 또는 배치 변환 작업에서 캡처된 데이터를 분석하기 위한 사전 구축된 컨테이너를 제공합니다. 하지만 자체 컨테이너를 생성하는 것이 권장되는 시나리오도 있습니다. 다음 시나리오를 고려해 보세요.
-
조직 내부적으로 생성 및 유지 관리되는 컨테이너만 사용하도록 되어 있는 규제 및 규정 준수 요구 사항이 적용되는 경우
-
몇 가지 타사 라이브러리를 포함하려는 경우
requirements.txt파일을 로컬 디렉터리에 배치하고 런타임 시 라이브러리 설치를 활성화하는 SageMaker AI 예측기의source_dir파라미터를 사용하여 참조할 수 있습니다. 하지만 훈련 작업을 실행하는 동안 설치 시간이 늘어나게 만드는 라이브러리나 종속성이 많다면, BYOC(Bring Your Own Container)를 활용하는 것이 좋습니다. -
인터넷 연결이 불가능한 사용자 환경(또는 사일로)이라서 패키지 다운로드가 어려운 경우
-
테이블 형식이 아닌 데이터 형식의 데이터를 모니터링하려는 경우(예: NLP 또는 CV 사용 사례)
-
Model Monitor에서 지원하는 것 이외의 추가적인 모니터링 지표가 필요한 경우
Q: 저는 NLP 및 CV 모델을 가지고 있는데 데이터 드리프트를 모니터링하려면 어떻게 해야 하나요?
Amazon SageMaker AI의 사전 구축된 컨테이너는 테이블 형식 데이터 세트를 지원합니다. NLP 및 CV 모델을 모니터링하려는 경우, Model Monitor에서 제공하는 확장 지점을 활용하여 사용자 자체 컨테이너를 가져올 수 있습니다. 요구 사항에 대한 자세한 내용은 Bring your own containers를 참조하세요. 다음은 몇 가지 추가적인 예입니다.
-
컴퓨터 비전 사용 사례에 Model Monitor를 활용하는 방법에 대한 자세한 설명은 Detecting and Analyzing incorrect predictions
을 참조하세요. -
Model Monitor를 NLP 사용 사례에 활용할 수 있는 시나리오는 Detect NLP data drift using custom Amazon SageMaker Model Monitor
를 참조하세요.
Q: Model Monitor가 활성화된 모델 엔드포인트를 삭제하고 싶은데 모니터링 일정이 아직 활성화되어 있어서 삭제할 수 없습니다. 어떻게 해야 합니까?
모델 모니터가 활성화된 SageMaker AI에서 호스팅되는 추론 엔드포인트를 삭제하려면 먼저 모델 모니터링 일정(DeleteMonitoringScheduleCLI 또는 API 사용)을 삭제해야 합니다. 그 다음에 엔드포인트를 삭제하면 됩니다.
Q: SageMaker Model Monitor는 입력에 대한 지표와 통계를 계산하나요?
Model Monitor는 입력이 아닌 출력에 대한 지표과 통계를 계산합니다.
Q: SageMaker Model Monitor는 다중 모델 엔드포인트를 지원하나요?
아니요, Model Monitor는 단일 모델을 호스팅하는 엔드포인트만 지원하고 다중 모델 엔드포인트 모니터링은 지원하지 않습니다.
Q: SageMaker Model Monitor는 추론 파이프라인의 개별 컨테이너에 대한 모니터링 데이터를 제공하나요?
Model Monitor는 추론 파이프라인 모니터링을 지원하지만 데이터 캡처 및 분석은 파이프라인의 개별 컨테이너가 아닌 전체 파이프라인에 대해 수행됩니다.
Q: 데이터 캡처가 설정된 경우 추론 요청에 영향을 미치지 않도록 하려면 어떻게 해야 하나요?
Data Capture는 추론 요청에 영향이 없도록 하기 위해 디스크 사용량이 많은 경우 요청 캡처를 중단합니다. 데이터 캡처가 요청을 계속 캡처하도록 하려면, 디스크 사용률을 75% 미만으로 유지하는 것이 좋습니다.
Q: Amazon S3 데이터 캡처가 모니터링 일정이 설정된 AWS 리전과 다른 리전에 있을 수 있나요?
아니요, Amazon S3 Data Capture는 반드시 해당 모니터링 일정과 동일한 리전에 있어야 합니다.
Q: 기준이란 무엇이며, 어떻게 생성하나요? 사용자 지정 기준을 생성할 수 있나요?
기준은 모델의 실시간 또는 배치 예측을 비교하기 위한 레퍼런스로서 사용됩니다. 이는 통계 및 지표와 함께 관련 제약 조건을 계산합니다. 모니터링 과정에서는 이러한 모든 항목이 함께 사용되어 위반을 식별합니다.
Amazon SageMaker Model Monitor의 기본 솔루션을 사용하려면 Amazon SageMaker Python SDK
기준 작업의 결과물은 두 파일, 즉 statistics.json및 constraints.json입니다. Schema for statistics 및 schema for constraints에 각 파일의 스키마가 나와 있습니다. 생성된 제약 조건을 검토하고 이를 모니터링에 사용하기 전에 수정할 수 있습니다. 해당 분야와 비즈니스 문제에 대한 이해를 바탕으로 제약 조건을 보다 공격적으로 만들거나 완화하는 방식으로 위반의 건수와 특성을 제어하는 것이 가능합니다.
Q: 기준 데이터세트를 만들기 위한 지침은 무엇인가요?
모든 종류의 모니터링에 대한 기본적인 요구 사항은 지표와 제약 조건을 계산하는 데 사용되는 기준 데이터세트를 보유하는 것입니다. 일반적으로 이는 모델에서 사용되는 훈련 데이터세트에 해당하지만, 경우에 따라서는 다른 참조 데이터세트를 사용하는 것도 가능합니다.
기준 데이터세트의 열 이름은 Spark와 호환되어야 합니다. Spark, CSV, JSON 및 Parquet 간의 호환성을 극대화하려면 소문자만을 사용하고 구분자로는 _만 사용하는 것이 좋습니다. “ ” 등의 특수 문자는 문제를 일으킬 수 있습니다.
Q: StartTimeOffset및 EndTimeOffset매개변수는 무엇이며 언제 사용되나요?
모델 품질과 같은 작업을 모니터링하는 데 Amazon SageMaker Ground Truth가 필요한 경우, Ground Truth가 준비되어 있는 데이터만 모니터링 작업에 사용되도록 해야 합니다. EndpointInputstart_time_offset및 end_time_offset매개변수를 사용하면 모니터링 작업에서 사용하는 데이터를 선택할 수 있습니다. 모니터링 작업은 start_time_offset및 end_time_offset에 의해 정의된 기간 안의 데이터를 사용합니다. 이러한 매개변수는 ISO8601 기간 형식
-
만약 예측이 이루어진 지 3일 후에 Ground Truth 결과가 도착한다면,
start_time_offset="-P3D"및end_time_offset="-P1D"(각각 3일과 1일에 해당)으로 설정합니다. -
Ground Truth 결과가 예측 후 6시간 후에 도착하고, 시간별 일정이 설정되어 있는 경우라면,
start_time_offset="-PT6H"및end_time_offset="-PT1H"(6시간 1시간에 해당)으로 설정합니다.
Q: 모니터링 작업을 '온디맨드'로 실행할 수 있나요?
예.SageMaker Processing 작업을 실행하면 '온디맨드' 모니터링 작업을 실행할 수 있습니다. 배치 변환의 경우 Pipelines에는 모니터링 작업을 온디맨드로 실행하는 SageMaker AI 파이프라인을 생성하는 데 사용할 수 있는 MonitorBatchTransformStep
Q: Model Monitor 설정은 어떻게 해야 하나요?
다음과 같은 방법으로 Model Monitor를 설정할 수 있습니다.
-
Amazon SageMaker AI Python SDK
- 기준 제안, 모니터링 일정 생성 등을 지원하는 클래스와 함수가 포함된 모델 모니터 모듈이 있습니다. SageMaker AI Python SDK를 활용하여 Model Monitor를 설정하는 자세한 노트북은 Amazon SageMaker Model Monitor 노트북 예제 를 참조하세요. SageMaker -
Pipelines – Pipelines은 QualityCheck Step 및 ClarifyCheckStep API를 통해 Model Monitor와 통합됩니다. 이러한 단계를 포함하고 파이프라인이 실행될 때마다 온디맨드로 모니터링 작업을 실행하는 데 사용할 수 있는 SageMaker AI 파이프라인을 생성할 수 있습니다.
-
Amazon SageMaker Studio Classic – 배포된 모델 엔드포인트 목록에서 엔드포인트를 선택함으로써 데이터 품질 또는 모델 품질 모니터링 일정을 모델 편향 및 설명 가능성 일정과 함께 UI에서 직접 만들 수 있습니다. 다른 유형의 모니터링 일정은 UI에서 관련 탭을 선택함으로써 생성할 수 있습니다.
-
SageMaker Model Dashboard - 엔드포인트에 배포되어 있는 모델을 선택함으로써 엔드포인트에 대한 모니터링을 활성화할 수 있습니다. SageMaker AI 콘솔의 다음 스크린샷에서는 모델 대시보드의 모델 섹션에서 이름이 인 모델을 선택
group1했습니다. 이 페이지에서 모니터링 일정을 생성하고 기존 모니터링 일정 및 알림을 편집, 활성화 또는 비활성화하는 작업을 수행할 수 있습니다. 알림 및 모델 모니터 일정을 확인하는 방법에 대한 단계별 지침은 View Model Monitor schedules and alerts를 참조하세요.
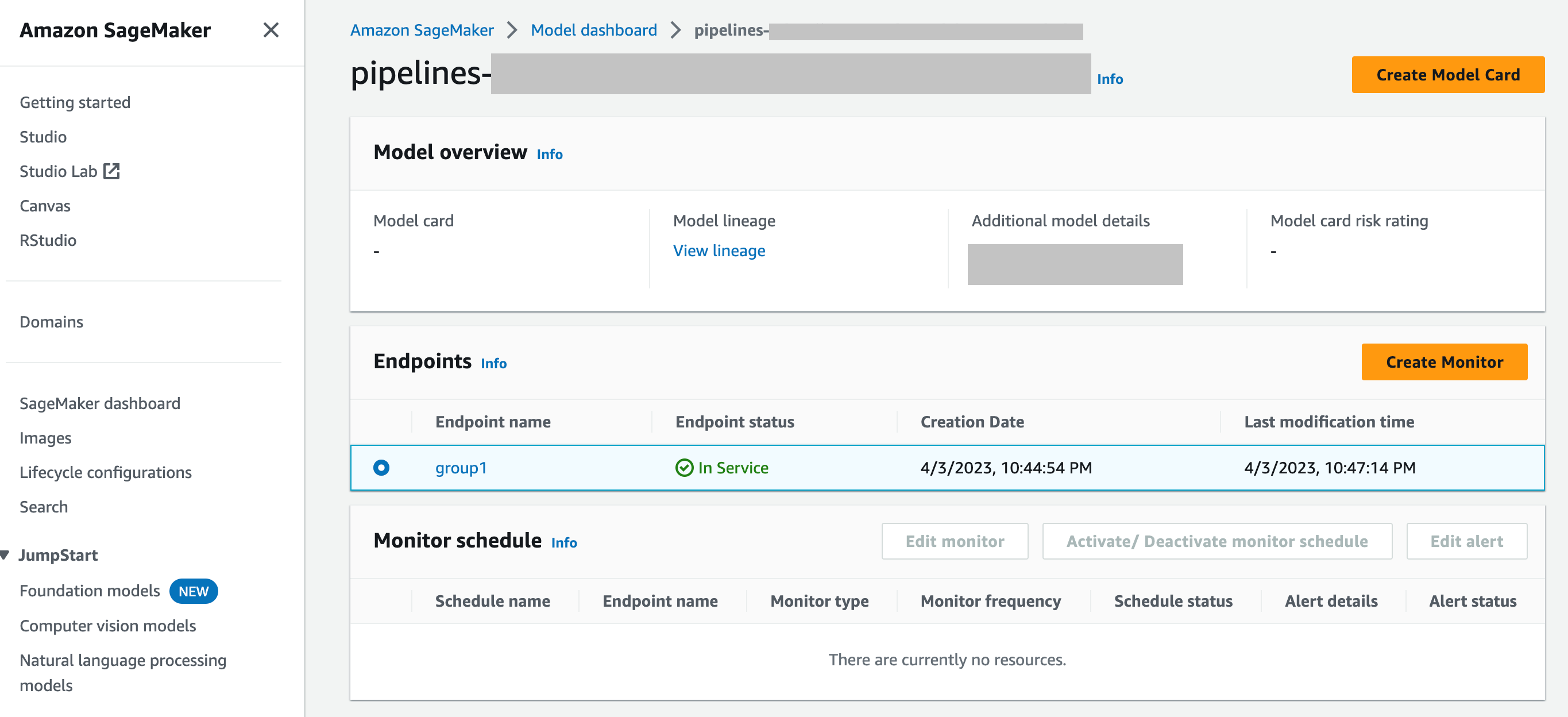
Q: Model Monitor는 SageMaker Model Dashboard와 어떻게 통합되나요?
SageMaker Model Dashboard는 예상 동작과의 편차에 대한 자동 알림 기능 그리고 모델을 검사하여 시간 경과에 따라 모델 성능에 영향을 미치는 요인을 분석하기 위한 문제 해결 기능을 제공함으로써 모든 모델에 대한 통합 모니터링을 구현합니다.
