Generate personalized and re-ranked recommendations using Amazon Personalize
Mason Cahill, Matthew Chasse, and Tayo Olajide, Amazon Web Services
Summary
This pattern shows you how to use Amazon Personalize to generate personalized recommendations—including re-ranked recommendations—for your users based on the ingestion of real-time user-interaction data from those users. The example scenario used in this pattern is based on a pet adoption website that generates recommendations for its users based on their interactions (for example, what pets a user visits). By following the example scenario, you learn to use Amazon Kinesis Data Streams to ingest interaction data, AWS Lambda to generate recommendations and re-rank the recommendations, and Amazon Data Firehose to store the data in an Amazon Simple Storage Service (Amazon S3) bucket. You also learn to use AWS Step Functions to build a state machine that manages the solution version (that is, a trained model) that generates your recommendations.
Prerequisites and limitations
Prerequisites
An active AWS account
with a bootstrapped AWS Cloud Development Kit (AWS CDK) AWS Command Line Interface (AWS CLI) with configured credentials
Product versions
Python 3.9
AWS CDK 2.23.0 or later
AWS CLI 2.7.27 or later
Architecture
Technology stack
Amazon Data Firehose
Amazon Kinesis Data Streams
Amazon Personalize
Amazon Simple Storage Service (Amazon S3)
AWS Cloud Development Kit (AWS CDK)
AWS Command Line Interface (AWS CLI)
AWS Lambda
AWS Step Functions
Target architecture
The following diagram illustrates a pipeline for ingesting real-time data into Amazon Personalize. The pipeline then uses that data to generate personalized and re-ranked recommendations for users.
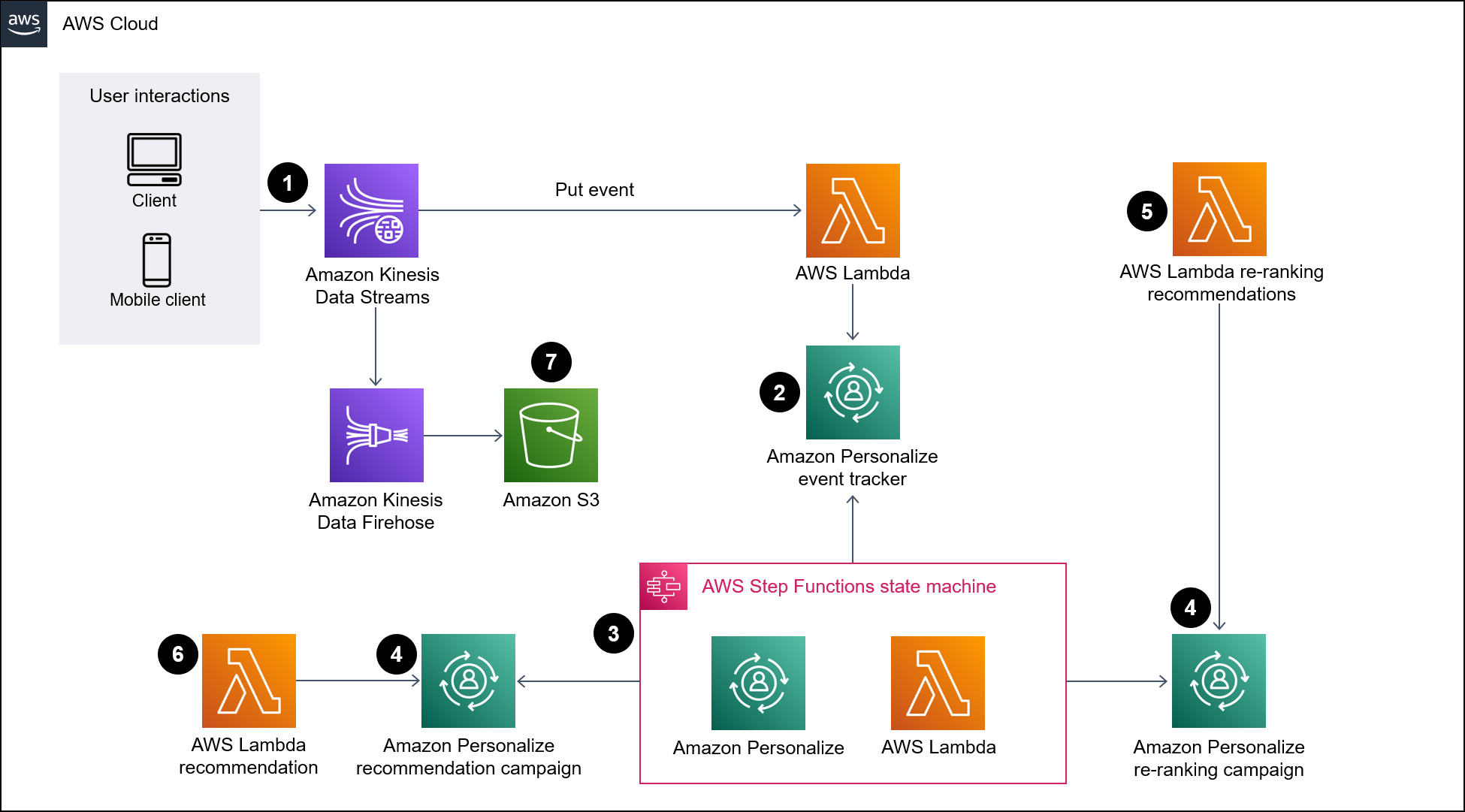
The diagram shows the following workflow:
Kinesis Data Streams ingests real-time user data (for example, events like visited pets) for processing by Lambda and Firehose.
A Lambda function processes the records from Kinesis Data Streams and makes an API call to add the user-interaction in the record to an event tracker in Amazon Personalize.
A time-based rule invokes a Step Functions state machine and generates new solution versions for the recommendation and re-ranking models by using the events from the event tracker in Amazon Personalize.
Amazon Personalize campaigns are updated by the state machine to use the new solution version.
Lambda re-ranks the list of recommended items by calling the Amazon Personalize re-ranking campaign.
Lambda retrieves the list of recommended items by calling the Amazon Personalize recommendations campaign.
Firehose saves the events to an S3 bucket where they can be accessed as historical data.
Tools
AWS tools
AWS Cloud Development Kit (AWS CDK) is a software development framework that helps you define and provision AWS Cloud infrastructure in code.
AWS Command Line Interface (AWS CLI) is an open-source tool that helps you interact with AWS services through commands in your command-line shell.
Amazon Data Firehose helps you deliver real-time streaming data
to other AWS services, custom HTTP endpoints, and HTTP endpoints owned by supported third-party service providers. Amazon Kinesis Data Streams helps you collect and process large streams of data records in real time.
AWS Lambda is a compute service that helps you run code without needing to provision or manage servers. It runs your code only when needed and scales automatically, so you pay only for the compute time that you use.
Amazon Personalize is a fully managed machine learning (ML) service that helps you generate item recommendations for your users based on your data.
AWS Step Functions is a serverless orchestration service that helps you combine Lambda functions and other AWS services to build business-critical applications.
Other tools
Code
The code for this pattern is available in the GitHub Animal Recommender
Note
The Amazon Personalize solution versions, event tracker, and campaigns are backed by custom resources (within the infrastructure) that expand on native CloudFormation resources.
Epics
| Task | Description | Skills required |
|---|---|---|
Create an isolated Python environment. | Mac/Linux setup
Windows setup To manually create a virtual environment, run the | DevOps engineer |
Synthesize the CloudFormation template. |
NoteIn step 2, | DevOps engineer |
Deploy resources and create infrastructure. | To deploy the solution resources, run the This command installs the required Python dependencies. A Python script creates an S3 bucket and an AWS Key Management Service (AWS KMS) key, and then adds the seed data for the initial model creations. Finally, the script runs NoteThe initial model training happens during stack creation. It can take up to two hours for the stack to finish getting created. | DevOps engineer |
Related resources
Additional information
Example payloads and responses
Recommendation Lambda function
To retrieve recommendations, submit a request to the recommendation Lambda function with a payload in the following format:
{ "userId": "3578196281679609099", "limit": 6 }
The following example response contains a list of animal groups:
[{"id": "1-domestic short hair-1-1"}, {"id": "1-domestic short hair-3-3"}, {"id": "1-domestic short hair-3-2"}, {"id": "1-domestic short hair-1-2"}, {"id": "1-domestic short hair-3-1"}, {"id": "2-beagle-3-3"},
If you leave out the userId field, the function returns general recommendations.
Re-ranking Lambda function
To use re-ranking, submit a request to the re-ranking Lambda function. The payload contains the userId of all the item IDs to be re-ranked and their metadata. The following example data uses the Oxford Pets classes for animal_species_id (1=cat, 2=dog) and integers 1-5 for animal_age_id and animal_size_id:
{ "userId":"12345", "itemMetadataList":[ { "itemId":"1", "animalMetadata":{ "animal_species_id":"2", "animal_primary_breed_id":"Saint_Bernard", "animal_size_id":"3", "animal_age_id":"2" } }, { "itemId":"2", "animalMetadata":{ "animal_species_id":"1", "animal_primary_breed_id":"Egyptian_Mau", "animal_size_id":"1", "animal_age_id":"1" } }, { "itemId":"3", "animalMetadata":{ "animal_species_id":"2", "animal_primary_breed_id":"Saint_Bernard", "animal_size_id":"3", "animal_age_id":"2" } } ] }
The Lambda function re-ranks these items, and then returns an ordered list that includes the item IDs and the direct response from Amazon Personalize. This is a ranked list of the animal groups that the items are in and their score. Amazon Personalize uses User-Personalization and Personalized-Ranking recipes to include a score for each item in the recommendations. These scores represent the relative certainty that Amazon Personalize has about which item the user will choose next. Higher scores represent greater certainty.
{ "ranking":[ "1", "3", "2" ], "personalizeResponse":{ "ResponseMetadata":{ "RequestId":"a2ec0417-9dcd-4986-8341-a3b3d26cd694", "HTTPStatusCode":200, "HTTPHeaders":{ "date":"Thu, 16 Jun 2022 22:23:33 GMT", "content-type":"application/json", "content-length":"243", "connection":"keep-alive", "x-amzn-requestid":"a2ec0417-9dcd-4986-8341-a3b3d26cd694" }, "RetryAttempts":0 }, "personalizedRanking":[ { "itemId":"2-Saint_Bernard-3-2", "score":0.8947961 }, { "itemId":"1-Siamese-1-1", "score":0.105204 } ], "recommendationId":"RID-d97c7a87-bd4e-47b5-a89b-ac1d19386aec" } }
Amazon Kinesis payload
The payload to send to Amazon Kinesis has the following format:
{ "Partitionkey": "randomstring", "Data": { "userId": "12345", "sessionId": "sessionId4545454", "eventType": "DetailView", "animalMetadata": { "animal_species_id": "1", "animal_primary_breed_id": "Russian_Blue", "animal_size_id": "1", "animal_age_id": "2" }, "animal_id": "98765" } }
Note
The userId field is removed for an unauthenticated user.
