As traduções são geradas por tradução automática. Em caso de conflito entre o conteúdo da tradução e da versão original em inglês, a versão em inglês prevalecerá.
AWS Arquitetura recomendada para previsão de demanda de novos produtos
Ao escalar seu pipeline de IA/ML para vários produtos e regiões, é recomendável seguir as melhores práticas de operações de aprendizado de máquina (MLOps) para reprodutibilidade, confiabilidade e escalabilidade. Para obter mais informações, consulte Implementar MLOps na documentação do Amazon SageMaker AI. A imagem a seguir mostra um exemplo de AWS arquitetura para implementar um modelo de ML que prevê a demanda por lançamentos de novos produtos.
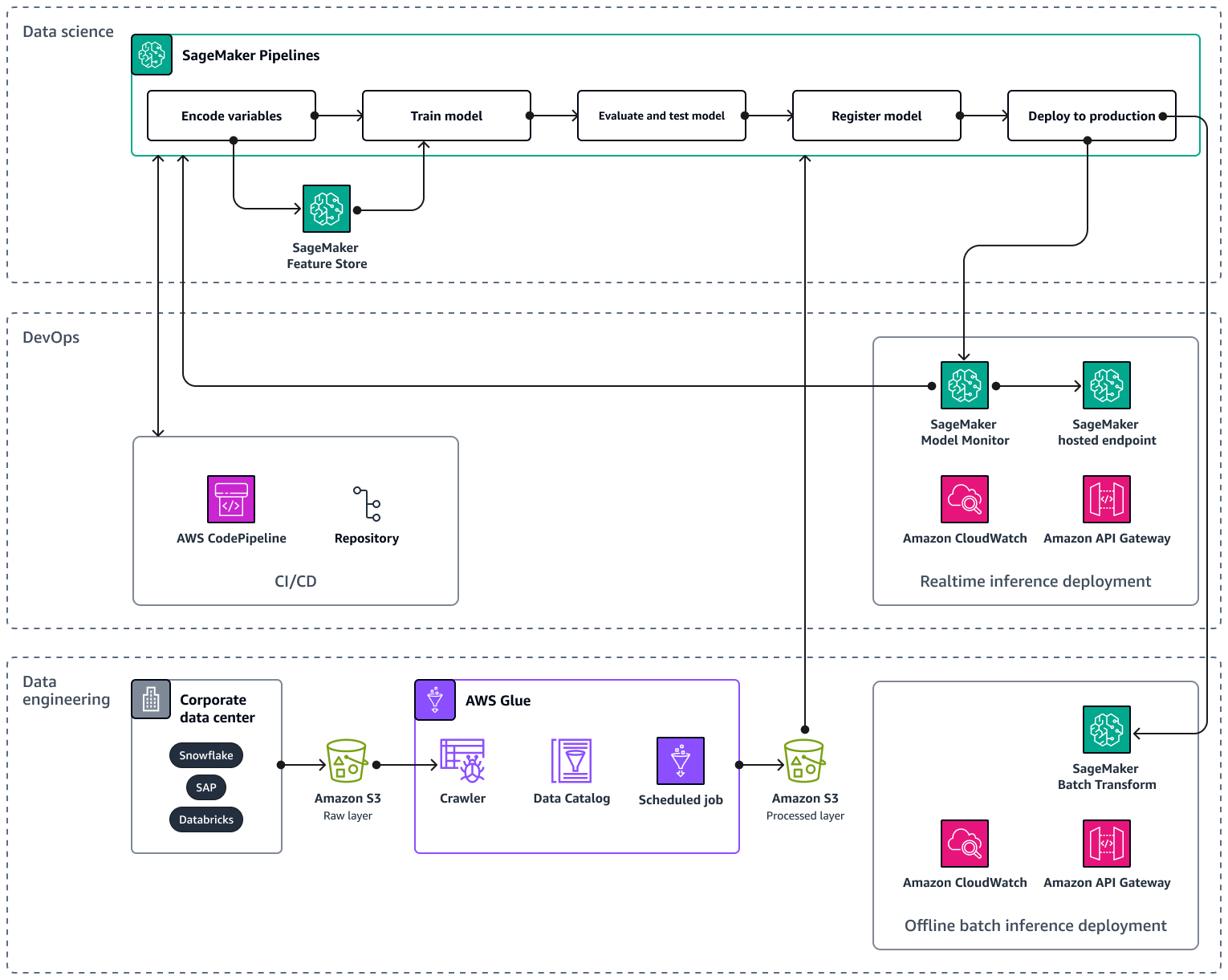
A AWS arquitetura de exemplo consiste em três camadas: engenharia de dados e ciência de dados. DevOps
A camada de engenharia de dados se concentra na ingestão de dados de fontes de dados corporativas usando AWS Gluee armazenando os dados de forma econômica no Amazon Simple Storage Service (Amazon S3). AWS Glueé um ETL serviço sem servidor totalmente gerenciado que ajuda você a categorizar, limpar, transformar e transferir dados de forma confiável entre diferentes armazenamentos de dados. O Amazon S3 é um serviço de armazenamento de objetos que oferece escalabilidade, disponibilidade de dados, segurança e desempenho. A camada de engenharia de dados também mostra a implantação de inferência em lote offline usando a transformação em lote na Amazon SageMaker AI. A transformação em lote obtém os dados de entrada do Amazon S3 e os envia em uma ou HTTP mais solicitações por meio do APIAmazon Gateway para o modelo de pipeline de inferência. O Amazon API Gateway é um serviço totalmente gerenciado que ajuda você a criar, publicar, manter, monitorar e proteger APIs em qualquer escala. Por fim, a camada de engenharia de dados mostra o uso da Amazon CloudWatch, um serviço que dá visibilidade do desempenho de todo o sistema e ajuda você a definir alarmes, reagir automaticamente às mudanças e obter uma visão unificada da integridade operacional. CloudWatch armazena os arquivos de log em um bucket do Amazon S3 que você especificar.
A DevOps camada usa API Gateway e Amazon SageMaker AI Model Monitor para implantação de inferência em tempo real. CloudWatch O Model Monitor ajuda você a configurar um sistema automatizado de acionamento de alertas para desvios na qualidade do modelo, como desvios de dados e anomalias. O Amazon CloudWatch Logs coleta arquivos de log do Model Monitor e notifica você quando a qualidade do seu modelo atinge determinados limites, que você predefine. A DevOps camada também mostra o uso de AWS CodePipelinepara automatizar pipelines de entrega de código.
A camada de ciência de dados mostra o uso do Amazon SageMaker AI Pipelines e do Amazon SageMaker AI Feature Store para gerenciar o ciclo de vida do aprendizado de máquina. SageMaker O AI Pipelines é um serviço específico de orquestração de fluxo de trabalho que ajuda você a automatizar todas as fases do ML, do pré-processamento de dados ao monitoramento do modelo. Com uma interface de usuário intuitiva e PythonSDK, você pode gerenciar pipelines de end-to-end ML repetíveis em grande escala. A integração nativa com vários Serviços da AWS ajuda você a personalizar o ciclo de vida do ML com base em seus MLOps requisitos. O Feature Store é um repositório totalmente gerenciado e desenvolvido especificamente para armazenar, compartilhar e gerenciar recursos para modelos de ML. Os recursos são entradas para os modelos de ML e são usados durante o treinamento e a inferência.
