本文属于机器翻译版本。若本译文内容与英语原文存在差异,则一律以英文原文为准。
用于预测新产品需求的推荐 AWS 架构
在将 AI/ML 管道扩展到多个产品和地区时,建议您遵循机器学习操作 (MLOps) 最佳实践,以实现可重复性、可靠性和可扩展性。有关更多信息,请参阅 Amazon A SageMaker I 文档MLOps中的实施。下图显示了实现机器学习模型的示例 AWS 架构,该模型可以预测对新产品推出的需求。
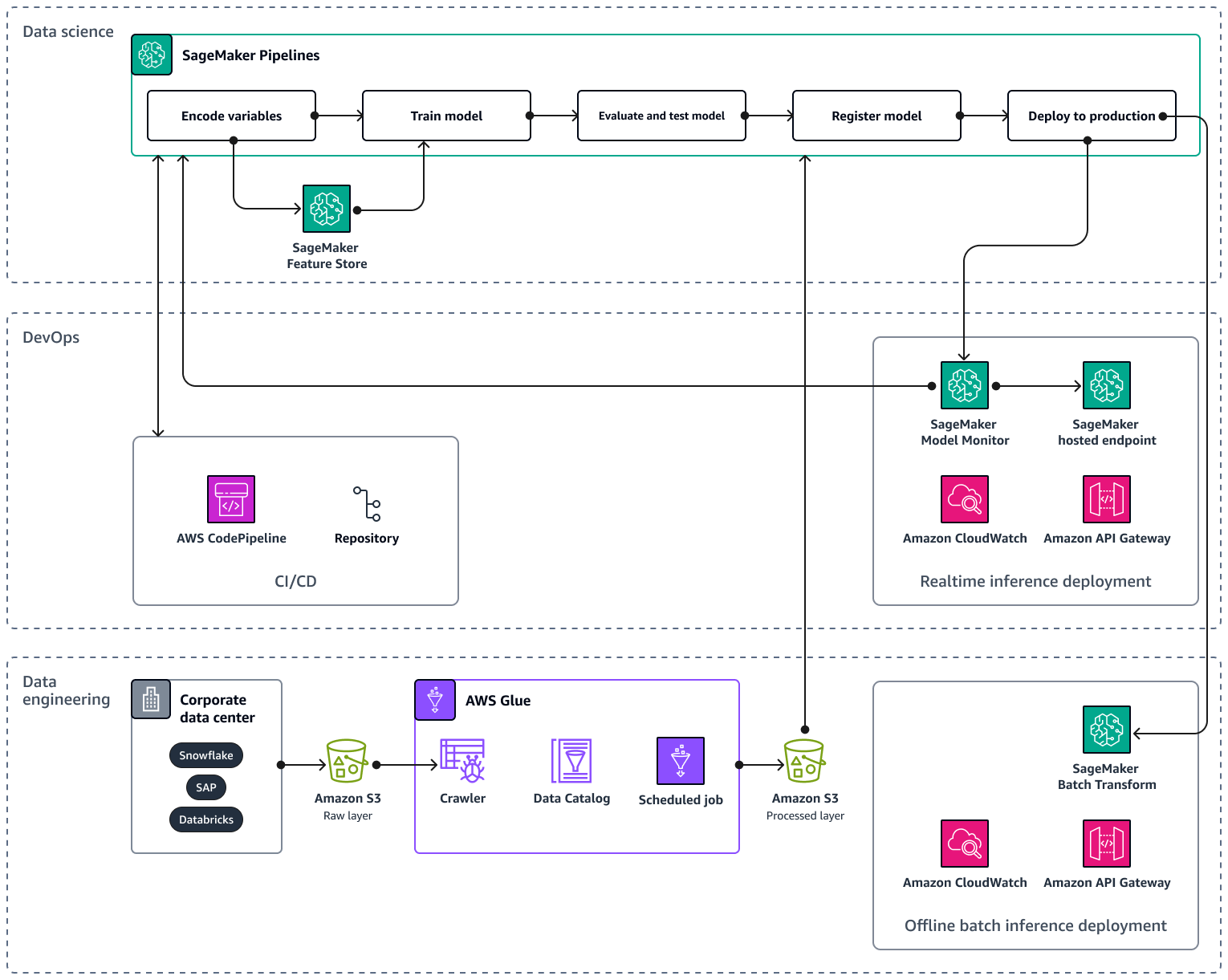
示例 AWS 架构由三个层组成:数据工程和数据科学。 DevOps
数据工程层侧重于通过使用企业数据源提取数据,AWS Glue然后以经济实惠的方式将数据存储在亚马逊简单存储服务 (Amazon S3) 中。 AWS Glue是一项完全托管的无服务器ETL服务,可帮助您在不同的数据存储之间对数据进行分类、清理、转换和可靠地传输。Amazon S3 是一种对象存储服务,提供可扩展性、数据可用性、安全性和性能。数据工程层还通过在 Amazon A SageMaker I 中使用批量转换来显示离线批量推理部署。批量转换从 Amazon S3 获取输入数据,然后通过 Amazon Gate APIw ay 通过一个或多个HTTP请求将其发送到推理管道模型。Amazon API Gateway 是一项完全托管的服务,可帮助您创建、发布、维护、监控和保护APIs任何规模。最后,数据工程层展示了 Amazon 的使用情况 CloudWatch,该服务可让您了解整个系统的性能,并帮助您设置警报、自动对变化做出反应并获得统一的运营状况视图。 CloudWatch 将日志文件存储到您指定的 Amazon S3 存储桶中。
该 DevOps 层使用API网关 CloudWatch、和 Amazon A SageMaker I 模型监控器进行实时推理部署。Model Monitor 可帮助您针对模型质量的偏差(例如数据漂移和异常)设置自动警报触发系统。Amazon Logs 会从模型监视器收集 CloudWatch 日志文件,并在您的模型质量达到您预设的特定阈值时通知您。该 DevOps 层还显示了AWS CodePipeline用于自动化代码交付管道的用途。
数据科学层展示了如何使用 Amazon A SageMaker I Pipelines 和 SageMaker Amazon AI 功能商店来管理机器学习生命周期。 SageMaker AI Pipelines 是一项专门构建的工作流程编排服务,可帮助您实现从数据预处理到模型监控的所有机器学习阶段的自动化。借助直观的用户界面和 PythonSDK,您可以大规模管理可重复的 end-to-end机器学习管道。与多个机器的原生集成 AWS 服务 可帮助您根据自己的MLOps要求自定义机器学习生命周期。Feature Store 是一个完全托管的专用存储库,用于存储、共享和管理机器学习模型的功能。特征是机器学习模型的输入,它们在训练和推理过程中使用。
