第 2 步:准备数据
获得原始数据后,您需要处理诸如数据缺失之类的复杂问题,确保为预测模型准备最能反映预期解释的数据。
如何处理缺失数据
在现实世界的预测问题中,常见的情况是原始数据中存在缺失值。时间序列中缺失值是指在指定频率下,每个时间点上对应的真实值无法用于进一步处理。将值标记为缺失的原因可能有多种。
缺失值可能是由于未进行交易或可能的测量错误(例如,因为监控某些数据的服务无法正常运行,或者无法正确进行测量)。在零售案例研究中,后者的主要示例是需求预测中的缺货情况,这意味着需求不等于当天的销售额。
在云计算场景中,当服务达到限制时(例如,某个 AWS 区域 中的 Amazon EC2
缺失值也可以由特征处理组件插入,以确保时间序列的长度与填充长度相等。如果缺失值足够普遍,则会严重影响模型的准确性。
示例 1
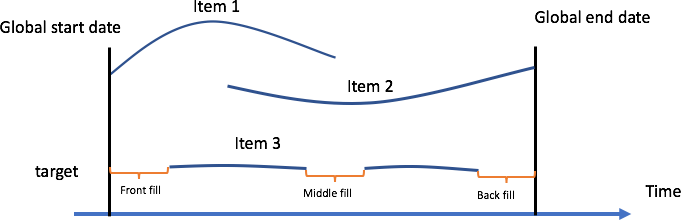
填充是向数据集中缺少的条目添加标准化值的过程。在下图中,针对包含三个项目的数据集中的项目 2,说明了处理 Amazon Forecast 中缺失值的不同策略(前填充、中间填充、回填充和未来填充)。
Amazon Forecast 支持填充目标时间序列和相关时间序列。全局开始日期定义为数据集中所有项目的开始日期中的最早开始日期。在以下示例中,项目 1 的开始日期为全局开始日期。类似地,全局结束日期定义为所有项目的时间序列的最晚结束日期,该日期为项目 2 的结束日期。
前填充是指填充从特定时间序列开始到全局开始日期的每个值。在发布本文档时,Amazon Forecast 未开启任何前填充,允许所有时间序列从不同的时间点开始。中间填充表示在时间序列中间(例如,在项目的开始日期和结束日期之间)填充的值,回填充是指从该时间序列的最后日期到全局结束日期之间的填充。
对于目标时间序列,中间填充和回填充方法的默认填充逻辑为零。未来填充(仅适用于相关时间序列)是指填充项目的全局结束日期和客户指定的预测期间之间的任何缺失值。在 Prophet 和 DeepAR+ 中使用相关时间序列数据集时需要未来值,对于 CNN-QR 则是可选的。
Amazon Forecast 中的缺失值处理策略
在上图中,全局开始日期表示所有项目的开始日期中的最早开始日期,全局结束日期表示所有项目的结束日期中的最晚结束日期。预测期间是指 Forecast 提供目标值预测的时段。
这是零售研究中常见的场景,表示可用项目的交易数据的销售额为零。这些值被视为真正的零,并在度量评估组件中使用。Amazon Forecast 使用户能够识别实际缺失的值,并将它们编码为非数字(NaN, not a number)以供算法处理。接下来,本白皮书将探讨这两种情况的不同之处,以及每种情况何时有用。
在零售案例研究中,零售商售出零件可用商品的信息不同于出售零件不可用商品的信息,无论是在商品存在以外的时期(例如,推出之前或弃用之后),还是在其存在期间内(例如,部分缺货或没有记录该时间范围内的销售数据)。默认的零填充适用于前一种情况。在后者中,即使相应的目标值通常为零,但标记为缺失的值还会传递额外的信息。最佳做法是保留缺失数据的信息,而不是丢弃这些信息。请参阅以下示例,了解为什么保留信息很重要。
Amazon Forecast 支持值、平均值、中值、最小值和最大值的其他填充逻辑。对于相关时间序列(例如,价格或促销),没有为中间填充、回填充或未来填充方法指定默认值,因为正确的缺失值逻辑因属性类型和使用案例而异。相关时间序列支持的填充逻辑包括零、值、平均值、中值、最小值和最大值。
要执行缺失值填充,请指定在调用 CreatePredictor 操作时要实施的填充类型。填充逻辑在 FeaturizationMethod 对象中指定。例如,要对不表示目标时间序列中不可用产品销量为零的值进行编码,请通过将填充类型设置为 NaN 将该值标记为真正缺失。与零填充不同,使用 NaN 编码的值被视为真正的缺失,并且不会在度量评估组件中使用

0 填充与 NaN 填充对同一项目预测的影响
在上图的左图中,垂直黑线左侧的值用 0 填充,从而导致预测偏差不足(在垂直黑线右侧)。在右图中,这些值被标记为 NaN,从而得出相应的预测。
示例 2
上图说明了正确处理线性状态空间模型(例如 ARIMA 或 ETS)缺失值的重要性。它绘制了对部分缺货商品的需求预测。训练区域在左图中以绿色显示,右侧面板中的预测范围以红色显示,真实目标以黑色显示。中位数、p10 和 p90 预测分别显示在红线和阴影区域中。底部显示用红色标记的缺货商品(占数据的 80%)。在左图中,缺货区域被忽略并用 0 填充。
这导致预测模型假设有很多零需要预测,因此预测值太低。在右图中,缺货区域被视为真正的缺失观测值,缺货区域的需求变得不确定。将缺货商品的缺失值适当标记为 NaN 后,您可以看到此图中的预测范围没有偏差。Amazon Forecast 填补了这些数据空白,使您可以轻松地正确处理缺失数据,而无需明确修改所有输入数据。
特征化和相关时间序列的概念
Amazon Forecast 使用户能够输入相关数据,以帮助提高某些支持的预测模型的准确性。这些数据可以有两种类型:相关时间序列或静态项目元数据。
注意
元数据和相关数据在机器学习中被称为特征,在统计中被称为协变量。
相关时间序列是指与目标值有一定相关性的时间序列,它直观地解释了目标值,因此对目标值的预测具有一定的统计强度(有关示例,请参阅 Amazon Forecast:大规模预测时间序列
在 Amazon Forecast 中,您可以添加两种类型的相关时间序列:历史时间序列和前瞻时间序列。历史相关时间序列包含预测期间之前的数据点,不包含未来预测期间内的任何数据点。前瞻相关时间序列包含预测期间之前和预测期间内的数据点。
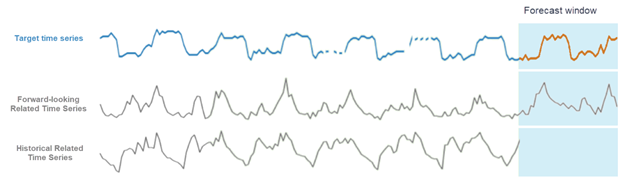
在 Amazon Forecast 中使用相关时间序列的不同方法
示例 3
下图显示了如何使用相关时间序列来预测一本畅销书籍的未来需求的示例。蓝线代表目标时间序列中的需求。价格显示为绿线。垂直线表示预测开始日期,两个分位数的预测显示在垂直线的右侧。
此示例使用前瞻相关时间序列,该时间序列在预测粒度上与目标时间序列保持一致,并且在预测开始日期到预测开始日期加预测期间(预测结束日期)的范围内的未来所有(或大多数)时间已知。
下图还显示了价格是一个适合使用的特征,因为您可以看到价格下降与产品销量增加之间的相关性。相关时间序列可以通过单独的 CSV 文件提供给 Amazon Forecast,其中包含商品 SKU、时间戳和相关时间序列值(在本例中为价格)。
Amazon Forecast 支持目标时间序列的平均和求和等聚合方法,但不支持相关时间序列。例如,将每日价格与每周价格相加是没有意义的,对于每日促销也是如此。
Amazon Forecast 可以通过包含内置的特征化数据集,自动将天气和节假日信息合并到模型中(参见 SupplementaryFeature)。天气信息和节假日会显著影响零售需求。
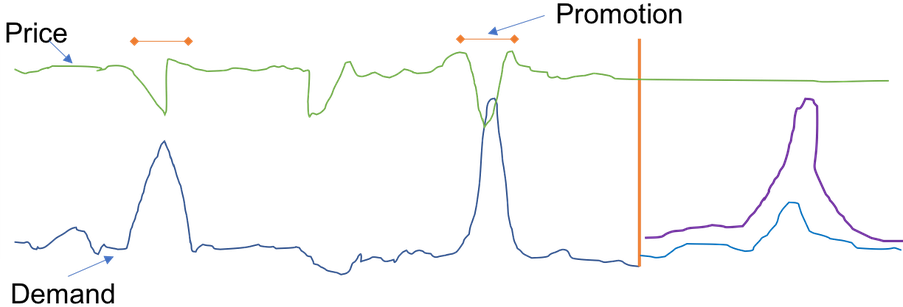
特定商品的销售额(蓝色表示,垂直红线左侧)
项目元数据(也称为分类变量)是可以输入到 Amazon Forecast 的其他有用特征(有关示例,请参阅 Amazon Forecast:大规模预测时间序列
