本文為英文版的機器翻譯版本,如內容有任何歧義或不一致之處,概以英文版為準。
使用 Oracle Data Pump 將內部部署 Oracle 資料庫遷移至 Amazon RDS for Oracle
Mohan Annam 和 Brian motzer,Amazon Web Services
Summary
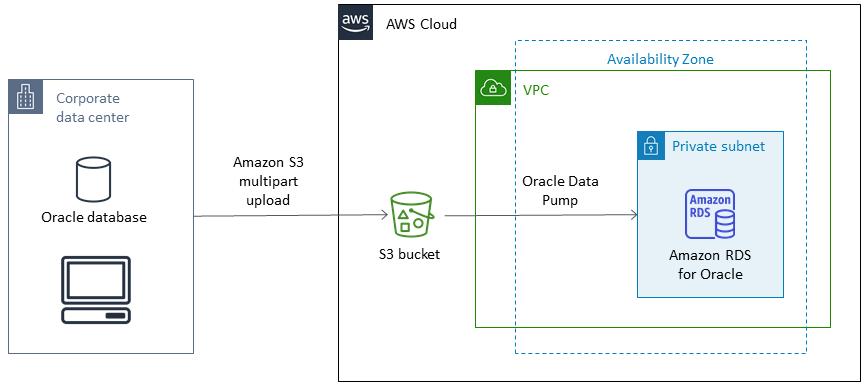
此模式說明如何使用 Oracle Data Pump,將 Oracle 資料庫從內部部署資料中心遷移至 Amazon Relational Database Service (Amazon RDS) for Oracle 資料庫執行個體。
模式涉及從來源資料庫建立資料傾印檔案、將檔案存放在 Amazon Simple Storage Service (Amazon S3) 儲存貯體中,然後將資料還原至 Amazon RDS for Oracle 資料庫執行個體。當您使用 AWS Database Migration Service (AWS DMS) 進行遷移時,此模式非常有用。
先決條件和限制
先決條件
作用中的 AWS 帳戶
在 AWS Identity and Access Management (IAM) 和 Amazon S3 分段上傳中建立角色所需的許可
從來源資料庫匯出資料所需的許可
安裝https://docs.aws.amazon.com/cli/latest/userguide/getting-started-install.html並設定 AWS Command Line Interface (AWS CLI)
產品版本
Oracle Data Pump 僅適用於 Oracle Database 10g 版本 1 (10.1) 和更新版本。
架構
來源技術堆疊
內部部署 Oracle 資料庫
目標技術堆疊
Amazon RDS for Oracle
SQL 用戶端 (Oracle SQL Developer)
S3 儲存貯體
來源和目標架構
工具
AWS 服務
AWS Identity and Access Management (IAM) 可透過控制已驗證並獲授權使用的人員,協助您安全地管理對 AWS 資源的存取。在此模式中,IAM 用於建立將資料從 Amazon S3 遷移至 Amazon RDS for Oracle 所需的角色和政策。
Amazon Relational Database Service (Amazon RDS) for Oracle 可協助您在 AWS 雲端中設定、操作和擴展 Oracle 關聯式資料庫。
Amazon Simple Storage Service (Amazon S3) 是一種雲端型物件儲存服務,可協助您儲存、保護和擷取任何數量的資料。
其他工具
Oracle Data Pump
可協助您以高速將資料和中繼資料從一個資料庫移至另一個資料庫。在此模式中,Oracle Data Pump 會用來將資料傾印 (.dmp) 檔案匯出至 Oracle 伺服器,並將其匯入 Amazon RDS for Oracle。如需詳細資訊,請參閱《Amazon RDS 文件》中的將資料匯入 Oracle on Amazon RDS。 Oracle SQL Developer
是一種整合的開發環境,可簡化傳統和雲端部署中 Oracle 資料庫的開發和管理。它與現場部署 Oracle 資料庫和 Amazon RDS for Oracle 互動,以執行匯出和匯入資料所需的 SQL 命令。
史詩
| 任務 | 描述 | 所需的技能 |
|---|---|---|
建立儲存貯體。 | 若要建立 S3 儲存貯體,請遵循 AWS 文件中的指示。 | AWS 系統管理員 |
| 任務 | 描述 | 所需的技能 |
|---|---|---|
設定 IAM 許可。 | 若要設定許可,請遵循 AWS 文件中的指示。 | AWS 系統管理員 |
| 任務 | 描述 | 所需的技能 |
|---|---|---|
建立使用者。 | 從 Oracle SQL Developer 或 SQL*Plus 連線至目標 Amazon RDS for Oracle 資料庫,並執行下列 SQL 命令來建立要匯入結構描述的使用者。
| DBA |
| 任務 | 描述 | 所需的技能 |
|---|---|---|
建立資料傾印檔案。 | 若要在
檢閱本機 | DBA |
| 任務 | 描述 | 所需的技能 |
|---|---|---|
將資料傾印檔案從來源上傳至 S3 儲存貯體。 | 使用 AWS CLI,執行下列命令。
| DBA |
| 任務 | 描述 | 所需的技能 |
|---|---|---|
將資料傾印檔案下載至 Amazon RDS | 若要將傾印檔案
先前的命令會輸出任務 ID。若要檢閱任務 ID 中的資料來檢閱下載狀態,請執行下列命令。
若要查看
| AWS 系統管理員 |
| 任務 | 描述 | 所需的技能 |
|---|---|---|
將結構描述和資料還原至 Amazon RDS。 | 若要將傾印檔案匯入
若要從匯入查看日誌檔案,請執行下列命令。
| DBA |
| 任務 | 描述 | 所需的技能 |
|---|---|---|
列出並清除匯出檔案。 | 列出並移除
| AWS 系統管理員 |
相關資源
