本文為英文版的機器翻譯版本,如內容有任何歧義或不一致之處,概以英文版為準。
模型監控常見問答集
如需有關 Amazon SageMaker Model Monitor 的詳細資訊,請參閱下列常見問答集。
問:模型監控和 SageMaker Clarify 如何協助客戶監控模型行為?
客戶可以透過 Amazon SageMaker Model Monitor 和 SageMaker Clarify 來監控以下四個維度的模型行為:資料品質、模型品質、偏差偏離和功能屬性偏離。Model Monitor
問:啟用 Sagemaker Model Monitor 時,在背景中會發生什麼情況?
Amazon SageMaker Model Monitor 可自動進行模型監控,因此無需手動監控模型或建置任何其他工具。為了將程序自動化,模型監控可讓您使用訓練模型的資料來建立一組基準統計資料和限制條件,然後設定排程以監控在端點上進行的預測。模型監控會使用規則來偵測模型中的偏離,並在發生偏離時向您提出警示。下列步驟說明啟用模型監控時會發生什麼情況:
-
啟用模型監控:對於即時端點,您必須啟用端點將傳入請求中的資料擷取到部署的機器學習 (ML) 模型,以及產生的模型預測。對於批次轉換工作,啟用批次轉換輸入和輸出的資料擷取。
-
基準處理工作:然後從用來訓練模型的資料集建立基準。基準會計算指標,並建議指標的限制條件。例如,模型的回呼分數不應迴歸並降至 0.571 以下,或精確度分數不應低於 1.0。模型中的即時或批次預測會與限制條件進行比較,如果超出限制條件值,則會報告為違規。
-
監控工作:然後建立監控排程,指定要收集哪些資料、收集資料的頻率、如何分析資料,以及要產生哪些報告。
-
合併工作:這只有在您利用 Amazon SageMaker Ground Truth 時才適用。模型監控會將模型所做的預測與 Ground Truth 標籤進行比較,以測量模型的品質。為了這麼做,您可以定期標籤端點或批次轉換工作擷取的資料,並將其上傳到 Amazon S3。
建立並上傳 Ground Truth 標籤後,在建立監控工作時將標籤的位置納入為參數。
當您使用模型監控來監控批次轉換工作而非即時端點時,則不會接收端點的要求和追蹤預測,而是模型監控會監控推論輸入和輸出。在模型監控排程中,客戶會提供要用於處理工作的執行個體計數和類型。無論目前執行的狀態為何,這些資源都會保留,直到刪除排程為止。
問:什麼是資料擷取,為什麼需要資料擷取,以及如何啟用?
為了將模型端點的輸入和從部署模型的推論輸出記錄到 Amazon S3,您可以啟用名為資料擷取的功能。如需有關如何為即時端點和批次轉換工作啟用此功能的詳細資訊,請參閱從即時端點擷取資料和從批次轉換工作擷取資料。
問:啟用資料擷取是否會影響即時端點的效能?
資料擷取以非同步方式進行,不會影響生產流量。在啟用資料擷取後,請求和回應承載以及一些其他中繼資料會儲存在您於 DataCaptureConfig 中指定的 Amazon S3 位置。請注意,將擷取的資料傳播到 Amazon S3 可能會延遲。
您也可以列出儲存在 Amazon S3 中的資料擷取檔案以檢視擷取日期。Amazon S3 路徑的格式為:s3:///{endpoint-name}/{variant-name}/yyyy/mm/dd/hh/filename.jsonl。Amazon S3 資料擷取應與模型監控排程位於同一區域。您也應確定基準資料集的欄位名稱只有小寫字母和一個底線 (_) 做為唯一的分隔符號。
問:為什麼模型監控需要 Ground Truth?
模型監控的以下功能需要 Ground Truth 標籤:
-
模型品質監控會將模型所做的預測與 Ground Truth 標籤進行比較,以測量模型的品質。
-
模型偏差監控會監控偏差的預測。當訓練中使用的資料與用於產生預測的資料不同時,會在部署的機器學習 (ML) 模型中導致偏差。如果用於訓練的資料隨著時間變更 (例如抵押貸款利率波動),則除非使用更新的資料重新訓練模型,否則模型預測不夠準確,在此情況下會特別明顯。例如,如果用於訓練模型的抵押貸款利率與真實世界最目前的抵押貸款利率不同,則用於預測房屋價格的模型可能會偏差。
問:對於利用 Ground Truth 進行標籤的客戶,我可以採取哪些步驟來監控模型的品質?
模型品質監控會將模型所做的預測與 Ground Truth 標籤進行比較,以測量模型的品質。為了這麼做,您可以定期標籤端點或批次轉換工作擷取的資料,並將其上傳到 Amazon S3。除了擷取之外,模型偏差監控執行還需要 Ground Truth 資料。在實際使用案例中,應定期收集 Ground Truth 資料並上傳到指定的 Amazon S3 位置。為了讓 Ground Truth 標籤與擷取的預測資料相符,資料集中的每個記錄都必須有唯一識別碼。如需了解每個記錄有關 Ground Truth 資料的結構,請參閱擷取 Ground Truth 標籤並將其與預測合併。
下面的程式碼範例可用於產生表格式資料集的人工 Ground Truth 資料。
import random def ground_truth_with_id(inference_id): random.seed(inference_id) # to get consistent results rand = random.random() # format required by the merge container return { "groundTruthData": { "data": "1" if rand < 0.7 else "0", # randomly generate positive labels 70% of the time "encoding": "CSV", }, "eventMetadata": { "eventId": str(inference_id), }, "eventVersion": "0", } def upload_ground_truth(upload_time): records = [ground_truth_with_id(i) for i in range(test_dataset_size)] fake_records = [json.dumps(r) for r in records] data_to_upload = "\n".join(fake_records) target_s3_uri = f"{ground_truth_upload_path}/{upload_time:%Y/%m/%d/%H/%M%S}.jsonl" print(f"Uploading {len(fake_records)} records to", target_s3_uri) S3Uploader.upload_string_as_file_body(data_to_upload, target_s3_uri) # Generate data for the last hour upload_ground_truth(datetime.utcnow() - timedelta(hours=1)) # Generate data once a hour def generate_fake_ground_truth(terminate_event): upload_ground_truth(datetime.utcnow()) for _ in range(0, 60): time.sleep(60) if terminate_event.is_set(): break ground_truth_thread = WorkerThread(do_run=generate_fake_ground_truth) ground_truth_thread.start()
下面的程式碼範例顯示如何產生人工流量以傳送至模型端點。請注意上面用於調用的 inferenceId 屬性。如果此屬性存在,會用於與 Ground Truth 資料聯結 (否則,會使用 eventId)。
import threading class WorkerThread(threading.Thread): def __init__(self, do_run, *args, **kwargs): super(WorkerThread, self).__init__(*args, **kwargs) self.__do_run = do_run self.__terminate_event = threading.Event() def terminate(self): self.__terminate_event.set() def run(self): while not self.__terminate_event.is_set(): self.__do_run(self.__terminate_event) def invoke_endpoint(terminate_event): with open(test_dataset, "r") as f: i = 0 for row in f: payload = row.rstrip("\n") response = sagemaker_runtime_client.invoke_endpoint( EndpointName=endpoint_name, ContentType="text/csv", Body=payload, InferenceId=str(i), # unique ID per row ) i += 1 response["Body"].read() time.sleep(1) if terminate_event.is_set(): break # Keep invoking the endpoint with test data invoke_endpoint_thread = WorkerThread(do_run=invoke_endpoint) invoke_endpoint_thread.start()
您必須將 Ground Truth 資料上傳到路徑格式與擷取資料相同的 Amazon S3 儲存貯體,格式如下:s3://<bucket>/<prefix>/yyyy/mm/dd/hh
注意
此路徑中的日期是收集 Ground Truth 標籤的日期。它不一定要符合產生推論的日期。
問:客戶如何自訂監控排程?
除了使用內建的監控機制之外,您還可以使用預先處理和後製處理指令碼,或使用或建置您自己的容器,以建立您自己的自訂監控排程和程序。請務必注意,預先處理和後製處理指令碼僅適用於資料和模型品質工作。
Amazon SageMaker AI 可讓您監控和評估模型端點觀察到的資料。為此,您必須建立與即時流量進行比較的基準。準備好基準後,設定排程以持續評估並與基準進行比較。建立排程時,您可以提供預先處理和後製處理指令碼。
下列範例顯示如何使用預先處理和後製處理指令碼來自訂監控排程。
import boto3, osfrom sagemaker import get_execution_role, Sessionfrom sagemaker.model_monitor import CronExpressionGenerator, DefaultModelMonitor # Upload pre and postprocessor scripts session = Session() bucket = boto3.Session().resource("s3").Bucket(session.default_bucket()) prefix = "demo-sagemaker-model-monitor" pre_processor_script = bucket.Object(os.path.join(prefix, "preprocessor.py")).upload_file("preprocessor.py") post_processor_script = bucket.Object(os.path.join(prefix, "postprocessor.py")).upload_file("postprocessor.py") # Get execution role role = get_execution_role() # can be an empty string # Instance type instance_type = "instance-type" # instance_type = "ml.m5.xlarge" # Example # Create a monitoring schedule with pre and post-processing my_default_monitor = DefaultModelMonitor( role=role, instance_count=1, instance_type=instance_type, volume_size_in_gb=20, max_runtime_in_seconds=3600, ) s3_report_path = "s3://{}/{}".format(bucket, "reports") monitor_schedule_name = "monitor-schedule-name" endpoint_name = "endpoint-name" my_default_monitor.create_monitoring_schedule( post_analytics_processor_script=post_processor_script, record_preprocessor_script=pre_processor_script, monitor_schedule_name=monitor_schedule_name, # use endpoint_input for real-time endpoint endpoint_input=endpoint_name, # or use batch_transform_input for batch transform jobs # batch_transform_input=batch_transform_name, output_s3_uri=s3_report_path, statistics=my_default_monitor.baseline_statistics(), constraints=my_default_monitor.suggested_constraints(), schedule_cron_expression=CronExpressionGenerator.hourly(), enable_cloudwatch_metrics=True, )
問:有哪些我可以利用預先處理指令碼的情況或使用案例?
當您需要將輸入轉換為模型監控時,可以使用預先處理指令碼。請思考下列範例情況:
-
預先處理指令碼進行資料轉換。
假設模型的輸出是陣列:
[1.0, 2.1]。模型監控容器僅適用於表格式或扁平化 JSON 結構,例如{“prediction0”: 1.0, “prediction1” : 2.1}。您可以使用如下範例的預先處理指令碼,將陣列轉換為正確的 JSON 結構。def preprocess_handler(inference_record): input_data = inference_record.endpoint_input.data output_data = inference_record.endpoint_output.data.rstrip("\n") data = output_data + "," + input_data return { str(i).zfill(20) : d for i, d in enumerate(data.split(",")) } -
從模型監控的指標計算中排除某些記錄。
假設您的模型具有可選功能,並且您使用
-1來表示可選功能有缺少值。如果您有資料品質監控,您可能想要將-1從輸入值陣列中移除,這樣它就不會包含在監控的指標計算中。您可以使用如下所示的指令碼來移除這些值。def preprocess_handler(inference_record): input_data = inference_record.endpoint_input.data return {i : None if x == -1 else x for i, x in enumerate(input_data.split(","))} -
套用自訂取樣策略。
您也可以在預先處理指令碼中套用自訂取樣策略。若要這麼做,請設定模型監控的第一方預先建置容器,根據您指定的取樣率忽略某個百分比的記錄。在下列範例中,處理常式會取樣 10% 的記錄,傳回 10% 的處理常式呼叫的記錄,其餘為空白清單。
import random def preprocess_handler(inference_record): # we set up a sampling rate of 0.1 if random.random() > 0.1: # return an empty list return [] input_data = inference_record.endpoint_input.data return {i : None if x == -1 else x for i, x in enumerate(input_data.split(","))} -
使用自訂記錄。
您可以將指令碼中所需的任何資訊記錄至 Amazon CloudWatch。這在發生錯誤對預先處理指令碼進行偵錯時非常有用。以下範例顯示如何使用
preprocess_handler介面記錄至 CloudWatch。def preprocess_handler(inference_record, logger): logger.info(f"I'm a processing record: {inference_record}") logger.debug(f"I'm debugging a processing record: {inference_record}") logger.warning(f"I'm processing record with missing value: {inference_record}") logger.error(f"I'm a processing record with bad value: {inference_record}") return inference_record
注意
在批次轉換資料上執行預先處理指令碼時,輸入類型並非永遠是 CapturedData 物件。如果是 CSV 資料,類型為字串。如果是 JSON 資料,類型是 Python 字典。
問:何時可以利用後製處理指令碼?
成功執行監控後,您可以利用後製處理指令碼做為延伸。以下是簡單的範例,但是您可以執行或呼叫在成功執行監控之後需要執行的任何業務函式。
def postprocess_handler(): print("Hello from the post-processing script!")
問:何時應考慮使用自有容器進行模型監控?
SageMaker AI 提供預先建置的容器,用於分析從表格式資料集的端點或批次轉換任務擷取的資料。不過,在某些情況下,您可能會想要建立自有容器。請考量下列情況:
-
您有法規和合規需求,只能使用在組織內部建立和維護的容器。
-
如果您想要包含幾個第三方程式庫,您可以將
requirements.txt檔案放在本機目錄中,並使用 SageMaker AI 估算器中的 source_dir參數來參考它,這會在執行時間啟用程式庫安裝。不過,如果您執行訓練工作時有許多程式庫或相依性會增加的安裝時間,您可能會想要利用 BYOC。 -
您的環境強制要求沒有網際網路連線 (或 Silo),因此無法下載套件。
-
您想要監控除表格式以外的資料格式的資料,例如 NLP 或 CV 使用案例。
-
當您需要模型監控所支援的監控指標以外的監控指標時。
問:我有 NLP 和 CV 模型。如何對其監控資料偏離?
Amazon SageMaker AI 的預先建置容器支援表格式資料集。如果要監控 NLP 和 CV 模型,可以利用模型監控提供的延伸點來使用自有容器。如需有關此需求的更多詳細資訊,請參閱使用自有容器。下列為更多範例:
-
如需如何針對電腦視覺使用案例使用模型監控的詳細說明,請參閱偵測和分析不正確的預測
。 -
如需針對 NLP 使用案例使用模型監控的案例,請參閱使用自訂 Amazon SageMaker Model Monitor 來偵測 NLP 資料偏離
。
問:我想要刪除已啟用模型監控的模型端點,但是由於監控排程仍作用中,所以我無法這樣做。我該怎麼辦?
如果您想要刪除 SageMaker AI 中託管且已啟用模型監控的推論端點,您必須先刪除模型監控排程 (使用 DeleteMonitoringSchedule CLI 或 API)。然後再刪除端點。
問:SageMaker Model Monitor 是否會計算輸入的指標和統計資料?
模型監控會計算輸出的指標和統計資料,而不是輸入。
問:SageMaker Model Monitor 是否支援多模型端點?
否,模型監控僅支援託管單一模型的端點,不支援監控多模型端點。
問:SageMaker Model Monitor 是否提供在推論管道中有關個別容器的監控資料?
模型監控支援監控推論管道,但擷取和分析資料是針對整個管道完成的,而不是針對管道中的單個容器。
問:在設定資料擷取時,如何防止對推論請求造成影響?
為了避免對推論要求造成影響,資料擷取會停止擷取需要高磁碟使用量的要求。建議您將磁碟使用率保持在 75% 以下,以確保資料擷取持續擷取要求。
問:Amazon S3 Data Capture 是否可以與設定監控排程 AWS 的區域位於不同的區域?
否,Amazon S3 資料擷取必須與模型監控排程位於同一區域。
問:什麼是基準?如何建立基準? 我可以建立自訂基準嗎?
基準用作比較模型中的即時或批次預測的參考。它會計算統計資料和指標及其限制條件。在監控期間,所有這些項目都會結合使用來識別違規。
若要使用 Amazon SageMaker Model Monitor 的預設解決方案,您可以利用 Amazon SageMaker Python
基準工作的結果為兩個檔案:statistics.json 和 constraints.json。統計資料的結構描述和限制條件的結構描述包含對應檔案的結構描述。您可以檢視產生的限制條件並進行修改,然後再將其用於監控。根據您對網域和企業問題的瞭解,您可以讓限制條件更積極,或放寬限制條件以控制違規的數量和性質。
問:建立基準資料集的指南為何?
任何監控類型的主要需求都是具有用於計算指標和限制條件的基準資料集。通常,這會是模型使用的訓練資料集,但在某些情況下,您可能會選擇使用其他參考資料集。
基準資料集的欄位名稱應與 Spark 相容。為了保持 Spark、CSV、JSON 和 Parquet 之間的最大相容性,建議僅使用小寫字母,並且僅用 _ 做為分隔符號。包括 “ ” 的特殊字元可能導致問題。
問:StartTimeOffset 和 EndTimeOffset 參數是什麼?要何時使用?
當需要 Amazon SageMaker Ground Truth 來監控模型品質等工作時,您需要確保監控工作只使用可用 Ground Truth 的資料。EndpointInputstart_time_offset 和 end_time_offset 參數可用來選取監控工作所使用的資料。監控工作會使用在 start_time_offset 和 end_time_offset 定義的時段中的資料。這些參數必須以 ISO 8601 持續時間格式
-
如果 Ground Truth 結果在進行預測後 3 天到達,則設定
start_time_offset="-P3D"和end_time_offset="-P1D",分別為 3 天和 1 天。 -
如果 Ground Truth 結果在預測後 6 小時到達,並且您有每小時的排程,則設定
start_time_offset="-PT6H"和end_time_offset="-PT1H",即 6 小時和 1 小時。
問:是否可以執行 '隨需' 監控工作?
可以,您可以透過執行 SageMaker Processing 工作來執行 '隨需' 監控工作。對於批次轉換,管道具有 MonitorBatchTransformStep
問:如何設定模型監控?
您可以使用下列方式來設定模型監控:
-
Amazon SageMaker AI Python SDK
– 有一個模型監控模組 ,其中包含類別和函數,可協助建議基準、建立監控排程等。如需利用 SageMaker AI Python SDK 設定模型監控的詳細筆記本,請參閱 Amazon SageMaker Model Monitor 筆記本範例 。 SageMaker -
管道 – 管道透過 QualityCheck 步驟和 ClarifyCheckStep APIs與模型監控整合。您可以建立 SageMaker AI 管道,其中包含這些步驟,並可用於在執行管道時隨需執行監控任務。
-
Amazon SageMaker Studio Classic – 您可以從部署的模型端點清單中選取端點,以直接從 UI 建立資料或模型品質監控排程,以及模型偏差和可解釋性排程。您可以在使用者介面中選取相關索引標籤,來建立其他類型監控的排程。
-
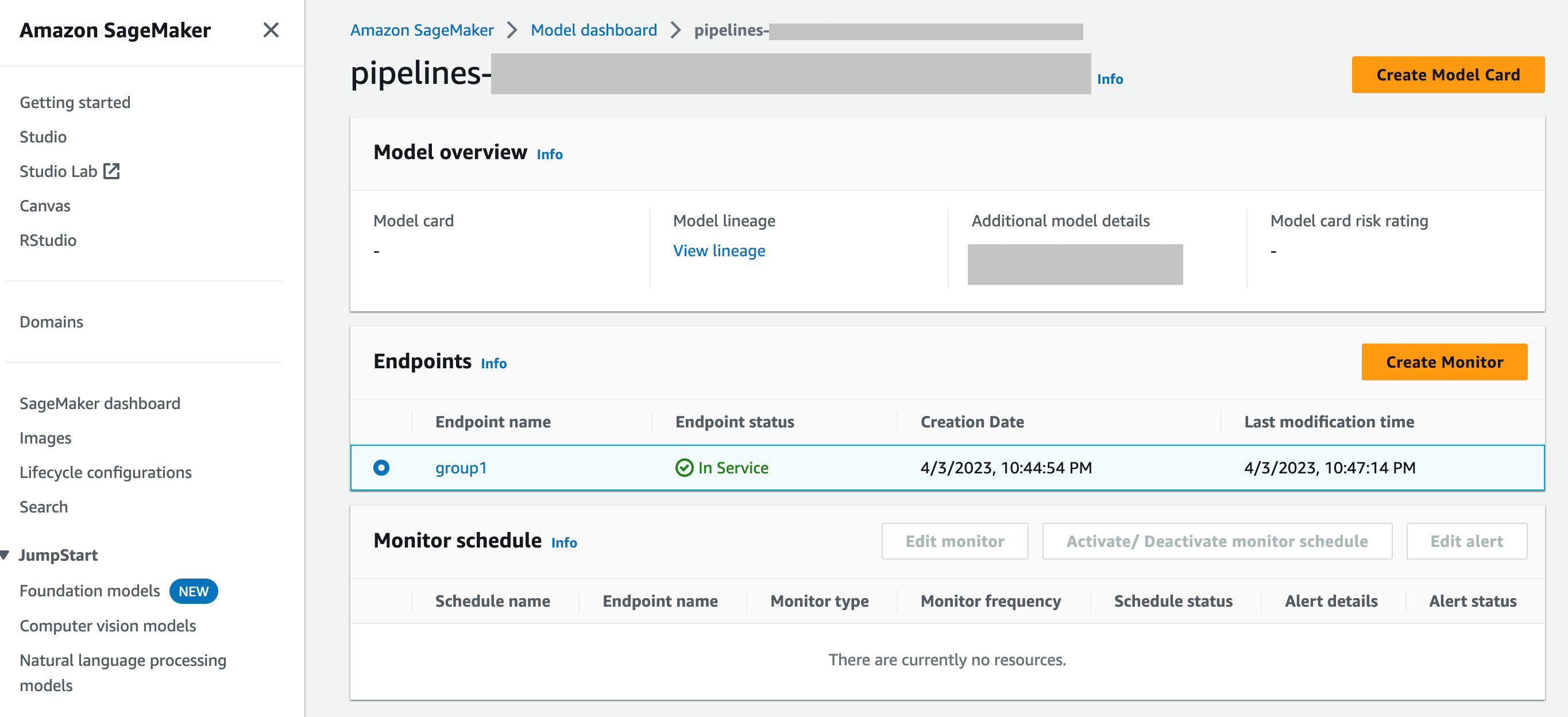
SageMaker 模型儀表板 — 您可以選取已部署到端點的模型來啟用端點上的監控。在 SageMaker AI 主控台的下列螢幕擷取畫面中,
group1已從模型儀表板的模型區段中選取名為 的模型。 您可以在此頁面建立監控排程,也可以編輯、啟動或停用現有的監控排程和警示。如需有關如何檢視警示和模型監控排程的逐步指南,請參閱檢視模型監控排程和警示。
問:模型監控如何與 SageMaker 模型儀表板整合
SageMaker 模型儀表板透過提供有關預期行為偏差的自動警示以及疑難排解,以檢查模型並分析隨著時間影響模型效能的因素,為您提供涵蓋所有模型的統一監控。
