Die vorliegende Übersetzung wurde maschinell erstellt. Im Falle eines Konflikts oder eines Widerspruchs zwischen dieser übersetzten Fassung und der englischen Fassung (einschließlich infolge von Verzögerungen bei der Übersetzung) ist die englische Fassung maßgeblich.
Vorbereiten von ML-Daten mit Amazon SageMaker Data Wrangler
Wichtig
Amazon SageMaker Data Wrangler wurde in Amazon SageMaker Canvas integriert. Im Rahmen des neuen Data Wrangler-Erlebnisses in SageMaker Canvas können Sie zusätzlich zur visuellen Oberfläche eine Benutzeroberfläche in natürlicher Sprache verwenden, um Ihre Daten zu untersuchen und zu transformieren. Weitere Informationen zu Data Wrangler in SageMaker Canvas finden Sie unter. Datenaufbereitung
Amazon SageMaker Data Wrangler (Data Wrangler) ist eine Funktion von Amazon SageMaker Studio Classic, die eine end-to-end Lösung zum Importieren, Vorbereiten, Transformieren, Funktionalisieren und Analysieren von Daten bietet. Sie können einen Data Wrangler-Datenvorbereitungsablauf in Ihre Workflows für Machine Learning (ML) integrieren, um die Datenvorverarbeitung und das Feature-Engineering mit wenig bis gar keiner Codierung zu vereinfachen und zu optimieren. Sie können auch Ihre eigenen Python-Skripts und -Transformationen hinzufügen, um Workflows anzupassen.
Data Wrangler bietet die folgenden Kernfunktionen, mit denen Sie Daten für Machine Learning analysieren und aufbereiten können.
-
Import — Connect zu Amazon Simple Storage Service (Amazon S3), Amazon Athena (Athena), Amazon Redshift, Snowflake und Databricks her und importieren Sie Daten aus diesen.
-
Daten-Flow – Erstellen Sie einen Daten-Flow, um eine Reihe von Schritten zur ML-Datenvorbereitung zu definieren. Sie können einen Flow verwenden, um Datensätze aus verschiedenen Datenquellen zu kombinieren, die Anzahl und die Typen von Transformationen zu ermitteln, die Sie auf Datensätze anwenden möchten, und einen Datenvorbereitungsworkflow zu definieren, der in eine ML-Pipeline integriert werden kann.
-
Transformieren – Bereinigen und transformieren Sie Ihren Datensatz mithilfe von Standardtransformationen wie String-, Vektor- und numerischen Datenformatierungstools. Präsentieren Sie Ihre Daten mithilfe von Transformationen wie Text und Einbettung sowie kategorischer Kodierung. date/time
-
Generieren Sie Dateneinblicke – Überprüfen Sie mit Data Wrangler Dateneinblicke und Qualitätsbericht automatisch die Datenqualität und erkennen Sie Auffälligkeiten in Ihren Daten.
-
Analysieren – Analysieren Sie Features in Ihrem Datensatz an jedem beliebigen Punkt Ihres Daten-Flows. Data Wrangler umfasst integrierte Tools zur Datenvisualisierung wie Streudiagramme und Histogramme sowie Datenanalysetools wie Target Leakage Analysis und Schnellmodellierung, um die Merkmalskorrelation zu verstehen.
-
Export – Exportieren Sie Ihren Datenvorbereitungs-Workflow an einen anderen Ort. Im Folgenden finden Sie Beispiele für Standorte:
-
Amazon Simple Storage Service (Amazon S3)-Bucket
-
Amazon SageMaker Pipelines — Verwenden Sie Pipelines, um die Modellbereitstellung zu automatisieren. Sie können die Daten, die Sie transformiert haben, direkt in die Pipelines exportieren.
-
Amazon SageMaker Feature Store — Speichern Sie die Funktionen und ihre Daten in einem zentralen Speicher.
-
Python-Skript – Speichern Sie die Daten und ihre Transformationen in einem Python-Skript für Ihre benutzerdefinierten Workflows.
-
Informationen zum Einstieg in die Verwendung von Data Wrangler finden Sie unter Erste Schritte mit Data Wrangler.
Wichtig
Data Wrangler unterstützt Jupyter Lab Version 1 () nicht mehr. JL1 Um auf die neuesten Funktionen und Updates zuzugreifen, aktualisieren Sie auf Jupyter Lab Version 3. Weitere Informationen zum Upgrade finden Sie unter Die JupyterLab Version einer Anwendung von der Konsole aus anzeigen und aktualisieren.
Wichtig
Die Informationen und Verfahren in diesem Handbuch verwenden die neueste Version von Amazon SageMaker Studio Classic. Informationen zur Aktualisierung von Studio Classic auf die neueste Version finden Sie unterÜberblick über die Amazon SageMaker Studio Classic-Benutzeroberfläche.
Sie müssen Studio Classic Version 1.3.0 oder höher verwenden. Gehen Sie wie folgt vor, um Amazon SageMaker Studio Classic zu öffnen und zu sehen, welche Version Sie verwenden.
Gehen Sie wie folgt vor, um Studio Classic zu öffnen und die Version zu überprüfen.
-
Gehen Sie wie unter beschrieben vorVoraussetzungen, um über Amazon SageMaker Studio Classic auf Data Wrangler zuzugreifen.
-
Wählen Sie neben dem Benutzer, den Sie zum Starten von Studio Classic verwenden möchten, die Option App starten aus.
-
Wählen Sie Studio.
-
Wählen Sie nach dem Laden von Studio Classic Datei, Neu und dann Terminal aus.
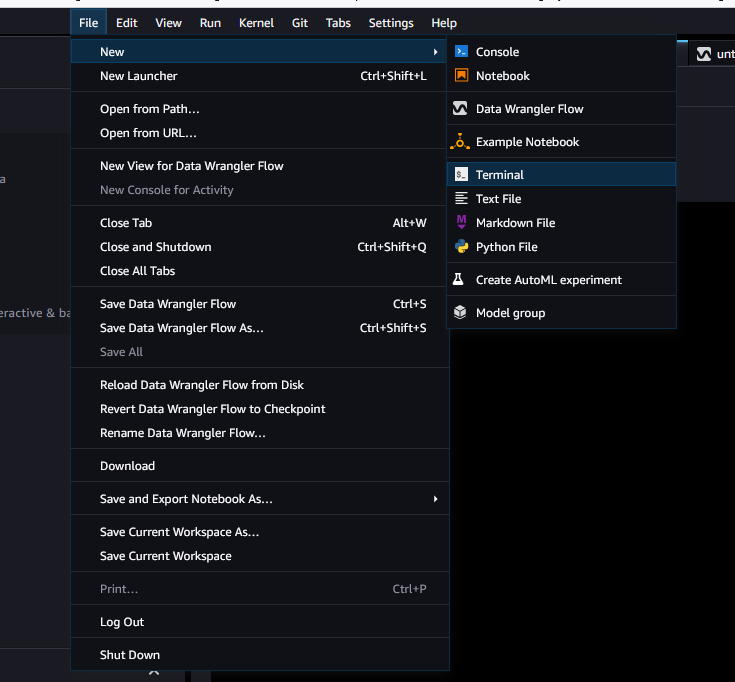
-
Nachdem Sie Studio Classic gestartet haben, wählen Sie Datei, Neu und dann Terminal aus.
-
Geben Sie ein
cat /opt/conda/share/jupyter/lab/staging/yarn.lock | grep -A 1 "@amzn/sagemaker-ui-data-prep-plugin@", um die Version Ihrer Studio Classic-Instanz zu drucken. Sie benötigen Studio Classic Version 1.3.0, um Snowflake verwenden zu können.
Sie können Amazon SageMaker Studio Classic von der aus aktualisieren AWS Management Console. Weitere Informationen zur Aktualisierung von Studio Classic finden Sie unterÜberblick über die Amazon SageMaker Studio Classic-Benutzeroberfläche.
