Die vorliegende Übersetzung wurde maschinell erstellt. Im Falle eines Konflikts oder eines Widerspruchs zwischen dieser übersetzten Fassung und der englischen Fassung (einschließlich infolge von Verzögerungen bei der Übersetzung) ist die englische Fassung maßgeblich.
Import
Sie können Amazon SageMaker Data Wrangler verwenden, um Daten aus den folgenden Datenquellen zu importieren: Amazon Simple Storage Service (Amazon S3), Amazon Athena, Amazon Redshift und Snowflake. Der Datensatz, den Sie importieren, kann bis zu 1000 Spalten enthalten.
Bei manchen Datenquellen können Sie mehrere Datenverbindungen hinzufügen:
-
Sie können eine Verbindung zu mehreren Amazon-Redshift-Clustern herstellen. Jeder Cluster wird zu einer Datenquelle.
-
Sie können jede Athena-Datenbank in Ihrem Konto abfragen, um Daten aus dieser Datenbank zu importieren.
Wenn Sie einen Datensatz aus einer Datenquelle importieren, wird er in Ihrem Datenablauf angezeigt. Data Wrangler leitet automatisch den Datentyp jeder Spalte in Ihrem Datensatz ab. Um diese Typen zu ändern, wählen Sie den Schritt Datentypen aus und wählen Sie Datentypen bearbeiten aus.
Wenn Sie Daten aus Athena oder Amazon Redshift importieren, werden die importierten Daten automatisch im standardmäßigen SageMaker AI S3-Bucket für die AWS Region gespeichert, in der Sie Studio Classic verwenden. Darüber hinaus speichert Athena Daten, die Sie in Data Wrangler in der Vorschau betrachten, in diesem Bucket. Weitere Informationen hierzu finden Sie unter Speicher für importierte Daten.
Wichtig
Der standardmäßige Amazon-S3-Bucket verfügt ggf. nicht über die am stärksten eingeschränkten Sicherheitseinstellungen, wie z. B. Bucket-Richtlinie und serverseitige Verschlüsselung (SSE). Wir empfehlen dringend, eine Bucket-Richtlinie hinzuzufügen, um den Zugriff auf in Data Wrangler importierte Datensätze einzuschränken.
Wichtig
Wenn Sie die verwaltete Richtlinie für SageMaker KI verwenden, empfehlen wir außerdem dringend, sie auf die restriktivste Richtlinie zu beschränken, die es Ihnen ermöglicht, Ihren Anwendungsfall durchzuführen. Weitere Informationen finden Sie unter Erteilen Sie einer IAM-Rolle die Erlaubnis, Data Wrangler zu verwenden.
Bei allen Datenquellen mit Ausnahme von Amazon Simple Storage Service (Amazon S3) müssen Sie eine SQL-Abfrage angeben, um Ihre Daten zu importieren. Für jede Abfrage müssen Sie Folgendes angeben:
-
Datenkatalog
-
Datenbank
-
Tabelle
Sie können den Namen der Datenbank oder des Datenkatalogs entweder in den Auswahlmenüs oder in der Abfrage angeben. Nachfolgend finden Sie Beispiele für Abfragen:
-
select * from- Die Abfrage verwendet zur Ausführung nichts, was in den Auswahlmenüs der Benutzeroberfläche (UI) angegeben ist. Sie fragtexample-data-catalog-name.example-database-name.example-table-nameexample-table-nameinnerhalb vonexample-database-nameinnerhalb vonexample-data-catalog-nameab. -
select * from– Die Abfrage verwendet für die Ausführung den Datenkatalog, den Sie im Auswahlmenü Datenkatalog angegeben haben. Sie fragtexample-database-name.example-table-nameexample-table-nameinnerhalb vonexample-database-nameinnerhalb des Datenkatalogs ab, den Sie angegeben haben. -
select * from– Für die Abfrage müssen Sie Felder für die Auswahlmenüs Datenkatalog und Datenbankname auswählen. Sie fragtexample-table-nameexample-table-nameinnerhalb des Datenkatalogs innerhalb der Datenbank und des Datenkatalogs ab, die Sie angegeben haben.
Die Verknüpfung zwischen Data Wrangler und der Datenquelle ist eine Verbindung. Sie verwenden die Verbindung, um Daten aus Ihrer Datenquelle zu importieren.
Es gibt die folgenden Verbindungstypen:
-
Direkt
-
Katalogisiert
Data Wrangler hat in einer direkten Verbindung immer Zugriff auf die aktuellsten Daten. Wenn die Daten in der Datenquelle aktualisiert wurden, können Sie die Verbindung verwenden, um die Daten zu importieren. Wenn z. B. jemand eine Datei zu einem Ihrer Amazon-S3-Buckets hinzufügt, können Sie die Datei importieren.
Eine katalogisierte Verbindung ist das Ergebnis einer Datenübertragung. Die Daten in der katalogisierten Verbindung enthalten nicht unbedingt die aktuellsten Daten. Sie könnten z. B. eine Datenübertragung zwischen Salesforce und Amazon S3 einrichten. Wenn die Salesforce-Daten aktualisiert werden, müssen Sie die Daten erneut übertragen. Sie können den Prozess der Datenübertragung automatisieren. Weitere Informationen zur Datenübertragung finden Sie unter Daten von SaaS-Plattformen (Software-as-a-Service) importieren.
Daten aus Amazon S3 importieren
Mit Hilfe von Amazon Simple Storage Service (Amazon S3) können Sie beliebige Datenmengen speichern und abrufen, jederzeit und von überall im Internet aus. Sie können diese Aufgaben mithilfe der AWS Management Console, einer einfachen und intuitiven Weboberfläche, und der Amazon S3 S3-API ausführen. Wenn Sie Ihren Datensatz lokal gespeichert haben, empfehlen wir Ihnen, ihn zu einem S3-Bucket hinzuzufügen, um ihn in Data Wrangler zu importieren. Wie das geht, erfahren Sie unter Ein Objekt in einen Bucket hochladen im Benutzerhandbuch zum Amazon Simple Storage Service.
Data Wrangler verwendet S3 Select
Wichtig
Wenn Sie planen, einen Datenfluss zu exportieren und einen Data Wrangler-Job zu starten, Daten in einen SageMaker KI-Feature-Store aufzunehmen oder eine SageMaker KI-Pipeline zu erstellen, beachten Sie, dass sich für diese Integrationen Amazon S3 S3-Eingabedaten in derselben Region befinden müssen. AWS
Wichtig
Wenn Sie eine CSV-Datei importieren, achten Sie darauf, dass diese die folgenden Anforderungen erfüllt:
-
Kein Datensatz in Ihrem Datensatz darf länger als eine Zeile sein.
-
Ein Backslash,
\, ist das einzige gültige Escape-Zeichen. -
Ihr Datensatz muss eines der folgenden Trennzeichen verwenden:
-
Komma –
, -
Doppelpunkt –
: -
Semikolon –
; -
Pipe –
| -
Tab –
[TAB]
-
Um Speicherplatz zu sparen, können Sie komprimierte CSV-Dateien importieren.
Data Wrangler bietet Ihnen die Möglichkeit, entweder den gesamten Datensatz zu importieren oder eine Stichprobe daraus. Für Amazon S3 bietet es die folgenden Optionen für die Probenahme:
-
Keine – Importiert den gesamten Datensatz.
-
Erstes K – Stichprobe der ersten K Zeilen des Datensatzes, wobei K eine von Ihnen angegebene Ganzzahl ist.
-
Randomisiert – Nimmt eine zufällige Stichprobe mit einer von Ihnen angegebenen Größe.
-
Stratifiziert – Entnimmt eine stratifizierte zufällige Stichprobe. Eine stratifizierte Stichprobe behält das Verhältnis der Werte in einer Spalte bei.
Sobald Sie Ihre Daten importiert haben, können Sie auch den Probenahme-Transformator verwenden, um eine oder mehrere Stichproben aus Ihrem gesamten Datensatz zu nehmen. Weitere Informationen über den Probenahme-Transformator finden Sie unter Sampling.
Verwenden Sie eine der folgenden Ressourcen-IDs, um Ihre Daten zu importieren:
-
Eine Amazon-S3-URI, die einen Amazon-S3-Bucket oder einen Amazon S3 Access Point verwendet
-
Ein Alias für einen Amazon S3 Access Point
-
Ein Amazon-Ressourcenname (ARN), der einen Amazon S3 Access Point oder einen Amazon-S3-Bucket verwendet
Amazon S3 Access Points sind benannte Netzwerk-Endpunkte, die an Buckets angehängt sind. Jeder Zugangspunkt verfügt über unterschiedliche Berechtigungen und Netzwerksteuerungen, die Sie konfigurieren können. Weitere Informationen zu Zugangspunkten finden Sie unter Verwalten des Datenzugriffs mit Amazon S3 Access Points.
Wichtig
Wenn Sie einen Amazon-Ressourcennamen (ARN) verwenden, um Ihre Daten zu importieren, muss dieser für eine Ressource gelten, die sich in derselben befindet AWS-Region , die Sie für den Zugriff auf Amazon SageMaker Studio Classic verwenden.
Sie können entweder eine einzelne Datei oder mehrere Dateien als Datensatz importieren. Sie können den Vorgang zum Importieren mehrerer Dateien verwenden, wenn Sie einen Datensatz haben, der in separate Dateien partitioniert ist. Er nimmt alle Dateien aus einem Amazon S3-Verzeichnis und importiert sie als ein einziger Datensatz. Informationen zu den Dateitypen, die Sie importieren können, und wie diese importiert werden, finden Sie in den folgenden Abschnitten.
Mit Hilfe von Parametern können Sie auch eine Teilmenge der Dateien importieren, die einem Muster entsprechen. Mithilfe von Parametern können Sie die Dateien, die Sie importieren, selektiver auswählen. Um mit der Verwendung von Parametern zu beginnen, bearbeiten Sie die Datenquelle und wenden Sie sie auf den Pfad an, den Sie zum Importieren der Daten verwenden. Weitere Informationen finden Sie unter Wiederverwenden von Datenabläufe für verschiedene Datensätze.
Daten aus Athena importieren
Verwenden Sie Amazon Athena, um Ihre Daten von Amazon Simple Storage Service (Amazon S3) in Data Wrangler zu importieren. In Athena schreiben Sie Standard-SQL-Abfragen, um die Daten auszuwählen, die Sie aus Amazon S3 importieren. Weitere Informationen finden Sie unter Was ist Amazon Athena?
Sie können das verwenden AWS Management Console , um Amazon Athena einzurichten. Sie müssen mindestens eine Datenbank in Athena erstellen, bevor Sie Abfragen ausführen können. Weitere Informationen zu den ersten Schritten mit Athena finden Sie unter Erste Schritte.
Athena ist direkt in Data Wrangler integriert. Sie können Athena-Abfragen schreiben, ohne die Benutzeroberfläche von Data Wrangler verlassen zu müssen.
Neben dem Schreiben einfacher Athena-Abfragen in Data Wrangler können Sie auch:
-
Athena-Arbeitsgruppen zur Verwaltung von Abfrageergebnissen verwenden. Weitere Informationen zu Arbeitsgruppen finden Sie unter Abfrageergebnisse verwalten.
-
Lebenszykluskonfigurationen zur Festlegung von Datenaufbewahrungszeiträumen. Weitere Informationen zur Datenspeicherung finden Sie unter Datenaufbewahrungszeitraum festlegen.
In Data Wrangler können Sie Abfragen in Athena vornehmen
Anmerkung
Data Wrangler unterstützt keine Verbundabfragen.
Wenn Sie Athena verwenden AWS Lake Formation , stellen Sie sicher, dass Ihre Lake Formation IAM-Berechtigungen die IAM-Berechtigungen für die Datenbank nicht überschreiben. sagemaker_data_wrangler
Data Wrangler bietet Ihnen die Möglichkeit, entweder den gesamten Datensatz zu importieren oder eine Stichprobe daraus. Für Athena bietet es die folgenden Optionen für die Probenahme:
-
Keine – Importiert den gesamten Datensatz.
-
Erstes K – Stichprobe der ersten K Zeilen des Datensatzes, wobei K eine von Ihnen angegebene Ganzzahl ist.
-
Randomisiert – Nimmt eine zufällige Stichprobe mit einer von Ihnen angegebenen Größe.
-
Stratifiziert – Entnimmt eine stratifizierte zufällige Stichprobe. Eine stratifizierte Stichprobe behält das Verhältnis der Werte in einer Spalte bei.
Das folgende Verfahren zeigt, wie ein Datensatz von Athena in Data Wrangler importiert wird.
Um einen Datensatz von Athena in Data Wrangler zu importieren
-
Melden Sie sich bei Amazon SageMaker AI Console
an. -
Wählen Sie Studio.
-
Wählen Sie App starten.
-
Wählen Sie in der Auswahlliste Studio aus.
-
Wählen Sie das Symbol Startseite aus.
-
Wählen Sie Datenaus.
-
Wählen Sie Data Wrangler.
-
Wählen Sie Daten importieren aus.
-
Wählen Sie unter Verfügbar Amazon Athena aus.
-
Wählen Sie für Datenkatalog einen Datenkatalog aus.
-
Wählen Sie von der Auswahlliste Datenbank die Datenbank aus, die Sie abfragen möchten. Wenn Sie eine Datenbank auswählen, können Sie mithilfe der unter Details aufgelisteten Tabellen eine Vorschau aller Tabellen in Ihrer Datenbank anzeigen.
-
(Optional) Wählen Sie Erweiterte Konfiguration aus.
-
Wählen Sie eine Arbeitsgruppe aus.
-
Wenn Ihre Arbeitsgruppe den Amazon S3-Ausgabespeicherort nicht durchgesetzt hat oder wenn Sie keine Arbeitsgruppe verwenden, geben Sie einen Wert für den Amazon S3-Speicherort für die Abfrageergebnisse an.
-
(Optional) Aktivieren Sie für Datenaufbewahrungsdauer das Kontrollkästchen, um eine Datenaufbewahrungsdauer festzulegen, und geben Sie die Anzahl der Tage an, für die die Daten gespeichert werden sollen, bevor sie gelöscht werden.
-
(Optional) Data Wrangler speichert die Verbindung standardmäßig. Sie können das Kontrollkästchen deaktivieren und die Verbindung nicht speichern.
-
-
Wählen Sie für Probenahme eine Methode zur Probenahme aus. Wählen Sie Keine, um die Probenahme zu deaktivieren.
-
Geben Sie Ihre Abfrage in den Abfrage-Editor ein und verwenden Sie die Schaltfläche Ausführen, um die Abfrage auszuführen. Nach erfolgreicher Abfrage sehen Sie im Editor eine Vorschau Ihres Ergebnisses.
Anmerkung
Salesforce-Daten verwenden den Typ
timestamptz. Wenn Sie die Spalte für Zeitstempel abfragen, die Sie aus Salesforce in Athena importiert haben, wandeln Sie die Daten in der Spalte in den Typtimestampum. Die folgende Abfrage wandelt die Spalte für Zeitstempel in den richtigen Typ um.# cast column timestamptz_col as timestamp type, and name it as timestamp_col select cast(timestamptz_col as timestamp) as timestamp_col from table -
Um die Ergebnisse Ihrer Abfrage zu importieren, wählen Sie Import aus.
Sobald Sie das obige Verfahren abgeschlossen haben, erscheint der Datensatz, den Sie abgefragt und importiert haben, im Data Wrangler-Ablauf.
Data Wrangler speichert die Verbindungseinstellungen standardmäßig als neue Verbindung. Wenn Sie Ihre Daten importieren, wird die Abfrage, die Sie bereits angegeben haben, als neue Verbindung angezeigt. Die gespeicherten Verbindungen speichern Informationen über die Athena-Arbeitsgruppen und Amazon-S3-Buckets, die Sie verwenden. Wenn Sie erneut eine Verbindung zu der Datenquelle herstellen, können Sie die gespeicherte Verbindung auswählen.
Abfrageergebnisse verwalten
Data Wrangler unterstützt die Verwendung von Athena-Arbeitsgruppen zur Verwaltung der Abfrageergebnisse innerhalb eines AWS -Kontos. Sie können für jede Arbeitsgruppe einen Amazon-S3-Ausgabespeicherort angeben. Sie können auch angeben, ob die Ausgabe der Abfrage an verschiedene Amazon S3-Speicherorte gesendet werden kann. Weitere Informationen finden Sie unter Zugriffs- und Kostenkontrolle für Abfragen mit Hilfe von Arbeitsgruppen.
Ihre Arbeitsgruppe ist möglicherweise so konfiguriert, dass sie den Amazon S3-Abfragespeicherort erzwingt. Sie können den Ausgabespeicherort der Abfrageergebnisse für diese Arbeitsgruppen nicht ändern.
Wenn Sie keine Arbeitsgruppe verwenden oder keinen Ausgabespeicherort für Ihre Abfragen angeben, verwendet Data Wrangler den standardmäßigen Amazon S3 S3-Bucket in derselben AWS Region, in der sich Ihre Studio Classic-Instance befindet, um Athena-Abfrageergebnisse zu speichern. Es erstellt temporäre Tabellen in dieser Datenbank, um die Abfrageausgabe in diesen Amazon-S3-Bucket zu verschieben. Es löscht diese Tabellen, sobald Daten importiert wurden. Die Datenbank sagemaker_data_wrangler bleibt jedoch bestehen. Weitere Informationen hierzu finden Sie unter Speicher für importierte Daten.
Um Athena-Arbeitsgruppen zu verwenden, richten Sie die IAM-Richtlinie ein, die den Zugriff auf Arbeitsgruppen gewährt. Wenn Sie eine SageMaker AI-Execution-Role verwenden, empfehlen wir, die Richtlinie zur Rolle hinzuzufügen. Weitere Informationen zu IAM-Richtlinien für Arbeitsgruppen finden Sie unter IAM-Richtlinien für den Zugriff auf Arbeitsgruppen. Beispielrichtlinien für Arbeitsgruppen finden Sie unter Beispielrichtlinien für Arbeitsgruppen.
Datenaufbewahrungszeitraum festlegen
Data Wrangler legt automatisch eine Datenaufbewahrungsdauer für die Abfrageergebnisse fest. Die Ergebnisse werden nach Ablauf der Aufbewahrungsfrist gelöscht. Die Standardaufbewahrungsdauer beträgt z. B. fünf Tage. Die Ergebnisse der Abfrage werden nach fünf Tagen gelöscht. Diese Konfiguration soll Ihnen helfen, Daten zu bereinigen, die Sie nicht mehr verwenden. Durch das Bereinigen Ihrer Daten wird verhindert, dass unbefugte Benutzer darauf zugreifen können. Es hilft auch, die Kosten zum Speichern Ihrer Daten auf Amazon S3 zu kontrollieren.
Wenn Sie keinen Aufbewahrungszeitraum festlegen, bestimmt die Amazon S3-Lebenszykluskonfiguration die Dauer, für die die Objekte gespeichert werden. Die Datenaufbewahrungsrichtlinie, die Sie für die Lebenszykluskonfiguration angegeben haben, entfernt alle Abfrageergebnisse, die älter sind als die von Ihnen angegebene Lebenszykluskonfiguration. Weitere Informationen finden Sie unter Lebenszykluskonfiguration in einem Bucket festlegen.
Data Wrangler verwendet Amazon S3-Lebenszykluskonfigurationen, um die Aufbewahrung und den Ablauf von Daten zu verwalten. Sie müssen Ihrer Amazon SageMaker Studio Classic IAM-Ausführungsrolle Berechtigungen zur Verwaltung von Bucket-Lebenszykluskonfigurationen erteilen. Gehen Sie wie folgt vor, um Berechtigungen zu erteilen.
Gehen Sie wie folgt vor, um Berechtigungen zur Verwaltung der Lebenszykluskonfiguration zu erteilen.
-
Melden Sie sich bei der an AWS Management Console und öffnen Sie die IAM-Konsole unter. https://console.aws.amazon.com/iam/
-
Wählen Sie Roles.
-
Geben Sie in der Suchleiste die Amazon SageMaker AI-Ausführungsrolle an, die Amazon SageMaker Studio Classic verwendet.
-
Wählen Sie die Rolle aus.
-
Wählen Sie Add permissions (Berechtigungen hinzufügen) aus.
-
Wählen Sie Inline-Richtlinie erstellen aus.
-
Geben Sie für Service S3 an und wählen Sie diesen aus.
-
Wählen Sie im Abschnitt Lesen die Option GetLifecycleConfiguration.
-
Wählen Sie im Abschnitt Schreiben die Option PutLifecycleConfiguration.
-
Wählen Sie für Ressourcen die Option Spezifisch aus.
-
Wählen Sie für Aktionen das Pfeilsymbol neben Berechtigungsverwaltung aus.
-
Wählen Sie PutResourcePolicy.
-
Wählen Sie für Ressourcen die Option Spezifisch aus.
-
Wählen Sie das Kontrollkästchen neben Alle in diesem Konto aus.
-
Wählen Sie Richtlinie prüfen.
-
Geben Sie für Name einen Namen an.
-
Wählen Sie Richtlinie erstellen aus.
Daten aus Amazon Redshift importieren
Amazon Redshift ist ein vollständig verwalteter Data-Warehouse-Service in Petabytegröße in der Cloud. Der erste Schritt zur Erstellung eines Data Warehouse besteht darin, eine Reihe von Knoten zu starten, die als Amazon-Redshift-Cluster bezeichnet werden. Sobald Sie Ihren Cluster bereitgestellt haben, können Sie Ihren Datensatz hochladen und anschließend Datenanalyseabfragen vornehmen.
Sie können in Data Wrangler eine Verbindung zu einem oder mehreren Amazon Redshift-Clustern herstellen und diese abfragen. Um diese Importoption verwenden zu können, müssen Sie mindestens einen Cluster in Amazon Redshift erstellen. Wie das geht, erfahren Sie unter Erste Schritte mit Amazon Redshift.
Sie können die Ergebnisse Ihrer Amazon Redshift-Abfrage an einem der folgenden Speicherorte ausgeben:
-
Der Standard-Amazon-S3-Bucket
-
Ein Amazon S3-Ausgabespeicherort, den Sie angeben
Sie können entweder den gesamten Datensatz importieren oder eine Stichprobe davon. Für Amazon Redshift bietet es die folgenden Probenahme-Optionen:
-
Keine – Importiert den gesamten Datensatz.
-
Erstes K – Stichprobe der ersten K Zeilen des Datensatzes, wobei K eine von Ihnen angegebene Ganzzahl ist.
-
Randomisiert – Nimmt eine zufällige Stichprobe mit einer von Ihnen angegebenen Größe.
-
Stratifiziert – Entnimmt eine stratifizierte zufällige Stichprobe. Eine stratifizierte Stichprobe behält das Verhältnis der Werte in einer Spalte bei.
Der standardmäßige Amazon S3 S3-Bucket befindet sich in derselben AWS Region, in der sich Ihre Studio Classic-Instance zum Speichern von Amazon Redshift Redshift-Abfrageergebnissen befindet. Weitere Informationen finden Sie unter Speicher für importierte Daten.
Für den standardmäßigen Amazon-S3-Bucket oder den von Ihnen angegebenen Bucket haben Sie die folgenden Verschlüsselungsoptionen:
-
Die standardmäßige AWS serviceseitige Verschlüsselung mit einem von Amazon S3 verwalteten Schlüssel (SSE-S3)
-
Ein AWS Key Management Service (AWS KMS) Schlüssel, den Sie angeben
Ein AWS KMS Schlüssel ist ein Verschlüsselungsschlüssel, den Sie erstellen und verwalten. Weitere Informationen zu KMS-Schlüsseln finden Sie unter AWS Key Management Service.
Sie können einen AWS KMS Schlüssel entweder mit dem Schlüssel-ARN oder dem ARN Ihres AWS Kontos angeben.
Wenn Sie die von IAM verwaltete Richtlinie verwendenAmazonSageMakerFullAccess, um einer Rolle die Berechtigung zur Verwendung von Data Wrangler in Studio Classic zu erteilen, muss Ihr Datenbankbenutzername das Präfix haben. sagemaker_access
Gehen Sie wie folgt vor, um zu erfahren, wie Sie einen neuen Cluster hinzufügen.
Anmerkung
Data Wrangler verwendet die Amazon-Redshift-Daten-API mit temporären Anmeldeinformationen. Weitere Informationen zu dieser API finden Sie unter Verwendung des Amazon-Redshift-Daten-API im Amazon Redshift Management-Leitfaden.
So stellen Sie eine Verbindung zu einem Amazon-Redshift-Cluster her
-
Melden Sie sich bei Amazon SageMaker AI Console
an. -
Wählen Sie Studio.
-
Wählen Sie App starten.
-
Wählen Sie in der Auswahlliste Studio aus.
-
Wählen Sie das Symbol Startseite aus.
-
Wählen Sie Datenaus.
-
Wählen Sie Data Wrangler.
-
Wählen Sie Daten importieren aus.
-
Wählen Sie unter Verfügbar Amazon Athena aus.
-
Wählen Sie Amazon Redshift aus.
-
Wählen Sie Temporäre Anmeldeinformationen (IAM) als Typ aus.
-
Geben Sie einen Verbindungsnamen ein. Dies ist ein Name, der von Data Wrangler verwendet wird, um diese Verbindung zu identifizieren.
-
Geben Sie die Cluster-ID ein, um anzugeben, zu welchem Cluster Sie eine Verbindung herstellen möchten. Hinweis: Geben Sie nur die Cluster-ID und nicht den vollständigen Endpunkt des Amazon-Redshift-Clusters ein.
-
Geben Sie den Datenbanknamen der Datenbank ein, mit der Sie eine Verbindung herstellen möchten.
-
Geben Sie einen Datenbankbenutzer ein, um den Benutzer zu identifizieren, den Sie für die Verbindung mit der Datenbank verwenden möchten.
-
Geben Sie für IAM-Rolle entladen den IAM-Rollen-ARN der Rolle ein, die der Amazon-Redshift-Cluster annehmen soll, um Daten in Amazon S3 zu verschieben und zu schreiben. Weitere Informationen zu dieser Rolle finden Sie unter Autorisieren von Amazon Redshift, in Ihrem Namen auf andere AWS Services zuzugreifen, im Amazon Redshift Management Guide.
-
Wählen Sie Connect aus.
-
(Optional) Geben Sie für den Amazon S3-Ausgabespeicherort den S3-URI zum Speichern der Abfrageergebnisse an.
-
(Optional) Geben Sie für die KMS-Schlüssel-ID den ARN des AWS KMS Schlüssels oder Alias an. Die folgende Abbildung zeigt Ihnen, wo Sie jeden dieser Schlüssel in der AWS Management Console finden.

Die folgende Abbildung zeigt alle Felder aus dem vorangehenden Verfahren.
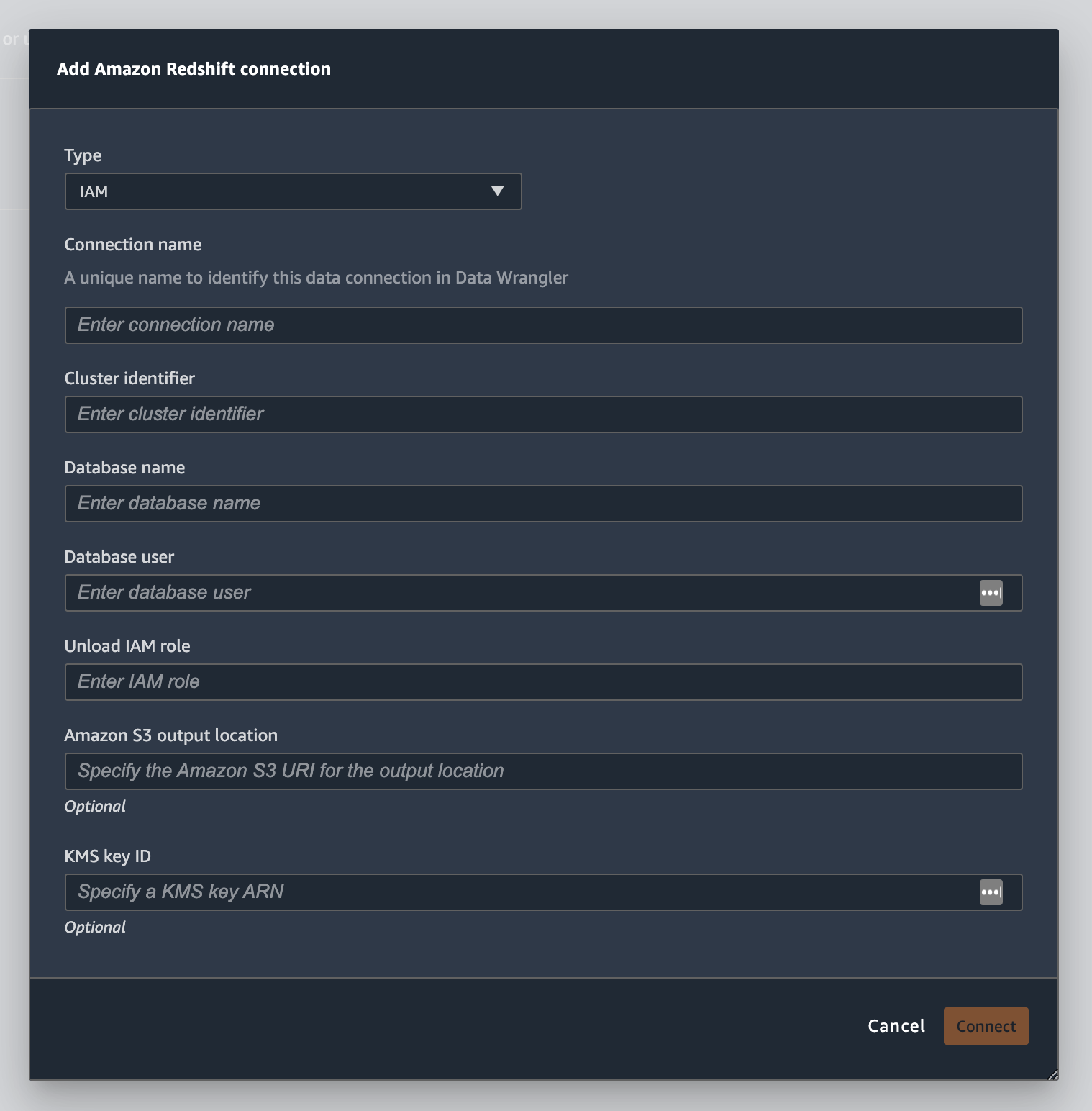
Sobald Ihre Verbindung erfolgreich hergestellt wurde, erscheint sie als Datenquelle unter Datenimport. Wählen Sie diese Datenquelle aus, um Ihre Datenbank abzufragen und Daten zu importieren.
Gehen Sie wie folgt vor, um Daten aus Amazon Redshift abzufragen und zu importieren
-
Wählen Sie aus Datenquellen die Verbindung aus, über die Sie die Abfrage vornehmen möchten.
-
Wählen Sie ein Schema aus. Weitere Informationen zu Amazon Redshift-Schemata finden Sie unter Schemata im Entwicklerhandbuch für Amazon Redshift-Datenbanken.
-
(Optional) Geben Sie unter Erweiterte Konfiguration die Probenahme-Methode an, die Sie verwenden möchten.
-
Geben Sie Ihre Abfrage in den Abfrage-Editor ein und wählen Sie Ausführen, um die Abfrage auszuführen. Nach erfolgreicher Abfrage sehen Sie im Editor eine Vorschau Ihres Ergebnisses.
-
Wählen Sie Datensatz importieren aus, um den abgefragten Datensatz zu importieren.
-
Geben Sie einen Datensatznamen ein. Wenn Sie einen Datensatznamen hinzufügen, der Leerzeichen enthält, werden diese Leerzeichen beim Import Ihres Datensatzes durch Unterstriche ersetzt.
-
Wählen Sie Hinzufügen aus.
Gehen Sie wie folgt vor, um einen Datensatz zu bearbeiten.
-
Navigieren Sie zu Ihrem Data Wrangler-Ablauf.
-
Wählen Sie das + neben Quelle – Gesampelt.
-
Ändern Sie die importierten Daten.
-
Wählen Sie Anwenden aus.
Daten aus Amazon EMR importieren
Sie können Amazon EMR als Datenquelle für Ihren Amazon SageMaker Data Wrangler-Flow verwenden. Amazon EMR ist eine verwaltete Cluster-Plattform, mit der Sie große Datenmengen verarbeiten und analysieren können. Weitere Informationen über Amazon EMR finden Sie unter Was ist Amazon EMR? Um einen Datensatz aus EMR zu importieren, stellen Sie eine Verbindung dazu her und nehmen Sie eine Abfrage vor.
Wichtig
Sie müssen die folgenden Voraussetzungen erfüllen, um eine Verbindung mit einem Amazon EMR-Cluster herzustellen:
Voraussetzungen
-
Netzwerkkonfigurationen
-
Sie haben eine Amazon VPC in der Region, die Sie für den Start von Amazon SageMaker Studio Classic und Amazon EMR verwenden.
-
Sowohl Amazon EMR als auch Amazon SageMaker Studio Classic müssen in privaten Subnetzen gestartet werden. Sie können sich im selben oder in verschiedenen Subnetzen befinden.
-
Amazon SageMaker Studio Classic muss sich im Nur-VPC-Modus befinden.
Weitere Informationen zum Erstellen einer VPC finden Sie unter Erstellen einer VPC.
Weitere Informationen zum Erstellen einer VPC finden Sie unter SageMaker Studio Classic-Notebooks in einer VPC mit externen Ressourcen Connect.
-
Die Amazon EMR-Cluster, die Sie ausführen, müssen sich in derselben Amazon-VPC befinden.
-
Die Amazon EMR-Cluster und die Amazon VPC müssen sich im selben AWS Konto befinden.
-
Auf Ihren Amazon EMR-Clustern läuft Hive oder Presto.
-
Hive-Cluster müssen eingehenden Datenverkehr von Studio Classic-Sicherheitsgruppen auf Port 10000 zulassen.
-
Presto-Cluster müssen eingehenden Datenverkehr von Studio Classic-Sicherheitsgruppen an Port 8889 zulassen.
Anmerkung
Die Portnummer ist für Amazon EMR-Cluster, die IAM-Rollen verwenden, unterschiedlich. Weitere Informationen finden Sie am Ende des Abschnitts mit den Voraussetzungen.
-
-
-
SageMaker Studio Classic
-
Amazon SageMaker Studio Classic muss Jupyter Lab Version 3 ausführen. Informationen zur Aktualisierung der Jupyter-Lab-Version finden Sie unter. Die JupyterLab Version einer Anwendung von der Konsole aus anzeigen und aktualisieren
-
Amazon SageMaker Studio Classic hat eine IAM-Rolle, die den Benutzerzugriff steuert. Die Standard-IAM-Rolle, die Sie für die Ausführung von Amazon SageMaker Studio Classic verwenden, hat keine Richtlinien, die Ihnen Zugriff auf Amazon EMR-Cluster gewähren können. Sie müssen die Berechtigungen erteilende Richtlinie an die IAM-Rolle anhängen. Weitere Informationen finden Sie unter Amazon EMR-Cluster auflisten.
-
Der IAM-Rolle muss außerdem die folgende Richtlinie angefügt sein
secretsmanager:PutResourcePolicy. -
Wenn Sie eine Studio Classic-Domain verwenden, die Sie bereits erstellt haben, stellen Sie sicher, dass sie sich im
AppNetworkAccessTypeNur-VPC-Modus befindet. Hinweise zur Aktualisierung einer Domain zur Verwendung des Nur-VPC-Modus finden Sie unter Fahren Sie SageMaker Studio Classic herunter und aktualisieren Sie es.
-
-
Amazon EMR-Cluster
-
Sie müssen Hive oder Presto in Ihrem Cluster installiert haben.
-
Amazon EMR muss Version 5.5.0 oder höher sein.
Anmerkung
Amazon EMR unterstützt automatisches Beenden. Automatisches Beenden verhindert, dass inaktive Cluster ausgeführt werden, und verhindert, dass Ihnen Kosten entstehen. Die folgenden Versionen unterstützen automatisches Beenden:
-
Für 6.x-Versionen Version 6.1.0 oder später.
-
Für 5.x-Versionen Version 5.30.0 oder später.
-
-
-
Amazon EMR-Cluster mit IAM-Laufzeitrollen
-
Verwenden Sie die folgenden Seiten, um IAM-Laufzeitrollen für den Amazon EMR-Cluster einzurichten. Wenn Sie Laufzeitrollen verwenden, müssen Sie die Verschlüsselung während der Übertragung aktivieren:
-
Sie benötigen Lake Formation als Governance-Tool für die Daten in Ihren Datenbanken. Sie müssen außerdem die externe Datenfilterung für die Zugriffskontrolle verwenden.
-
Weitere Informationen zu Lake Formation finden Sie unter Was ist AWS Lake Formation?
-
Weitere Informationen zur Integration von Lake Formation in Amazon EMR finden Sie unter Integration von Drittanbieter-Services in Lake Formation.
-
-
Die Version Ihres Clusters muss 6.9.0 oder später sein.
-
Zugriff auf AWS Secrets Manager. Weitere Informationen über Secrets Manager finden Sie unter Was ist AWS Secrets Manager?
-
Hive-Cluster müssen eingehenden Datenverkehr von Studio Classic-Sicherheitsgruppen auf Port 10000 zulassen.
-
Eine Amazon VPC ist ein virtuelles Netzwerk, das logisch von anderen Netzwerken in der AWS Cloud isoliert ist. Amazon SageMaker Studio Classic und Ihr Amazon EMR-Cluster existieren nur innerhalb der Amazon VPC.
Gehen Sie wie folgt vor, um Amazon SageMaker Studio Classic in einer Amazon VPC zu starten.
Gehen Sie wie folgt vor, um Studio Classic in einer VPC zu starten.
-
Navigieren Sie zur SageMaker AI-Konsole unter https://console.aws.amazon.com/sagemaker/
. -
Wählen Sie Launch SageMaker Studio Classic.
-
Wählen Sie Standardeinstellung.
-
Wählen Sie für die Standardausführungsrolle die IAM-Rolle aus, um Studio Classic einzurichten.
-
Wählen Sie die VPC aus, auf der Sie die Amazon EMR-Cluster gestartet haben.
-
Wählen Sie als Subnetz ein privates Subnetz aus.
-
Geben Sie für Sicherheitsgruppe(n) die Sicherheitsgruppen an, die Sie zwischen Ihren VPC zur Steuerung verwenden.
-
Wählen Sie Nur VPC.
-
(Optional) AWS verwendet einen Standard-Verschlüsselungsschlüssel. Sie können einen AWS Key Management Service Schlüssel zur Verschlüsselung Ihrer Daten angeben.
-
Wählen Sie Weiter aus.
-
Wählen Sie unter Studio-Einstellungen die Konfigurationen aus, die am besten für Sie geeignet sind.
-
Wählen Sie Weiter, um die SageMaker Canvas-Einstellungen zu überspringen.
-
Wählen Sie Weiter, um die RStudio Einstellungen zu überspringen.
Wenn Sie noch keinen Amazon EMR-Cluster haben, können Sie mit dem folgenden Verfahren einen solchen erstellen. Weitere Informationen zu Amazon EMR finden Sie unter Was ist Amazon EMR?
Gehen Sie wie folgt vor, um einen Cluster zu erstellen.
-
Navigieren Sie zur AWS Management Console.
-
Geben Sie in die Suchleiste
Amazon EMRein. -
Wählen Sie Cluster erstellen.
-
Geben Sie als Cluster-Name den Namen Ihres Clusters ein.
-
Wählen Sie als Veröffentlichung die veröffentlichte Version des Clusters aus.
Anmerkung
Amazon EMR unterstützt die automatische Beenden für die folgenden Versionen:
-
Für 6.x-Versionen: Versionen 6.1.0 oder später
-
Für 5.x-Versionen die Versionen 5.30.0 oder später
Automatisches Beenden verhindert, dass inaktive Cluster ausgeführt werden, und verhindert, dass Ihnen Kosten entstehen.
-
-
(Optional) Wählen Sie für Anwendungen Presto aus.
-
Wählen Sie die Anwendung aus, die Sie auf dem Cluster ausführen.
-
Geben Sie unter Netzwerk für Hardwarekonfiguration die Hardwarekonfigurationseinstellungen an.
Wichtig
Wählen Sie für Networking die VPC aus, auf der Amazon SageMaker Studio Classic ausgeführt wird, und wählen Sie ein privates Subnetz aus.
-
Geben Sie unter Sicherheit und Zugriff die Sicherheitseinstellungen an.
-
Wählen Sie Erstellen aus.
Ein Tutorial zur Erstellung eines Amazon EMR-Clusters finden Sie unter Erste Schritte mit Amazon EMR. Informationen zu bewährten Methoden für die Konfiguration eines Clusters finden Sie unter Überlegungen und bewährte Methoden.
Anmerkung
Aus Sicherheitsgründen kann Data Wrangler nur Verbindungen zu VPCs privaten Subnetzen herstellen. Sie können keine Verbindung zum Master-Knoten herstellen, es sei denn, Sie verwenden AWS Systems Manager ihn für Ihre Amazon EMR-Instances. Weitere Informationen finden Sie unter Sicherung des Zugriffs auf EMR-Cluster mithilfe von AWS Systems Manager
Sie können derzeit die folgenden Methoden verwenden, um auf einen Amazon EMR-Cluster zuzugreifen:
-
Keine Authentifizierung
-
Lightweight Directory Access Protocol (LDAP)
-
IAM (Laufzeitrolle)
Wenn Sie keine Authentifizierung oder LDAP verwenden, müssen Sie möglicherweise mehrere Cluster und EC2 Amazon-Instance-Profile erstellen. Wenn Sie Administrator sind, müssen Sie ggf. Benutzergruppen mit unterschiedlichen Zugriffsebenen auf die Daten anlegen. Diese Methoden können zu einem Verwaltungsaufwand führen, der die Verwaltung Ihrer Benutzer erschwert.
Wir empfehlen die Verwendung einer IAM-Laufzeitrolle, mit der sich mehrere Benutzer mit demselben Amazon EMR-Cluster verbinden können. Eine Laufzeitrolle ist eine IAM-Rolle, die Sie einem Benutzer zuweisen können, der eine Verbindung zu einem Amazon EMR-Cluster herstellt. Sie können die IAM-Laufzeitrolle so konfigurieren, dass sie über Berechtigungen verfügt, die für jede Benutzergruppe spezifisch sind.
Verwenden Sie die folgenden Abschnitte, um einen Presto- oder Hive Amazon EMR-Cluster mit aktiviertem LDAP zu erstellen.
Verwenden Sie die folgenden Abschnitte, um die LDAP-Authentifizierung für Amazon EMR-Cluster zu verwenden, die Sie bereits erstellt haben.
Gehen Sie wie folgt vor, um Daten aus einem Cluster zu importieren.
Gehen Sie wie folgt vor, um Daten aus einem Cluster zu importieren.
-
Öffnen Sie einen Data Wrangler-Ablauf.
-
Wählen Sie Create Connection (Verbindung erstellen) aus.
-
Wählen Sie Amazon EMR aus.
-
Führen Sie eine der folgenden Aufgaben aus.
-
(Optional) Geben Sie für Secrets ARN die Amazon-Ressourcennummer (ARN) der Datenbank innerhalb des Clusters an. Secrets geben zusätzliche Sicherheit. Weitere Informationen zu Geheimnissen finden Sie unter Was ist AWS Secrets Manager? Informationen zum Erstellen eines Geheimnisses für Ihren Cluster finden Sie unter Ein AWS Secrets Manager Geheimnis für Ihren Cluster erstellen.
Wichtig
Sie müssen ein Secret angeben, wenn Sie für die Authentifizierung eine IAM-Laufzeitrolle verwenden.
-
Wählen Sie aus der Dropdown-Tabelle einen Cluster aus.
-
-
Wählen Sie Weiter aus.
-
Wählen Sie für Wählen Sie einen Endpunkt für den
example-cluster-nameCluster eine Abfrage-Engine aus. -
(Optional) Wählen Sie Verbindung speichern aus.
-
Wählen Sie Weiter aus, wählen Sie Anmeldung und wählen Sie dann eine der folgenden Optionen aus:
-
Keine Authentifizierung
-
LDAP
-
IAM
-
-
Geben Sie für Login to
example-cluster-namecluster den Benutzernamen und das Passwort für den Cluster an. -
Wählen Sie Connect aus.
-
Geben Sie im Abfrage-Editor eine SQL-Abfrage an.
-
Wählen Sie Ausführen aus.
-
Wählen Sie Importieren aus.
Ein AWS Secrets Manager Geheimnis für Ihren Cluster erstellen
Wenn Sie für den Zugriff auf Ihren Amazon EMR-Cluster eine IAM-Laufzeitrolle verwenden, müssen Sie die Anmeldeinformationen, die Sie für den Zugriff auf Amazon EMR verwenden, als Secrets-Manager-Secret speichern. Sie speichern alle Anmeldeinformationen, die Sie für den Zugriff auf den Cluster verwenden, innerhalb des Secrets.
Sie müssen die folgenden Informationen im Secret speichern:
-
JDBC-Endpunkt –
jdbc:hive2:// -
DNS-Name – Der DNS-Name Ihres Amazon-EMR-Clusters. Dies ist entweder der Endpunkt für den Primärknoten oder der Hostname.
-
Port –
8446
Auch die folgenden Zusatzinformationen können Sie innerhalb des Secrets speichern:
-
IAM-Rolle – Die IAM-Rolle, die Sie für den Zugriff auf den Cluster verwenden. Data Wrangler verwendet standardmäßig Ihre SageMaker AI-Ausführungsrolle.
-
Truststore-Pfad – Standardmäßig erstellt Data Wrangler einen Truststore-Pfad für Sie. Außerdem können Sie einen eigenen Truststore-Pfad verwenden. Weitere Informationen zu Truststore-Pfaden finden Sie unter Verschlüsselung bei der Übertragung in 2. HiveServer
-
Truststore-Passwort – Standardmäßig erstellt Data Wrangler ein Truststore-Passwort für Sie. Außerdem können Sie einen eigenen Truststore-Pfad verwenden. Weitere Informationen zu Truststore-Pfaden finden Sie unter Verschlüsselung bei der Übertragung in 2. HiveServer
Gehen Sie wie folgt vor, um die Anmeldeinformationen in einem Secrets-Manager-Secret zu speichern.
Gehen Sie wie folgt vor, um Ihre Anmeldeinformationen als Secret zu speichern.
-
Navigieren Sie zur AWS Management Console.
-
Geben Sie im Suchfeld Secrets Manager an.
-
Wählen Sie AWS Secrets Manager.
-
Wählen Sie Store a new secret (Ein neues Secret speichern).
-
Als Secret-Typ wählen Sie Anderer Secret-Typ aus.
-
Wählen Sie unter Schlüssel/Wert-Paare die Option Klartext aus.
-
Für Cluster, auf denen Hive läuft, können Sie für die IAM-Authentifizierung die folgende Vorlage verwenden.
{"jdbcURL": "" "iam_auth": {"endpoint": "jdbc:hive2://", #required "dns": "ip-xx-x-xxx-xxx.ec2.internal", #required "port": "10000", #required "cluster_id": "j-xxxxxxxxx", #required "iam_role": "arn:aws:iam::xxxxxxxx:role/xxxxxxxxxxxx", #optional "truststore_path": "/etc/alternatives/jre/lib/security/cacerts", #optional "truststore_password": "changeit" #optional }}Anmerkung
Wenn Sie Ihre Daten importiert haben, wenden Sie Transformationen darauf an. Anschließend exportieren Sie die so transformierten Daten an einen bestimmten Speicherort. Wenn Sie ein Jupyter Notebook verwenden, um Ihre transformierten Daten nach Amazon S3 zu exportieren, müssen Sie den im vorangehenden Beispiel angegebenen Truststore-Pfad verwenden.
Ein Secrets-Manager-Secret speichert die JDBC-URL des Amazon EMR-Clusters als Secret. Die Verwendung eines Secrets ist sicherer als die direkte Eingabe Ihrer Anmeldeinformationen.
Gehen Sie wie folgt vor, um die JDBC-URL als Geheimnis zu speichern.
Gehen Sie wie folgt vor, um die JDBC-URL als Geheimnis zu speichern.
-
Navigieren Sie zur AWS Management Console.
-
Geben Sie im Suchfeld Secrets Manager an.
-
Wählen Sie AWS Secrets Manager.
-
Wählen Sie Store a new secret (Ein neues Secret speichern).
-
Als Secret-Typ wählen Sie Anderer Secret-Typ aus.
-
Geben Sie für Schlüssel/Wert-Paare
jdbcURLals Schlüssel und eine gültige JDBC-URL als Wert an.Das Format einer gültigen JDBC-URL hängt davon ab, ob Sie die Authentifizierung verwenden und ob Sie Hive oder Presto als Abfrage-Engine verwenden. Die folgende Liste zeigt die gültigen JBDC-URL-Formate für die verschiedenen möglichen Konfigurationen.
-
Hive, keine Authentifizierung –
jdbc:hive2://emr-cluster-master-public-dns:10000/; -
Hive, LDAP-Authentifizierung –
jdbc:hive2://emr-cluster-master-public-dns-name:10000/;AuthMech=3;UID=david;PWD=welcome123; -
Bei Hive mit aktiviertem SSL hängt das JDBC-URL-Format davon ab, ob Sie für die TLS-Konfiguration eine Java-Keystore-Datei verwenden. Die Java-Keystore-Datei hilft dabei, die Identität des Hauptknotens des Amazon EMR-Clusters zu überprüfen. Um eine Java-Keystore-Datei zu verwenden, generieren Sie diese auf einem EMR-Cluster und laden Sie sie auf Data Wrangler hoch. Verwenden Sie den folgenden Befehl auf dem Amazon EMR-Cluster,
keytool -genkey -alias hive -keyalg RSA -keysize 1024 -keystore hive.jks, um eine Datei zu generieren. Informationen zum Ausführen von Befehlen auf einem Amazon EMR-Cluster finden Sie unter Zugriffs auf EMR-Cluster sichern mithilfe von AWS Systems Manager. Um eine Datei hochzuladen, wählen Sie links auf der Navigationsleiste der Data Wrangler-Benutzeroberfläche den Aufwärtspfeil. Im Folgenden sind die gültigen JDBC-URL-Formate für Hive mit aktiviertem SSL aufgeführt:
-
Ohne Java-Keystore-Datei –
jdbc:hive2://emr-cluster-master-public-dns:10000/;AuthMech=3;UID=user-name;PWD=password;SSL=1;AllowSelfSignedCerts=1; -
Mit Java-Keystore-Datei –
jdbc:hive2://emr-cluster-master-public-dns:10000/;AuthMech=3;UID=user-name;PWD=password;SSL=1;SSLKeyStore=/home/sagemaker-user/data/Java-keystore-file-name;SSLKeyStorePwd=Java-keystore-file-passsword;
-
-
Presto, keine Authentifizierung — jdbc:presto: //:8889/;
emr-cluster-master-public-dns -
Bei Presto mit aktivierter LDAP-Authentifizierung und SSL hängt das JDBC-URL-Format davon ab, ob Sie für die TLS-Konfiguration eine Java-Keystore-Datei verwenden. Die Java-Keystore-Datei hilft dabei, die Identität des Hauptknotens des Amazon EMR-Clusters zu überprüfen. Um eine Java-Keystore-Datei zu verwenden, generieren Sie diese auf einem EMR-Cluster und laden Sie sie auf Data Wrangler hoch. Um eine Datei hochzuladen, wählen Sie links auf der Navigationsleiste der Data Wrangler-Benutzeroberfläche den Aufwärtspfeil. Informationen zum Erstellen einer Java-Keystore-Datei für Presto finden Sie unter Java-Keystore-Datei für TLS
. Informationen zum Ausführen von Befehlen auf einem Amazon EMR-Cluster finden Sie unter Zugriffs auf EMR-Cluster sichern mithilfe von AWS Systems Manager . -
Ohne Java-Keystore-Datei –
jdbc:presto://emr-cluster-master-public-dns:8889/;SSL=1;AuthenticationType=LDAP Authentication;UID=user-name;PWD=password;AllowSelfSignedServerCert=1;AllowHostNameCNMismatch=1; -
Mit Java-Keystore-Datei –
jdbc:presto://emr-cluster-master-public-dns:8889/;SSL=1;AuthenticationType=LDAP Authentication;SSLTrustStorePath=/home/sagemaker-user/data/Java-keystore-file-name;SSLTrustStorePwd=Java-keystore-file-passsword;UID=user-name;PWD=password;
-
-
Während des Importierens von Daten aus einem Amazon-EMR-Cluster können Probleme auftreten. Informationen zur Fehlerbehebung finden Sie unter Beheben von Problemen mit Amazon EMR.
Daten aus Databricks importieren (JDBC)
Sie können Databricks als Datenquelle für Ihren Amazon SageMaker Data Wrangler-Flow verwenden. Um einen Datensatz aus Databricks zu importieren, verwenden Sie die JDBC-Importfunktion (Java Database Connectivity), um auf Ihre Databricks-Datenbank zuzugreifen. Sobald Sie die Datenbank öffnen, geben Sie eine SQL-Abfrage an, um die Daten abzurufen und zu importieren.
Wir gehen davon aus, dass Sie einen laufenden Databricks-Cluster haben und dass Sie Ihren JDBC-Treiber entsprechend konfiguriert haben. Weitere Informationen finden Sie auf den folgenden Seiten mit der Dokumentation zu Databricks:
Data Wrangler speichert Ihre JDBC-URL in. AWS Secrets Manager Sie müssen Ihrer Amazon SageMaker Studio Classic IAM-Ausführungsrolle Berechtigungen zur Verwendung von Secrets Manager erteilen. Gehen Sie wie folgt vor, um Berechtigungen zu erteilen.
Gehen Sie wie folgt vor, um Secrets Manager Berechtigungen zu erteilen.
-
Melden Sie sich bei der an AWS Management Console und öffnen Sie die IAM-Konsole unter. https://console.aws.amazon.com/iam/
-
Wählen Sie Roles.
-
Geben Sie in der Suchleiste die Amazon SageMaker AI-Ausführungsrolle an, die Amazon SageMaker Studio Classic verwendet.
-
Wählen Sie die Rolle aus.
-
Wählen Sie Add permissions (Berechtigungen hinzufügen) aus.
-
Wählen Sie Inline-Richtlinie erstellen aus.
-
Geben Sie für Service Secrets Manager an und wählen Sie ihn aus.
-
Wählen Sie für Aktionen das Pfeilsymbol neben Berechtigungsverwaltung aus.
-
Wählen Sie PutResourcePolicy.
-
Wählen Sie für Ressourcen die Option Spezifisch aus.
-
Wählen Sie das Kontrollkästchen neben Alle in diesem Konto aus.
-
Wählen Sie Richtlinie prüfen.
-
Geben Sie für Name einen Namen an.
-
Wählen Sie Richtlinie erstellen aus.
Sie können Partitionen verwenden, um Ihre Daten schneller zu importieren. Mit Partitionen kann Data Wrangler die Daten parallel verarbeiten. Standardmäßig verwendet Data Wrangler 2 Partitionen. In den meisten Anwendungsfällen bieten Ihnen 2 Partitionen nahezu optimale Datenverarbeitungsgeschwindigkeiten.
Wenn Sie mehr als 2 Partitionen angeben möchten, können Sie auch eine Spalte angeben, um die Daten zu partitionieren. Die Werte in der Spalte müssen vom Typ „Numerisch“ oder „Datum“ sein.
Wir empfehlen, Partitionen nur dann zu verwenden, wenn Sie die Struktur der Daten und deren Verarbeitung kennen.
Sie können entweder den gesamten Datensatz importieren oder eine Stichprobe davon. Für eine Databricks-Datenbank werden die folgenden Optionen für die Probenahme angeboten:
-
Keine – Importiert den gesamten Datensatz.
-
Erstes K – Stichprobe der ersten K Zeilen des Datensatzes, wobei K eine von Ihnen angegebene Ganzzahl ist.
-
Randomisiert – Nimmt eine zufällige Stichprobe mit einer von Ihnen angegebenen Größe.
-
Stratifiziert – Entnimmt eine stratifizierte zufällige Stichprobe. Eine stratifizierte Stichprobe behält das Verhältnis der Werte in einer Spalte bei.
Gehen Sie wie folgt vor, um Ihre Daten aus einer Databricks-Datenbank zu importieren.
Gehen Sie wie folgt vor, um Daten aus Databricks zu importieren.
-
Melden Sie sich bei Amazon SageMaker AI Console
an. -
Wählen Sie Studio.
-
Wählen Sie App starten.
-
Wählen Sie von der Auswahlliste Studio aus.
-
Wählen Sie in Ihrem Data Wrangler-Ablauf auf der Registerkarte Daten importieren die Option Databricks aus.
-
Geben Sie die folgenden Felder an:
-
Datensatzname – Ein Name, den Sie für den Datensatz in Ihrem Data Wrangler-Ablauf verwenden möchten.
-
Treiber – com.simba.spark.jdbc.Driver.
-
JDBC-URL – Die URL der Databricks-Datenbank. Die URL-Formatierung kann zwischen den Databricks-Instances variieren. Informationen zum Auffinden der URL und zur Angabe der darin enthaltenen Parameter finden Sie unter JDBC-Konfiguration und Verbindungsparameter
. Im Folgenden finden Sie ein Beispiel dafür, wie eine URL formatiert werden kann: jdbc:spark://aws-sagemaker-datawrangler.cloud.databricks.com:443/default; transportMode=http; ssl=1; httpPath= /3122619508517275/0909-200301-cut318; =3; UID=; PWD=. sql/protocolv1/o AuthMech tokenpersonal-access-tokenAnmerkung
Sie können eine Secret-ARN angeben, die die JDBC-URL enthält, anstatt die JDBC-URL selbst anzugeben. Das Secret muss ein Schlüssel-Wert-Paar mit dem folgenden Format enthalten:
jdbcURL:. Weitere Informationen finden Sie unter Was ist der Secrets Manager?.JDBC-URL
-
-
Geben Sie eine SQL SELECT-Anweisung an.
Anmerkung
Data Wrangler unterstützt innerhalb einer Abfrage keine Common-Table-Expressions (CTE) oder temporäre Tabellen.
-
Wählen Sie für Probenahme eine Methode zur Probenahme aus.
-
Wählen Sie Ausführen aus.
-
(Optional) Wählen Sie für die VORSCHAU die Zahnräder, um die Partitionseinstellungen zu öffnen.
-
Geben Sie die Anzahl der Partitionen an. Sie können nach Spalten partitionieren, wenn Sie die Anzahl der Partitionen angeben:
-
Anzahl der Partitionen eingeben – Geben Sie einen Wert an, der größer als 2 ist.
-
(Optional) Partitionieren nach Spalten – Geben Sie die folgenden Felder an. Sie können nur dann nach einer Spalte partitionieren, wenn Sie einen Wert für Anzahl der Partitionen eingeben angegeben haben.
-
Spalte auswählen – Wählen Sie die Spalte aus, die Sie für die Datenpartition verwenden. Der Datentyp der Spalte muss ein numerisches oder ein Datumsformat haben.
-
Obergrenze – Aus den Werten in der Spalte, die Sie angegeben haben, ist die Obergrenze derjenige Wert, den Sie in der Partition verwenden. Der von Ihnen angegebene Wert ändert nichts an den Daten, die Sie importieren. Er wirkt sich nur auf die Geschwindigkeit des Imports aus. Um eine optimale Leistung zu erzielen, geben Sie eine Obergrenze an, die nahe am Maximum für die Spalte liegt.
-
Untergrenze – Aus den Werten in der Spalte, die Sie angegeben haben, ist die Untergrenze der Wert, den Sie in der Partition verwenden. Der von Ihnen angegebene Wert ändert nichts an den Daten, die Sie importieren. Er wirkt sich nur auf die Geschwindigkeit des Imports aus. Um eine optimale Leistung zu erzielen, geben Sie eine Untergrenze an, die nahe am Minimum für die Spalte liegt.
-
-
-
-
Wählen Sie Importieren aus.
Daten aus Salesforce Data Cloud importieren
Sie können Salesforce Data Cloud als Datenquelle in Amazon SageMaker Data Wrangler verwenden, um die Daten in Ihrer Salesforce Data Cloud für maschinelles Lernen vorzubereiten.
Mit Salesforce Data Cloud als Datenquelle in Data Wrangler können Sie schnell eine Verbindung zu Ihren Salesforce-Daten herstellen, ohne eine einzige Zeile Code schreiben zu müssen. Sie können Ihre Salesforce-Daten mit Daten aus jeder anderen Datenquelle in Data Wrangler zusammenführen.
Sobald Sie eine Verbindung mit der Data Cloud hergestellt haben, haben Sie folgende Optionen:
-
Ihre Daten mit integrierten Visualisierungen visualisieren
-
Die Daten verstehen und potenzielle Fehler und Extremwerte identifizieren
-
Die Daten mit mehr als 300 integrierten Transformationen transformieren
-
Die so transformierten Daten exportieren
Administrator-Einrichtung
Wichtig
Bevor Sie beginnen, stellen Sie sicher, dass Ihre Benutzer Amazon SageMaker Studio Classic Version 1.3.0 oder höher ausführen. Informationen zum Überprüfen und Aktualisieren der Version von Studio Classic finden Sie unterVorbereiten von ML-Daten mit Amazon SageMaker Data Wrangler.
Wenn Sie den Zugriff auf Salesforce Data Cloud einrichten, müssen Sie die folgenden Aufgaben ausführen:
-
Abrufen Ihrer Salesforce-Domain-URL. Salesforce bezieht sich auf die Domain-URL auch als URL Ihrer Organisation.
-
OAuth Anmeldeinformationen von Salesforce abrufen.
-
Abrufen der Autorisierungs-URL und der Token-URL für Ihre Salesforce-Domain.
-
Mit der OAuth Konfiguration ein AWS Secrets Manager Geheimnis erstellen.
-
Erstellen einer Lebenszykluskonfiguration, die Data Wrangler verwendet, um die Anmeldeinformationen aus dem Secret zu lesen.
-
Data Wrangler die Erlaubnis erteilen, das Secret zu lesen.
Nachdem Sie die vorherigen Aufgaben ausgeführt haben, können sich Ihre Benutzer mit Hilfe von bei der Salesforce Data Cloud anmelden OAuth.
Anmerkung
Ihre Benutzer stoßen ggf. auf Probleme, wenn Sie alles eingerichtet haben. Informationen zur Fehlerbehebung finden Sie unter Fehlerbehebung mit Salesforce.
Gehen Sie wie folgt vor, um die Domain-URL abzurufen.
-
Navigieren Sie zur Salesforce-Anmeldeseite.
-
Geben Sie für Schnellsuche Meine Domain an.
-
Kopieren Sie den Wert von Meine aktuelle Domain-URL in eine Textdatei.
-
Fügen Sie am Anfang der URL
https://hinzu.
Sobald Sie die Salesforce-Domain-URL erhalten haben, können Sie das folgende Verfahren verwenden, um die Anmeldeinformationen von Salesforce abzurufen und Data Wrangler den Zugriff auf Ihre Salesforce-Daten zu erlauben.
Gehen Sie wie folgt vor, um die Anmeldeinformationen von Salesforce abzurufen und Zugriff auf Data Wrangler zu gewähren.
-
Navigieren Sie zu Ihrer Salesforce-Domain-URL und melden Sie sich bei Ihrem Konto an.
-
Wählen Sie das Zahnradsymbol aus.
-
Geben Sie in der Suchleiste, die nun erscheintn App Manager an.
-
Wählen Sie Neue verbundene App aus.
-
Geben Sie die folgenden Felder an:
-
Name der verbundenen App – Sie können einen beliebigen Namen angeben. Wir empfehlen jedoch, einen Namen zu wählen, der Data Wrangler enthält. Sie können z. B. Salesforce Data Cloud Data Wrangler-Integration angeben.
-
API-Name – Verwenden Sie den Standardwert.
-
Kontakt-E-Mail – Geben Sie Ihre E-Mail-Adresse an.
-
Aktivieren Sie unter der API-Überschrift ( OAuth Einstellungen aktivieren) das Kontrollkästchen, um die OAuth Einstellungen zu aktivieren.
-
Geben Sie für Callback-URL die Amazon SageMaker Studio Classic-URL an. Um die URL für Studio Classic abzurufen, greifen Sie von der darauf zu AWS Management Console und kopieren Sie die URL.
-
-
Verschieben Sie unter Ausgewählte OAuth Bereiche Folgendes aus den verfügbaren Bereichen in Ausgewählte OAuth OAuth Bereiche:
-
Benutzerdaten verwalten über () APIs
api -
Anfragen jederzeit ausführen (
refresh_token,offline_access) -
Führen Sie ANSI-SQL-Abfragen für Salesforce Data Cloud-Daten durch (
cdp_query_api) -
Profildaten der Salesforce Customer Data Platform verwalten (
cdp_profile_api)
-
-
Wählen Sie Speichern. Wenn Sie Ihre Änderungen gespeichert haben, öffnet Salesforce eine neue Seite.
-
Klicken Sie auf Continue
-
Navigieren Sie zu Verbraucherschlüssel und Secret.
-
Wählen Sie Verbraucherdaten verwalten aus. Salesforce leitet Sie auf eine neue Seite weiter, auf der Sie ggf. die Zwei-Faktor-Authentifizierung passieren müssen.
-
Wichtig
Kopieren Sie den Verbraucherschlüssel und das Verbraucher-Secret in einen Texteditor. Diese Informationen brauchen Sie, um die Verbindung zwischen der Data Cloud und Data Wrangler herzustellen.
-
Navigieren Sie zurück zu Verbundene Apps verwalten.
-
Navigieren Sie zum Namen der verbundenen App und zum Namen Ihrer Anwendung.
-
Wählen Sie Manage (Verwalten).
-
Wählen Sie Richtlinien bearbeiten aus.
-
Ändern Sie IP-Lockerung in IP-Einschränkungen lockern.
-
Wählen Sie Speichern aus.
-
Wenn Sie den Zugriff auf Ihre Salesforce Data Cloud gewährt haben, müssen Sie noch Ihren Benutzern Berechtigungen erteilen. Gehen Sie wie folgt vor, um ihnen Berechtigungen zu erteilen.
Gehen Sie wie folgt vor, um Ihren Benutzern Berechtigungen zu erteilen.
-
Navigieren Sie zur Setup-Homepage.
-
Suchen Sie in der linken Navigationsleiste nach Benutzern und wählen Sie den Menüpunkt Benutzer aus.
-
Wählen Sie das Hyperlink mit Ihrem Benutzernamen.
-
Navigieren Sie zu Zuweisungen für den Berechtigungssatz.
-
Wählen Sie Zuweisungen bearbeiten.
-
Fügen Sie die folgenden Berechtigungen hinzu:
-
Administrator der Kundendatenplattform
-
Data-Aware-Spezialist für die Kundendatenplattform
-
-
Wählen Sie Speichern.
Nachdem Sie die Informationen für Ihre Salesforce-Domäne erhalten haben, müssen Sie die Autorisierungs-URL und die Token-URL für das AWS Secrets Manager Geheimnis abrufen, das Sie erstellen.
Gehen Sie wie folgt vor, um die Autorisierungs-URL und die Token-URL abzurufen.
Zum Abrufen der Autorisierungs-URL und der Token-URL
-
Navigieren Sie zu Ihrer Salesforce-Domain-URL.
-
Verwenden Sie eine der folgenden Methoden, um die zu erhalten URLs. Wenn Sie eine Linux-Distribution verwenden und
curlundjqinstalliert haben, empfehlen wir, die Methode zu verwenden, die nur unter Linux funktioniert.-
(Nur Linux) Geben Sie in Ihrem Terminal den folgenden Befehl an.
curlsalesforce-domain-URL/.well-known/openid-configuration | \ jq '. | { authorization_url: .authorization_endpoint, token_url: .token_endpoint }' | \ jq '. += { identity_provider: "SALESFORCE", client_id: "example-client-id", client_secret: "example-client-secret" }' -
-
Navigieren Sie
example-org-URL/.well-known/openid-configuration -
Kopieren Sie
authorization_endpointundtoken_endpointin einen Texteditor. -
Erstellen Sie das folgende JSON-Objekt:
{ "identity_provider": "SALESFORCE", "authorization_url": "example-authorization-endpoint", "token_url": "example-token-endpoint", "client_id": "example-consumer-key", "client_secret": "example-consumer-secret" }
-
-
Nachdem Sie das OAuth Konfigurationsobjekt erstellt haben, können Sie ein AWS Secrets Manager Geheimnis erstellen, in dem es gespeichert wird. Gehen Sie wie folgt vor, um das Secret zu erstellen.
Gehen Sie wie folgt vor, um ein Secret zu erstellen.
-
Navigieren Sie zur AWS Secrets Manager -Konsole
. -
Wählen Sie Secret speichern aus.
-
Wählen Sie Anderer Geheimnistyp aus.
-
Wählen Sie unter Schlüssel/Wert-Paare die Option Klartext aus.
-
Ersetzen Sie das leere JSON durch die folgenden Konfigurationseinstellungen.
{ "identity_provider": "SALESFORCE", "authorization_url": "example-authorization-endpoint", "token_url": "example-token-endpoint", "client_id": "example-consumer-key", "client_secret": "example-consumer-secret" } -
Wählen Sie Weiter aus.
-
Geben Sie unter Name des Secrets den Namen des Secrets an.
-
Wählen Sie unter Tags die Option Hinzufügen aus.
-
Geben Sie als Schlüssel sagemaker:partner an. Wir empfehlen, für Value einen Wert anzugeben, der für Ihren Anwendungsfall nützlich sein könnte. Sie können jedoch eine beliebige Angabe machen.
Wichtig
Sie müssen den Schlüssel erstellen. Sie können Ihre Daten nicht aus Salesforce importieren, wenn Sie sie nicht erstellen.
-
-
Wählen Sie Weiter aus.
-
Wählen Sie Store (Speichern) aus.
-
Wählen Sie das Secret aus, das Sie erstellt haben.
-
Notieren Sie sich die folgenden Felder:
-
Die Amazon Resource Number (ARN) des Secrets
-
Den Namen des Secrets
-
Wenn Sie das Geheimnis erstellt haben, müssen Sie Berechtigungen hinzufügen, damit Data Wrangler das Secret lesen kann. Gehen Sie wie folgt vor, um Berechtigungen hinzuzufügen.
Gehen Sie wie folgt vor, um Leseberechtigungen für Data Wrangler hinzuzufügen.
-
Navigieren Sie zur Amazon SageMaker AI-Konsole
. -
Wählen Sie Domains aus.
-
Wählen Sie die Domain aus, die Sie für den Zugriff auf Data Wrangler verwenden.
-
Wählen Sie Ihr Benutzerprofil aus.
-
Suchen Sie unter Details nach der Ausführungsrolle. Ihre ARN hat das folgende Format:
arn:aws:iam::111122223333:role/. Notieren Sie sich die SageMaker KI-Ausführungsrolle. Innerhalb der ARN geht es um alles nachexample-rolerole/. -
Navigieren Sie zur IAM-Konsole
. -
Geben Sie in der Suchleiste Search IAM den Namen der SageMaker AI-Ausführungsrolle an.
-
Wählen Sie die Rolle aus.
-
Wählen Sie Add permissions (Berechtigungen hinzufügen) aus.
-
Wählen Sie Inline-Richtlinie erstellen aus.
-
Wählen Sie den Tab JSON.
-
Geben Sie im Editor die folgende Richtlinie an.
-
Wählen Sie Review policy (Richtlinie überprüfen) aus.
-
Geben Sie für Name einen Namen an.
-
Wählen Sie Richtlinie erstellen aus.
Nachdem Sie Data Wrangler-Berechtigungen zum Lesen des Secrets erteilt haben, müssen Sie Ihrem Amazon SageMaker Studio Classic-Benutzerprofil eine Lifecycle-Konfiguration hinzufügen, die Ihr Secrets Manager-Geheimnis verwendet.
Gehen Sie wie folgt vor, um eine Lebenszykluskonfiguration zu erstellen und sie dem Studio Classic-Profil hinzuzufügen.
Gehen Sie wie folgt vor, um eine Lebenszykluskonfiguration zu erstellen und sie dem Studio Classic-Profil hinzuzufügen.
-
Navigieren Sie zur Amazon SageMaker AI-Konsole.
-
Wählen Sie Domains aus.
-
Wählen Sie die Domain aus, die Sie für den Zugriff auf Data Wrangler verwenden.
-
Wählen Sie Ihr Benutzerprofil aus.
-
Wenn Sie die folgenden Anwendungen sehen, löschen Sie sie:
-
KernelGateway
-
JupyterKernel
Anmerkung
Durch das Löschen der Anwendungen wird Studio Classic aktualisiert. Es kann eine Weile dauern, bis die Updates erfolgen.
-
-
Während Sie auf die Updates warten, wählen Sie Lebenszykluskonfigurationen aus.
-
Stellen Sie sicher, dass auf der Seite, auf der Sie sich befinden, Studio Classic Lifecycle-Konfigurationen steht.
-
Wählen Sie Create configuration (Konfiguration erstellen).
-
Achten Sie darauf, dass die Jupyter-Server-App ausgewählt wurde.
-
Wählen Sie Weiter.
-
Geben Sie für Name einen Namen für die Konfiguration an.
-
Geben Sie für Skripte das folgende Skript an:
#!/bin/bash set -eux cat > ~/.sfgenie_identity_provider_oauth_config <<EOL { "secret_arn": "secrets-arn-containing-salesforce-credentials" } EOL -
Wählen Sie Absenden aus.
-
Wählen Sie in der linken Navigationsleiste Domains aus.
-
Wählen Sie Ihre Domain aus.
-
Wählen Sie Environment (Umgebung) aus.
-
Wählen Sie unter Lebenszykluskonfigurationen für persönliche Studio Classic-Apps die Option Anhängen aus.
-
Wählen Sie Vorhandene Konfiguration aus.
-
Wählen Sie unter Studio Classic Lifecycle-Konfigurationen die von Ihnen erstellte Lebenszykluskonfiguration aus.
-
Wählen Sie An Domain anhängen aus.
-
Aktivieren Sie das Kontrollkästchen neben der Lebenszykluskonfiguration, die Sie angehängt haben.
-
Wählen Sie Als Standard festlegen aus.
Beim Einrichten Ihrer Lebenszykluskonfiguration können Probleme auftreten. Informationen zum Debuggen finden Sie unter Konfigurationen für den Debug-Lebenszyklus.
Leitfaden für Datenwissenschaftler
Gehen Sie wie folgt vor, um Salesforce Data Cloud mit Data Wrangler zu verbinden und von dort aus auf Ihre Daten zuzugreifen.
Wichtig
Ihr Administrator muss die Informationen in den vorangehenden Abschnitten verwenden, um Salesforce Data Cloud einzurichten. Wenn Probleme auftreten, wenden Sie sich an Ihren Administrator, um Hilfe bei der Fehlerbehebung zu erhalten.
Gehen Sie wie folgt vor, um Studio Classic zu öffnen und die Version zu überprüfen.
-
Gehen Sie wie unter beschrieben vorVoraussetzungen, um über Amazon SageMaker Studio Classic auf Data Wrangler zuzugreifen.
-
Wählen Sie neben dem Benutzer, den Sie zum Starten von Studio Classic verwenden möchten, die Option App starten aus.
-
Wählen Sie Studio.
Um in Data Wrangler einen Datensatz mit Daten aus der Salesforce Data Cloud zu erstellen
-
Melden Sie sich bei Amazon SageMaker AI Console
an. -
Wählen Sie Studio.
-
Wählen Sie App starten.
-
Wählen Sie in der Auswahlliste Studio aus.
-
Wählen Sie das Symbol Startseite aus.
-
Wählen Sie Datenaus.
-
Wählen Sie Data Wrangler.
-
Wählen Sie Daten importieren aus.
-
Wählen Sie unter Verfügbar die Option Salesforce Data Cloud aus.
-
Geben Sie unter Name der Verbindung einen Namen für Ihre Verbindung zur Salesforce Data Cloud an.
-
Geben Sie für Org URL die Organisations-URL in Ihrem Salesforce-Konto an. Die URL können Sie von Ihrem Administrator erhalten.
-
Wählen Sie Connect aus.
-
Geben Sie Ihre Anmeldeinformationen an, um sich bei Salesforce anzumelden.
Sie können mit der Erstellung eines Datensatzes mithilfe von Daten aus der Salesforce Data Cloud beginnen, sobald Sie eine Verbindung hergestellt haben.
Sobald Sie eine Tabelle ausgewählt haben, können Sie Abfragen schreiben und ausführen. Die Ausgabe zu Ihrer Abfrage wird unter Abfrageergebnisse angezeigt.
Wenn Sie sich für die Ausgabe zu Ihrer Abfrage entschieden haben, können Sie nun die Ausgabe zu Ihrer Abfrage in einen Data Wrangler-Ablauf importieren, um Datentransformationen durchzuführen.
Wenn Sie einen Datensatz erstellt haben, navigieren Sie zu dem Bildschirm Datenablauf, um mit der Transformation Ihrer Daten zu beginnen.
Importieren von Daten aus Snowflake
Sie können Snowflake als Datenquelle in Data Wrangler verwenden, um SageMaker Daten in Snowflake für maschinelles Lernen vorzubereiten.
Mit Snowflake als Datenquelle in Data Wrangler können Sie schnell eine Verbindung zu Snowflake herstellen, ohne eine einzige Zeile Code schreiben zu müssen. In Snowflake können Sie Ihre Daten mit Daten aus jeder anderen Datenquelle in Data Wrangler zusammenführen.
Sobald die Verbindung hergestellt ist, können Sie in Snowflake gespeicherte Daten interaktiv abfragen, mehr als 300 vorkonfigurierte Transformationen auf die Daten anwenden, Daten verstehen und potenzielle Fehler und Extremwerte mit einer Reihe robuster vorkonfigurierter Visualisierungsvorlagen identifizieren, schnell Inkonsistenzen in Ihrem Datenvorbereitungsworkflow erkennen und Probleme diagnostizieren, bevor Modelle in der Produktion eingesetzt werden. Schließlich können Sie Ihren Datenvorbereitungs-Workflow nach Amazon S3 exportieren, um ihn mit anderen SageMaker KI-Funktionen wie Amazon SageMaker Autopilot, Amazon SageMaker Feature Store und Amazon SageMaker Pipelines zu verwenden.
Sie können die Ausgabe Ihrer Abfragen mit einem von Ihnen erstellten AWS Key Management Service Schlüssel verschlüsseln. Weitere Informationen zu finden Sie AWS KMS unter AWS Key Management Service.
Administratorhandbuch
Wichtig
Weitere Informationen zur detaillierten Zugriffskontrolle und zu bewährten Methoden finden Sie unter Security Access Control
Dieser Abschnitt richtet sich an Snowflake-Administratoren, die den Zugriff auf Snowflake von Data Wrangler aus einrichten. SageMaker
Wichtig
Sie sind für die Verwaltung und Überwachung der Zugriffskontrolle in Snowflake verantwortlich. Data Wrangler fügt keine zusätzliche Zugriffskontrollebene für Snowflake hinzu.
Zur Zugriffskontrolle gehören u.a.:
-
Die Daten, auf die ein Benutzer zugreift
-
(Optional) Die Speicherintegration, mit deren Hilfe Snowflake Abfrageergebnisse in einen Amazon-S3-Bucket schreiben kann
-
Die Abfragen, die ein Benutzer ausführen kann
(Optional) Snowflake-Datenimportberechtigungen konfigurieren
Standardmäßig fragt Data Wrangler die Daten in Snowflake ab, ohne an einem Amazon S3-Standort eine Kopie davon zu erstellen. Verwenden Sie die folgenden Informationen, wenn Sie eine Speicherintegration in Snowflake konfigurieren. Ihre Benutzer können eine Speicherintegration verwenden, um ihre Abfrageergebnisse an einem Amazon S3-Standort zu speichern.
Ihre Benutzer haben ggf. unterschiedliche Zugriffsebenen für sensible Daten. Für eine optimale Sicherheit der Daten sollten Sie für jeden Benutzer eine eigene Speicherintegration anlegen. Für jede Speicherintegration sollte eine eigene Datenverwaltungsrichtlinie gelten.
Diese Funktion steht in den Opt-in-Regionen derzeit nicht zur Verfügung.
Snowflake benötigt die folgenden Berechtigungen für einen S3-Bucket und ein Verzeichnis, um auf Dateien im Verzeichnis zugreifen zu können:
-
s3:GetObject -
s3:GetObjectVersion -
s3:ListBucket -
s3:ListObjects -
s3:GetBucketLocation
Eine IAM-Richtlinie erstellen
Sie müssen eine IAM-Richtlinie erstellen, um Zugriffsberechtigungen für Snowflake zum Laden und Entladen von Daten aus einem Amazon-S3-Bucket zu konfigurieren.
Im Folgenden finden Sie das JSON-Richtliniendokument, das Sie zur Erstellung der Richtlinie verwenden:
# Example policy for S3 write access # This needs to be updated { "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Action": [ "s3:PutObject", "s3:GetObject", "s3:GetObjectVersion", "s3:DeleteObject", "s3:DeleteObjectVersion" ], "Resource": "arn:aws:s3:::bucket/prefix/*" }, { "Effect": "Allow", "Action": [ "s3:ListBucket" ], "Resource": "arn:aws:s3:::bucket/", "Condition": { "StringLike": { "s3:prefix": ["prefix/*"] } } } ] }
Informationen und Verfahren zum Erstellen von Richtlinien mit Richtliniendokumenten finden Sie unter IAM-Richtlinien erstellen.
Eine Dokumentation, die einen Überblick über die Verwendung von IAM-Berechtigungen mit Snowflake bietet, finden Sie in den folgenden Ressourcen:
Um der Snowflake-Rolle des Datenwissenschaftlers die Nutzungsberechtigung für die Speicherintegration zu erteilen, müssen Sie GRANT USAGE ON INTEGRATION
integration_name TO snowflake_role; ausführen.
-
integration_nameist der Name Ihrer Speicherintegration. -
snowflake_roleist der Name der Snowflake-Standardrolle, die dem Datenwissenschaftler als Benutzer zugewiesen wurde.
Snowflake Access einrichten OAuth
Anstatt Ihre Benutzer ihre Anmeldeinformationen direkt in Data Wrangler eingeben zu lassen, können Sie sie für den Zugriff auf Snowflake einen Identitätsanbieter verwenden lassen. Im Folgenden finden Sie Links zur Snowflake-Dokumentation für die von Data Wrangler unterstützten Identitätsanbieter.
Verwenden Sie die Dokumentation unter den obigen Links, um den Zugang zu Ihrem Identitätsanbieter einzurichten. Mit Hilfe der in diesem Abschnitt beschriebenen Informationen und Verfahren verstehen Sie leichter, wie Sie die Dokumentation für den Zugriff auf Snowflake in Data Wrangler richtig verwenden.
Ihr Identitätsanbieter muss Data Wrangler als Anwendung erkennen. Gehen Sie wie folgt vor, um Data Wrangler als Anwendung beim Identitätsanbieter zu registrieren:
-
Wählen Sie die Konfiguration aus, die den Registrierungsprozess für Data Wrangler als Anwendung startet.
-
Gewähren Sie den Benutzern innerhalb des Identitätsanbieters Zugriff auf Data Wrangler.
-
Aktivieren Sie die OAuth Client-Authentifizierung, indem Sie die Client-Anmeldeinformationen geheim speichern. AWS Secrets Manager
-
Geben Sie eine Umleitungs-URL im folgenden Format an: https://
domain-ID.studio.AWS-Region.sagemaker. aws/jupyter/default/labWichtig
Sie geben die Amazon SageMaker AI-Domain-ID an AWS-Region , die Sie zum Ausführen von Data Wrangler verwenden.
Wichtig
Sie müssen eine URL für jede Amazon SageMaker AI-Domain registrieren und für AWS-Region die Sie Data Wrangler ausführen. Benutzer aus einer Domain, für AWS-Region die keine Weiterleitung URLs eingerichtet ist, können sich nicht beim Identitätsanbieter authentifizieren, um auf die Snowflake-Verbindung zuzugreifen.
-
Vergewissern Sie sich, dass die Gewährungstypen für den Berechtigungscode und das Refresh-Token für die Anwendung Data Wrangler zulässig sind.
Innerhalb Ihres Identitätsanbieters müssen Sie einen Server einrichten, der OAuth Token auf Benutzerebene an Data Wrangler sendet. Der Server sendet die Token mit Snowflake als Zielgruppe.
Snowflake verwendet das Konzept von Rollen, bei denen es sich um unterschiedliche Rollen handelt, in denen die IAM-Rollen verwendet werden. AWS Sie müssen den Identitätsanbieter so konfigurieren, dass er eine beliebige Rolle verwendet, um die dem Snowflake-Konto zugeordnete Standardrolle zu verwenden. Wenn ein Benutzer z. B. systems administrator als Standardrolle in seinem Snowflake-Profil hat, wird für die Verbindung von Data Wrangler zu Snowflake systems administrator als Rolle verwendet.
Gehen Sie wie folgt vor, um den Server einzurichten.
Gehen Sie wie folgt vor, um den Server einzurichten. Sie arbeiten für alle außer dem letzten Schritte in Snowflake.
-
Beginnen Sie damit, den Server oder die API einzurichten.
-
Konfigurieren Sie den Autorisierungsserver so, dass er die Gewährungstypen Autorisierungscode und Aktualisierungstoken verwendet.
-
Geben Sie die Lebensdauer des Zugriffstokens an.
-
Legen Sie die Leerlaufzeitüberschreitung für das Aktualisierungstoken fest. Die Leerlaufzeitüberschreitung ist die Zeitdauer, nach der das Aktualisierungstoken abläuft, wenn es nicht verwendet wird.
Anmerkung
Wenn Sie Jobs in Data Wrangler planen, empfehlen wir, die Leerlaufzeitüberschreitung länger als die Häufigkeit des Verarbeitungsauftrags festzulegen. Andernfalls könnten manche Verarbeitungsaufträge fehlschlagen, weil das Aktualisierungstoken abgelaufen ist, bevor der Auftrag ausgeführt werden konnte. Wenn das Aktualisierungstoken abläuft, muss sich der Benutzer erneut authentifizieren, indem er auf die Verbindung zugreift, die er über Data Wrangler zu Snowflake hergestellt hat.
-
Geben Sie
session:role-anyals neuen Bereich an.Anmerkung
Kopieren Sie für Azure AD die eindeutige Kennung für den Bereich. Data Wrangler verlangt von Ihnen, dass Sie ihm die Kennung zur Verfügung stellen.
-
Wichtig
Aktivieren Sie in der externen OAuth Sicherheitsintegration für Snowflake die Option.
external_oauth_any_role_mode
Wichtig
Data Wrangler unterstützt keine rotierenden Aktualisierungstoken. Die Verwendung rotierender Aktualisierungstoken kann dazu führen, dass der Zugriff fehlschlägt oder der Benutzer sich häufig anmelden muss.
Wichtig
Wenn der Aktualisierungstoken abläuft, müssen sich Ihre Benutzer erneut authentifizieren, indem sie auf die Verbindung zugreifen, die sie über Data Wrangler zu Snowflake hergestellt haben.
Nachdem Sie den OAuth Anbieter eingerichtet haben, stellen Sie Data Wrangler die Informationen zur Verfügung, die für die Verbindung mit dem Anbieter erforderlich sind. Sie können die Dokumentation Ihres Identitätsanbieters verwenden, um Werte für die folgenden Felder abzurufen:
-
Token-URL – Die URL des Tokens, das der Identitätsanbieter an Data Wrangler sendet.
-
Autorisierungs-URL – Die URL des Autorisierungsservers des Identitätsanbieters.
-
Client-ID – Die ID des Identitätsanbieters.
-
Client-Secret – Das Secret, das nur der Autorisierungsserver oder die API erkennen.
-
(Nur Azure AD) Die OAuth Bereichsanmeldedaten, die Sie kopiert haben.
Sie speichern die Felder und Werte in einem AWS Secrets Manager Geheimnis und fügen es der Amazon SageMaker Studio Classic-Lebenszykluskonfiguration hinzu, die Sie für Data Wrangler verwenden. Eine Lebenszykluskonfiguration ist ein Shell-Skript. Damit können Sie Data Wrangler den Amazon Resource Name (ARN) des Secrets zugänglich zu machen. Informationen zum Erstellen von Geheimnissen finden Sie unter Hartcodierte Geheimnisse verschieben nach. AWS Secrets Manager Informationen zur Verwendung von Lebenszykluskonfigurationen in Studio Classic finden Sie unterVerwenden Sie Lebenszykluskonfigurationen, um Studio Classic anzupassen.
Wichtig
Bevor Sie ein Secrets Manager-Geheimnis erstellen, stellen Sie sicher, dass die SageMaker AI-Ausführungsrolle, die Sie für Amazon SageMaker Studio Classic verwenden, über Berechtigungen zum Erstellen und Aktualisieren von Geheimnissen in Secrets Manager verfügt. Weitere Informationen zum Hinzufügen von Berechtigungen finden Sie unter Beispiel: Berechtigung zum Erstellen von Secrets.
Für Okta und Ping Federate ist das folgende das Format des Secrets:
{ "token_url":"https://identityprovider.com/oauth2/example-portion-of-URL-path/v2/token", "client_id":"example-client-id", "client_secret":"example-client-secret", "identity_provider":"OKTA"|"PING_FEDERATE", "authorization_url":"https://identityprovider.com/oauth2/example-portion-of-URL-path/v2/authorize" }
Für Azure AD ist das folgende Format für das Secret vorgesehen:
{ "token_url":"https://identityprovider.com/oauth2/example-portion-of-URL-path/v2/token", "client_id":"example-client-id", "client_secret":"example-client-secret", "identity_provider":"AZURE_AD", "authorization_url":"https://identityprovider.com/oauth2/example-portion-of-URL-path/v2/authorize", "datasource_oauth_scope":"api://appuri/session:role-any)" }
Sie müssen über eine Lebenszykluskonfiguration verfügen, die das Secrets-Manager-Secret verwendet, das Sie erstellt haben. Sie können entweder die Lebenszykluskonfiguration erstellen oder eine bereits erstellte ändern. Die Konfiguration muss das folgende Skript verwenden.
#!/bin/bash set -eux ## Script Body cat > ~/.snowflake_identity_provider_oauth_config <<EOL { "secret_arn": "example-secret-arn" } EOL
Informationen zur Einrichtung von Lebenszykluskonfigurationen finden Sie unter Erstellen und Zuordnen einer Lebenszykluskonfiguration. Gehen Sie beim Einrichten wie folgt vor:
-
Stellen Sie den Anwendungstyp der Konfiguration auf
Jupyter Serverein. -
Hängen Sie die Konfiguration an die Amazon SageMaker AI-Domain an, die Ihre Benutzer hat.
-
Lassen Sie die Konfiguration standardmäßig ausführen. Sie muss jedes Mal ausgeführt werden, wenn sich ein Benutzer bei Studio Classic anmeldet. Andernfalls sind die in der Konfiguration gespeicherten Anmeldeinformationen für Ihre Benutzer nicht verfügbar, wenn sie Data Wrangler verwenden.
-
Die Lebenszykluskonfiguration erstellt eine Datei mit dem Namen
snowflake_identity_provider_oauth_configim Home-Ordner des Benutzers. Die Datei enthält das Secrets-Manager-Secret. Vergewissern Sie sich, dass es sich bei jeder Initialisierung der Jupyter Server-Instance im Home-Ordner des Benutzers befindet.
Private Konnektivität zwischen Data Wrangler und Snowflake über AWS PrivateLink
In diesem Abschnitt wird erklärt, wie Sie AWS PrivateLink eine private Verbindung zwischen Data Wrangler und Snowflake herstellen können. Die einzelnen Schritte werden in den folgenden Abschnitten erläutert.
Erstellen einer VPC
Wenn Sie keine VPC eingerichtet haben, folgen Sie den Anweisungen unter Neue VPC erstellen, um eine zu erstellen.
Sobald Sie eine VPC ausgewählt haben, die Sie zur Herstellung einer privaten Verbindung verwenden möchten, geben Sie Ihrem Snowflake-Administrator die folgenden Anmeldeinformationen zur Aktivierung an AWS PrivateLink:
-
VPC-ID
-
AWS Konto-ID
-
Ihre entsprechende Konto-URL, mit der Sie auf Snowflake zugreifen
Wichtig
Wie in der Snowflake-Dokumentation beschrieben, kann die Aktivierung Ihres Snowflake-Kontos bis zu zwei Werktage dauern.
Snowflake AWS PrivateLink -Integration einrichten
Rufen Sie nach AWS PrivateLink der Aktivierung die AWS PrivateLink Konfiguration für Ihre Region ab, indem Sie den folgenden Befehl in einem Snowflake-Arbeitsblatt ausführen. Melden Sie sich bei Ihrer Snowflake-Konsole an und geben Sie unter Arbeitsblätter Folgendes ein: select
SYSTEM$GET_PRIVATELINK_CONFIG();
-
Rufen Sie die Werte für Folgendes ab:
privatelink-account-name,privatelink_ocsp-url,privatelink-account-urlundprivatelink_ocsp-urlaus dem resultierenden JSON-Objekt. Beispiele für jeden dieser Werte sind im folgenden Ausschnitt gezeigt. Speichern Sie diese Werte zur späteren Verwendung.privatelink-account-name: xxxxxxxx.region.privatelink privatelink-vpce-id: com.amazonaws.vpce.region.vpce-svc-xxxxxxxxxxxxxxxxx privatelink-account-url: xxxxxxxx.region.privatelink.snowflakecomputing.com privatelink_ocsp-url: ocsp.xxxxxxxx.region.privatelink.snowflakecomputing.com -
Wechseln Sie zu Ihrer AWS Konsole und navigieren Sie zum VPC-Menü.
-
Wählen Sie im linken Bereich das Link Endpunkte aus, um zur Einrichtung der VPC-Endpunkte zu gelangen.
Wählen Sie dort Endpunkt erstellen aus.
-
Wählen Sie die Optionsschaltfläche für Dienst nach Name suchen aus, wie im folgenden Screenshot gezeigt.
-
Fügen Sie im Feld Dienstname den Wert für
privatelink-vpce-id, den Sie im vorangehenden Schritt abgerufen haben, und wählen Sie Überprüfen aus.Wenn die Verbindung erfolgreich ist, erscheint auf Ihrem Bildschirm eine grüne Warnung mit der Meldung Dienstname gefunden, und die Optionen für VPC und Subnetz werden automatisch erweitert, wie im folgenden Screenshot gezeigt. Je nach Ihrer Zielregion wird auf dem dann angezeigten Bildschirm ggf. der Name einer anderen AWS -Region angezeigt.

-
Wählen Sie dieselbe VPC-ID, die Sie an Snowflake gesendet haben, von der Auswahlliste VPC aus.
-
Wenn Sie noch kein Subnetz erstellt haben, folgen Sie den folgenden Anweisungen zum Erstellen eines Subnetzes.
-
Wählen Sie Subnetze von der Auswahlliste VPC aus. Wählen Sie dann Subnetz erstellen aus und folgen Sie den Anweisungen, um in Ihrer VPC eine Teilmenge zu erstellen. Achten Sie darauf, dass Sie auch diejenige VPC-ID auswählen, die Sie an Snowflake gesendet haben.
-
Wählen Sie unter Konfiguration von Sicherheitsgruppen die Option Neue Sicherheitsgruppe erstellen aus, um das Standardfenster für Sicherheitsgruppen auf einer neuen Registerkarte zu öffnen. Wählen Sie auf dieser neuen Registerkarte die Option Sicherheitsgruppe erstellen aus.
-
Geben Sie einen Namen für die neue Sicherheitsgruppe (z. B.
datawrangler-doc-snowflake-privatelink-connection) und eine Beschreibung ein. Achten Sie darauf, die VPC-ID auszuwählen, die Sie in den vorangehenden Schritten verwendet haben. -
Fügen Sie zwei Regeln hinzu, um Datenverkehr von innerhalb Ihrer VPC zu diesem VPC-Endpunkt zuzulassen.
Navigieren Sie auf einer separaten Registerkarte zu Ihrer VPCs VPC und rufen Sie Ihren CIDR-Block für Ihre VPC ab. Wählen Sie dann im Abschnitt Regeln für eingehenden Datenverkehr die Option Regel hinzufügen aus. Wählen Sie als Typ
HTTPSaus, belassen Sie im Formular Quelle als Benutzerdefiniert und fügen Sie den beim vorangehendendescribe-vpcsAufruf abgerufenen Wert ein (z. B.10.0.0.0/16). -
Wählen Sie Sicherheitsgruppen erstellen aus. Rufen Sie die ID der Sicherheitsgruppe aus der neu erstellten Sicherheitsgruppe ab (z. B.
sg-xxxxxxxxxxxxxxxxx). -
Entfernen Sie im Konfigurationsbildschirm VPC-Endpunkte die Standardsicherheitsgruppe. Fügen Sie die ID der Sicherheitsgruppe in das Suchfeld ein und aktivieren Sie das Kontrollkästchen.

-
Wählen Sie Endpunkt erstellen aus.
-
Wenn die Endpunkterstellung erfolgreich ist, sehen Sie eine Seite mit einem Link zur Konfiguration Ihres VPC-Endpunktes, die durch die VPC-ID angegeben ist. Wählen Sie das Link aus, damit die gesamte Konfiguration angezeigt wird.
Rufen Sie den obersten Eintrag auf der Liste mit den DNS-Namen ab. Dieser Name kann von anderen DNS-Namen unterschieden werden, da er nur den Namen der Region (z. B.
us-west-2) und keine Bezeichnung mit einem Buchstaben für die Availability Zone (z. B.us-west-2a) enthält. Speichern Sie diese Informationen zur späteren Verwendung.
DNS für Snowflake-Endpunkte in Ihrer VPC konfigurieren
In diesem Abschnitt wird erklärt, wie DNS für Snowflake-Endpunkte in Ihrer VPC konfiguriert werden. Damit kann Ihre VPC Anfragen an den AWS PrivateLink Snowflake-Endpunkt auflösen.
-
Navigieren Sie in Ihrer AWS Konsole zum Route 53 53-Menü
. -
Wählen Sie die Option Gehostete Zonen (erweitern Sie ggf. links das Menü, um diese Option zu finden).
-
Wählen Sie Create Hosted Zone.
-
Schauen Sie im Feld Domainname den Wert nach, der in den vorangehenden Schritten für
privatelink-account-urlgespeichert wurde. In diesem Feld wird Ihre Snowflake-Konto-ID aus dem DNS-Namen entfernt und es wird nur der Wert verwendet, der mit der Regionskennung beginnt. Später wird auch ein Resource Record Set für die Subdomain erstellt, z. B.region.privatelink.snowflakecomputing.com -
Wählen Sie die Optionsschaltfläche für Private Hosted Zone im Abschnitt Typ aus. Der Code für Ihre Region ist ggf. nicht
us-west-2. Schauen Sie den DNS-Namen nach, den Sie von Snowflake erhalten haben.
-
Wählen Sie im VPCs Abschnitt Mit der gehosteten Zone verknüpfen die Region aus, in der sich Ihre VPC befindet, und die VPC-ID, die Sie in den vorherigen Schritten verwendet haben.
-
Wählen Sie Erstellte gehostete Zone.
-
-
Erstellen Sie als Nächstes zwei Datensätze, einen für
privatelink-account-urlund einen fürprivatelink_ocsp-url.-
Wählen Sie im Menü Hosted Zone die Option Datensätze erstellen aus.
-
Geben Sie unter Datensatzname nur Ihre Snowflake-Konto-ID ein (die ersten 8 Zeichen in
privatelink-account-url). -
Wählen Sie unter Datensatztyp die Option CNAME aus.
-
Geben Sie unter Wert den DNS-Namen für den regionalen VPC-Endpunkt ein, den Sie im letzten Schritt im Abschnitt Snowflake-Integration für AWS PrivateLink einrichten abgerufen haben.

-
Wählen Sie Create records (Datensätze erstellen).
-
Wiederholen Sie die vorangehenden Schritte für den OCSP-Datensatz, den wir als
privatelink-ocsp-urlwir notiert haben, beginnend mitocspbis zu der 8-stelligen Snowflake-ID für den Datensatznamen (z. B.ocsp.xxxxxxxx).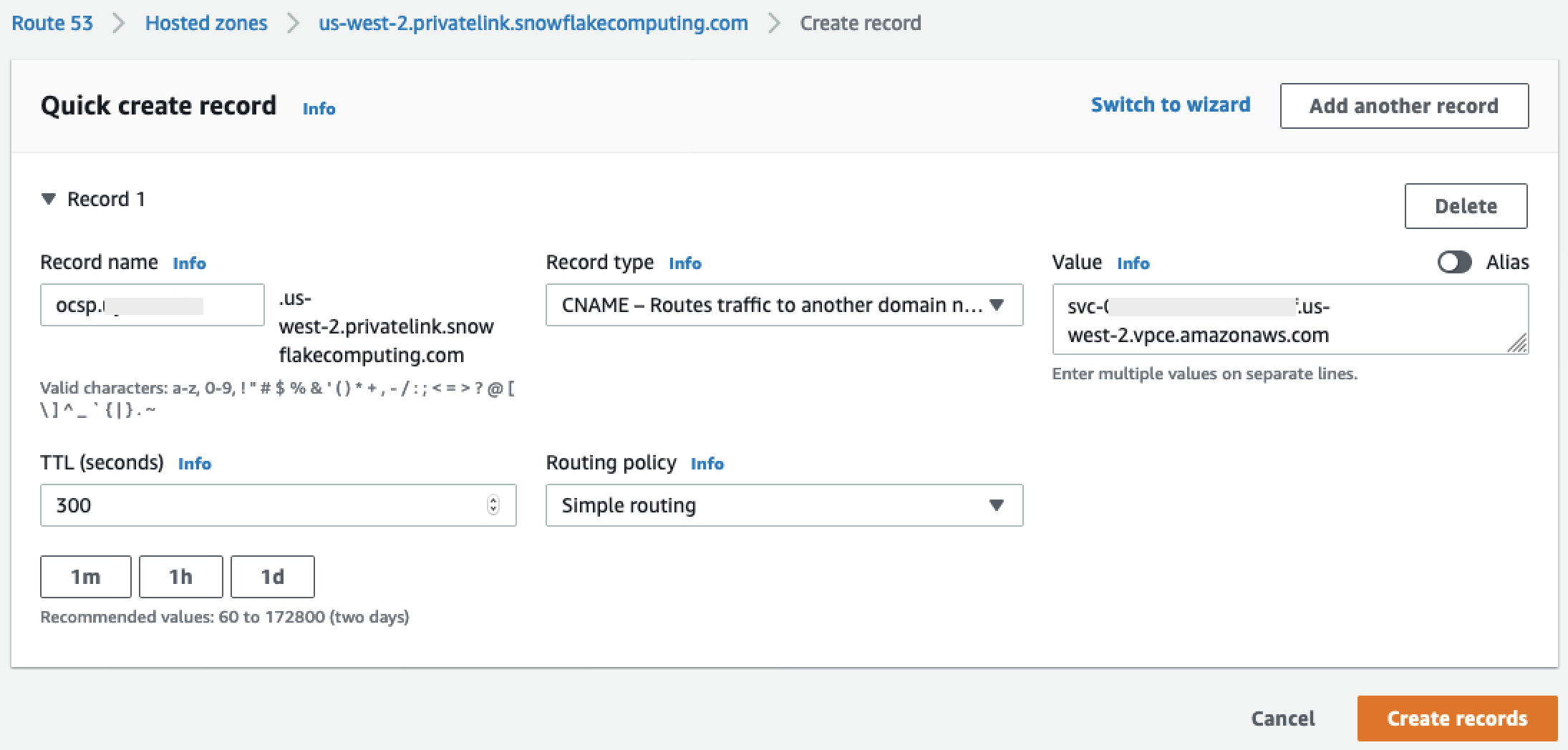
-
-
Konfigurieren Sie Route 53 Resolver Endpunkt für eingehenden Datenverkehr für Ihre VPC
In diesem Abschnitt wird erklärt, wie die Endpunkte für eingehenden Datenverkehr von Route 53 Resolvern für Ihre VPC konfiguriert werden.
-
Navigieren Sie in Ihrer AWS Konsole zum Route 53 53-Menü
. -
Wählen Sie links im Bereich Sicherheit die Option Sicherheitsgruppen aus.
-
-
Wählen Sie Sicherheitsgruppen erstellen aus.
-
Geben Sie einen Namen für Ihre Sicherheitsgruppe (z. B.
datawranger-doc-route53-resolver-sg) und eine Beschreibung ein. -
Wählen Sie die in den vorangehenden Schritten verwendete VPC-ID aus.
-
Erstellen Sie Regeln, die von innerhalb des VPC-CIDR-Blocks DNS über UDP und TCP zulassen.

-
Wählen Sie Sicherheitsgruppen erstellen aus. Notieren Sie sich die Sicherheitsgruppen-ID, da eine Regel hinzugefügt wird, die den Datenverkehr zur Sicherheitsgruppe des VPC-Endpunktes zulässt.
-
-
Navigieren Sie in Ihrer AWS Konsole zum Route 53 53-Menü
. -
Wählen Sie im Bereich Resolver die Option Endpunkt für eingehenden Datenverkehr aus.
-
-
Wählen Sie Endpunkt für eingehenden Datenverkehr erstellen aus.
-
Geben Sie einen Namen für den Endpunkt ein.
-
Wählen Sie von der Auswahlliste VPC in der Region die VPC-ID aus, die Sie in allen vorangehenden Schritten verwendet haben.
-
Wählen Sie von der Auswahlliste Sicherheitsgruppe für diesen Endpunkt die Sicherheitsgruppen-ID aus Schritt 2 in diesem Abschnitt aus.

-
Wählen Sie im Abschnitt IP-Adresse eine Availability Zones aus, wählen Sie ein Subnetz aus und lassen Sie für jede IP-Adresse die Optionsschaltfläche für Automatisch ausgewählte IP-Adresse verwende ausgewählt.
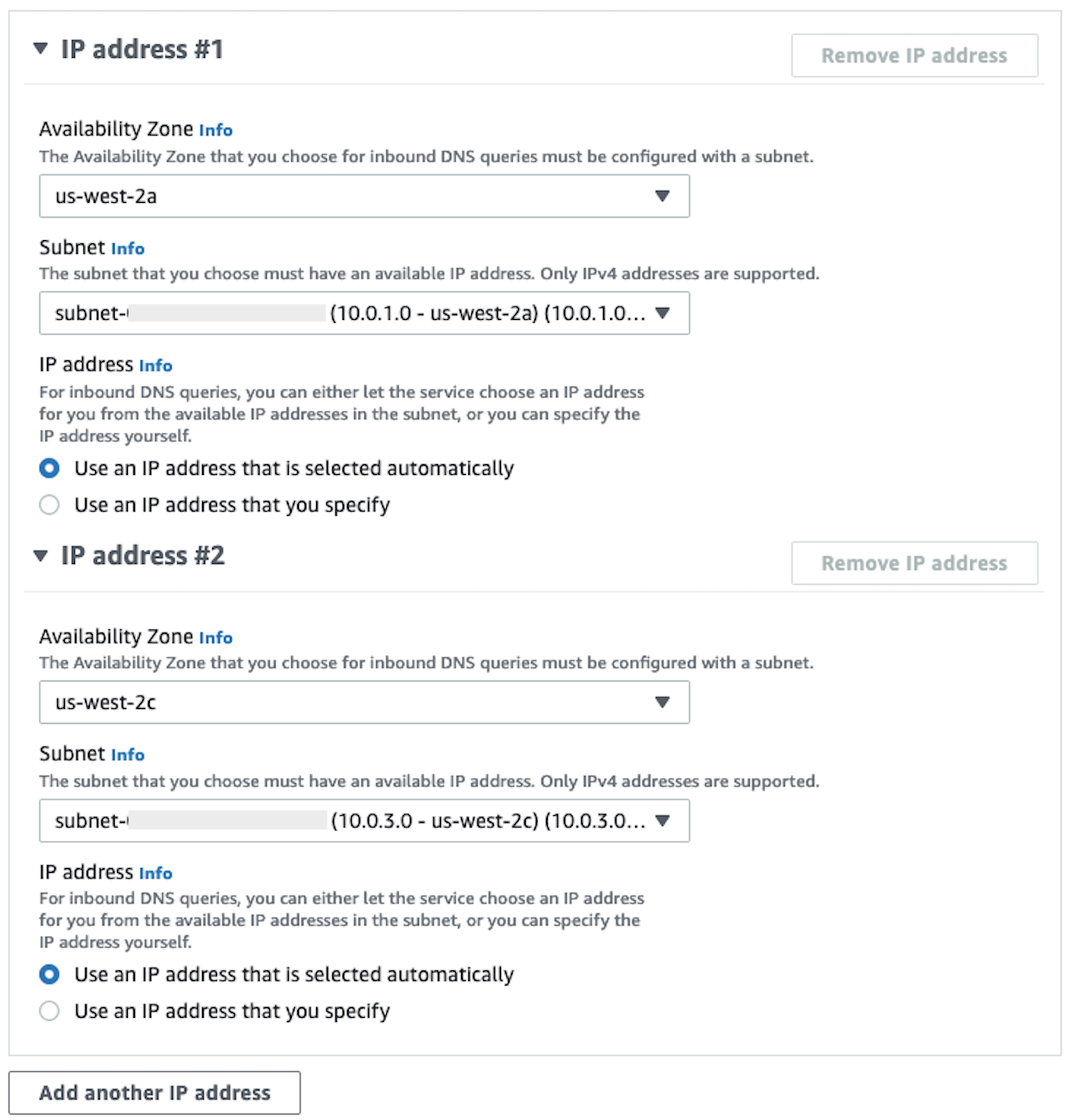
-
Wählen Sie Absenden aus.
-
-
Wählen Sie den Endpunkt für eingehenden Datenverkehr aus, sobald dieser erstellt wurde.
-
Sobald der Endpunkt für eingehenden Datenverkehr erstellt wurde, notieren Sie sich die beiden IP-Adressen für die Resolver.

SageMaker KI VPC-Endpunkte
In diesem Abschnitt wird erklärt, wie Sie VPC-Endpoints für Folgendes erstellen: Amazon SageMaker Studio Classic, SageMaker Notebooks, die SageMaker API, SageMaker Runtime Runtime und Amazon SageMaker Feature Store Runtime.
Eine Sicherheitsgruppe erstellen, die auf alle Endgeräte angewendet wird.
-
Navigieren Sie zum EC2 Menü
in der AWS Konsole. -
Wählen Sie im Bereich Netzwerk und Sicherheit die Option Sicherheitsgruppen aus.
-
Wählen Sie Sicherheitsgruppe erstellen aus.
-
Geben Sie einen Namen und eine Beschreibung für die Sicherheitsgruppe an (z. B.
datawrangler-doc-sagemaker-vpce-sg). Später wird eine Regel hinzugefügt, um Traffic über HTTPS von SageMaker KI zu dieser Gruppe zuzulassen.
Endpunkte erstellen
-
Navigieren Sie in der AWS Konsole zum VPC-Menü
. -
Wählen Sie die Option Endpunkte aus.
-
Klicken Sie auf Create Endpunkt (Endpunkt erstellen).
-
Suchen Sie nach dem Dienst, indem Sie dessen Namen in das Feld Suchen eingeben.
-
Wählen Sie aus der VPC-Dropdownliste die VPC aus, in der Ihre AWS PrivateLink Snowflake-Verbindung besteht.
-
Wählen Sie im Abschnitt Subnetze die Subnetze aus, die Zugriff auf die Snowflake-Verbindung haben. PrivateLink
-
Lassen Sie das Kontrollkästchen DNS-Namen aktivieren aktiviert.
-
Wählen Sie im Abschnitt Sicherheitsgruppen die Sicherheitsgruppe aus, die Sie im vorangehenden Abschnitt erstellt haben.
-
Klicken Sie auf Endpunkt erstellen.
Konfigurieren Sie Studio Classic und Data Wrangler
In diesem Abschnitt wird erklärt, wie Studio Classic und Data Wrangler konfiguriert werden.
-
Sicherheitsgruppe konfigurieren.
-
Navigieren Sie in der AWS Konsole zum EC2 Amazon-Menü.
-
Wählen Sie im Bereich Netzwerk und Sicherheit die Option Sicherheitsgruppen aus.
-
Wählen Sie Sicherheitsgruppen erstellen aus.
-
Geben Sie einen Namen und eine Beschreibung für Ihre Sicherheitsgruppe an (z. B.
datawrangler-doc-sagemaker-studio). -
Erstellen Sie die folgenden Regeln für eingehenden Datenverkehr.
-
Die HTTPS-Verbindung zu der Sicherheitsgruppe, die Sie für die PrivateLink Snowflake-Verbindung bereitgestellt haben, die Sie im Schritt PrivateLink Snowflake-Integration einrichten erstellt haben.
-
Die HTTP-Verbindung zu der Sicherheitsgruppe, die Sie für die PrivateLink Snowflake-Verbindung bereitgestellt haben, die Sie im Schritt Snowflake-Integration einrichten erstellt haben. PrivateLink
-
Die Sicherheitsgruppe für UDP und TCP für DNS (Port 53) zum Route 53 Resolver-Endpunkt für eingehenden Datenverkehr, die Sie in Schritt 2 von Route 53 Resolver Endpunkt für eingehenden Datenverkehr konfigurieren für Ihre VPC erstellen.
-
-
Wählen Sie unten rechts in der Ecke die Schaltfläche Sicherheitsgruppe erstellen.
-
-
Konfigurieren Sie Studio Classic.
-
Navigieren Sie in der AWS Konsole zum SageMaker AI-Menü.
-
Wählen Sie auf der linken Konsole die Option SageMaker AI Studio Classic aus.
-
Wenn Sie keine Domains konfiguriert haben, wird das Menü Erste Schritte angezeigt.
-
Wählen Sie im Menü Erste Schritte die Option Standardeinrichtung aus.
-
Wählen Sie unter Authentifizierungsmethode die Option AWS Identity and Access Management (IAM).
-
Im Menü Berechtigungen können Sie je nach Anwendungsfall eine neue Rolle erstellen oder eine bereits vorhandene Rolle verwenden.
-
Wenn Sie Neue Rolle erstellen wählen, erhalten Sie die Option, einen S3-Bucket-Namen anzugeben. Außerdem wird eine Richtlinie für Sie erzeugt.
-
Wenn Sie bereits eine Rolle mit Berechtigungen für die S3-Buckets erstellt haben, auf die Sie Zugriff benötigen, wählen Sie die Rolle von der Auswahlliste aus. Dieser Rolle sollte die Richtlinie
AmazonSageMakerFullAccessangefügt werden.
-
-
Wählen Sie die Dropdownliste Netzwerk und Speicher aus, um die VPC, Sicherheit und Subnetze SageMaker zu konfigurieren, die AI verwendet.
-
Wählen Sie unter VPC die VPC aus, in der Ihre PrivateLink Snowflake-Verbindung besteht.
-
Wählen Sie unter Subnetz (e) die Subnetze aus, die Zugriff auf die Snowflake-Verbindung haben. PrivateLink
-
Wählen Sie unter Netzwerkzugriff für Studio Classic die Option Nur VPC aus.
-
Wählen Sie unter Sicherheitsgruppe(n) die Sicherheitsgruppe aus, die Sie in Schritt 1 erstellt haben.
-
-
Wählen Sie Absenden aus.
-
-
Bearbeiten Sie die SageMaker AI-Sicherheitsgruppe.
-
Erstellen Sie die folgenden Regeln für eingehenden Datenverkehr:
-
Port 2049 zu den eingehenden und ausgehenden NFS-Sicherheitsgruppen, die von SageMaker AI in Schritt 2 automatisch erstellt wurden (die Namen der Sicherheitsgruppen enthalten die Studio Classic-Domänen-ID).
-
Zugriff auf alle TCP-Ports zu sich selbst (nur für SageMaker AI for VPC erforderlich).
-
-
-
VPC-Endpunkt-Sicherheitsgruppen bearbeiten:
-
Navigieren Sie in der AWS Konsole zum EC2 Amazon-Menü.
-
Suchen Sie die Sicherheitsgruppe, die Sie in einem vorangehenden Schritt erstellt haben.
-
Fügen Sie eine Regel für eingehenden Datenverkehr hinzu, nach der HTTPS-Datenverkehr von der in Schritt 1 erstellten Sicherheitsgruppe zulässig ist.
-
-
Benutzerprofil erstellen.
-
Wählen Sie im SageMaker Studio Classic Control Panel die Option Benutzer hinzufügen.
-
Geben Sie einen Benutzernamen an.
-
Wählen Sie für die Ausführungsrolle aus, ob Sie eine neue Rolle erstellen oder eine bereits vorhandene Rolle verwenden möchten.
-
Wenn Sie Neue Rolle erstellen auswählen, erhalten Sie die Option, einen Amazon-S3-Bucket-Namen anzugeben, und es wird eine Richtlinie für Sie erzeugt.
-
Wenn Sie bereits eine Rolle mit Berechtigungen für die Amazon-S3-Buckets erstellt haben, auf die Sie Zugriff benötigen, wählen Sie die Rolle von der Auswahlliste aus. Dieser Rolle sollte die Richtlinie
AmazonSageMakerFullAccessangefügt werden.
-
-
Wählen Sie Absenden aus.
-
-
Erstellen Sie einen Datenablauf (folgen Sie hierzu dem Leitfaden für Datenwissenschaftler, der in einem vorangehenden Abschnitt beschrieben wurde).
-
Geben Sie beim Hinzufügen einer Snowflake-Verbindung anstelle des einfachen Snowflake-Kontonamens den Wert von
privatelink-account-name(aus dem Schritt PrivateLinkSnowflake-Integration einrichten) in das Feld Snowflake-Kontoname (alphanumerisch) ein. Alles andere bleibt unverändert.
-
Informationen für den Datenwissenschaftler zur Verfügung stellen
Stellen Sie dem Datenwissenschaftler die Informationen zur Verfügung, die er für den Zugriff auf Snowflake von Amazon SageMaker AI Data Wrangler aus benötigt.
Wichtig
Ihre Benutzer müssen Amazon SageMaker Studio Classic Version 1.3.0 oder höher ausführen. Informationen zum Überprüfen und Aktualisieren der Version von Studio Classic finden Sie unterVorbereiten von ML-Daten mit Amazon SageMaker Data Wrangler.
-
Damit Ihr Datenwissenschaftler von SageMaker Data Wrangler aus auf Snowflake zugreifen kann, stellen Sie ihm eine der folgenden Informationen zur Verfügung:
-
Für die Basisauthentifizierung einen Snowflake-Kontonamen, einen Benutzernamen und ein Passwort.
-
Für OAuth, einen Benutzernamen und ein Passwort im Identity Provider.
-
Für ARN, das Secrets-Manager-Secret Amazon Resource Name (ARN).
-
Ein Secret, das mit AWS Secrets Manager und dem ARN des Secrets erstellt wurde. Gehen Sie wie folgt vor, um das Secret für Snowflake zu erstellen, wenn Sie diese Option wählen.
Wichtig
Wenn Ihre Datenwissenschaftler die Option Snowflake-Anmeldeinformationen (Benutzername und Passwort) verwenden, um eine Verbindung zu Snowflake herzustellen, können Sie die Anmeldeinformationen mit Secrets Manager in einem Secret speichern. Secrets Manager rotiert Secrets im Rahmen eines auf bewährten Methoden basierenden Sicherheitsplans. Auf das im Secrets Manager erstellte Geheimnis kann nur zugegriffen werden, wenn die Studio Classic-Rolle konfiguriert ist, wenn Sie ein Studio Classic-Benutzerprofil einrichten. Dazu müssen Sie diese Berechtigung zu der Richtlinie hinzufügen
secretsmanager:PutResourcePolicy, die Ihrer Studio Classic-Rolle zugeordnet ist.Es wird dringend empfohlen, die Rollenrichtlinie so zu gestalten, dass unterschiedliche Rollen für verschiedene Gruppen von Studio Classic-Benutzern verwendet werden. Sie können weitere ressourcenbasierte Berechtigungen für die Secrets-Manager-Secrets hinzufügen. Bedingungsschlüssel, die Sie verwenden können, finden Sie unter Secret Policy verwalten.
Informationen dazu, wie Sie ein Secret erstellen können, finden Sie unter Secret erstellen. Die von Ihnen erstellten Secrets werden Ihnen in Rechnung gestellt.
-
-
(Optional) Teilen Sie dem Datenwissenschaftler den Namen der Speicherintegration mit, die Sie mithilfe des Verfahrens Cloud-Speicherintegration in Snowflake erstellen
erstellt haben. Dies ist der Name der neuen Integration und wird integration_namein dem von Ihnen ausgeführtenCREATE INTEGRATIONSQL-Befehl aufgerufen, der im folgenden Codeausschnitt dargestellt ist:CREATE STORAGE INTEGRATION integration_name TYPE = EXTERNAL_STAGE STORAGE_PROVIDER = S3 ENABLED = TRUE STORAGE_AWS_ROLE_ARN = 'iam_role' [ STORAGE_AWS_OBJECT_ACL = 'bucket-owner-full-control' ] STORAGE_ALLOWED_LOCATIONS = ('s3://bucket/path/', 's3://bucket/path/') [ STORAGE_BLOCKED_LOCATIONS = ('s3://bucket/path/', 's3://bucket/path/') ]
Leitfaden für Datenwissenschaftler
Gehen Sie wie folgt vor, um Snowflake zu verbinden und in Data Wrangler auf Ihre Daten zuzugreifen.
Wichtig
Ihr Administrator muss die Informationen in den vorangehenden Abschnitten verwenden, um Snowflake einzurichten. Wenn Sie Probleme auftreten, wenden Sie sich an Ihren Administrator, um Hilfe bei der Fehlerbehebung zu erhalten.
Eine Verbindung zu Snowflake können Sie wie folgt herstellen:
-
Geben Sie Ihre Snowflake-Anmeldeinformationen (Kontoname, Benutzername und Passwort) in Data Wrangler an.
-
Angabe eines Amazon Resource Name (ARN) eines Secrets mit den Anmeldeinformationen.
-
Verwendung eines offenen Standardanbieters für die Zugriffsdelegierung (OAuth), der eine Verbindung zu Snowflake herstellt. Ihr Administrator kann Ihnen Zugriff auf einen der folgenden OAuth Anbieter gewähren:
Sprechen Sie mit Ihrem Administrator über die Methode, die Sie für die Verbindung zu Snowflake verwenden müssen.
In den folgenden Abschnitten finden Sie Informationen darüber, wie Sie mit den o.g. Methoden eine Verbindung zu Snowflake herstellen können.
Sie können mit dem Import Ihrer Daten aus Snowflake beginnen, sobald Sie eine Verbindung hergestellt haben.
In Data Wrangler können Sie sich Ihre Data Warehouses, Datenbanken und Schemata sowie das Augensymbol anzeigen lassen, über das Sie sich eine Vorschau Ihrer Tabelle anzeigen lassen können. Wenn Sie das Symbol Tabellenvorschau ausgewählt haben, wird die Schemavorschau dieser Tabelle erzeugt. Sie müssen ein Warehouse auswählen, bevor Sie eine Tabellenvorschau sehen können.
Wichtig
Wenn Sie einen Datensatz mit Spalten vom Typ TIMESTAMP_TZ oder TIMESTAMP_LTZ importieren, fügen Sie ::string zu den Spaltennamen Ihrer Abfrage hinzu. Weitere Informationen finden Sie unter So entladen Sie TIMESTAMP_TZ- und TIMESTAMP_LTZ-Daten in eine Parquet-Datei
Wenn Sie ein Data Warehouse, eine Datenbank und ein Schema ausgewählt haben, können Sie nun Abfragen schreiben und diese ausführen. Die Ausgabe zu Ihrer Abfrage wird unter Abfrageergebnisse angezeigt.
Wenn Sie sich für die Ausgabe Ihrer Abfrage entschieden haben, können Sie die Ausgabe Ihrer Abfrage in einen Data-Wrangler-Ablauf importieren, um Datentransformationen vorzunehmen.
Wenn Sie Ihre Daten importiert haben, navigieren Sie zu Ihrem Data-Wrangler-Ablauf und beginnen Sie damit, Transformationen hinzuzufügen. Eine Liste der verfügbaren Transformationen finden Sie unter Daten transformieren.
Daten von SaaS-Plattformen (Software-as-a-Service) importieren
Mit Data Wrangler können Sie Daten von mehr als vierzig SaaS-Plattformen (Software as a Service) importieren. Um Ihre Daten von Ihrer SaaS-Plattform zu importieren, müssen Sie oder Ihr Administrator Amazon verwenden, AppFlow um die Daten von der Plattform zu Amazon S3 oder Amazon Redshift zu übertragen. Weitere Informationen zu Amazon AppFlow finden Sie unter Was ist Amazon AppFlow? Wenn Sie Amazon Redshift nicht zu verwenden brauchen, empfehlen wir, die Daten nach Amazon S3 zu übertragen, um das Verfahren zu vereinfachen.
Data Wrangler unterstützt die Übertragung von Daten von den folgenden SaaS-Plattformen:
Die obige Liste enthält Links zu weiteren Informationen dazu, wie Sie Ihre Datenquelle einrichten müssen. Sie oder Ihr Administrator können auf die obigen Links verweisen, sobald Sie die folgenden Informationen gelesen haben.
Wenn Sie in Ihrem Data-Wrangler-Ablauf zur Registerkarte Import navigieren, sehen Sie Datenquellen in den folgenden Abschnitten:
-
Verfügbar
-
Datenquellen einrichten
Sie können unter Verfügbar eine Verbindung zu Datenquellen herstellen, ohne dass eine zusätzliche Konfiguration erforderlich ist. Sie können die Datenquelle auswählen und Ihre Daten importieren.
Für Datenquellen unter Datenquellen einrichten müssen Sie oder Ihr Administrator Amazon AppFlow verwenden, um die Daten von der SaaS-Plattform zu Amazon S3 oder Amazon Redshift zu übertragen. Informationen zur Durchführung einer Übertragung finden Sie unter Amazon AppFlow zur Übertragung Ihrer Daten verwenden.
Wenn Sie die Datenübertragung durchgeführt haben, erscheint wird die SaaS-Plattform als Datenquelle unter Verfügbar. Sie können sie auswählen und die Daten, die Sie in Data Wrangler übertragen haben, importieren. Die Daten, die Sie übertragen haben, werden als Tabellen angezeigt, die Sie abfragen können.
Amazon AppFlow zur Übertragung Ihrer Daten verwenden
Amazon AppFlow ist eine Plattform, mit der Sie Daten von Ihrer SaaS-Plattform zu Amazon S3 oder Amazon Redshift übertragen können, ohne Code schreiben zu müssen. Um eine Datenübertragung durchzuführen, verwenden Sie die AWS Management Console.
Wichtig
Sie müssen sich vergewissern, dass Sie die Berechtigungen für die Durchführung einer Datenübertragung eingerichtet haben. Weitere Informationen finden Sie unter AppFlow Amazon-Berechtigungen.
Sobald Sie die Berechtigungen hinzugefügt haben, können Sie die Daten übertragen. Innerhalb von Amazon AppFlow erstellen Sie einen Flow zur Übertragung der Daten. Ein Ablauf besteht aus einer Reihe von Konfigurationen. Sie können damit angeben, ob Sie die Datenübertragung nach einem Zeitplan ausführen oder ob Sie die Daten in separate Dateien partitionieren. Wenn Sie den Ablauf konfiguriert haben, führen Sie ihn aus, um die Daten zu übertragen.
Informationen zum Erstellen eines Flows finden Sie unter Flows in Amazon erstellen AppFlow. Informationen zum Ausführen eines Flows finden Sie unter Aktivieren eines AppFlow Amazon-Flows.
Gehen Sie nach der Übertragung der Daten wie folgt vor, um auf die Daten in Data Wrangler zuzugreifen.
Wichtig
Bevor Sie versuchen, auf Ihre Daten zuzugreifen, vergewissern Sie sich, dass für Ihre IAM-Rolle die folgende Richtlinie gilt:
Standardmäßig ist die IAM-Rolle, die Sie für den Zugriff auf Data Wrangler verwenden, die SageMakerExecutionRole. Weitere Informationen dazu, wie Richtlinien hinzugefügt werden, finden Sie unter IAM-Identitätsberechtigungen hinzufügen (Konsole).
Gehen Sie wie folgt vor, um eine Verbindung zu einer Datenquelle herzustellen.
-
Melden Sie sich bei Amazon SageMaker AI Console
an. -
Wählen Sie Studio.
-
Wählen Sie App starten.
-
Wählen Sie in der Auswahlliste Studio aus.
-
Wählen Sie das Symbol Startseite aus.
-
Wählen Sie Datenaus.
-
Wählen Sie Data Wrangler.
-
Wählen Sie Daten importieren aus.
-
Wählen Sie unter Verfügbar die Datenquelle aus.
-
Geben Sie im Feld Name den Namen der Verbindung ein.
-
(Optional) Wählen Sie Erweiterte Konfiguration aus.
-
Wählen Sie eine Arbeitsgruppe aus.
-
Wenn Ihre Arbeitsgruppe den Amazon S3-Ausgabespeicherort nicht durchgesetzt hat oder wenn Sie keine Arbeitsgruppe verwenden, geben Sie einen Wert für den Amazon S3-Speicherort für die Abfrageergebnisse an.
-
(Optional) Aktivieren Sie für Datenaufbewahrungsdauer das Kontrollkästchen, um eine Datenaufbewahrungsdauer festzulegen, und geben Sie die Anzahl der Tage an, für die die Daten gespeichert werden sollen, bevor sie gelöscht werden.
-
(Optional) Data Wrangler speichert die Verbindung standardmäßig. Sie können das Kontrollkästchen deaktivieren und die Verbindung nicht speichern.
-
-
Wählen Sie Connect aus.
-
Geben Sie eine Abfrage an.
Anmerkung
Als Hilfestellung bei der Angabe einer Abfrage können Sie im linken Navigationsbereich eine Tabelle auswählen. Data Wrangler zeigt den Tabellennamen und eine Vorschau der Tabelle an. Wählen Sie das Symbol neben dem Tabellennamen aus, um den Namen zu kopieren. Den Tabellennamen können Sie in der Abfrage verwenden.
-
Wählen Sie Ausführen aus.
-
Wählen Sie Abfrage importieren aus.
-
Geben Sie als Datensatzname den Namen des Datensatzes an.
-
Wählen Sie Hinzufügen aus.
Wenn Sie zum Bildschirm Daten importieren navigieren, können Sie die Verbindung sehen, die Sie erstellt haben. Über die Verbindung können Sie weitere Daten importieren.
Speicher für importierte Daten
Wichtig
Wir empfehlen Ihnen dringend, den bewährten Methoden zum Schutz Ihres Amazon-S3-Buckets zu folgen, indem Sie den bewährten Sicherheitsmethoden folgen.
Wenn Sie Daten von Amazon Athena oder Amazon Redshift abfragen, wird der abgefragte Datensatz automatisch in Amazon S3 gespeichert. Daten werden im standardmäßigen SageMaker AI S3-Bucket für die AWS Region gespeichert, in der Sie Studio Classic verwenden.
Standard-S3-Buckets haben die folgende Namenskonvention: sagemaker-. Wenn Ihre Kontonummer beispielsweise 111122223333 lautet und Sie Studio Classic in verwendenregion-account
numberus-east-1, werden Ihre importierten Datensätze in 111122223333 gespeichert. sagemaker-us-east-1-
Data-Wrangler-Abläufe hängen von diesem Speicherort für Amazon S3-Datensätze ab. Daher sollten Sie diesen Datensatz in Amazon S3 nicht ändern, solange Sie einen abhängigen Ablauf verwenden. Wenn Sie diesen S3-Speicherort ändern und Ihren Datenablauf weiterhin verwenden möchten, müssen Sie alle Objekte in trained_parameters in Ihrer .flow-Datei entfernen. Laden Sie dazu die .flow-Datei von Studio Classic herunter und löschen Sie für jede Instanz von alle Einträge. trained_parameters Wenn Sie damit fertig sind, sollte trained_parameters ein leeres JSON-Objekt sein:
"trained_parameters": {}
Wenn Sie Ihren Datenablauf exportieren und zur Verarbeitung Ihrer Daten verwenden, bezieht sich die von Ihnen exportierte .flow-Datei auf diesen Datensatz in Amazon S3. In den folgenden Abschnitten erfahren Sie mehr dazu.
Speicher für Amazon Redshift-Import
Data Wrangler speichert die Datensätze, die sich aus Ihrer Abfrage ergeben, in einer Parquet-Datei in Ihrem standardmäßigen SageMaker AI S3-Bucket.
Diese Datei wird unter dem folgenden Präfix (Verzeichnis) gespeichert: redshift/ uuid /data/, wobei sich ein eindeutiger Bezeichner befindet, der für jede uuid Abfrage erstellt wird.
Wenn Ihr Standard-Bucket beispielsweise lautet, befindet sich ein einzelner Datensatzsagemaker-us-east-1-111122223333, der von Amazon Redshift abgefragt wurde, in s3://-1-111122223333/redshift/ /data/. sagemaker-us-east uuid
Speicher für Amazon Athena-Import
Wenn Sie eine Athena-Datenbank abfragen und einen Datensatz importieren, speichert Data Wrangler den Datensatz sowie eine Teilmenge dieses Datensatzes oder Vorschaudateien in Amazon S3.
Der Datensatz, den Sie importieren, indem Sie Datensatz importieren auswählen, wird in Amazon S3 im Parquet-Format gespeichert.
Vorschaudateien werden im CSV-Format geschrieben, wenn Sie auf dem Athena-Importbildschirm Ausführen auswählen, und enthalten bis zu 100 Zeilen aus dem von Ihnen abgefragten Datensatz.
Der Datensatz, den Sie abfragen, befindet sich unter dem Präfix (Verzeichnis): athena/ /data/, wobei es sich um eine eindeutige Kennung handelt, die für jede Abfrage erstellt wird. uuid uuid
Wenn Ihr Standard-Bucket beispielsweise lautet, befindet sich ein einzelner Datensatzsagemaker-us-east-1-111122223333, der von Athena abgefragt wurde, in s3://sagemaker-us-east-1-111122223333 /athena/ /data/. uuid example_dataset.parquet
Die Teilmenge des Datensatzes, die zur Vorschau von Dataframes in Data Wrangler gespeichert wird, wird unter dem Präfix: athena/ abgespeichert.
