Die vorliegende Übersetzung wurde maschinell erstellt. Im Falle eines Konflikts oder eines Widerspruchs zwischen dieser übersetzten Fassung und der englischen Fassung (einschließlich infolge von Verzögerungen bei der Übersetzung) ist die englische Fassung maßgeblich.
Modellmonitor FAQs
Im Folgenden finden Sie FAQs weitere Informationen zu Amazon SageMaker Model Monitor.
F: Wie helfen Model Monitor und SageMaker Clarify Kunden dabei, das Verhalten von Modellen zu überwachen?
Mit Amazon SageMaker Model Monitor und SageMaker Clarify können Kunden das Modellverhalten anhand von vier Dimensionen überwachen: Datenqualität, Modellqualität, Verzerrungsabweichung und Feature-Attributionsabweichung. Model Monitor
F: Was passiert im Hintergrund, wenn Sagemaker Model Monitor aktiviert ist?
Amazon SageMaker Model Monitor automatisiert die Modellüberwachung, sodass die Modelle nicht mehr manuell überwacht oder zusätzliche Tools erstellt werden müssen. Um den Prozess zu automatisieren, bietet Ihnen Model Monitor die Möglichkeit, anhand der Daten, mit denen Ihr Modell trainiert wurde, eine Reihe von Basisstatistiken und Einschränkungen zu erstellen und anschließend einen Zeitplan zur Überwachung der auf Ihrem Endpunkt getroffenen Vorhersagen aufzustellen. Model Monitor verwendet Regeln, um Abweichungen in Ihren Modellen zu erkennen, und warnt Sie, wenn sie auftreten. In den folgenden Schritten wird beschrieben, was passiert, wenn Sie die Modellüberwachung aktivieren:
-
Modellüberwachung aktivieren: Für einen Echtzeit-Endpunkt müssen Sie den Endpunkt so einrichten, dass er Daten aus eingehenden Anfragen an ein bereitgestelltes ML-Modell und die daraus resultierenden Modellvorhersagen erfasst. Aktivieren Sie für einen Batch-Transformationsjauftrag die Datenerfassung der Eingaben und Ausgaben der Batch-Transformation.
-
Baseline-Verarbeitungsauftrag: Erstellen Sie eine Baseline aus dem Datensatz, mit dem das Modell trainiert wurde. Die Baseline berechnet Metriken und schlägt Einschränkungen für die Metriken vor. Beispielsweise sollte der Recall-Score für das Modell nicht zurückgehen und unter 0,571 fallen, oder der Präzisionswert sollte nicht unter 1,0 fallen. Echtzeit- oder Batchvorhersagen aus Ihrem Modell werden mit den Beschränkungen verglichen und als Verstöße gemeldet, wenn sie außerhalb der eingeschränkten Werte liegen.
-
Auftrag überwachen: Erstellen Sie einen Überwachungsplan, der angibt, welche Daten gesammelt werden sollen, wie oft sie erfasst werden, wie sie analysiert werden und welche Berichte erstellt werden sollen.
-
Auftrag zusammenführen: Dies gilt nur, wenn Sie Amazon SageMaker Ground Truth nutzen. Model Monitor vergleicht die Vorhersagen Ihres Modells mit Ground-Truth-Labels, um die Qualität des Modells zu messen. Damit dies funktioniert, kennzeichnen Sie regelmäßig Daten, die von Ihrem Endpunkt- oder Batch-Transformationsauftrag erfasst wurden, und laden sie auf Amazon S3 hoch.
Nachdem Sie die Ground-Truth-Labels erstellt und hochgeladen haben, geben Sie bei der Erstellung des Monitoring-Aufträge die Position der Beschriftung als Parameter an.
Wenn Sie Model Monitor verwenden, um einen Batch-Transformationsauftrag anstelle eines Echtzeit-Endpunkts zu überwachen, anstatt Anfragen an einen Endpunkt zu empfangen und die Vorhersagen zu verfolgen, überwacht Model Monitor die Inferenzeingaben und -ausgaben. In einem Model Monitor-Zeitplan gibt der Kunde die Anzahl und Art der Instances an, die für den Verarbeitungsauftrag verwendet werden sollen. Diese Ressourcen bleiben reserviert, bis der Zeitplan gelöscht wird, unabhängig vom Status der aktuellen Ausführung.
F: Was ist Datenerfassung, warum ist sie erforderlich und wie kann ich sie aktivieren?
Um die Eingaben am Modellendpunkt und die Inferenzausgaben des bereitgestellten Modells in Amazon S3 zu protokollieren, können Sie eine Funktion namens Data Capture aktivieren. Weitere Informationen darüber, wie Sie sie für einen Echtzeit-Endpunkt- und Batch-Transformationsauftrag aktivieren, finden Sie unter Daten vom Echtzeit-Endpunkt erfassen und Daten aus einem Batch-Transformationsauftrag erfassen.
F: Beeinträchtigt die Aktivierung der Datenerfassung die Leistung eines Echtzeit-Endpunkts?
Die Datenerfassung erfolgt asynchron, ohne den Produktionsverkehr zu beeinträchtigen. Da Sie die Datenerfassung in den vorherigen Schritten aktiviert haben, werden die Anforderungs- und Antwort-Nutzlast zusammen mit einigen zusätzlichen Metadaten an dem Amazon S3-Speicherort gespeichert, den Sie in DataCaptureConfig angegeben haben. Beachten Sie, dass es zu Verzögerungen bei der Übertragung der erfassten Daten an Amazon S3 kommen kann.
Sie können die erfassten Daten auch anzeigen, indem Sie die in Amazon S3 gespeicherten Datenerfassungsdateien auflisten. Das Format des Amazon S3 Pfades ist: s3:///{endpoint-name}/{variant-name}/yyyy/mm/dd/hh/filename.jsonl. Amazon S3 Data Capture sollte sich in derselben Region wie der Model Monitor-Zeitplan befinden. Sie sollten auch sicherstellen, dass die Spaltennamen für den Baseline-Datensatz nur Kleinbuchstaben und einen Unterstrich (_) als einziges Trennzeichen enthalten.
F: Warum wird Ground Truth für die Modellüberwachung benötigt?
Ground-Truth-Etiketten sind für die folgenden Funktionen von Model Monitor erforderlich:
-
Bei der Überwachung der Modellqualität werden die Vorhersagen Ihres Modells mit Ground-Truth-Labels verglichen, um die Qualität des Modells zu messen.
-
Bei der Überwachung von Modellverzerrungen werden Prognosen auf Verzerrungen hin überwacht. Eine Möglichkeit, Verzerrungen in eingesetzten ML-Modellen einzuführen, besteht darin, dass sich die in dem Training verwendeten Daten von den Daten unterscheiden, die zur Generierung von Vorhersagen verwendet wurden. Dies ist besonders ausgeprägt, wenn sich die für das Training verwendeten Daten im Laufe der Zeit ändern (z. B. schwankende Hypothekenzinsen) und die Modellvorhersage nicht so genau ist, es sei denn, das Modell wird mit aktualisierten Daten neu trainiert. Ein Modell zur Vorhersage von Eigenheimpreisen kann beispielsweise verzerrt sein, wenn die Hypothekenzinsen, die für das Modell verwendet wurden, von den aktuellsten realen Hypothekenzinsen abweichen.
F: Welche Maßnahmen kann ich für Kunden ergreifen, die Ground Truth für die Etikettierung nutzen, um die Qualität des Modells zu überwachen?
Bei der Überwachung der Modellqualität werden die Vorhersagen Ihres Modells mit Ground-Truth-Labels verglichen, um die Qualität des Modells zu messen. Damit dies funktioniert, kennzeichnen Sie regelmäßig Daten, die von Ihrem Endpunkt- oder Batch-Transformationsauftrag erfasst wurden, und laden sie auf Amazon S3 hoch. Für die Überwachung der Modellverzerrung sind neben der Erfassung auch Ground-Truth-Daten erforderlich. In realen Anwendungsfällen sollten Ground-Truth-Daten regelmäßig gesammelt und an den dafür vorgesehenen Amazon S3-Standort hochgeladen werden. Um Ground-Truth-Bezeichnungen mit erfassten Vorhersagedaten abzugleichen, muss für jeden Datensatz im Datensatz eine eindeutige Kennung vorhanden sein. Die Struktur der einzelnen Datensätze für Ground-Truth-Daten finden Sie unter Ground-Truth-Labels aufnehmen und mit Prognosen zusammenführen.
Das folgende Codebeispiel kann verwendet werden, um künstliche Ground-Truth-Daten für einen tabellarischen Datensatz zu generieren.
import random def ground_truth_with_id(inference_id): random.seed(inference_id) # to get consistent results rand = random.random() # format required by the merge container return { "groundTruthData": { "data": "1" if rand < 0.7 else "0", # randomly generate positive labels 70% of the time "encoding": "CSV", }, "eventMetadata": { "eventId": str(inference_id), }, "eventVersion": "0", } def upload_ground_truth(upload_time): records = [ground_truth_with_id(i) for i in range(test_dataset_size)] fake_records = [json.dumps(r) for r in records] data_to_upload = "\n".join(fake_records) target_s3_uri = f"{ground_truth_upload_path}/{upload_time:%Y/%m/%d/%H/%M%S}.jsonl" print(f"Uploading {len(fake_records)} records to", target_s3_uri) S3Uploader.upload_string_as_file_body(data_to_upload, target_s3_uri) # Generate data for the last hour upload_ground_truth(datetime.utcnow() - timedelta(hours=1)) # Generate data once a hour def generate_fake_ground_truth(terminate_event): upload_ground_truth(datetime.utcnow()) for _ in range(0, 60): time.sleep(60) if terminate_event.is_set(): break ground_truth_thread = WorkerThread(do_run=generate_fake_ground_truth) ground_truth_thread.start()
Im folgenden Codebeispiel wird veranschaulicht, wie künstlicher Datenverkehr generiert wird, der an den Modellendpunkts gesendet wird. Beachten Sie das oben zum Aufrufen verwendete inferenceId Attribut. Wenn dieser vorhanden ist, wird er für die Verknüpfung mit Ground-Truth-Daten verwendet (andernfalls eventId wird der verwendet).
import threading class WorkerThread(threading.Thread): def __init__(self, do_run, *args, **kwargs): super(WorkerThread, self).__init__(*args, **kwargs) self.__do_run = do_run self.__terminate_event = threading.Event() def terminate(self): self.__terminate_event.set() def run(self): while not self.__terminate_event.is_set(): self.__do_run(self.__terminate_event) def invoke_endpoint(terminate_event): with open(test_dataset, "r") as f: i = 0 for row in f: payload = row.rstrip("\n") response = sagemaker_runtime_client.invoke_endpoint( EndpointName=endpoint_name, ContentType="text/csv", Body=payload, InferenceId=str(i), # unique ID per row ) i += 1 response["Body"].read() time.sleep(1) if terminate_event.is_set(): break # Keep invoking the endpoint with test data invoke_endpoint_thread = WorkerThread(do_run=invoke_endpoint) invoke_endpoint_thread.start()
Sie müssen Ground-Truth-Daten in einen Amazon-S3-Bucket hochladen, der dasselbe Pfadformat wie die erfassten Daten hat, und zwar im folgenden Format: s3://<bucket>/<prefix>/yyyy/mm/dd/hh
Anmerkung
Das Datum in diesem Pfad ist das Datum, an dem die Ground-Truth-Beschriftung abgeholt wurde. Es muss nicht mit dem Datum übereinstimmen, an dem die Schlussfolgerung generiert wurde.
F: Wie können Kunden die Überwachungspläne anpassen?
Zusätzlich zur Verwendung der integrierten Überwachungsmechanismen können Sie eigene benutzerdefinierte Überwachungspläne und -verfahren mithilfe von Vorverarbeitungs- und Nachverarbeitungsskripten oder mithilfe eines eigenen Containers erstellen. Es ist wichtig zu beachten, dass Skripte für die Vor- und Nachverarbeitung nur bei Aufträgen mit Daten- und Modellqualität funktionieren.
Amazon SageMaker AI bietet Ihnen die Möglichkeit, die von den Modellendpunkten beobachteten Daten zu überwachen und auszuwerten. Dazu müssen Sie eine Basislinie erstellen, mit der Sie den Echtzeitverkehr vergleichen. Wenn eine Basislinie fertig ist, richten Sie einen Zeitplan ein, um sie kontinuierlich zu bewerten und mit der Basislinie zu vergleichen. Bei der Erstellung eines Zeitplans können Sie das Skript für die Vor- und Nachbearbeitung bereitstellen.
Das folgende Beispiel zeigt, wie Sie Überwachungspläne mit Vor- und Nachverarbeitungsskripten anpassen können.
import boto3, osfrom sagemaker import get_execution_role, Sessionfrom sagemaker.model_monitor import CronExpressionGenerator, DefaultModelMonitor # Upload pre and postprocessor scripts session = Session() bucket = boto3.Session().resource("s3").Bucket(session.default_bucket()) prefix = "demo-sagemaker-model-monitor" pre_processor_script = bucket.Object(os.path.join(prefix, "preprocessor.py")).upload_file("preprocessor.py") post_processor_script = bucket.Object(os.path.join(prefix, "postprocessor.py")).upload_file("postprocessor.py") # Get execution role role = get_execution_role() # can be an empty string # Instance type instance_type = "instance-type" # instance_type = "ml.m5.xlarge" # Example # Create a monitoring schedule with pre and post-processing my_default_monitor = DefaultModelMonitor( role=role, instance_count=1, instance_type=instance_type, volume_size_in_gb=20, max_runtime_in_seconds=3600, ) s3_report_path = "s3://{}/{}".format(bucket, "reports") monitor_schedule_name = "monitor-schedule-name" endpoint_name = "endpoint-name" my_default_monitor.create_monitoring_schedule( post_analytics_processor_script=post_processor_script, record_preprocessor_script=pre_processor_script, monitor_schedule_name=monitor_schedule_name, # use endpoint_input for real-time endpoint endpoint_input=endpoint_name, # or use batch_transform_input for batch transform jobs # batch_transform_input=batch_transform_name, output_s3_uri=s3_report_path, statistics=my_default_monitor.baseline_statistics(), constraints=my_default_monitor.suggested_constraints(), schedule_cron_expression=CronExpressionGenerator.hourly(), enable_cloudwatch_metrics=True, )
F: In welchen Szenarien oder Anwendungsfällen kann ich ein Vorverarbeitungsskript nutzen?
Sie können Vorverarbeitungsskripten verwenden, wenn Sie die Eingaben in Ihren Modellmonitor transformieren müssen. Betrachten Sie die folgenden Beispielszenarien:
-
Vorverarbeitungsskript für die Datentransformation.
Angenommen, die Ausgabe Ihres Modells ist ein Array:
[1.0, 2.1]. Der Model Monitor Container arbeitet nur mit tabellarischen oder flattened JSON-Strukturen, wie z. B.{“prediction0”: 1.0, “prediction1” : 2.1}. Sie könnten ein Vorverarbeitungsskript wie das folgende Beispiel verwenden, um das Array in die richtige JSON-Struktur umzuwandeln.def preprocess_handler(inference_record): input_data = inference_record.endpoint_input.data output_data = inference_record.endpoint_output.data.rstrip("\n") data = output_data + "," + input_data return { str(i).zfill(20) : d for i, d in enumerate(data.split(",")) } -
Schließen Sie bestimmte Datensätze aus den Metrikberechnungen von Model Monitor aus.
Angenommen, Ihr Modell verfügt über optionale Funktionen und Sie
-1geben damit an, dass das optionale Feature einen fehlenden Wert hat. Wenn Sie über einen Datenqualitätsmonitor verfügen, sollten Sie den-1aus dem Eingabe-Werte-Array entfernen, damit er nicht in den metrischen Berechnungen des Monitors berücksichtigt wird. Sie könnten ein Skript wie das folgende verwenden, um diese Werte zu entfernen.def preprocess_handler(inference_record): input_data = inference_record.endpoint_input.data return {i : None if x == -1 else x for i, x in enumerate(input_data.split(","))} -
Wenden Sie eine benutzerdefinierte Probenahmestrategie an.
Sie können in Ihrem Vorverarbeitungsskript auch eine benutzerdefinierte Sampling-Strategie anwenden. Konfigurieren Sie dazu den vorgefertigten Container von Model Monitor aus erster Hand so, dass ein bestimmter Prozentsatz der Datensätze entsprechend der von Ihnen angegebenen Sampling-Rate ignoriert wird. Im folgenden Beispiel nimmt der Handler eine Stichprobe von 10% der Datensätze vor, indem er den Datensatz bei 10% der Handler-Aufrufe zurückgibt und andernfalls eine leere Liste ausgibt.
import random def preprocess_handler(inference_record): # we set up a sampling rate of 0.1 if random.random() > 0.1: # return an empty list return [] input_data = inference_record.endpoint_input.data return {i : None if x == -1 else x for i, x in enumerate(input_data.split(","))} -
Verwenden Sie die benutzerdefinierte Protokollierung.
Sie können alle Informationen, die Sie benötigen, aus Ihrem Skript bei Amazon protokollieren CloudWatch. Dies kann beim Debuggen Ihres Vorverarbeitungsskripts im Falle eines Fehlers nützlich sein. Das folgende Beispiel zeigt, wie Sie sich
preprocess_handlerüber die Schnittstelle anmelden können CloudWatch.def preprocess_handler(inference_record, logger): logger.info(f"I'm a processing record: {inference_record}") logger.debug(f"I'm debugging a processing record: {inference_record}") logger.warning(f"I'm processing record with missing value: {inference_record}") logger.error(f"I'm a processing record with bad value: {inference_record}") return inference_record
Anmerkung
Wenn das Vorverarbeitungsskript für Batch-Transformationsdaten ausgeführt wird, ist der Eingabetyp nicht immer das CapturedData Objekt. Für CSV-Daten ist der Typ eine Zeichenge-Zuweisung. Für JSON-Daten ist der Typ ein Python-Wörterbuch.
F: Wann kann ich ein Post-Processing-Skript nutzen?
Sie können ein Nachbearbeitungsskript nach einem erfolgreichen Überwachungslauf als Erweiterung nutzen. Das Folgende ist ein einfaches Beispiel, aber Sie können jede Geschäftsfunktion ausführen oder aufrufen, die Sie nach einem erfolgreichen Überwachungslauf ausführen müssen.
def postprocess_handler(): print("Hello from the post-processing script!")
F: Wann sollte ich in Betracht ziehen, meinen eigenen Container für die Modellüberwachung mitzubringen?
SageMaker AI bietet einen vorgefertigten Container für die Analyse von Daten, die von Endpunkten erfasst wurden, oder für Batch-Transformationsaufträge für tabellarische Datensätze. Es gibt jedoch Szenarien, in denen Sie möglicherweise Ihren eigenen Container erstellen möchten. Betrachten Sie folgende Szenarien:
-
Sie haben gesetzliche Vorschriften und Compliance-Anforderungen, sodass Sie nur die Container verwenden dürfen, die intern in Ihrer Organisation erstellt und verwaltet werden.
-
Wenn Sie einige Bibliotheken von Drittanbietern einbeziehen möchten, können Sie eine
requirements.txtDatei in einem lokalen Verzeichnis platzieren und mithilfe dessource_dirParameters im SageMaker AI-Estimatordarauf verweisen, was die Bibliotheksinstallation zur Laufzeit ermöglicht. Wenn Sie jedoch über viele Bibliotheken oder Abhängigkeiten verfügen, die die Installationszeit während der Ausführung des Trainingsauftrages verlängern, sollten Sie BYOC nutzen. -
Ihre Umgebung erzwingt keine Internetverbindung (oder Silo), wodurch das Herunterladen von Paketen verhindert wird.
-
Sie möchten Daten überwachen, die in anderen als tabellarischen Datenformaten vorliegen, z. B. in NLP- oder CV-Anwendungsfällen.
-
Wenn Sie zusätzliche Monitoring-Metriken als die von Model Monitor unterstützten benötigen.
F: Ich habe NLP- und CV-Modelle. Wie überwache ich sie auf Datendrift?
Der vorgefertigte Container von Amazon SageMaker AI unterstützt tabellarische Datensätze. Wenn Sie NLP- und CV-Modelle überwachen möchten, können Sie Ihren eigenen Container mitbringen, indem Sie die von Model Monitor bereitgestellten Erweiterungspunkte nutzen. Weitere Informationen zu den Anforderungen finden Sie unter Bring your own containers. Im Folgenden sind einige Beispiele für aufgeführt.
-
Eine ausführliche Erläuterung der Verwendung von Model Monitor für einen Anwendungsfall im Bereich Computer Vision finden Sie unter Erkennen und Analysieren falscher Vorhersagen
. -
Ein Szenario, in dem Model Monitor für einen NLP-Anwendungsfall genutzt werden kann, finden Sie unter Erkennen von NLP-Datendrift mithilfe von benutzerdefiniertem Amazon SageMaker
Model Monitor.
F: Ich möchte den Modellendpunkt löschen, für den Model Monitor aktiviert wurde, kann das aber nicht tun, da der Überwachungsplan noch aktiv ist. Was soll ich tun?
Wenn Sie einen in SageMaker AI gehosteten Inferenzendpunkt löschen möchten, für den Model Monitor aktiviert ist, müssen Sie zunächst den Modellüberwachungszeitplan (mit der DeleteMonitoringSchedule CLI oder API) löschen. Löschen Sie dann den Endpunkt
F: Berechnet SageMaker Model Monitor Metriken und Statistiken für die Eingabe?
Model Monitor berechnet Metriken und Statistiken für die Ausgabe, nicht für die Eingabe.
F: Unterstützt SageMaker Model Monitor Endpunkte mit mehreren Modellen?
Nein, Model Monitor unterstützt derzeit nur Endpunkte, die ein einzelnes Modell hosten, und keine Überwachung von Endpunkten mit mehreren Modellen.
F: Stellt SageMaker Model Monitor Überwachungsdaten zu einzelnen Containern in einer Inferenz-Pipeline bereit?
Model Monitor unterstützt die Überwachung von Inferenz-Pipelines. Erfassung und Analyse von Daten erfolgen jedoch für die gesamte Pipeline, nicht für einzelne Container in der Pipeline.
F: Was kann ich tun, um Auswirkungen auf Inferenzanfragen zu verhindern, wenn die Datenerfassung eingerichtet ist?
Um Auswirkungen auf Inferenzanfragen zu vermeiden, stoppt Data Capture die Erfassung von Anfragen bei hoher Festplattenauslastung. Es wird empfohlen, die Festplattenauslastung unter 75% zu halten, um sicherzustellen, dass die Datenerfassung auch weiterhin Anfragen erfasst.
F: Kann sich Amazon S3 Data Capture in einer anderen AWS Region befinden als in der Region, in der der Überwachungsplan eingerichtet wurde?
Nein, Amazon-S3-Data-Capture muss sich in derselben Region wie der Überwachungsplan befinden.
F: Was ist eine Baseline und wie erstelle ich eine? Kann ich eine benutzerdefinierte Baseline erstellen?
Eine Basislinie wird als Referenz verwendet, um Echtzeit- oder Batchvorhersagen aus dem Modell zu vergleichen. Es berechnet Statistiken und Metriken sowie deren Einschränkungen. Bei der Überwachung werden all diese Daten zusammen verwendet, um Verstöße zu identifizieren.
Um die Standardlösung von Amazon SageMaker Model Monitor zu verwenden, können Sie das Amazon SageMaker Python SDK
Das Ergebnis eines Baseline-Jobs sind zwei Dateien: statistics.json und constraints.json. Das Schema für Statistiken und das Schema für Einschränkungen enthalten das Schema der jeweiligen Dateien. Sie können die generierten Einschränkungen überprüfen und ändern, bevor Sie sie für die Überwachung verwenden. Je nachdem, was Sie über die Domain und das Geschäftsproblem wissen, können Sie eine Einschränkung aggressiver gestalten oder sie lockern, um die Anzahl und Art der Verstöße zu kontrollieren.
F: Welche Richtlinien gelten für die Erstellung eines Basisdatensatzes?
Die Hauptanforderung für jede Art von Überwachung ist ein Basisdatensatz, der zur Berechnung von Metriken und Einschränkungen verwendet wird. In der Regel ist dies der Trainingsdatensatz, der vom Modell verwendet wird. In einigen Fällen können Sie sich jedoch auch für einen anderen Referenzdatensatz entscheiden.
Die Spaltennamen des Baseline-Datensatzes sollten mit Spark kompatibel sein. Um die maximale Kompatibilität zwischen Spark, CSV, JSON und Parquet zu gewährleisten, ist es ratsam, nur Kleinbuchstaben und nur _ als Trennzeichen zu verwenden. Auch Sonderzeichen “ ” können zu Problemen führen.
F: Was sind die EndTimeOffset Parameter StartTimeOffset und wann werden sie verwendet?
Wenn Amazon SageMaker Ground Truth für die Überwachung von Aufgaben wie der Modellqualität benötigt wird, müssen Sie sicherstellen, dass ein Überwachungsauftrag nur Daten verwendet, für die Ground Truth verfügbar ist. Die end_time_offset Parameter start_time_offset und von EndpointInputstart_time_offset und end_time_offset definiert ist. Diese Parameter müssen im ISO 8601-Dauerformat
-
Wenn Ihre Ground-Truth-Ergebnisse 3 Tage nach der Erstellung der Vorhersagen eintreffen, legen Sie einen Wert von
start_time_offset="-P3D"undend_time_offset="-P1D"fest, was 3 Tage bzw. 1 Tag entspricht. -
Wenn die Ground-Truth-Ergebnisse 6 Stunden nach den Vorhersagen eintreffen und Sie einen Stundenplan haben, legen Sie
start_time_offset="-PT6H"undend_time_offset="-PT1H"fest, der 6 Stunden und 1 Stunde beträgt.
F: Kann ich Monitoring-Jobs „auf Abruf“ ausführen?
Ja, Sie können Überwachungsaufträge „bei Bedarf“ ausführen, indem Sie einen SageMaker Verarbeitungsauftrag ausführen. Für Batch Transform bietet Pipelines eine MonitorBatchTransformStep
F: Wie richte ich Model Monitor ein?
Sie können Model Monitor auf folgende Weise einrichten:
-
Amazon SageMaker AI Python SDK
— Es gibt ein Model Monitor-Modul , das Klassen und Funktionen enthält, die dabei helfen, Baselines vorzuschlagen, Überwachungspläne zu erstellen und vieles mehr. In den Amazon SageMaker Model Monitor-Notebook-Beispielen finden Sie detaillierte Notebooks, die das SageMaker KI-Python-SDK für die Einrichtung von Model Monitor nutzen. -
Pipelines — Pipelines werden über die QualityCheck Schritte und in Model Monitor integriert. ClarifyCheckStep APIs Sie können eine SageMaker KI-Pipeline erstellen, die diese Schritte enthält und verwendet werden kann, um Überwachungsjobs bei Bedarf auszuführen, wann immer die Pipeline ausgeführt wird.
-
Amazon SageMaker Studio Classic — Sie können einen Zeitplan für die Überwachung der Daten- oder Modellqualität zusammen mit Zeitplänen für Modellverzerrungen und Erklärbarkeit direkt von der Benutzeroberfläche aus erstellen, indem Sie einen Endpunkt aus der Liste der bereitgestellten Modellendpunkte auswählen. Zeitpläne für andere Arten der Überwachung können erstellt werden, indem Sie die entsprechende Registerkarte in der Benutzeroberfläche auswählen.
-
SageMaker Modell-Dashboard — Sie können die Überwachung auf Endpunkten aktivieren, indem Sie ein Modell auswählen, das auf einem Endpunkt bereitgestellt wurde. Im folgenden Screenshot der SageMaker AI-Konsole
group1wurde im Bereich Modelle des Modell-Dashboards ein Modell mit dem Namen ausgewählt. Auf dieser Seite können Sie einen Überwachungsplan erstellen und bestehende Überwachungspläne und Warnmeldungen bearbeiten, aktivieren oder deaktivieren. Eine schrittweise Anleitung zum Anzeigen von Warnmeldungen und Modellmonitor-Zeitplänen finden Sie unter Zeitpläne und Warnmeldungen von Model Monitor anzeigen.
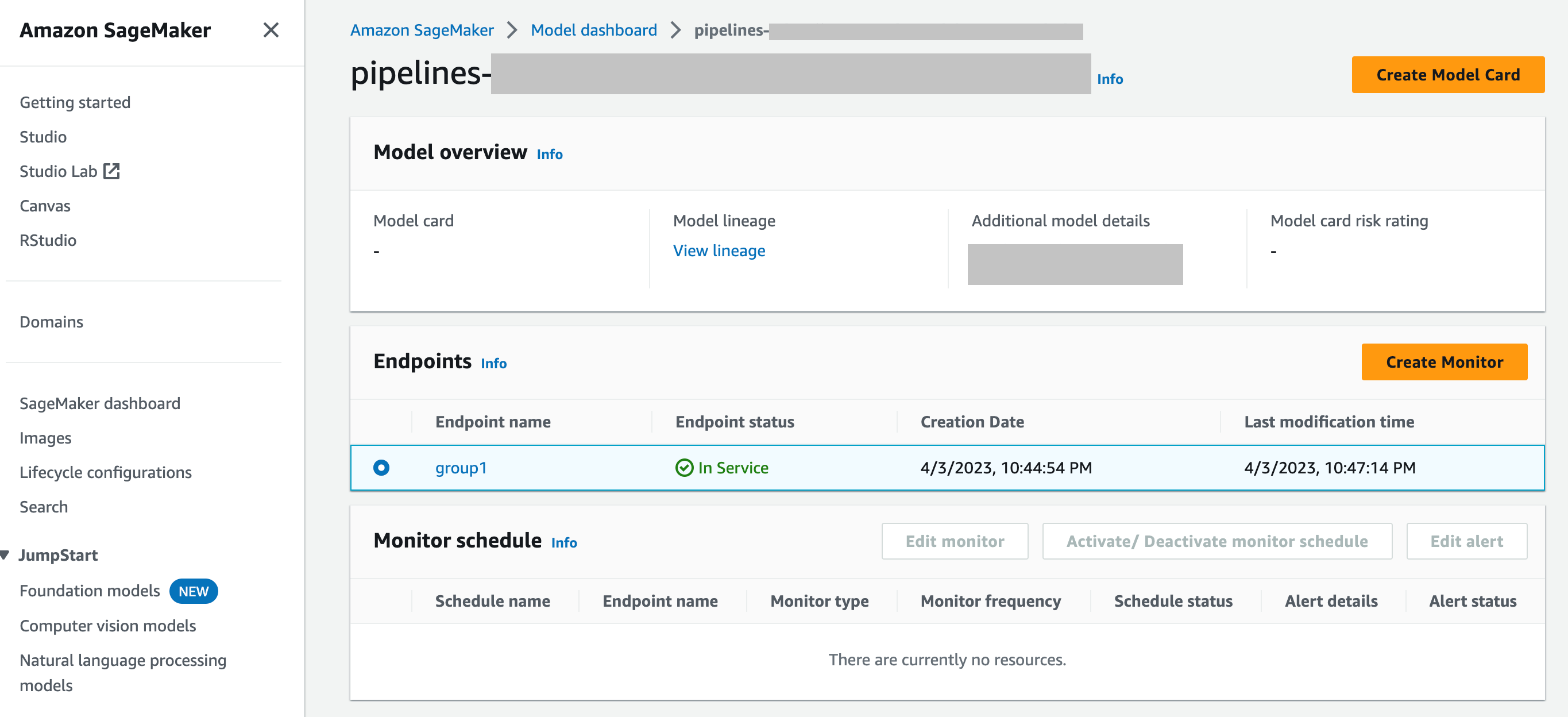
F: Wie lässt sich Model Monitor in SageMaker Model Dashboard integrieren
SageMaker Model Dashboard bietet Ihnen eine einheitliche Überwachung all Ihrer Modelle, indem es automatische Benachrichtigungen über Abweichungen vom erwarteten Verhalten und zur Fehlerbehebung bereitstellt, um Modelle zu überprüfen und Faktoren zu analysieren, die sich im Laufe der Zeit auf die Modellleistung auswirken.
