Enhanced health reporting and monitoring in Elastic Beanstalk
This section explains the functionality of the Elastic Beanstalk Enhanced Health feature.
Enhanced health reporting is a feature that you can enable on your environment to allow AWS Elastic Beanstalk to gather additional information about resources in your environment. Elastic Beanstalk analyzes the information gathered to provide a better picture of overall environment health and aid in the identification of issues that can cause your application to become unavailable.
In addition to changes in how health color works, enhanced health adds a status descriptor that provides an indicator of the severity of issues observed when an environment is yellow or red. When more information is available about the current status, you can choose the Causes button to view detailed health information on the health page.
To provide detailed health information about the Amazon EC2 instances running in your environment, Elastic Beanstalk includes a health agent in the Amazon Machine Image (AMI) for each platform version that supports enhanced health. The health agent monitors web server logs and system metrics and relays them to the Elastic Beanstalk service. Elastic Beanstalk analyzes these metrics and data from Elastic Load Balancing and Amazon EC2 Auto Scaling to provide an overall picture of an environment's health.
In addition to collecting and presenting information about your environment's resources, Elastic Beanstalk monitors the resources in your environment for several error conditions and provides notifications to help you avoid failures and resolve configuration issues. Factors that influence your environment's health include the results of each request served by your application, metrics from your instances' operating system, and the status of the most recent deployment.
You can view health status in real time by using the environment overview page of the Elastic Beanstalk console or
the eb health command in the Elastic Beanstalk command line interface (EB CLI). To record
and track environment and instance health over time, you can configure your environment to publish the information gathered by Elastic Beanstalk for enhanced health
reporting to Amazon CloudWatch as custom metrics. CloudWatch chargesEnvironmentHealth, which is free of charge.
Windows platform notes
When you enable enhanced health reporting on a Windows Server environment, don't change IIS logging configuration
In addition, don't disable or stop the Elastic Beanstalk health agent Windows service on any of your environment's instances. To collect and report enhanced health information on an instance, this service should be enabled and running.
The first time you create an environment Elastic Beanstalk prompts you to create the required roles and enables enhanced health reporting by default. Continue reading for details on how enhanced health reporting works, or see Enabling Elastic Beanstalk enhanced health reporting to get started using it right away.
Topics
The Elastic Beanstalk health agent
The Elastic Beanstalk health agent is a daemon process (or service, on Windows environments) that runs on each Amazon EC2 instance in your environment, monitoring operating system and application-level health metrics and reporting issues to Elastic Beanstalk. The health agent is included in all platform versions starting with version 2.0 of each platform.
The health agent reports similar metrics to those published to CloudWatch by Amazon EC2 Auto Scaling and Elastic Load Balancing as part of basic health reporting, including CPU load, HTTP codes, and latency. The health agent, however, reports directly to Elastic Beanstalk, with greater granularity and frequency than basic health reporting.
For basic health, these metrics are published every five minutes and can be monitored with graphs in the environment management console. With enhanced health, the Elastic Beanstalk health agent reports metrics to Elastic Beanstalk every 10 seconds. Elastic Beanstalk uses the metrics provided by the health agent to determine the health status of each instance in the environment and, combined with other factors, to determine the overall health of the environment.
The overall health of the environment can be viewed in real time in the environment overview page of the Elastic Beanstalk console, and is published to CloudWatch by Elastic Beanstalk every 60 seconds. You can view detailed metrics reported by the health agent in real time with the eb health command in the EB CLI.
For an additional charge, you can choose to publish individual instance and environment-level metrics to CloudWatch every 60 seconds. Metrics published to CloudWatch can then be used to create monitoring graphs in the environment management console.
Enhanced health reporting only incurs a charge if you choose to publish enhanced health metrics to CloudWatch. When you use enhanced health, you still get the basic health metrics published for free, even if you don't choose to publish enhanced health metrics.
See Instance metrics for details on the metrics reported by the health agent. For details on publishing enhanced health metrics to CloudWatch, see Publishing Amazon CloudWatch custom metrics for an environment.
Factors in determining instance and environment health
In addition to the basic health reporting system checks, including Elastic Load Balancing health checks and resource monitoring, Elastic Beanstalk enhanced health reporting gathers additional data about the state of the instances in your environment. This includes operating system metrics, server logs, and the state of ongoing environment operations such as deployments and updates. The Elastic Beanstalk health reporting service combines information from all available sources and analyzes it to determine the overall health of the environment.
Operations and commands
When you perform an operation on your environment, such as deploying a new version of an application, Elastic Beanstalk makes several changes that affect the environment's health status.
For example, when you deploy a new version of an application to an environment that is running multiple instances, you might see messages similar to the following as you monitor the environment's health with the EB CLI.
id status cause
Overall Info Command is executing on 3 out of 5 instances
i-bb65c145 Pending 91 % of CPU is in use. 24 % in I/O wait
Performing application deployment (running for 31 seconds)
i-ba65c144 Pending Performing initialization (running for 12 seconds)
i-f6a2d525 Ok Application deployment completed 23 seconds ago and took 26 seconds
i-e8a2d53b Pending 94 % of CPU is in use. 52 % in I/O wait
Performing application deployment (running for 33 seconds)
i-e81cca40 OkIn this example, the overall status of the environment is Ok and the cause of this status is that the Command is executing on
3 out of 5 instances. Three of the instances in the environment have the status Pending, indicating that an operation
is in progress.
When an operation completes, Elastic Beanstalk reports additional information about the operation. For the example, Elastic Beanstalk displays the following information about an instance that has already been updated with the new version of the application:
i-f6a2d525 Ok Application deployment completed 23 seconds ago and took 26 secondsInstance health information also includes details about the most recent deployment to each instance in your environment. Each instance reports a deployment ID and status. The deployment ID is an integer that increases by one each time you deploy a new version of your application or change settings for on-instance configuration options, such as environment variables. You can use the deployment information to identify instances that are running the wrong version of your application after a failed rolling deployment.
In the cause column, Elastic Beanstalk includes informational messages about successful operations and other healthy states across multiple health checks, but they don't persist indefinitely. Causes for unhealthy environment statuses persist until the environment returns to a healthy status.
Command timeout
Elastic Beanstalk applies a command timeout from the time an operation begins to allow an instance to transition into a healthy state. This command timeout is set in your environment's update and deployment configuration (in the aws:elasticbeanstalk:command namespace) and defaults to 10 minutes.
During rolling updates, Elastic Beanstalk applies a separate timeout to each batch in the operation. This timeout is set as part of the environment's rolling update configuration (in the aws:autoscaling:updatepolicy:rollingupdate namespace). If all instances in the batch are healthy within the rolling update timeout, the operation continues to the next batch. If not, the operation fails.
Note
If your application does not pass health checks with an OK status but is stable at a different level, you can set
the HealthCheckSuccessThreshold option in the aws:elasticbeanstalk:command namespace to change the level at which Elastic Beanstalk considers an instance to be healthy.
For a web server environment to be considered healthy, each instance in the environment or batch must pass 12 consecutive health checks over the course of two minutes. For a worker tier environment, each instance must pass 18 health checks. Before the command times out, Elastic Beanstalk doesn't lower an environment's health status when health checks fail. If the instances in the environment become healthy within the command timeout, the operation succeeds.
HTTP requests
When no operation is in progress on an environment, the primary source of information about instance and environment health is the web server logs for each instance. To determine the health of an instance and the overall health of the environment, Elastic Beanstalk considers the number of requests, the result of each request, and the speed at which each request was resolved.
On Linux-based platforms, Elastic Beanstalk reads and parses web server logs to get information about HTTP requests. On the Windows Server platform, Elastic Beanstalk receives this information directly from the IIS web server.
Your environment might not have an active web server. For example, the Multicontainer Docker platform doesn't include a web server. Other platforms include a web server, and your application might disable it. In these cases, your environment requires additional configuration to provide the Elastic Beanstalk health agent with logs in the format that it needs to relay health information to the Elastic Beanstalk service. See Enhanced health log format for details.
Operating system metrics
Elastic Beanstalk monitors operating system metrics reported by the health agent to identify instances that are consistently low on system resources.
See Instance metrics for details on the metrics reported by the health agent.
Health check rule customization
Elastic Beanstalk enhanced health reporting relies on a set of rules to determine the health of your environment. Some of these rules might not be appropriate for your particular application. A common case is an application that returns frequent HTTP 4xx errors by design. Elastic Beanstalk, using one of its default rules, concludes that something is going wrong, and changes your environment health status from OK to Warning, Degraded, or Severe, depending on the error rate. To handle this case correctly, Elastic Beanstalk allows you to configure this rule and ignore application HTTP 4xx errors. For details, see Configuring enhanced health rules for an environment.
Enhanced health roles
Enhanced health reporting requires two roles—a service role for Elastic Beanstalk and an instance profile for the environment. The service role allows Elastic Beanstalk to interact with other AWS services on your behalf to gather information about the resources in your environment. The instance profile allows the instances in your environment to write logs to Amazon S3 and to communicate enhanced health information to the Elastic Beanstalk service.
When you create an Elastic Beanstalk environment using the Elastic Beanstalk console or the EB CLI, Elastic Beanstalk creates a default service role and attaches required managed policies to a default instance profile for your environment.
If you use the API, an SDK, or the AWS CLI to create environments, you must create these roles in advance, and specify them during environment creation to use enhanced health. For instructions on creating appropriate roles for your environments, see Elastic Beanstalk Service roles, instance profiles, and user policies.
We recommend that you use managed policies for your instance profile and service role. Managed policies are AWS Identity and Access Management (IAM) policies that Elastic Beanstalk maintains. Using managed policies guarantees that your environment has all permissions it needs to function properly.
For the instance profile, you can use the AWSElasticBeanstalkWebTier or AWSElasticBeanstalkWorkerTier managed policy, for a
web server tier or worker tier environment, respectively. For details
about these two managed instance profile policies, see Managing Elastic Beanstalk instance profiles.
Enhanced health authorization
The Elastic Beanstalk instance profile managed policies contain permissions for the elasticbeanstalk:PutInstanceStatistics action. This action isn't
part of the Elastic Beanstalk API. It's part of a different API that environment instances use internally to communicate enhanced health information to the Elastic Beanstalk
service. You don't call this API directly.
When you create a new environment, authorization for the elasticbeanstalk:PutInstanceStatistics action is enabled by default. To increase
security of your environment and help prevent health data spoofing on your behalf, we recommend that you keep authorization for this action enabled. If
you use managed policies for your instance profile, this feature is available for your new environment without any further configuration. However, If you
use a custom instance profile instead of a managed policy, your environment might display a No
Data health status. This happens because the instances aren't authorized for the action that communicates enhanced health data to the
service.
To authorize the action, include the following statement in your instance profile.
{ "Sid": "ElasticBeanstalkHealthAccess", "Action": [ "elasticbeanstalk:PutInstanceStatistics" ], "Effect": "Allow", "Resource": [ "arn:aws:elasticbeanstalk:*:*:application/*", "arn:aws:elasticbeanstalk:*:*:environment/*" ] }
If you don’t want to use enhanced health authorization at this time, disable it by setting set the EnhancedHealthAuthEnabled option in
the aws:elasticbeanstalk:healthreporting:system namespace to false. If this option is disabled, the permissions
described previously aren’t required. You can remove them from the instance profile for
least privilege access to your applications and environments.
Note
Previously the default setting for EnhancedHealthAuthEnabled was false, which resulted in authorization for the
elasticbeanstalk:PutInstanceStatistics action also being disabled by default. To enable this action for an existing environment, set the
EnhancedHealthAuthEnabled option in the aws:elasticbeanstalk:healthreporting:system namespace to
true. You can configure this option by using an option setting in a configuration file.
Enhanced health events
The enhanced health system generates events when an environment transitions between states. The following example shows events output by an environment transitioning between Info, OK, and Severe states.
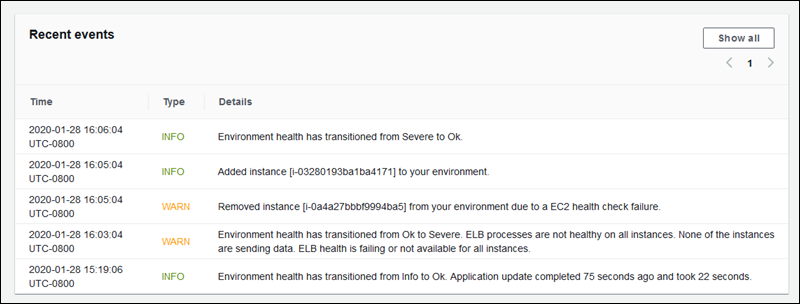
When transitioning to a worse state, the enhanced health event includes a message indicating the transition cause.
Not all changes in status at an instance level cause Elastic Beanstalk to emit an event. To prevent false alarms, Elastic Beanstalk generates a health-related event only if an issue persists across multiple checks.
Real-time environment-level health information, including status, color, and cause, is available in the environment overview page of the Elastic Beanstalk console and the EB CLI. By attaching the EB CLI to your environment and running the eb health command, you can also view real-time statuses from each of the instances in your environment.
Enhanced health reporting behavior during updates, deployments, and scaling
Enabling enhanced health reporting can affect how your environment behaves during configuration updates and deployments. Elastic Beanstalk won't complete a batch of updates until all of the instances pass health checks consistently. Also, because enhanced health reporting applies a higher standard for health and monitors more factors, instances that pass basic health reporting's ELB health check won't necessarily pass with enhanced health reporting. See the topics on rolling configuration updates and rolling deployments for details on how health checks affect the update process.
Enhanced health reporting can also highlight the need to set a proper health check URL for Elastic Load Balancing. When your environment scales up to meet demand, new instances will start taking requests as soon as they pass enough ELB health checks. If a health check URL is not configured, this can be as little as 20 seconds after a new instance is able to accept a TCP connection.
If your application hasn't finished starting up by the time the load balancer declares it healthy enough to receive traffic, you will see a flood of failed requests, and your environment will start to fail health checks. A health check URL that hits a path served by your application can prevent this issue. ELB health checks won't pass until a GET request to the health check URL returns a 200 status code.
