Uso de machine learning de Amazon Aurora con Aurora MySQL
Al utilizar el machine learning de Amazon Aurora con su clúster de base de datos de Aurora MySQL, puede utilizar Amazon Bedrock, Amazon Comprehend o IA de Amazon SageMaker, en función de sus necesidades. Cada uno admite casos de uso de machine learning diferentes.
Contenido
Requisitos para usar machine learning de Aurora con Aurora MySQL
Funciones y limitaciones compatibles del machine learning de Aurora con Aurora MySQL
Configuración del clúster de base de datos Aurora MySQL para utilizar el machine learning de Aurora
Configuración del clúster de base de datos de Aurora MySQL para utilizar Amazon Bedrock
Configuración del clúster de base de datos de Aurora MySQL para utilizar Amazon Comprehend
Configuración del clúster de base de datos de Aurora MySQL para utilizar IA de SageMaker
Concesión de acceso a los usuarios de bases de datos a machine learning de Aurora
Uso de Amazon Bedrock con el clúster de base de datos de Aurora MySQL
Uso de Amazon Comprehend con el clúster de base de datos de Aurora MySQL
Uso de IA de SageMaker con el clúster de base de datos de Aurora MySQL
Consideraciones sobre el rendimiento para utilizar el machine learning de Aurora con Aurora MySQL
Requisitos para usar machine learning de Aurora con Aurora MySQL
Los servicios de machine learning de AWS son servicios administrados que se configuran y ejecutan en sus propios entornos de producción. El machine learning de Aurora admite la integración con Amazon Bedrock, Amazon Comprehend e IA de SageMaker. Antes de intentar configurar el clúster de base de datos de Aurora MySQL para usar el machine learning de Aurora, asegúrese de comprender los siguientes requisitos y requisitos previos.
-
Los servicios de machine learning deben ejecutarse en la misma Región de AWS que su clúster de base de datos de Aurora MySQL. No puede utilizar los servicios de machine learning de un clúster de base de datos de Aurora MySQL en una región diferente.
-
Si su clúster de base de datos de Aurora MySQL se encuentra en una nube pública virtual (VPC) diferente a la de su servicio de Amazon Bedrock, Amazon Comprehend o IA de SageMaker, el grupo de seguridad de la VPC debe permitir las conexiones salientes al servicio de machine learning de Aurora de destino. Para obtener más información, consulte Controlar el tráfico hacia los recursos de AWS mediante grupos de seguridad en la Guía del usuario de Amazon VPC.
-
Puede actualizar un clúster de Aurora que ejecute una versión anterior de Aurora MySQL a una versión posterior compatible si desea utilizar el machine learning de Aurora con ese clúster. Para obtener más información, consulte Actualizaciones del motor de base de datos de Amazon Aurora MySQL.
-
Su clúster de base de datos de Aurora MySQL debe utilizar un grupo de parámetros de clúster de base de datos personalizado. Al final del proceso de configuración de cada servicio de machine learning de Aurora que desee utilizar, añada el nombre de recurso de Amazon (ARN) del rol de IAM asociado que se creó para el servicio. Le recomendamos que cree un grupo de parámetros de clúster de base de datos personalizado para su Aurora MySQL con antelación y que configure su clúster de base de datos de Aurora MySQL para usarlo de modo que esté listo para modificarlo al final del proceso de configuración.
-
Para IA de SageMaker:
-
Los componentes de machine learning que desee usar para las inferencias deben estar configurados y listos para usarse. Durante el proceso de configuración de su clúster de base de datos de Aurora MySQL, asegúrese de tener disponible el ARN del punto de conexión de IA de SageMaker. Es probable que los científicos de datos de su equipo sean los más capacitados para trabajar con IA de SageMaker para preparar los modelos y gestionar otras tareas similares. Para empezar a utilizar IA de Amazon SageMaker, consulte Get Started with Amazon SageMaker AI. Para obtener más información sobre inferencias y puntos de conexión, consulte Inferencia en tiempo real.
-
Para utilizar IA de SageMaker con sus propios datos de entrenamiento, debe configurar un bucket de Amazon S3 como parte de la configuración de Aurora MySQL para el machine learning de Aurora. Para ello, siga el mismo proceso general utilizado para configurar la integración de IA de SageMaker. Para obtener un resumen de este proceso de configuración opcional, consulte Configuración del clúster de base de datos de Aurora MySQL para utilizar Amazon S3 para IA de SageMaker (opcional).
-
-
Para las bases de datos globales de Aurora, debe configurar los servicios de machine learning de Aurora que desea utilizar en todas las Regiones de AWS que conforman la base de datos global de Aurora. Por ejemplo, si desea utilizar el machine learning de Aurora con IA de SageMaker para su base de datos global de Aurora, haga lo siguiente para cada clúster de base de datos de Aurora MySQL en cada Región de AWS:
-
Configure los servicios de IA de Amazon SageMaker con los mismos modelos de entrenamiento y puntos de conexión de IA de SageMaker. También deben usar los mismos nombres.
-
Cree los roles de IAM tal y como se detalla en Configuración del clúster de base de datos Aurora MySQL para utilizar el machine learning de Aurora.
-
Agregue el ARN del rol de IAM al grupo de parámetros del clúster de base de datos personalizado para cada clúster de base de datos de Aurora MySQL en cada Región de AWS.
Estas tareas requieren que el machine learning de Aurora esté disponible para su versión de Aurora MySQL en todas las Regiones de AWS que conforman la base de datos global de Aurora.
-
Disponibilidad en regiones y versiones
La disponibilidad de las características varía según las versiones específicas de cada motor de base de datos de Aurora y entre Regiones de AWS.
-
Para obtener información sobre la disponibilidad en versiones y regiones de Amazon Comprehend e IA de Amazon SageMaker con Aurora MySQL, consulte Machine Learning de Aurora con Aurora MySQL.
-
Amazon Bedrock solo es compatible con Aurora MySQL versión 3.06 y posteriores.
Para obtener información sobre la disponibilidad en regiones de Amazon Bedrock, consulte Model support by Región de AWS en la Guía del usuario de Amazon Bedrock.
Funciones y limitaciones compatibles del machine learning de Aurora con Aurora MySQL
Al usar Aurora MySQL con el machine learning de Aurora, se aplican las siguientes limitaciones:
-
La extensión de machine learning de Aurora no admite interfaces vectoriales.
-
Las integraciones de machine learning de Aurora no se admiten cuando se utilizan en un disparador.
Las funciones de machine learning de Aurora no son compatibles con la replicación de registro binario (binlog).
-
La opción
--binlog-format=STATEMENTgenera una excepción en las llamadas a las funciones de Machine Learning de Aurora. -
Las funciones de machine learning de Aurora son no deterministas, y las funciones almacenadas no deterministas no son compatibles con el formato binlog.
Para obtener más información, consulte Binary Logging Formats
en la documentación de MySQL. -
-
No se admiten las funciones almacenadas que llaman a tablas con columnas generadas siempre. Esto se aplica a cualquier función almacenada de Aurora MySQL. Para obtener más información sobre este tipo de columna, consulte CREAR TABLA y columnas generadas
en la documentación de MySQL. -
Las funciones de Amazon Bedrock no admiten
RETURNS JSON. Puede usarCONVERToCASTpara convertirTEXTenJSONsi es necesario. -
Amazon Bedrock no admite solicitudes por lotes.
-
Aurora MySQL es compatible con cualquier punto de conexión de IA de SageMaker que lea y escriba el formato de valores separados por comas (CSV), a través de un
ContentTypedetext/csv. Los siguientes algoritmos integrados de IA de SageMaker aceptan este formato:-
Linear Learner
-
Random Cut Forest
-
XGBoost
Para obtener más información sobre estos algoritmos, consulte Choose an Algorithm en la Guía para desarrolladores de IA de Amazon SageMaker.
-
Configuración del clúster de base de datos Aurora MySQL para utilizar el machine learning de Aurora
En los siguientes temas, puede encontrar procedimientos de configuración independientes para cada uno de estos servicios de machine learning de Aurora.
Temas
Configuración del clúster de base de datos de Aurora MySQL para utilizar Amazon Bedrock
Configuración del clúster de base de datos de Aurora MySQL para utilizar Amazon Comprehend
Configuración del clúster de base de datos de Aurora MySQL para utilizar IA de SageMaker
Concesión de acceso a los usuarios de bases de datos a machine learning de Aurora
Configuración del clúster de base de datos de Aurora MySQL para utilizar Amazon Bedrock
El machine learning de Aurora se basa en roles de AWS Identity and Access Management (IAM) y políticas para permitir que su clúster de base de datos de Aurora MySQL acceda a los servicios de Amazon Bedrock y los utilice. Los siguientes procedimientos crean una política de permisos y un rol de IAM para que el clúster de base de datos se pueda integrar con Amazon Bedrock.
Creación de la política de IAM
Inicie sesión en la AWS Management Console y abra la consola de IAM en https://console.aws.amazon.com/iam/
. -
En el panel de navegación, seleccione Políticas.
-
Elija Crear una política.
-
En la página Especificar permisos, en Seleccionar un servicio, elija Bedrock.
Aparecen los permisos de Amazon Bedrock.
-
Expanda Leer y, a continuación, seleccione InvokeModel.
-
En Recursos, seleccione Todos.
La página Especificar permisos debería parecerse a la de la siguiente figura.

-
Elija Siguiente.
-
En la página Revisar y crear, en introduzca un nombre para la política como, por ejemplo,
BedrockInvokeModel. -
Revise la política y luego seleccione Crear política.
A continuación, debe crear el rol de IAM que usa la política de permisos de Amazon Bedrock.
Creación del rol de IAM
Inicie sesión en la AWS Management Console y abra la consola de IAM en https://console.aws.amazon.com/iam/
. -
Seleccione Roles en el panel de navegación.
-
Elija Creación de rol.
-
En la página Seleccionar entidad de confianza, en Caso de uso, elija RDS.
-
Seleccione RDS - Agregar rol a la base de datos y, a continuación, elija Siguiente.
-
En la página Agregar permisos, en Políticas de permisos, seleccione la política de IAM que creó y, a continuación, seleccione Siguiente.
-
En la página Asignar nombre, revisar y crear, introduzca un nombre para su rol como, por ejemplo,
ams-bedrock-invoke-model-role.El rol debería parecerse al de la siguiente figura.
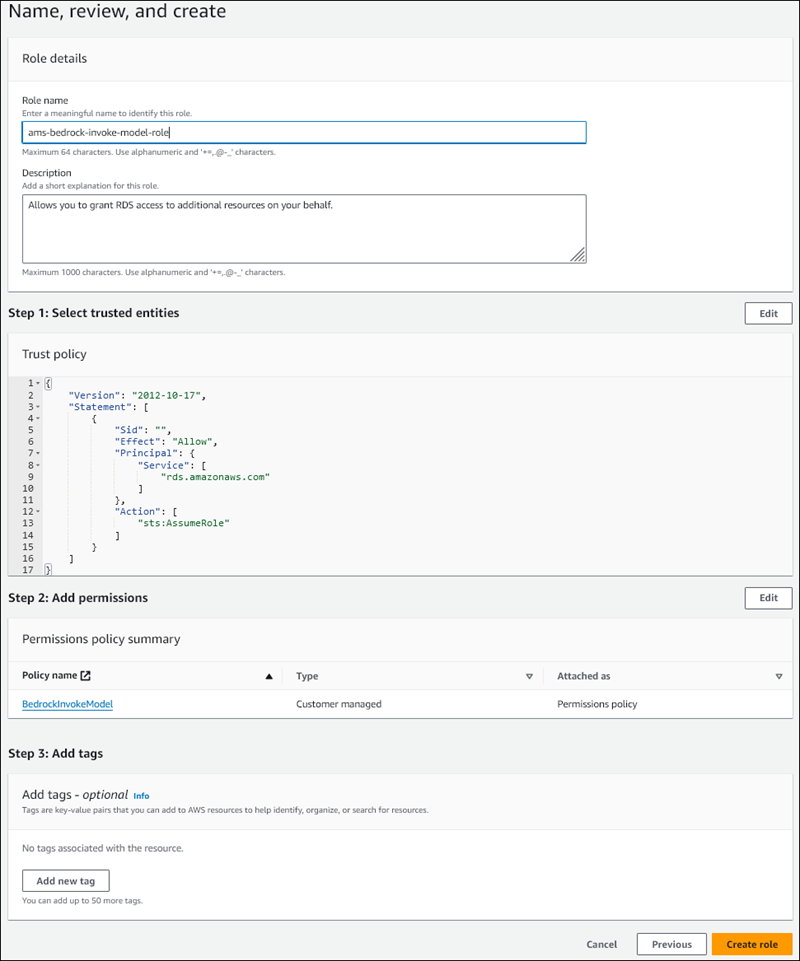
-
Revise el rol y, a continuación, elija Crear rol.
A continuación, asocie el rol de IAM de Amazon Bedrock con su clúster de base de datos.
Asociación del rol de IAM a su clúster de base de datos
Inicie sesión en la AWS Management Console y abra la consola de Amazon RDS en https://console.aws.amazon.com/rds/
. -
Elija Bases de datos en el panel de navegación.
-
Elija el clúster de base de datos de Aurora MySQL que desea conectar a los servicios de Amazon Bedrock.
-
Elija la pestaña Conectividad y seguridad.
-
En la sección Administrar los roles de IAM, elija Seleccionar roles de IAM para agregarlos a este clúster.
-
Elija el rol de IAM que creó y, a continuación, seleccione Agregar rol.
El rol de IAM está asociado a su clúster de base de datos, primero con el estado Pendiente y, después, Activo. Cuando se complete el proceso, puede encontrar el rol en la lista Current IAM roles for this clúster (Roles de IAM actuales para este clúster).
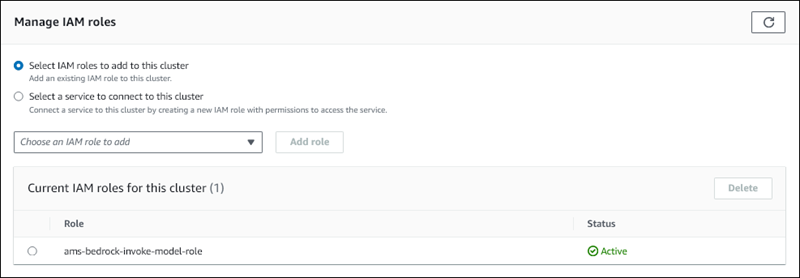
Debe agregar el ARN de este rol de IAM al parámetro aws_default_bedrock_role del grupo de parámetros del clúster de base de datos personalizado asociado a su clúster de base de datos de Aurora MySQL. Si el clúster de base de datos de Aurora MySQL no usa un grupo de parámetros de clúster de base de datos personalizado, debe crear uno para usarlo con el clúster de base de datos de Aurora MySQL para completar la integración. Para obtener más información, consulte Grupos de parámetros de clústeres de base de datos para clústeres de base de datos en Amazon Aurora.
Configuración del parámetro del clúster de base de datos
-
En la consola de Amazon RDS, abra la pestaña Configuración del clúster de base de datos de Aurora MySQL.
-
Localice el grupo de parámetros del clúster de base de datos configurado para su clúster. Elija el enlace para abrir el grupo de parámetros del clúster de base de datos personalizado y, a continuación elija Editar.
-
Busque el parámetro
aws_default_bedrock_roleen el grupo de parámetros del clúster de base de datos personalizado. -
En el campo Valor, escriba el ARN del rol de IAM.
-
Elija Guardar cambios, para guardar la configuración.
-
Reinicie la instancia principal del clúster de base de datos de Aurora MySQL para que se aplique esta configuración de parámetros.
La integración de IAM para Amazon Bedrock está completa. Continúe configurando su clúster de base de datos de Aurora MySQL para que funcione con Amazon Bedrock mediante Concesión de acceso a los usuarios de bases de datos a machine learning de Aurora.
Configuración del clúster de base de datos de Aurora MySQL para utilizar Amazon Comprehend
El machine learning de Aurora se basa en roles y políticas de AWS Identity and Access Management para permitir que su clúster de base de datos de Aurora MySQL acceda a los servicios de Amazon Comprehend y los utilice. El siguiente procedimiento crea automáticamente una política y un rol de IAM para su clúster, de modo que pueda usar Amazon Comprehend.
Para configurar el clúster de base de datos de Aurora MySQL para utilizar Amazon Comprehend
Inicie sesión en la AWS Management Console y abra la consola de Amazon RDS en https://console.aws.amazon.com/rds/
. -
Elija Bases de datos en el panel de navegación.
-
Elija el clúster de base de datos de Aurora MySQL que desea conectar a los servicios de Amazon Comprehend.
-
Elija la pestaña Conectividad y seguridad.
-
En la sección Administrar los roles de IAM, elija Seleccionar un servicio para conectarse a este clúster.
-
Elija Amazon Comprehend en el menú y, a continuación, seleccione Conectar servicio.
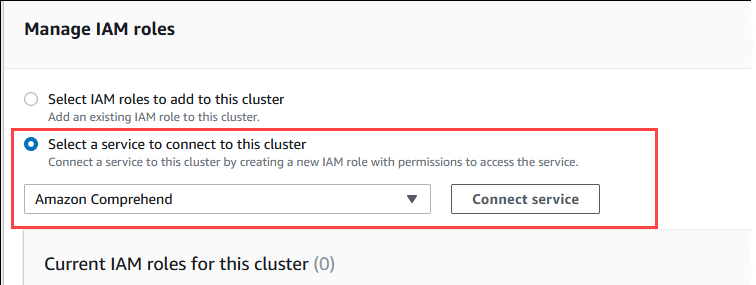
El cuadro de diálogo Connect clúster to Amazon Comprehend (Conectar el clúster a Amazon Comprehend) no requiere información adicional. Sin embargo, es posible que vea un mensaje que le notifique que la integración entre Aurora y Amazon Comprehend se encuentra actualmente en versión preliminar. Asegúrese de leer el mensaje antes de continuar. Puede elegir Cancelar si prefiere no continuar.
Elija Connect service (Conectar servicio) para completar el proceso de integración.
Aurora crea el rol de IAM. También crea la política que permite al clúster de base de datos de Aurora MySQL utilizar los servicios de Amazon Comprehend y asocia la política al rol. Cuando se complete el proceso, puede encontrar el rol en la lista Current IAM roles for this clúster (Roles de IAM actuales para este clúster), como se muestra en la siguiente imagen.
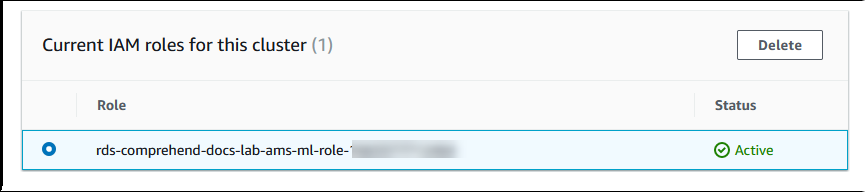
Debe agregar el ARN de este rol de IAM al parámetro
aws_default_comprehend_roledel grupo de parámetros del clúster de base de datos personalizado asociado a su clúster de base de datos de Aurora MySQL. Si el clúster de base de datos de Aurora MySQL no usa un grupo de parámetros de clúster de base de datos personalizado, debe crear uno para usarlo con el clúster de base de datos de Aurora MySQL para completar la integración. Para obtener más información, consulte Grupos de parámetros de clústeres de base de datos para clústeres de base de datos en Amazon Aurora.Tras crear el grupo de parámetros del clúster de base de datos personalizado y asociarlo al clúster de base de datos de Aurora MySQL, puede seguir estos pasos.
Si el clúster utiliza un grupo de parámetros del clúster de base de datos personalizado, haga lo siguiente.
En la consola de Amazon RDS, abra la pestaña Configuración del clúster de base de datos de Aurora MySQL.
-
Localice el grupo de parámetros del clúster de base de datos configurado para su clúster. Elija el enlace para abrir el grupo de parámetros del clúster de base de datos personalizado y, a continuación elija Editar.
Busque el parámetro
aws_default_comprehend_roleen el grupo de parámetros del clúster de base de datos personalizado.En el campo Valor, escriba el ARN del rol de IAM.
Elija Save Changes (Guardar cambios), para guardar la configuración. En la siguiente imagen, puede ver un ejemplo.
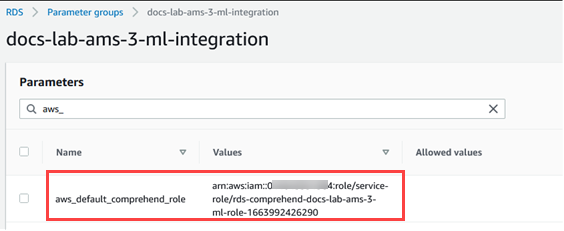
Reinicie la instancia principal del clúster de base de datos de Aurora MySQL para que se aplique esta configuración de parámetros.
La integración de IAM para Amazon Comprehend está completa. Siga configurando su clúster de base de datos Aurora MySQL para que funcione con Amazon Comprehend concediendo acceso a los usuarios de la base de datos adecuados.
Configuración del clúster de base de datos de Aurora MySQL para utilizar IA de SageMaker
El siguiente procedimiento crea automáticamente una política y un rol de IAM para su clúster de base de datos de Aurora MySQL, de modo que pueda usar IA de SageMaker. Antes de intentar seguir este procedimiento, asegúrese de tener disponible el punto de conexión de IA de SageMaker para poder introducirlo cuando sea necesario. Por lo general, los científicos de datos de su equipo se encargarían de crear un punto de conexión que pueda utilizar desde su clúster de base de datos de Aurora MySQL. Puede encontrar estos puntos de conexión en la consola de IA de SageMaker
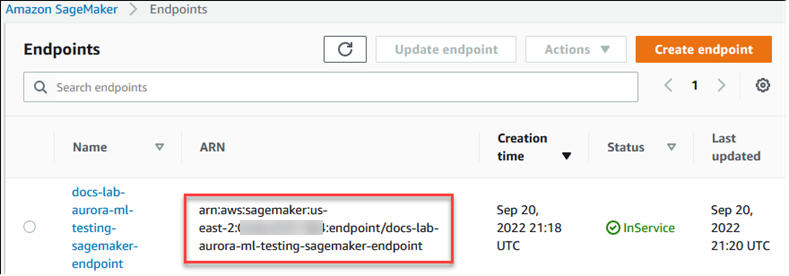
Configuración del clúster de base de datos Aurora MySQL para que utilice IA de SageMaker
Inicie sesión en la AWS Management Console y abra la consola de Amazon RDS en https://console.aws.amazon.com/rds/
. -
Elija Base de datos en el menú de navegación de Amazon RDS y, a continuación elija el clúster de base de datos de Aurora MySQL que desee conectar a los servicios de IA de SageMaker.
-
Elija la pestaña Conectividad y seguridad.
-
Desplácese a la sección Administrar roles de IAM y, a continuación, elija Seleccione un servicio para conectarse a este clúster. Elija IA de SageMaker en el selector.
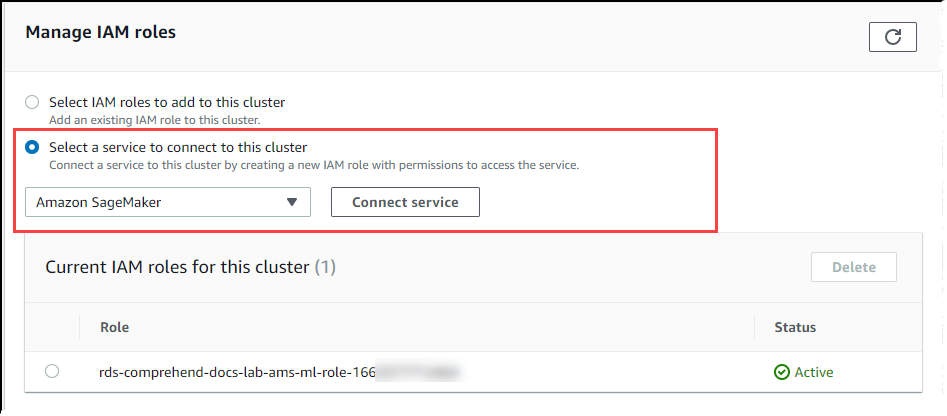
Elija Conectar servicio.
En el cuadro de diálogo Conectar el clúster a IA de SageMaker, escriba el ARN del punto de conexión de IA de SageMaker.
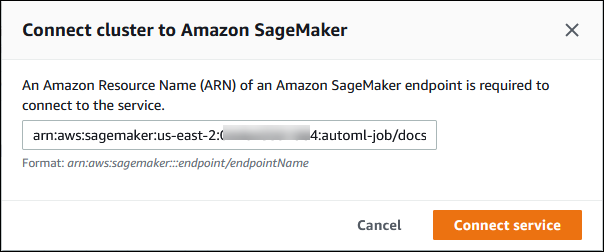
-
Aurora crea el rol de IAM. También crea la política que permite al clúster de base de datos de Aurora MySQL utilizar los servicios de IA de SageMaker y asocia la política al rol. Cuando se complete el proceso, puede encontrar el rol en la lista Roles de IAM actuales para este clúster.
Abra la consola de IAM en https://console.aws.amazon.com/iam/
. Elija Roles en la sección Gestión de acceso del menú de navegación de AWS Identity and Access Management.
Busque el rol entre los que figuran en la lista. Su nombre utiliza el siguiente patrón.
rds-sagemaker-your-cluster-name-role-auto-generated-digitsAbra la página de resumen del rol y localice el ARN. Anote el ARN o cópielo con el widget de copia.
Abra la consola de Amazon RDS en https://console.aws.amazon.com/rds/
. Elija el clúster de base de datos de Aurora MySQL y, a continuación, elija la pestaña Configuration (Configuración).
Localice el grupo de parámetros del clúster de base de datos y elija el enlace para abrir el grupo de parámetros del clúster de base de datos personalizado. Busque el parámetro
aws_default_sagemaker_rolee introduzca el ARN del rol de IAM en el campo Value (Valor) y guarde la configuración.Reinicie la instancia principal del clúster de base de datos de Aurora MySQL para que se aplique esta configuración de parámetros.
La configuración de IAM ya se ha completado. Siga configurando su clúster de base de datos Aurora MySQL para que funcione con IA de SageMaker concediendo acceso a los usuarios de la base de datos adecuados.
Si desea utilizar sus modelos de IA de SageMaker para el entrenamiento en lugar de utilizar componentes prediseñados de IA de SageMaker, también debe añadir el bucket de Amazon S3 a su clúster de base de datos de Aurora MySQL, tal y como se describe en Configuración del clúster de base de datos de Aurora MySQL para utilizar Amazon S3 para IA de SageMaker (opcional) a continuación.
Configuración del clúster de base de datos de Aurora MySQL para utilizar Amazon S3 para IA de SageMaker (opcional)
Para utilizar IA de SageMaker con sus propios modelos en lugar de utilizar los componentes prediseñados que ofrece IA de SageMaker, debe configurar un bucket de Amazon S3 para que lo utilice el clúster de base de datos de Aurora MySQL. Para obtener más información sobre la creación de un bucket de Amazon S3, consulte la sección de Creación de un bucket en la Guía del usuario de Amazon Simple Storage Service.
Configuración del clúster de base de datos Aurora MySQL para que utilice un bucket de Amazon S3 para IA de SageMaker
Inicie sesión en la AWS Management Console y abra la consola de Amazon RDS en https://console.aws.amazon.com/rds/
. -
Elija Base de datos en el menú de navegación de Amazon RDS y, a continuación elija el clúster de base de datos de Aurora MySQL que desee conectar a los servicios de IA de SageMaker.
-
Elija la pestaña Conectividad y seguridad.
-
Desplácese a la sección Manage IAM roles (Administrar roles de IAM) y, a continuación, elija Select a service to connect to this clúster (Seleccione un servicio para conectarse a este clúster). Elija Amazon S3 en el selector.
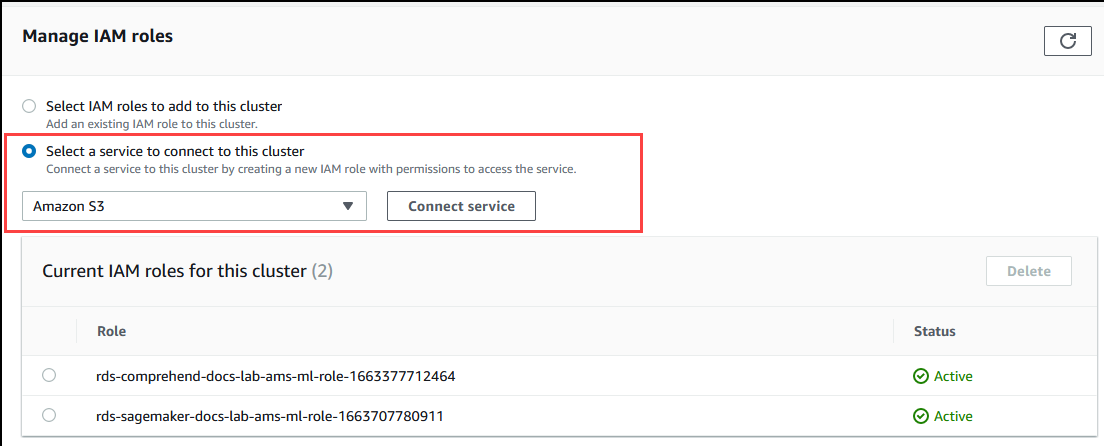
Elija Conectar servicio.
En el cuadro de diálogo Conectar el clúster a Amazon S3, escriba el ARN del bucket de Amazon S3, según se muestra en la imagen siguiente.

Elija Conectar servicio para completar este proceso.
Para obtener más información sobre el uso de los buckets de Amazon S3 con IA de SageMaker, consulte Specify an Amazon S3 Bucket to Upload Training Datasets and Store Output Data en la Guía para desarrolladores de IA de Amazon SageMaker. Para obtener más información sobre cómo trabajar con IA de SageMaker, consulte Get Started with Amazon SageMaker AI Notebook Instances en la Guía para desarrolladores de Amazon SageMaker.
Concesión de acceso a los usuarios de bases de datos a machine learning de Aurora
Los usuarios de la base de datos deben tener permiso para invocar las funciones de machine learning de Aurora. La forma de conceder los permisos depende de la versión de MySQL que utilice para el clúster de base de datos Aurora MySQL, tal como se describe a continuación. La forma de hacerlo depende de la versión de MySQL que utilice el clúster de base de datos de Aurora MySQL.
Para la versión 3 de Aurora MySQL (compatible con MySQL 8.0), los usuarios de bases de datos deben tener el rol de base de datos adecuado. Para obtener más información, consulte Using Roles
en el Manual de referencia de MySQL 8.0. Para la versión 2 de Aurora MySQ (compatible con MySQL 5.7), los usuarios de bases de datos tienen privilegios. Para obtener más información, consulte Access Control and Account Management
en el Manual de referencia de MySQL 5.7.
La siguiente tabla muestra los roles y los privilegios que los usuarios de bases de datos necesitan para trabajar con funciones de machine learning.
| Aurora MySQL versión 3 (rol) | Aurora MySQL versión 2 (privilegio) |
|---|---|
|
AWS_BEDROCK_ACCESS |
– |
|
AWS_COMPREHEND_ACCESS |
INVOKE COMPREHEND |
|
AWS_SAGEMAKER_ACCESS |
INVOKE SAGEMAKER |
Concesión de acceso a las funciones de Amazon Bedrock
Para dar a los usuarios de bases de datos acceso a las funciones de Amazon Bedrock, utilice la siguiente instrucción de SQL:
GRANT AWS_BEDROCK_ACCESS TOuser@domain-or-ip-address;
Los usuarios de bases de datos también deben tener permisos EXECUTE para las funciones que cree para trabajar con Amazon Bedrock:
GRANT EXECUTE ON FUNCTIONdatabase_name.function_nameTOuser@domain-or-ip-address;
Por último, los usuarios de la base de datos deben tener sus roles configurados en:AWS_BEDROCK_ACCESS
SET ROLE AWS_BEDROCK_ACCESS;
Las funciones de Amazon Bedrock ya están disponibles para su uso.
Concesión de acceso a las funciones de Amazon Comprehend
Para dar a los usuarios de bases de datos acceso a las funciones de Amazon Comprehend, utilice la sentencia correspondiente para su versión de Aurora MySQL.
Aurora MySQL versión 3 (compatible con MySQL 8.0)
GRANT AWS_COMPREHEND_ACCESS TOuser@domain-or-ip-address;Aurora MySQL versión 2 (compatible con MySQL 5.7)
GRANT INVOKE COMPREHEND ON *.* TOuser@domain-or-ip-address;
Las funciones de Amazon Comprehend ya están disponibles para su uso. Para ejemplos de uso, consulte Uso de Amazon Comprehend con el clúster de base de datos de Aurora MySQL.
Concesión de acceso a las funciones de IA de SageMaker
Para dar a los usuarios de bases de datos acceso a las funciones de IA de SageMaker, utilice la sentencia correspondiente para su versión de Aurora MySQL.
Aurora MySQL versión 3 (compatible con MySQL 8.0)
GRANT AWS_SAGEMAKER_ACCESS TOuser@domain-or-ip-address;Aurora MySQL versión 2 (compatible con MySQL 5.7)
GRANT INVOKE SAGEMAKER ON *.* TOuser@domain-or-ip-address;
Los usuarios de bases de datos también deben tener permisos EXECUTE para las funciones que cree para trabajar con IA de SageMaker. Supongamos que ha creado dos funciones db1.anomoly_score y db2.company_forecasts, para invocar los servicios de su punto de conexión de IA de SageMaker. Debe conceder privilegios de ejecución como se muestra en el siguiente ejemplo.
GRANT EXECUTE ON FUNCTION db1.anomaly_score TOuser1@domain-or-ip-address1; GRANT EXECUTE ON FUNCTION db2.company_forecasts TOuser2@domain-or-ip-address2;
Las funciones de IA de SageMaker ya están disponibles para su uso. Para ejemplos de uso, consulte Uso de IA de SageMaker con el clúster de base de datos de Aurora MySQL.
Uso de Amazon Bedrock con el clúster de base de datos de Aurora MySQL
Para utilizar Amazon Bedrock, debe crear una función definida por el usuario (UDF) en la base de datos de Aurora MySQL que invoque un modelo. Para obtener más información, consulte Modelos compatibles en Amazon Bedrock en la Guía del usuario de Amazon Bedrock.
Una UDF utiliza la siguiente sintaxis:
CREATE FUNCTIONfunction_name(argumenttype) [DEFINER = user] RETURNSmysql_data_type[SQL SECURITY {DEFINER | INVOKER}] ALIAS AWS_BEDROCK_INVOKE_MODEL MODEL ID 'model_id' [CONTENT_TYPE 'content_type'] [ACCEPT 'content_type'] [TIMEOUT_MStimeout_in_milliseconds];
-
Las funciones de Amazon Bedrock no admiten
RETURNS JSON. Puede usarCONVERToCASTpara convertirTEXTenJSONsi es necesario. -
Si no especifica
CONTENT_TYPEniACCEPT, el valor predeterminado esapplication/json. -
Si no especifica
TIMEOUT_MS, se utiliza el valor deaurora_ml_inference_timeout.
Por ejemplo, la siguiente UDF invoca el modelo Text Express de Amazon Titan:
CREATE FUNCTION invoke_titan (request_body TEXT) RETURNS TEXT ALIAS AWS_BEDROCK_INVOKE_MODEL MODEL ID 'amazon.titan-text-express-v1' CONTENT_TYPE 'application/json' ACCEPT 'application/json';
Para permitir que un usuario de base de datos utilice esta función, utilice el siguiente comando de SQL:
GRANT EXECUTE ON FUNCTIONdatabase_name.invoke_titan TOuser@domain-or-ip-address;
A continuación, el usuario puede llamar a invoke_titan como a cualquier otra función, como se muestra en el siguiente ejemplo. Asegúrese de formatear el cuerpo de la solicitud de acuerdo con los modelos de texto de Amazon Titan.
CREATE TABLE prompts (request varchar(1024)); INSERT INTO prompts VALUES ( '{ "inputText": "Generate synthetic data for daily product sales in various categories - include row number, product name, category, date of sale and price. Produce output in JSON format. Count records and ensure there are no more than 5.", "textGenerationConfig": { "maxTokenCount": 1024, "stopSequences": [], "temperature":0, "topP":1 } }'); SELECT invoke_titan(request) FROM prompts; {"inputTextTokenCount":44,"results":[{"tokenCount":296,"outputText":" ```tabular-data-json { "rows": [ { "Row Number": "1", "Product Name": "T-Shirt", "Category": "Clothing", "Date of Sale": "2024-01-01", "Price": "$20" }, { "Row Number": "2", "Product Name": "Jeans", "Category": "Clothing", "Date of Sale": "2024-01-02", "Price": "$30" }, { "Row Number": "3", "Product Name": "Hat", "Category": "Accessories", "Date of Sale": "2024-01-03", "Price": "$15" }, { "Row Number": "4", "Product Name": "Watch", "Category": "Accessories", "Date of Sale": "2024-01-04", "Price": "$40" }, { "Row Number": "5", "Product Name": "Phone Case", "Category": "Accessories", "Date of Sale": "2024-01-05", "Price": "$25" } ] } ```","completionReason":"FINISH"}]}
Para otros modelos que utilice, asegúrese de formatear el cuerpo de la solicitud de forma adecuada para ellos. Para obtener más información, consulte Inference parameters for foundation models en la Guía del usuario de Amazon Bedrock.
Uso de Amazon Comprehend con el clúster de base de datos de Aurora MySQL
Para Aurora MySQL, el machine learning de Aurora proporciona las dos funciones integradas siguientes para trabajar con Amazon Comprehend y sus datos de texto. Proporciona el texto para analizar (input_data) y especifica el idioma (language_code).
- aws_comprehend_detect_sentiment
-
Esta función identifica que el texto tiene una postura emocional positiva, negativa, neutra o mixta. La documentación de referencia de esta función es la siguiente.
aws_comprehend_detect_sentiment( input_text, language_code [,max_batch_size] )Para obtener más información, consulte Sentiment en la Guía para desarrolladores de Amazon Comprehend.
- aws_comprehend_detect_sentiment_confidence
-
Esta función mide el nivel de confianza del sentimiento detectado para un texto determinado. Devuelve un valor (type,
double) que indica la confianza del sentimiento asignado al texto por la función aws_comprehend_detect_sentiment. La confianza es una métrica estadística entre 0 y 1. Cuanto mayor sea el nivel de confianza, mayor será el peso que se le pueda dar al resultado. A continuación se presenta un resumen de la documentación de la función.aws_comprehend_detect_sentiment_confidence( input_text, language_code [,max_batch_size] )
En ambas funciones (aws_comprehend_detect_sentiment_confidence, aws_comprehend_detect_sentiment), max_batch_size utiliza un valor por defecto de 25 si no se especifica ninguno. El tamaño del lote siempre debe ser mayor que 0. Puede usar max_batch_size para ajustar el rendimiento de las llamadas a funciones de Amazon Comprehend. Un tamaño de lote grande sacrifica un rendimiento más rápido por un mayor uso de la memoria en el clúster de base de datos de Aurora MySQL. Para obtener más información, consulte Consideraciones sobre el rendimiento para utilizar el machine learning de Aurora con Aurora MySQL.
Para obtener más información acerca de los parámetros y los tipos de valores devueltos en las funciones de detección de opiniones de Amazon Comprehend, consulte DetectSentiment.
ejemplo Ejemplo: una consulta sencilla con las funciones de Amazon Comprehend
Este es un ejemplo de una consulta sencilla que invoca estas dos funciones para ver el grado de satisfacción de los clientes con su equipo de soporte. Supongamos que tiene una tabla de base de datos (support) que almacena los comentarios de los clientes después de cada solicitud de ayuda. En esta consulta de ejemplo se aplican ambas funciones integradas al texto de la columna feedback de la tabla y se obtienen los resultados. Los valores de confianza devueltos por la función son dobles entre 0,0 (0,0) y 1,0 Para obtener resultados más legibles, esta consulta redondea los resultados a 6 decimales. Para facilitar las comparaciones, esta consulta también ordena los resultados en orden descendente, empezando por el que tiene el mayor grado de confianza.
SELECT feedback AS 'Customer feedback', aws_comprehend_detect_sentiment(feedback, 'en') AS Sentiment, ROUND(aws_comprehend_detect_sentiment_confidence(feedback, 'en'), 6) AS Confidence FROM support ORDER BY Confidence DESC;+----------------------------------------------------------+-----------+------------+ | Customer feedback | Sentiment | Confidence | +----------------------------------------------------------+-----------+------------+ | Thank you for the excellent customer support! | POSITIVE | 0.999771 | | The latest version of this product stinks! | NEGATIVE | 0.999184 | | Your support team is just awesome! I am blown away. | POSITIVE | 0.997774 | | Your product is too complex, but your support is great. | MIXED | 0.957958 | | Your support tech helped me in fifteen minutes. | POSITIVE | 0.949491 | | My problem was never resolved! | NEGATIVE | 0.920644 | | When will the new version of this product be released? | NEUTRAL | 0.902706 | | I cannot stand that chatbot. | NEGATIVE | 0.895219 | | Your support tech talked down to me. | NEGATIVE | 0.868598 | | It took me way too long to get a real person. | NEGATIVE | 0.481805 | +----------------------------------------------------------+-----------+------------+ 10 rows in set (0.1898 sec)
ejemplo Ejemplo: determinar el sentimiento medio de un texto por encima de un nivel de confianza específico
Una consulta de Amazon Comprehend típica busca filas en las que la opinión sea un valor determinado, con un nivel de confianza superior a un número determinado. Por ejemplo, la siguiente consulta muestra cómo puede determinar el promedio de la opinión de los documentos de la base de datos. La consulta tiene en cuenta solo los documentos en los que la confianza de la evaluación sea al menos del 80 %.
SELECT AVG(CASE aws_comprehend_detect_sentiment(productTable.document, 'en') WHEN 'POSITIVE' THEN 1.0 WHEN 'NEGATIVE' THEN -1.0 ELSE 0.0 END) AS avg_sentiment, COUNT(*) AS total FROM productTable WHERE productTable.productCode = 1302 AND aws_comprehend_detect_sentiment_confidence(productTable.document, 'en') >= 0.80;
Uso de IA de SageMaker con el clúster de base de datos de Aurora MySQL
Para usar la funcionalidad de IA de SageMaker desde su clúster de base de datos de Aurora MySQL, debe crear funciones almacenadas que integren las llamadas en el punto de conexión de IA de SageMaker y sus funciones de inferencia. Se logra utilizando CREATE FUNCTION de MySQL generalmente de la misma manera que lo hace para otras tareas de procesamiento en su clúster de base de datos de Aurora MySQL.
Para utilizar los modelos implementados en IA de SageMaker para la inferencia, cree funciones definidas por el usuario mediante las instrucciones en lenguaje de definición de datos (DDL) de MySQL para las funciones almacenadas. Cada función almacenada representa el punto de conexión de IA de SageMaker que aloja el modelo. Al definir una función así, especifique los paramentos de entrada en el modelo, el punto de conexión de IA de SageMaker específico que desee invocar y el tipo de valor devuelto. La función devuelve la inferencia calculada por el punto de conexión de IA de SageMaker después de aplicar el modelo a los parámetros de entrada.
Todas las funciones almacenadas de machine learning de Aurora devuelven tipos numéricos o VARCHAR. Puede utilizar cualquier tipo numérico excepto BIT. No se permiten otros tipos, como JSON, BLOB, TEXT y DATE.
En el siguiente ejemplo, se muestra la sintaxis de CREATE FUNCTION para trabajar con IA de SageMaker.
CREATE FUNCTION function_name (
arg1 type1,
arg2 type2, ...)
[DEFINER = user]
RETURNS mysql_type
[SQL SECURITY { DEFINER | INVOKER } ]
ALIAS AWS_SAGEMAKER_INVOKE_ENDPOINT
ENDPOINT NAME 'endpoint_name'
[MAX_BATCH_SIZE max_batch_size];
Esta es una extensión de la instrucción regular de DDL de CREATE FUNCTION. En la instrucción CREATE FUNCTION que define la función de IA de SageMaker, no se especifica el cuerpo de la función. En cambio, se especifica la palabra clave ALIAS donde normalmente va el cuerpo de la función. Actualmente, el machine learning de Aurora solo admite aws_sagemaker_invoke_endpoint en esta sintaxis ampliada. Debe especificar el parámetro endpoint_name. Un punto de conexión de IA de SageMaker puede tener diferentes características en cada modelo.
nota
Para obtener más información sobre CREATE FUNCTION, consulte las instrucciones CREATE PROCEDURSE y CREATE FUNCTION
El parámetro max_batch_size es opcional. De forma predeterminada, el tamaño máximo de lote es 10 000. Puede utilizar este parámetro en la función para restringir el número máximo de entradas procesadas en una solicitud por lotes a IA de SageMaker. El parámetro max_batch_size puede ayudar a evitar un error provocado por entradas demasiado grandes o a hacer que IA de SageMaker devuelva una respuesta más rápidamente. Este parámetro afecta al tamaño de un búfer interno utilizado para el procesamiento de solicitudes de IA de SageMaker. Especificar un valor demasiado grande en max_batch_size podría provocar una sobrecarga significativa de la memoria en la instancia de base de datos.
Recomendamos que deje la opción MANIFEST en su valor predeterminado de OFF. Aunque puede utilizar la opción MANIFEST ON, algunas características de IA de SageMaker no pueden utilizar directamente el CSV exportado con esta opción. El formato del manifiesto no es compatible con el formato esperado del manifiesto en IA de SageMaker.
Puede crear una función almacenada independiente para cada uno de sus modelos de IA de SageMaker. Esta asignación de funciones a los modelos es obligatoria, porque un punto de conexión se asocia con un modelo específico y cada modelo acepta diferentes parámetros. El uso de tipos de SQL para las entradas del modelo y el tipo de salida del modelo ayuda a evitar errores de conversión de tipos que transfieren datos de manera bidireccional entre los servicios de AWS. Puede controlar quién puede aplicar el modelo. También puede controlar las características de tiempo de ejecución especificando un parámetro que represente el tamaño máximo del lote.
Actualmente, todas las funciones de machine learning de Aurora cuentan con la propiedad NOT DETERMINISTIC. Si no especifica dicha propiedad de manera explícita, Aurora establece NOT DETERMINISTIC automáticamente. Este requisito se debe a que el modelo de IA de SageMaker se puede modificar sin ninguna notificación dirigida a la base de datos. Si esto ocurre, las llamadas a una función de machine learning de Aurora podrían devolver resultados distintos para la misma entrada en una única transacción.
No puede utilizar las características CONTAINS SQL, NO SQL, READS SQL DATA o MODIFIES SQL DATA en la instrucción CREATE
FUNCTION.
A continuación, se muestra un ejemplo del uso de la invocación de un punto de conexión de IA de SageMaker para detectar anomalías. Hay un punto de conexión de IA de SageMaker random-cut-forest-model. El algoritmo random-cut-forest ya ha entrenado el modelo correspondiente. En cada entrada, el modelo devuelve el origen de una anomalía. En este ejemplo, se muestran los puntos de datos cuya puntuación es superior a 3 desviaciones estándar (aproximadamente el percentil 99,9) con respecto de la puntuación media.
CREATE FUNCTION anomaly_score(value real) returns real
alias aws_sagemaker_invoke_endpoint endpoint name 'random-cut-forest-model-demo';
set @score_cutoff = (select avg(anomaly_score(value)) + 3 * std(anomaly_score(value)) from nyc_taxi);
select *, anomaly_detection(value) score from nyc_taxi
where anomaly_detection(value) > @score_cutoff;
Requisito del conjunto de caracteres en las funciones de IA de SageMaker que devuelven cadenas
Recomendamos especificar un conjunto de caracteres de utf8mb4 como el tipo de valor devuelto en las funciones de IA de SageMaker que devuelven valores de cadena. Si no resulta útil, utilice una longitud de cadena lo suficientemente grande para que el tipo de valor devuelto retenga un valor representado en el conjunto de caracteres utf8mb4. En el siguiente ejemplo, se muestra cómo declarar el conjunto de caracteres utf8mb4 en la función.
CREATE FUNCTION my_ml_func(...) RETURNS VARCHAR(5) CHARSET utf8mb4 ALIAS ...Actualmente, todas las funciones de IA de SageMaker que devuelven una cadena utilizan el conjunto de caracteres utf8mb4 en el valor devuelto. El valor devuelto utiliza este conjunto de caracteres aunque la función de IA de SageMaker declare implícita o explícitamente un conjunto de caracteres diferente para su tipo de valor devuelto. Si la función de IA de SageMaker declara otro conjunto de caracteres para el valor devuelto, los datos devueltos podrían truncarse inadvertidamente si los almacena en la columna de una tabla que no sea lo suficientemente grande. Por ejemplo, una consulta con una cláusula DISTINCT crea una tabla temporal. Así, el resultado de la función de IA de SageMaker se podría truncar debido a la manera en que las cadenas se gestionan internamente durante una consulta.
Exportación de datos a Amazon S3 para el entrenamiento de modelos de IA de SageMaker (avanzado)
Le recomendamos que comience a usar el machine learning de Aurora e IA de SageMaker utilizando algunos de los algoritmos proporcionados, y que los científicos de datos de su equipo le proporcionen los puntos de conexión de IA de SageMaker que pueda usar con su código SQL. A continuación, encontrará información mínima sobre el uso de su propio bucket de Amazon S3 con sus propios modelos de IA de SageMaker y su clúster de base de datos Aurora MySQL.
El machine learning consta de dos pasos principales: entrenamiento e inferencia. Para entrenar modelos de IA de SageMaker, exporte los datos a un bucket de Amazon S3. Una instancia de cuaderno de Jupyter de IA de SageMaker utiliza el bucket de Amazon S3 para entrenar el modelo antes de que se implemente. La instrucción SELECT INTO OUTFILE S3 permite consultar datos de un clúster de bases de datos Aurora MySQL y guardarlos directamente en archivos de texto almacenados en un bucket de Amazon S3. A continuación, la instancia de bloc de notas consume los datos del bucket de Amazon S3 para el entrenamiento.
El machine learning de Aurora amplía la sintaxis de SELECT INTO OUTFILE existente en Aurora MySQL para exportar los datos a formato CSV. Los modelos que necesitan este formato para el entrenamiento pueden consumir directamente el archivo CSV generado.
SELECT * INTO OUTFILE S3 's3_uri' [FORMAT {CSV|TEXT} [HEADER]] FROM table_name;La ampliación admite el formato CSV estándar.
-
El formato
TEXTes el mismo que el formato de exportación de MySQL existente. Este es el formato predeterminado. -
El formato
CSVes un formato introducido recientemente que sigue la especificación de RFC-4180. -
Si especifique la palabra clave opcional
HEADER, el archivo de salida contiene una línea de encabezado. Las etiquetas de la línea de encabezado se corresponden con los nombres de las columnas de la instrucciónSELECT. -
Puede seguir utilizando las palabras claves
CSVyHEADERcomo identificadores.
La gramática y la sintaxis ampliadas de SELECT INTO son ahora las siguientes:
INTO OUTFILE S3 's3_uri'
[CHARACTER SET charset_name]
[FORMAT {CSV|TEXT} [HEADER]]
[{FIELDS | COLUMNS}
[TERMINATED BY 'string']
[[OPTIONALLY] ENCLOSED BY 'char']
[ESCAPED BY 'char']
]
[LINES
[STARTING BY 'string']
[TERMINATED BY 'string']
]
Consideraciones sobre el rendimiento para utilizar el machine learning de Aurora con Aurora MySQL
Los servicios de Amazon Bedrock, Amazon Comprehend e IA de SageMaker realizan la mayor parte del trabajo cuando se invocan mediante una función de machine learning de Aurora. Esto significa que puede escalar esos recursos según sea necesario, de forma independiente. Para su clúster de base de datos Aurora MySQL, puede hacer que sus llamadas a funciones sean lo más eficientes posible. A continuación, encontrará algunas consideraciones de rendimiento que debe tener en cuenta al trabajar con el machine learning de Aurora.
Modelo y petición
El rendimiento al utilizar Amazon Bedrock depende en gran medida del modelo y de la petición que utilice. Elija un modelo y una petición que sean óptimos para su caso de uso.
Caché de consultas
La caché de consulta de Aurora MySQL no funciona para las funciones de machine learning de Aurora. Aurora MySQL no almacena los resultados de las consultas en la caché de consultas para las sentencias SQL que llaman a las funciones de machine learning de Aurora.
Optimización de lotes para las llamadas a las funciones de machine learning de Aurora
El aspecto principal del rendimiento de machine learning de Aurora en el que puede influir desde el clúster de Aurora es la opción de modo de lote para las llamadas a las funciones almacenadas de machine learning de Aurora. Las funciones de Machine Learning normalmente requieren una sobrecarga sustancial, lo que hace que sea poco práctico llamar a un servicio externo por separado para cada fila. El machine learning de Aurora puede minimizar esta sobrecarga combinando las llamadas al servicio de machine learning de Aurora externo para muchas filas en un solo lote. El machine learning de Aurora recibe las respuestas de un lote de filas de entrada y, luego, devuelve las respuestas a la consulta en ejecución una fila a la vez. Esta optimización mejora el rendimiento y la latencia de las consultas de Aurora sin modificar los resultados.
Al crear una función almacenada de Aurora conectada a un punto de conexión de IA de SageMaker, se define el parámetro de tamaño del lote. Este parámetro influye en el número de filas que se transfieren en cada llamada subyacente a IA de SageMaker. En las consultas que procesan un número elevado de filas, la sobrecarga para realizar una llamada de IA de SageMaker independiente en cada fila puede ser significativa. Cuanto más grande sea el conjunto de datos procesado por el procedimiento almacenado, mayor puede ser el tamaño del lote.
Puede comprobar si se puede aplicar la optimización del modo de lote a una función de IA de SageMaker consultando el plan de consulta generado por la instrucción EXPLAIN PLAN. En este caso, la columna extra del plan de ejecución incluye Batched machine learning. En el siguiente ejemplo, se muestra una llamada a una función de IA de SageMaker que utiliza el modo de lote.
mysql> CREATE FUNCTION anomaly_score(val real) returns real alias aws_sagemaker_invoke_endpoint endpoint name 'my-rcf-model-20191126';
Query OK, 0 rows affected (0.01 sec)
mysql> explain select timestamp, value, anomaly_score(value) from nyc_taxi;
+----+-------------+----------+------------+------+---------------+------+---------+------+------+----------+--------------------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+----------+------------+------+---------------+------+---------+------+------+----------+--------------------------+
| 1 | SIMPLE | nyc_taxi | NULL | ALL | NULL | NULL | NULL | NULL | 48 | 100.00 | Batched machine learning |
+----+-------------+----------+------------+------+---------------+------+---------+------+------+----------+--------------------------+
1 row in set, 1 warning (0.01 sec)
Al llamar a una de las funciones de Amazon Comprehend integradas, puede controlar el tamaño del lote especificando el parámetro max_batch_size opcional. Este parámetro restringe el número máximo de valores input_text procesados en cada lote. El envío de varios elementos a la vez reduce el número de recorridos de ida y vuelta entre Aurora y Amazon Comprehend. Resulta útil limitar el tamaño del lote en situaciones como una consulta con una cláusula LIMIT. Al utilizar un valor pequeño para max_batch_size, puede evitar invocar Amazon Comprehend más veces que los textos de entrada que tenga.
La optimización de lotes para la evaluación de funciones de machine learning de Aurora se aplica en los siguientes casos:
-
Llamadas a funciones de la lista de selección o la cláusula
WHEREde instruccionesSELECT -
Llamadas a funciones presentes en la lista
VALUESde instruccionesINSERTyREPLACE -
Funciones de IA de SageMaker en valores
SETde instruccionesUPDATE:INSERT INTO MY_TABLE (col1, col2, col3) VALUES (ML_FUNC(1), ML_FUNC(2), ML_FUNC(3)), (ML_FUNC(4), ML_FUNC(5), ML_FUNC(6)); UPDATE MY_TABLE SET col1 = ML_FUNC(col2), SET col3 = ML_FUNC(col4) WHERE ...;
Monitorización del machine learning de Aurora
Puede monitorear las operaciones por lotes de machine learning de Aurora consultando varias variables globales, como en el siguiente ejemplo.
show status like 'Aurora_ml%';
Puede restablecer las variables de estado utilizando una instrucción FLUSH STATUS. Así, todas las cifras representan los valores totales, los promedios, etc., desde la última vez que se restableció la variable.
Aurora_ml_logical_request_cnt-
La cantidad de solicitudes lógicas que la instancia de base de datos ha evaluado para enviarse a los servicios de machine learning de Aurora desde el último restablecimiento de estado. Dependiendo de si se ha utilizado el procesamiento por lotes, este valor puede ser superior a
Aurora_ml_actual_request_cnt. Aurora_ml_logical_response_cnt-
El recuento acumulado de respuestas que recibe Aurora MySQL de los servicios de machine learning de Aurora en todas las consultas ejecutadas por usuarios de la instancia de base de datos.
Aurora_ml_actual_request_cnt-
El recuento acumulado de solicitudes que hace Aurora MySQL a los servicios de machine learning de Aurora en todas las consultas ejecutadas por usuarios de la instancia de base de datos.
Aurora_ml_actual_response_cnt-
El recuento acumulado de respuestas que recibe Aurora MySQL de los servicios de machine learning de Aurora en todas las consultas ejecutadas por usuarios de la instancia de base de datos.
Aurora_ml_cache_hit_cnt-
El número acumulado de aciertos de la caché interna que Aurora MySQL recibe de los servicios de machine learning de Aurora en todas las consultas ejecutadas por usuarios de la instancia de base de datos.
Aurora_ml_retry_request_cnt-
La cantidad de solicitudes reintentadas que la instancia de base de datos ha enviado a los servicios de machine learning de Aurora desde el último restablecimiento de estado.
Aurora_ml_single_request_cnt-
El número acumulado de funciones de machine learning de Aurora evaluadas por un modo distinto al modo de lote en todas las consultas ejecutadas por usuarios de la instancia de base de datos.
Para obtener información acerca del monitoreo del rendimiento de las operaciones de SageMaker llamadas desde las funciones del machine learning de Aurora, consulte Monitoreo de IA de Amazon SageMaker.
