Las traducciones son generadas a través de traducción automática. En caso de conflicto entre la traducción y la version original de inglés, prevalecerá la version en inglés.
Conexión con orígenes de datos
En Amazon SageMaker Canvas, puede importar datos desde una ubicación fuera de su sistema de archivos local a través de un AWS servicio, una plataforma SaaS u otras bases de datos mediante conectores JDBC. Por ejemplo, es posible que desee importar tablas desde un almacenamiento de datos en Amazon Redshift o puede que quiera importar datos de Google Analytics.
Cuando realice el flujo de trabajo de importación para importar datos en la aplicación de Canvas, podrá elegir el origen de datos y, a continuación, seleccionar los datos que desee importar. Para determinados orígenes de datos, como Snowflake y Amazon Redshift, debe especificar sus credenciales y agregar una conexión al origen de datos.
La siguiente captura de pantalla muestra la barra de herramientas de orígenes de datos del flujo de trabajo de importación, con todos los orígenes de datos disponibles resaltados. Solo puede importar datos de los orígenes de datos que estén disponibles. Póngase en contacto con el administrador si el origen de datos que desea no está disponible.
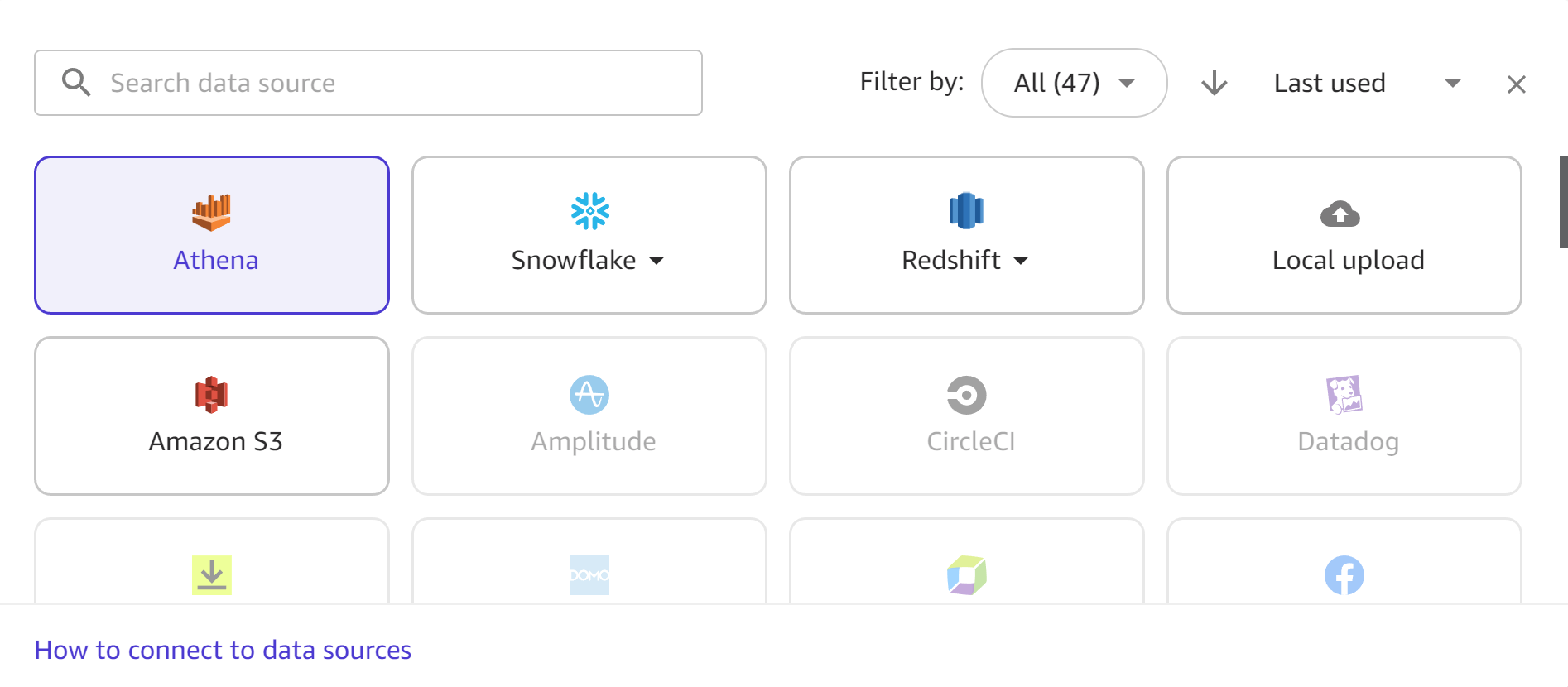
Las siguientes secciones proporcionan información sobre el establecimiento de conexiones con orígenes de datos externos y la importación de datos desde ellos. Revise primero la sección siguiente para determinar qué permisos necesita para importar datos desde su origen de datos.
Permisos
Revise la siguiente información para asegurarse de que dispone de los permisos necesarios para importar datos de su origen de datos:
Amazon S3: puede importar datos de cualquier bucket de Amazon S3 siempre que el usuario tenga permisos para acceder al bucket. Para obtener más información sobre el uso de AWS IAM para controlar el acceso a los buckets de Amazon S3, consulte Administración de identidad y acceso en Amazon S3 en la Guía del usuario de Amazon S3.
Amazon Athena: si tienes la AmazonSageMakerFullAccesspolítica y la AmazonSageMakerCanvasFullAccesspolítica asociada a la función de ejecución de tu usuario, puedes consultarla AWS Glue Data Catalog con Amazon Athena. Si forma parte de un grupo de trabajo de Athena, asegúrese de que el usuario de Canvas tenga permisos para ejecutar consultas de Athena en los datos. Si desea obtener más información, consulte Uso de grupos de trabajo para la ejecución de consultas en la Guía del usuario de Amazon Athena.
Amazon DocumentDB: puede importar datos de cualquier base de datos de Amazon DocumentDB siempre que tenga las credenciales (nombre de usuario y contraseña) para conectarse a la base de datos y tenga los permisos básicos mínimos de Canvas asociados al rol de ejecución del usuario. Para obtener más información acerca de los permisos de Canvas, consulte Requisitos previos para configurar Amazon Canvas SageMaker .
Amazon Redshift: para darse los permisos necesarios para importar datos de Amazon Redshift, consulte Concesión a los usuarios de permisos para importar datos de Amazon Redshift.
Amazon RDS: si tiene la AmazonSageMakerCanvasFullAccesspolítica asociada a la función de ejecución de su usuario, podrá acceder a sus bases de datos de Amazon RDS desde Canvas.
Plataformas SaaS: si tiene la AmazonSageMakerFullAccesspolítica y la AmazonSageMakerCanvasFullAccesspolítica asociadas a la función de ejecución de su usuario, entonces tiene los permisos necesarios para importar datos de las plataformas SaaS. Consulte Uso de conectores de SaaS con Canvas para obtener más información acerca de cómo conectarse a un conector de SaaS específico.
Conectores JDBC: para fuentes de bases de datos como Databricks, MySQL o MariaDB, debe habilitar la autenticación con nombre de usuario y contraseña en la base de datos de origen antes de intentar conectarse desde Canvas. Si se conecta a una base de datos de Databricks, debe tener la URL de JDBC que contenga las credenciales necesarias.
Conectarse a una base de datos almacenada en AWS
Es posible que desee importar los datos que ha almacenado AWS. Puede importar datos de Amazon S3, utilizar Amazon Athena para consultar una base de datos AWS Glue Data Catalog, importar datos de Amazon RDS o establecer una conexión a una base de datos de Amazon Redshift aprovisionada (no a Redshift Serverless).
Puede crear varias conexiones a Amazon Redshift. En el caso de Amazon Athena, puede acceder a cualquier base de datos que tenga en su AWS Glue Data Catalog. En el caso de Amazon S3, puede importar datos desde un bucket siempre que cuente con los permisos necesarios.
Revise las siguientes secciones para obtener información más detallada.
Conexión a los datos en Amazon S3, Amazon Athena o Amazon RDS
Para Amazon S3, puede importar datos de cualquier bucket de Amazon S3 siempre que tenga permisos para acceder al bucket.
En el caso de Amazon Athena, puede acceder a sus bases de datos AWS Glue Data Catalog siempre que tenga permisos a través de su grupo de trabajo de Amazon Athena.
En el caso de Amazon RDS, si tiene la AmazonSageMakerCanvasFullAccesspolítica asociada al rol de su usuario, podrá importar datos de sus bases de datos de Amazon RDS a Canvas.
Para importar datos de un bucket de Amazon S3 o para ejecutar consultas e importar tablas de datos con Amazon Athena, consulte Creación de un conjunto de datos. Solo puede importar datos tabulares desde Amazon Athena y puede importar datos tabulares y de imágenes de Amazon S3.
Conexión a una base de datos de Amazon DocumentDB
Amazon DocumentDB es un servicio de base de datos de documentos completamente administrado y sin servidor. Puede importar datos de documentos no estructurados almacenados en una base de datos de Amazon DocumentDB SageMaker a Canvas como un conjunto de datos tabular y, a continuación, puede crear modelos de aprendizaje automático con los datos.
importante
Su dominio de SageMaker IA debe estar configurado solo en modo VPC para añadir conexiones a Amazon DocumentDB. Solo puede acceder a clústeres de Amazon DocumentDB en la misma Amazon VPC que su aplicación de Canvas. Además, Canvas solo se puede conectar a clústeres de Amazon DocumentDB con TLS. Para obtener más información acerca de cómo configurar Canvas en el modo solo VPC, consulte Configurar Amazon SageMaker Canvas en una VPC sin acceso a Internet.
Para importar datos de las bases de datos de Amazon DocumentDB, debe tener credenciales para acceder a la base de datos de Amazon DocumentDB y especificar el nombre de usuario y la contraseña al crear una conexión a la base de datos. Puede configurar permisos más detallados y restringir el acceso modificando los permisos de usuario de Amazon DocumentDB. Para obtener más información sobre el control de acceso en Amazon DocumentDB, consulte Acceso a bases de datos mediante control de acceso basado en roles en la Guía para desarrolladores de Amazon DocumentDB.
Al importar desde Amazon DocumentDB, Canvas convierte los datos no estructurados en un conjunto de datos tabular mediante la asignación de los campos a las columnas de una tabla. Se crean tablas adicionales para cada campo complejo (o estructura anidada) de los datos, donde las columnas corresponden a los subcampos del campo complejo. Para obtener información más detallada sobre este proceso y ejemplos de conversión de esquemas, consulte la página de descubrimiento de esquemas de controladores JDBC de Amazon DocumentDB
Canvas solo puede establecer una conexión a una única base de datos en Amazon DocumentDB. Para importar datos de una base de datos distinta debe crear una conexión nueva.
Puede importar datos de Amazon DocumentDB a Canvas mediante los siguientes métodos:
-
Creación de un conjunto de datos. Puede importar datos de Amazon DocumentDB y crear un conjunto de datos tabular en Canvas. Si elige este método, asegúrese de seguir el procedimiento de Importación de datos tabulares.
-
Creación de un flujo de datos. Puede crear una canalización de preparación de datos en Canvas y añadir la base de datos de Amazon DocumentDB como origen de datos.
Para continuar con la importación de los datos, siga el procedimiento de uno de los métodos enlazados en la lista anterior.
Cuando llegue al paso en cualquiera de los flujos de trabajo para elegir un origen de datos (paso 6 para crear un conjunto de datos o paso 8 para crear un flujo de datos), haga lo siguiente:
En Origen de datos, abra el menú desplegable y seleccione DocumentDB.
Elija Agregar conexión.
-
En el cuadro de diálogo, especifique sus credenciales de Amazon DocumentDB:
Especifique un Nombre de la conexión. Canvas utiliza este nombre para identificar esta conexión.
En Clúster, seleccione el clúster de Amazon DocumentDB que almacena los datos. Canvas rellena automáticamente el menú desplegable con clústeres de Amazon DocumentDB en la misma VPC que la aplicación de Canvas.
Escriba el Nombre de usuario para el clúster de Amazon DocumentDB.
Escriba la Contraseña para el clúster de Amazon DocumentDB.
Escriba el nombre de la Base de datos a la que desea conectarse.
-
La opción de Preferencias de lectura determina los tipos de instancias del clúster desde los que Canvas lee los datos. Seleccione una de estas opciones:
Se prefiere secundaria: Canvas lee de forma predeterminada las instancias secundarias del clúster, pero si no hay una instancia secundaria disponible, Canvas lee una instancia principal.
Secundaria: Canvas solo lee las instancias secundarias del clúster, lo que evita que las operaciones de lectura interfieran en las operaciones de lectura y escritura habituales del clúster.
-
Elija Agregar conexión. La siguiente imagen muestra el cuadro de diálogo con los campos anteriores para una conexión a Amazon DocumentDB.
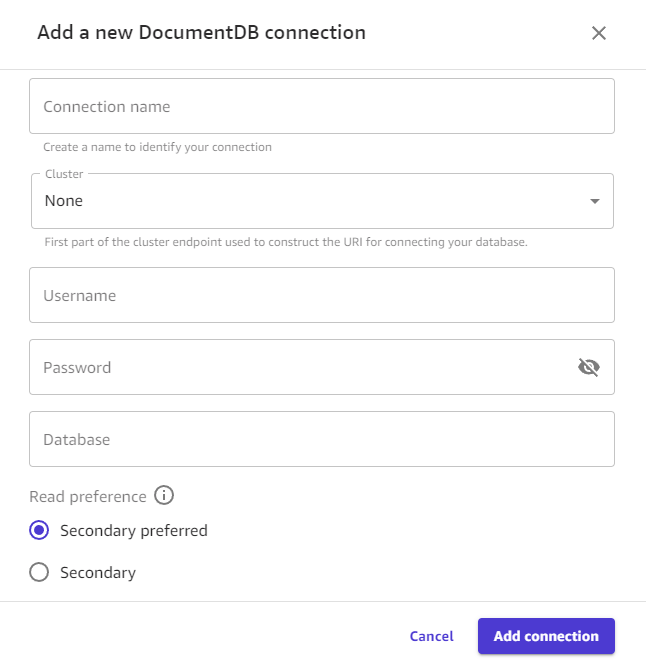
Ahora debería tener una conexión a Amazon DocumentDB y puede usar sus datos de Amazon DocumentDB en Canvas para crear un conjunto de datos o un flujo de datos.
Conexión a una base de datos de Amazon Redshift
Puede importar datos de Amazon Redshift, un almacenamiento de datos en el que su organización guarda sus datos. Para poder importar datos de Amazon Redshift, la función de AWS IAM que utilice debe tener la política AmazonRedshiftFullAccess gestionada adjunta. Para obtener instrucciones sobre cómo asociar esta política, consulte Concesión a los usuarios de permisos para importar datos de Amazon Redshift.
Para importar datos desde Amazon Redshift, haga lo siguiente:
-
Cree una conexión a una base de datos de Amazon Redshift.
-
Seleccione los datos que vaya a importar.
-
Importe los datos.
Puede usar el editor Amazon Redshift para arrastrar conjuntos de datos al panel de importación e importarlos a Canvas. SageMaker Para tener un mayor control sobre los valores devueltos en el conjunto de datos, se puede usar lo siguiente:
-
Consultas SQL
-
Uniones
Las consultas SQL le permiten personalizar la forma en que se importan los valores en el conjunto de datos. Por ejemplo, puede especificar las columnas devueltas en el conjunto de datos o el rango de valores de una columna.
Puede usar las uniones para combinar varios conjuntos de datos de Amazon Redshift en un solo conjunto de datos. Puede arrastrar sus conjuntos de datos desde Amazon Redshift al panel que le permite unir los conjuntos de datos.
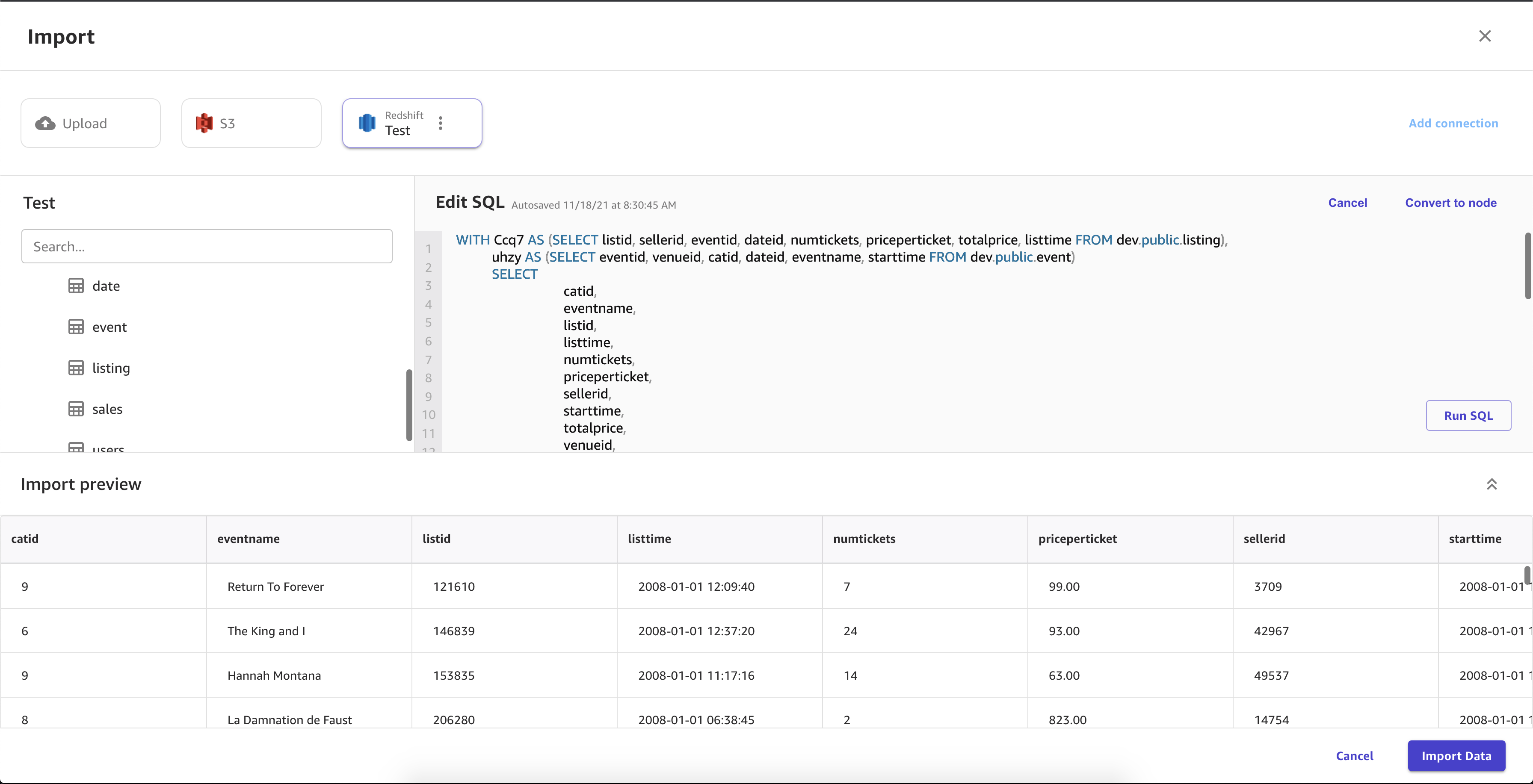
Puede usar el editor SQL para editar el conjunto de datos que ha unido y convertir el conjunto de datos unido en un solo nodo. Puede unir otro conjunto de datos en el nodo. Puede importar los datos que ha seleccionado a SageMaker Canvas.
Utilice el siguiente procedimiento para importar datos desde Amazon Redshift.
En la aplicación SageMaker Canvas, vaya a la página Conjuntos de datos.
Seleccione Importar datos y, en el menú desplegable, elija Tabular.
-
Escriba un nombre para el conjunto de datos y, a continuación, elija Crear.
Para Origen de datos, abra el menú desplegable y seleccione Redshift.
-
Elija Agregar conexión.
-
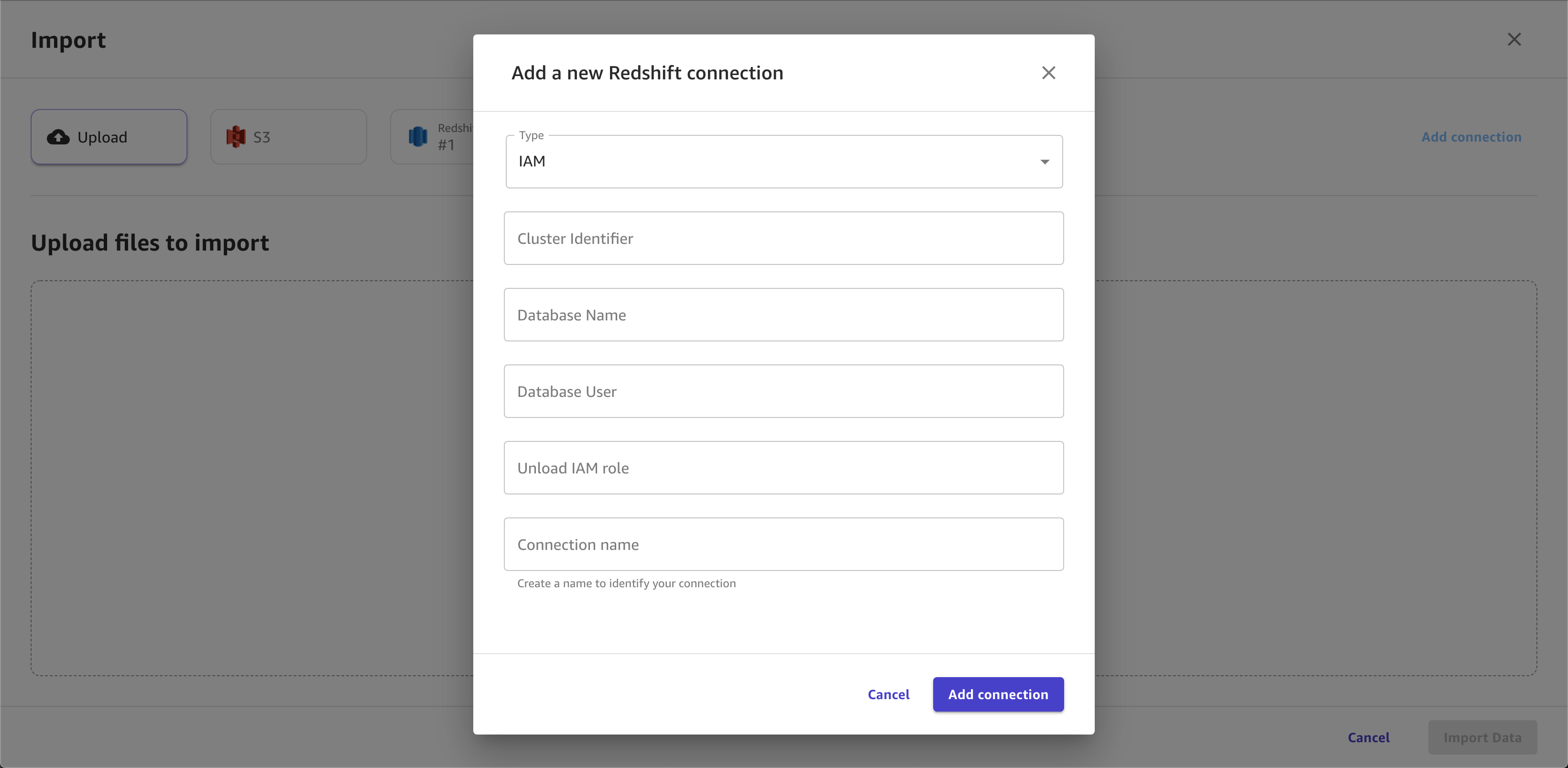
En el cuadro de diálogo, especifique sus credenciales de Amazon Redshift:
-
En Método de autenticación, seleccione IAM.
-
Ingrese el Identificador del clúster para especificar a qué clúster desea conectarse. Introduzca solo el identificador del clúster y no el punto de conexión completo del clúster de Amazon Redshift.
-
Especifique el Nombre de la base de datos a la que desea conectarse.
-
Ingrese un Usuario de la base de datos para identificar el usuario que desea utilizar para conectarse a la base de datos.
-
En ARN, especifique el ARN del rol de IAM del rol que debe asumir el clúster de Amazon Redshift para mover y escribir datos en Amazon S3. Para obtener más información sobre esta función, consulte Autorizar a Amazon Redshift a acceder a AWS otros servicios en su nombre en la Guía de administración de Amazon Redshift.
-
Especifique un Nombre de la conexión. Canvas utiliza este nombre para identificar esta conexión.
-
-
Desde la pestaña que tiene el nombre de su conexión, arrastre el archivo .csv que va a importar al panel Arrastrar y soltar para importar.
-
Opcional: Arrastrar tablas adicionales al panel de importación. Puede utilizar la interfaz gráfica de usuario para unir las tablas. Para obtener una mayor especificidad en las uniones, elija Editar en SQL.
-
Opcional: si utiliza SQL para consultar los datos, puede elegir Contexto para agregar contexto a la conexión especificando valores para lo siguiente:
-
Almacén
-
Base de datos
-
Esquema
-
-
Elija Importar datos.
En la imagen siguiente, se muestra un ejemplo de campos especificados para una conexión de Amazon Redshift.
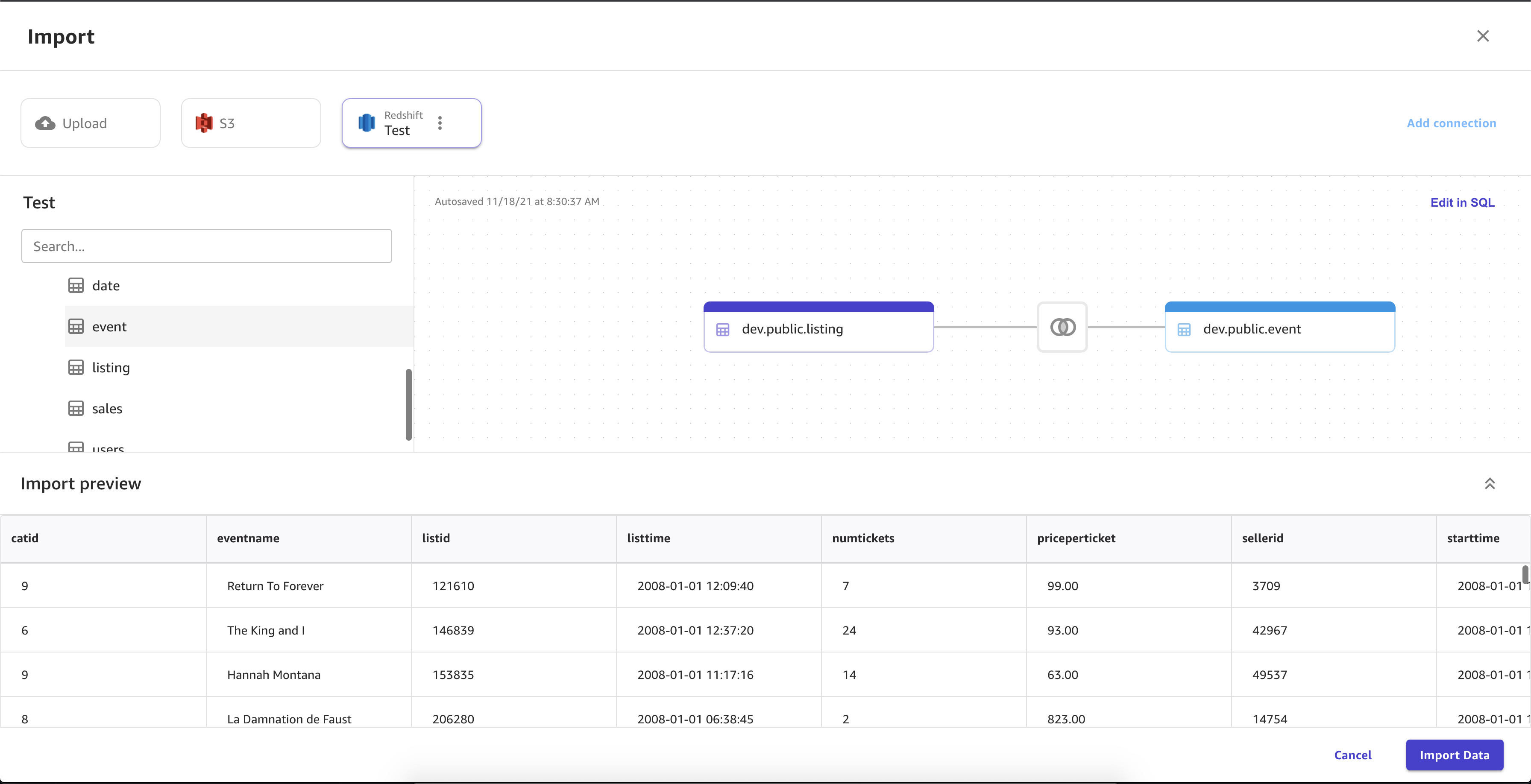
La siguiente imagen muestra la página utilizada para unir conjuntos de datos en Amazon Redshift.
La siguiente imagen muestra una consulta SQL que se utiliza para editar una unión en Amazon Redshift.
Conexión a sus datos con conectores JDBC
Con JDBC, puede conectarse a sus bases de datos desde fuentes como Databricks, MySQL, SQLServer PostgreSQL, MariaDB, Amazon RDS y Amazon Aurora.
Debe asegurarse de tener las credenciales y los permisos necesarios para crear la conexión desde Canvas.
En el caso de Databricks, debe proporcionar una URL de JDBC. El formato de la URL puede variar entre las instancias de Databricks. Para obtener información sobre cómo encontrar la URL y especificar los parámetros que contiene, consulte JDBC configuration and connection parameters
en la documentación de Databricks. A continuación, se muestra un ejemplo de cómo se puede formatear una URL: jdbc:spark://aws-sagemaker-datawrangler.cloud.databricks.com:443/default;transportMode=http;ssl=1;httpPath=sql/protocolv1/o/3122619508517275/0909-200301-cut318;AuthMech=3;UID=token;PWD=personal-access-tokenPara otros orígenes de bases de datos, debe configurar la autenticación con nombre de usuario y contraseña y, a continuación, especificar esas credenciales al conectarse a la base de datos desde Canvas.
Además, se debe poder acceder al origen de datos a través del Internet público o, si la aplicación de Canvas se ejecuta en modo solo VPC, el origen de datos debe ejecutarse en la misma VPC. Para obtener más información sobre la configuración de una base de datos de Amazon RDS en una VPC, consulte Amazon VPC VPCs y Amazon RDS en la Guía del usuario de Amazon RDS.
Tras configurar las credenciales de su origen de datos, puede iniciar sesión en la aplicación de Canvas y crear una conexión con el origen de datos. Especifique sus credenciales (o, en el caso de Databricks, la URL) al crear la conexión.
Conéctese a fuentes de datos con OAuth
Canvas admite su uso OAuth como método de autenticación para conectarse a sus datos en Snowflake y Salesforce Data Cloud. OAuth
nota
Solo puede establecer una OAuth conexión para cada fuente de datos.
Para autorizar la conexión, debe seguir la configuración inicial descrita en Configure las conexiones a las fuentes de datos con OAuth.
Tras configurar las OAuth credenciales, puede hacer lo siguiente para añadir una conexión de Snowflake o Salesforce Data Cloud con: OAuth
Inicie sesión en la aplicación de Canvas.
Cree un conjunto de datos tabular. Cuando se le pida que cargue datos, elija Snowflake o Salesforce Data Cloud como origen de datos.
Cree una nueva conexión a su origen de datos de Snowflake o Salesforce Data Cloud. Especifique el método OAuth de autenticación e introduzca los detalles de la conexión.
Ahora debería poder importar datos de sus bases de datos en Snowflake o Salesforce Data Cloud.
Conexión a una plataforma SaaS
Puede importar datos de Snowflake y de más de 40 plataformas de SaaS externas. Para obtener una lista completa de conectores, consulte la tabla de Importación de datos.
nota
Solo puede importar datos tabulares, como tablas de datos, desde plataformas de SaaS.
Uso de Snowflake con Canvas
Snowflake es un servicio de almacenamiento y análisis de datos, y puede importar sus datos de Snowflake a Canvas. SageMaker Para obtener más información acerca de Snowflake, consulte la documentación de Snowflake
Puede importar datos desde su cuenta de Snowflake por medio del siguiente procedimiento:
-
Crear una conexión a la base de datos de Snowflake.
-
Seleccionar los datos que va a importar arrastrando y soltando la tabla desde el menú de navegación de la izquierda hasta el editor.
-
Importe los datos.
Puede usar el editor Snowflake para arrastrar conjuntos de datos al panel de importación e importarlos a Canvas. SageMaker Para tener un mayor control sobre los valores devueltos en el conjunto de datos, se puede usar lo siguiente:
-
Consultas SQL
-
Uniones
Las consultas SQL le permiten personalizar la forma en que se importan los valores en el conjunto de datos. Por ejemplo, puede especificar las columnas devueltas en el conjunto de datos o el rango de valores de una columna.
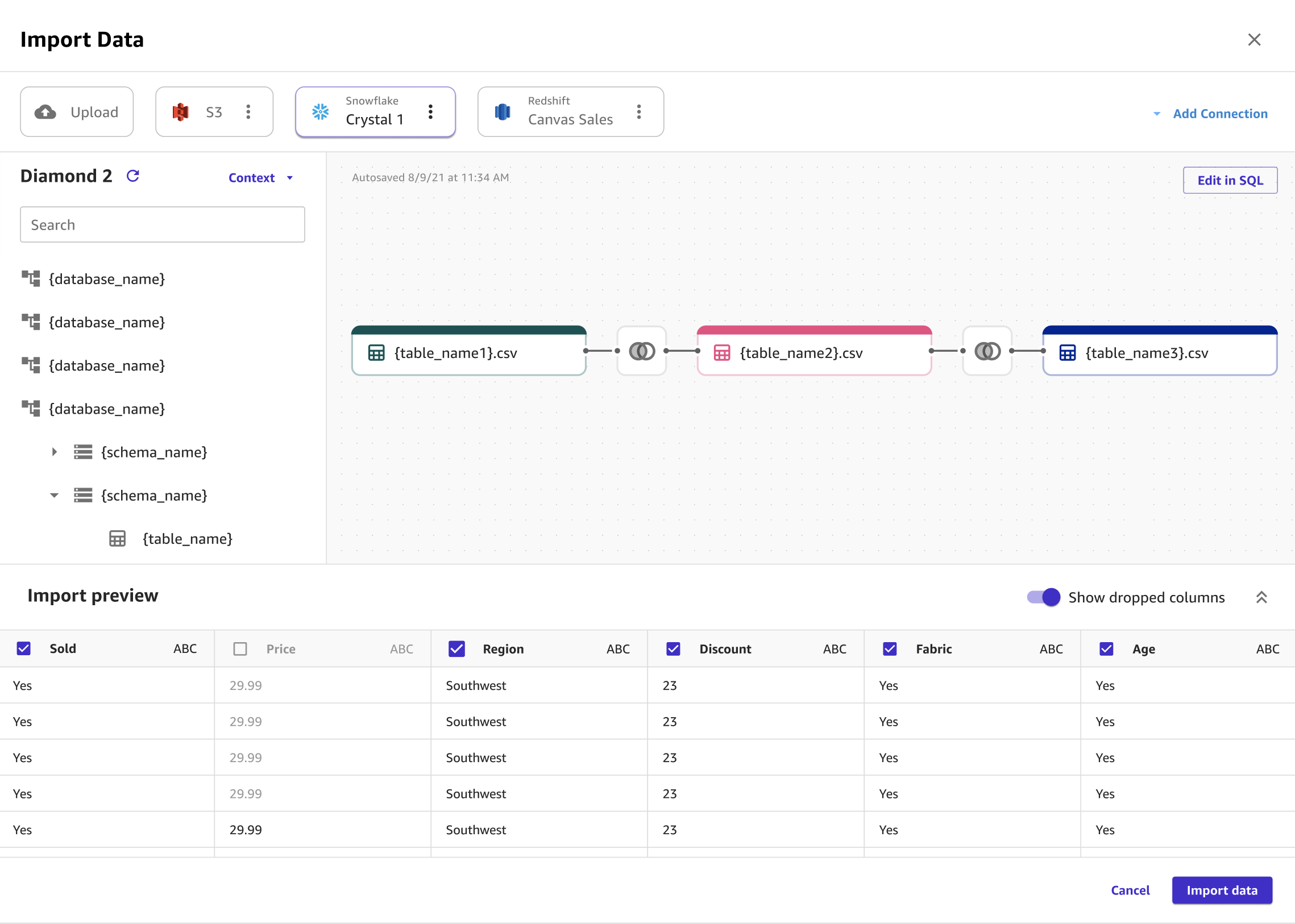
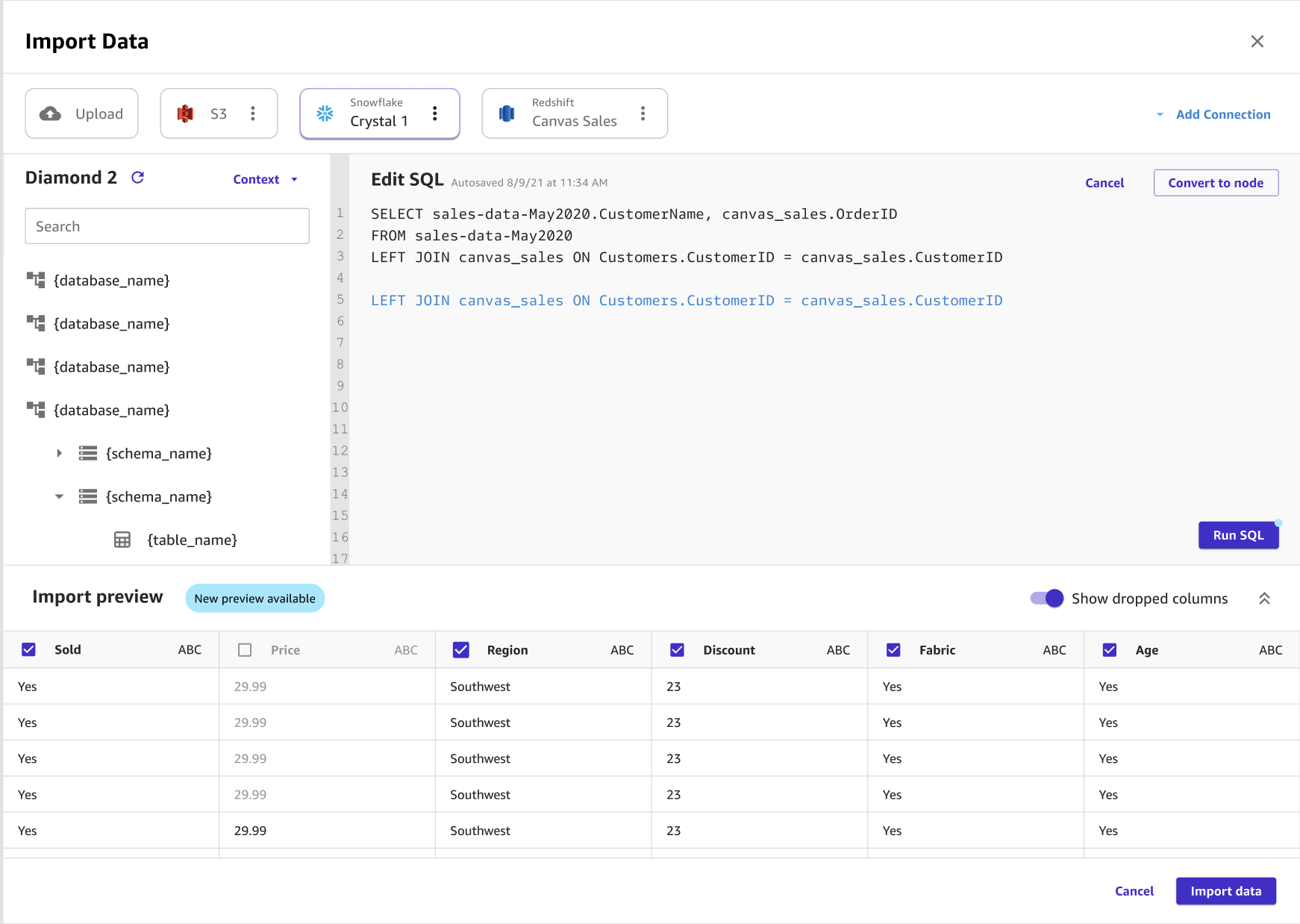
Puede unir varios conjuntos de datos de Snowflake en un solo conjunto de datos antes de importarlos a Canvas mediante SQL o la interfaz de Canvas. Puede arrastrar los conjuntos de datos de Snowflake al panel que le permite unir los conjuntos de datos, o bien puede editar las combinaciones en SQL y convertir el SQL en un solo nodo. Puede unir otros nodos con el nodo que ha convertido. A continuación, puede combinar los conjuntos de datos que ha unido en un único nodo y unir los nodos con un conjunto de datos de Snowflake diferente. Por último, puede importar los datos que ha seleccionado a Canvas.
Utilice el siguiente procedimiento para importar datos de Snowflake a Amazon SageMaker Canvas.
En la aplicación SageMaker Canvas, vaya a la página Conjuntos de datos.
Seleccione Importar datos y, en el menú desplegable, elija Tabular.
-
Escriba un nombre para el conjunto de datos y, a continuación, elija Crear.
Para Origen de datos, abra el menú desplegable y seleccione Snowflake.
-
Elija Agregar conexión.
-
En el cuadro de diálogo Agregar una nueva conexión a Snowflake, especifique sus credenciales de Snowflake. En Método de autenticación, elija una de las siguientes opciones:
Básico: nombre de usuario y contraseña: indique su ID de cuenta, nombre de usuario y contraseña de Snowflake.
-
ARN: para mejorar la protección de sus credenciales de Snowflake, proporcione el ARN de un AWS Secrets Manager secreto que contenga sus credenciales. Para obtener más información, consulte Crear un AWS Secrets Manager secreto en la Guía del usuario.AWS Secrets Manager
El secreto debe contener las credenciales de Snowflake almacenadas en el siguiente formato JSON:
{"accountid": "ID", "username": "username", "password": "password"} OAuth— OAuth permite autenticarse sin necesidad de proporcionar una contraseña, pero requiere una configuración adicional. Para obtener más información sobre la configuración de OAuth las credenciales de Snowflake, consulte. Configure las conexiones a las fuentes de datos con OAuth
-
Elija Agregar conexión.
-
Desde la pestaña que tiene el nombre de su conexión, arrastre el archivo .csv que va a importar al panel Arrastrar y soltar para importar.
-
Opcional: Arrastrar tablas adicionales al panel de importación. Puede utilizar la interfaz gráfica para unir las tablas. Para obtener una mayor especificidad en las uniones, elija Editar en SQL.
-
Opcional: si utiliza SQL para consultar los datos, puede elegir Contexto para agregar contexto a la conexión especificando valores para lo siguiente:
-
Almacén
-
Base de datos
-
Esquema
Añadir contexto a una conexión facilita la especificación de consultas futuras.
-
-
Elija Importar datos.
En la imagen siguiente, se muestra un ejemplo de campos especificados para una conexión de Snowflake.

La siguiente imagen muestra la página utilizada para agregar contexto a una conexión.

La siguiente imagen muestra la página utilizada para unir conjuntos de datos en Snowflake.
La siguiente imagen muestra una consulta SQL que se utiliza para editar una unión en Snowflake.
Uso de conectores de SaaS con Canvas
nota
Para las plataformas de SaaS aparte de Snowflake, solo puede tener una conexión por origen de datos.
Antes de poder importar datos desde una plataforma de SaaS, el administrador debe autenticarse y crear una conexión con el origen de datos. Para obtener más información sobre cómo los administradores pueden crear una conexión con una plataforma SaaS, consulte Administrar AppFlow las conexiones de Amazon en la Guía AppFlow del usuario de Amazon.
Si eres administrador y estás empezando a usar Amazon AppFlow por primera vez, consulta Cómo empezar en la Guía del AppFlow usuario de Amazon.
Para importar datos desde una plataforma de SaaS, puede seguir el procedimiento estándar Importación de datos tabulares, que le muestra cómo importar conjuntos de datos tabulares en Canvas.
