Las traducciones son generadas a través de traducción automática. En caso de conflicto entre la traducción y la version original de inglés, prevalecerá la version en inglés.
Monitor de modelo FAQs
Consulta lo siguiente FAQs para obtener más información sobre Amazon SageMaker Model Monitor.
P: ¿Cómo ayudan Model Monitor y SageMaker Clarify a los clientes a monitorear el comportamiento de los modelos?
Los clientes pueden monitorear el comportamiento del modelo en cuatro dimensiones: calidad de los datos, calidad del modelo, desviación de sesgo y desviación de atribución de características a través de Amazon SageMaker Model Monitor y SageMaker Clarify. Model Monitor
P: ¿Qué ocurre en segundo plano cuando el monitor de modelos de SageMaker está habilitado?
Amazon SageMaker Model Monitor automatiza la supervisión de modelos, lo que reduce la necesidad de monitorizarlos manualmente o de crear herramientas adicionales. Para automatizar el proceso, el monitor de modelos le permite crear un conjunto de estadísticas y restricciones de referencia a partir de los datos con los que se entrenó el modelo y, a continuación, configurar una programación para supervisar las predicciones realizadas en su punto de conexión. El monitor de modelos utiliza reglas para detectar desviaciones en sus modelos y le avisa cuando se producen. Los siguientes pasos describen lo que ocurre cuando se habilita la supervisión del modelo:
-
Supervisión del modelo habilitada: para un punto de conexión en tiempo real, tiene que habilitar el punto de conexión para capturar datos de las solicitudes entrantes a un modelo ML implementado y las predicciones del modelo resultantes. Para un trabajo de transformación por lotes, habilite la captura de datos de las entradas y salidas de la transformación por lotes.
-
Trabajo de procesamiento de referencia: a continuación, cree una referencia a partir del conjunto de datos que se utilizó para entrenar el modelo. La referencia calcula las métricas y sugiere las limitaciones de las métricas. Por ejemplo, la puntuación de recuperación del modelo no debe retroceder y caer por debajo de 0,571, o la puntuación de precisión no debe caer por debajo de 1,0. Las predicciones en tiempo real o por lotes del modelo se comparan con las restricciones y se consideran infracciones si están fuera de los valores restringidos.
-
Trabajo de supervisión: a continuación, cree una programación de supervisión que especifique qué datos se recopilarán, con qué frecuencia se recopilarán, cómo analizarlos y qué informes se producirán.
-
Trabajo de fusión: esto solo se aplica si utilizas Amazon SageMaker Ground Truth. El monitor de modelos compara las predicciones que hace su modelo con las etiquetas de Ground Truth para medir la calidad del modelo. Para que esto funcione, debe etiquetar periódicamente los datos capturados por su punto de conexión o trabajo de transformación por lotes y cargarlos en Amazon S3.
Después de crear y cargar las etiquetas de Ground Truth, incluya la ubicación de las etiquetas como parámetro al crear el trabajo de supervisión.
Cuando usa el monitor de modelos para supervisar un trabajo de transformación por lotes en lugar de un punto de conexión en tiempo real, en lugar de recibir solicitudes a un punto de conexión y rastrear las predicciones, el monitor de modelos supervisa las entradas y salidas de las inferencias. En una programación del monitor de modelos, el cliente proporciona el recuento y el tipo de instancias que se van a utilizar en el trabajo de procesamiento. Estos recursos permanecen reservados hasta que se elimine la programación, independientemente del estado de la ejecución actual.
P: ¿Qué es la captura de datos, por qué es necesaria y cómo puedo habilitarla?
Para registrar las entradas de su punto de conexión y las salidas de inferencia del modelo implementado en Amazon S3, puede habilitar una característica llamada Captura de datos. Para obtener más información sobre cómo habilitarla para un trabajo de transformación por lotes y de punto de conexión en tiempo real, consulte Captura de datos del punto de conexión en tiempo real y Captura de datos del trabajo de transformación por lotes.
P: ¿La activación de la captura de datos afecta al rendimiento de un punto de conexión en tiempo real?
La captura de datos se realiza de forma asíncrona sin afectar al tráfico de producción. Después de habilitar la captura de datos, la carga de solicitud y respuesta, junto con algunos metadatos adicionales, se guarda en la ubicación de Amazon S3 especificada en DataCaptureConfig. Tenga en cuenta que puede haber un retraso en la propagación de los datos capturados a Amazon S3.
También puede ver los datos capturados so enumera los archivos de captura de datos almacenados en Amazon S3. El formato de la ruta de Amazon S3 es: s3:///{endpoint-name}/{variant-name}/yyyy/mm/dd/hh/filename.jsonl. La captura de datos de Amazon S3 debe realizarse en la misma región que la programación del monitor de modelos. También debe asegurarse de que los nombres de las columnas del conjunto de datos de referencia solo tengan letras minúsculas y un guión bajo (_) como único separador.
P: ¿Por qué se necesita Ground Truth para la supervisión de modelos?
Las siguientes funciones del monitor de modelos requieren las etiquetas Ground Truth:
-
La supervisión de la calidad del modelo compara las predicciones que hace su modelo con las etiquetas de Ground Truth para medir la calidad del modelo.
-
La supervisión del sesgo del modelo supervisa el sesgo en las predicciones. Una forma en que se puede introducir el sesgo en los modelos de ML implementados es cuando los datos utilizados en el entrenamiento difieren de los datos utilizados para generar las predicciones. Esto es especialmente pronunciado si los datos utilizados para el entrenamiento cambian con el tiempo (como la fluctuación de las tasas hipotecarias) y la predicción del modelo no es tan precisa a menos que se vuelva a entrenar el modelo con datos actualizados. Por ejemplo, un modelo para predecir los precios de las viviendas pueden sesgarse si las tasas hipotecarias utilizadas para entrenar el modelo difieren de las tasas hipotecarias más actuales del mundo real.
P: En el caso de los clientes que utilizan Ground Truth para el etiquetado, ¿qué medidas puedo tomar para controlar la calidad del modelo?
La supervisión de la calidad del modelo compara las predicciones que hace su modelo con las etiquetas de Ground Truth para medir la calidad del modelo. Para que esto funcione, debe etiquetar periódicamente los datos capturados por su punto de conexión o trabajo de transformación por lotes y cargarlos en Amazon S3. Además de las capturas, la ejecución de supervisión del sesgo del modelo también requiere datos de Ground Truth. En casos de uso reales, los datos de Ground Truth deben recopilarse y cargarse periódicamente en la ubicación designada de Amazon S3. Para cotejar las etiquetas de Ground Truth con los datos de predicción capturados, debe haber un identificador único para cada registro del conjunto de datos. Para ver la estructura de cada registro de datos de Ground Truth, consulte Ingest Ground Truth Labels y Merge Them With Predictions.
El siguiente ejemplo de código se puede utilizar para generar datos artificiales de Ground Truth para un conjunto de datos tabular.
import random def ground_truth_with_id(inference_id): random.seed(inference_id) # to get consistent results rand = random.random() # format required by the merge container return { "groundTruthData": { "data": "1" if rand < 0.7 else "0", # randomly generate positive labels 70% of the time "encoding": "CSV", }, "eventMetadata": { "eventId": str(inference_id), }, "eventVersion": "0", } def upload_ground_truth(upload_time): records = [ground_truth_with_id(i) for i in range(test_dataset_size)] fake_records = [json.dumps(r) for r in records] data_to_upload = "\n".join(fake_records) target_s3_uri = f"{ground_truth_upload_path}/{upload_time:%Y/%m/%d/%H/%M%S}.jsonl" print(f"Uploading {len(fake_records)} records to", target_s3_uri) S3Uploader.upload_string_as_file_body(data_to_upload, target_s3_uri) # Generate data for the last hour upload_ground_truth(datetime.utcnow() - timedelta(hours=1)) # Generate data once a hour def generate_fake_ground_truth(terminate_event): upload_ground_truth(datetime.utcnow()) for _ in range(0, 60): time.sleep(60) if terminate_event.is_set(): break ground_truth_thread = WorkerThread(do_run=generate_fake_ground_truth) ground_truth_thread.start()
En el siguiente ejemplo de código se muestra cómo generar tráfico artificial para enviarlo al punto de conexión del modelo. Observe el atributo inferenceId utilizado anteriormente para invocar. Si está presente, se usa para unirse a los datos de Ground Truth (de lo contrario, se usa eventId).
import threading class WorkerThread(threading.Thread): def __init__(self, do_run, *args, **kwargs): super(WorkerThread, self).__init__(*args, **kwargs) self.__do_run = do_run self.__terminate_event = threading.Event() def terminate(self): self.__terminate_event.set() def run(self): while not self.__terminate_event.is_set(): self.__do_run(self.__terminate_event) def invoke_endpoint(terminate_event): with open(test_dataset, "r") as f: i = 0 for row in f: payload = row.rstrip("\n") response = sagemaker_runtime_client.invoke_endpoint( EndpointName=endpoint_name, ContentType="text/csv", Body=payload, InferenceId=str(i), # unique ID per row ) i += 1 response["Body"].read() time.sleep(1) if terminate_event.is_set(): break # Keep invoking the endpoint with test data invoke_endpoint_thread = WorkerThread(do_run=invoke_endpoint) invoke_endpoint_thread.start()
Debe cargar los datos de Ground Truth a un bucket de Amazon S3 que tenga el mismo formato de ruta que los datos capturados, que tiene el siguiente formato: s3://<bucket>/<prefix>/yyyy/mm/dd/hh
nota
La fecha de esta ruta es la fecha en que se recopiló la etiqueta de Ground Truth. No tiene que coincidir con la fecha en que se generó la inferencia.
P: ¿Cómo pueden los clientes personalizar los programas de supervisión?
Además de utilizar los mecanismos de supervisión integrados, puede crear sus propios programas y procedimientos de supervisión personalizados mediante scripts de preprocesamiento y postprocesamiento o mediante el uso o la creación de su propio contenedor. Es importante tener en cuenta que los scripts de preprocesamiento y postprocesamiento solo funcionan con trabajos de calidad de datos y modelos.
Amazon SageMaker AI le permite monitorear y evaluar los datos observados por los puntos finales del modelo. Para ello, debe crear una referencia con la que comparar el tráfico en tiempo real. Una vez que la referencia esté lista, establezca una programación para evaluarla y compararla continuamente con la referencia. Al crear una programación, puede proporcionar el script preprocesamiento y postprocesamiento.
En el ejemplo siguiente se muestra cómo personalizar los programas de supervisión con scripts de preprocesamiento y postprocesamiento.
import boto3, osfrom sagemaker import get_execution_role, Sessionfrom sagemaker.model_monitor import CronExpressionGenerator, DefaultModelMonitor # Upload pre and postprocessor scripts session = Session() bucket = boto3.Session().resource("s3").Bucket(session.default_bucket()) prefix = "demo-sagemaker-model-monitor" pre_processor_script = bucket.Object(os.path.join(prefix, "preprocessor.py")).upload_file("preprocessor.py") post_processor_script = bucket.Object(os.path.join(prefix, "postprocessor.py")).upload_file("postprocessor.py") # Get execution role role = get_execution_role() # can be an empty string # Instance type instance_type = "instance-type" # instance_type = "ml.m5.xlarge" # Example # Create a monitoring schedule with pre and post-processing my_default_monitor = DefaultModelMonitor( role=role, instance_count=1, instance_type=instance_type, volume_size_in_gb=20, max_runtime_in_seconds=3600, ) s3_report_path = "s3://{}/{}".format(bucket, "reports") monitor_schedule_name = "monitor-schedule-name" endpoint_name = "endpoint-name" my_default_monitor.create_monitoring_schedule( post_analytics_processor_script=post_processor_script, record_preprocessor_script=pre_processor_script, monitor_schedule_name=monitor_schedule_name, # use endpoint_input for real-time endpoint endpoint_input=endpoint_name, # or use batch_transform_input for batch transform jobs # batch_transform_input=batch_transform_name, output_s3_uri=s3_report_path, statistics=my_default_monitor.baseline_statistics(), constraints=my_default_monitor.suggested_constraints(), schedule_cron_expression=CronExpressionGenerator.hourly(), enable_cloudwatch_metrics=True, )
P: ¿Cuáles son algunos de los escenarios o casos de uso en los que puedo utilizar un script de preprocesamiento?
Puede utilizar scripts de preprocesamiento cuando necesite transformar las entradas del monitor de modelos. Considere los siguientes escenarios de ejemplo:
-
Script de preprocesamiento para la transformación de datos.
Suponga que la salida de su modelo es una matriz:
[1.0, 2.1]. El contenedor del monitor de modelos solo funciona con estructuras JSON tabulares o aplanadas, como{“prediction0”: 1.0, “prediction1” : 2.1}. Puede utilizar un script de preprocesamiento como el siguiente ejemplo para transformar la matriz en la estructura JSON correcta.def preprocess_handler(inference_record): input_data = inference_record.endpoint_input.data output_data = inference_record.endpoint_output.data.rstrip("\n") data = output_data + "," + input_data return { str(i).zfill(20) : d for i, d in enumerate(data.split(",")) } -
Excluya determinados registros de los cálculos métricos del monitor de modelos.
Suponga que el modelo tiene características opcionales y que utiliza
-1para indicar que a la característica opcional le falta un valor. Si tiene un monitor de calidad de datos, es posible que desee eliminar el-1de la matriz de valores de entrada para que no se incluya en los cálculos de métricas del monitor. Puede utilizar un script como el siguiente para eliminar esos valores.def preprocess_handler(inference_record): input_data = inference_record.endpoint_input.data return {i : None if x == -1 else x for i, x in enumerate(input_data.split(","))} -
Aplique una estrategia de muestreo personalizada.
También puede aplicar una estrategia de muestreo personalizada en su script de preprocesamiento. Para ello, configure el contenedor propio y prediseñado del monitor de modelos para que haga caso omiso de un porcentaje de los registros de acuerdo con la frecuencia de muestreo especificada. En el siguiente ejemplo, el controlador muestrea el 10 % de los registros devolviendo el registro del 10 % de las llamadas al controlador y, en caso contrario, devuelve una lista vacía.
import random def preprocess_handler(inference_record): # we set up a sampling rate of 0.1 if random.random() > 0.1: # return an empty list return [] input_data = inference_record.endpoint_input.data return {i : None if x == -1 else x for i, x in enumerate(input_data.split(","))} -
Utilice un registro personalizado.
Puedes registrar cualquier información que necesites de tu script en Amazon CloudWatch. Esto puede resultar útil a la hora de depurar el script de preprocesamiento en caso de que se produzca un error. El siguiente ejemplo muestra cómo puedes usar la
preprocess_handlerinterfaz para iniciar sesión CloudWatch.def preprocess_handler(inference_record, logger): logger.info(f"I'm a processing record: {inference_record}") logger.debug(f"I'm debugging a processing record: {inference_record}") logger.warning(f"I'm processing record with missing value: {inference_record}") logger.error(f"I'm a processing record with bad value: {inference_record}") return inference_record
nota
Cuando el script de preprocesamiento se ejecuta en datos de transformación por lotes, el tipo de entrada no siempre es el objeto CapturedData. En el caso de los datos CSV, el tipo es una cadena. Para los datos JSON, el tipo es un diccionario de Python.
P: ¿Cuándo puedo aprovechar un script de postprocesamiento?
Puede utilizar un script de postprocesamiento como extensión después de una ejecución de supervisión correcta. El siguiente es un ejemplo sencillo, pero puede realizar o llamar a cualquier función empresarial que necesite realizar tras una ejecución de supervisión satisfactoria.
def postprocess_handler(): print("Hello from the post-processing script!")
P: ¿Cuándo debo considerar la posibilidad de utilizar mi propio contenedor para la supervisión de modelos?
SageMaker La IA proporciona un contenedor prediseñado para analizar los datos capturados en los puntos finales o realizar tareas de transformación por lotes para conjuntos de datos tabulares. Sin embargo, hay situaciones en las que puede que desee crear su propio contenedor. Considere los siguientes escenarios:
-
Tiene requisitos normativos y de conformidad que exigen utilizar únicamente los contenedores que se creen y mantengan internamente en su organización.
-
Si desea incluir algunas bibliotecas de terceros, puede colocar un
requirements.txtarchivo en un directorio local y hacer referencia a él mediante elsource_dirparámetro del estimador de SageMaker IA, que permite la instalación de la biblioteca en tiempode ejecución. Sin embargo, si tiene muchas bibliotecas o dependencias que aumentan el tiempo de instalación mientras ejecuta el trabajo de entrenamiento, puede que le interese utilizar su propio contenedor. -
Su entorno no requiere conectividad a Internet (o silo), lo que impide la descarga de paquetes.
-
Desea supervisar los datos que están en formatos de datos distintos de los tabulares, como los casos de uso de NLP o CV.
-
Cuando necesite métricas de supervisión adicionales a las compatibles con el monitor de modelos.
P: Tengo modelos de NLP y CV. ¿Cómo puedo supervisarlos para detectar la desviación de datos?
El contenedor prediseñado de Amazon SageMaker AI admite conjuntos de datos tabulares. Si desea supervisar modelos de NLP y CV, puede utilizar su propio contenedor y aprovechar los puntos de extensión que proporciona el monitor de modelos. Para obtener más información sobre los requisitos, consulte Utilice sus propios contenedores. A continuación, se muestran más ejemplos:
-
Para obtener una explicación detallada de cómo utilizar el monitor de modelos para un caso práctico de visión artificial, consulte Detecting and Analyzing incorrect predictions
. -
Para ver un escenario en el que se puede aprovechar Model Monitor para un caso de uso de la PNL, consulte Detectar la desviación de datos de la PNL con Amazon SageMaker Model Monitor personalizado
.
P: Deseo eliminar el punto de conexión del modelo para el que estaba activado el monitor de modelos, pero no puedo hacerlo porque el programa de supervisión sigue activo. ¿Qué tengo que hacer?
Si desea eliminar un punto final de inferencia alojado en SageMaker AI que tenga habilitado Model Monitor, primero debe eliminar el programa de monitoreo del modelo (con la DeleteMonitoringSchedule CLI o la API). A continuación, elimine el punto de conexión.
P: ¿ SageMaker Model Monitor calcula las métricas y las estadísticas para las entradas?
El monitor de modelos calcula métricas y estadísticas para la salida, no para la entrada.
P: ¿Soporta SageMaker Model Monitor puntos finales multimodelo?
No, el monitor de modelos admite solo puntos de conexión que alojan un solo modelo y no admite la supervisión de puntos de conexión multimodelo.
P: ¿ SageMaker Model Monitor proporciona datos de monitoreo sobre los contenedores individuales en un proceso de inferencia?
El monitor de modelos admite la supervisión de canalizaciones de inferencia, pero la captura y el análisis de datos se realiza para toda la canalización, no para contenedores individuales en la canalización.
P: ¿Qué puedo hacer para evitar que las solicitudes de inferencia se vean afectadas cuando se configura la captura de datos?
Para evitar que las solicitudes de inferencia se vean afectadas, la captura de datos deja de capturar solicitudes con niveles altos de uso de disco. Se recomienda mantener la utilización del disco por debajo del 75 % para garantizar que la captura de datos siga capturando las solicitudes.
P: ¿La captura de datos de Amazon S3 puede estar en una AWS región diferente a la región en la que se configuró el programa de monitoreo?
La captura de datos de Amazon S3 debe realizarse en la misma región que la programación de supervisión de modelos.
P: ¿Qué es una referencia y cómo puedo crearla? ¿Puedo crear una referencia personalizada?
La referencia sirve para comparar las predicciones en tiempo real o por lotes del modelo. Calcula las estadísticas y las métricas junto con sus restricciones. Durante la supervisión, todos estos elementos se utilizan en conjunto para identificar las infracciones.
Para usar la solución predeterminada de Amazon SageMaker Model Monitor, puede aprovechar el SDK de Amazon SageMaker Python
El resultado de un trabajo de referencia son dos archivos: statistics.json y constraints.json. El esquema de estadísticas y el esquema de restricciones contienen el esquema de los archivos respectivos. Puede revisar las restricciones generadas y modificarlas antes de utilizarlas para la supervisión. En función de su comprensión del dominio y del problema empresarial, puede hacer que una restricción sea más agresiva o flexibilizarla para controlar el número y la naturaleza de las infracciones.
P: ¿Cuáles son las pautas para crear un conjunto de datos de referencia?
El requisito principal para cualquier tipo de supervisión es tener un conjunto de datos de referencia que se utilice para calcular las métricas y las restricciones. Normalmente, este es el conjunto de datos de entrenamiento que utiliza el modelo, pero en algunos casos puede optar por utilizar algún otro conjunto de datos de referencia.
Los nombres de las columnas del conjunto de datos de referencia deben ser compatibles con Spark. Para mantener la máxima compatibilidad entre Spark, CSV, JSON y Parquet, se recomienda utilizar únicamente letras minúsculas y utilizar únicamente _ como separador. Los caracteres especiales, lo que incluye “ ”, pueden causar problemas.
P: ¿Cuáles son los parámetros StartTimeOffset y EndTimeOffset y cuándo se utilizan?
Cuando se requiere Amazon SageMaker Ground Truth para monitorear trabajos como la calidad de los modelos, debes asegurarte de que un trabajo de monitoreo solo use datos para los que Ground Truth esté disponible. Los end_time_offset parámetros start_time_offset y de se EndpointInputstart_time_offset y end_time_offset. Estos parámetros deben especificarse en el formato de duración ISO 8601
-
Si tus resultados de Ground Truth llegan 3 días después de que se hayan realizado las predicciones, establezca
start_time_offset="-P3D"yend_time_offset="-P1D", es decir, 3 días y 1 día, respectivamente. -
Si los resultados de Ground Truth llegan 6 horas después de las predicciones y tiene una programación por horas, establezca
start_time_offset="-PT6H"yend_time_offset="-PT1H", que es 6 horas y 1 hora.
P: ¿Puedo ejecutar trabajos de supervisión “bajo demanda”?
Sí, puede ejecutar trabajos de monitoreo «bajo demanda» ejecutando un trabajo de SageMaker procesamiento. Para Batch Transform, Pipelines tiene una canalización MonitorBatchTransformStep
P: ¿Cómo se configura el monitor de modelos?
Puede configurar el monitor de modelos de una de las siguientes formas:
-
Amazon SageMaker AI Python SDK
: hay un módulo Model Monitor que contiene clases y funciones que ayudan a sugerir líneas de base, crear cronogramas de monitoreo y más. Consulte los ejemplos de cuadernos de Amazon SageMaker Model Monitor para ver cuadernos detallados que utilizan el SDK de Python para SageMaker IA para configurar Model Monitor. -
Canalizaciones: las canalizaciones se integran con Model Monitor a través de Step y. QualityCheck ClarifyCheckStep APIs Puede crear una canalización de SageMaker IA que contenga estos pasos y que pueda usarse para ejecutar trabajos de monitoreo bajo demanda siempre que se ejecute la canalización.
-
Amazon SageMaker Studio Classic: puede crear un programa de monitoreo de la calidad de los datos o del modelo junto con programas de sesgo y explicabilidad del modelo directamente desde la interfaz de usuario seleccionando un punto final de la lista de puntos finales del modelo implementados. Puede crear programaciones para otros tipos de supervisión si selecciona la pestaña correspondiente en la interfaz de usuario.
-
SageMaker Panel de control del modelo: puede habilitar la supervisión de los puntos finales seleccionando un modelo que se haya implementado en un punto final. En la siguiente captura de pantalla de la consola de SageMaker IA, se
group1ha seleccionado un modelo denominado en la sección Modelos del panel de control de modelos. En esta página, puede crear una programación de supervisión y editar, activar o desactivar los programas y alertas de supervisión actuales. Para obtener una guía paso a paso sobre cómo ver las alertas y las programaciones de supervisión de modelos, consulte Ver los horarios y las alertas del monitor de modelos.
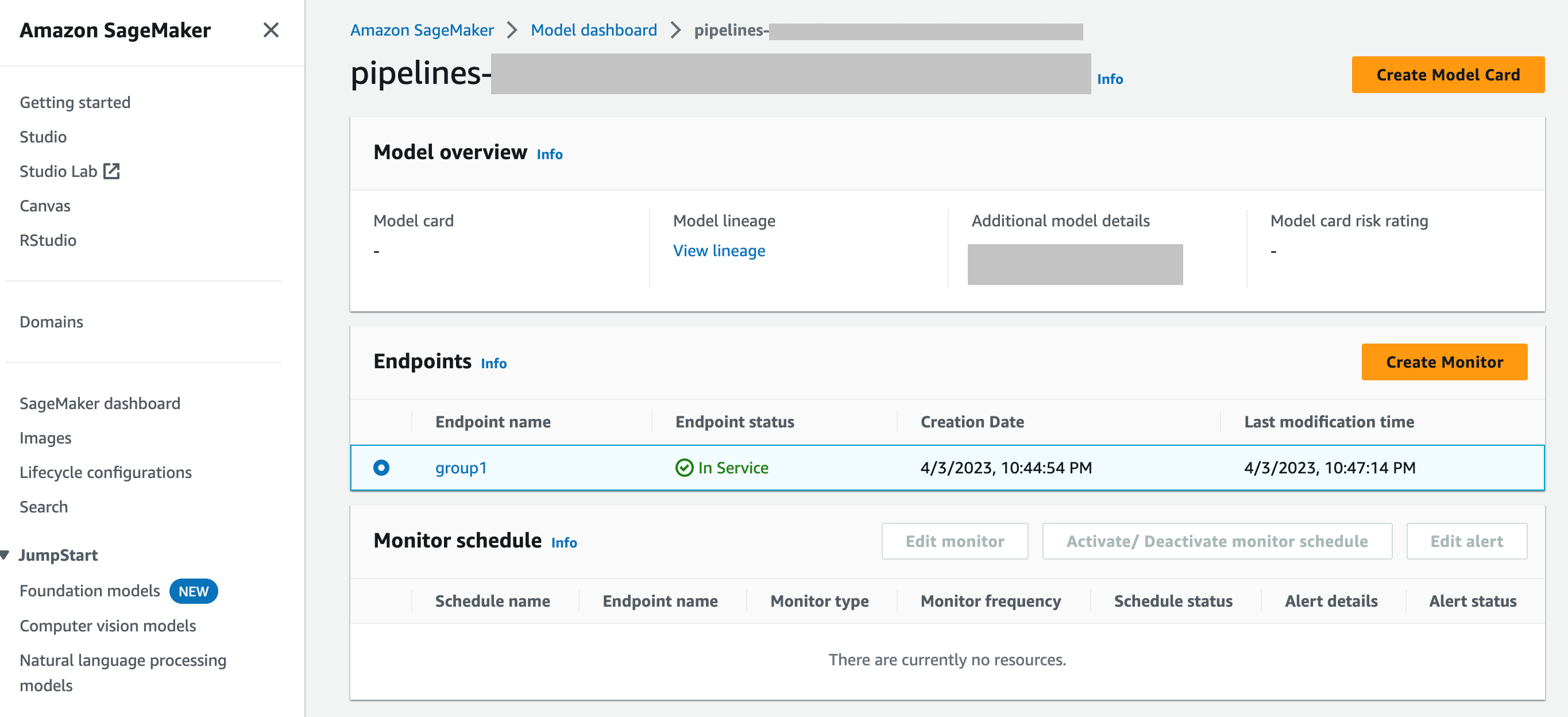
P: ¿Cómo se integra Model Monitor con SageMaker Model Dashboard
SageMaker Model Dashboard le brinda una supervisión unificada de todos sus modelos al proporcionar alertas automatizadas sobre las desviaciones del comportamiento esperado y la solución de problemas para inspeccionar los modelos y analizar los factores que afectan al rendimiento del modelo a lo largo del tiempo.
