Terjemahan disediakan oleh mesin penerjemah. Jika konten terjemahan yang diberikan bertentangan dengan versi bahasa Inggris aslinya, utamakan versi bahasa Inggris.
Menggunakan pembelajaran mesin Amazon Aurora dengan Aurora My SQL
Dengan menggunakan pembelajaran mesin Amazon Aurora dengan cluster Aurora My SQL DB Anda, Anda dapat menggunakan Amazon Bedrock, Amazon Comprehend, atau Amazon AI, tergantung pada kebutuhan Anda. SageMaker Mereka masing-masing mendukung kasus penggunaan pembelajaran mesin yang berbeda.
Daftar Isi
Persyaratan untuk menggunakan pembelajaran mesin Aurora dengan Aurora My SQL
Fitur dan keterbatasan pembelajaran mesin Aurora yang didukung dengan Aurora My SQL
Menyiapkan cluster Aurora My SQL DB Anda untuk menggunakan pembelajaran mesin Aurora
Menggunakan Amazon Bedrock dengan cluster Aurora My DB SQL Anda
Menggunakan Amazon Comprehend dengan cluster Aurora My DB Anda SQL
Menggunakan SageMaker AI dengan cluster Aurora My SQL DB Anda
Pertimbangan kinerja untuk menggunakan pembelajaran mesin Aurora dengan Aurora My SQL
Persyaratan untuk menggunakan pembelajaran mesin Aurora dengan Aurora My SQL
AWS Layanan pembelajaran mesin adalah layanan terkelola yang diatur dan dijalankan di lingkungan produksi mereka sendiri. Pembelajaran mesin Aurora mendukung integrasi dengan Amazon Bedrock, Amazon Comprehend, dan AI. SageMaker Sebelum mencoba mengatur cluster Aurora My SQL DB Anda untuk menggunakan pembelajaran mesin Aurora, pastikan Anda memahami persyaratan dan prasyarat berikut.
-
Layanan pembelajaran mesin harus berjalan Wilayah AWS sama dengan cluster Aurora My SQL DB Anda. Anda tidak dapat menggunakan layanan pembelajaran mesin dari cluster Aurora My SQL DB di Wilayah yang berbeda.
-
Jika klaster Aurora My SQL DB Anda berada di cloud publik virtual (VPC) yang berbeda dari Amazon Bedrock, Amazon Comprehend, atau layanan SageMaker AI Anda, grup Keamanan perlu mengizinkan koneksi keluar ke layanan pembelajaran mesin VPC Aurora target. Untuk informasi selengkapnya, lihat Mengontrol lalu lintas ke AWS sumber daya Anda menggunakan grup keamanan di Panduan VPC Pengguna Amazon.
-
Anda dapat memutakhirkan cluster Aurora yang menjalankan versi Aurora My yang lebih rendah SQL ke versi yang lebih tinggi yang didukung jika Anda ingin menggunakan pembelajaran mesin Aurora dengan cluster itu. Untuk informasi selengkapnya, lihat Pembaruan mesin database untuk Amazon Aurora My SQL.
-
Cluster Aurora My SQL DB Anda harus menggunakan grup parameter cluster DB kustom. Di akhir proses penyiapan untuk setiap layanan machine learning Aurora yang ingin Anda gunakan, Anda menambahkan Amazon Resource Name (ARN) dari IAM peran terkait yang dibuat untuk layanan tersebut. Kami menyarankan Anda membuat grup parameter cluster DB khusus untuk Aurora My Anda SQL terlebih dahulu dan mengkonfigurasi cluster Aurora My SQL DB Anda untuk menggunakannya sehingga siap untuk Anda modifikasi di akhir proses penyiapan.
-
Untuk SageMaker AI:
-
Komponen pembelajaran mesin yang ingin Anda gunakan untuk kesimpulan harus diatur dan siap digunakan. Selama proses konfigurasi untuk cluster Aurora My SQL DB Anda, pastikan untuk memiliki titik ARN akhir SageMaker AI yang tersedia. Ilmuwan data di tim Anda kemungkinan besar paling mampu menangani bekerja dengan SageMaker AI untuk mempersiapkan model dan menangani tugas-tugas semacam itu lainnya. Untuk memulai dengan Amazon SageMaker AI, lihat Memulai dengan Amazon SageMaker AI. Untuk informasi selengkapnya tentang inferensi dan titik akhir, lihat Inferensi real-time.
-
Untuk menggunakan SageMaker AI dengan data pelatihan Anda sendiri, Anda harus menyiapkan bucket Amazon S3 sebagai bagian dari konfigurasi Aurora My SQL untuk pembelajaran mesin Aurora. Untuk melakukannya, Anda mengikuti proses umum yang sama seperti untuk menyiapkan integrasi SageMaker AI. Untuk ringkasan proses penyiapan opsional ini, lihat Menyiapkan cluster Aurora My SQL DB Anda untuk menggunakan Amazon S3 SageMaker untuk AI (Opsional).
-
-
Untuk database global Aurora, Anda menyiapkan layanan pembelajaran mesin Aurora yang ingin Anda gunakan dalam semua yang Wilayah AWS membentuk basis data global Aurora Anda. Misalnya, jika Anda ingin menggunakan pembelajaran mesin Aurora dengan SageMaker AI untuk database global Aurora Anda, Anda melakukan hal berikut untuk setiap cluster Aurora My DB di setiap: SQL Wilayah AWS
-
Siapkan layanan Amazon SageMaker AI dengan model pelatihan SageMaker AI dan titik akhir yang sama. Ini juga harus menggunakan nama yang sama.
-
Buat IAM peran seperti yang dijelaskan dalamMenyiapkan cluster Aurora My SQL DB Anda untuk menggunakan pembelajaran mesin Aurora.
-
Tambahkan IAM peran ke grup parameter cluster DB khusus untuk setiap cluster Aurora My SQL DB di setiap cluster. ARN Wilayah AWS
Tugas-tugas ini mengharuskan pembelajaran mesin Aurora tersedia untuk versi Aurora My Anda SQL dalam semua Wilayah AWS yang membentuk basis data global Aurora Anda.
-
Wilayah dan ketersediaan versi
Ketersediaan fitur dan dukungan bervariasi di seluruh versi khusus dari setiap mesin basis data Aurora, dan di seluruh Wilayah AWS.
-
Untuk informasi tentang versi dan ketersediaan Wilayah untuk Amazon Comprehend dan SageMaker Amazon AI dengan SQL Aurora My, lihat. Machine learning Aurora dengan Aurora MySQL
-
Amazon Bedrock hanya didukung di Aurora SQL My versi 3.06 dan lebih tinggi.
Untuk informasi tentang ketersediaan Wilayah untuk Amazon Bedrock, lihat Dukungan model oleh Wilayah AWS di Panduan Pengguna Amazon Bedrock.
Fitur dan keterbatasan pembelajaran mesin Aurora yang didukung dengan Aurora My SQL
Saat menggunakan SQL Aurora My dengan pembelajaran mesin Aurora, batasan berikut berlaku:
-
Ekstensi pembelajaran mesin Aurora tidak mendukung antarmuka vektor.
-
Integrasi pembelajaran mesin Aurora tidak didukung saat digunakan dalam pemicu.
Fungsi pembelajaran mesin Aurora tidak kompatibel dengan replikasi biner logging (binlog).
-
Pengaturan
--binlog-format=STATEMENTmemunculkan pengecualian untuk panggilan ke fungsi machine learning Aurora. -
Fungsi machine learning Aurora Function bersifat nondeterministik, dan fungsi tersimpan nondeterministik tidak kompatibel dengan format binlog.
Untuk informasi selengkapnya, lihat Format Pencatatan Biner
di SQL dokumentasi Saya. -
-
Fungsi tersimpan yang memanggil tabel dengan kolom generated-always tidak didukung. Ini berlaku untuk semua fungsi Aurora My storageSQL. Untuk mempelajari lebih lanjut tentang jenis kolom ini, lihat CREATETABLEdan Kolom yang Dihasilkan
dalam SQL dokumentasi Saya. -
Fungsi Amazon Bedrock tidak mendukung
RETURNS JSON. Anda dapat menggunakanCONVERTatauCASTmengonversi dariTEXTkeJSONjika diperlukan. -
Amazon Bedrock tidak mendukung permintaan batch.
-
Aurora My SQL mendukung titik akhir SageMaker AI apa pun yang membaca dan menulis format value (CSV) yang dipisahkan koma, melalui file.
ContentTypetext/csvFormat ini diterima oleh algoritme SageMaker AI bawaan berikut:-
Linear Learner
-
Random Cut Forest
-
XGBoost
Untuk mempelajari lebih lanjut tentang algoritme ini, lihat Memilih Algoritma di Panduan Pengembang Amazon SageMaker AI.
-
Menyiapkan cluster Aurora My SQL DB Anda untuk menggunakan pembelajaran mesin Aurora
Dalam topik berikut, Anda dapat menemukan prosedur pengaturan terpisah untuk masing-masing layanan machine learning Aurora ini.
Topik
Menyiapkan cluster Aurora My SQL DB Anda untuk menggunakan Amazon Bedrock
Pembelajaran mesin Aurora bergantung pada AWS Identity and Access Management (IAM) peran dan kebijakan untuk memungkinkan klaster Aurora My SQL DB Anda mengakses dan menggunakan layanan Amazon Bedrock. Prosedur berikut membuat kebijakan dan peran IAM izin sehingga klaster DB Anda dapat berintegrasi dengan Amazon Bedrock.
Untuk membuat IAM kebijakan
Masuk ke AWS Management Console dan buka IAM konsol di https://console.aws.amazon.com/iam/
. -
Pilih Kebijakan di panel navigasi.
-
Pilih Buat kebijakan.
-
Pada halaman Tentukan izin, untuk Pilih layanan, pilih Batuan Dasar.
Tampilan izin Amazon Bedrock.
-
Perluas Baca, lalu pilih InvokeModel.
-
Untuk Sumber Daya, pilih Semua.
Halaman Tentukan izin harus menyerupai gambar berikut.

-
Pilih Berikutnya.
-
Pada halaman Tinjau dan buat, masukkan nama untuk kebijakan Anda, misalnya
BedrockInvokeModel. -
Tinjau kebijakan Anda, lalu pilih Buat kebijakan.
Selanjutnya Anda membuat IAM peran yang menggunakan kebijakan izin Amazon Bedrock.
Untuk membuat IAM peran
Masuk ke AWS Management Console dan buka IAM konsol di https://console.aws.amazon.com/iam/
. -
Pilih Peran di panel navigasi.
-
Pilih Buat peran.
-
Pada halaman Pilih entitas tepercaya, untuk kasus penggunaan, pilih RDS.
-
Pilih RDS- Tambahkan Peran ke Database, lalu pilih Berikutnya.
-
Pada halaman Tambahkan izin, untuk kebijakan Izin, pilih IAM kebijakan yang Anda buat, lalu pilih Berikutnya.
-
Pada halaman Nama, tinjau, dan buat, masukkan nama untuk peran Anda, misalnya
ams-bedrock-invoke-model-role.Peran harus menyerupai gambar berikut.
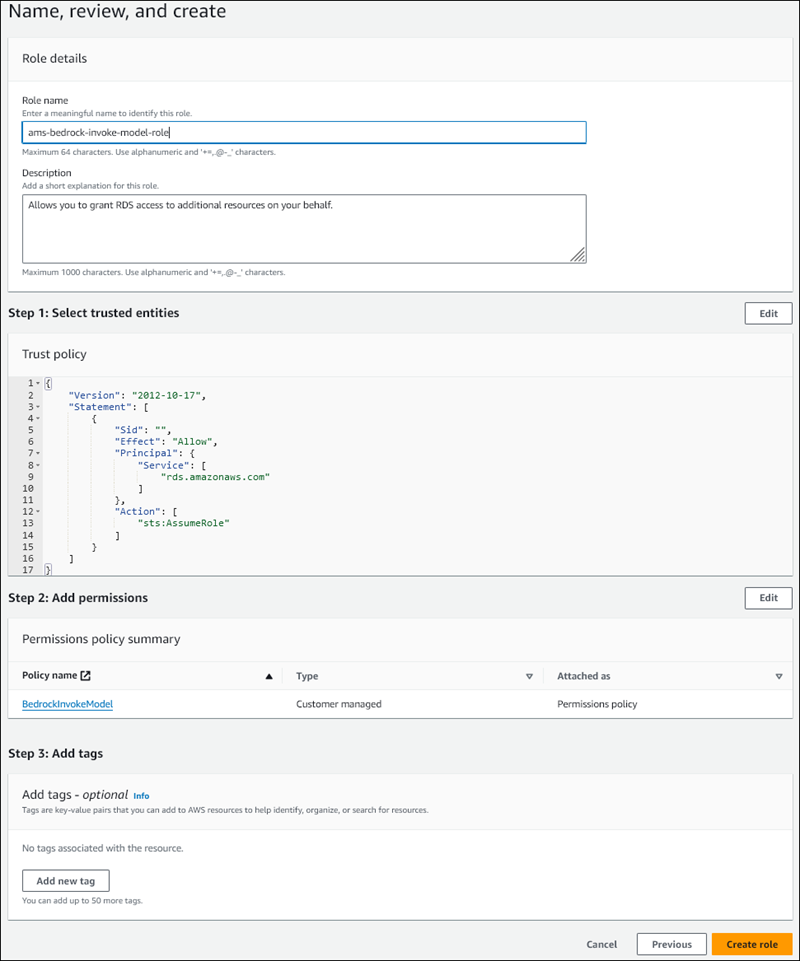
-
Tinjau peran Anda, lalu pilih Buat peran.
Selanjutnya Anda mengaitkan IAM peran Amazon Bedrock dengan cluster DB Anda.
Untuk mengaitkan IAM peran dengan cluster DB Anda
Masuk ke AWS Management Console dan buka RDS konsol Amazon di https://console.aws.amazon.com/rds/
. -
Pilih Basis data dari panel navigasi.
-
Pilih klaster Aurora My SQL DB yang ingin Anda sambungkan ke layanan Amazon Bedrock.
-
Pilih tab Konektivitas & keamanan.
-
Untuk bagian Kelola IAM peran, pilih Pilih IAM untuk ditambahkan ke klaster ini.
-
Pilih IAM yang Anda buat, lalu pilih Tambah peran.
IAMPeran dikaitkan dengan cluster DB Anda, pertama dengan status Tertunda, lalu Aktif. Saat proses selesai, Anda dapat menemukan peran dalam daftar Peran saat ini IAM untuk klaster ini.
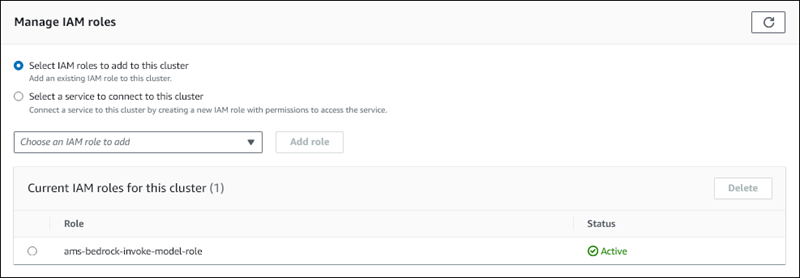
Anda harus menambahkan IAM peran ini ke parameter grup aws_default_bedrock_role parameter cluster DB kustom yang terkait dengan cluster Aurora My SQL DB Anda. ARN Jika cluster Aurora My SQL DB Anda tidak menggunakan grup parameter cluster DB kustom, Anda perlu membuatnya untuk digunakan dengan cluster Aurora My SQL DB Anda untuk menyelesaikan integrasi. Untuk informasi selengkapnya, lihat Grup parameter cluster DB untuk cluster Amazon Aurora DB.
Untuk mengkonfigurasi parameter cluster DB
-
Di RDS Konsol Amazon, buka tab Konfigurasi klaster Aurora My SQL DB Anda.
-
Temukan grup parameter cluster DB yang dikonfigurasi untuk cluster Anda. Pilih tautan untuk membuka grup parameter cluster DB kustom Anda, lalu pilih Edit.
-
Temukan parameter
aws_default_bedrock_roledalam grup parameter klaster DB kustom Anda. -
Di bidang Nilai, masukkan ARN IAM peran.
-
Pilih Simpan perubahan untuk menyimpan pengaturan.
-
Reboot instance utama cluster Aurora My SQL DB Anda sehingga pengaturan parameter ini berlaku.
IAMIntegrasi untuk Amazon Bedrock selesai. Lanjutkan menyiapkan cluster Aurora My SQL DB Anda untuk bekerja dengan Amazon Bedrock oleh. Memberikan akses pengguna basis data ke machine learning Aurora
Menyiapkan cluster Aurora My SQL DB Anda untuk menggunakan Amazon Comprehend
Pembelajaran mesin Aurora bergantung pada AWS Identity and Access Management peran dan kebijakan untuk memungkinkan klaster Aurora My SQL DB Anda mengakses dan menggunakan layanan Amazon Comprehend. Prosedur berikut secara otomatis membuat IAM peran dan kebijakan untuk klaster Anda sehingga dapat menggunakan Amazon Comprehend.
Untuk mengatur klaster Aurora My SQL DB Anda agar menggunakan Amazon Comprehend
Masuk ke AWS Management Console dan buka RDS konsol Amazon di https://console.aws.amazon.com/rds/
. -
Pilih Basis data dari panel navigasi.
-
Pilih klaster Aurora My SQL DB yang ingin Anda sambungkan ke layanan Amazon Comprehend.
-
Pilih tab Konektivitas & keamanan.
-
Untuk bagian Kelola IAM peran, pilih Pilih layanan untuk terhubung ke klaster ini.
-
Pilih Amazon Comprehend dari menu, lalu pilih Connect service.
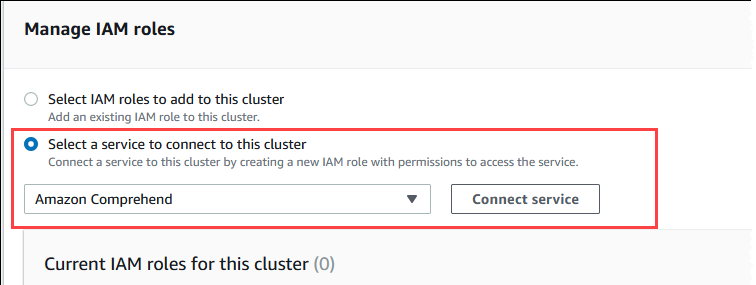
Dialog Hubungkan klaster ke Amazon Comprehend tidak memerlukan informasi tambahan apa pun. Namun, Anda mungkin melihat pesan yang memberi tahu Anda bahwa integrasi antara Aurora dan Amazon Comprehend saat ini sedang dalam pratinjau. Pastikan untuk membaca pesan tersebut sebelum melanjutkan. Anda dapat memilih Batal jika Anda memilih untuk tidak melanjutkan.
Pilih Hubungkan layanan untuk menyelesaikan proses integrasi.
Aurora menciptakan peran. IAM Ini juga membuat kebijakan yang memungkinkan klaster Aurora My SQL DB menggunakan layanan Amazon Comprehend dan melampirkan kebijakan ke peran tersebut. Saat proses selesai, Anda dapat menemukan peran dalam daftar Peran saat ini IAM untuk klaster ini seperti yang ditunjukkan pada gambar berikut.

Anda perlu menambahkan IAM peran ini ke parameter grup
aws_default_comprehend_roleparameter cluster DB kustom yang terkait dengan cluster Aurora My SQL DB Anda. ARN Jika cluster Aurora My SQL DB Anda tidak menggunakan grup parameter cluster DB kustom, Anda perlu membuatnya untuk digunakan dengan cluster Aurora My SQL DB Anda untuk menyelesaikan integrasi. Untuk informasi selengkapnya, lihat Grup parameter cluster DB untuk cluster Amazon Aurora DB.Setelah membuat grup parameter cluster DB kustom Anda dan mengaitkannya dengan cluster Aurora SQL My DB Anda, Anda dapat melanjutkan mengikuti langkah-langkah ini.
Jika klaster Anda menggunakan grup parameter klaster DB kustom, lakukan hal berikut.
Di RDS Konsol Amazon, buka tab Konfigurasi klaster Aurora My SQL DB Anda.
-
Temukan grup parameter cluster DB yang dikonfigurasi untuk cluster Anda. Pilih tautan untuk membuka grup parameter cluster DB kustom Anda, lalu pilih Edit.
Temukan parameter
aws_default_comprehend_roledalam grup parameter klaster DB kustom Anda.Di bidang Nilai, masukkan ARN IAM peran.
Pilih Simpan perubahan untuk menyimpan pengaturan. Pada gambar berikut, Anda dapat melihat contohnya.

Reboot instance utama cluster Aurora My SQL DB Anda sehingga pengaturan parameter ini berlaku.
IAMIntegrasi untuk Amazon Comprehend selesai. Lanjutkan menyiapkan klaster Aurora My SQL DB Anda agar berfungsi dengan Amazon Comprehend dengan memberikan akses ke pengguna database yang sesuai.
Menyiapkan cluster Aurora My SQL DB Anda untuk menggunakan AI SageMaker
Prosedur berikut secara otomatis membuat IAM peran dan kebijakan untuk cluster Aurora My SQL DB Anda sehingga dapat menggunakan SageMaker AI. Sebelum mencoba mengikuti prosedur ini, pastikan Anda memiliki titik akhir SageMaker AI yang tersedia sehingga Anda dapat memasukkannya saat diperlukan. Biasanya, ilmuwan data di tim Anda akan melakukan pekerjaan untuk menghasilkan titik akhir yang dapat Anda gunakan dari cluster Aurora SQL My DB Anda. Anda dapat menemukan titik akhir seperti itu di konsol SageMaker AI
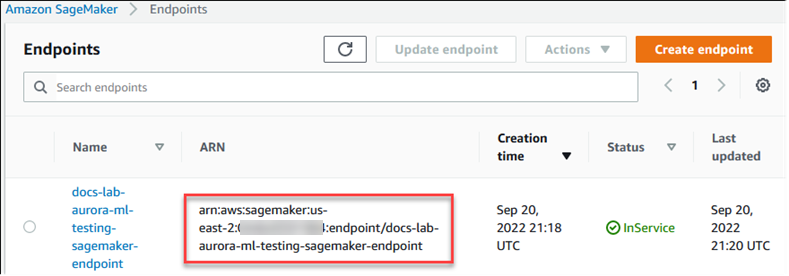
Untuk mengatur cluster Aurora My SQL DB Anda untuk menggunakan AI SageMaker
Masuk ke AWS Management Console dan buka RDS konsol Amazon di https://console.aws.amazon.com/rds/
. -
Pilih Database dari menu RDS navigasi Amazon dan kemudian pilih cluster Aurora SQL My DB yang ingin Anda sambungkan SageMaker ke layanan AI.
-
Pilih tab Konektivitas & keamanan.
-
Gulir ke bagian Kelola IAM peran, lalu pilih Pilih layanan untuk terhubung ke klaster ini. Pilih SageMaker AI dari pemilih.
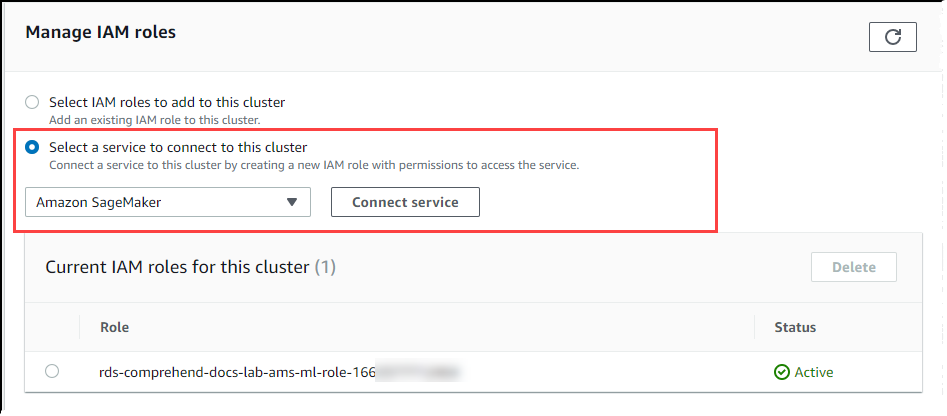
Pilih Hubungkan layanan.
Dalam dialog Connect cluster to SageMaker AI, masukkan ARN endpoint SageMaker AI.

-
Aurora menciptakan peran. IAM Ini juga menciptakan kebijakan yang memungkinkan cluster Aurora My SQL DB untuk menggunakan layanan SageMaker AI dan melampirkan kebijakan ke peran tersebut. Saat proses selesai, Anda dapat menemukan peran dalam daftar Peran saat ini IAM untuk klaster ini.
Buka konsol IAM di https://console.aws.amazon.com/iam/
. Pilih Peran dari bagian Manajemen akses pada menu navigasi AWS Identity and Access Management .
Temukan peran yang dicari di daftar peran. Namanya menggunakan pola berikut.
rds-sagemaker-your-cluster-name-role-auto-generated-digitsBuka halaman Ringkasan peran dan temukanARN. Catat ARN atau salin menggunakan widget salin.
Buka RDS konsol Amazon di https://console.aws.amazon.com/rds/
. Pilih klaster Aurora My SQL DB Anda, lalu pilih tab Konfigurasinya.
Temukan grup parameter klaster DB, dan pilih tautan untuk membuka grup parameter klaster DB kustom Anda. Temukan
aws_default_sagemaker_roleparameter dan masukkan ARN IAM peran di bidang Nilai dan Simpan pengaturan.Reboot instance utama cluster Aurora My SQL DB Anda sehingga pengaturan parameter ini berlaku.
IAMPengaturan sekarang selesai. Lanjutkan menyiapkan cluster Aurora My SQL DB Anda untuk bekerja dengan SageMaker AI dengan memberikan akses ke pengguna database yang sesuai.
Jika Anda ingin menggunakan model SageMaker AI Anda untuk pelatihan daripada menggunakan komponen SageMaker AI pra-bangun, Anda juga perlu menambahkan bucket Amazon S3 ke cluster Aurora SQL My DB Anda, seperti yang diuraikan dalam berikut ini. Menyiapkan cluster Aurora My SQL DB Anda untuk menggunakan Amazon S3 SageMaker untuk AI (Opsional)
Menyiapkan cluster Aurora My SQL DB Anda untuk menggunakan Amazon S3 SageMaker untuk AI (Opsional)
Untuk menggunakan SageMaker AI dengan model Anda sendiri daripada menggunakan komponen pra-bangun yang disediakan oleh SageMaker AI, Anda perlu menyiapkan bucket Amazon S3 untuk digunakan cluster Aurora SQL My DB. Untuk informasi selengkapnya tentang cara membuat bucket Amazon S3, lihat Membuat bucket dalam Panduan Pengguna Amazon Simple Storage Service.
Untuk mengatur cluster Aurora My SQL DB Anda agar menggunakan bucket Amazon S3 untuk AI SageMaker
Masuk ke AWS Management Console dan buka RDS konsol Amazon di https://console.aws.amazon.com/rds/
. -
Pilih Database dari menu RDS navigasi Amazon dan kemudian pilih cluster Aurora SQL My DB yang ingin Anda sambungkan SageMaker ke layanan AI.
-
Pilih tab Konektivitas & keamanan.
-
Gulir ke bagian Kelola IAM peran, lalu pilih Pilih layanan untuk terhubung ke klaster ini. Pilih Amazon S3 dari pemilih.
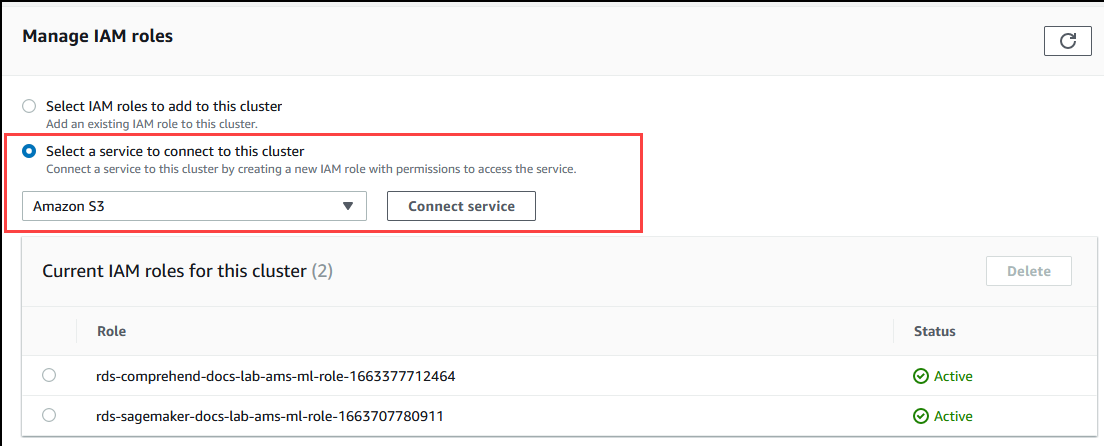
Pilih Hubungkan layanan.
Dalam dialog Connect cluster to Amazon S3, masukkan bucket Amazon S3, seperti yang ditunjukkan pada gambar berikut. ARN
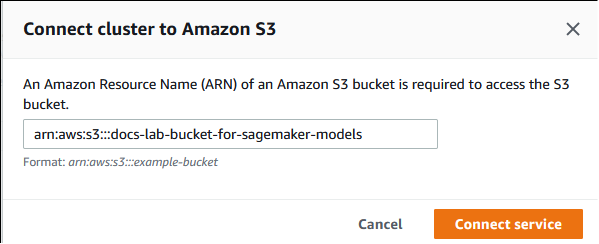
Pilih Hubungkan layanan untuk menyelesaikan proses ini.
Untuk informasi selengkapnya tentang menggunakan bucket Amazon S3 dengan SageMaker AI, lihat Menentukan Bucket Amazon S3 untuk Mengunggah Kumpulan Data Pelatihan dan Menyimpan Data Output di Panduan Pengembang Amazon AI. SageMaker Untuk mempelajari selengkapnya tentang bekerja dengan SageMaker AI, lihat SageMaker Memulai Instans Notebook Amazon AI di Panduan Pengembang Amazon SageMaker AI.
Memberikan akses pengguna basis data ke machine learning Aurora
Pengguna database harus diberikan izin untuk menjalankan fungsi pembelajaran mesin Aurora. Cara Anda memberikan izin tergantung pada versi My SQL yang Anda gunakan untuk cluster Aurora My SQL DB Anda, sebagaimana diuraikan dalam berikut ini. Bagaimana Anda melakukannya tergantung pada versi My SQL yang digunakan cluster Aurora My SQL DB Anda.
Untuk Aurora My SQL version 3 (My SQL 8.0 kompatibel), pengguna database harus diberikan peran database yang sesuai. Untuk informasi selengkapnya, lihat Menggunakan Peran
di Manual Referensi SQL 8.0 Saya. Untuk Aurora My SQL version 2 (My SQL 5.7 kompatibel), pengguna database diberikan hak istimewa. Untuk informasi selengkapnya, lihat Kontrol Akses dan Manajemen Akun
di Manual Referensi SQL 5.7 Saya.
Tabel berikut menunjukkan peran dan hak istimewa yang dibutuhkan pengguna database untuk bekerja dengan fungsi pembelajaran mesin.
| Aurora SQL Versi saya 3 (peran) | Aurora SQL Versi saya 2 (hak istimewa) |
|---|---|
|
AWS_BEDROCK_ACCESS |
– |
|
AWS_COMPREHEND_ACCESS |
INVOKE COMPREHEND |
|
AWS_SAGEMAKER_ACCESS |
INVOKE SAGEMAKER |
Memberikan akses ke fungsi Amazon Bedrock
Untuk memberi pengguna database akses ke fungsi Amazon Bedrock, gunakan SQL pernyataan berikut:
GRANT AWS_BEDROCK_ACCESS TOuser@domain-or-ip-address;
Pengguna database juga perlu diberikan EXECUTE izin untuk fungsi yang Anda buat untuk bekerja dengan Amazon Bedrock:
GRANT EXECUTE ON FUNCTIONdatabase_name.function_nameTOuser@domain-or-ip-address;
Terakhir, pengguna database harus mengatur peran mereka keAWS_BEDROCK_ACCESS:
SET ROLE AWS_BEDROCK_ACCESS;
Fungsi Amazon Bedrock sekarang tersedia untuk digunakan.
Memberikan akses ke fungsi Amazon Comprehend
Untuk memberi pengguna database akses ke fungsi Amazon Comprehend, gunakan pernyataan yang sesuai untuk versi Aurora Saya. SQL
Aurora SQL Versi saya 3 (kompatibel dengan SQL 8.0 saya)
GRANT AWS_COMPREHEND_ACCESS TOuser@domain-or-ip-address;Aurora SQL Versi saya 2 (kompatibel dengan SQL 5.7 saya)
GRANT INVOKE COMPREHEND ON *.* TOuser@domain-or-ip-address;
Fungsi Amazon Comprehend sekarang tersedia untuk digunakan. Untuk contoh penggunaan, lihat Menggunakan Amazon Comprehend dengan cluster Aurora My DB Anda SQL.
Memberikan akses ke fungsi SageMaker AI
Untuk memberi pengguna database akses ke fungsi SageMaker AI, gunakan pernyataan yang sesuai untuk versi Aurora My SQL Anda.
Aurora SQL Versi saya 3 (kompatibel dengan SQL 8.0 saya)
GRANT AWS_SAGEMAKER_ACCESS TOuser@domain-or-ip-address;Aurora SQL Versi saya 2 (kompatibel dengan SQL 5.7 saya)
GRANT INVOKE SAGEMAKER ON *.* TOuser@domain-or-ip-address;
Pengguna database juga perlu diberikan EXECUTE izin untuk fungsi yang Anda buat untuk bekerja dengan SageMaker AI. Misalkan Anda membuat dua fungsi, db1.anomoly_score dandb2.company_forecasts, untuk memanggil layanan titik akhir SageMaker AI Anda. Anda memberikan hak istimewa eksekusi seperti yang ditunjukkan pada contoh berikut.
GRANT EXECUTE ON FUNCTION db1.anomaly_score TOuser1@domain-or-ip-address1; GRANT EXECUTE ON FUNCTION db2.company_forecasts TOuser2@domain-or-ip-address2;
Fungsi SageMaker AI sekarang tersedia untuk digunakan. Untuk contoh penggunaan, lihat Menggunakan SageMaker AI dengan cluster Aurora My SQL DB Anda.
Menggunakan Amazon Bedrock dengan cluster Aurora My DB SQL Anda
Untuk menggunakan Amazon Bedrock, Anda membuat fungsi (UDF) yang ditentukan pengguna di SQL database Aurora My yang memanggil model. Untuk informasi selengkapnya, lihat Model yang didukung di Amazon Bedrock di Panduan Pengguna Amazon Bedrock.
A UDF menggunakan sintaks berikut:
CREATE FUNCTIONfunction_name(argumenttype) [DEFINER = user] RETURNSmysql_data_type[SQL SECURITY {DEFINER | INVOKER}] ALIAS AWS_BEDROCK_INVOKE_MODEL MODEL ID 'model_id' [CONTENT_TYPE 'content_type'] [ACCEPT 'content_type'] [TIMEOUT_MStimeout_in_milliseconds];
-
Fungsi Amazon Bedrock tidak mendukung
RETURNS JSON. Anda dapat menggunakanCONVERTatauCASTmengonversi dariTEXTkeJSONjika diperlukan. -
Jika Anda tidak menentukan
CONTENT_TYPEatauACCEPT, defaultnya adalahapplication/json. -
Jika Anda tidak menentukan
TIMEOUT_MS, nilai untukaurora_ml_inference_timeoutdigunakan.
Misalnya, berikut ini UDF memanggil model Amazon Titan Text Express:
CREATE FUNCTION invoke_titan (request_body TEXT) RETURNS TEXT ALIAS AWS_BEDROCK_INVOKE_MODEL MODEL ID 'amazon.titan-text-express-v1' CONTENT_TYPE 'application/json' ACCEPT 'application/json';
Untuk memungkinkan pengguna DB menggunakan fungsi ini, gunakan SQL perintah berikut:
GRANT EXECUTE ON FUNCTIONdatabase_name.invoke_titan TOuser@domain-or-ip-address;
Kemudian pengguna dapat memanggil invoke_titan seperti fungsi lainnya, seperti yang ditunjukkan pada contoh berikut. Pastikan untuk memformat badan permintaan sesuai dengan model teks Amazon Titan.
CREATE TABLE prompts (request varchar(1024)); INSERT INTO prompts VALUES ( '{ "inputText": "Generate synthetic data for daily product sales in various categories - include row number, product name, category, date of sale and price. Produce output in JSON format. Count records and ensure there are no more than 5.", "textGenerationConfig": { "maxTokenCount": 1024, "stopSequences": [], "temperature":0, "topP":1 } }'); SELECT invoke_titan(request) FROM prompts; {"inputTextTokenCount":44,"results":[{"tokenCount":296,"outputText":" ```tabular-data-json { "rows": [ { "Row Number": "1", "Product Name": "T-Shirt", "Category": "Clothing", "Date of Sale": "2024-01-01", "Price": "$20" }, { "Row Number": "2", "Product Name": "Jeans", "Category": "Clothing", "Date of Sale": "2024-01-02", "Price": "$30" }, { "Row Number": "3", "Product Name": "Hat", "Category": "Accessories", "Date of Sale": "2024-01-03", "Price": "$15" }, { "Row Number": "4", "Product Name": "Watch", "Category": "Accessories", "Date of Sale": "2024-01-04", "Price": "$40" }, { "Row Number": "5", "Product Name": "Phone Case", "Category": "Accessories", "Date of Sale": "2024-01-05", "Price": "$25" } ] } ```","completionReason":"FINISH"}]}
Untuk model lain yang Anda gunakan, pastikan untuk memformat badan permintaan dengan tepat untuk mereka. Untuk informasi selengkapnya, lihat Parameter inferensi untuk model foundation di Panduan Pengguna Amazon Bedrock.
Menggunakan Amazon Comprehend dengan cluster Aurora My DB Anda SQL
Untuk Aurora My, pembelajaran mesin SQL Aurora menyediakan dua fungsi bawaan berikut untuk bekerja dengan Amazon Comprehend dan data teks Anda. Anda memberikan teks untuk menganalisis (input_data) dan menentukan bahasa (language_code).
- aws_comprehend_detect_sentiment
-
Fungsi ini mengidentifikasi teks seolah-olah memiliki postur emosional positif, negatif, netral, atau campuran. Dokumentasi referensi fungsi ini adalah sebagai berikut.
aws_comprehend_detect_sentiment( input_text, language_code [,max_batch_size] )Untuk mempelajari selengkapnya, lihat Sentimen di Panduan Developer Amazon Comprehend.
- aws_comprehend_detect_sentiment_confidence
-
Fungsi ini mengukur tingkat kepercayaan sentimen yang terdeteksi untuk teks tertentu. Ia menampilkan nilai (type,
double) yang menunjukkan kepercayaan sentimen yang ditetapkan oleh fungsi aws_comprehend_detect_sentiment ke teks. Keyakinan adalah metrik statistik antara 0 dan 1. Makin tinggi tingkat kepercayaan, makin berat hasil yang bisa Anda berikan. Ringkasan dokumentasi fungsinya adalah sebagai berikut.aws_comprehend_detect_sentiment_confidence( input_text, language_code [,max_batch_size] )
Di kedua fungsi (aws_comprehend_detect_sentiment_confidence, aws_comprehend_detect_sentiment), max_batch_size menggunakan nilai default 25 jika tidak ada yang ditentukan. Ukuran Batch harus selalu lebih besar dari 0. Anda dapat menggunakan max_batch_size untuk menyetel performa dari panggilan fungsi Amazon Comprehend. Ukuran batch yang besar memperdagangkan kinerja yang lebih cepat untuk penggunaan memori yang lebih besar di cluster Aurora My SQL DB. Untuk informasi selengkapnya, lihat Pertimbangan kinerja untuk menggunakan pembelajaran mesin Aurora dengan Aurora My SQL.
Untuk informasi selengkapnya tentang parameter dan tipe pengembalian untuk fungsi deteksi sentimen di Amazon Comprehend, lihat DetectSentiment
contoh Contoh: Kueri sederhana menggunakan fungsi Amazon Comprehend
Berikut adalah contoh kueri sederhana yang menginvokasi dua fungsi ini untuk melihat seberapa senang pelanggan Anda dengan tim dukungan Anda. Misalkan Anda memiliki tabel basis data (support) yang menyimpan umpan balik pelanggan setelah setiap permintaan bantuan. Contoh kueri ini menerapkan kedua fungsi default ke teks di kolom feedback dari tabel dan menampilkan hasilnya. Nilai kepercayaan yang ditampilkan oleh fungsi adalah ganda, antara 0,0 dan 1,0. Untuk output yang lebih mudah dibaca, kueri ini membulatkan hasil menjadi 6 poin desimal. Untuk perbandingan yang lebih mudah, kueri ini juga mengurutkan hasil dalam urutan menurun, dari hasil yang memiliki tingkat kepercayaan tertinggi, pertama.
SELECT feedback AS 'Customer feedback', aws_comprehend_detect_sentiment(feedback, 'en') AS Sentiment, ROUND(aws_comprehend_detect_sentiment_confidence(feedback, 'en'), 6) AS Confidence FROM support ORDER BY Confidence DESC;+----------------------------------------------------------+-----------+------------+ | Customer feedback | Sentiment | Confidence | +----------------------------------------------------------+-----------+------------+ | Thank you for the excellent customer support! | POSITIVE | 0.999771 | | The latest version of this product stinks! | NEGATIVE | 0.999184 | | Your support team is just awesome! I am blown away. | POSITIVE | 0.997774 | | Your product is too complex, but your support is great. | MIXED | 0.957958 | | Your support tech helped me in fifteen minutes. | POSITIVE | 0.949491 | | My problem was never resolved! | NEGATIVE | 0.920644 | | When will the new version of this product be released? | NEUTRAL | 0.902706 | | I cannot stand that chatbot. | NEGATIVE | 0.895219 | | Your support tech talked down to me. | NEGATIVE | 0.868598 | | It took me way too long to get a real person. | NEGATIVE | 0.481805 | +----------------------------------------------------------+-----------+------------+ 10 rows in set (0.1898 sec)
contoh Contoh: Menentukan sentimen rata-rata untuk teks di atas tingkat kepercayaan tertentu
Kueri Amazon Comprehend biasanya mencari baris di mana sentimennya adalah nilai tertentu, dengan tingkat kepercayaan yang lebih besar dari angka tertentu. Misalnya, kueri berikut ini memperlihatkan bagaimana Anda bisa menentukan sentimen rata-rata dokumen di basis data Anda. Kueri hanya mempertimbangkan dokumen dengan tingkat kepercayaan penilaian minimal 80%.
SELECT AVG(CASE aws_comprehend_detect_sentiment(productTable.document, 'en') WHEN 'POSITIVE' THEN 1.0 WHEN 'NEGATIVE' THEN -1.0 ELSE 0.0 END) AS avg_sentiment, COUNT(*) AS total FROM productTable WHERE productTable.productCode = 1302 AND aws_comprehend_detect_sentiment_confidence(productTable.document, 'en') >= 0.80;
Menggunakan SageMaker AI dengan cluster Aurora My SQL DB Anda
Untuk menggunakan fungsionalitas SageMaker AI dari cluster Aurora My SQL DB Anda, Anda perlu membuat fungsi tersimpan yang menyematkan panggilan Anda ke titik akhir SageMaker AI dan fitur inferensinya. Anda melakukannya dengan menggunakan My SQL secara umum dengan cara yang sama seperti yang Anda lakukan untuk tugas pemrosesan lainnya di cluster Aurora My SQL DB Anda. CREATE FUNCTION
Untuk menggunakan model yang diterapkan di SageMaker AI untuk inferensi, Anda membuat fungsi yang ditentukan pengguna menggunakan pernyataan My SQL data definition language (DDL) untuk fungsi yang disimpan. Setiap fungsi yang disimpan mewakili titik akhir SageMaker AI yang menghosting model. Saat Anda menentukan fungsi seperti itu, Anda menentukan parameter input ke model, titik akhir SageMaker AI spesifik yang akan dipanggil, dan jenis pengembalian. Fungsi mengembalikan inferensi yang dihitung oleh titik akhir SageMaker AI setelah menerapkan model ke parameter input.
Semua fungsi tersimpan machine learning Aurora menampilkan tipe numerik atau VARCHAR. Anda dapat menggunakan jenis numerik kecuali BIT. Jenis lainnya, seperti JSON, BLOB, TEXT, dan DATE tidak diizinkan.
Contoh berikut menunjukkan CREATE FUNCTION sintaks untuk bekerja dengan SageMaker AI.
CREATE FUNCTION function_name (
arg1 type1,
arg2 type2, ...)
[DEFINER = user]
RETURNS mysql_type
[SQL SECURITY { DEFINER | INVOKER } ]
ALIAS AWS_SAGEMAKER_INVOKE_ENDPOINT
ENDPOINT NAME 'endpoint_name'
[MAX_BATCH_SIZE max_batch_size];
Ini adalah perpanjangan dari CREATE FUNCTION DDL pernyataan reguler. Dalam CREATE FUNCTION pernyataan yang mendefinisikan fungsi SageMaker AI, Anda tidak menentukan badan fungsi. Alih-alih, Anda menentukan kata kunci ALIAS yang biasanya digunakan oleh badan fungsi. Saat ini, machine learning Aurora hanya mendukung aws_sagemaker_invoke_endpoint untuk sintaksis yang diperluas ini. Anda harus menentukan parameter endpoint_name. Titik akhir SageMaker AI dapat memiliki karakteristik yang berbeda untuk setiap model.
catatan
Untuk informasi selengkapnya tentangCREATE FUNCTION, lihat CREATEPROCEDUREdan CREATE FUNCTION Pernyataan
Parameter max_batch_size bersifat opsional. Secara default, ukuran batch maksimum adalah 10.000. Anda dapat menggunakan parameter ini dalam fungsi Anda untuk membatasi jumlah maksimum input yang diproses dalam permintaan batch ke AI. SageMaker max_batch_sizeParameter dapat membantu menghindari kesalahan yang disebabkan oleh input yang terlalu besar, atau membuat SageMaker AI mengembalikan respons lebih cepat. Parameter ini memengaruhi ukuran buffer internal yang digunakan untuk pemrosesan permintaan SageMaker AI. Menentukan nilai yang terlalu besar untuk max_batch_size dapat menyebabkan overhead memori yang besar pada instans DB Anda.
Sebaiknya biarkan pengaturan MANIFEST pada nilai default OFF. Meskipun Anda dapat menggunakan MANIFEST ON opsi ini, beberapa fitur SageMaker AI tidak dapat langsung menggunakan yang CSV diekspor dengan opsi ini. Format manifes tidak kompatibel dengan format manifes yang diharapkan dari SageMaker AI.
Anda membuat fungsi tersimpan terpisah untuk setiap model SageMaker AI Anda. Pemetaan fungsi ke model ini diperlukan karena titik akhir dikaitkan dengan model tertentu, dan setiap model menerima parameter yang berbeda. Menggunakan SQL tipe untuk input model dan tipe keluaran model membantu menghindari kesalahan konversi tipe yang meneruskan data bolak-balik antara AWS layanan. Anda dapat mengontrol siapa yang dapat menerapkan model tersebut. Anda juga dapat mengontrol karakteristik runtime dengan menentukan parameter yang mewakili ukuran batch maksimum.
Saat ini, semua fungsi machine learning Aurora memiliki properti NOT DETERMINISTIC. Jika Anda tidak menentukan properti tersebut secara eksplisit, Aurora menyetel NOT DETERMINISTIC secara otomatis. Persyaratan ini karena model SageMaker AI dapat diubah tanpa pemberitahuan apa pun ke database. Jika itu terjadi, panggilan ke fungsi machine learning Aurora mungkin menampilkan hasil yang berbeda untuk input yang sama dalam satu transaksi.
Anda tidak dapat menggunakan karakteristik CONTAINS SQL, NO SQL, READS SQL DATA, atau MODIFIES SQL DATA dalam pernyataan CREATE
FUNCTION Anda.
Berikut ini adalah contoh penggunaan titik akhir SageMaker AI untuk mendeteksi anomali. Ada titik akhir SageMaker random-cut-forest-model AI. Model yang sesuai sudah dilatih oleh algoritma random-cut-forest. Untuk setiap input, model menampilkan skor anomali. Contoh ini menunjukkan poin data yang nilainya lebih besar dari 3 deviasi standar (kira-kira persentil ke-99,9) dari skor rata-rata.
CREATE FUNCTION anomaly_score(value real) returns real
alias aws_sagemaker_invoke_endpoint endpoint name 'random-cut-forest-model-demo';
set @score_cutoff = (select avg(anomaly_score(value)) + 3 * std(anomaly_score(value)) from nyc_taxi);
select *, anomaly_detection(value) score from nyc_taxi
where anomaly_detection(value) > @score_cutoff;
Persyaratan set karakter untuk fungsi SageMaker AI yang mengembalikan string
Sebaiknya tentukan kumpulan karakter utf8mb4 sebagai tipe pengembalian untuk fungsi SageMaker AI Anda yang mengembalikan nilai string. Jika itu tidak praktis, gunakan panjang string yang cukup besar agar jenis kembalian dapat menampung nilai yang direpresentasikan dalam kumpulan karakter utf8mb4. Contoh berikut menunjukkan cara mendeklarasikan set karakter utf8mb4 untuk fungsi Anda.
CREATE FUNCTION my_ml_func(...) RETURNS VARCHAR(5) CHARSET utf8mb4 ALIAS ...Saat ini, setiap fungsi SageMaker AI yang mengembalikan string menggunakan set karakter utf8mb4 untuk nilai yang dikembalikan. Nilai yang dikembalikan menggunakan set karakter ini meskipun fungsi SageMaker AI Anda mendeklarasikan set karakter yang berbeda untuk tipe pengembaliannya secara implisit atau eksplisit. Jika fungsi SageMaker AI Anda mendeklarasikan set karakter yang berbeda untuk nilai yang dikembalikan, data yang dikembalikan mungkin terpotong secara diam-diam jika Anda menyimpannya di kolom tabel yang tidak cukup panjang. Misalnya, kueri dengan klausa DISTINCT membuat tabel sementara. Dengan demikian, hasil fungsi SageMaker AI mungkin terpotong karena cara string ditangani secara internal selama kueri.
Mengekspor data ke Amazon S3 SageMaker untuk pelatihan model AI (Lanjutan)
Kami menyarankan Anda memulai pembelajaran mesin Aurora dan SageMaker AI dengan menggunakan beberapa algoritme yang disediakan, dan bahwa ilmuwan data di tim Anda memberi Anda titik akhir SageMaker AI yang dapat Anda gunakan dengan kode Anda. SQL Berikut ini, Anda dapat menemukan informasi minimal tentang penggunaan bucket Amazon S3 Anda sendiri dengan model SageMaker AI Anda sendiri dan cluster Aurora My DB Anda. SQL
Machine learning terdiri dari dua langkah utama: pelatihan, dan inferensi. Untuk melatih model SageMaker AI, Anda mengekspor data ke bucket Amazon S3. Bucket Amazon S3 digunakan oleh instance notebook Jupyter SageMaker AI untuk melatih model Anda sebelum digunakan. Anda dapat menggunakan SELECT INTO OUTFILE S3 pernyataan untuk menanyakan data dari cluster Aurora My SQL DB dan menyimpannya langsung ke file teks yang disimpan dalam bucket Amazon S3. Kemudian instans notebook menggunakan data dari bucket Amazon S3 untuk pelatihan.
Pembelajaran mesin Aurora memperluas SELECT INTO OUTFILE sintaks yang ada di Aurora SQL My untuk mengekspor data ke format. CSV CSVFile yang dihasilkan dapat langsung dikonsumsi oleh model yang membutuhkan format ini untuk tujuan pelatihan.
SELECT * INTO OUTFILE S3 's3_uri' [FORMAT {CSV|TEXT} [HEADER]] FROM table_name;Ekstensi mendukung CSV format standar.
-
TEXTFormatnya sama dengan format SQL ekspor Saya yang ada. Ini adalah format default. -
Format
CSVadalah format yang baru diperkenalkan yang mengikuti spesifikasi di RFC-4180. -
Jika Anda menentukan kata kunci opsional
HEADER, file output akan berisi satu baris header. Label di baris header sesuai dengan nama kolom dari pernyataanSELECT. -
Anda masih dapat menggunakan kata kunci
CSVdanHEADERsebagai pengenal.
Sintaks dan tata bahasa SELECT INTO yang diperluas sekarang adalah sebagai berikut:
INTO OUTFILE S3 's3_uri'
[CHARACTER SET charset_name]
[FORMAT {CSV|TEXT} [HEADER]]
[{FIELDS | COLUMNS}
[TERMINATED BY 'string']
[[OPTIONALLY] ENCLOSED BY 'char']
[ESCAPED BY 'char']
]
[LINES
[STARTING BY 'string']
[TERMINATED BY 'string']
]
Pertimbangan kinerja untuk menggunakan pembelajaran mesin Aurora dengan Aurora My SQL
Amazon Bedrock, Amazon Comprehend SageMaker , dan layanan AI melakukan sebagian besar pekerjaan ketika dipanggil oleh fungsi pembelajaran mesin Aurora. Itu berarti Anda dapat menskalakan sumber daya tersebut sesuai kebutuhan, secara mandiri. Untuk cluster Aurora My SQL DB Anda, Anda dapat membuat panggilan fungsi Anda seefisien mungkin. Berikut ini, Anda dapat menemukan beberapa pertimbangan performa yang perlu diperhatikan saat bekerja dengan machine learning Aurora.
Model dan prompt
Performa saat menggunakan Amazon Bedrock sangat bergantung pada model dan prompt yang Anda gunakan. Pilih model dan prompt yang optimal untuk kasus penggunaan Anda.
Cache kueri
Cache SQL kueri Aurora My tidak berfungsi untuk fungsi pembelajaran mesin Aurora. Aurora My SQL tidak menyimpan hasil kueri di cache kueri untuk SQL pernyataan apa pun yang memanggil fungsi pembelajaran mesin Aurora.
Optimalisasi batch untuk panggilan fungsi machine learning Aurora
Aspek performa utama machine learning Aurora yang dapat Anda pengaruhi dari klaster Aurora adalah pengaturan mode batch untuk panggilan ke fungsi tersimpan machine learning Aurora. Fungsi machine learning biasanya membutuhkan overhead yang besar, sehingga tidak praktis untuk memanggil layanan eksternal secara terpisah untuk setiap baris. Machine learning Aurora dapat meminimalkan overhead ini dengan menggabungkan panggilan ke layanan machine learning Aurora eksternal untuk banyak baris ke dalam satu batch. Machine learning Aurora menerima respons untuk semua baris input, dan mengirimkan respons, satu baris dalam satu waktu, ke kueri saat dijalankan. Pengoptimalan ini meningkatkan throughput dan latensi kueri Aurora Anda tanpa mengubah hasil.
Saat Anda membuat fungsi tersimpan Aurora yang terhubung ke titik akhir SageMaker AI, Anda menentukan parameter ukuran batch. Parameter ini memengaruhi berapa banyak baris yang ditransfer untuk setiap panggilan yang mendasarinya ke SageMaker AI. Untuk kueri yang memproses sejumlah besar baris, overhead untuk membuat panggilan SageMaker AI terpisah untuk setiap baris bisa sangat besar. Semakin besar kumpulan data yang diproses oleh prosedur tersimpan, semakin besar Anda dapat membuat ukuran batch.
Jika pengoptimalan mode batch dapat diterapkan ke fungsi SageMaker AI, Anda dapat mengetahuinya dengan memeriksa paket kueri yang dihasilkan oleh EXPLAIN PLAN pernyataan tersebut. Dalam kasus ini, kolom extra dalam rencana eksekusi termasuk Batched machine learning. Contoh berikut menunjukkan panggilan ke fungsi SageMaker AI yang menggunakan mode batch.
mysql> CREATE FUNCTION anomaly_score(val real) returns real alias aws_sagemaker_invoke_endpoint endpoint name 'my-rcf-model-20191126';
Query OK, 0 rows affected (0.01 sec)
mysql> explain select timestamp, value, anomaly_score(value) from nyc_taxi;
+----+-------------+----------+------------+------+---------------+------+---------+------+------+----------+--------------------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+----------+------------+------+---------------+------+---------+------+------+----------+--------------------------+
| 1 | SIMPLE | nyc_taxi | NULL | ALL | NULL | NULL | NULL | NULL | 48 | 100.00 | Batched machine learning |
+----+-------------+----------+------------+------+---------------+------+---------+------+------+----------+--------------------------+
1 row in set, 1 warning (0.01 sec)
Saat Anda memanggil salah satu fungsi Amazon Comprehend default, Anda dapat mengontrol ukuran batch dengan menentukan parameter max_batch_size opsional. Parameter ini membatasi jumlah maksimum nilai input_text yang diproses di setiap batch. Dengan mengirim beberapa item sekaligus, ini mengurangi jumlah perjalanan bolak-balik antara Aurora dan Amazon Comprehend. Membatasi ukuran batch berguna dalam situasi seperti kueri dengan klausa LIMIT. Dengan menggunakan nilai kecil untuk max_batch_size, Anda dapat menghindari permintaan Amazon Comprehend lebih sering daripada Anda memiliki teks input.
Optimalisasi batch untuk mengevaluasi fungsi machine learning Aurora berlaku dalam kasus berikut:
-
Fungsi panggilan dalam daftar pilih atau
WHEREklausa pernyataanSELECT -
Panggilan fungsi dalam
VALUESdaftarINSERTdanREPLACEpernyataan -
SageMaker Fungsi AI dalam
SETnilai dalamUPDATEpernyataan:INSERT INTO MY_TABLE (col1, col2, col3) VALUES (ML_FUNC(1), ML_FUNC(2), ML_FUNC(3)), (ML_FUNC(4), ML_FUNC(5), ML_FUNC(6)); UPDATE MY_TABLE SET col1 = ML_FUNC(col2), SET col3 = ML_FUNC(col4) WHERE ...;
Memantau machine learning Aurora
Anda dapat memantau operasi batch pembelajaran mesin Aurora dengan menanyakan beberapa variabel global, seperti yang ditunjukkan pada contoh berikut.
show status like 'Aurora_ml%';
Anda dapat mengatur ulang variabel status dengan menggunakan pernyataan FLUSH STATUS. Jadi, semua angka mewakili total, rata-rata, dan seterusnya, sejak terakhir kali variabel disetel ulang.
Aurora_ml_logical_request_cnt-
Jumlah permintaan logis yang telah dievaluasi instans DB untuk dikirim ke layanan machine learning Aurora sejak status pengaturan ulang status terakhir. Bergantung pada apakah proses batching telah digunakan, nilai ini dapat lebih tinggi dari
Aurora_ml_actual_request_cnt. Aurora_ml_logical_response_cnt-
Jumlah respons agregat yang diterima Aurora SQL My dari layanan pembelajaran mesin Aurora di semua kueri yang dijalankan oleh pengguna instans DB.
Aurora_ml_actual_request_cnt-
Jumlah permintaan agregat yang dibuat Aurora SQL My ke layanan pembelajaran mesin Aurora di semua kueri yang dijalankan oleh pengguna instans DB.
Aurora_ml_actual_response_cnt-
Jumlah respons agregat yang diterima Aurora SQL My dari layanan pembelajaran mesin Aurora di semua kueri yang dijalankan oleh pengguna instans DB.
Aurora_ml_cache_hit_cnt-
Jumlah cache internal agregat yang diterima Aurora SQL My dari layanan pembelajaran mesin Aurora di semua kueri yang dijalankan oleh pengguna instans DB.
Aurora_ml_retry_request_cnt-
Jumlah permintaan yang dicoba ulang yang dikirim instans DB ke layanan machine learning Aurora sejak pengaturan ulang status terakhir.
Aurora_ml_single_request_cnt-
Jumlah gabungan fungsi machine learning Aurora yang dievaluasi oleh mode non-batch di semua kueri yang dijalankan oleh pengguna instans DB.
Untuk informasi tentang pemantauan kinerja operasi SageMaker AI yang disebut dari fungsi pembelajaran mesin Aurora, lihat Memantau Amazon SageMaker AI.
