Le traduzioni sono generate tramite traduzione automatica. In caso di conflitto tra il contenuto di una traduzione e la versione originale in Inglese, quest'ultima prevarrà.
Che cos'è S3 Express One Zone?
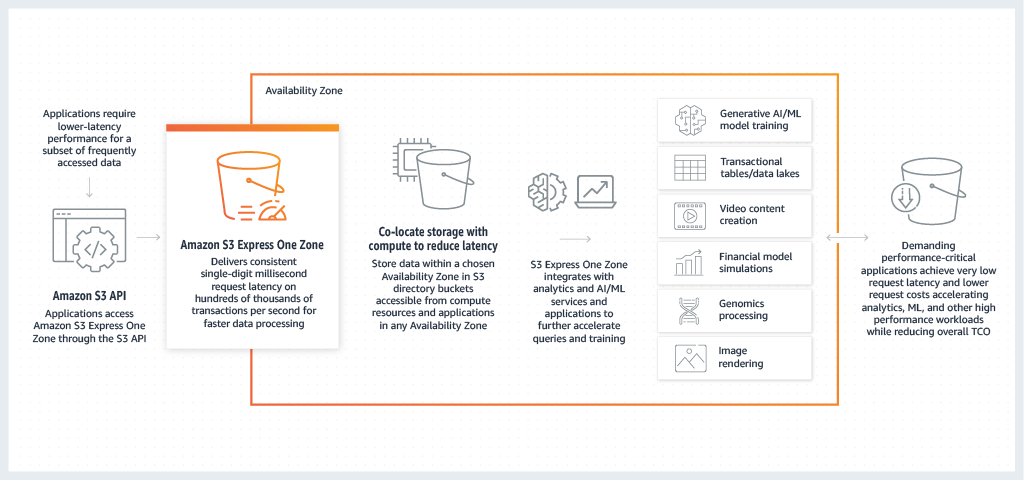
Amazon S3 Express One Zone è una classe di archiviazione Amazon S3 a zona singola ad alte prestazioni, creata appositamente per fornire un accesso ai dati coerente di pochi millisecondi per le applicazioni sensibili alla latenza. S3 Express One Zone è la classe di storage di oggetti cloud con la latenza più bassa disponibile oggi, con velocità di accesso ai dati fino a 10 volte più veloci e con costi di richiesta inferiori del 50% rispetto a S3 Standard. Le applicazioni possono trarre immediatamente vantaggio dal fatto che le richieste vengano completate fino a un ordine di grandezza più velocemente. S3 Express One Zone offre un'elasticità prestazionale simile a quella delle altre classi di storage S3.
Come per le altre classi di storage di Amazon S3, non è necessario pianificare o fornire in anticipo i requisiti di capacità o throughput. Puoi aumentare o ridurre lo storage in base alle necessità e accedere ai dati tramite l'API Amazon S3.
S3 Express One Zone è la prima classe di archiviazione S3 in cui è possibile selezionare una singola zona di disponibilità con la possibilità di co-ubicare l'archiviazione di oggetti con le risorse di calcolo, che offre la massima velocità di accesso possibile. Inoltre, per aumentare ulteriormente la velocità di accesso e supportare centinaia di migliaia di richieste al secondo, i dati nella classe di storage S3 Express One Zone vengono archiviati in un nuovo tipo di bucket: un bucket di directory Amazon S3. Ogni bucket di directory può supportare centinaia di migliaia di transazioni al secondo (TPS), a prescindere dai nomi delle chiavi o dal modello di accesso.
La classe di storage Amazon S3 Express One Zone è progettata per una disponibilità del 99,95% all'interno di una singola zona di disponibilità ed è supportata dal Service Level Agreement di Amazon S3
S3 Express One Zone è ideale per qualsiasi applicazione in cui è importante ridurre al minimo la latenza richiesta per accedere a un oggetto. Tali applicazioni possono essere flussi di lavoro interattivi con l'uomo, come l'editing video, in cui i professionisti creativi necessitano di un accesso reattivo ai contenuti dalle loro interfacce utente. S3 Express One Zone beneficia, inoltre, di carichi di lavoro di analisi e machine learning che hanno requisiti di reattività simili ai relativi dati, in particolare carichi di lavoro con molti accessi più piccoli o un numero elevato di accessi casuali. S3 Express One Zone può essere utilizzato con altri Servizi AWS per supportare carichi di lavoro di analisi, intelligenza artificiale e machine learning (AI/ML), come Amazon EMR, SageMaker Amazon e Amazon Athena.
Quando usi S3 Express One Zone, puoi interagire con il tuo bucket di directory in un cloud privato virtuale (VPC) utilizzando un endpoint VPC gateway. Con un endpoint gateway, puoi accedere ai bucket di directory S3 Express One Zone dal tuo VPC senza un gateway Internet o un dispositivo NAT per il tuo VPC e senza costi aggiuntivi.
Puoi utilizzare molte delle stesse operazioni e funzionalità dell'API di Amazon S3 con i bucket di directory utilizzati con i bucket generici e altre classi di storage. Queste includono Mountpoint per Amazon S3, crittografia lato server con chiavi gestite da Amazon S3 (SSE-S3), Operazioni in batch S3 e Blocco dell'accesso pubblico S3. Puoi accedere a S3 Express One Zone utilizzando la console Amazon S3 AWS Command Line Interface ,AWS CLI() AWS , gli SDK e l'API REST di Amazon S3.
Per ulteriori informazioni su S3 Express One Zone, consulta i seguenti argomenti.
Panoramica
Per ottimizzare le prestazioni e ridurre la latenza, S3 Express One Zone introduce i seguenti nuovi concetti.
Zona di disponibilità singola
La classe di storage Amazon S3 Express One Zone è progettata per una disponibilità del 99,95% all'interno di una singola zona di disponibilità ed è supportata dal Service Level Agreement di Amazon S3
Una zona di disponibilità consiste in uno o più data center separati con alimentazione, rete e connettività ridondanti in una Regione AWS. Quando crei un bucket di directory, scegli la zona di disponibilità e Regione AWS dove collocare il bucket.
Bucket di directory
Esistono due tipi di bucket Amazon S3: i bucket generici S3 e i bucket di directory S3. I bucket per uso generico sono il tipo di bucket Amazon S3 predefinito utilizzato per la maggior parte dei casi d'uso S3. I bucket di directory utilizzano solo la classe di archiviazione S3 Express One Zone, progettata per carichi di lavoro o applicazioni con prestazioni critiche che richiedono una latenza costante di pochi millisecondi. Scegli il tipo di bucket più adatto alle tue esigenze applicative e prestazionali.
I bucket di directory organizzano i dati gerarchicamente in directory, a differenza della struttura di archiviazione piatta dei bucket generici. Non ci sono limiti di prefissi per i bucket di directory e le singole directory possono essere dimensionate orizzontalmente.
I bucket di directory utilizzano la classe di archiviazione S3 Express One Zone, creata per essere utilizzata da applicazioni sensibili alle prestazioni. Con S3 Express One Zone, puoi selezionare una singola zona di disponibilità con la possibilità di co-localizzare lo storage di oggetti con le tue risorse di elaborazione, il che offre la massima velocità di accesso possibile. Ciò è diverso dai bucket per uso generico, che archiviano oggetti in modo ridondante su più zone di disponibilità in. Regioni AWS
Per ulteriori informazioni sui bucket di directory, consulta Bucks di directory. Per ulteriori informazioni sui bucket per uso generico, consulta Panoramica dei bucket.
Endpoint ed endpoint VPC del gateway
Le operazioni API di gestione dei bucket per i bucket di directory sono disponibili tramite un endpoint regionale e sono denominate operazioni API degli endpoint regionali. Esempi di operazioni API degli endpoint regionali sono CreateBucket e DeleteBucket. Dopo aver creato un bucket di directory, puoi utilizzare le operazioni API degli endpoint zonali per caricare e gestire gli oggetti nel bucket di directory. Le operazioni API degli endpoint zonali sono disponibili tramite un endpoint zonale. Esempi di operazioni API degli endpoint zonali sono PutObject e CopyObject.
Puoi accedere a S3 Express One Zone dal tuo VPC utilizzando gli endpoint VPC gateway. Dopo aver creato un endpoint del gateway, puoi aggiungerlo come una destinazione nella tabella di routing per il traffico in transito dal VPC a S3 Express One Zone. Analogamente ad Amazon S3, l'utilizzo di endpoint del gateway non comporta costi supplementari. Per ulteriori informazioni su come configurare gli endpoint VPC del gateway, consulta Servizi di rete per S3 Express One Zone
Autorizzazione basata sulla sessione
Con S3 Express One Zone, autentichi e autorizzi le richieste tramite un nuovo meccanismo basato sulla sessione, ottimizzato per fornire la latenza più bassa. Puoi utilizzare CreateSession per richiedere credenziali temporanee che forniscono un accesso a bassa latenza al bucket. Queste credenziali temporanee sono definite per un bucket di directory S3 specifico. I token di sessione vengono utilizzati solo con operazioni zonali (a livello di oggetto) (ad eccezione di). CopyObject Per ulteriori informazioni, consulta Autorizzazione CreateSession.
Gli AWS SDK supportati per S3 Express One Zone gestiscono la creazione e l'aggiornamento delle sessioni per tuo conto. Per proteggere le sessioni, le credenziali di sicurezza temporanee scadono dopo 5 minuti. Dopo aver scaricato e installato gli AWS SDK e configurato le autorizzazioni AWS Identity and Access Management (IAM) necessarie, puoi iniziare immediatamente a utilizzare le operazioni API.
Funzionalità di S3 Express One Zone
Le seguenti funzionalità S3 sono disponibili per S3 Express One Zone. Per un elenco completo delle operazioni API supportate e delle funzionalità non supportate, consulta. In cosa differisce S3 Express One Zone?
Gestione degli accessi e sicurezza
Con i bucket di directory, puoi utilizzare le seguenti funzionalità per eseguire l'audit e gestire l'accesso. Per impostazione predefinita, i bucket di directory sono privati e l'accesso è possibile solo dagli utenti a cui è concesso esplicitamente l'accesso. A differenza dei bucket per uso generico, che possono impostare il limite di controllo dell'accesso a livello di bucket, prefisso o tag dell'oggetto, il limite di controllo dell'accesso per i bucket di directory viene impostato solo a livello di bucket. Per ulteriori informazioni, consulta AWS Identity and Access Management (IAM) per S3 Express One Zone.
-
S3 Block Public Access: tutte le impostazioni di S3 Block Public Access sono abilitate per impostazione predefinita a livello di bucket. Questa impostazione predefinita non può essere modificata.
-
S3 Object Ownership (proprietario del bucket applicato per impostazione predefinita): le liste di controllo degli accessi (ACL) non sono supportate per i bucket di directory. I bucket di directory utilizzano automaticamente l'impostazione imposta dal proprietario del bucket per S3 Object Ownership. L'applicazione del proprietario del bucket significa che gli ACL sono disabilitati e il proprietario del bucket possiede automaticamente e ha il pieno controllo su ogni oggetto nel bucket. Questa impostazione predefinita non può essere modificata.
-
AWS Identity and Access Management (IAM): IAM ti aiuta a controllare in modo sicuro l'accesso ai tuoi bucket di directory. Puoi utilizzare IAM per concedere l'accesso alle operazioni API di gestione dei bucket (regionali) e alle operazioni API di gestione degli oggetti (zonali) tramite l'azione.
s3express:CreateSessionPer ulteriori informazioni, consulta AWS Identity and Access Management (IAM) per S3 Express One Zone. A differenza delle azioni di gestione degli oggetti, le azioni di gestione dei bucket non possono essere multi-account. Solo il proprietario del bucket può eseguire tali azioni. -
Policy di bucket: utilizza il linguaggio delle policy basato su IAM per configurare le autorizzazioni basate sulle risorse per i bucket di directory. Puoi anche utilizzare IAM per controllare l'accesso al funzionamento dell'
CreateSessionAPI, il che ti consente di utilizzare le operazioni API Zonal o di gestione degli oggetti. Puoi concedere l'accesso allo stesso account o a più account alle operazioni dell'API Zonal. Per ulteriori informazioni sulle autorizzazioni e le politiche di S3 Express One Zone, consulta. AWS Identity and Access Management (IAM) per S3 Express One Zone -
IAM Access Analyzer for S3: valuta e monitora le tue policy di accesso per assicurarti che forniscano solo l'accesso previsto alle tue risorse S3.
Registrazione di log e monitoraggio
S3 Express One Zone utilizza i seguenti strumenti di registrazione e monitoraggio S3 che puoi utilizzare per monitorare e controllare il modo in cui vengono utilizzate le tue risorse:
-
CloudWatch Parametri Amazon: monitora AWS le tue risorse e le tue applicazioni utilizzandole CloudWatch per raccogliere e tenere traccia dei parametri. S3 Express One Zone utilizza lo stesso spazio dei CloudWatch nomi delle altre classi di storage Amazon S3 (
AWS/S3) e supporta i parametri di storage giornalieri per i bucket di directory: e.BucketSizeBytesNumberOfObjectsPer ulteriori informazioni, consulta Monitoraggio delle metriche con Amazon CloudWatch. -
AWS CloudTrail logs: AWS CloudTrail è uno strumento Servizio AWS che ti aiuta a implementare il controllo operativo e dei rischi, la governance e la conformità della tua azienda registrando le azioni intraprese Account AWS da un utente, ruolo o un. Servizio AWS Per S3 Express One Zone, CloudTrail acquisisce le operazioni delle API degli endpoint regionali (ad esempio,
CreateBucketePutBucketPolicy) come eventi di gestione. Questi eventi includono le azioni intraprese nelle operazioni AWS Management Console, AWS Command Line Interface (AWS CLI), AWS SDK e API. AWS Gli eventieventsourceper la CloudTrail gestione di S3 Express One Zone sono.s3express.amazonaws.comPer ulteriori informazioni, consulta Eventi Amazon S3 CloudTrail .
Nota
I log di accesso al server Amazon S3 non sono supportati con S3 Express One Zone.
Gestione degli oggetti
Dopo aver creato un bucket di directory, puoi gestire lo storage di oggetti utilizzando la console Amazon S3 AWS , gli SDK e. AWS CLI Le seguenti funzionalità sono disponibili per la gestione degli oggetti con S3 Express One Zone:
-
Operazioni Batch S3: utilizza le operazioni batch per eseguire operazioni in blocco sugli oggetti nei bucket di directory, ad esempio la funzione Copy and Invoke. AWS Lambda Ad esempio, puoi utilizzare Operazioni in batch per copiare oggetti tra bucket di directory e bucket per uso generico. Con Batch Operations, puoi gestire miliardi di oggetti su larga scala con una singola richiesta S3 utilizzando gli AWS SDK AWS CLI o con pochi clic nella console Amazon S3.
-
Importa: dopo aver creato un bucket di directory, puoi popolarlo con oggetti utilizzando la funzionalità di importazione nella console Amazon S3. L'importazione è un metodo ottimizzato di creazione di processi Operazioni in batch per copiare oggetti da bucket per uso generico in bucket di directory.
AWS SDK e librerie client
Dopo aver creato un bucket di directory e caricato un oggetto nel bucket, puoi gestire l'archiviazione degli oggetti utilizzando quanto segue.
-
Mountpoint per Amazon
S3 — Mountpoint per Amazon S3 è un client di file open source che offre un accesso a throughput elevato, riducendo i costi di elaborazione per i data lake su Amazon S3. Mountpoint per Amazon S3 traduce le chiamate API del file system locale in chiamate API di oggetti S3 come e. GETLISTÈ ideale per carichi di lavoro di data lake ad alta intensità di lettura che elaborano petabyte di dati e richiedono l'elevata velocità di trasmissione elastica fornita da Amazon S3 per scalare verso l'alto e verso il basso su migliaia di istanze. -
S3A
— S3A è un'interfaccia Hadoop compatibile consigliata per l'accesso agli archivi dati in Amazon S3. S3Asostituisce il client del S3N Hadoop file system. -
PyTorchon AWS — PyTorch on AWS è un framework open source di deep learning che semplifica lo sviluppo di modelli di machine learning e la loro implementazione in produzione.
-
AWS SDK
: puoi utilizzare gli AWS SDK per sviluppare applicazioni con Amazon S3. Gli AWS SDK semplificano le attività di programmazione integrando l'API REST di Amazon S3 sottostante. Per ulteriori informazioni sull'utilizzo degli AWS SDK con S3 Express One Zone, consulta. AWS SDK
Crittografia e protezione dei dati
Gli oggetti archiviati nei bucket di directory vengono crittografati automaticamente utilizzando la crittografia lato server con chiavi gestite di Amazon S3 (SSE-S3). I bucket di directory non supportano la crittografia lato server con chiavi AWS Key Management Service (AWS KMS) (SSE-KMS), la crittografia lato server con chiavi di crittografia fornite dal cliente (SSE-C) o la crittografia lato server a doppio livello con (DSSE-KMS). AWS KMS keys Per ulteriori informazioni, consulta Protezione e crittografia dei dati e Uso della crittografia lato server con chiavi gestite da Amazon S3 (SSE-S3).
S3 Express One Zone offre la possibilità di scegliere l'algoritmo di checksum utilizzato per convalidare i dati durante il caricamento o il download. Puoi selezionare uno dei seguenti algoritmi di controllo dell'integrità dei dati Secure Hash Algorithms (SHA) o Cyclic Redundancy Check (CRC): CRC32, CRC32C, SHA-1 e SHA-256. I checksum basati su MD5 non sono supportati con la classe di storage S3 Express One Zone.
Per ulteriori informazioni, consulta Best practice per il checksum S3 aggiuntivo.
AWS Versione Signature 4 () SigV4
S3 Express One Zone utilizza AWS la versione Signature 4 (SigV4). SigV4è un protocollo di firma utilizzato per autenticare le richieste ad Amazon S3 tramite HTTPS. S3 Express One Zone firma le richieste utilizzando. AWS Sigv4 Per ulteriori informazioni, consulta Authenticating Requests (AWS Signature Version 4) nel riferimento all'API di Amazon Simple Storage Service.
Forte coerenza
S3 Express One Zone offre una forte read-after-write coerenza per DELETE tutte PUT le richieste di oggetti presenti nei bucket di directory. Regioni AWS Per ulteriori informazioni, consulta Modello di consistenza dati Amazon S3.
Servizi correlati
Puoi utilizzare quanto segue Servizi AWS con la classe di storage S3 Express One Zone per supportare il tuo caso d'uso specifico a bassa latenza.
-
Amazon Elastic Compute Cloud (Amazon EC2) — Amazon EC2 fornisce capacità di elaborazione sicura e scalabile in. Cloud AWS L'utilizzo Amazon EC2 riduce la necessità di investimenti anticipati in hardware e ti permette di sviluppare e distribuire più rapidamente le applicazioni. Puoi utilizzare Amazon EC2 per avviare il numero di server virtuali necessari, configurare la sicurezza e i servizi di rete, nonché gestire l'archiviazione.
-
AWS Lambda: Lambda è un servizio di calcolo che consente di eseguire il codice senza provisioning o gestire server. È possibile configurare le impostazioni di notifica su un bucket e concedere ad Amazon S3 l'autorizzazione a invocare una funzione sulla policy di autorizzazione basata sulle risorse della funzione.
-
Amazon Elastic Kubernetes Service (Amazon EKS) — Amazon EKS è un servizio gestito che elimina la necessità di installare, utilizzare e mantenere Kubernetes il proprio piano di controllo. AWSKubernetes
è un sistema open source che automatizza la gestione, la scalabilità e la distribuzione di applicazioni containerizzate. -
Amazon Elastic Container Service (Amazon ECS): Amazon ECS è un servizio di orchestrazione di container completamente gestito che facilita l'implementazione, la gestione e il dimensionamento di applicazioni distribuite in container.
-
Amazon Athena: Athena è un servizio di query interattivo che semplifica l'analisi dei dati direttamente in Amazon S3 utilizzando SQL standard. Puoi anche utilizzare Athena per eseguire analisi dei dati in modo interattivo Apache Spark senza dover pianificare, configurare o gestire le risorse. Quando esegui Apache Spark applicazioni su Athena, invii il Spark codice per l'elaborazione e ricevi direttamente i risultati.
-
Amazon SageMaker Runtime Model Training — Amazon SageMaker Runtime è un servizio di machine learning completamente gestito. Con SageMaker Runtime, data scientist e sviluppatori possono creare e addestrare modelli di machine learning in modo rapido e semplice e poi distribuirli direttamente in un ambiente ospitato pronto per la produzione.
-
AWS Glue— AWS Glue è un servizio di integrazione dei dati senza server che consente agli utenti di analisi di scoprire, preparare, spostare e integrare facilmente i dati provenienti da più fonti. È possibile utilizzarlo AWS Glue per l'analisi, l'apprendimento automatico e lo sviluppo di applicazioni. AWS Glue include anche strumenti di produttività e data-ops aggiuntivi per la creazione, l'esecuzione di lavori e l'implementazione dei flussi di lavoro aziendali.
-
Amazon EMR: Amazon EMR è una piattaforma di cluster gestita che semplifica l'esecuzione di framework di big data, come «and on», AWS per elaborare Apache Hadoop e analizzare Apache Spark grandi quantità di dati.
Passaggi successivi
Per ulteriori informazioni sull'utilizzo della classe di archiviazione S3 Express One Zone e dei bucket di directory, consulta gli argomenti seguenti:
