Amazon RDS のマルチ AZ DB クラスターデプロイ
あるマルチ AZ DB クラスターデプロイは、2 つの読み取り可能なリードレプリカ DB インスタンスを持つ Amazon RDS の準同期の高可用性のデプロイモードです。マルチ AZ DB クラスターには、同じ AWS リージョン に 3 つの別々のアベイラビリティーゾーンに 1 つのライター DB インスタンスと 2 つのリーダー DB インスタンスがあります。マルチ AZ DB クラスターは、マルチ AZ DB インスタンスの配置と比較して、高可用性、読み取りワークロードの容量の増加、および書き込みレイテンシーの低減を提供します。
ダウンタイムを短縮して Amazon RDS for MySQL データベースにデータをインポートする の説明に従って、オンプレミスデータベースからマルチ AZ DB クラスターにデータをインポートできます。
マルチ AZ DB クラスターのリザーブド DB インスタンスを購入できます。詳細については、「マルチ AZ DB クラスターのリザーブド DB インスタンス」を参照してください。
機能の利用可能性とサポートは、各データベースエンジンの特定のバージョン、および AWS リージョン によって異なります。マルチ AZ DB クラスターを使用した Amazon RDS のバージョンとリージョンの可用性の詳細ついては、「Amazon RDS のマルチ AZ DB クラスターでサポートされているリージョンと DB エンジン」を参照してください。
トピック
重要
マルチ AZ DB クラスターは Aurora DB クラスターと同じではありません。Aurora DB クラスターの情報については、Amazon Aurora ユーザーガイドを参照してください。
マルチ AZ DB クラスターで利用できるインスタンスクラス
マルチ AZ DB クラスター配置は、次の DB インスタンスクラスでサポートされています。db.m5d、db.m6gd、db.m6id、db.m6idn、db.r5d、db.r6gd、db.x2iedn、db.r6id、db.r6idn、db.c6gd。
注記
medium インスタンスサイズをサポートするインスタンスクラスは、c6gd インスタンスクラスのみです。
DB インスタンスクラスの詳細については、「 DB インスタンスクラス」を参照してください。
マルチ AZ DB クラスターアーキテクチャ
マルチ AZ DB クラスターでは、Amazon RDS は DB エンジンのネイティブレプリケーション機能を使用して、ライター DB インスタンスから両方のリーダー DB インスタンスにデータを複製します。ライター DB インスタンスに変更が加えられると、各リーダー DB インスタンスに送信されます。
マルチ AZ DB クラスター配置では、準同期レプリケーションを使用します。変更をコミットするには、少なくとも 1 つのリーダー DB インスタンスからの承認が必要です。イベントが完全に実行され、すべてのレプリカでコミットされたことを確認する必要はありません。
リーダー DB インスタンスは自動フェイルオーバーターゲットとして機能し、読み取りトラフィックを処理してアプリケーションの読み取りスループットを向上させます。 ライター DB インスタンスで機能停止が発生した場合、RDS はリーダー DB インスタンスのうち 1 つへのフェイルオーバーを管理します。RDS は、最新の変更記録があるリーダー DB インスタンスを基にこれを実行します。
次の図は、マルチ AZ DB クラスターを示しています。
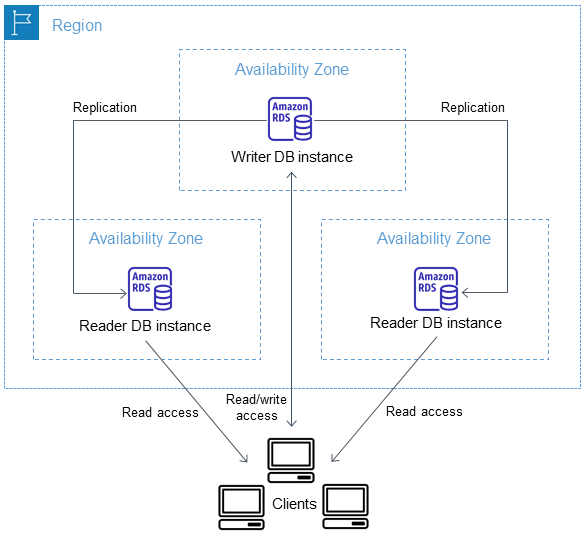
マルチ AZ DB クラスターは、マルチ AZ DB インスタンスの配置と比較して、通常、書き込みレイテンシーが少なくなります。また、リーダー DB インスタンスで読み取り専用ワークロードを実行することもできます。RDS コンソールには、ライター DB インスタンスのアベイラビリティーゾーンとリーダー DB インスタンスのアベイラビリティーゾーンが表示されます。また、 describe-db-clustersCLI コマンドまたはこの情報を見つけるためのDescribeDBClustersAPI オペレーションを使用することもできます。
重要
RDS for MySQL マルチ AZ DB クラスターのレプリケーションエラーを防ぐため、すべてのテーブルにプライマリキーを設定することを強くお勧めします。
マルチ AZ DB クラスターのパラメータグループ
マルチ AZ DBクラスターでは、DB クラスターパラメータグループは、マルチ AZ DB クラスター内のすべての DB インスタンスに適用されるエンジン構成値のコンテナーとして機能します。
マルチ AZ DB クラスターでは、DB パラメータグループは、DB エンジンおよび DB エンジンバージョンのデフォルトの DB パラメータグループに設定されています。DB クラスターパラメータグループの設定は、クラスター内のすべての DB インスタンスに使用されます。
パラメータグループの詳細については、「マルチ AZ DB クラスターの DB クラスターパラメータグループを使用する」を参照してください。
マルチ AZ DB クラスターを備えた RDS Proxy
Amazon RDS Proxy を使用すると、マルチ AZ DB クラスターに対してプロキシを作成できます。RDS プロキシを使用すると、アプリケーションではデータベース接続をプールおよび共有し、そのスケール能力を向上させることができます。各プロキシは、接続の多重化も実行します。これは接続の再利用とも呼ばれます。多重化により、RDS Proxy は 1 つの基となるデータベース接続を使用して 1 つのトランザクションのすべてのオペレーションを実行します。RDS Proxy を使用すると、マルチ AZ DB クラスターのマイナーバージョンアップグレードのダウンタイムを 1 秒以下に短縮することもできます。RDS Prox のメリットの詳細については、「Amazon RDS Proxy」を参照してください。
マルチ AZ DB クラスターのプロキシを設定するには、クラスター作成時に [RDS Proxy の作成] を選択します。RDS Proxy エンドポイントの作成と管理の手順については、「Amazon RDS Proxy エンドポイントの操作」を参照してください。
レプリカの遅延とマルチ AZ DB クラスター
レプリカの遅延とは、ライター DB インスタンスの最新のトランザクションと、リーダー DB インスタンスで最後に適用されたトランザクションとの時間の差です。Amazon CloudWatch メトリクス ReplicaLag は、この時間の差を表します。CloudWatch のメトリクスの詳細については、「Amazon CloudWatch を使用した Amazon RDS メトリクスのモニタリング」を参照してください。
マルチ AZ DB クラスターでは高い書き込みパフォーマンスが得られますが、エンジンベースのレプリケーションの性質上、レプリカの遅延が発生する可能性があります。フェイルオーバーでは、新しいライター DB インスタンスに昇格する前にまずレプリカの遅延を解決する必要があるため、レプリカの遅延のモニタリングおよび管理は考慮事項です。
RDS for MySQL マルチ AZ DB クラスターの場合、フェイルオーバーの時間は残りの両方のリーダー DB インスタンスのレプリカの遅延によって異なります。どちらのリーダー DB インスタンスについても、いずれかが新しいライター DB インスタンスに昇格する前に、未適用のトランザクションを適用する必要があります。
RDS for PostgreSQL マルチ AZ DB クラスターの場合、フェイルオーバーの時間は残りの 2 つのリーダー DB インスタンスの最も低いレプリカの遅延によって異なります。レプリカの遅延が最も低いリーダー DB インスタンスについては、新しいライター DB インスタンスに昇格する前に、未適用のトランザクションを適用する必要があります。
レプリカの遅延が設定された時間を超過した際に CloudWatch アラームを作成する方法のチュートリアルについては、「チュートリアル: Amazon RDS のマルチ AZ DB クラスターレプリカラグ用の Amazon CloudWatch アラームを作成する」を参照してください。
レプリカの遅延の一般的な原因
一般に、レプリカの遅延は書き込みワークロードが高すぎてリーダー DB インスタンスでトランザクションを効率的に適用できない場合に発生します。異なるワークロードでは、一時的に、または継続的にレプリカの遅延が発生する可能性があります。一般的な原因の例をいくつか次に示します。
-
書き込みの同時実行性が高いか、ライター DB インスタンスで大量のバッチ更新が行われるため、リーダー DB インスタンスの適用プロセスが遅れている。
-
1 つ以上のリーダー DB インスタンスでリソースを使用しており、読み取りワークロード負荷が高い。低速または大規模なクエリを実行すると、適用プロセスに影響し、レプリカの遅延が発生する可能性があります。
-
大量のデータまたは DDL ステートメントを変更するトランザクション。データベースのコミットの順序を保持する必要があるため、レプリカの遅延が一時的に増加することがあります。
レプリカの遅延の軽減
RDS for MySQL および RDS for PostgreSQL のマルチ AZ DB クラスターでは、ライター DB インスタンスの負荷を軽減することで、レプリカの遅延を軽減できます。また、フロー制御を使用してレプリカの遅延を軽減できます。フロー制御は、ライター DB インスタンスに対する書き込みをスロットリングすることで機能します。これにより、レプリカの遅延が無制限に増加し続けることを防ぎます。書き込みスロットリングは、トランザクションの最後に遅延を追加することで実現されます。これにより、ライター DB インスタンスの書き込みスループットが低下します。フロー制御は遅延をなくすことを保証するものではありませんが、多くのワークロードで全体的な遅延を軽減するのに役立ちます。次のセクションでは、RDS for MySQL および RDS for PostgreSQL でのフロー制御の使用方法について説明します。
RDS for MySQL でのフロー制御によるレプリカの遅延の軽減
RDS for MySQL マルチ AZ DB クラスターを使用している場合、動的パラメータ rpl_semi_sync_master_target_apply_lag を使用することでデフォルトでフロー制御が有効になります。このパラメータは、レプリカの遅延における上限を指定します。レプリカの遅延が設定された上限に近づくと、フロー制御は指定された値より小さいレプリカの遅延を含むようにライター DB インスタンス上の書き込みトランザクションをスロットリングします。場合によっては、レプリカの遅延が指定された上限を超えることがあります。デフォルトでは、パラメータは 120 秒に設定されています。フロー制御を無効にするには、このパラメータを最大値の 86,400 秒 (1 日) に設定します。
フロー制御によって挿入される現在の遅延を表示するには、次のクエリを実行してパラメータ Rpl_semi_sync_master_flow_control_current_delay を表示します。
SHOW GLOBAL STATUS like '%flow_control%';
出力は以下のようになります。
+-------------------------------------------------+-------+
| Variable_name | Value |
+-------------------------------------------------+-------+
| Rpl_semi_sync_master_flow_control_current_delay | 2010 |
+-------------------------------------------------+-------+
1 row in set (0.00 sec)注記
遅延はマイクロ秒単位で示されます。
RDS for MySQL マルチ AZ DB クラスターの Performance Insights を有効にすると、クエリがフロー制御によって遅延したことを示す SQL ステートメントに対応する待機イベントをモニタリングできます。フロー制御により遅延が発生すると、Performance Insights ダッシュボードで SQL ステートメントに対応する待機イベント /wait/synch/cond/semisync/semi_sync_flow_control_delay_cond を表示できます。これらのメトリクスを表示するには、Performance Schema が有効になっていることを確認してください。Performance Insights の詳細については、「Amazon RDS での Performance Insights を使用したDB 負荷のモニタリング」を参照してください。
RDS for PostgreSQL でのフロー制御によるレプリカの遅延の軽減
RDS for PostgreSQL のマルチ AZ DB クラスターを使用している場合、フロー制御は拡張機能としてデプロイされています。これにより、DB クラスターのすべての DB インスタンスでバックグラウンドワーカーが開始します。デフォルトでは、リーダー DB インスタンスのバックグラウンドワーカーは、現在のレプリカの遅延をライター DB インスタンスのバックグラウンドワーカーに伝えます。いずれかのリーダー DB インスタンスで遅延が 2 分を超える場合、ライター DB インスタンスのバックグラウンドワーカーは、トランザクションの最後に遅延を追加します。遅延のしきい値を制御するには、パラメータ flow_control.target_standby_apply_lag を使用します。
フロー制御が PostgreSQL プロセスをスロットリングすると、pg_stat_activity および Performance Insights の Extension 待機イベントに表示されます。現在追加されている遅延の量に関する詳細が関数 get_flow_control_stats に表示されます。
フロー制御は、短いが負荷の高い同時トランザクションを持つほとんどのオンライントランザクション処理 (OLTP) のワークロードにメリットがあります。バッチ操作などの長時間実行されるトランザクションによって遅延が発生した場合、それほど大きなメリットはありません。
フロー制御を無効にするには、shared_preload_libraries から拡張機能を削除するか、DB インスタンスを再起動します。
マルチ AZ DB クラスターのスナップショット
Amazon RDS は、設定されたバックアップ期間中に、マルチ AZ DB クラスターの自動バックアップを作成して保存します。RDS は DB クラスターのストレージボリュームのスナップショットを作成し、個々のインスタンスだけではなく、クラスター全体をバックアップします。
マルチ AZ DB クラスターの手動バックアップを取ることもできます。非常に長期間のバックアップの場合、スナップショットデータを Amazon S3 にエクスポートすることを検討してください。詳細については、「Amazon RDS のマルチ AZ DB クラスターのスナップショットの作成」を参照してください。
マルチ AZ DB クラスターを指定の時点に復元し、新しいマルチ AZ DB クラスターを作成できます。手順については、マルチ AZ DB クラスターを指定の時点の状態に復元する を参照してください。
または、マルチ AZ DB クラスターのスナップショットをシングル AZ デプロイまたはマルチ AZ DB インスタンスデプロイに復元することができます。手順については、マルチ AZ DB クラスターのスナップショットから DB インスタンスへの復元 を参照してください。
