翻訳は機械翻訳により提供されています。提供された翻訳内容と英語版の間で齟齬、不一致または矛盾がある場合、英語版が優先します。
Data Wrangler の開始方法
Amazon SageMaker Data Wrangler は、Amazon SageMaker Studio Classic の機能です。このセクションでは、Data Wrangler にアクセスして使用を開始する方法について説明します。以下の操作を実行します。
-
前提条件の各ステップを完了します。
-
Data Wrangler にアクセスするの手順に従い、Data Wrangler の使用を開始します。
前提条件
Data Wrangler を使用するには、以下の前提条件を満たす必要があります。
-
Data Wrangler を使用するには、Amazon Elastic Compute Cloud (Amazon EC2) インスタンスにアクセスする必要があります。使用できる Amazon EC2 インスタンスの詳細については、「インスタンス」を参照してください。クォータを表示する方法と、必要に応じてクォータの引き上げをリクエストする方法については、「AWS サービスクォータ」を参照してください。
-
「セキュリティと権限」で説明しているように、必要なアクセス許可を設定します。
-
組織でインターネットトラフィックをブロックするファイアウォールを使用している場合は、次の URL へアクセスをすることが必要です。
-
https://ui.prod-1.data-wrangler.sagemaker.aws/ -
https://ui.prod-2.data-wrangler.sagemaker.aws/ -
https://ui.prod-3.data-wrangler.sagemaker.aws/ -
https://ui.prod-4.data-wrangler.sagemaker.aws/
-
Data Wrangler を使用するには、アクティブな Studio Classic インスタンスが必要です。新しいインスタンスを起動する方法については、「Amazon SageMaker AI ドメインの概要」を参照してください。Studio Classic インスタンスが準備完了の場合は、「Data Wrangler にアクセスする」の手順を使用します。
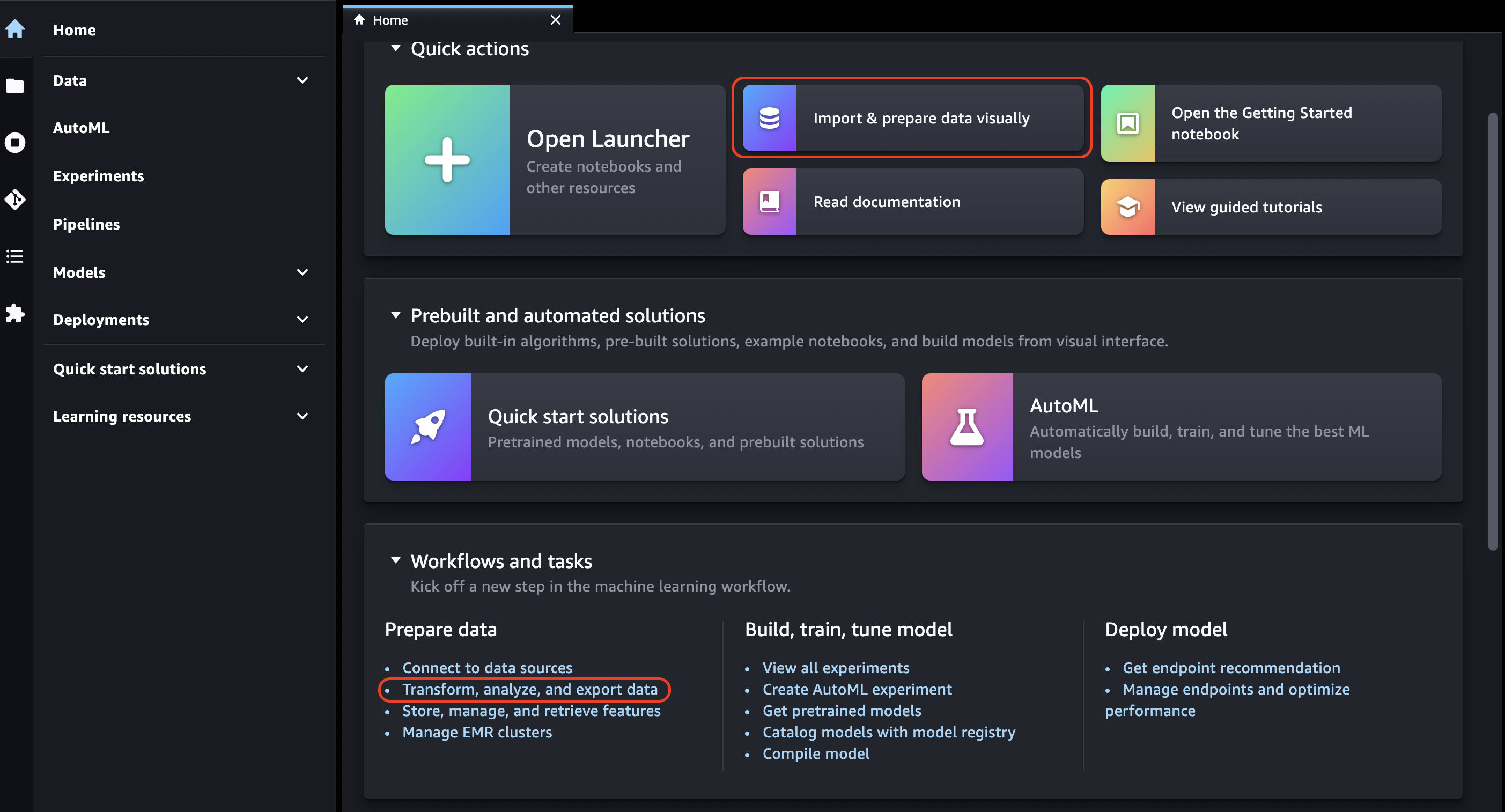
Data Wrangler にアクセスする
次の手順では、前提条件 をすでに完了していることを前提としています。
Studio Classic で Data Wrangler にアクセスするには、以下を実行します。
-
Studio Classic にサインインします。詳細については、「Amazon SageMaker AI ドメインの概要」を参照してください。
-
[Studio] を選択します。
-
[アプリの起動] を選択します。
-
ドロップダウンリストから [Studio] を選択します。
-
[Home] アイコンを選択します。
-
[データ] を選択します。
-
[Data Wrangler] を選択します。
-
次の方法で Data Wrangler フローを作成することもできます。
-
上部のナビゲーションバーで、[ファイル] を選択します。
-
[新規] を選択します。
-
[Data Wrangler Flow] を選択します。
-
-
(オプション) 新しいディレクトリと .flow ファイルの名前を変更します。
-
Studio Classic で新しい .flow ファイルを作成すると、Data Wrangler を紹介するカルーセルが表示される場合があります。
このプロセスには数分かかることがあります。
このメッセージは、KernelGateway アプリが [ユーザーの詳細] ページで [保留中] である間は保持されます。このアプリのステータスを確認するには、Amazon SageMaker Studio Classic ページの Amazon SageMakerコンソールで、Studio Classic へのアクセスに使用するユーザーの名前を選択します。[User Details] (ユーザー詳細) ページで、[Apps] (アプリ) の下に [KernelGateway] アプリが表示されます。このアプリのステータスが [Ready] (準備完了) になるまで待ってから、Data Wrangler の使用を開始します。Data Wrangler の初回起動時には約 5 分かかることがあります。
![[ユーザーの詳細] ページでKernelGateway アプリケーションのステータスが [準備完了] であることを示す例](images/studio/mohave/gatewayKernel-ready.png)
-
開始するには、データソースを選択し、それを使用してデータセットをインポートします。詳細については、「[Import](インポート)」を参照してください。
データセットをインポートすると、データフローに表示されます。詳細についてはData Wrangler フローを作成して使用するを参照してください。
-
データセットをインポートすると、Data Wrangler は各列のデータのタイプを自動的に推測します。[Data types] (データ型) ステップの横にある [+] を選択し、[Edit data types] (データ型を編集) を選択します。
重要
変換を [Data types] (データ型) ステップに追加した後には [Update types] (更新の種類) を使用して列タイプを一括更新することはできません。
-
データフローを使用して変換と分析を追加します。詳細については、「データを変換する」および「分析および視覚化」を参照してください。
-
完全なデータフローをエクスポートするには、[Export] (エクスポート) を選択し、エクスポートオプションを選択します。詳細についてはエクスポートを参照してください。
-
最後に、[コンポーネントとレジストリ] アイコンを選択し、ドロップダウンリストから [Data Wrangler] を選択して作成したすべての .flow ファイルを表示します。このメニューを使用してデータフローを検索し、移動できます。
Data Wrangler を起動したら、次のセクションで Data Wrangler を使った ML データ準備フローの作成方法について説明します。
Data Wrangler を更新する
Data Wrangler Studio Classic アプリケーションは定期的にアップデートして、最新の機能とアップデートを利用することをお勧めします。Data Wrangler アプリ名は、sagemaker-data-wrang で始まります。Studio Classic アプリケーションをアップデートする方法については、「Studio Classic アプリのシャットダウンと更新」を参照してください。
デモ: Data Wrangler Titanic データセットのチュートリアル
次のセクションでは、Data Wrangler の使用開始に役立つチュートリアルを示します。このチュートリアルでは、Data Wrangler にアクセスする の手順をすでに実行しており、デモで使用する新しいデータフローファイルが開かれていることを前提としています。この .flow ファイルの名前を titanic-demo.flow のような名前に変更することもできます。
このチュートリアルでは Titanic データセット
本チュートリアルでは、次のステップを実行します。
-
次のいずれかを行います:
-
Data Wrangler フローを開き、[サンプルデータセットの使用] を選択します。
-
Titanic データセット
を Amazon Simple Storage Service (Amazon S3) にアップロードし、このデータセットを Data Wrangler にインポートします。
-
-
Data Wrangler 分析を使用してこのデータセットを分析します。
-
Data Wrangler データ変換を使用してデータフローを定義します。
-
Data Wrangler ジョブの作成に使用できる Jupyter ノートブックにフローをエクスポートします。
-
データを処理し、SageMaker トレーニングジョブを開始して XgBoost 二項分類子をトレーニングします。
S3 にデータセットをアップロードしてインポートする
開始するには、以下の方法のいずれかを使用して Titanic データセットを Data Wrangler にインポートします。
-
Data Wrangler フローからデータセットを直接インポートする
-
データセットを Amazon S3 にアップロードし、Data Wrangler にインポートする
データセットを Data Wrangler に直接インポートするには、フローを開いて [サンプルデータセットの使用] を選択します。
データセットを Amazon S3 にアップロードして Data Wrangler にインポートする操作は、独自のデータをインポートする操作に似ています。データセットをアップロードしてインポートする方法は以下の通りです。
Data Wrangler へのデータのインポートを開始する前に、Titanic データセット
Amazon S3 の新しいユーザーの場合、Amazon S3 コンソールでドラッグアンドドロップを使用してこれを行うことができます。この方法の詳細については、Amazon Simple Storage Service ユーザーガイドの「ドラッグアンドドロップを使用したファイルとフォルダのアップロード」を参照してください。
重要
このデモを完了するために使用するリージョンと同じ AWS リージョンの S3 バケットにデータセットをアップロードします。
データセットが Amazon S3 に正常にアップロードされたら、そのデータセットを Data Wrangler にインポートできます。
Titanic データセットを Data Wrangler にインポートする
-
[データフロー] タブの [データをインポートする] ボタンを選択するか、[インポート] タブを選択します。
-
[Amazon S3] を選択します。
-
[Import a dataset from S3] (S3 からデータセットをインポート) テーブルで、Titanic データセットを追加したバケットを見つけます。Titanic データセットの CSV ファイルを選択して、[Details] (詳細) ペインを開きます。
-
[Details] (詳細) で、[File type] (ファイルタイプ) を CSV にする必要があります。[最初の行はヘッダー] をチェックし、データセットの最初の行がヘッダーであることを指定します。データセットには、
Titanic-trainのようなわかりやすい名前を付けることもできます。 -
[インポート] ボタンを選択します。
データセットが Data Wrangler にインポートされると、[データフロー] タブに表示されます。ノードをダブルクリックしてノード詳細ビューに入り、変換や分析を追加できます。[+] アイコンを使用してナビゲーションにすばやくアクセスできます。次のセクションでは、このデータフローを使用して分析と変換ステップを追加します。
データフロー
データフローセクションでは、データフローの唯一のステップが、最近インポートしたデータセットと [データタイプ] ステップのみです。変換を適用した後、このタブに戻ってデータフローがどのように表示されるのかを確認できます。次に、[Prepare] (準備) と [Analyze] (分析) タブでいくつかの基本的な変換を追加します。
準備して視覚化する
Data Wrangler には、データの分析、クリーニング、変換に使用できる変換と視覚化が組み込まれています。
ノード詳細ビューの [データ] タブでは、すべての組み込み変換が右側のパネルにリストされます。このパネルには、カスタム変換を追加できる領域も含まれています。次のユースケースに、これらの変換の使用方法を示します。
データ探索や特徴量エンジニアリングに役立つ情報を入手するには、データ品質とインサイトに関するレポートを作成してください。レポートからの情報は、データのクリーニングと処理に役立ちます。欠落した値の数、外れ値の数などの情報が得られます。ターゲット漏洩や不均衡などデータに問題がある場合、インサイトレポートによってそれらの問題に注意を払うことができます。レポート作成についての詳細は、「データとデータ品質に関するインサイトを取得する」を参照してください。
データ探索
まず、分析を使用してデータのテーブル概要を作成します。以下の操作を実行します。
-
データフローの [Data type] (データタイプ) ステップの横にある [+] を選択し、[Add analysis] (分析を追加) を選択します。
-
[Analysis] (分析) 領域で、ドロップダウンリストから [Table summary] (テーブル概要) を選択します。
-
テーブル概要に名前を付けます。
-
[Preview] (プレビュー) を選択して、作成するテーブルをプレビューします。
-
[保存] を選択して、データフローに保存します。これは、[All Analyses] (すべての分析) に表示されます。
表示される統計を使用して、このデータセットに関する次のような観測を行うことができます。
-
運賃平均 (平均) は 33 USD 前後で、最高額は 500 USD を超えています。この列には外れ値が含まれている可能性があります。
-
このデータセットは ? を使用して欠落した値を示します。[cabin] (キャビン)、[embarked] (乗船)、[home.dest] の列に欠落した値があります。
-
年齢カテゴリでは 250 以上の値が欠落しています。
次に、これらの統計から得られたインサイトを使用して、データをクリーンアップします。
未使用の列をドロップする
前のセクションの分析を使用してデータセットをクリーンアップし、トレーニングの準備をします。新しい変換をデータフローに追加するには、データフローの [Data type] (データタイプ) ステップの横にある [+] を選択し、[Add transform] (変換を追加) を選択します。
最初に、トレーニングに使用しない列をドロップします。これは、pandas
以下の手順に従って、未使用の列を削除します。
未使用の列を削除するには。
-
Data Wrangler フローを開きます。
-
Data Wrangler フローには 2 つのノードがあります。[データタイプ] ノードの右にある [+] を選択します。
-
[変換を追加] を選択します。
-
[すべてのステップ] 列で [ステップの追加] を選択します。
-
[標準] トランスフォームリストで、[列の管理] を選択します。標準変換は既製の組み込み変換です。[ドロップ列] が選択されていることを確認します。
-
[削除する列] で、次の列名を確認します。
-
cabin
-
ticket
-
名前
-
sibsp
-
parch
-
home.dest
-
boat
-
本文
-
-
[プレビュー] を選択します。
-
列がドロップされていることを確認してから、[追加] を選択します。
pandas を使用してこれを行うには、以下を実行します。
-
[すべてのステップ] 列で [ステップの追加] を選択します。
-
[カスタム] 変換リストで [カスタム変換] を選択します。
-
変換の名前を入力し、ドロップダウンリストから [Python (Pandas)] を選択します。
-
コードボックスに次の Python スクリプトを入力します。
cols = ['name', 'ticket', 'cabin', 'sibsp', 'parch', 'home.dest','boat', 'body'] df = df.drop(cols, axis=1) -
[プレビュー] を選択して変更をプレビューし、[追加] を選択して変換を追加します。
欠落した値をクリーンアップする
次に、欠落した値をクリーンアップします。これは、[Handling missing values] (欠落した値の処理) 変換グループで実行できます。
いくつかの列に欠落した値があります。残りの列のうち、[age] (年齢) と [fare] (運賃) に欠落した値が含まれています。これは [カスタム変換] を使用して確認します。
[Python (Pandas)] オプションで以下を使用して、各列のエントリ数をすばやく確認します。
df.info()

欠落した値のある行をドロップするには、[age] (年齢) カテゴリで次の操作を行います。
-
[欠落値を処理] を選択します。
-
[Transformer] (トランスフォーマー) に対して [Drop missing] (欠落をドロップ) を選択します。
-
[Input column] (入力列) に対して [age] (年齢) を選択します。
-
[Preview] (プレビュー) を選択して新しいデータフレームを表示し、[Add] (追加) を選択してトランスフォームをフローに追加します。
-
[fare] (運賃) に対して同じプロセスを繰り返します。
[Custom transform] (カスタム変換) セクションで df.info() を使用し、すべての行の値が 1,045 になっていることを確認できます。
カスタム Pandas: エンコード
Pandas を使用してフラットエンコーディングを試行します。カテゴリ別データのエンコーディングは、カテゴリの数値表現を作成するプロセスです。例えば、カテゴリが Dog と Cat の場合、Dog を表す [1,0] と Cat を表す [0,1] の 2 つのベクトルにこの情報をエンコードできます。
-
[Custom Transform] (カスタム変換) セクションで、ドロップダウンリストから [Python (Pandas)] を選択します。
-
コードボックスに次を入力します。
import pandas as pd dummies = [] cols = ['pclass','sex','embarked'] for col in cols: dummies.append(pd.get_dummies(df[col])) encoded = pd.concat(dummies, axis=1) df = pd.concat((df, encoded),axis=1) -
[Preview] (プレビュー) を選択して変更をプレビューします。各列のエンコーディングされたバージョンがデータセットに追加されます。
-
[Add] (追加) を選択して変換を追加します。
カスタム SQL: SELECT 列
次に、SQL を使用して維持する列を選択します。このデモでは、以下の SELECT ステートメントに表示される列を選択します。[survived] (生存) はトレーニングのターゲット列なので、その列を最初に配置します。
-
[Custom Transform] (カスタム変換) セクションで、ドロップダウンリストから [SQL (PySpark SQL)] を選択します。
-
コードボックスに次を入力します。
SELECT survived, age, fare, 1, 2, 3, female, male, C, Q, S FROM df; -
[Preview] (プレビュー) を選択して変更をプレビューします。
SELECTステートメントに表示される列は、残っている列のみです。 -
[Add] (追加) を選択して変換を追加します。
Data Wrangler ノートブックにエクスポートする
データフローの作成が完了すると、いくつかのエクスポートオプションを使用できます。次のセクションでは、Data Wrangler ジョブノートブックにエクスポートする方法について説明します。Data Wrangler ジョブは、データフローで定義されたステップを使用してデータを処理するために使用されます。すべてのエクスポートオプションの詳細については、「エクスポート」を参照してください。
Data Wrangler ジョブノートブックにエクスポートする
Data Wrangler ジョブを使用してデータフローをエクスポートすると、その処理によって Jupyter Notebook が自動的に作成されます。このノートブックは Studio Classic インスタンスで自動的に開き、SageMaker Processing ジョブを実行して Data Wrangler データフローを実行するように設定されます。これは Data Wrangler ジョブと呼ばれます。
-
データフローを保存します。[File] (ファイル) を選択して、[Save Data Wrangler Flow] (Data Wrangler フローを保存) を選択します。
-
[データフロー] タブに戻り、データフロー (SQL) の最後のステップを選択し、[+] を選択してナビゲーションを開きます。
-
[エクスポート]、[Amazon S3 (Jupyter Notebook 経由)] を選択します。これにより、Jupyter ノートブックが開きます。

-
[Kernel] (カーネル) に対していずれかの [Python 3 (Data Science)] (Python 3 (データサイエンス)) カーネルを選択します。
-
カーネルが起動したら、[Kick off SageMaker Training Job (Optional)] (SageMaker トレーニングジョブを開始 (オプション)) までノートブック内のセルを実行します。
-
必要に応じて、XGBoost 分類子をトレーニングする SageMaker AI トレーニングジョブを作成する場合は、Kick off SageMaker Training Job (オプション) でセルを実行できます。 SageMaker SageMaker トレーニングジョブを実行するコストは、「Amazon SageMaker の料金
」で確認できます。 または、XGBoost 分類子のトレーニングで見つかったコードブロックをノートブックに追加して、XGBoost 分類子をトレーニングする XGBoost
オープンソースライブラリを使用するように実行できます。 -
コメントを解除して、[Cleanup] (クリーンアップ) でセルを実行し、SageMaker Python SDK を元のバージョンに戻します。
Data Wrangler ジョブのステータスは、処理タブの SageMaker AI コンソールでモニタリングできます。また、Amazon CloudWatch を使用して Data Wrangler のジョブをモニタリングすることもできます。詳細については、「Monitor Amazon SageMaker Processing Jobs with CloudWatch Logs and Metrics」(CloudWatch Logs とメトリクスで Amazon SageMaker の処理ジョブをモニタリングする) を参照してください。
トレーニングジョブを開始した場合は、トレーニングセクションのトレーニングジョブの下にある SageMaker AI コンソールを使用して、そのステータスをモニタリングできます。
XGBoost 分類子のトレーニング
XGBoost 二項分類器は、Jupyter Notebook または Amazon SageMaker Autopilot のいずれかを使用してトレーニングできます。Autopilot を使用すると、Data Wrangler フローから直接変換したデータに基づいてモデルを自動的にトレーニングおよび調整できます。Autopilot の詳細については、「データフローでモデルを自動的にトレーニングする」を参照してください。
Data Wrangler ジョブを開始したのと同じノートブックで、データをプルし、最小限のデータ準備で準備されたデータを使用して XGBoost 二項分類器をトレーニングできます。
-
まず、
pipを使用して必要なモジュールをアップグレードし、_SUCCESS ファイルを削除します (この最後のファイルはawswranglerの使用時に問題が発生します)。! pip install --upgrade awscli awswrangler boto sklearn ! aws s3 rm {output_path} --recursive --exclude "*" --include "*_SUCCESS*" -
Amazon S3 からデータを読み取ります。
awswranglerを使用して S3 プレフィックス内のすべての CSV ファイルを再帰的に読み取ることができます。その後、データは特徴とラベルに分割されます。ラベルはデータフレームの最初の列です。import awswrangler as wr df = wr.s3.read_csv(path=output_path, dataset=True) X, y = df.iloc[:,:-1],df.iloc[:,-1]-
最後に、DMatrices (データの XGBoost プリミティブ構造) を作成し、XGBoost 二項分類を使用して交差検証を実行します。
import xgboost as xgb dmatrix = xgb.DMatrix(data=X, label=y) params = {"objective":"binary:logistic",'learning_rate': 0.1, 'max_depth': 5, 'alpha': 10} xgb.cv( dtrain=dmatrix, params=params, nfold=3, num_boost_round=50, early_stopping_rounds=10, metrics="rmse", as_pandas=True, seed=123)
-
Data Wrangler をシャットダウンする
Data Wrangler の使用が終了したら、追加料金が発生しないように、実行中のインスタンスをシャットダウンすることをお勧めします。Data Wrangler アプリと関連するインスタンスをシャットダウンする方法については、「Data Wrangler をシャットダウンする」を参照してください。
