Aurora MySQL과 함께 Amazon Aurora 기계 학습 사용
Amazon Aurora 기계 학습을 Aurora MySQL DB 클러스터와 함께 사용하면 필요에 따라 Amazon Bedrock, Amazon Comprehend 또는 Amazon SageMaker AI를 사용할 수 있습니다. 서비스마다 다른 기계 학습 사용 사례를 지원합니다.
Aurora MySQL과 함께 Aurora 기계 학습을 사용할 때 요구 사항
AWS 기계 학습 서비스는 자체 프로덕션 환경에서 설정되고 실행되는 관리형 서비스입니다. Aurora 기계 학습은 Amazon Bedrock, Amazon Comprehend, SageMaker AI와의 통합을 지원합니다. Aurora 기계 학습을 사용하도록 Aurora MySQL DB 클러스터를 설정하기 전에 다음 요구 사항 및 사전 조건을 이해해야 합니다.
-
기계 학습 서비스가 Aurora MySQL DB 클러스터와 동일한 AWS 리전에서 실행되어야 합니다. 다른 리전의 Aurora MySQL DB 클러스터에서는 기계 학습 서비스를 사용할 수 없습니다.
-
Aurora MySQL DB 클러스터가 Amazon Bedrock, Amazon Comprehend 및 SageMaker AI 서비스와 다른 Virtual Public Cloud(VPC)에 있는 경우 VPC의 보안 그룹은 대상 Aurora 기계 학습 서비스에 대한 아웃바운드 연결을 허용해야 합니다. 자세한 내용은 Amazon VPC 사용 설명서의 보안 그룹을 사용하여 AWS 리소스에 대한 트래픽 제어를 참조하세요.
-
해당 클러스터와 Aurora Machine Learning을 함께 사용하려는 경우 이전 버전의 Aurora MySQL을 실행하는 Aurora 클러스터를 지원되는 상위 버전으로 업그레이드할 수 있습니다. 자세한 내용은 Amazon Aurora MySQL에 대한 데이터베이스 엔진 업데이트 단원을 참조하십시오.
-
Aurora MySQL DB 클러스터에서 사용자 지정 DB 클러스터 파라미터 그룹을 사용해야 합니다. 사용하려는 각 Aurora 기계 학습 서비스의 설정 프로세스가 끝날 때 해당 서비스에 대해 생성된 관련 IAM 역할의 Amazon 리소스 이름(ARN)을 추가합니다. Aurora MySQL용 사용자 지정 DB 클러스터 파라미터 그룹을 미리 생성하고 이를 사용하도록 Aurora MySQL DB 클러스터를 구성하여 설정 프로세스 종료 시 바로 수정할 수 있도록 하는 것이 좋습니다.
-
SageMaker AI의 경우:
-
추론에 사용할 기계 학습 구성 요소를 설정하고 사용할 준비가 되어 있어야 합니다. Aurora MySQL DB 클러스터에 대한 구성 프로세스에서 SageMaker AI 엔드포인트의 ARN을 사용할 수 있어야 합니다. 팀의 데이터 과학자는 SageMaker AI와 협력하여 모델을 준비하고 그 외의 작업을 처리하는 데 가장 잘 대처할 수 있을 것입니다. Amazon SageMaker AI를 시작하려면 Get Started with Amazon SageMaker AI를 참조하세요. 추론 및 엔드포인트에 대한 자세한 내용은 Real-time inference(실시간 추론)를 참조하세요.
-
SageMaker AI를 자체 훈련 데이터와 함께 사용하려면 Aurora 기계 학습에 대한 Aurora MySQL 구성의 일부로 Amazon S3 버킷을 설정해야 합니다. 이렇게 하려면 SageMaker AI 통합을 설정하는 것과 동일한 일반 프로세스를 따라야 합니다. 이 선택적 설정 프로세스를 요약한 내용은 Amazon S3 for SageMaker AI를 사용하도록 Aurora MySQL DB 클러스터 설정(선택 사항) 섹션을 참조하세요.
-
-
Aurora Global Database의 경우 Aurora Global Database를 구성하는 모든 AWS 리전에서 사용할 Aurora 기계 학습 서비스를 설정합니다. 예를 들어 Aurora 글로벌 데이터베이스에 SageMaker AI와 함께 Aurora 기계 학습을 사용하려면 모든 AWS 리전에 대해 다음 작업을 수행하세요.
-
동일한 SageMaker AI 훈련 모델 및 엔드포인트로 Amazon SageMaker AI 서비스를 설정합니다. 이름도 동일해야 합니다.
-
Aurora 기계 학습을 사용하도록 Aurora MySQL DB 클러스터 설정에 설명된 대로 IAM 역할을 생성합니다.
-
모든 AWS 리전에서 각 Aurora MySQL DB 클러스터의 사용자 지정 DB 클러스터 파라미터 그룹에 IAM 역할의 ARN을 추가합니다.
이러한 작업을 수행하려면 Aurora Global Database를 구성하는 모든 AWS 리전의 Aurora MySQL 버전에서 Aurora 기계 학습을 사용할 수 있어야 합니다.
-
리전 및 버전 사용 가능 여부
기능 가용성 및 해당 지원은 각 Aurora 데이터베이스 엔진의 특정 버전 및 AWS 리전에 따라 다릅니다.
-
Aurora MySQL과 함께 사용하는 Amazon Comprehend 및 Amazon SageMaker AI의 버전 및 리전 가용성에 대한 자세한 정보는 Aurora MySQL을 사용하는 Aurora 기계 학습 섹션을 참조하세요.
-
Amazon Bedrock은 Aurora MySQL 버전 3.06 이상에서만 지원됩니다.
Amazon Bedrock의 리전 가용성에 대한 자세한 내용은 Amazon Bedrock 사용 설명서에서 AWS 리전에서 지원하는 모델을 참조하세요.
Aurora MySQL을 사용하는 Aurora 기계 학습의 지원 기능 및 제한 사항
Aurora 기계 학습과 함께 Aurora MySQL 사용하는 경우 다음과 같은 제한 사항이 적용됩니다.
-
Aurora 기계 학습 확장은 벡터 인터페이스를 지원하지 않습니다.
-
Aurora 기계 학습 통합은 트리거에 사용될 경우 지원되지 않습니다.
Aurora 기계 학습 함수는 바이너리 로깅(binlog) 복제와 호환되지 않습니다.
-
--binlog-format=STATEMENT설정은 Aurora Machine Learning 함수 호출에 대해 예외를 발생시킵니다. -
Aurora 기계 학습 함수는 비결정적이며 비결정적 저장 함수는 binlog 형식과 호환되지 않습니다.
자세한 내용은 MySQL 설명서의 Binary Logging Formats
를 참조하세요. -
-
generated-always 열이 있는 테이블을 호출하는 저장 함수는 지원되지 않습니다. 이는 모든 Aurora MySQL 저장 함수에 적용됩니다. 이 열 유형에 대해 자세히 알아보려면 MySQL 설명서에서 CREATE TABLE and Generated Columns
(CREATE TABLE 및 생성된 열)를 참조하세요. -
Amazon Bedrock 함수는
RETURNS JSON을 지원하지 않습니다. 필요한 경우CONVERT또는CAST를 사용하여TEXT에서JSON으로 변환할 수 있습니다. -
Amazon Bedrock은 배치 요청을 지원하지 않습니다.
-
Aurora MySQL은
text/csv의ContentType을 통해 쉼표로 구분된 값(CSV) 형식을 읽고 쓸 수 있는 모든 SageMaker AI 엔드포인트를 지원합니다. 이 형식은 다음과 같은 내장 SageMaker AI 알고리즘에서 사용할 수 있습니다.-
Linear Learner
-
랜덤 컷 포레스트
-
XGBoost
이러한 알고리즘에 대해 자세히 알아보려면 Amazon SageMaker AI Developer Guide의 Choose an Algorithm을 참조하세요.
-
Aurora 기계 학습을 사용하도록 Aurora MySQL DB 클러스터 설정
다음 주제에서는 이러한 Aurora 기계 학습 서비스 각각에 대한 별도의 설정 절차를 찾을 수 있습니다.
주제
Amazon Bedrock을 사용하도록 Aurora MySQL DB 클러스터 설정
Aurora 기계 학습은 AWS Identity and Access Management(IAM) 역할과 정책을 기반으로 Aurora MySQL DB 클러스터가 Amazon Bedrock 서비스에 액세스하고 사용할 수 있도록 합니다. 다음 절차는 DB 클러스터를 Amazon Bedrock과 통합할 수 있도록 IAM 권한 정책 및 역할을 생성합니다.
IAM 정책을 생성하려면
AWS Management Console에 로그인하여 https://console.aws.amazon.com/iam/
에서 IAM 콘솔을 엽니다. -
탐색 창에서 정책을 선택합니다.
-
정책 생성을 선택합니다.
-
권한 지정 페이지의 서비스 선택에서 Bedrock을 선택합니다.
Amazon Bedrock 권한이 표시됩니다.
-
읽기를 확장한 다음 InvokeModel을 선택합니다.
-
리소스에서 모두를 선택합니다.
권한 지정 페이지는 다음 그림과 비슷합니다.
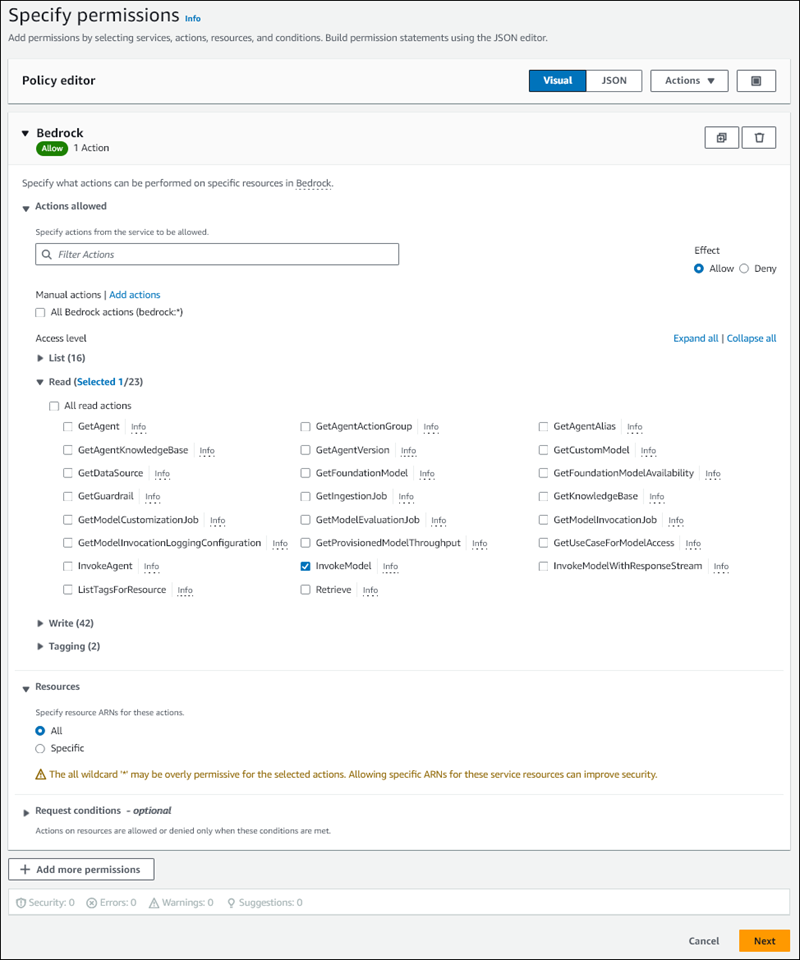
-
Next(다음)를 선택합니다.
-
검토 및 생성 페이지에
BedrockInvokeModel과 같이 정책 이름을 입력합니다. -
정책을 검토한 후 정책 생성을 선택합니다.
다음으로 Amazon Bedrock 권한 정책을 사용하는 IAM 역할을 생성합니다.
IAM 역할을 만들려면
AWS Management Console에 로그인하여 https://console.aws.amazon.com/iam/
에서 IAM 콘솔을 엽니다. -
탐색 창에서 역할을 선택합니다.
-
역할 생성을 선택합니다.
-
신뢰할 수 있는 엔터티 선택 페이지의 사용 사례에서 RDS를 선택합니다.
-
RDS - 데이터베이스에 역할 추가를 선택한 후 다음을 선택합니다.
-
권한 추가 페이지의 권한 정책에서 생성한 IAM 정책을 선택한 후 다음을 선택합니다.
-
이름, 검토 및 생성 페이지에
ams-bedrock-invoke-model-role과 같이 역할 이름을 입력합니다.역할은 다음 그림과 비슷합니다.
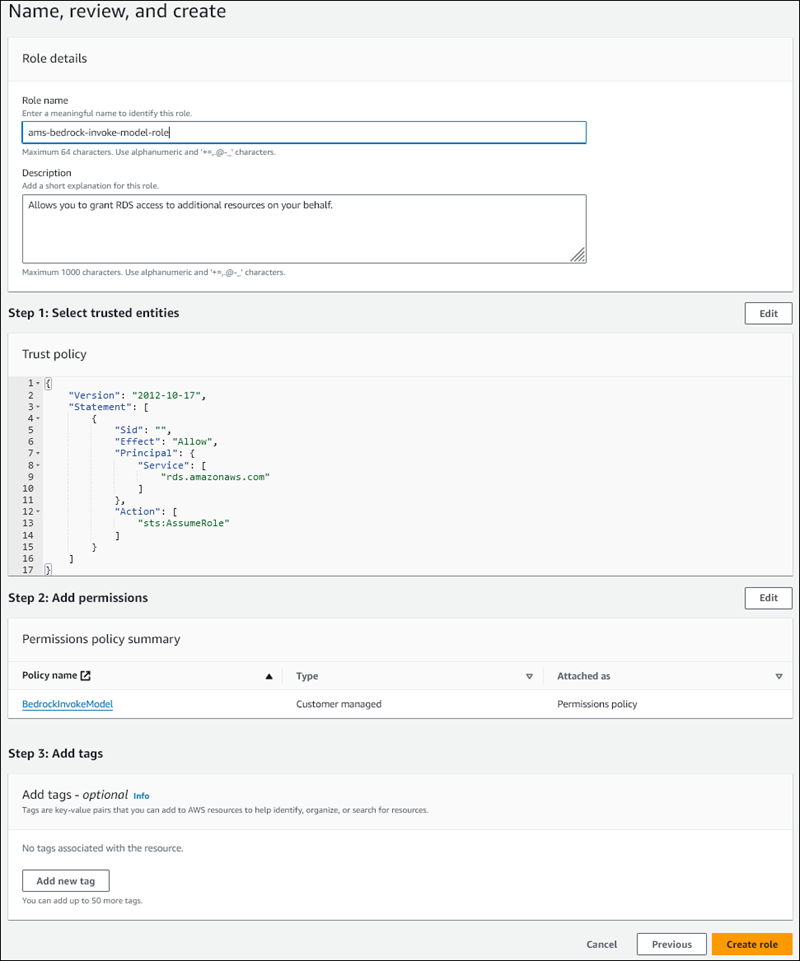
-
역할을 검토한 후 역할 생성을 선택합니다.
다음으로 Amazon Bedrock IAM 역할을 DB 클러스터와 연결합니다.
IAM 역할을 DB 클러스터에 연결하는 방법
https://console.aws.amazon.com/rds/
에서 AWS Management Console에 로그인한 후 Amazon RDS 콘솔을 엽니다. -
탐색 창에서 데이터베이스를 선택합니다.
-
Amazon Bedrock 서비스에 연결할 Aurora MySQL DB 클러스터를 선택합니다.
-
연결 및 보안(Connectivity & security) 탭을 선택합니다.
-
IAM 역할 관리 섹션에서 이 클러스터에 추가할 IAM 선택을 선택합니다.
-
생성한 IAM을 선택한 다음 역할 추가를 선택합니다.
IAM 역할이 DB 클러스터와 연결되며, 처음에는 보류 중 상태였다가 활성 상태가 됩니다. 프로세스가 완료되면 이 클러스터의 현재 IAM 역할 목록에서 역할을 찾을 수 있습니다.
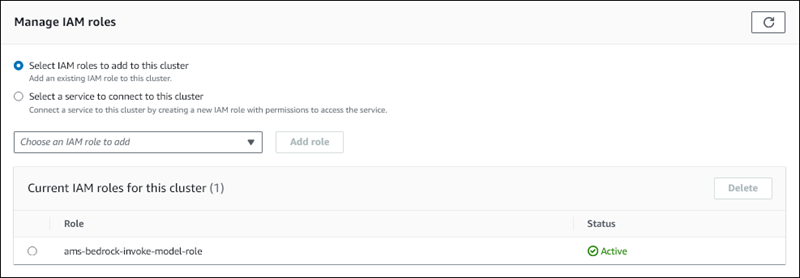
Aurora MySQL DB 클러스터와 연결된 사용자 지정 DB 클러스터 파라미터 그룹의 aws_default_bedrock_role 파라미터에 이 IAM 역할의 ARN을 추가해야 합니다. Aurora MySQL DB 클러스터에서 사용자 지정 DB 클러스터 파라미터 그룹을 사용하지 않는 경우 Aurora MySQL DB 클러스터와 함께 사용할 그룹을 만들어 통합을 완료해야 합니다. 자세한 내용은 Amazon Aurora DB 클러스터의 DB 클러스터 파라미터 그룹 단원을 참조하십시오.
DB 클러스터 파라미터를 구성하는 방법
-
Amazon RDS 콘솔에서 Aurora MySQL DB 클러스터의 구성 탭을 엽니다.
-
클러스터에 대해 구성한 DB 클러스터 파라미터 그룹을 찾습니다. 링크를 선택하여 사용자 지정 DB 클러스터 파라미터 그룹을 연 다음 편집을 선택합니다.
-
사용자 지정 DB 클러스터 파라미터 그룹에서
aws_default_bedrock_role파라미터를 찾습니다. -
값 필드에 IAM 역할의 ARN을 입력합니다.
-
변경 사항 저장을 선택하여 설정을 저장합니다.
-
이 파라미터 설정이 적용되도록 Aurora MySQL DB 클러스터의 기본 인스턴스를 재부팅합니다.
Amazon Bedrock에 대한 IAM 통합이 완료되었습니다. 데이터베이스 사용자에게 Aurora 기계 학습에 대한 액세스 권한 부여를 통해 Aurora MySQL DB 클러스터를 Amazon Bedrock와 함께 사용할 수 있도록 계속해서 설정하세요.
Amazon Comprehend를 사용하도록 Aurora MySQL DB 클러스터 설정
Aurora 기계 학습은 AWS Identity and Access Management 역할과 정책을 기반으로 Aurora MySQL DB 클러스터가 Amazon Comprehend 서비스에 액세스하고 사용할 수 있도록 합니다. 다음 절차는 Amazon Comprehend를 사용할 수 있도록 클러스터의 IAM 역할 및 정책을 자동으로 생성합니다.
Amazon Comprehend를 사용하도록 Aurora MySQL DB 클러스터를 설정하는 방법
https://console.aws.amazon.com/rds/
에서 AWS Management Console에 로그인한 후 Amazon RDS 콘솔을 엽니다. -
탐색 창에서 데이터베이스를 선택합니다.
-
Amazon Comprehend 서비스에 연결할 Aurora MySQL DB 클러스터를 선택합니다.
-
연결 및 보안(Connectivity & security) 탭을 선택합니다.
-
IAM 역할 관리 섹션에서 이 클러스터에 연결할 서비스 선택을 선택합니다.
-
메뉴에서 Amazon Comprehend를 선택한 다음 서비스 연결을 선택합니다.
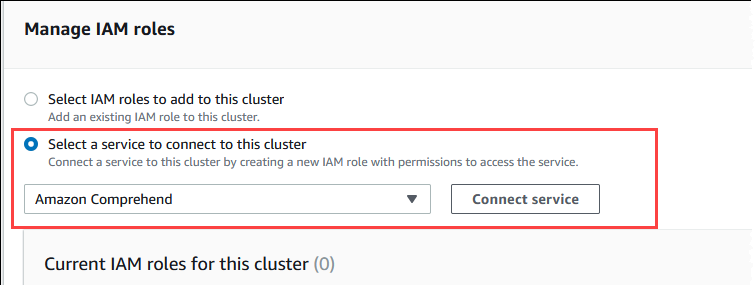
클러스터를 Amazon Comprehend에 연결 대화 상자에는 추가 정보가 필요하지 않습니다. 하지만 Aurora와 Amazon Comprehend 간의 통합이 현재 미리 보기 중임을 알리는 메시지가 표시될 수 있습니다. 계속하기 전에 메시지를 반드시 읽어보세요. 계속 진행하지 않으려면 취소를 선택하면 됩니다.
서비스 연결을 선택하여 통합 프로세스를 완료합니다.
Aurora가 IAM 역할을 생성합니다. 또한 Aurora MySQL DB 클러스터가 Amazon Comprehend 서비스를 사용하도록 허용하는 정책을 생성하고 해당 역할에 정책을 연결합니다. 프로세스가 완료되면 다음 이미지와 같이 이 클러스터의 현재 IAM 역할 목록에서 역할을 찾을 수 있습니다.
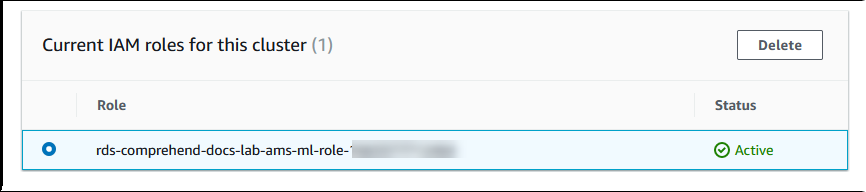
Aurora MySQL DB 클러스터와 연결된 사용자 지정 DB 클러스터 파라미터 그룹의
aws_default_comprehend_role파라미터에 이 IAM 역할의 ARN을 추가해야 합니다. Aurora MySQL DB 클러스터에서 사용자 지정 DB 클러스터 파라미터 그룹을 사용하지 않는 경우 Aurora MySQL DB 클러스터와 함께 사용할 그룹을 만들어 통합을 완료해야 합니다. 자세한 내용은 Amazon Aurora DB 클러스터의 DB 클러스터 파라미터 그룹 단원을 참조하십시오.사용자 지정 DB 클러스터 파라미터 그룹을 만들어 Aurora MySQL DB 클러스터와 연결한 후에 다음 단계를 계속 수행할 수 있습니다.
클러스터에서 사용자 지정 DB 클러스터 파라미터 그룹을 사용하는 경우 다음 작업을 수행하세요.
Amazon RDS 콘솔에서 Aurora MySQL DB 클러스터의 구성 탭을 엽니다.
-
클러스터에 대해 구성한 DB 클러스터 파라미터 그룹을 찾습니다. 링크를 선택하여 사용자 지정 DB 클러스터 파라미터 그룹을 연 다음 편집을 선택합니다.
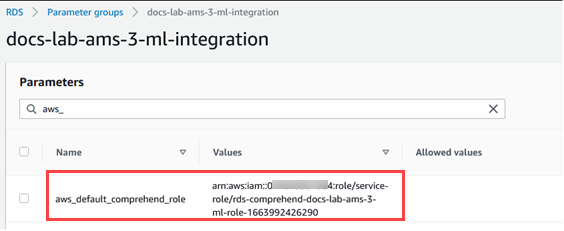
사용자 지정 DB 클러스터 파라미터 그룹에서
aws_default_comprehend_role파라미터를 찾습니다.값 필드에 IAM 역할의 ARN을 입력합니다.
변경 사항 저장을 선택하여 설정을 저장합니다. 다음 이미지에서 예시를 볼 수 있습니다.
이 파라미터 설정이 적용되도록 Aurora MySQL DB 클러스터의 기본 인스턴스를 재부팅합니다.
Amazon Comprehend IAM 통합이 완료되었습니다. 적절한 데이터베이스 사용자에게 액세스 권한을 부여하여 Amazon Comprehend와 함께 작동하도록 Aurora MySQL DB 클러스터 설정을 계속하세요.
SageMaker AI를 사용하도록 Aurora MySQL DB 클러스터 설정
다음 프로시저는 SageMaker AI를 사용할 수 있도록 Aurora MySQL DB 클러스터의 IAM 역할 및 정책을 자동으로 만듭니다. 이 프로시저를 따르기 전에 필요할 때 입력할 수 있도록 SageMaker AI 엔드포인트를 준비하세요. 일반적으로 팀의 데이터 과학자가 Aurora MySQL DB 클러스터에서 사용할 수 있는 엔드포인트를 만드는 작업을 수행합니다. SageMaker AI 콘솔
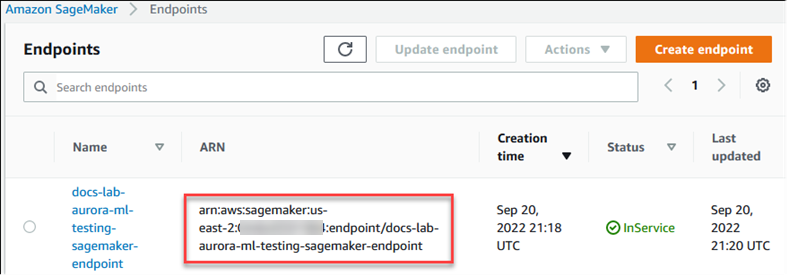
SageMaker AI를 사용하도록 Aurora MySQL DB 클러스터를 설정하는 방법
https://console.aws.amazon.com/rds/
에서 AWS Management Console에 로그인한 후 Amazon RDS 콘솔을 엽니다. -
Amazon RDS 탐색 메뉴에서 데이터베이스를 선택한 다음 SageMaker AI 서비스에 연결하려는 Aurora MySQL DB 클러스터를 선택합니다.
-
연결 및 보안(Connectivity & security) 탭을 선택합니다.
-
IAM 역할 관리 섹션으로 스크롤한 후 이 클러스터에 연결할 서비스 선택을 선택합니다. 선택기에서 SageMaker AI를 선택합니다.
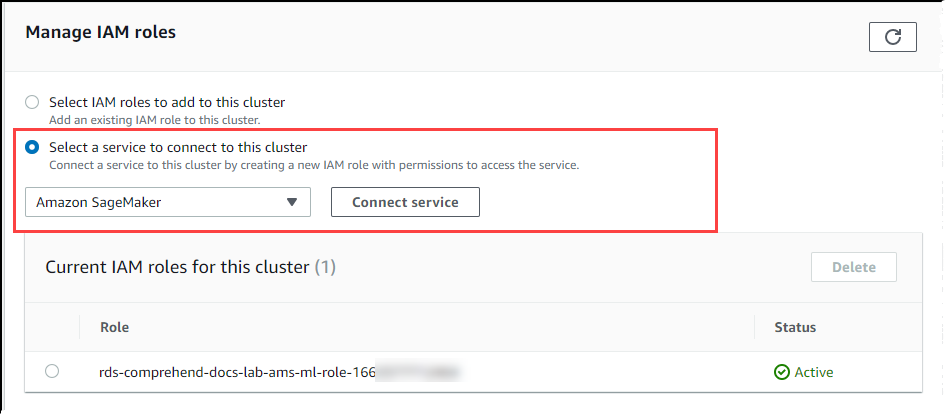
Connect service(서비스 연결)를 선택합니다.
SageMaker AI에 클러스터 연결 대화 상자에서 SageMaker AI 엔드포인트의 ARN을 입력합니다.
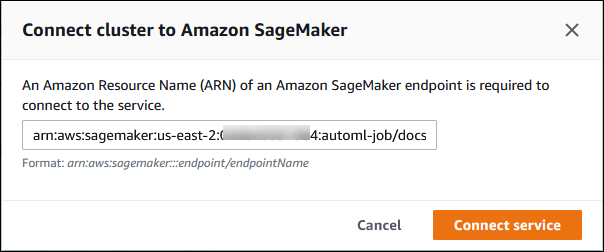
-
Aurora가 IAM 역할을 생성합니다. 또한 Aurora MySQL DB 클러스터가 SageMaker AI 서비스를 사용하도록 허용하는 정책을 만들고 해당 역할에 정책을 연결합니다. 프로세스가 완료되면 이 클러스터의 현재 IAM 역할 목록에서 역할을 찾을 수 있습니다.
https://console.aws.amazon.com/iam/
에서 IAM 콘솔을 엽니다. AWS Identity and Access Management 탐색 메뉴의 액세스 관리 섹션에서 역할을 선택합니다.
나열된 역할 중에서 역할을 찾습니다. 이름은 다음 패턴을 사용합니다.
rds-sagemaker-your-cluster-name-role-auto-generated-digits역할의 요약 페이지를 열고 ARN을 찾습니다. ARN을 기록하거나 복사 위젯을 사용하여 복사합니다.
https://console.aws.amazon.com/rds/
에서 Amazon RDS 콘솔을 엽니다. Aurora MySQL DB 클러스터를 선택한 다음 구성 탭을 선택합니다.
DB 클러스터 파라미터 그룹을 찾아 링크를 선택하여 사용자 지정 DB 클러스터 파라미터 그룹을 엽니다.
aws_default_sagemaker_role파라미터를 찾아 값 필드에 IAM 역할의 ARN을 입력하고 설정을 저장합니다.이 파라미터 설정이 적용되도록 Aurora MySQL DB 클러스터의 기본 인스턴스를 재부팅합니다.
이제 IAM 설정이 완료되었습니다. 적절한 데이터베이스 사용자에게 액세스 권한을 부여하여 SageMaker AI와 함께 작동하도록 Aurora MySQL DB 클러스터 설정을 계속하세요.
사전 구축된 SageMaker AI 구성 요소를 사용하는 대신 훈련에 SageMaker AI 모델을 사용하려면 아래 Amazon S3 for SageMaker AI를 사용하도록 Aurora MySQL DB 클러스터 설정(선택 사항)에 설명된 것과 같이 Amazon S3 버킷을 Aurora MySQL DB 클러스터에 추가해야 합니다.
Amazon S3 for SageMaker AI를 사용하도록 Aurora MySQL DB 클러스터 설정(선택 사항)
SageMaker AI에서 제공하는 사전 구축된 구성 요소를 사용하는 대신 자체 모델과 함께 SageMaker AI를 사용하려면 Aurora MySQL DB 클러스터에서 사용할 Amazon S3 버킷을 설정해야 합니다. Amazon S3 버킷 생성에 대한 자세한 내용은 Amazon Simple Storage Service 사용 설명서의 버킷 생성을 참조하세요.
SageMaker AI용 Amazon S3 버킷을 사용하도록 Aurora MySQL DB 클러스터를 설정하는 방법
https://console.aws.amazon.com/rds/
에서 AWS Management Console에 로그인한 후 Amazon RDS 콘솔을 엽니다. -
Amazon RDS 탐색 메뉴에서 데이터베이스를 선택한 다음 SageMaker AI 서비스에 연결하려는 Aurora MySQL DB 클러스터를 선택합니다.
-
연결 및 보안(Connectivity & security) 탭을 선택합니다.
-
IAM 역할 관리 섹션으로 스크롤한 후 이 클러스터에 연결할 서비스 선택을 선택합니다. 선택기에서 Amazon S3를 선택합니다.
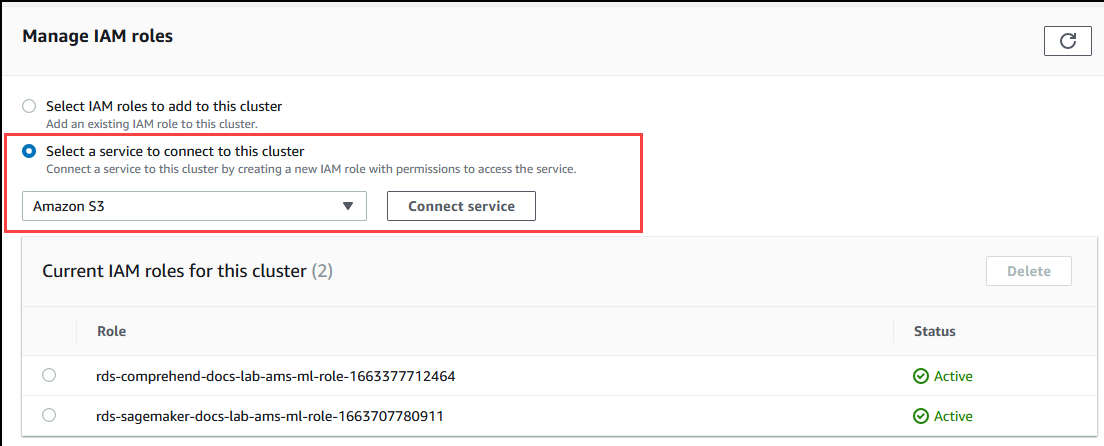
Connect service(서비스 연결)를 선택합니다.
Amazon S3에 클러스터 연결 대화 상자에서 다음 이미지와 같이 Amazon S3 버킷의 ARN을 입력합니다.
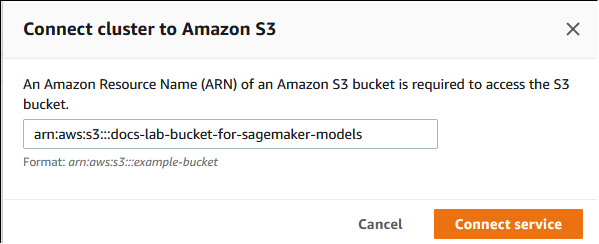
서비스 연결을 선택하여 이 프로세스를 완료합니다.
SageMaker AI와 함께 Amazon S3 버킷을 사용하는 방법에 대한 자세한 내용은 Amazon SageMaker AI Developer Guide의 Specify an Amazon S3 Bucket to Upload Training Datasets and Store Output Data를 참조하세요. SageMaker AI를 사용하는 방법에 대해 자세히 알아보려면 Amazon SageMaker AI Developer Guide의 Get Started with Amazon SageMaker AI Notebook Instances를 참조하세요.
데이터베이스 사용자에게 Aurora 기계 학습에 대한 액세스 권한 부여
데이터베이스 사용자에게 Aurora 기계 학습 함수를 간접 호출할 수 있는 권한을 부여해야 합니다. 권한 부여 방법은 아래에 설명된 대로 Aurora MySQL DB 클러스터에 사용하는 MySQL 버전에 따라 다릅니다. 이 작업을 수행하는 방법은 Aurora MySQL DB 클러스터에서 사용하는 MySQL 버전에 따라 달라집니다.
Aurora MySQL 버전 3(MySQL 8.0 호환)의 경우 데이터베이스 사용자에게 적절한 데이터베이스 역할을 부여해야 합니다. 자세한 내용은 MySQL 8.0 Reference Manual의 Using Roles
를 참조하세요. Aurora MySQL 버전 2(MySQL 5.7 호환)의 경우 데이터베이스 사용자에게 권한을 부여합니다. 자세한 내용은 MySQL 5.7 참조 매뉴얼의 Access Control and Account Management
를 참조하세요.
다음 테이블에는 데이터베이스 사용자가 기계 학습 기능을 사용하는 데 필요한 역할과 권한이 나와 있습니다.
| Aurora MySQL 버전 3(역할) | Aurora MySQL 버전 2(권한) |
|---|---|
|
AWS_BEDROCK_ACCESS |
– |
|
AWS_COMPREHEND_ACCESS |
INVOKE COMPREHEND |
|
AWS_SAGEMAKER_ACCESS |
INVOKE SAGEMAKER |
Amazon Bedrock 함수에 대한 액세스 권한 부여
데이터베이스 사용자에게 Amazon Bedrock 함수에 대한 액세스 권한을 부여하려면 다음 SQL 문을 사용하세요.
GRANT AWS_BEDROCK_ACCESS TOuser@domain-or-ip-address;
Amazon Bedrock을 사용하기 위해 생성하는 함수에 대한 EXECUTE 권한도 데이터베이스 사용자에게 부여해야 합니다.
GRANT EXECUTE ON FUNCTIONdatabase_name.function_nameTOuser@domain-or-ip-address;
마지막으로 데이터베이스 사용자의 역할은 다음과 같이 AWS_BEDROCK_ACCESS로 설정해야 합니다.
SET ROLE AWS_BEDROCK_ACCESS;
이제 Amazon Bedrock 함수를 사용할 수 있습니다.
Amazon Comprehend 함수에 대한 액세스 권한 부여
데이터베이스 사용자에게 Amazon Comprehend 함수에 대한 액세스 권한을 부여하려면 사용 중인 Aurora MySQL 버전에 해당하는 문을 사용하세요.
Aurora MySQL 버전 3(MySQL 8.0 호환)
GRANT AWS_COMPREHEND_ACCESS TOuser@domain-or-ip-address;Aurora MySQL 버전 2(MySQL 5.7 호환)
GRANT INVOKE COMPREHEND ON *.* TOuser@domain-or-ip-address;
이제 Amazon Comprehend 함수를 사용할 수 있습니다. 사용 예시는 Aurora MySQL DB 클러스터와 함께 Amazon Comprehend 사용 섹션을 참조하세요.
SageMaker AI 함수에 대한 액세스 권한 부여
데이터베이스 사용자에게 SageMaker AI 함수에 대한 액세스 권한을 부여하려면 사용 중인 Aurora MySQL 버전에 해당하는 문을 사용하세요.
Aurora MySQL 버전 3(MySQL 8.0 호환)
GRANT AWS_SAGEMAKER_ACCESS TOuser@domain-or-ip-address;Aurora MySQL 버전 2(MySQL 5.7 호환)
GRANT INVOKE SAGEMAKER ON *.* TOuser@domain-or-ip-address;
SageMaker AI로 작업하기 위해 만드는 함수에 대한 EXECUTE 권한도 데이터베이스 사용자에게 부여해야 합니다. SageMaker AI 엔드포인트의 서비스를 간접 호출하기 위해 db1.anomoly_score 및 db2.company_forecasts 함수를 만들었다고 가정해 보겠습니다. 다음 예시에서처럼 실행 권한을 부여합니다.
GRANT EXECUTE ON FUNCTION db1.anomaly_score TOuser1@domain-or-ip-address1; GRANT EXECUTE ON FUNCTION db2.company_forecasts TOuser2@domain-or-ip-address2;
이제 SageMaker AI 함수를 사용할 수 있습니다. 사용 예시는 Aurora MySQL DB 클러스터와 함께 SageMaker AI 사용 섹션을 참조하세요.
Aurora MySQL DB 클러스터와 함께 Amazon Bedrock 사용
Amazon Bedrock을 사용하려면 모델을 간접 호출하는 사용자 정의 함수(UDF)를 Aurora MySQL 데이터베이스에 생성해야 합니다. 자세한 내용은 Amazon Bedrock 사용 설명서의 Amazon Bedrock에서 지원되는 모델을 참조하세요.
UDF는 다음 구문을 사용합니다.
CREATE FUNCTIONfunction_name(argumenttype) [DEFINER = user] RETURNSmysql_data_type[SQL SECURITY {DEFINER | INVOKER}] ALIAS AWS_BEDROCK_INVOKE_MODEL MODEL ID 'model_id' [CONTENT_TYPE 'content_type'] [ACCEPT 'content_type'] [TIMEOUT_MStimeout_in_milliseconds];
-
Amazon Bedrock 함수는
RETURNS JSON을 지원하지 않습니다. 필요한 경우CONVERT또는CAST를 사용하여TEXT에서JSON으로 변환할 수 있습니다. -
CONTENT_TYPE또는ACCEPT를 지정하지 않으면 기본값은application/json입니다. -
TIMEOUT_MS를 지정하지 않으면aurora_ml_inference_timeout의 값이 사용됩니다.
예를 들어, 다음 UDF는 Amazon Titan Text Express 모델을 간접 호출합니다.
CREATE FUNCTION invoke_titan (request_body TEXT) RETURNS TEXT ALIAS AWS_BEDROCK_INVOKE_MODEL MODEL ID 'amazon.titan-text-express-v1' CONTENT_TYPE 'application/json' ACCEPT 'application/json';
DB 사용자가 이 함수를 사용할 수 있도록 허용하려면 다음 SQL 명령을 사용하세요.
GRANT EXECUTE ON FUNCTIONdatabase_name.invoke_titan TOuser@domain-or-ip-address;
그러면 사용자는 다음 예시에서와 같이 다른 함수처럼 invoke_titan을 직접 호출할 수 있습니다. Amazon Titan 텍스트 모델에 따라 요청 본문의 형식을 지정해야 합니다.
CREATE TABLE prompts (request varchar(1024)); INSERT INTO prompts VALUES ( '{ "inputText": "Generate synthetic data for daily product sales in various categories - include row number, product name, category, date of sale and price. Produce output in JSON format. Count records and ensure there are no more than 5.", "textGenerationConfig": { "maxTokenCount": 1024, "stopSequences": [], "temperature":0, "topP":1 } }'); SELECT invoke_titan(request) FROM prompts; {"inputTextTokenCount":44,"results":[{"tokenCount":296,"outputText":" ```tabular-data-json { "rows": [ { "Row Number": "1", "Product Name": "T-Shirt", "Category": "Clothing", "Date of Sale": "2024-01-01", "Price": "$20" }, { "Row Number": "2", "Product Name": "Jeans", "Category": "Clothing", "Date of Sale": "2024-01-02", "Price": "$30" }, { "Row Number": "3", "Product Name": "Hat", "Category": "Accessories", "Date of Sale": "2024-01-03", "Price": "$15" }, { "Row Number": "4", "Product Name": "Watch", "Category": "Accessories", "Date of Sale": "2024-01-04", "Price": "$40" }, { "Row Number": "5", "Product Name": "Phone Case", "Category": "Accessories", "Date of Sale": "2024-01-05", "Price": "$25" } ] } ```","completionReason":"FINISH"}]}
사용하는 다른 모델의 경우 요청 본문의 형식을 해당 모델에 맞게 적절히 지정해야 합니다. 자세한 내용은 Amazon Bedrock 사용 설명서의 파운데이션 모델의 추론 파라미터를 참조하세요.
Aurora MySQL DB 클러스터와 함께 Amazon Comprehend 사용
Aurora MySQL의 경우 Aurora 기계 학습은 Amazon Comprehend 및 텍스트 데이터를 사용하기 위한 다음 두 가지 내장 함수를 제공합니다. 분석할 텍스트(input_data)를 제공하고 언어(language_code)를 지정합니다.
- aws_comprehend_detect_sentiment
-
이 함수는 텍스트에 긍정적, 부정적, 중립적 또는 혼합된 감정 태도가 있는 것으로 식별합니다. 이 함수의 참조 문서는 다음과 같습니다.
aws_comprehend_detect_sentiment( input_text, language_code [,max_batch_size] )자세히 알아보려면 Amazon Comprehend 개발자 안내서의 Sentiment(감정)를 참조하세요.
- aws_comprehend_detect_sentiment_confidence
-
이 함수는 주어진 텍스트에 대해 감지된 감정의 신뢰도를 측정합니다. aws_comprehend_detect_sentiment 함수에서 텍스트에 할당한 감정의 신뢰도를 나타내는 값(유형,
double)을 반환합니다. 신뢰도는 0과 1 사이의 통계 지표입니다. 신뢰도가 높을수록 결과에 더 많은 가중치를 줄 수 있습니다. 함수 설명서의 요약은 다음과 같습니다.aws_comprehend_detect_sentiment_confidence( input_text, language_code [,max_batch_size] )
두 함수(aws_comprehend_detect_sentiment_confidence, aws_comprehend_detect_sentiment) 모두 아무것도 지정되지 않을 경우 max_batch_size는 기본값인 25를 사용합니다. 배치 크기는 항상 0보다 커야 합니다. max_batch_size를 사용하여 Amazon Comprehend 함수 호출의 성능을 조정할 수 있습니다. 대용량 배치는 Aurora MySQL DB 클러스터의 더 큰 메모리 사용으로 인한 더 빠른 성능을 상쇄합니다. 자세한 내용은 Aurora MySQL을 사용하는 Aurora 기계 학습의 성능 고려 사항 단원을 참조하십시오.
Amazon Comprehend의 감성 감지 함수에 대한 파라미터 및 반환 유형에 관한 자세한 내용은 DetectSentiment를 참조하세요.
예: Amazon Comprehend 함수를 사용하는 간단한 쿼리
다음은 고객이 지원 팀에 얼마나 만족하는지 확인하기 위해 이 두 함수를 호출하는 간단한 쿼리의 예입니다. 도움 요청이 있을 때마다 고객 피드백을 저장하는 데이터베이스 테이블(support)이 있다고 가정해 봅시다. 이 예시 쿼리는 두 내장 함수를 테이블 feedback 열의 텍스트에 모두 적용하고 결과를 출력합니다. 함수에서 반환되는 신뢰도 값은 0.0~1.0의 double입니다. 더 읽기 쉬운 출력을 위해 이 쿼리는 결과를 소수점 6개로 반올림합니다. 더 쉽게 비교할 수 있도록 이 쿼리는 신뢰도가 가장 높은 결과부터 먼저 결과를 내림차순으로 정렬합니다.
SELECT feedback AS 'Customer feedback', aws_comprehend_detect_sentiment(feedback, 'en') AS Sentiment, ROUND(aws_comprehend_detect_sentiment_confidence(feedback, 'en'), 6) AS Confidence FROM support ORDER BY Confidence DESC;+----------------------------------------------------------+-----------+------------+ | Customer feedback | Sentiment | Confidence | +----------------------------------------------------------+-----------+------------+ | Thank you for the excellent customer support! | POSITIVE | 0.999771 | | The latest version of this product stinks! | NEGATIVE | 0.999184 | | Your support team is just awesome! I am blown away. | POSITIVE | 0.997774 | | Your product is too complex, but your support is great. | MIXED | 0.957958 | | Your support tech helped me in fifteen minutes. | POSITIVE | 0.949491 | | My problem was never resolved! | NEGATIVE | 0.920644 | | When will the new version of this product be released? | NEUTRAL | 0.902706 | | I cannot stand that chatbot. | NEGATIVE | 0.895219 | | Your support tech talked down to me. | NEGATIVE | 0.868598 | | It took me way too long to get a real person. | NEGATIVE | 0.481805 | +----------------------------------------------------------+-----------+------------+ 10 rows in set (0.1898 sec)
예: 특정 신뢰도를 초과하는 텍스트의 평균 감정 결정
일반적인 Amazon Comprehend 쿼리는 감성이 특정 값이고 신뢰도 수준이 특정 숫자보다 더 큰 행을 찾습니다. 예를 들어 다음 쿼리에서는 데이터베이스 내 문서의 평균 감성을 확인하는 방법을 보여줍니다. 이 쿼리에서는 평가 신뢰도가 80% 이상인 문서만 고려합니다.
SELECT AVG(CASE aws_comprehend_detect_sentiment(productTable.document, 'en') WHEN 'POSITIVE' THEN 1.0 WHEN 'NEGATIVE' THEN -1.0 ELSE 0.0 END) AS avg_sentiment, COUNT(*) AS total FROM productTable WHERE productTable.productCode = 1302 AND aws_comprehend_detect_sentiment_confidence(productTable.document, 'en') >= 0.80;
Aurora MySQL DB 클러스터와 함께 SageMaker AI 사용
Aurora MySQL DB 클러스터에서 SageMaker AI 기능을 사용하려면 SageMaker AI 엔드포인트에 대한 직접 호출 및 해당 추론 기능을 내장하는 저장 함수를 만들어야 합니다. 이렇게 하려면 일반적으로 Aurora MySQL DB 클러스터의 다른 처리 작업과 동일한 방식으로 MySQL의 CREATE FUNCTION을 사용합니다.
추론을 위해 SageMaker AI에 배포된 모델을 사용하려면 저장 함수에 대해 MySQL 데이터 정의 언어(DDL) 문을 사용하여 사용자 정의 함수를 만듭니다. 각 저장 함수는 이 모델을 호스팅하는 SageMaker AI 엔드포인트를 대표합니다. 이러한 함수를 정의할 때 모델에 대한 입력 파라미터, 간접 호출할 특정 SageMaker AI 엔드포인트, 반환 유형을 지정합니다. 이 함수에서는 입력 파라미터에 모델을 적용한 후에 SageMaker AI 엔드포인트가 계산한 추론을 반환합니다.
모든 Aurora Machine Learning 저장 함수에서는 숫자 형식 또는 VARCHAR를 반환합니다. BIT를 제외한 모든 숫자형을 사용할 수 있습니다. JSON, BLOB, TEXT, DATE 등 다른 유형은 허용되지 않습니다.
다음 예시는 SageMaker AI를 사용하기 위한 CREATE FUNCTION 구문을 보여줍니다.
CREATE FUNCTION function_name (
arg1 type1,
arg2 type2, ...)
[DEFINER = user]
RETURNS mysql_type
[SQL SECURITY { DEFINER | INVOKER } ]
ALIAS AWS_SAGEMAKER_INVOKE_ENDPOINT
ENDPOINT NAME 'endpoint_name'
[MAX_BATCH_SIZE max_batch_size];
이는 일반 CREATE FUNCTION DDL 명령문의 확장입니다. SageMaker AI 함수를 정의하는 CREATE FUNCTION 문에서 함수 본문을 정의해서는 안 됩니다. 그 대신에 키워드인 ALIAS를 함수 본문이 일반적으로 배치되는 곳에 지정합니다. 현재 Aurora Machine Learning은 이 확장 구문에 대해 aws_sagemaker_invoke_endpoint만 지원합니다. endpoint_name 파라미터를 지정해야 합니다. SageMaker AI 엔드포인트는 모델마다 다양한 특성이 있을 수 있습니다.
참고
CREATE FUNCTION에 대한 자세한 내용은 MySQL 8.0 참조 매뉴얼의 CREATE PROCEDURE 및 CREATE FUNCTION 문에 관한 문서
max_batch_size 파라미터는 선택 항목입니다. 기본적으로 최대 배치 크기는 10,000입니다. 함수에서 이 파라미터를 사용하여 SageMaker AI에 대한 배치 요청에서 처리되는 입력의 최대 개수를 제한할 수 있습니다. max_batch_size 파라미터는 너무 큰 입력으로 인한 오류를 방지하거나 SageMaker AI가 응답을 더 빨리 반환하게 하는 데 도움이 될 수 있습니다. 이 파라미터는 SageMaker AI 요청 처리에 사용되는 내부 버퍼의 크기에 영향을 미칩니다. max_batch_size에 너무 큰 값을 지정하면 DB 인스턴스에 상당한 메모리 오버헤드가 발생할 수 있습니다.
MANIFEST 설정을 기본값인 OFF로 두는 것이 좋습니다. 사용자는 MANIFEST ON 옵션을 사용할 수 있지만 일부 SageMaker AI 기능에서는 이 옵션을 통해 내보낸 CSV를 직접 사용할 수 없습니다. 매니페스트 형식은 SageMaker AI의 예상 매니페스트 형식과 호환되지 않습니다.
각 SageMaker AI 모델에 대해 별도 저장 함수를 만듭니다. 이렇게 함수를 모델에 매핑해야 하는 이유는 엔드포인트가 특정 모델과 연결되어 있고 각 모델은 서로 다른 파라미터를 받아들이기 때문입니다. 모델 입력 및 모델 출력 유형에 SQL 유형을 사용하면 AWS 서비스 간 데이터 전달 과정에서 발생하는 유형 변환 오류를 방지하는 데 도움이 됩니다. 모델을 누가 적용할 수 있는지 제어할 수 있습니다. 또한 최대 배치 크기를 나타내는 파라미터를 지정하여 런타임 특성을 제어할 수 있습니다.
현재 모든 Aurora Machine Learning 함수에는 NOT DETERMINISTIC 속성이 있습니다. 이 속성을 명시적으로 지정하지 않으면 Aurora가 NOT DETERMINISTIC으로 자동 설정합니다. 이러한 요구 사항이 있는 이유는 SageMaker AI 모델이 데이터베이스에 대한 알림 없이 변경될 수 있기 때문입니다. 변경된 경우 Aurora Machine Learning 함수에 대한 호출을 통해 단일 트랜잭션 내에서 동일 입력에 대해 다른 결과가 반환될 수 있습니다.
CONTAINS SQL 문에서는 NO SQL, READS SQL DATA, MODIFIES SQL DATA 또는 CREATE
FUNCTION 특성을 사용할 수 없습니다.
다음은 이상을 감지하기 위해 SageMaker AI 엔드포인트를 간접 호출하는 방법에 관한 예시입니다. SageMaker AI 엔드포인트 random-cut-forest-model이 있습니다. 이에 상응하는 모델은 이미 random-cut-forest 알고리즘의 교육을 받았습니다. 각 입력에 대해 이 모델은 이상 점수를 반환합니다. 이 예에서는 평균 점수 기준 표준 편차 3개를 초과하는 점수(약 99.9 백분위수)를 지닌 데이터 포인트를 보여줍니다.
CREATE FUNCTION anomaly_score(value real) returns real
alias aws_sagemaker_invoke_endpoint endpoint name 'random-cut-forest-model-demo';
set @score_cutoff = (select avg(anomaly_score(value)) + 3 * std(anomaly_score(value)) from nyc_taxi);
select *, anomaly_detection(value) score from nyc_taxi
where anomaly_detection(value) > @score_cutoff;
문자열을 반환하는 SageMaker AI 함수에 대한 문자 집합 요구 사항
문자열을 반환하는 SageMaker AI 함수에 대한 반환 유형으로 utf8mb4 문자 집합을 지정하는 것이 좋습니다. 그렇게 하기 어렵다면 utf8mb4 문자 집합에서 나타내는 값을 담을 수 있을 만큼 충분히 큰 문자열 길이를 반환 유형에 사용하십시오. 다음 예에서는 함수에 utf8mb4 문자 집합을 선언하는 방법을 보여줍니다.
CREATE FUNCTION my_ml_func(...) RETURNS VARCHAR(5) CHARSET utf8mb4 ALIAS ...현재 문자열을 반환하는 각 SageMaker AI 함수에서는 반환 값에 대해 utf8mb4 문자 집합을 사용합니다. 반환 값에서는 SageMaker AI 함수가 반환 유형에 다른 문자 집합을 묵시적으로 또는 명시적으로 선언한다 하더라도 이러한 문자 집합을 사용합니다. SageMaker AI 함수가 반환 값에 대해 다른 문자 집합을 선언하는 경우 반환된 데이터는 충분히 길지 않은 테이블 열에 저장하면 자동으로 잘릴 수 있습니다. 예를 들어 DISTINCT 절을 이용한 쿼리로 인해 임시 테이블이 생성됩니다. 따라서 SageMaker AI 함수 결과는 쿼리 중에 문자열이 내부적으로 처리되는 방식으로 인해 잘릴 수 있습니다.
SageMaker AI 모델 훈련을 위해 Amazon S3로 데이터 내보내기(고급)
제공된 알고리즘 중 일부를 사용하여 Aurora 기계 학습과 SageMaker AI를 시작하고, 팀의 데이터 과학자가 SQL 코드와 함께 사용할 수 있는 SageMaker AI 엔드포인트를 제공하는 것이 좋습니다. 다음에서는 자체 SageMaker AI 모델 및 Aurora MySQL DB 클러스터와 함께 자체 Amazon S3 버킷을 사용하는 방법에 대한 간략한 정보를 찾을 수 있습니다.
기계 학습은 학습과 추론이라는 두 가지 주요 단계로 구성됩니다. SageMaker AI 모델을 훈련하려면 데이터를 Amazon S3 버킷으로 내보냅니다. Amazon S3 버킷은 Jupyter SageMaker AI 노트북 인스턴스가 모델을 배포하기 전에 모델을 훈련하는 데 사용합니다. SELECT INTO OUTFILE S3 문을 사용하여 Aurora MySQL DB 클러스터에서 데이터를 쿼리한 후 Amazon S3 버킷에 저장된 텍스트 파일에 직접 저장할 수 있습니다. 그런 다음 노트북 인스턴스는 교육용 Amazon S3 버킷에서 데이터를 소비합니다.
Aurora Machine Learning은 Aurora MySQL의 기존 SELECT INTO OUTFILE 구문을 확장하여 데이터를 CSV 형식으로 내보냅니다. 생성된 CSV 파일은 교육 목적으로 이 형식이 필요한 모델이 직접 소비할 수 있습니다.
SELECT * INTO OUTFILE S3 's3_uri' [FORMAT {CSV|TEXT} [HEADER]] FROM table_name;이 확장에서는 표준 CSV 형식을 지원합니다.
-
TEXT형식은 기존 MySQL 내보내기 형식과 동일합니다. 이것은 기본 형식입니다. -
CSV형식은 새로 도입된 형식으로서, RFC-4180의 사양을 따릅니다. -
선택적 키워드인
HEADER를 지정하는 경우 출력 파일에는 헤더 행이 한 줄 포함됩니다. 이 헤더 행의 레이블은SELECT문의 열 이름에 해당합니다. -
CSV및HEADER라는 키워드를 식별자로 계속 사용할 수 있습니다.
SELECT INTO의 확장 구문 및 문법은 현재 다음과 같습니다.
INTO OUTFILE S3 's3_uri'
[CHARACTER SET charset_name]
[FORMAT {CSV|TEXT} [HEADER]]
[{FIELDS | COLUMNS}
[TERMINATED BY 'string']
[[OPTIONALLY] ENCLOSED BY 'char']
[ESCAPED BY 'char']
]
[LINES
[STARTING BY 'string']
[TERMINATED BY 'string']
]
Aurora MySQL을 사용하는 Aurora 기계 학습의 성능 고려 사항
Amazon Bedrock, Amazon Comprehend 및 SageMaker AI 서비스는 Aurora 기계 학습 함수에서 간접 호출할 때 대부분의 작업을 수행합니다. 즉, 필요에 따라 독립적으로 리소스를 확장할 수 있습니다. Aurora MySQL DB 클러스터의 경우 함수 호출을 최대한 효율적으로 만들 수 있습니다. 다음은 Aurora 기계 학습을 사용할 때 참고해야 할 몇 가지 성능 고려 사항입니다.
모델 및 프롬프트
Amazon Bedrock을 사용할 때의 성능은 사용하는 모델 및 프롬프트에 따라 크게 달라집니다. 사용 사례에 가장 적합한 모델과 프롬프트를 선택하세요.
쿼리 캐시
Aurora MySQL 쿼리 캐시는 Aurora 기계 학습 함수에 대해 작동하지 않습니다. Aurora MySQL은 Aurora 기계 학습 함수를 호출하는 모든 SQL 문에 대한 쿼리 결과를 쿼리 캐시에 저장하지 않습니다.
Aurora Machine Learning 함수 호출을 위한 배치 최적화
Aurora 클러스터에서 영향을 미칠 수 있는 주요 Aurora Machine Learning 성능 측면은 Aurora Machine Learning 저장 함수에 대한 호출의 배치 모드 설정입니다. 기계 학습 함수는 일반적으로 상당한 오버헤드가 필요하므로 각 행에 대해 외부 서비스를 별도로 호출하는 것은 실용적이지 않습니다. Aurora Machine Learning은 많은 행에 대한 외부 Aurora Machine Learning 서비스 호출을 단일 배치로 결합하여 이러한 오버헤드를 최소화할 수 있습니다. Aurora Machine Learning에서 모든 입력 행에 대한 응답을 수신한 다음 응답을 실행 중인 쿼리에 한 번에 한 행씩 다시 전달합니다. 이러한 최적화를 통해 결과를 변경하지 않고도 Aurora 쿼리의 처리량 및 지연 시간을 개선할 수 있습니다.
SageMaker AI 엔드포인트에 연결된 Aurora 저장 함수를 만들 때 배치 크기 파라미터를 정의합니다. 이 파라미터는 SageMaker AI에 대한 모든 기본 직접 호출을 위해 전송되는 행의 수에 영향을 미칩니다. 대량의 행을 처리하는 쿼리의 경우 각 행에 대해 별도의 SageMaker AI 직접 호출을 수행하는 데 드는 오버헤드는 상당히 클 수 있습니다. 저장 프로시저에서 처리하는 데이터 세트의 용량이 크면 클수록 배치 크기를 더 크게 확장할 수 있습니다.
배치 모드 최적화를 SageMaker AI 함수에 적용할 수 있는 경우 EXPLAIN PLAN 문에서 산출하는 쿼리 계획을 확인함으로써 이를 구별할 수 있습니다. 이 경우 실행 계획의 extra 열에는 Batched machine learning이 포함됩니다. 다음 예에서는 배치 모드를 사용하는 SageMaker AI 함수 직접 호출을 보여줍니다.
mysql> CREATE FUNCTION anomaly_score(val real) returns real alias aws_sagemaker_invoke_endpoint endpoint name 'my-rcf-model-20191126';
Query OK, 0 rows affected (0.01 sec)
mysql> explain select timestamp, value, anomaly_score(value) from nyc_taxi;
+----+-------------+----------+------------+------+---------------+------+---------+------+------+----------+--------------------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+----------+------------+------+---------------+------+---------+------+------+----------+--------------------------+
| 1 | SIMPLE | nyc_taxi | NULL | ALL | NULL | NULL | NULL | NULL | 48 | 100.00 | Batched machine learning |
+----+-------------+----------+------------+------+---------------+------+---------+------+------+----------+--------------------------+
1 row in set, 1 warning (0.01 sec)
내장된 Amazon Comprehend 함수 중 하나를 호출할 때 선택 사항인 max_batch_size 파라미터를 지정하여 배치 크기를 제어할 수 있습니다. 이 파라미터는 각 배치에서 처리되는 input_text 값의 최대 수를 제한합니다. 한 번에 여러 항목을 전송함으로써 Aurora 및 Amazon Comprehend 간 왕복 횟수를 줄입니다. 배치 크기 제한은 LIMIT 절을 이용한 쿼리와 같은 상황에서 유용합니다. max_batch_size에 작은 값을 사용함으로써 입력 텍스트를 얻는 횟수보다 더 많이 Amazon Comprehend를 호출하는 것을 방지할 수 있습니다.
Aurora Machine Learning 함수 평가를 위한 배치 최적화는 다음 경우에 적용됩니다.
-
선택 목록 또는
SELECT문의WHERE절 내 함수 호출 -
INSERT및REPLACE문의VALUES목록 내 함수 호출 -
UPDATE문 내SET값의 SageMaker AI 함수INSERT INTO MY_TABLE (col1, col2, col3) VALUES (ML_FUNC(1), ML_FUNC(2), ML_FUNC(3)), (ML_FUNC(4), ML_FUNC(5), ML_FUNC(6)); UPDATE MY_TABLE SET col1 = ML_FUNC(col2), SET col3 = ML_FUNC(col4) WHERE ...;
Aurora Machine Learning 모니터링
다음 예시와 같이 여러 글로벌 변수를 쿼리하여 Aurora 기계 학습 배치 작업을 모니터링할 수 있습니다.
show status like 'Aurora_ml%';
FLUSH STATUS 문을 사용하여 상태 변수를 재설정할 수 있습니다. 따라서 모든 숫자는 변수를 마지막으로 재설정한 이후의 합계, 평균 등을 나타냅니다.
Aurora_ml_logical_request_cnt-
마지막 상태 재설정 이후 DB 인스턴스가 Aurora 기계 학습 서비스로 전송되어야 한다고 평가한 논리적 요청의 수입니다. 배치 사용 여부에 따라 이 값은
Aurora_ml_actual_request_cnt보다 높을 수 있습니다. Aurora_ml_logical_response_cnt-
DB 인스턴스 사용자가 실행하는 모든 쿼리에 걸쳐 Aurora MySQL이 Aurora 기계 학습 서비스에서 수신하는 총 응답 횟수입니다.
Aurora_ml_actual_request_cnt-
DB 인스턴스 사용자가 실행하는 모든 쿼리에 걸쳐 Aurora MySQL이 Aurora 기계 학습 서비스에 전송하는 총 요청 수입니다.
Aurora_ml_actual_response_cnt-
DB 인스턴스 사용자가 실행하는 모든 쿼리에 걸쳐 Aurora MySQL이 Aurora 기계 학습 서비스에서 수신하는 총 응답 횟수입니다.
Aurora_ml_cache_hit_cnt-
DB 인스턴스 사용자가 실행하는 모든 쿼리에 걸쳐 Aurora MySQL이 Aurora 기계 학습 서비스에서 수신하는 총 내부 캐시 히트 횟수입니다.
Aurora_ml_retry_request_cnt-
마지막 상태 재설정 이후 DB 인스턴스가 Aurora 기계 학습 서비스로 전송한 재시도 요청의 수입니다.
Aurora_ml_single_request_cnt-
DB 인스턴스 사용자가 실행하는 모든 쿼리에 걸쳐 비일괄 모드로 평가되는 Aurora 기계 학습 함수의 총 개수입니다.
Aurora 기계 학습 함수에서 직접 호출하는 SageMaker AI 작업의 성능을 모니터링하는 방법에 대한 자세한 내용은 Monitor Amazon SageMaker AI를 참조하세요.
