Build an advanced mainframe file viewer in the AWS Cloud
Boopathy GOPALSAMY and Jeremiah O'Connor, Amazon Web Services
Summary
This pattern provides code samples and steps to help you build an advanced tool for browsing and reviewing your mainframe fixed-format files by using AWS serverless services. The pattern provides an example of how to convert a mainframe input file to an Amazon OpenSearch Service document for browsing and searching. The file viewer tool can help you achieve the following:
Retain the same mainframe file structure and layout for consistency in your AWS target migration environment (for example, you can maintain the same layout for files in a batch application that transmits files to external parties)
Speed up development and testing during your mainframe migration
Support maintenance activities after the migration
Prerequisites and limitations
Prerequisites
An active AWS account
A virtual private cloud (VPC) with a subnet that’s reachable by your legacy platform
Note
An input file and its corresponding common business-oriented language (COBOL) copybook (: For input file and COBOL copybook examples, see gfs-mainframe-solutions
on the GitHub repository. For more information about COBOL copybooks, see the Enterprise COBOL for z/OS 6.3 Programming Guide on the IBM website.)
Limitations
Copybook parsing is limited to no more than two nested levels (OCCURS)
Architecture
Source technology stack
Input files in FB (Fixed Blocked)
format COBOL copybook layout
Target technology stack
Amazon Athena
Amazon OpenSearch Service
Amazon Simple Storage Service (Amazon S3)
AWS Lambda
AWS Step Functions
Target architecture
The following diagram shows the process of parsing and converting a mainframe input file to an OpenSearch Service document for browsing and searching.

The diagram shows the following workflow:
An admin user or application pushes input files to one S3 bucket and COBOL copybooks to another S3 bucket.
Note
The S3 bucket with the input files invokes a Lambda function that kicks off a serverless Step Functions workflow. : The use of an S3 event trigger and Lambda function to drive the Step Functions workflow in this pattern is optional. The GitHub code samples in this pattern don’t include the use of these services, but you can use these services based on your requirements.
The Step Functions workflow coordinates all the batch processes from the following Lambda functions:
The
s3copybookparser.pyfunction parses the copybook layout and extracts field attributes, data types, and offsets (required for input data processing).The
s3toathena.pyfunction creates an Athena table layout. Athena parses the input data that’s processed by thes3toathena.pyfunction and converts the data to a CSV file.The
s3toelasticsearch.pyfunction ingests the results file from the S3 bucket and pushes the file to OpenSearch Service.
Users access OpenSearch Dashboards with OpenSearch Service to retrieve the data in various table and column formats and then run queries against the indexed data.
Tools
AWS services
Amazon Athena is an interactive query service that helps you analyze data directly in Amazon Simple Storage Service (Amazon S3) using standard SQL.
AWS Lambda is a compute service that helps you run code without needing to provision or manage servers. It runs your code only when needed and scales automatically, so you pay only for the compute time that you use. In this pattern, you use Lambda to implement core logic, such as parsing files, converting data, and loading data into OpenSearch Service for interactive file access.
Amazon OpenSearch Service is a managed service that helps you deploy, operate, and scale OpenSearch Service clusters in the AWS Cloud. In this pattern, you use OpenSearch Service to index the converted files and provide interactive search capabilities for users.
Amazon Simple Storage Service (Amazon S3) is a cloud-based object storage service that helps you store, protect, and retrieve any amount of data.
AWS Command Line Interface (AWS CLI) is an open-source tool that helps you interact with AWS services through commands in your command-line shell.
AWS Identity and Access Management (IAM) helps you securely manage access to your AWS resources by controlling who is authenticated and authorized to use them.
AWS Step Functions is a serverless orchestration service that helps you combine Lambda functions and other AWS services to build business-critical applications. In this pattern, you use Step Functions to orchestrate Lambda functions.
Other tools
Code
The code for this pattern is available in the GitHub gfs-mainframe-patterns
Epics
| Task | Description | Skills required |
|---|---|---|
Create the S3 bucket. | Create an S3 bucket for storing the copybooks, input files, and output files. We recommend the following folder structure for your S3 bucket:
| General AWS |
Create the s3copybookparser function. |
| General AWS |
Create the s3toathena function. |
| General AWS |
Create the s3toelasticsearch function. |
| General AWS |
Create the OpenSearch Service cluster. | Create the cluster
Grant access to the IAM role To provide fine-grained access to the Lambda function’s IAM role (
| General AWS |
Create Step Functions for orchestration. |
| General AWS |
| Task | Description | Skills required |
|---|---|---|
Upload the input files and copybooks to the S3 bucket. | Download sample files from the GitHub
| General AWS |
Invoke the Step Functions. |
For example:
| General AWS |
Validate the workflow execution in Step Functions. | In the Step Functions console For an example of a graphical workflow execution, see Step Functions graph in the Additional information section of this pattern. | General AWS |
Validate the delivery logs in Amazon CloudWatch. |
For an example of successful delivery logs, see CloudWatch delivery logs in the Additional information section of this pattern. | General AWS |
Validate the formatted file in OpenSearch Dashboards and perform file operations. |
| General AWS |
Related resources
References
Example COBOL copybook
(IBM documentation) BMC Compuware File-AID
(BMC documentation)
Tutorials
Tutorial: Using an Amazon S3 trigger to invoke a Lambda function (AWS Lambda documentation)
How do I create a serverless workflow with AWS Step Functions and AWS Lambda
(AWS documentation) Using OpenSearch Dashboards with Amazon OpenSearch Service (AWS documentation)
Additional information
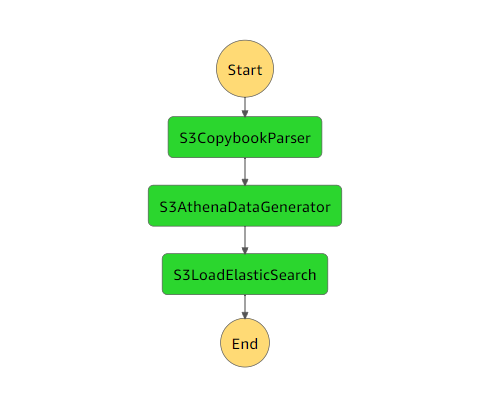
Step Functions graph
The following example shows a Step Functions graph. The graph shows the execution run status for the Lambda functions used in this pattern.
CloudWatch delivery logs
The following example shows successful delivery logs for the execution of the s3toelasticsearch execution.
2022-08-10T15:53:33.033-05:00 | Number of processing documents: 100 | |
|---|---|---|
2022-08-10T15:53:33.171-05:00 | [INFO] 2022-08-10T20:53:33.171Z a1b2c3d4-5678-90ab-cdef-EXAMPLE11111POST https://search-essearch-3h4uqclifeqaj2vg4mphe7ffle.us-east-2.es.amazonaws.com:443/_bulk [status:200 request:0.100s] | |
2022-08-10T15:53:33.172-05:00 | Bulk write succeed: 100 documents |
