本文為英文版的機器翻譯版本,如內容有任何歧義或不一致之處,概以英文版為準。
新產品需求預測的建議 AWS 架構
當您將 AI/ML 管道擴展到多個產品和區域時,建議您遵循機器學習操作 (MLOps) 的重現性、可靠性和可擴展性最佳實務。如需詳細資訊,請參閱《Amazon SageMaker AI 文件》中的實作MLOps。下圖顯示實作 ML 模型的範例 AWS 架構,可預測新產品推出的需求。
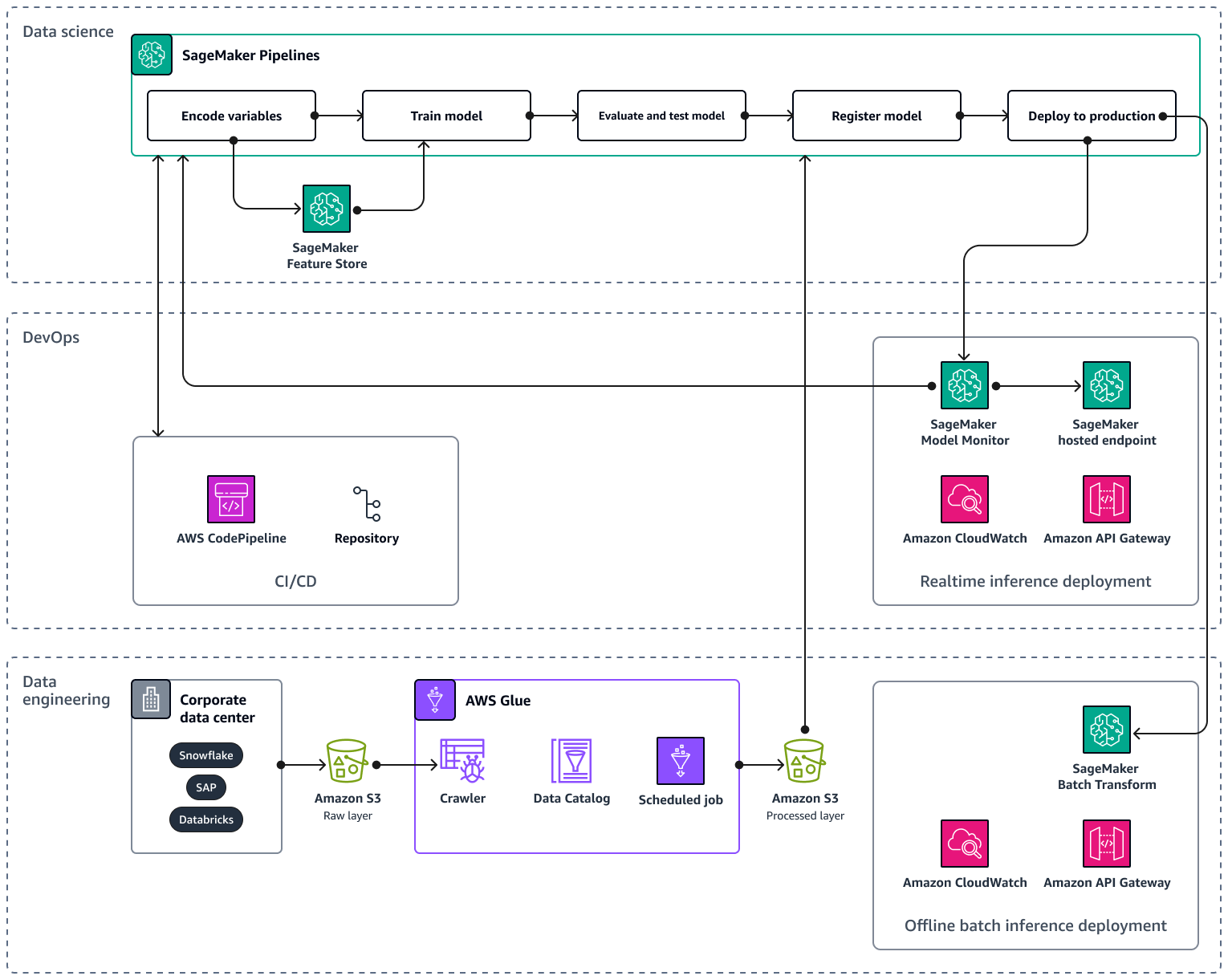
範例 AWS 架構包含三個圖層:資料工程 DevOps和資料科學。
資料工程層著重於使用 AWS Glue ,然後在 Amazon Simple Storage Service (Amazon S3) 中以經濟實惠的方式儲存資料,從公司資料來源擷取資料。 AWS Glue是全受管無伺服器ETL服務,可協助您分類、清理、轉換和可靠地在不同資料存放區之間傳輸資料。Amazon S3 是一種物件儲存服務,可提供可擴展性、資料可用性、安全性和效能。資料工程層也會在 Amazon SageMaker AI 中使用批次轉換,顯示離線批次推論部署。批次轉換會從 Amazon S3 取得輸入資料,並透過 Amazon API Gateway 在一或多個HTTP請求中將其傳送至推論管道模型。Amazon API Gateway 是一項全受管服務,可協助您APIs建立、發佈、維護、監控和保護任何規模。最後,資料工程層會顯示 Amazon CloudWatch 的使用,這項服務可讓您了解整個系統的效能,並協助您設定警示、自動回應變更,以及取得營運運作狀態的統一檢視。 會將日誌檔案 CloudWatch 儲存到您指定的 Amazon S3 儲存貯體。
layer DevOps 使用 API Gateway CloudWatch、 和 Amazon SageMaker AI Model Monitor 進行即時推論部署。Model Monitor 可協助您設定自動警示觸發系統,以找出模型品質的偏差,例如資料偏離和異常。Amazon CloudWatch Logs 會從模型監控收集日誌檔案,並在模型品質達到您預設的特定閾值時通知您。layer DevOps 也顯示使用 AWS CodePipeline來自動化程式碼交付管道。
資料科學層顯示使用 Amazon SageMaker AI Pipelines 和 Amazon SageMaker AI Feature Store 來管理機器學習生命週期。 SageMaker AI Pipelines 是一種專門建置的工作流程協調服務,可協助您自動化從資料預先處理到模型監控的所有 ML 階段。透過直覺式 UI 和 Python SDK,您可以大規模管理可 end-to-end重複的 ML 管道。原生整合多個 AWS 服務 可協助您根據您的MLOps需求自訂 ML 生命週期。Feature Store 是全受管、專門建置的儲存庫,可存放、共用和管理 ML 模型的功能。功能是 ML 模型的輸入,而且會在訓練和推論期間使用。
