步驟 2:準備資料
有了可用的原始資料後,您必須處理複雜性 (例如遺漏的資料),並確定您為預測模型準備的資料能夠確切擷取預期的解釋。
如何處理遺漏的資料
在實際的預測問題中,常見的情況是原始資料中有遺漏值存在。時間序列中有遺漏值,表示具有指定頻率的每個時間點的真實對應值無法供進一步處理之用。值被標示為遺漏可能有多種原因。
發生遺漏值的原因可能是沒有交易,或可能的測量錯誤 (例如,因為監視特定資料的服務未正常運作,或因為測量無法正確進行)。在零售案例研究中,第二種原因的常見範例是需求預測中的缺貨狀況,這表示需求不等於當天的銷售額。
當服務達到限制時 (例如,特定 AWS 區域 中的 Amazon EC2
遺漏值也可以由特徵處理元件插入,以透過填補確保時間序列的長度相等。遺漏值若遍佈到某種程度,可能會嚴重影響模型的準確性。
範例 1
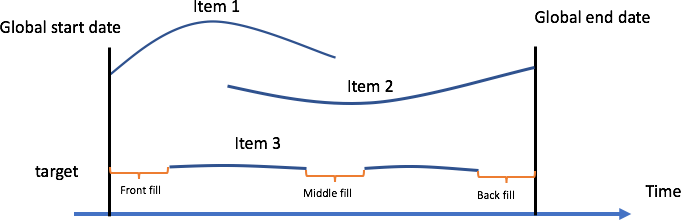
填入是將標準化值新增至資料集中的遺失項目的程序。下圖針對由三個品項組成的資料集中的品項 2,說明了在 Amazon Forecast 中處理遺漏值的不同策略 — 前端、中間、往回和未來填入。
Amazon Forecast 對於目標和相關時間序列均支援填入。全域開始日期定義為您的資料集中所有品項的開始日期之中最早的開始日期。在下列範例中,全域開始日期是品項 1 的開始日期。同樣地,全域結束日期定義為所有品項的時間序列最晚的結束日期,即品項 2 的結束日期。
前端填入會填入從特定時間序列的開頭到全域開始日期之間的每個值。截至本文件發佈時,Amazon Forecast 並未開啟任何前端填入,並允許所有時間序列從不同的時間點開始。中間填入表示在時間序列中間 (例如,在品項的開始日期和結束日期之間) 填入的值,往回填入則會在該時間序列的最後一個日期到全域結束日期之間填入。
對於目標時間序列,中間和往回填入方法的預設填入邏輯為零。未來填入 (僅適用於相關時間序列) 會填入品項的全域結束日期與客戶指定的預測期間之間的任何遺漏值。將相關時間序列資料集與 Prophet 和 DeepAR+ 一起使用時需要未來值,對 CNN-QR 而言則是選用的。
Amazon Forecast 中的遺漏價值處理策略
在上圖中,全域開始日期表示所有品項的開始日期之中最早的開始日期,而全域結束日期則表示所有品項的結束日期之中最晚的結束日期。預測期間是 Forecast 就目標值提供預測的期間。
可供貨品項的交易資料顯示銷售額為零,是零售研究中常見的情況。這些值會被視為真的零,並且用於指標評估元件中。Amazon Forecast 可讓使用者識別實際上遺漏的值,並將其編碼為非數字 (NaN) 以供演算法處理。本文接下來將探討為何這兩種案例有所不同,及其各自的適用時機。
在零售案例研究中,零售商銷售了零個可供貨品項的資訊,會與銷售了零個不可供貨品項的資訊不同;這可分成在該品項的非上市期間 (例如,在該品項推出前或停賣後) 或在其上市期間 (例如,部分缺貨,或沒有此時間範圍內的銷售資料記錄) 兩種情況。預設的零填入適用於前述的第一個案例。在第二個案例中,即使對應的目標值通常為零,但在標示為遺漏的值中還會傳達其他資訊。最佳實務是保留有遺漏資料的資訊,而不要捨棄此資訊。請參閱下列範例,了解保留該資訊有何重要性。
Amazon Forecast 支援值、平均值、中位數、最小值和最大值等其他填入邏輯。對於相關時間序列 (例如價格或促銷),並沒有針對中間、往回或未來填入方法指定的預設值,因為正確的遺漏值邏輯會隨著屬性類型與使用案例而不同。支援相關時間序列的填入邏輯包括零、值、平均值、中位數、最小值和最大值。
若要執行遺漏值填入,請指定您在呼叫 CreatePredictor 操作時要實作的填入類型。填入邏輯指定於 FeaturizationMethod 物件中。例如,若某值不代表目標時間序列中不可供貨產品的銷售額為零,在對該值進行編碼時,請將填入類型設定為 NaN,以將值標示為真正的遺漏值。與零填入不同,使用 NaN 編碼的值會被視為真正的遺漏值,而不會用於指標評估元件中

對同一品項進行預測時使用 0 填入與 NaN 填入的效果
在上方的左圖中,垂直黑線左側的值填入 0,產生了低估偏差的預測 (垂直黑線右側)。在右圖中,這些值標示為 NaN,而產生了適當的預測。
範例 2
上圖說明對線性狀態空間模型 (例如ARIMA 或 ETS) 正確處理遺漏值的重要性。其中繪製了部分缺貨之品項的需求預測。訓練區域以綠色顯示在左圖中,預測範圍在右側面板中以紅色顯示,真正的目標顯示為黑色。中位數、p10 和 p90 預測分別顯示為紅線和陰影區域。底部顯示以紅色標示的缺貨商品 (80% 的資料)。在左圖中,缺貨區域遭到忽略,並以 0 填入。
這導致預測模型假設有很多零要預測,因而致使預測過低。在右圖中,缺貨區域被視為真正的遺漏觀察值,缺貨區域中的需求變成未定值。將缺貨品項的遺漏值適當標示為 NaN 後,您會在此圖中看到預測範圍內沒有低估偏差。Amazon Forecast 填補了資料中的這些缺漏,讓您可以輕鬆地正確處理遺漏的資料,而無須明確修改所有的輸入資料。
特徵化和相關時間序列的概念
Amazon Forecast 可讓使用者輸入相關資料,以利提高特定支援預測模型的準確性。這項資料有兩種類型:相關時間序列或靜態項目中繼資料。
注意
中繼資料和相關資料在機器學習中稱為特徵,在統計學中則稱為共變數。
相關時間序列是與目標值有一定關聯的時間序列,應提供某種程度的統計強度來預測目標值,因為它們以直觀的詞彙提供解釋 (如需範例,請參閱 Amazon Forecast:大規模預測時間序列
在 Amazon Forecast 中,您可以新增兩種類型的相關時間序列:歷史時間序列和前瞻性時間序列。歷史相關時間序列包含預測期間之前的資料點,而不包含未來預測期間內的任何資料點。前瞻性相關時間序列包含預測期間之前和期間內的資料點。
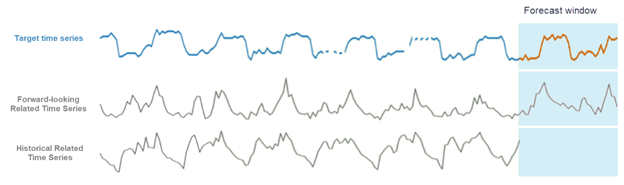
透過 Amazon Forecast 使用相關時間序列的不同方法
範例 3
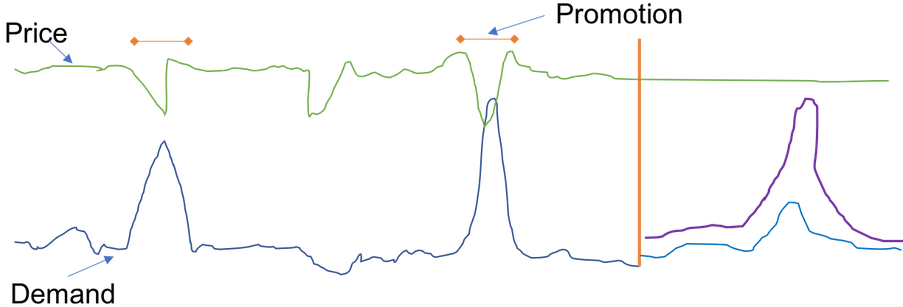
下圖顯示如何使用相關時間序列來預測暢銷書未來需求的範例。藍線代表目標時間序列中的需求。價格顯示為綠線。垂直線代表預測的開始日期,垂直線右側顯示兩個分位數的預測。
此範例使用前瞻性相關時間序列,此序列與目標時間序列的預測精細程度保持一致,且未來在預測開始日期到預測期間遞增的預測開始日期 (預測結束日期) 之間的範圍內,全程 (或多數時間) 都是已知的。
下圖也顯示價格是合用的特徵,因為您可以看到價格下降與產品銷售量增加之間的相關性。相關時間序列可透過個別的 CSV 檔案提供給 Amazon Forecast,其中包含品項 SKU、時間戳記和相關時間序列值 (在此案例中為價格)。
Amazon Forecast 支援彙總方法 (例如目標時間序列的平均值和總和),但不支援相關時間序列。例如,將每日價格與每週價格相加沒有什麼意義,每日促銷也是如此。
Amazon Forecast 可納入內建的特徵化資料集,將天氣和假日資訊自動整合到模型中 (請參閱 SupplementaryFeature)。天氣資訊和假日對零售需求可能有很大的影響。
特定商品的銷售量 (在垂直紅線左側顯示為藍色)
項目中繼資料 (也稱為類別變數) 是可輸入至 Amazon Forecast 的其他有用特徵 (如需範例,請參閱 Amazon Forecast:大規模預測時間序列
