翻訳は機械翻訳により提供されています。提供された翻訳内容と英語版の間で齟齬、不一致または矛盾がある場合、英語版が優先します。
拡張状態ヘルスレポートおよびモニタリング
拡張ヘルスレポートは、環境で有効にすることができる機能の 1 つであり、これにより、AWS Elastic Beanstalk は環境内のリソースに関する追加の情報を収集できます。Elastic Beanstalk は、収集された情報を分析して環境全体の状態をより的確に示し、アプリケーションの使用を妨げる可能性のある問題を特定するために役立ちます。
色で状態を示す機能が変更されたことに加え、拡張ヘルスレポートにはステータス記述子が追加されています。これは、環境の状態が黄色または赤色の場合に検出された問題の重大度を示します。現在のステータスに関する詳細情報があるときは、[Causes] ボタンを選択して、[Health] ページにヘルスに関する詳細情報を表示できます。
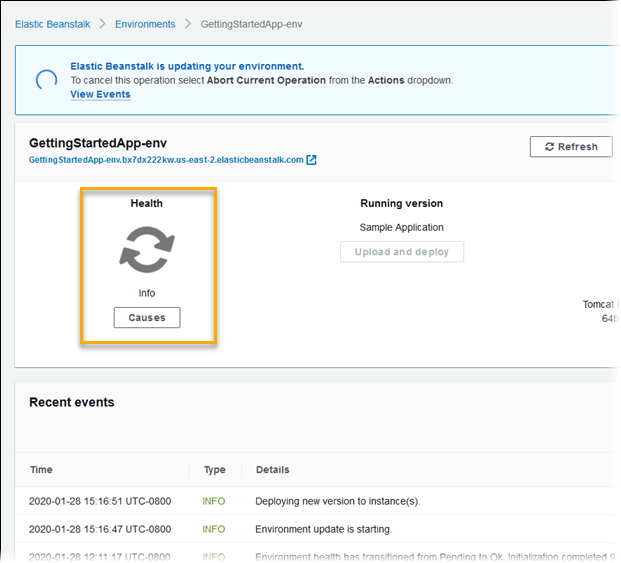
環境内で実行されている Amazon EC2 インスタンスに関する詳細なヘルス情報を提供するため、Elastic Beanstalk は、拡張ヘルスをサポートする各プラットフォームのバージョンの Amazon マシンイメージ (AMI) にヘルスエージェントを含めます。状態エージェントは、ウェブサーバーログとシステムメトリクスを監視して、Elastic Beanstalk サービスに中継します。Elastic Beanstalk は、これらのメトリクスと、Elastic Load Balancing と Amazon EC2 Auto Scaling から取られたデータを分析し、環境の状態に関する全体像を提示します。
環境のリソースに関する情報の収集および提示に加えて、Elastic Beanstalk は何種類かのエラー状態に備えて環境内のリソースを監視し、通知を提供します。これは、障害を回避し、設定の問題を解決するために役立ちます。お客様の環境のヘルスに影響を与える要因としては、アプリケーションによって処理された各リクエストの結果、お客様のインスタンスのオペレーティングシステムからのメトリクス、最新のデプロイのステータスなどがあります。
Elastic Beanstalk コンソールで環境の概要ページを使用するか、Elastic Beanstalk コマンドラインインターフェイス (EB CLI) で eb health コマンドを実行することで、ヘルスステータスをリアルタイムで確認できます。Elastic Beanstalk によって収集された拡張ヘルスレポートのための情報を Amazon CloudWatch にカスタムメトリクスとしてパブリッシュするように環境を設定することで、環境とインスタンスの状態を記録し、追跡することができます。無料の EnvironmentHealth 以外のすべてのメトリクスには、カスタムメトリクスに対する CloudWatch 料金
拡張ヘルスレポートでは、バージョン 2 以降の プラットフォームバージョンが必要です。リソースのモニタリングとメトリクスの公開を行うには、環境にインスタンスプロファイルとサービスロールの両方を用意する必要があります。マルチコンテナ Docker プラットフォームは、デフォルトではウェブサーバーを含んでいませんが、適切な形式でログを提供するようにウェブサーバーを設定している場合は、拡張ヘルスレポートで使用できます。
Windows プラットフォームのメモ
-
この機能は、バージョン 2 (v2) 以前の Windows Server プラットフォームバージョンでは使用できません。
-
Windows Server 環境で拡張ヘルスレポートを有効にするときは、IIS ログ設定
は変更しないでください。拡張ヘルスモニタリングを正しく動作させるには、IIS のログ記録を W3C 形式および ETW イベントのみまたはログファイルと ETW イベントの両方のログイベント送信先で設定する必要があります。 さらに、いずれの環境のインスタンスでも、Elastic Beanstalk ヘルスエージェントの Windows サービスを無効化または停止しないでください。インスタンスで拡張ヘルス情報を収集および報告するには、このサービスが有効で実行中である必要があります。
拡張ヘルスでは、環境にインスタンスプロファイルが必要です。インスタンスプロファイルには、環境インスタンスが拡張ヘルス情報を収集してレポートするためのアクセス許可を提供するロールが必要です。Elastic Beanstalk コンソールで v2 プラットフォームバージョンを使用して初めて環境を作成すると、デフォルトでは、必要なロールを作成するよう Elastic Beanstalk から求められ、拡張ヘルスレポートが有効になります。拡張ヘルスレポートの詳しいしくみについては、この後の説明を参照してください。すぐに開始するには、「Elastic Beanstalk の拡張ヘルスレポートの有効化」を参照してください。
Amazon Linux 2 プラットフォームにはインスタンスプロファイルが必要なため、拡張ヘルスは無条件にサポートできます。Amazon Linux 2 プラットフォームを使用して環境を作成する場合、Elastic Beanstalk は常に拡張ヘルスを有効にします。これは、環境を作成する方法 (Elastic Beanstalk コンソール、EB CLI 、AWS CLI、または API) に関係なく当てはまります。
トピック
- Elastic Beanstalk のヘルスエージェント
- インスタンスと環境の状態を判断するための要素
- ヘルスチェックルールのカスタマイズ
- 拡張ヘルスレポートのロール
- 拡張ヘルス認証
- 拡張ヘルスレポートのイベント
- 更新、デプロイ、およびスケーリング中の拡張ヘルスレポートの動作
- Elastic Beanstalk の拡張ヘルスレポートの有効化
- 環境管理コンソールでの拡張ヘルスモニタリング
- 状態の色とステータス
- インスタンスメトリクス
- 環境の拡張ヘルスルールの設定
- 環境の Amazon CloudWatch カスタムメトリクスの発行
- Elastic Beanstalk API での拡張ヘルスレポートの使用
- 拡張ヘルスログ形式
- 通知とトラブルシューティング
Elastic Beanstalk のヘルスエージェント
Elastic Beanstalk のヘルスエージェントは、環境内の各 Amazon EC2 インスタンスで実行されるデーモンプロセス (または Windows 環境のサービス) であり、オペレーティングシステムおよびアプリケーションレベルのヘルスメトリクスをモニタリングし、問題を Elastic Beanstalk に報告します。ヘルスエージェントは、各プラットフォームのバージョン 2.0 以降、すべてのプラットフォームのバージョンに含まれています。
状態エージェントからの報告内容は、ベーシックヘルスレポートの一部として Amazon EC2 Auto Scaling および Elastic Load Balancing によって CloudWatch に公開されるメトリクスと似ており、CPU 負荷、HTTP コード、レイテンシーなどが含まれます。ただし、状態エージェントによるレポートは、ベーシックヘルスレポートより高い詳細度と頻度で直接 Elastic Beanstalk に送信されます。
ベーシックヘルスレポートの場合、これらのメトリクスは、5 分間隔で公開され、環境マネジメントコンソールのグラフで確認できます。拡張ヘルスでは、Elastic Beanstalk ヘルスエージェントは 10 秒ごとに Elastic Beanstalk にメトリクスを報告します。Elastic Beanstalk は状態エージェントから提供されたメトリクスを使用して、環境内の各インスタンスのヘルスステータスを判断します。さらに、他の要素と組み合わせて、環境全体の状態を判断します。
環境全体の状態は、Elastic Beanstalk によって 60 秒間隔で CloudWatch に公開され、Elastic Beanstalk コンソールの環境の概要ページでリアルタイムで確認できます。状態エージェントによって報告された詳細なメトリクスは、EB CLI の eb health コマンドを使用してリアルタイムで確認できます。
個々のインスタンスおよび環境レベルのメトリクスを 60 秒間隔で CloudWatch に公開することもできます (追加料金が必要です)。CloudWatch に公開されたメトリクスを使用すると、環境マネジメントコンソールでモニタリンググラフを作成できます。
拡張ヘルスレポートで料金が発生するのは、拡張ヘルスレポートのメトリクスを CloudWatch に公開するオプションを選択した場合のみです。拡張ヘルスレポートを使用していて、拡張ヘルスレポートのメトリクスを公開するオプションを選択していなくても、ベーシックヘルスレポートのメトリクスは無料で公開できます。
状態エージェントによって報告されるメトリクスの詳細については、「インスタンスメトリクス」を参照してください。拡張ヘルスメトリクスのメトリクスを CloudWatch に公開する方法の詳細については、「」を参照してください環境の Amazon CloudWatch カスタムメトリクスの発行
インスタンスと環境の状態を判断するための要素
Elastic Beanstalk 拡張ヘルスレポートは、基本的なヘルスレポートのシステムチェック (Elastic Load Balancing のヘルスチェック およびリソースモニタリングなど) に加えて、環境内のインスタンスの状態に関する追加のデータを収集します。これには、オペレーティングシステムのメトリクス、サーバーログ、およびデプロイや更新などの進行中の環境オペレーションの状態が含まれます。Elastic Beanstalk ヘルスレポートサービスは、利用可能なすべてのソースからの情報を組み合わせて分析し、環境全体の状態を判断します。
オペレーションとコマンド
環境内でオペレーション (アプリケーションの新しいバージョンのデプロイなど) を実行する場合、Elastic Beanstalk では、環境のヘルスステータスに影響するいくつかの変更が行われます。
たとえば、複数のインスタンスを実行する環境にアプリケーションの新しいバージョンをデプロイする場合、EB CLI で環境の状態をモニタリングしていると、次のようなメッセージが表示されることがあります。
id status cause
Overall Info Command is executing on 3 out of 5 instances
i-bb65c145 Pending 91 % of CPU is in use. 24 % in I/O wait
Performing application deployment (running for 31 seconds)
i-ba65c144 Pending Performing initialization (running for 12 seconds)
i-f6a2d525 Ok Application deployment completed 23 seconds ago and took 26 seconds
i-e8a2d53b Pending 94 % of CPU is in use. 52 % in I/O wait
Performing application deployment (running for 33 seconds)
i-e81cca40 Okこの例では、環境全体のステータスが Ok であり、このステータスの原因は Command is executing on 3 out of 5 instances です。環境内の 3 つのインスタンスのステータスが Pending であり、オペレーションが進行中であることを示します。
オペレーションが完了すると、Elastic Beanstalk により、オペレーションに関する追加情報が報告されます。たとえば、アプリケーションの新しいバージョンに更新が完了しているインスタンスについては、次の情報が表示されます。
i-f6a2d525 Ok Application deployment completed 23 seconds ago and took 26 secondsインスタンスのヘルスに関する情報には、お客様の環境内の各インスタンスへの最新のデプロイに関する詳細も含まれます。各インスタンスについて、デプロイ ID とステータスがレポートされます。デプロイ ID は整数であり、アプリケーションの新しいバージョンをデプロイするか、環境変数などインスタンス関連の設定オプションの設定を変更するたびに、1 ずつ増えます。デプロイに関する情報を使用して、ローリングデプロイの失敗後にアプリケーションの間違ったバージョンを実行しているインスタンスを特定できます。
Elastic Beanstalk は、原因を示す列に、成功したオペレーションに関する情報メッセージと、複数のヘルスチェックにおけるその他のヘルスステータスを表示しますが、これらは無期限に保存されるわけではありません。環境の異常な状態の原因を示す情報が保存されるのは、環境の状態が正常に戻るまでです。
コマンドタイムアウト
インスタンスが正常な状態に移行できるように、Elastic Beanstalk では、オペレーションが開始した時点からコマンドタイムアウトが適用されます。このコマンドタイムアウトは、環境の更新およびデプロイ設定 (aws:elasticbeanstalk:command 名前空間) で設定されており、デフォルト値は 10 分です。
ローリング更新の実行中、Elastic Beanstalk は、オペレーション内の各バッチに別々のタイムアウトを適用します。このタイムアウトは環境のローリング更新の一部として (aws:autoscaling:updatepolicy:rollingupdate 名前空間で) 設定されます。バッチ内のすべてのインスタンスがローリング更新タイムアウト内で正常に実行されている場合は、オペレーションが次のバッチに進みます。それ以外の場合、オペレーションは失敗となります。
注記
アプリケーションがヘルスチェックで OK ステータスにならなくても、別のレベルで安定する場合は、HealthCheckSuccessThreshold で aws:elasticbeanstalk:command namespace オプションを設定して、Elastic Beanstalk でインスタンスが正常と見なされるレベルに変更できます。
ウェブサーバー環境が正常であると見なされるには、環境内またはバッチ内の各インスタンスが 2 分間にわたって連続して行われる 12 のヘルスチェックに合格する必要があります。ワーカー枠環境の場合は、各インスタンスが 18 のヘルスチェックに合格する必要があります。Elastic Beanstalk は、ヘルスチェックで異常が検出されても、コマンドタイムアウトの前には、環境のヘルスステータスを引き下げません。環境内のインスタンスがコマンドタイムアウト内に正常な状態である場合、オペレーションは成功となります。
HTTP リクエスト
環境で進行中のオペレーションがない場合、インスタンスと環境の状態に関する情報のプライマリソースは、各インスタンスのウェブサーバーログです。インスタンスの状態と環境全体の状態を判断するためには、リクエストの数、各リクエストの結果、各リクエストが解決された速度が考慮されます。
Linux ベースのプラットフォームでは、Elastic Beanstalk はウェブサーバーのログを読み取り、解析して HTTP リクエストに関する情報を取得します。Windows Server プラットフォームでは、Elastic Beanstalk はこの情報を IIS ウェブサーバーから直接受け取ります。
環境にはアクティブなウェブサーバーがない可能性があります。たとえば、複数コンテナ Docker プラットフォームにはウェブサーバーは含まれません。その他のプラットフォームにはウェブサーバーがあり、アプリケーションがこれを無効にする可能性があります。このような場合、環境では、ヘルス情報を Elastic Beanstalk サービスに中継するために必要な形式のログを Elastic Beanstalk ヘルスエージェントに提供するための、追加の設定が必要です。詳細については、「拡張ヘルスログ形式」を参照してください。
オペレーティングシステムのメトリクス
Elastic Beanstalk は、状態エージェントから報告されたオペレーティング システムのメトリクスを監視し、継続的にシステムリソースが不足しているインスタンスを特定します。
状態エージェントによって報告されるメトリクスの詳細については、「インスタンスメトリクス」を参照してください。
ヘルスチェックルールのカスタマイズ
Elastic Beanstalk 拡張ヘルスレポートは、環境のヘルスを判断するための一連のルールに依存しています。これらのルールの一部は、特定のアプリケーションに適していない場合があります。よくあるケースは、仕様により頻繁に HTTP 4xx エラーを返すアプリケーションです。Elastic Beanstalk は、デフォルトのルールの 1 つを使用して、何かが間違っていると判断すると、エラーレートに応じて、環境のヘルスステータスを、OK から警告、パフォーマンス低下、または重大へと変化させます。このケースを正しく処理するために、Elastic Beanstalk ではこのルールを正しく設定して、アプリケーション HTTP 4xx エラーを無視するように設定できます。詳細については、「環境の拡張ヘルスルールの設定」を参照してください。
拡張ヘルスレポートのロール
拡張ヘルスレポートには、2 つのロールが必要です。Elastic Beanstalk 用のサービスロールと、環境用のインスタンスプロファイルです。サービスロールにより、Elastic Beanstalk はユーザーの代わりに他の AWS のサービスと対話して、環境内のリソースに関する情報を収集できます。インスタンスプロファイルを使用すると、環境内のインスタンスがログを Amazon S3 に書き込んだり、拡張ヘルス情報を Elastic Beanstalk サービスに伝達したりできます。
Elastic Beanstalk コンソールまたは EB CLI を使用して Elastic Beanstalk 環境を作成すると、Elastic Beanstalk はデフォルトのサービスロールを作成し、必要な管理ポリシーを環境のデフォルトのインスタンスプロファイルにアタッチします。
API、SDK、または AWS CLI を使用して環境を作成する場合に、拡張ヘルスを使用するには、これらのロールをあらかじめ作成してから、環境の作成中に指定する必要があります。環境に適切なロールを作成する方法については、「」を参照してくださいサービスロール、インスタンスプロファイル、ユーザーポリシー
インスタンスプロファイルとサービスロールには管理ポリシーを使用することをお勧めします。管理ポリシーは、Elastic Beanstalk が維持する AWS Identity and Access Management (IAM) ポリシーです。管理ポリシーを使用すると、環境が適切に機能するために必要なすべてのアクセス許可を持つことが保証されます。
インスタンスプロファイルでは、ウェブサーバー層またはワーカー層環境に対して、AWSElasticBeanstalkWebTier または AWSElasticBeanstalkWorkerTier 管理ポリシーをそれぞれ使用できます。これら 2 つのマネージドインスタンスプロファイルポリシーの詳細については、「Elastic Beanstalk インスタンスプロファイルの管理」を参照してください。
拡張ヘルス認証
Elastic Beanstalk インスタンスプロファイルマネージドポリシーには、elasticbeanstalk:PutInstanceStatistics アクションに対するアクセス許可が含まれています。このアクションは Elastic Beanstalk API の一部ではありません。これは、環境インスタンスが拡張ヘルス情報を Elastic Beanstalk サービスに伝達するために内部的に使用する別の API の一部です。この API を直接呼び出すことはありません。
新しい環境を作成すると、elasticbeanstalk:PutInstanceStatistics アクションに対する認証がデフォルトで有効になっています。環境のセキュリティを強化し、ユーザーに代わってヘルスデータのスプーフィングを防ぐために、このアクションに対する認可を有効にしておくことをお勧めします。インスタンスプロファイルでマネージドポリシーを使用する場合、この機能は追加設定なしで新しい環境で使用できます。管理ポリシーの代わりにカスタムインスタンスプロファイルを使用すると、環境に [No Data] (データがありません) のヘルスステータスが表示されることがあります。これは、インスタンスで拡張ヘルスデータをサービスに伝達するアクションが許可されていないために発生します。
アクションを認証するには、インスタンスプロファイルに次のステートメントを含めます。
{ "Sid": "ElasticBeanstalkHealthAccess", "Action": [ "elasticbeanstalk:PutInstanceStatistics" ], "Effect": "Allow", "Resource": [ "arn:aws:elasticbeanstalk:*:*:application/*", "arn:aws:elasticbeanstalk:*:*:environment/*" ] }
現時点では拡張ヘルス認証を使用しない場合は、aws:elasticbeanstalk:healthreporting:system 名前空間の EnhancedHealthAuthEnabled オプションを false に設定して無効にします。このオプションが無効になっている場合、前述のアクセス許可は必要ありません。アプリケーションと環境への最小特権アクセスのために、これらをインスタンスプロファイルから削除できます。
注記
以前の EnhancedHealthAuthEnabled のデフォルト設定は false であったため、elasticbeanstalk:PutInstanceStatistics アクションに対する認可でもデフォルトでは無効となっています。既存の環境でこのアクションを有効にするには、aws:elasticbeanstalk:healthreporting:system 名前空間の EnhancedHealthAuthEnabled オプションを true に設定します。このオプションは、設定ファイルのオプション設定を使用して設定できます。
拡張ヘルスレポートのイベント
拡張ヘルスレポートのシステムでは、環境の状態が変化するとイベントが生成されます。次の例は、環境の状態が Info、OK、Severe の間で変化した場合に出力されたイベントを示しています。
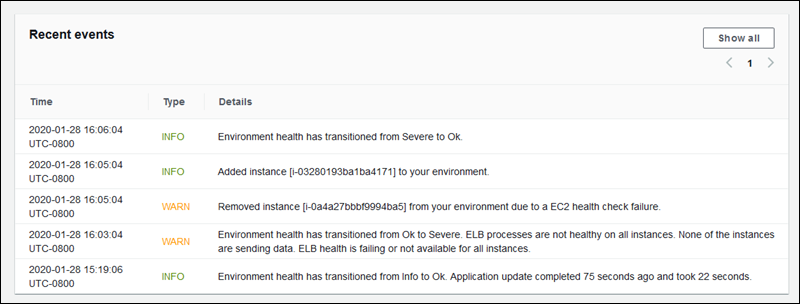
現在より悪い状態に変化した場合は、変化の原因を示すメッセージが拡張ヘルスイベントに含められます。
インスタンスレベルでのステータスの変化がすべて Elastic Beanstalk によるイベントの出力になるわけではありません。Elastic Beanstalk では、誤ったアラームを回避するために、複数のチェックで同じ問題が生じている場合のみ、状態に関連したイベントを出力します。
ステータス、色、原因など、環境レベルのリアルタイムの状態情報は、Elastic Beanstalk コンソールの環境の概要ページおよび EB CLI から利用できます。EB CLI を環境にアタッチして eb health コマンドを実行すると、環境内のインスタンスに関するリアルタイムのステータスを表示することもできます。
更新、デプロイ、およびスケーリング中の拡張ヘルスレポートの動作
拡張ヘルスレポートを有効にすると、設定更新中およびデプロイ中の環境の動作に影響が及ぶ可能性があります。Elastic Beanstalk は、すべてのインスタンスが一貫してヘルスチェックに合格するまで、更新のバッチを完了しません。また、拡張ヘルスレポートはより高い標準をヘルスに適用し、より多くの要素をモニタリングするため、基本ヘルスレポートの ELB ヘルスチェックに合格したインスタンスが、必ずしも拡張ヘルスレポートに合格するとは限りません。ヘルスチェックがアップデート処理にどのように影響するかについては、ローリング設定更新およびローリングデプロイのトピックを参照してください。
拡張ヘルスレポートは、Elastic Load Balancing のヘルスチェック URL を適切に設定する必要があることについても指摘します。要求に対応するために環境がスケールアップすると、新しいインスタンスは、十分な数の ELB ヘルスチェックに合格するとすぐにリクエストの受け取りを開始します。ヘルスチェック URL が設定されていなければ、新しいインスタンスが TCP 接続を受け付けてからわずか 20 秒で開始することがあります。
ロードバランサーによってアプリケーションが正常であり、トラフィックを受け取っても問題がないと宣言されるまでにアプリケーションの起動が終了していない場合、大量のリクエストが失敗し、環境がヘルスチェックに合格しなくなります。アプリケーションによって処理されるパスをヒットするヘルスチェック URL が、この問題を防止できます。ヘルスチェック URL への GET リクエストが 200 ステータスコードを返すまで、ELB ヘルスチェックに合格しません。
