Best practices for Amazon RDS
Learn best practices for working with Amazon RDS. As new best practices are identified, we will keep this section up to date.
Note
For common recommendations for Amazon RDS, see Recommendations from Amazon RDS.
Amazon RDS basic operational guidelines
The following are basic operational guidelines that everyone should follow when working with Amazon RDS. Note that the Amazon RDS Service Level Agreement requires that you follow these guidelines:
-
Use metrics to monitor your memory, CPU, replica lag, and storage usage. You can set up Amazon CloudWatch to notify you when the usage patterns change or when your deployment approaches capacity limits. This allows you to maintain system performance and availability.
-
Scale up your DB instance when you are approaching storage capacity limits. You should have some buffer in storage and memory to accommodate unforeseen increases in demand from your applications.
-
Enable automatic backups and set the backup window to occur during the daily low in write IOPS. That's when a backup is least disruptive to your database usage.
-
If your database workload requires more I/O than you have provisioned, recovery after a failover or database failure will be slow. To increase the I/O capacity of a DB instance, do any or all of the following:
Migrate to a different DB instance class with high I/O capacity.
Convert from General Purpose SSD to Provisioned IOPS SSD storage, depending on how much of an increase you need. For information on available storage types, see Amazon RDS storage types.
If you convert to Provisioned IOPS storage, make sure you also use a DB instance class that is optimized for Provisioned IOPS. For information on Provisioned IOPS, see Provisioned IOPS SSD storage.
If you are already using Provisioned IOPS storage, provision additional throughput capacity.
-
If your client application is caching the Domain Name Service (DNS) data of your DB instances, set a time-to-live (TTL) value of less than 30 seconds. The underlying IP address of a DB instance can change after a failover. Caching the DNS data for an extended time can thus lead to connection failures. Your application might try to connect to an IP address that's no longer in service.
-
Test failover for your DB instance to understand how long the process takes for your particular use case. Also test failover to ensure that the application that accesses your DB instance can automatically connect to the new DB instance after failover occurs.
DB instance RAM recommendations
An Amazon RDS performance best practice is to allocate enough RAM so that your working set resides almost completely in memory. The working set is the data and indexes that are frequently in use on your instance. The more you use the DB instance, the more the working set will grow.
To tell if your working set is almost all in memory, check the ReadIOPS metric (using Amazon CloudWatch) while the DB instance is under load. The value of ReadIOPS should be small and stable. In some cases, scaling up the DB instance class to a class with more RAM results in a dramatic drop in ReadIOPS. In these cases, your working set was not almost completely in memory. Continue to scale up until ReadIOPS no longer drops dramatically after a scaling operation, or ReadIOPS is reduced to a very small amount. For information on monitoring a DB instance's metrics, see Viewing metrics in the Amazon RDS console.
Keeping database engine versions up to date
Regularly upgrade your database engine version to maintain security, performance, and compliance. Amazon RDS releases new minor and major versions that include security patches, performance enhancements, and new features. Running an outdated database engine can expose your workloads to known vulnerabilities, compatibility issues, and reduced support from AWS and database vendors.
To minimize disruption, consider the following when you plan upgrades:
-
Test in a staging environment – Validate the new version against your workload before you upgrade production databases.
-
Use Amazon RDS managed upgrades – Enable automatic minor version upgrades for easier patching.
-
Schedule major version upgrades – Review release notes, test application compatibility, and plan a controlled upgrade window.
Regular upgrades help ensure your database remains secure, optimized, and aligned with AWS best practices.
AWS database drivers
We recommend the AWS suite of drivers for application connectivity. The drivers have been designed to provide support for faster switchover and failover times, and authentication with AWS Secrets Manager, AWS Identity and Access Management (IAM), and Federated Identity. The AWS drivers rely on monitoring DB instance status and being aware of the instance topology to determine the new writer. This approach reduces switchover and failover times to single-digit seconds, compared to tens of seconds for open-source drivers.
As new service features are introduced, the goal of the AWS suite of drivers is to have built-in support for these service features.
For more information, see Connecting to DB instances with the AWS drivers.
Using Enhanced Monitoring to identify operating system issues
When Enhanced Monitoring is enabled, Amazon RDS provides metrics in real time for the operating system (OS) that your DB instance runs on. You can view the metrics for your DB instance using the console. You can also consume the Enhanced Monitoring JSON output from Amazon CloudWatch Logs in a monitoring system of your choice. For more information about Enhanced Monitoring, see Monitoring OS metrics with Enhanced Monitoring.
Using metrics to identify performance issues
To identify performance issues caused by insufficient resources and other common bottlenecks, you can monitor the metrics available for your Amazon RDS DB instance.
Viewing performance metrics
You should monitor performance metrics on a regular basis to see the average, maximum, and minimum values for a variety of time ranges. If you do so, you can identify when performance is degraded. You can also set Amazon CloudWatch alarms for particular metric thresholds so you are alerted if they are reached.
To troubleshoot performance issues, it's important to understand the baseline performance of the system. When you set up a DB instance and run it with a typical workload, capture the average, maximum, and minimum values of all performance metrics. Do so at a number of different intervals (for example, one hour, 24 hours, one week, two weeks). This can give you an idea of what is normal. It helps to get comparisons for both peak and off-peak hours of operation. You can then use this information to identify when performance is dropping below standard levels.
If you use Multi-AZ DB clusters, monitor the time difference between the latest transaction on the writer DB instance and the latest applied transaction on a reader DB instance. This difference is called replica lag. For more information, see Replica lag and Multi-AZ DB clusters.
You can view the combined Performance Insights and CloudWatch metrics in the Performance Insights dashboard and monitor your DB instance. To use this monitoring view, Performance Insights must be turned on for your DB instance. For information about this monitoring view, see Viewing combined metrics with the Performance Insights dashboard.
You can create a performance analysis report for a specific time period and view the insights identified and the recommendations to resolve the issues. For more information see, Creating a performance analysis report in Performance Insights.
To view performance metrics
Sign in to the AWS Management Console and open the Amazon RDS console at https://console.aws.amazon.com/rds/
. In the navigation pane, choose Databases, and then choose a DB instance.
Choose Monitoring.
The dashboard provides the performance metrics. The metrics default to show the information for the last three hours.
Use the pagination buttons to page through the additional metrics, or adjust the settings to see more metrics.
Choose a performance metric to adjust the time range in order to see data for other than the current day. You can change the Statistic, Time Range, and Period values to adjust the information displayed. For example, you might want to see the peak values for a metric for each day of the last two weeks. If so, set Statistic to Maximum, Time Range to Last 2 Weeks, and Period to Day.
You can also view performance metrics using the CLI or API. For more information, see Viewing metrics in the Amazon RDS console.
To set a CloudWatch alarm
-
Sign in to the AWS Management Console and open the Amazon RDS console at https://console.aws.amazon.com/rds/
. -
In the navigation pane, choose Databases, and then choose a DB instance.
-
Choose Logs & events.
-
In the CloudWatch alarms section, choose Create alarm.
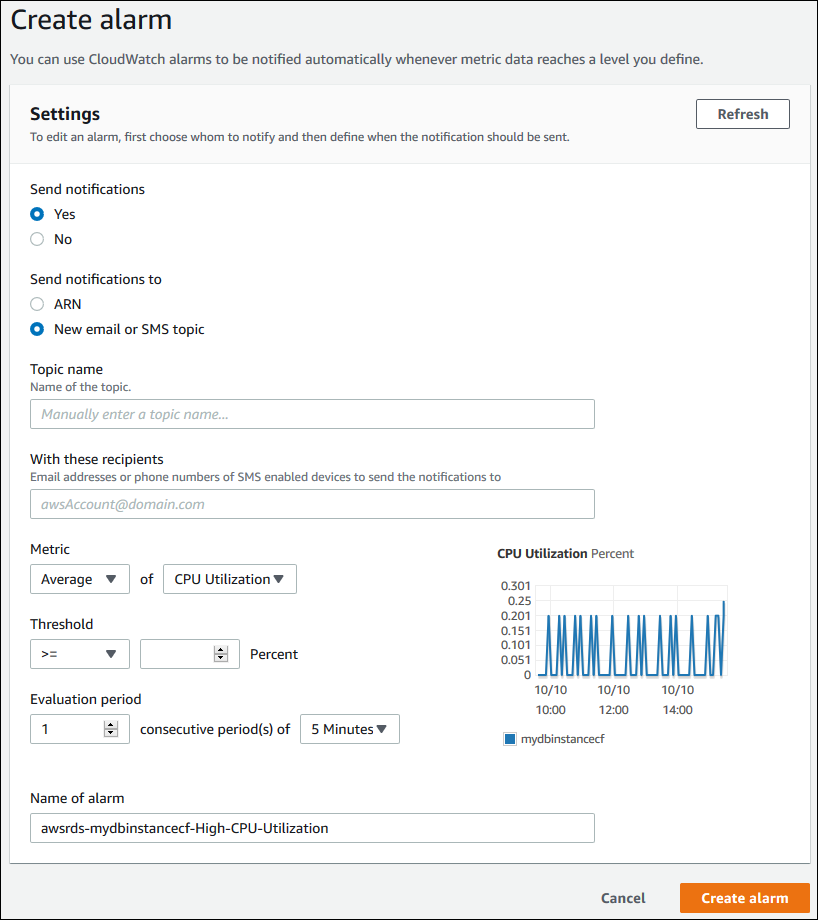
-
For Send notifications, choose Yes, and for Send notifications to, choose New email or SMS topic.
-
For Topic name, enter a name for the notification, and for With these recipients, enter a comma-separated list of email addresses and phone numbers.
-
For Metric, choose the alarm statistic and metric to set.
-
For Threshold, specify whether the metric must be greater than, less than, or equal to the threshold, and specify the threshold value.
-
For Evaluation period, choose the evaluation period for the alarm. For consecutive period(s) of, choose the period during which the threshold must have been reached in order to trigger the alarm.
-
For Name of alarm, enter a name for the alarm.
-
Choose Create Alarm.
The alarm appears in the CloudWatch alarms section.
Evaluating performance metrics
A DB instance has a number of different categories of metrics, and how to determine acceptable values depends on the metric.
CPU
CPU Utilization – Percentage of computer processing capacity used.
Memory
-
Freeable Memory – How much RAM is available on the DB instance, in bytes. The red line in the Monitoring tab metrics is marked at 75% for CPU, Memory and Storage Metrics. If instance memory consumption frequently crosses that line, then this indicates that you should check your workload or upgrade your instance.
Swap Usage – How much swap space is used by the DB instance, in bytes.
Disk space
Free Storage Space – How much disk space is not currently being used by the DB instance, in megabytes.
Input/output operations
Read IOPS, Write IOPS – The average number of disk read or write operations per second.
Read Latency, Write Latency – The average time for a read or write operation in milliseconds.
Read Throughput, Write Throughput – The average number of megabytes read from or written to disk per second.
Queue Depth – The number of I/O operations that are waiting to be written to or read from disk.
Network traffic
Network Receive Throughput, Network Transmit Throughput – The rate of network traffic to and from the DB instance in bytes per second.
Database connections
DB Connections – The number of client sessions that are connected to the DB instance.
For more detailed individual descriptions of the performance metrics available, see Monitoring Amazon RDS metrics with Amazon CloudWatch.
Generally speaking, acceptable values for performance metrics depend on what your baseline looks like and what your application is doing. Investigate consistent or trending variances from your baseline. Advice about specific types of metrics follows:
High CPU or RAM consumption – High values for CPU or RAM consumption might be appropriate. For example, they might be so if they are in keeping with your goals for your application (like throughput or concurrency) and are expected.
Disk space consumption – Investigate disk space consumption if space used is consistently at or above 85 percent of the total disk space. See if it is possible to delete data from the instance or archive data to a different system to free up space.
Network traffic – For network traffic, talk with your system administrator to understand what expected throughput is for your domain network and internet connection. Investigate network traffic if throughput is consistently lower than expected.
Database connections – Consider constraining database connections if you see high numbers of user connections in conjunction with decreases in instance performance and response time. The best number of user connections for your DB instance will vary based on your instance class and the complexity of the operations being performed. To determine the number of database connections, associate your DB instance with a parameter group. In this group, set the User Connections parameter to other than 0 (unlimited). You can either use an existing parameter group or create a new one. For more information, see Parameter groups for Amazon RDS.
IOPS metrics – The expected values for IOPS metrics depend on disk specification and server configuration, so use your baseline to know what is typical. Investigate if values are consistently different than your baseline. For best IOPS performance, make sure your typical working set will fit into memory to minimize read and write operations.
For issues with performance metrics, a first step to improve performance is to tune the most used and most expensive queries. Tune them to see if doing so lowers the pressure on system resources. For more information, see Tuning queries.
If your queries are tuned and an issue persists, consider upgrading your Amazon RDS DB instance classes. You might upgrade it to one with more of the resource (CPU, RAM, disk space, network bandwidth, I/O capacity) that is related to the issue.
Tuning queries
One of the best ways to improve DB instance performance is to tune your most commonly used and most resource-intensive queries. Here, you tune them to make them less expensive to run. For information on improving queries, use the following resources:
-
MySQL – See Optimizing SELECT statements
in the MySQL documentation. For additional query tuning resources, see MySQL performance tuning and optimization resources . -
Oracle – See Database SQL Tuning Guide
in the Oracle Database documentation. -
SQL Server – See Analyzing a query
in the Microsoft documentation. You can also use the execution-, index-, and I/O-related data management views (DMVs) described in System Dynamic Management Views in the Microsoft documentation to troubleshoot SQL Server query issues. A common aspect of query tuning is creating effective indexes. For potential index improvements for your DB instance, see Database Engine Tuning Advisor
in the Microsoft documentation. For information on using Tuning Advisor on RDS for SQL Server, see Analyzing your database workload on an Amazon RDS for SQL Server DB instance with Database Engine Tuning Advisor. -
PostgreSQL – See Using EXPLAIN
in the PostgreSQL documentation to learn how to analyze a query plan. You can use this information to modify a query or underlying tables in order to improve query performance. For information about how to specify joins in your query for the best performance, see Controlling the planner with explicit JOIN clauses
. -
MariaDB – See Query optimizations
in the MariaDB documentation.
Best practices for working with MySQL
Both table sizes and number of tables in a MySQL database can affect performance.
Table size
Typically, operating system constraints on file sizes determine the effective maximum table size for MySQL databases. So, the limits usually aren't determined by internal MySQL constraints.
On a MySQL DB instance, avoid tables in your database growing too large. Although the general storage limit is 64 TiB, provisioned storage limits restrict the maximum size of a MySQL table file to 16 TiB. Partition your large tables so that file sizes are well under the 16 TiB limit. This approach can also improve performance and recovery time. For more information, see MySQL file size limits in Amazon RDS.
Very large tables (greater than 100 GB in size) can negatively affect performance for both reads and writes (including DML statements and
especially DDL statements). Indexes on larges tables can significantly improve select performance, but they can also degrade the performance
of DML statements. DDL statements, such as ALTER TABLE, can be significantly slower for the large tables
because those operations might completely rebuild a table in some cases. These DDL statements might lock the tables for the duration
of the operation.
The amount of memory required by MySQL for reads and writes depends on the tables involved in the operations. It is a best practice to have at least enough RAM to the hold the indexes of actively used tables. To find the ten largest tables and indexes in a database, use the following query:
select table_schema, TABLE_NAME, dat, idx from (SELECT table_schema, TABLE_NAME, ( data_length ) / 1024 / 1024 as dat, ( index_length ) / 1024 / 1024 as idx FROM information_schema.TABLES order by 3 desc ) a order by 3 desc limit 10;
Number of tables
Your underlying file system might have a limit on the number of files that represent tables. However, MySQL has no limit on the number of tables. Despite this, the total number of tables in the MySQL InnoDB storage engine can contribute to the performance degradation, regardless of the size of those tables. To limit the operating system impact, you can split the tables across multiple databases in the same MySQL DB instance. Doing so might limit the number of files in a directory but won't solve the overall problem.
When there is performance degradation because of a large number of tables (more than 10 thousand), it is caused by MySQL working with storage
files, including opening and closing them. To address this issue, you can increase the size of the table_open_cache and
table_definition_cache parameters. However, increasing the values of those parameters might significantly increase the amount of
memory MySQL uses, and might even use all of the available memory. For more information, see
How MySQL Opens and Closes Tables
In addition, too many tables can significantly affect MySQL startup time. Both a clean shutdown and restart and a crash recovery can be affected, especially in versions prior to MySQL 8.0.
We recommend having fewer than 10,000 tables total across all of the databases in
a DB instance. For a use case with a large number of tables in a MySQL database, see
One
Million Tables in MySQL 8.0
Storage engine
The point-in-time restore and snapshot restore features of Amazon RDS for MySQL require a crash-recoverable storage engine. These features are supported for the InnoDB storage engine only. Although MySQL supports multiple storage engines with varying capabilities, not all of them are optimized for crash recovery and data durability. For example, the MyISAM storage engine doesn't support reliable crash recovery and might prevent a point-in-time restore or snapshot restore from working as intended. This might result in lost or corrupt data when MySQL is restarted after a crash.
InnoDB is the recommended and supported storage engine for MySQL DB instances on Amazon RDS. InnoDB instances can also be migrated to Aurora, while MyISAM instances can't be migrated. However, MyISAM performs better than InnoDB if you require intense, full-text search capability. If you still choose to use MyISAM with Amazon RDS, following the steps outlined in Automated backups with unsupported MySQL storage engines can be helpful in certain scenarios for snapshot restore functionality.
If you want to convert existing MyISAM tables to InnoDB tables, you can use the
process outlined in Converting Tables from MyISAM to InnoDB
In addition, Federated Storage Engine is currently not supported by Amazon RDS for MySQL.
Best practices for working with MariaDB
Both table sizes and number of tables in a MariaDB database can affect performance.
Table size
Typically, operating system constraints on file sizes determine the effective maximum table size for MariaDB databases. So, the limits usually aren't determined by internal MariaDB constraints.
On a MariaDB DB instance, avoid tables in your database growing too large. Although the general storage limit is 64 TiB, provisioned storage limits restrict the maximum size of a MariaDB table file to 16 TiB. Partition your large tables so that file sizes are well under the 16 TiB limit. This approach can also improve performance and recovery time.
Very large tables (greater than 100 GB in size) can negatively affect performance for both reads and writes (including DML statements and
especially DDL statements). Indexes on larges tables can significantly improve select performance, but they can also degrade the performance
of DML statements. DDL statements, such as ALTER TABLE, can be significantly slower for the large tables
because those operations might completely rebuild a table in some cases. These DDL statements might lock the tables for the duration
of the operation.
The amount of memory required by MariaDB for reads and writes depends on the tables involved in the operations. It is a best practice to have at least enough RAM to the hold the indexes of actively used tables. To find the ten largest tables and indexes in a database, use the following query:
select table_schema, TABLE_NAME, dat, idx from (SELECT table_schema, TABLE_NAME, ( data_length ) / 1024 / 1024 as dat, ( index_length ) / 1024 / 1024 as idx FROM information_schema.TABLES order by 3 desc ) a order by 3 desc limit 10;
Number of tables
Your underlying file system might have a limit on the number of files that represent tables. However, MariaDB has no limit on the number of tables. Despite this, the total number of tables in the MariaDB InnoDB storage engine can contribute to the performance degradation, regardless of the size of those tables. To limit the operating system impact, you can split the tables across multiple databases in the same MariaDB DB instance. Doing so might limit the number of files in a directory but doesn’t solve the overall problem.
When there is performance degradation because of a large number of tables (more
than 10,000), it's caused by MariaDB working with storage files. This work includes
MariaDB opening and closing storage files. To address this issue, you can increase
the size of the table_open_cache and
table_definition_cache parameters. However, increasing the values
of those parameters might significantly increase the amount of memory MariaDB uses.
It might even use all of the available memory. For more information, see Optimizing
table_open_cache
In addition, too many tables can significantly affect MariaDB startup time. Both a clean shutdown and restart and a crash recovery can be affected. We recommend having fewer than ten thousand tables total across all of the databases in a DB instance.
Storage engine
The point-in-time restore and snapshot restore features of Amazon RDS for MariaDB require a crash-recoverable storage engine. Although MariaDB supports multiple storage engines with varying capabilities, not all of them are optimized for crash recovery and data durability. For example, although Aria is a crash-safe replacement for MyISAM, it might still prevent a point-in-time restore or snapshot restore from working as intended. This might result in lost or corrupt data when MariaDB is restarted after a crash. InnoDB is the recommended and supported storage engine for MariaDB DB instances on Amazon RDS. If you still choose to use Aria with Amazon RDS, following the steps outlined in Automated backups with unsupported MariaDB storage engines can be helpful in certain scenarios for snapshot restore functionality.
If you want to convert existing MyISAM tables to InnoDB tables, you can use the
process outlined in Converting Tables from MyISAM to InnoDB
Best practices for working with Oracle
For information about best practices for working with Amazon RDS for Oracle, see Best practices for running Oracle database on Amazon Web Services.
A 2020 AWS virtual workshop included a presentation on running production Oracle databases on Amazon RDS. A video of the presentation is available here:
Best practices for working with PostgreSQL
Of two important areas where you can improve performance with RDS for PostgreSQL, one is when loading data into a DB instance. Another is when using the PostgreSQL autovacuum feature. The following sections cover some of the practices we recommend for these areas.
For information on how Amazon RDS implements other common PostgreSQL DBA tasks, see Common DBA tasks for Amazon RDS for PostgreSQL.
Loading data into a PostgreSQL DB instance
When loading data into an Amazon RDS for PostgreSQL DB instance, modify your DB instance settings and your DB parameter group values. Set these to allow for the most efficient importing of data into your DB instance.
Modify your DB instance settings to the following:
-
Disable DB instance backups (set backup_retention to 0)
-
Disable Multi-AZ
Modify your DB parameter group to include the following settings. Also, test the parameter settings to find the most efficient settings for your DB instance.
-
Increase the value of the
maintenance_work_memparameter. For more information about PostgreSQL resource consumption parameters, see the PostgreSQL documentation. -
Increase the value of the
max_wal_sizeandcheckpoint_timeoutparameters to reduce the number of writes to the write-ahead log (WAL) log. -
Disable the
synchronous_commitparameter. -
Disable the PostgreSQL autovacuum parameter.
-
Make sure that none of the tables you're importing are unlogged. Data stored in unlogged tables can be lost during a failover. For more information, see CREATE TABLE UNLOGGED
.
Use the pg_dump -Fc (compressed) or pg_restore -j
(parallel) commands with these settings.
After the load operation completes, return your DB instance and DB parameters to their normal settings.
Working with the PostgreSQL autovacuum feature
The autovacuum feature for PostgreSQL databases is a feature that we strongly recommend you use to maintain the health of your PostgreSQL DB instance. Autovacuum automates the execution of the VACUUM and ANALYZE command Using autovacuum is required by PostgreSQL, not imposed by Amazon RDS, and its use is critical to good performance. The feature is enabled by default for all new Amazon RDS for PostgreSQL DB instances, and the related configuration parameters are appropriately set by default.
Your database administrator needs to know and understand this maintenance operation. For the PostgreSQL documentation on
autovacuum, see The Autovacuum Daemon
Autovacuum is not a "resource free" operation, but it works in the background and
yields to user operations as much as possible. When enabled, autovacuum checks for
tables that have had a large number of updated or deleted tuples. It also protects
against loss of very old data due to transaction ID wraparound. For more information,
see Preventing transaction ID wraparound failures
Autovacuum should not be thought of as a high-overhead operation that can be reduced to gain better performance. On the contrary, tables that have a high velocity of updates and deletes will quickly deteriorate over time if autovacuum is not run.
Important
Not running autovacuum can result in an eventual required outage to perform a much more intrusive vacuum operation. In some cases, an RDS for PostgreSQL DB instance might become unavailable because of an over-conservative use of autovacuum. In these cases, the PostgreSQL database shuts down to protect itself. At that point, Amazon RDS must perform a single-user-mode full vacuum directly on the DB instance. This full vacuum can result in a multi-hour outage. Thus, we strongly recommend that you do not turn off autovacuum, which is turned on by default.
The autovacuum parameters determine when and how hard autovacuum works. Theautovacuum_vacuum_threshold and
autovacuum_vacuum_scale_factor parameters determine when autovacuum is run. The autovacuum_max_workers, autovacuum_nap_time,
autovacuum_cost_limit, and autovacuum_cost_delay parameters determine how hard autovacuum works. For more information about
autovacuum, when it runs, and what parameters are required, see Routine Vacuuming
The following query shows the number of "dead" tuples in a table named table1:
SELECT relname, n_dead_tup, last_vacuum, last_autovacuum FROM pg_catalog.pg_stat_all_tables WHERE n_dead_tup > 0 and relname = 'table1';
The results of the query will resemble the following:
relname | n_dead_tup | last_vacuum | last_autovacuum ---------+------------+-------------+----------------- tasks | 81430522 | | (1 row)
Amazon RDS for PostgreSQL best practices video
The 2020 AWS re:Invent conference included a presentation on new features and best practices for working with PostgreSQL on Amazon RDS. A video of the presentation is available here:
Best practices for working with SQL Server
Best practices for a Multi-AZ deployment with a SQL Server DB instance include the following:
Use Amazon RDS DB events to monitor failovers. For example, you can be notified by text message or email when a DB instance fails over. For more information about Amazon RDS events, see Working with Amazon RDS event notification.
If your application caches DNS values, set time to live (TTL) to less than 30 seconds. Setting TTL as so is a good practice in case there is a failover. In a failover, the IP address might change and the cached value might no longer be in service.
We recommend that you do not enable the following modes because they turn off transaction logging, which is required for Multi-AZ:
-
Simple recover mode
-
Offline mode
-
Read-only mode
-
Test to determine how long it takes for your DB instance to failover. Failover time can vary due to the type of database, the instance class, and the storage type you use. You should also test your application's ability to continue working if a failover occurs.
To shorten failover time, do the following:
Ensure that you have sufficient Provisioned IOPS allocated for your workload. Inadequate I/O can lengthen failover times. Database recovery requires I/O.
Use smaller transactions. Database recovery relies on transactions, so if you can break up large transactions into multiple smaller transactions, your failover time should be shorter.
Take into consideration that during a failover, there will be elevated latencies. As part of the failover process, Amazon RDS automatically replicates your data to a new standby instance. This replication means that new data is being committed to two different DB instances. So there might be some latency until the standby DB instance has caught up to the new primary DB instance.
Deploy your applications in all Availability Zones. If an Availability Zone does go down, your applications in the other Availability Zones will still be available.
When working with a Multi-AZ deployment of SQL Server, remember that Amazon RDS creates replicas for all SQL Server databases on your instance. If you don't want specific databases to have secondary replicas, set up a separate DB instance that doesn't use Multi-AZ for those databases.
Amazon RDS for SQL Server best practices video
The 2019 AWS re:Invent conference included a presentation on new features and best practices for working with SQL Server on Amazon RDS. A video of the presentation is available here:
Working with DB parameter groups
We recommend that you try out DB parameter group changes on a test DB instance before applying parameter group changes to your production DB instances. Improperly setting DB engine parameters in a DB parameter group can have unintended adverse effects, including degraded performance and system instability. Always exercise caution when modifying DB engine parameters and back up your DB instance before modifying a DB parameter group.
For information about backing up your DB instance, see Backing up, restoring, and exporting data.
Best practices for automating DB instance creation
It’s an Amazon RDS best practice to create a DB instance with the preferred minor version
of the database engine. You can use the AWS CLI, Amazon RDS API, or AWS CloudFormation to automate DB
instance creation. When you use these methods, you can specify only the major version
and Amazon RDS automatically creates the instance with the preferred minor version. For
example, if PostgreSQL 12.5 is the preferred minor version, and if you specify version
12 with create-db-instance, the DB instance will be version 12.5.
To determine the preferred minor version, you can run the
describe-db-engine-versions command with the
--default-only option as shown in the following example.
aws rds describe-db-engine-versions --default-only --engine postgres { "DBEngineVersions": [ { "Engine": "postgres", "EngineVersion": "12.5", "DBParameterGroupFamily": "postgres12", "DBEngineDescription": "PostgreSQL", "DBEngineVersionDescription": "PostgreSQL 12.5-R1", ...some output truncated... } ] }
For information on creating DB instances programmatically, see the following resources:
Using the AWS CLI – create-db-instance
Using the Amazon RDS API – CreateDBInstance
Using AWS CloudFormation – AWS::RDS::DBInstance
Amazon RDS new features video
The 2023 AWS re:Invent conference included a presentation on new Amazon RDS features. A video of the presentation is available here:
