Die vorliegende Übersetzung wurde maschinell erstellt. Im Falle eines Konflikts oder eines Widerspruchs zwischen dieser übersetzten Fassung und der englischen Fassung (einschließlich infolge von Verzögerungen bei der Übersetzung) ist die englische Fassung maßgeblich.
Entwickeln Sie mithilfe von Amazon Bedrock-Agenten und Wissensdatenbanken einen vollautomatischen Chat-basierten Assistenten
Jundong Qiao, Shuai Cao, Noah Hamilton, Kiowa Jackson, Praveen Kumar Jeyarajan und Kara Yang, Amazon Web Services
Übersicht
Viele Unternehmen stehen vor Herausforderungen, wenn es darum geht, einen chatbasierten Assistenten zu entwickeln, der in der Lage ist, verschiedene Datenquellen zu orchestrieren, um umfassende Antworten zu bieten. Dieses Muster bietet eine Lösung für die Entwicklung eines Chat-basierten Assistenten, der Anfragen sowohl aus der Dokumentation als auch aus Datenbanken beantworten kann, und das bei einer einfachen Bereitstellung.
Beginnend mit Amazon Bedrock bietet dieser vollständig verwaltete Service für generative künstliche Intelligenz (KI) eine breite Palette fortschrittlicher Basismodelle (FMs). Dies erleichtert die effiziente Erstellung generativer KI-Anwendungen mit einem starken Fokus auf Datenschutz und Sicherheit. Im Zusammenhang mit dem Abruf von Dokumenten ist die Retrieval Augmented Generation (RAG) ein zentrales Merkmal. Es verwendet Wissensdatenbanken, um FM-Eingabeaufforderungen um kontextrelevante Informationen aus externen Quellen zu erweitern. Ein Amazon OpenSearch Serverless-Index dient als Vektordatenbank hinter den Wissensdatenbanken für Amazon Bedrock. Diese Integration wird durch sorgfältiges, zeitnahes Engineering verbessert, um Ungenauigkeiten zu minimieren und sicherzustellen, dass die Antworten in einer sachlichen Dokumentation verankert sind. Für Datenbankabfragen transformieren Amazon Bedrock Textanfragen in strukturierte SQL-Abfragen, die spezifische Parameter enthalten. FMs Dies ermöglicht den präzisen Abruf von Daten aus Datenbanken, die von AWS Glue Glue-Datenbanken verwaltet werden. Amazon Athena wird für diese Abfragen verwendet.
Um kompliziertere Anfragen zu bearbeiten und umfassende Antworten zu erhalten, sind Informationen erforderlich, die sowohl aus der Dokumentation als auch aus Datenbanken stammen. Agents for Amazon Bedrock ist eine generative KI-Funktion, mit der Sie autonome Agenten erstellen können, die komplexe Aufgaben verstehen und sie für die Orchestrierung in einfachere Aufgaben aufteilen können. Die Kombination der Erkenntnisse aus den vereinfachten Aufgaben, die durch die autonomen Agenten von Amazon Bedrock unterstützt werden, verbessert die Informationssynthese und führt zu gründlicheren und umfassenderen Antworten. Dieses Muster zeigt, wie Sie mithilfe von Amazon Bedrock und den zugehörigen generativen KI-Diensten und -Funktionen innerhalb einer automatisierten Lösung einen chatbasierten Assistenten erstellen können.
Voraussetzungen und Einschränkungen
Voraussetzungen
Ein aktives AWS-Konto
AWS Cloud Development Kit (AWS CDK), installiert und in die
us-east-1AWS-Regionen gestartetus-west-2AWS-Befehlszeilenschnittstelle (AWS CLI), installiert und konfiguriert
Aktivieren Sie in Amazon Bedrock den Zugriff auf Claude 2, Claude 2.1, Claude Instant und Titan Embeddings G1 — Text
Einschränkungen
Diese Lösung wird auf einem einzigen AWS-Konto bereitgestellt.
Diese Lösung kann nur in AWS-Regionen eingesetzt werden, in denen Amazon Bedrock und Amazon OpenSearch Serverless unterstützt werden. Weitere Informationen finden Sie in der Dokumentation für Amazon Bedrock und Amazon OpenSearch Serverless.
Produktversionen
LLAMA-Index Version 0.10.6 oder höher
Sqlalchemy Version 2.0.23 oder höher
OpenSearch-PY Version 2.4.2 oder höher
Requests_AWS4Auth Version 1.2.3 oder höher
AWS SDK for Python (Boto3) Version 1.34.57 oder höher
Architektur
Zieltechnologie-Stack
Das AWS Cloud Development Kit (AWS CDK) ist ein Open-Source-Framework für die Softwareentwicklung, mit dem Cloud-Infrastruktur im Code definiert und über AWS bereitgestellt werden kann. CloudFormation Der in diesem Muster verwendete AWS-CDK-Stack stellt die folgenden AWS-Ressourcen bereit:
AWS Key Management Service (AWS KMS)
Amazon Simple Storage Service (Amazon-S3)
AWS Glue Glue-Datenkatalog für die AWS Glue Glue-Datenbankkomponente
AWS Lambda
AWS Identity and Access Management (IAM)
Amazon OpenSearch Serverlos
Amazon Elastic Container Registry (Amazon ECR)
Amazon Elastic Container Service (Amazon ECS)
AWS Fargate
Amazon Virtual Private Cloud (Amazon VPC)
Zielarchitektur
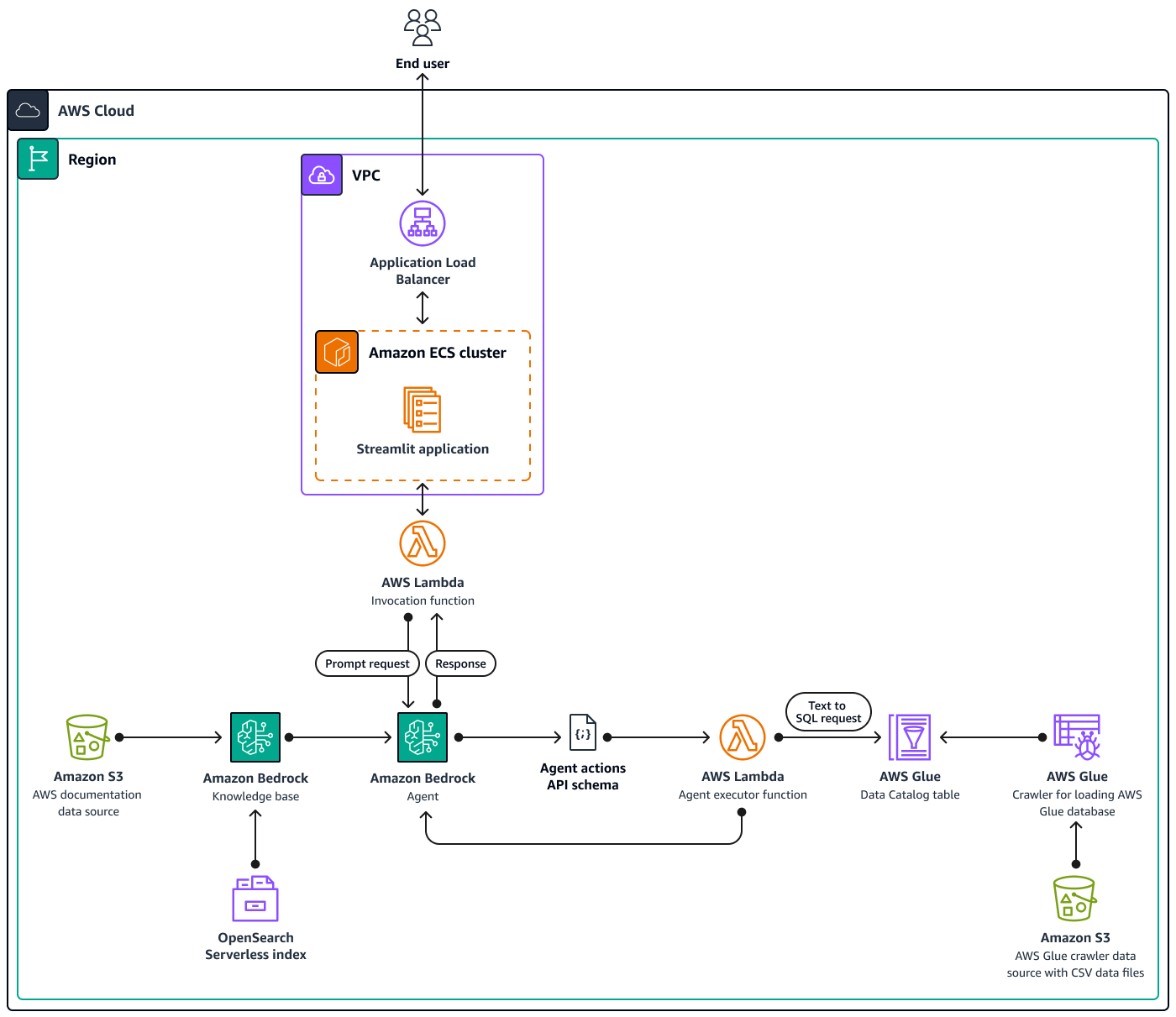
Das Diagramm zeigt ein umfassendes Cloud-natives AWS-Setup innerhalb einer einzigen AWS-Region unter Verwendung mehrerer AWS-Services. Die primäre Schnittstelle für den Chat-basierten Assistenten ist eine Streamlit-AnwendungInvocation Lambda-Funktion, die dann eine Schnittstelle zu Agenten für Amazon Bedrock herstellt. Dieser Agent beantwortet Benutzeranfragen, indem er entweder die Wissensdatenbanken für Amazon Bedrock konsultiert oder eine Agent executor Lambda-Funktion aufruft. Diese Funktion löst nach einem vordefinierten API-Schema eine Reihe von Aktionen aus, die dem Agenten zugeordnet sind. Die Wissensdatenbanken für Amazon Bedrock verwenden einen OpenSearch serverlosen Index als Grundlage für ihre Vektordatenbank. Darüber hinaus generiert die Agent executor Funktion SQL-Abfragen, die über Amazon Athena für die AWS Glue Glue-Datenbank ausgeführt werden.
Tools
AWS-Services
Amazon Athena ist ein interaktiver Abfrageservice, mit dem Sie Daten mithilfe von Standard-SQL direkt in Amazon Simple Storage Service (Amazon S3) analysieren können.
Amazon Bedrock ist ein vollständig verwalteter Service, der Ihnen leistungsstarke Basismodelle (FMs) von führenden KI-Startups und Amazon über eine einheitliche API zur Verfügung stellt.
Das AWS Cloud Development Kit (AWS CDK) ist ein Softwareentwicklungs-Framework, das Sie bei der Definition und Bereitstellung der AWS-Cloud-Infrastruktur im Code unterstützt.
AWS Command Line Interface (AWS CLI) ist ein Open-Source-Tool, mit dem Sie über Befehle in Ihrer Befehlszeilen-Shell mit AWS-Services interagieren können.
Amazon Elastic Container Service (Amazon ECS) ist ein hoch skalierbarer, schneller Container-Management-Service, der das Ausführen, Beenden und Verwalten von Containern in einem Cluster vereinfacht.
Elastic Load Balancing (ELB) verteilt eingehenden Anwendungs- oder Netzwerkverkehr auf mehrere Ziele. Sie können beispielsweise den Traffic auf Amazon Elastic Compute Cloud (Amazon EC2) -Instances, Container und IP-Adressen in einer oder mehreren Availability Zones verteilen.
AWS Glue ist ein vollständig verwalteter Service zum Extrahieren, Transformieren und Laden (ETL). Er hilft Ihnen dabei, Daten zuverlässig zu kategorisieren, zu bereinigen, anzureichern und zwischen Datenspeichern und Datenströmen zu verschieben. Dieses Muster verwendet einen AWS Glue Glue-Crawler und eine AWS Glue Glue-Datenkatalogtabelle.
AWS Lambda ist ein Rechenservice, mit dem Sie Code ausführen können, ohne Server bereitstellen oder verwalten zu müssen. Er führt Ihren Code nur bei Bedarf aus und skaliert automatisch, sodass Sie nur für die tatsächlich genutzte Rechenzeit zahlen.
Amazon OpenSearch Serverless ist eine serverlose On-Demand-Konfiguration für Amazon OpenSearch Service. In diesem Muster dient ein OpenSearch serverloser Index als Vektordatenbank für die Wissensdatenbanken für Amazon Bedrock.
Amazon Simple Storage Service (Amazon S3) ist ein cloudbasierter Objektspeicherservice, der Sie beim Speichern, Schützen und Abrufen beliebiger Datenmengen unterstützt.
Andere Tools
Streamlit
ist ein Open-Source-Python-Framework zur Erstellung von Datenanwendungen.
Code-Repository
Der Code für dieses Muster ist im GitHub genai-bedrock-agent-chatbot
assetsOrdner — Die statischen Elemente, wie das Architekturdiagramm und der öffentliche Datensatz.code/lambdas/action-lambdafolder — Der Python-Code für die Lambda-Funktion, die als Aktion für den Amazon Bedrock-Agenten fungiert.code/lambdas/create-index-lambdafolder — Der Python-Code für die Lambda-Funktion, die den OpenSearch Serverless-Index erstellt.code/lambdas/invoke-lambdafolder — Der Python-Code für die Lambda-Funktion, die den Amazon Bedrock-Agenten aufruft, der direkt aus der Streamlit-Anwendung aufgerufen wird.code/lambdas/update-lambdafolder — Der Python-Code für die Lambda-Funktion, die Ressourcen aktualisiert oder löscht, nachdem die AWS-Ressourcen über das AWS-CDK bereitgestellt wurden.code/layers/boto3_layerfolder — Der AWS-CDK-Stack, der eine Boto3-Ebene erstellt, die von allen Lambda-Funktionen gemeinsam genutzt wird.code/layers/opensearch_layerfolder — Der AWS-CDK-Stack, der eine OpenSearch serverlose Schicht erstellt, die alle Abhängigkeiten installiert, um den Index zu erstellen.code/streamlit-appfolder — Der Python-Code, der als Container-Image in Amazon ECS ausgeführt wirdcode/code_stack.py— Das AWS CDK erstellt Python-Dateien, die AWS-Ressourcen erstellen.app.py— Der AWS-CDK-Stapel von Python-Dateien, die AWS-Ressourcen im AWS-Zielkonto bereitstellen.requirements.txt— Die Liste aller Python-Abhängigkeiten, die für das AWS-CDK installiert werden müssen.cdk.json— Die Eingabedatei zur Bereitstellung der Werte, die für die Erstellung von Ressourcen erforderlich sind. Außerdem können Sie die Lösung in dencontext/configFeldern entsprechend anpassen. Weitere Informationen zur Anpassung finden Sie im Abschnitt Zusätzliche Informationen.
Bewährte Methoden
Das hier bereitgestellte Codebeispiel dient nur proof-of-concept (PoC) oder Pilotzwecken. Wenn Sie den Code für die Produktion verwenden möchten, sollten Sie unbedingt die folgenden bewährten Methoden anwenden:
Amazon S3 S3-Zugriffsprotokollierung aktivieren
VPC-Flow-Logs aktivieren
Richten Sie die Überwachung und Warnung für die Lambda-Funktionen ein. Weitere Informationen finden Sie unter Überwachung und Problembehandlung von Lambda-Funktionen. Bewährte Methoden finden Sie unter Bewährte Methoden für die Arbeit mit AWS Lambda Lambda-Funktionen.
Epen
| Aufgabe | Beschreibung | Erforderliche Fähigkeiten |
|---|---|---|
Exportieren Sie Variablen für das Konto und die Region. | Führen Sie die folgenden Befehle aus, um AWS-Anmeldeinformationen für das AWS-CDK mithilfe von Umgebungsvariablen bereitzustellen.
| AWS DevOps, DevOps Ingenieur |
Richten Sie das AWS-CLI mit dem Namen profile ein. | Um das benannte AWS-CLI-Profil für das Konto einzurichten, folgen Sie den Anweisungen unter Konfiguration und Einstellungen der Anmeldeinformationsdatei. | AWS DevOps, DevOps Ingenieur |
| Aufgabe | Beschreibung | Erforderliche Fähigkeiten |
|---|---|---|
Klonen Sie das Repo auf Ihre lokale Workstation. | Um das Repository zu klonen, führen Sie den folgenden Befehl in Ihrem Terminal aus.
| DevOps Ingenieur, AWS DevOps |
Richten Sie die virtuelle Python-Umgebung ein. | Führen Sie die folgenden Befehle aus, um die virtuelle Python-Umgebung einzurichten.
Führen Sie den folgenden Befehl aus, um die erforderlichen Abhängigkeiten einzurichten.
| DevOps Ingenieur, AWS DevOps |
Richten Sie die AWS-CDK-Umgebung ein. | Führen Sie den Befehl aus, um den Code in eine CloudFormation AWS-Vorlage zu konvertieren | AWS DevOps, DevOps Ingenieur |
| Aufgabe | Beschreibung | Erforderliche Fähigkeiten |
|---|---|---|
Stellen Sie Ressourcen im Konto bereit. | Gehen Sie wie folgt vor, um Ressourcen im AWS-Konto mithilfe des AWS-CDK bereitzustellen:
Nach erfolgreicher Bereitstellung können Sie über die URL auf der Registerkarte Outputs in der Konsole auf die Chat-basierte Assistentenanwendung zugreifen. CloudFormation | DevOps Ingenieur, AWS DevOps |
| Aufgabe | Beschreibung | Erforderliche Fähigkeiten |
|---|---|---|
Entfernen Sie die AWS-Ressourcen. | Nachdem Sie die Lösung getestet haben, führen Sie den Befehl aus, um die Ressourcen zu bereinigen | AWS DevOps, DevOps Ingenieur |
Zugehörige Ressourcen
AWS-Dokumentation
Ressourcen von Amazon Bedrock:
AWS-CDK-Ressourcen:
Andere AWS-Ressourcen
Sonstige Ressourcen
Zusätzliche Informationen
Passen Sie den Chat-basierten Assistenten mit Ihren eigenen Daten an
Folgen Sie diesen strukturierten Richtlinien, um Ihre benutzerdefinierten Daten für die Bereitstellung der Lösung zu integrieren. Diese Schritte sollen einen nahtlosen und effizienten Integrationsprozess gewährleisten, sodass Sie die Lösung effektiv mit Ihren maßgeschneiderten Daten implementieren können.
Für die Datenintegration in der Wissensdatenbank
Datenaufbereitung
Suchen Sie das
assets/knowledgebase_data_source/Verzeichnis.Platzieren Sie Ihren Datensatz in diesem Ordner.
Anpassungen der Konfiguration
Öffnen Sie die
cdk.jsonDatei.Navigieren Sie zu dem
context/configure/paths/knowledgebase_file_nameFeld und aktualisieren Sie es dann entsprechend.Navigieren Sie zu dem
bedrock_instructions/knowledgebase_instructionFeld, und aktualisieren Sie es dann, damit es die Nuancen und den Kontext Ihres neuen Datensatzes genau wiedergibt.
Für die Integration von Strukturdaten
Organisation der Daten
Erstellen Sie innerhalb des
assets/data_query_data_source/Verzeichnisses ein Unterverzeichnis, z. B.tabular_dataPlatzieren Sie Ihren strukturierten Datensatz (akzeptable Formate umfassen CSV, JSON, ORC und Parquet) in diesem neu erstellten Unterordner.
Wenn Sie eine Verbindung zu einer vorhandenen Datenbank herstellen, aktualisieren Sie die Funktion
create_sql_engine()unter So stellen Sie eine Verbindungcode/lambda/action-lambda/build_query_engine.pyzu Ihrer Datenbank her.
Konfiguration und Code-Updates
Aktualisieren Sie das
context/configure/paths/athena_table_data_prefixFeld in dercdk.jsonDatei so, dass es dem neuen Datenpfad entspricht.Überarbeiten Sie,
code/lambda/action-lambda/dynamic_examples.csvindem Sie neue text-to-SQL Beispiele einbeziehen, die Ihrem Datensatz entsprechen.Überarbeiten Sie
code/lambda/action-lambda/prompt_templates.py, um die Attribute Ihres strukturierten Datensatzes widerzuspiegeln.Aktualisieren Sie das
context/configure/bedrock_instructions/action_group_descriptionFeld in dercdk.jsonDatei, um den Zweck und die Funktionalität derAction groupLambda-Funktion zu erläutern.Erläutern Sie in der
assets/agent_api_schema/artifacts_schema.jsonDatei die neuen Funktionen IhrerAction groupLambda-Funktion.
Allgemeines Update
Geben Sie in der cdk.json Datei im context/configure/bedrock_instructions/agent_instruction Abschnitt eine umfassende Beschreibung der beabsichtigten Funktionalität und des Entwurfszwecks des Amazon Bedrock-Agenten unter Berücksichtigung der neu integrierten Daten.
