Die vorliegende Übersetzung wurde maschinell erstellt. Im Falle eines Konflikts oder eines Widerspruchs zwischen dieser übersetzten Fassung und der englischen Fassung (einschließlich infolge von Verzögerungen bei der Übersetzung) ist die englische Fassung maßgeblich.
Entwickeln Sie mithilfe von RAG und Prompting fortschrittliche, auf KI basierende Chat-Assistenten ReAct
Praveen Kumar Jeyarajan, Shuai Cao, Noah Hamilton, Kiowa Jackson, Jundong Qiao und Kara Yang, Amazon Web Services
Übersicht
In einem typischen Unternehmen sind 70 Prozent seiner Daten in isolierten Systemen gespeichert. Mithilfe generativer, KI-gestützter Chat-Assistenten können Sie mithilfe von Interaktionen in natürlicher Sprache Einblicke und Beziehungen zwischen diesen Datensilos gewinnen. Um das Beste aus generativer KI herauszuholen, müssen die Ergebnisse vertrauenswürdig und genau sein und die verfügbaren Unternehmensdaten beinhalten. Erfolgreiche Chat-Assistenten hängen von folgenden Faktoren ab:
Generative KI-Modelle (wie Anthropic Claude 2)
Vektorisierung von Datenquellen
Fortgeschrittene Argumentationstechniken, wie z. B. das ReAct Framework
, als Grundlage für das Modell
Dieses Muster bietet Datenabrufansätze aus Datenquellen wie Amazon Simple Storage Service (Amazon S3) -Buckets, AWS Glue und Amazon Relational Database Service (Amazon RDS). Aus diesen Daten wird Wert gewonnen, indem Retrieval Augmented Generation (RAG) mit Methoden verknüpft wird. chain-of-thought Die Ergebnisse unterstützen komplexe Chat-basierte Assistentengespräche, die sich auf die Gesamtheit der in Ihrem Unternehmen gespeicherten Daten stützen.
Dieses Muster verwendet SageMaker Amazon-Handbücher und Preisdatentabellen als Beispiel, um die Funktionen eines generativen KI-Assistenten auf Chatbasis zu untersuchen. Sie werden einen Chat-basierten Assistenten entwickeln, der Kunden hilft, den SageMaker Service zu bewerten, indem er Fragen zur Preisgestaltung und zu den Funktionen des Dienstes beantwortet. Die Lösung verwendet eine Streamlit-Bibliothek für die Erstellung der Frontend-Anwendung und das LangChain Framework für die Entwicklung des Anwendungs-Backends, das auf einem Large Language Model (LLM) basiert.
Anfragen an den Chat-Assistenten werden zunächst mit einer Absichtsklassifizierung beantwortet, sodass sie an einen von drei möglichen Workflows weitergeleitet werden. Der ausgefeilteste Arbeitsablauf kombiniert allgemeine Beratung mit komplexen Preisanalysen. Sie können das Muster an Anwendungsfälle in Unternehmen, Unternehmen und der Industrie anpassen.
Voraussetzungen und Einschränkungen
Voraussetzungen
AWS-Befehlszeilenschnittstelle (AWS CLI) installiert und konfiguriert
AWS Cloud Development Kit (AWS CDK) Toolkit 2.114.1 oder höher installiert und konfiguriert
Grundkenntnisse in Python und AWS CDK
Git
installiert Python 3.11 oder höher
installiert und konfiguriert (weitere Informationen finden Sie im Abschnitt Tools) Ein aktives AWS-Konto, das mithilfe von AWS CDK gestartet wurde
Der Zugriff auf die Modelle Amazon Titan und Anthropic Claude ist im Amazon Bedrock-Service aktiviert
AWS-Sicherheitsanmeldedaten
AWS_ACCESS_KEY_ID, einschließlich korrekt konfigurierter Anmeldeinformationen in Ihrer Terminalumgebung
Einschränkungen
LangChain unterstützt nicht jedes LLM für Streaming. Die Modelle von Anthropic Claude werden unterstützt, Modelle von AI21 Labs jedoch nicht.
Diese Lösung wird auf einem einzigen AWS-Konto bereitgestellt.
Diese Lösung kann nur in AWS-Regionen eingesetzt werden, in denen Amazon Bedrock und Amazon Kendra verfügbar sind. Informationen zur Verfügbarkeit finden Sie in der Dokumentation für Amazon Bedrock und Amazon Kendra.
Produktversionen
Python-Version 3.11 oder höher
Streamlit Version 1.30.0 oder höher
Streamlit-Chat Version 0.1.1 oder höher
LangChain Version 0.1.12 oder höher
AWS CDK Version 2.132.1 oder höher
Architektur
Zieltechnologie-Stack
Amazon Athena
Amazon Bedrock
Amazon Elastic Container Service (Amazon ECS)
AWS Glue
AWS Lambda
Amazon S3
Amazon Kendra
Elastic Load Balancing
Zielarchitektur
Der AWS-CDK-Code stellt alle Ressourcen bereit, die für die Einrichtung der Chat-basierten Assistentenanwendung in einem AWS-Konto erforderlich sind. Die in der folgenden Abbildung gezeigte Chat-basierte Assistentenanwendung wurde entwickelt, um verwandte Anfragen von Benutzern zu beantworten SageMaker . Benutzer stellen über einen Application Load Balancer eine Verbindung zu einer VPC her, die einen Amazon ECS-Cluster enthält, der die Streamlit-Anwendung hostet. Eine Orchestrierungs-Lambda-Funktion stellt eine Verbindung zur Anwendung her. S3-Bucket-Datenquellen stellen Daten für die Lambda-Funktion über Amazon Kendra und AWS Glue bereit. Die Lambda-Funktion stellt eine Verbindung zu Amazon Bedrock her, um Anfragen (Fragen) von Chat-basierten Assistentenbenutzern zu beantworten.
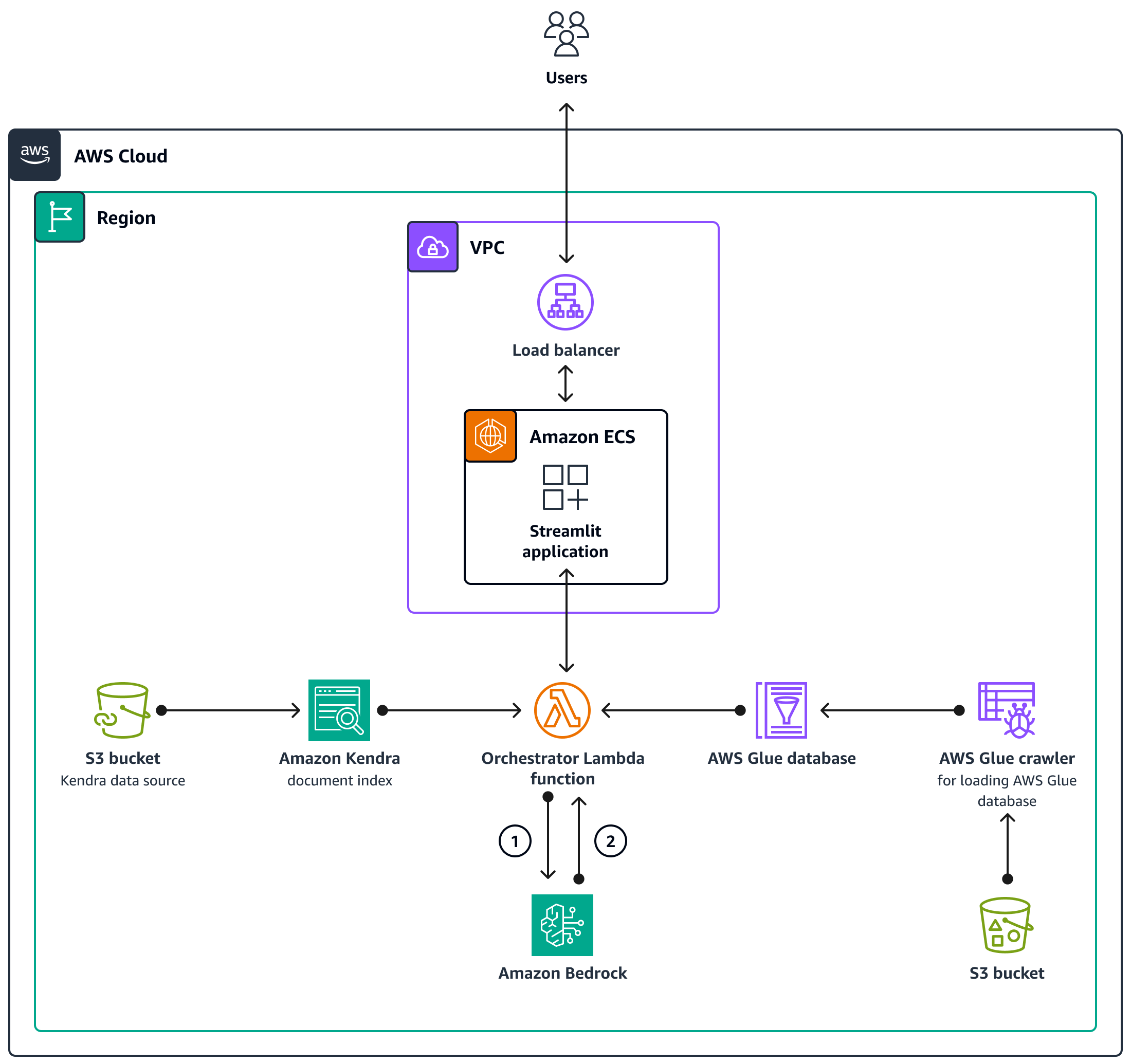
Die Orchestrierungs-Lambda-Funktion sendet die LLM-Prompt-Anfrage an das Amazon Bedrock-Modell (Claude 2).
Amazon Bedrock sendet die LLM-Antwort zurück an die Orchestrierungs-Lambda-Funktion.
Logikfluss innerhalb der Orchestrierungs-Lambda-Funktion
Wenn Benutzer über die Streamlit-Anwendung eine Frage stellen, wird die Orchestrierungs-Lambda-Funktion direkt aufgerufen. Das folgende Diagramm zeigt den Logikfluss, wenn die Lambda-Funktion aufgerufen wird.
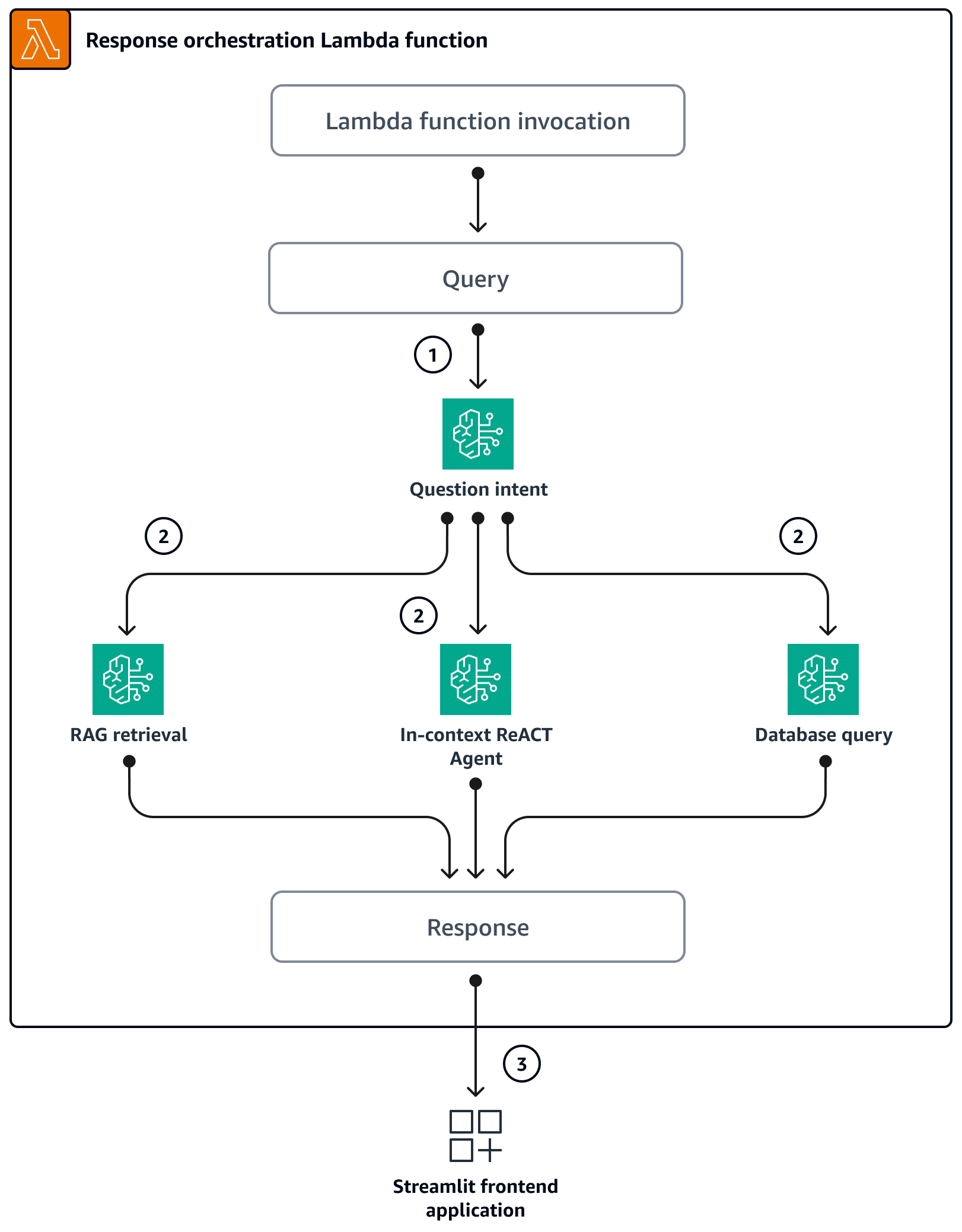
Schritt 1 — Die Eingabe
query(Frage) wird in eine der drei Absichten eingeteilt:Allgemeine SageMaker Orientierungsfragen
Allgemeine Fragen zur SageMaker Preisgestaltung (Schulung/Inferenz)
Komplexe Fragen im Zusammenhang mit und zur Preisgestaltung SageMaker
Schritt 2 — Die Eingabe
queryinitiiert einen der drei Dienste:RAG Retrieval service, das den relevanten Kontext aus der Amazon Kendra Kendra-Vektordatenbankabruft und das LLM über Amazon Bedrock aufruft, um den abgerufenen Kontext als Antwort zusammenzufassen. Database Query service, das das LLM, Datenbank-Metadaten und Beispielzeilen aus relevanten Tabellen verwendet, um die Eingabe in eine SQL-Abfrage umzuwandeln.queryDer Datenbankabfragedienst führt die SQL-Abfrage für die SageMaker Preisdatenbank über Amazon Athenaaus und fasst die Abfrageergebnisse als Antwort zusammen. In-context ReACT Agent service, der die Eingabequeryin mehrere Schritte unterteilt, bevor eine Antwort bereitgestellt wird. Der Agent verwendetRAG Retrieval serviceundDatabase Query serviceals Hilfsmittel, um während des Argumentationsprozesses relevante Informationen abzurufen. Nachdem der Argumentations- und Handlungsprozess abgeschlossen ist, generiert der Agent die endgültige Antwort als Antwort.
Schritt 3 — Die Antwort der Orchestrierungs-Lambda-Funktion wird als Ausgabe an die Streamlit-Anwendung gesendet.
Tools
AWS-Services
Amazon Athena ist ein interaktiver Abfrageservice, mit dem Sie Daten mithilfe von Standard-SQL direkt in Amazon Simple Storage Service (Amazon S3) analysieren können.
Amazon Bedrock ist ein vollständig verwalteter Service, der Ihnen leistungsstarke Basismodelle (FMs) von führenden KI-Startups und Amazon über eine einheitliche API zur Verfügung stellt.
Das AWS Cloud Development Kit (AWS CDK) ist ein Softwareentwicklungs-Framework, das Sie bei der Definition und Bereitstellung der AWS-Cloud-Infrastruktur im Code unterstützt.
AWS Command Line Interface (AWS CLI) ist ein Open-Source-Tool, mit dem Sie über Befehle in Ihrer Befehlszeilen-Shell mit AWS-Services interagieren können.
Amazon Elastic Container Service (Amazon ECS) ist ein hoch skalierbarer, schneller Container-Management-Service, der das Ausführen, Beenden und Verwalten von Containern in einem Cluster vereinfacht.
AWS Glue ist ein vollständig verwalteter Service zum Extrahieren, Transformieren und Laden (ETL). Er hilft Ihnen dabei, Daten zuverlässig zu kategorisieren, zu bereinigen, anzureichern und zwischen Datenspeichern und Datenströmen zu verschieben. Dieses Muster verwendet einen AWS Glue Glue-Crawler und eine AWS Glue Glue-Datenkatalogtabelle.
Amazon Kendra ist ein intelligenter Suchdienst, der natürliche Sprachverarbeitung und fortschrittliche Algorithmen für maschinelles Lernen verwendet, um spezifische Antworten auf Suchfragen aus Ihren Daten zurückzugeben.
AWS Lambda ist ein Rechenservice, mit dem Sie Code ausführen können, ohne Server bereitstellen oder verwalten zu müssen. Er führt Ihren Code nur bei Bedarf aus und skaliert automatisch, sodass Sie nur für die tatsächlich genutzte Rechenzeit zahlen.
Amazon Simple Storage Service (Amazon S3) ist ein cloudbasierter Objektspeicherservice, der Sie beim Speichern, Schützen und Abrufen beliebiger Datenmengen unterstützt.
Elastic Load Balancing (ELB) verteilt eingehenden Anwendungs- oder Netzwerkverkehr auf mehrere Ziele. Sie können beispielsweise den Traffic auf Amazon Elastic Compute Cloud (Amazon EC2) -Instances, Container und IP-Adressen in einer oder mehreren Availability Zones verteilen.
Code-Repository
Der Code für dieses Muster ist im GitHub genai-bedrock-chatbot
Das Code-Repository enthält die folgenden Dateien und Ordner:
assetsOrdner — Die statischen Objekte, das Architekturdiagramm und der öffentliche Datensatz.code/lambda-containerfolder — Der Python-Code, der in der Lambda-Funktion ausgeführt wirdcode/streamlit-appfolder — Der Python-Code, der als Container-Image in Amazon ECS ausgeführt wirdtestsfolder — Die Python-Dateien, die zum Komponententest der AWS-CDK-Konstrukte ausgeführt werdencode/code_stack.py— Das AWS-CDK-Konstrukt Python-Dateien, die zur Erstellung von AWS-Ressourcen verwendet werdenapp.py— Die AWS-CDK-Stack-Python-Dateien, die zur Bereitstellung von AWS-Ressourcen im AWS-Zielkonto verwendet werdenrequirements.txt— Die Liste aller Python-Abhängigkeiten, die für AWS CDK installiert werden müssenrequirements-dev.txt— Die Liste aller Python-Abhängigkeiten, die installiert werden müssen, damit AWS CDK die Unit-Test-Suite ausführen kanncdk.json— Die Eingabedatei zur Bereitstellung von Werten, die zum Hochfahren von Ressourcen erforderlich sind
Hinweis: Der AWS-CDK-Code verwendet L3-Konstrukte (Layer 3) und AWS Identity and Access Management (IAM) -Richtlinien, die von AWS für die Bereitstellung der Lösung verwaltet werden. |
|---|
Bewährte Methoden
Das hier bereitgestellte Codebeispiel ist nur für eine proof-of-concept (PoC) oder Pilotdemo vorgesehen. Wenn Sie den Code in die Produktionsumgebung übernehmen möchten, sollten Sie unbedingt die folgenden bewährten Methoden anwenden:
Richten Sie die Überwachung und Warnung für die Lambda-Funktion ein. Weitere Informationen finden Sie unter Überwachung und Problembehandlung von Lambda-Funktionen. Allgemeine bewährte Methoden für die Arbeit mit Lambda-Funktionen finden Sie in der AWS-Dokumentation.
Epen
| Aufgabe | Beschreibung | Erforderliche Fähigkeiten |
|---|---|---|
Exportieren Sie Variablen für das Konto und die AWS-Region, in der der Stack bereitgestellt wird. | Führen Sie die folgenden Befehle aus, um AWS-Anmeldeinformationen für AWS CDK mithilfe von Umgebungsvariablen bereitzustellen.
| DevOps Ingenieur, AWS DevOps |
Richten Sie das AWS-CLI-Profil ein. | Folgen Sie den Anweisungen in der AWS-Dokumentation, um das AWS-CLI-Profil für das Konto einzurichten. | DevOps Ingenieur, AWS DevOps |
| Aufgabe | Beschreibung | Erforderliche Fähigkeiten |
|---|---|---|
Klonen Sie das Repo auf Ihrem lokalen Computer. | Um das Repository zu klonen, führen Sie den folgenden Befehl in Ihrem Terminal aus.
| DevOps Ingenieur, AWS DevOps |
Richten Sie die virtuelle Python-Umgebung ein und installieren Sie die erforderlichen Abhängigkeiten. | Führen Sie die folgenden Befehle aus, um die virtuelle Python-Umgebung einzurichten.
Führen Sie den folgenden Befehl aus, um die erforderlichen Abhängigkeiten einzurichten.
| DevOps Ingenieur, AWS DevOps |
Richten Sie die AWS-CDK-Umgebung ein und synthetisieren Sie den AWS-CDK-Code. |
| DevOps Ingenieur, AWS DevOps |
| Aufgabe | Beschreibung | Erforderliche Fähigkeiten |
|---|---|---|
Gewähren Sie Zugriff auf das Claude-Modell. | Folgen Sie den Anweisungen in der Amazon Bedrock-Dokumentation, um den Zugriff auf das Anthropic-Claude-Modell für Ihr AWS-Konto zu aktivieren. | AWS DevOps |
Stellen Sie Ressourcen im Konto bereit. | Gehen Sie wie folgt vor, um Ressourcen im AWS-Konto mithilfe des AWS-CDK bereitzustellen:
Nach erfolgreicher Bereitstellung können Sie über die im Abschnitt CloudFormation Ausgaben angegebene URL auf die Chat-basierte Assistentenanwendung zugreifen. | AWS DevOps, DevOps Ingenieur |
Führen Sie den AWS Glue Glue-Crawler aus und erstellen Sie die Datenkatalogtabelle. | Ein AWS Glue Glue-Crawler wird verwendet, um das Datenschema dynamisch zu halten. Die Lösung erstellt und aktualisiert Partitionen in der AWS Glue Data Catalog-Tabelle, indem sie den Crawler bei Bedarf ausführt. Nachdem die CSV-Datensatzdateien in den S3-Bucket kopiert wurden, führen Sie den AWS Glue Glue-Crawler aus und erstellen Sie das Datenkatalog-Tabellenschema zum Testen:
AnmerkungDer AWS-CDK-Code konfiguriert den AWS Glue-Crawler so, dass er bei Bedarf ausgeführt wird. Sie können ihn aber auch so planen, dass er regelmäßig ausgeführt wird. | DevOps Ingenieur, AWS DevOps |
Initiieren Sie die Indizierung von Dokumenten. | Nachdem die Dateien in den S3-Bucket kopiert wurden, verwenden Sie Amazon Kendra, um sie zu crawlen und zu indizieren:
| AWS DevOps, DevOps Ingenieur |
| Aufgabe | Beschreibung | Erforderliche Fähigkeiten |
|---|---|---|
Entfernen Sie die AWS-Ressourcen. | Nachdem Sie die Lösung getestet haben, bereinigen Sie die Ressourcen:
| DevOps Ingenieur, AWS DevOps |
Fehlerbehebung
| Problem | Lösung |
|---|---|
AWS CDK gibt Fehler zurück. | Hilfe bei Problemen mit AWS CDK finden Sie unter Behebung häufiger Probleme mit AWS CDK. |
Zugehörige Ressourcen
Zusätzliche Informationen
AWS CDK-Befehle
Beachten Sie bei der Arbeit mit AWS CDK die folgenden nützlichen Befehle:
Listet alle Stacks in der App auf
cdk lsGibt die synthetisierte AWS-Vorlage aus CloudFormation
cdk synthStellt den Stack für Ihr AWS-Standardkonto und Ihre Region bereit
cdk deployVergleicht den bereitgestellten Stack mit dem aktuellen Status
cdk diffÖffnet die AWS CDK-Dokumentation
cdk docsLöscht den CloudFormation Stack und entfernt von AWS bereitgestellte Ressourcen
cdk destroy
