Die vorliegende Übersetzung wurde maschinell erstellt. Im Falle eines Konflikts oder eines Widerspruchs zwischen dieser übersetzten Fassung und der englischen Fassung (einschließlich infolge von Verzögerungen bei der Übersetzung) ist die englische Fassung maßgeblich.
Daten aus einem Amazon Redshift Redshift-Cluster kontenübergreifend nach Amazon S3 entladen
Andrew Kamel, Amazon Web Services
Übersicht
Wenn Sie Anwendungen testen, ist es hilfreich, Produktionsdaten in Ihrer Testumgebung zu haben. Mithilfe von Produktionsdaten können Sie die Anwendung, die Sie entwickeln, genauer einschätzen.
Dieses Muster extrahiert Daten aus einem Amazon Redshift Redshift-Cluster in einer Produktionsumgebung in einen Amazon Simple Storage Service (Amazon S3) -Bucket in einer Entwicklungsumgebung auf Amazon Web Services (AWS).
Das Muster führt Schritt für Schritt die Einrichtung von DEV- und PROD-Konten durch, einschließlich der folgenden Schritte:
Erforderliche -Ressourcen
AWS Identity and Access Management (IAM) -Rollen
Netzwerkanpassungen an Subnetzen, Sicherheitsgruppen und der Virtual Private Cloud (VPC) zur Unterstützung der Amazon Redshift Redshift-Verbindung
Eine AWS Lambda Beispielfunktion mit einer Python-Laufzeit zum Testen der Architektur
Um Zugriff auf den Amazon Redshift Redshift-Cluster AWS Secrets Manager zu gewähren, speichert das Muster die entsprechenden Anmeldeinformationen. Der Vorteil besteht darin, dass Sie über alle erforderlichen Informationen verfügen, um eine direkte Verbindung zum Amazon Redshift Redshift-Cluster herzustellen, ohne wissen zu müssen, wo sich der Amazon Redshift Redshift-Cluster befindet. Darüber hinaus können Sie die Verwendung des Geheimnisses überwachen.
Das in Secrets Manager gespeicherte Geheimnis umfasst den Host, den Datenbanknamen, den Port und die entsprechenden Anmeldeinformationen des Amazon Redshift Redshift-Clusters.
Informationen zu Sicherheitsaspekten bei der Verwendung dieses Musters finden Sie im Abschnitt Bewährte Methoden.
Voraussetzungen und Einschränkungen
Voraussetzungen
Ein Amazon Redshift Redshift-Cluster, der im PROD-Konto ausgeführt wird
VPC-Peering zwischen den DEV- und PROD-Konten mit entsprechend angepassten Routentabellen
DNS-Hostnamen und DNS-Auflösung sind für beide Peering-Verbindungen aktiviert VPCs
Einschränkungen
Abhängig von der Datenmenge, die Sie abfragen möchten, kann es bei der Lambda-Funktion zu einem Timeout kommen.
Wenn Ihre Ausführung länger als das maximale Lambda-Timeout (15 Minuten) dauert, verwenden Sie einen asynchronen Ansatz für Ihren Lambda-Code. Das Codebeispiel für dieses Muster verwendet die psycopg2-Bibliothek
für Python, die derzeit keine asynchrone Verarbeitung unterstützt. Einige AWS-Services sind nicht in allen verfügbar. AWS-Regionen Informationen zur Verfügbarkeit in den einzelnen Regionen finden Sie AWS-Services unter Nach Regionen
. Informationen zu bestimmten Endpunkten finden Sie auf der Seite Dienstendpunkte und Kontingente. Wählen Sie dort den Link für den Dienst aus.
Architektur
Das folgende Diagramm zeigt die Zielarchitektur mit DEV- und PROD-Konten.

Das Diagramm zeigt den folgenden Workflow:
Die Lambda-Funktion im DEV-Konto übernimmt die IAM-Rolle, die für den Zugriff auf die Amazon Redshift Redshift-Anmeldeinformationen in Secrets Manager im PROD-Konto erforderlich ist.
Die Lambda-Funktion ruft dann das Amazon Redshift Redshift-Clustergeheimnis ab.
Die Lambda-Funktion im DEV-Konto verwendet die Informationen, um über das Peered-Konto eine Verbindung zum Amazon Redshift Redshift-Cluster im PROD-Konto herzustellen. VPCs
Die Lambda-Funktion sendet dann einen Entladebefehl, um den Amazon Redshift Redshift-Cluster im PROD-Konto abzufragen.
Der Amazon Redshift Redshift-Cluster im PROD-Konto übernimmt die entsprechende IAM-Rolle für den Zugriff auf den S3-Bucket im DEV-Konto.
Der Amazon Redshift Redshift-Cluster entlädt die abgefragten Daten in den S3-Bucket im DEV-Konto.
Daten von Amazon Redshift abfragen
Das folgende Diagramm zeigt die Rollen, die zum Abrufen der Amazon Redshift Redshift-Anmeldeinformationen und zum Herstellen einer Verbindung mit dem Amazon Redshift Redshift-Cluster verwendet werden. Der Workflow wird durch die Lambda-Funktion initiiert.
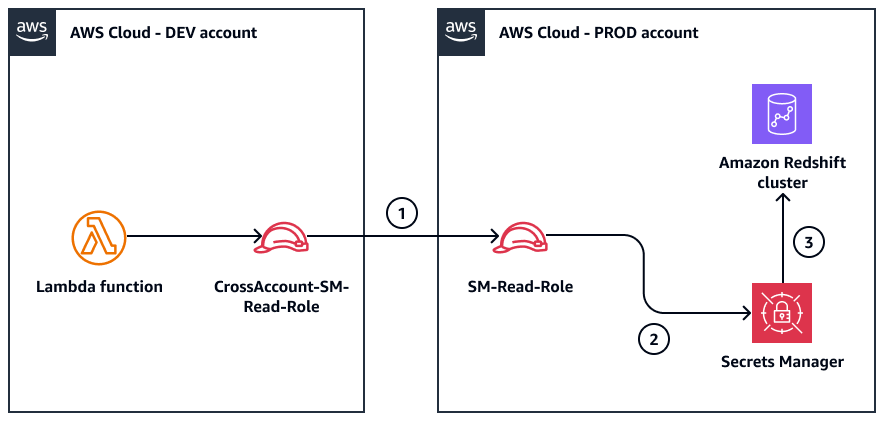
Das Diagramm zeigt den folgenden Workflow:
Das Konto
CrossAccount-SM-Read-Roleim DEV setzt das KontoSM-Read-Roleim PROD voraus.Die
SM-Read-RoleRolle verwendet die angehängte Richtlinie, um das Geheimnis aus Secrets Manager abzurufen.Die Anmeldeinformationen werden für den Zugriff auf den Amazon Redshift Redshift-Cluster verwendet.
Daten auf Amazon S3 hochladen
Das folgende Diagramm zeigt den kontoübergreifenden Lese- und Schreibvorgang für das Extrahieren von Daten und deren Upload auf Amazon S3. Der Workflow wird durch die Lambda-Funktion initiiert. Das Muster verkettet IAM-Rollen in Amazon Redshift. Der Befehl unload, der vom Amazon Redshift Redshift-Cluster kommtCrossAccount-S3-Write-Role, geht von und dann von der aus. S3-Write-Role Durch diese Rollenverkettung erhält Amazon Redshift Zugriff auf Amazon S3.

Der Workflow umfasst die folgenden Schritte:
Das Konto „
CrossAccount-SM-Read-RoleIm DEV“ setzt das Konto „SM-Read-RoleIm PROD“ voraus.Der
SM-Read-Roleruft die Amazon Redshift Redshift-Anmeldeinformationen von Secrets Manager ab.Die Lambda-Funktion stellt eine Verbindung zum Amazon Redshift Redshift-Cluster her und sendet eine Abfrage.
Der Amazon Redshift Redshift-Cluster geht davon aus.
CrossAccount-S3-Write-RoleDas
CrossAccount-S3-Write-Rolegeht davon aus, dass dasS3-Write-Roleim DEV-Konto ist.Die Abfrageergebnisse werden in den S3-Bucket im DEV-Konto entladen.
Tools
AWS-Services
AWS Key Management Service (AWS KMS) hilft Ihnen dabei, kryptografische Schlüssel zu erstellen und zu kontrollieren, um Ihre Daten zu schützen.
AWS Lambda ist ein Datenverarbeitungsservice, mit dem Sie Code ausführen können, ohne dass Sie Server bereitstellen oder verwalten müssen. Es führt Ihren Code nur bei Bedarf aus und skaliert automatisch, sodass Sie nur für die tatsächlich genutzte Rechenzeit zahlen.
Amazon Redshift ist ein verwalteter Data-Warehouse-Service im Petabyte-Bereich in der AWS-Cloud.
Mit AWS Secrets Manager können Sie fest codierte Anmeldeinformationen im Code (einschließlich Passwörter) durch einen API-Aufruf an Secrets Manager ersetzen und das Geheimnis programmgesteuert abrufen.
Amazon Simple Storage Service (Amazon S3) ist ein cloudbasierter Objektspeicherservice, der Sie beim Speichern, Schützen und Abrufen beliebiger Datenmengen unterstützt.
Code-Repository
Der Code für dieses Muster ist im GitHub unload-redshift-to-s3-Python-Repository
Bewährte Methoden
Haftungsausschluss zur Sicherheit
Bevor Sie diese Lösung implementieren, sollten Sie die folgenden wichtigen Sicherheitsempfehlungen berücksichtigen:
Denken Sie daran, dass die Verbindung von Entwicklungs- und Produktionskonten den Umfang erhöhen und die allgemeine Sicherheitslage verringern kann. Wir empfehlen, diese Lösung nur vorübergehend einzusetzen, den erforderlichen Teil der Daten zu extrahieren und dann die bereitgestellten Ressourcen sofort zu vernichten. Um die Ressourcen zu löschen, sollten Sie die Lambda-Funktion löschen, alle für diese Lösung erstellten IAM-Rollen und -Richtlinien entfernen und jeglichen Netzwerkzugriff widerrufen, der zwischen den Konten gewährt wurde.
Konsultieren Sie Ihre Sicherheits- und Compliance-Teams, bevor Sie Daten aus der Produktions- in die Entwicklungsumgebung kopieren. Persönlich identifizierbare Informationen (PII), geschützte Gesundheitsinformationen (PHI) und andere vertrauliche oder regulierte Daten sollten generell nicht auf diese Weise kopiert werden. Kopieren Sie nur öffentlich zugängliche, nicht vertrauliche Informationen (z. B. öffentliche Bestandsdaten aus einem Shop-Frontend). Erwägen Sie die Tokenisierung oder Anonymisierung von Daten oder die Generierung synthetischer Testdaten, anstatt nach Möglichkeit Produktionsdaten zu verwenden. Eines der AWS Sicherheitsprinzipien besteht darin, Menschen von Daten fernzuhalten. Mit anderen Worten, Entwickler sollten keine Operationen im Produktionskonto ausführen.
Beschränken Sie den Zugriff auf die Lambda-Funktion im Entwicklungskonto, da sie Daten aus dem Amazon Redshift Redshift-Cluster in der Produktionsumgebung lesen kann.
Um eine Unterbrechung der Produktionsumgebung zu vermeiden, sollten Sie die folgenden Empfehlungen umsetzen:
Verwenden Sie ein separates, dediziertes Entwicklungskonto für Test- und Entwicklungsaktivitäten.
Implementieren Sie strenge Netzwerkzugriffskontrollen und beschränken Sie den Datenverkehr zwischen Konten auf das Notwendige.
Überwachen und prüfen Sie den Zugriff auf die Produktionsumgebung und die Datenquellen.
Implementieren Sie Zugriffskontrollen mit den geringsten Rechten für alle beteiligten Ressourcen und Dienste.
Überprüfen Sie regelmäßig Anmeldeinformationen wie AWS Secrets Manager geheime Daten und IAM-Rollenzugriffsschlüssel und wechseln Sie diese ab.
Informationen zu den in diesem Artikel verwendeten Diensten finden Sie in der folgenden Sicherheitsdokumentation:
Sicherheit hat beim Zugriff auf Produktionsdaten und Ressourcen oberste Priorität. Halten Sie sich stets an bewährte Verfahren, implementieren Sie Zugriffskontrollen mit geringsten Rechten und überprüfen und aktualisieren Sie Ihre Sicherheitsmaßnahmen regelmäßig.
Epen
| Aufgabe | Beschreibung | Erforderliche Fähigkeiten |
|---|---|---|
Erstellen Sie ein Geheimnis für den Amazon Redshift Redshift-Cluster. | Gehen Sie wie folgt vor, um das Geheimnis für den Amazon Redshift Redshift-Cluster zu erstellen:
| DevOps Ingenieur |
Erstellen Sie eine Rolle für den Zugriff auf Secrets Manager. | Gehen Sie wie folgt vor, um die Rolle zu erstellen:
| DevOps Ingenieur |
| Aufgabe | Beschreibung | Erforderliche Fähigkeiten |
|---|---|---|
Erstellen Sie eine Rolle für den Zugriff auf den S3-Bucket. | Gehen Sie wie folgt vor, um die Rolle für den Zugriff auf den S3-Bucket zu erstellen:
| DevOps Ingenieur |
Erstellen Sie die Amazon Redshift Redshift-Rolle. | Gehen Sie wie folgt vor, um die Amazon Redshift Redshift-Rolle zu erstellen:
| DevOps Ingenieur |
| Aufgabe | Beschreibung | Erforderliche Fähigkeiten |
|---|---|---|
Stellen Sie die Lambda-Funktion bereit. | Gehen Sie wie folgt vor, um eine Lambda-Funktion in der Peering-VPC bereitzustellen:
| DevOps Ingenieur |
| Aufgabe | Beschreibung | Erforderliche Fähigkeiten |
|---|---|---|
Importieren Sie die erforderlichen Ressourcen. | Führen Sie die folgenden Befehle aus, um die erforderlichen Ressourcen zu importieren:
| App-Developer |
Führen Sie die Lambda-Handler-Funktion aus. | Die Lambda-Funktion verwendet AWS Security Token Service (AWS STS) für den kontoübergreifenden Zugriff und die temporäre Verwaltung von Anmeldeinformationen. Die Funktion verwendet den AssumeRole API-Vorgang, um vorübergehend die Berechtigungen der IAM-Rolle zu übernehmen. Verwenden Sie den folgenden Beispielcode, um die Lambda-Funktion auszuführen:
| App-Developer |
Hol dir das Geheimnis. | Verwenden Sie den folgenden Beispielcode, um das Amazon Redshift Redshift-Secret abzurufen:
| App-Developer |
Führen Sie den Befehl unload aus. | Verwenden Sie den folgenden Beispielcode, um die Daten in den S3-Bucket zu entladen.
| App-Developer |
| Aufgabe | Beschreibung | Erforderliche Fähigkeiten |
|---|---|---|
Löschen Sie die Lambda-Funktion. | Um ungeplante Kosten zu vermeiden, entfernen Sie die Ressourcen und die Verbindung zwischen den Konten DEV und PROD. Gehen Sie wie folgt vor, um die Lambda-Funktion zu entfernen:
| DevOps Ingenieur |
Entfernen Sie die IAM-Rollen und -Richtlinien. | Entfernen Sie die IAM-Rollen und -Richtlinien aus den DEV- und PROD-Konten. Gehen Sie im DEV-Konto wie folgt vor:
Gehen Sie im PROD-Konto wie folgt vor:
| DevOps Ingenieur |
Löschen Sie das Geheimnis in Secrets Manager. | Gehen Sie wie folgt vor, um das Geheimnis zu löschen:
| DevOps Ingenieur |
Entfernen Sie VPC-Peering- und Sicherheitsgruppenregeln. | Gehen Sie wie folgt vor, um VPC-Peering- und Sicherheitsgruppenregeln zu entfernen:
| DevOps Ingenieur |
Daten aus dem S3-Bucket entfernen. | Gehen Sie wie folgt vor, um die Daten aus Amazon S3 zu entfernen:
| DevOps Ingenieur |
AWS KMS Schlüssel aufräumen. | Wenn Sie benutzerdefinierte AWS KMS Schlüssel für die Verschlüsselung erstellt haben, gehen Sie wie folgt vor:
| DevOps Ingenieur |
Überprüfen und löschen Sie CloudWatch Amazon-Protokolle. | Gehen Sie wie folgt vor, um die CloudWatch Protokolle zu löschen:
| DevOps Ingenieur |
Zugehörige Ressourcen
Zusätzliche Informationen
Nachdem Sie die Daten von Amazon Redshift nach Amazon S3 entladen haben, können Sie sie mit Amazon Athena analysieren.
Amazon Athena ist ein Big-Data-Abfrageservice, der nützlich ist, wenn Sie auf große Datenmengen zugreifen müssen. Sie können Athena verwenden, ohne Server oder Datenbanken bereitstellen zu müssen. Athena unterstützt komplexe Abfragen, und Sie können es für verschiedene Objekte ausführen.
Wie bei den meisten AWS-Services Fällen besteht der Hauptvorteil der Verwendung von Athena darin, dass es eine große Flexibilität bei der Ausführung von Abfragen ohne zusätzliche Komplexität bietet. Wenn Sie Athena verwenden, können Sie verschiedene Datentypen wie CSV und JSON in Amazon S3 abfragen, ohne den Datentyp zu ändern. Sie können Daten aus verschiedenen Quellen abfragen, auch aus externen AWS Quellen. Athena reduziert die Komplexität, da Sie keine Server verwalten müssen. Athena liest Daten direkt aus Amazon S3, ohne die Daten zu laden oder zu ändern, bevor Sie die Abfrage ausführen.
