REL13-BP02 Verwenden von definierten Wiederherstellungsstrategien, um die Wiederherstellungsziele zu erreichen
Definieren Sie eine Notfallwiederherstellungsstrategie (Disaster Recovery, DR), die den Wiederherstellungszielen Ihrer Workloads entspricht. Wählen Sie eine Strategie aus, z. B. Backup und Wiederherstellung, Standby (aktiv/passiv) oder Aktiv/Aktiv.
Gewünschtes Ergebnis: Für jede Workload gibt es eine definierte und implementierte DR-Strategie, mit der die Workload die DR-Ziele erreichen kann. DR-Strategien zwischen Workloads nutzen wiederverwendbare Muster (wie die zuvor beschriebenen Strategien),
Typische Anti-Muster:
-
Implementierung von inkonsistenten Wiederherstellungsprozeduren für Workloads mit ähnlichen DR-Zielen.
-
Die DR-Strategie muss im Notfall Ad-hoc umgesetzt werden.
-
Es gibt keinen Plan für die Notfallwiederherstellung.
-
Abhängigkeit von Vorgängen auf der Steuerebene während der Wiederherstellung.
Vorteile der Nutzung dieser bewährten Methode:
-
Durch die Nutzung definierter Wiederherstellungsstrategien können Sie verbreitet verwendete Tools und Testverfahren verwenden.
-
Die Verwendung definierter Wiederherstellungsstrategien verbessert den Wissensaustausch zwischen den Teams und die Implementierung der Notfallwiederherstellung für ihre Workloads.
Risikostufe, wenn diese bewährte Methode nicht eingeführt wird: Hoch. Ohne eine geplante, implementierte und getestete DR-Strategie ist es unwahrscheinlich, dass Sie Ihre Wiederherstellungsziele im Falle eines Notfalls erreichen.
Implementierungsleitfaden
Eine DR-Strategie beruht auf der Fähigkeit, Ihre Workload an einem Wiederherstellungsstandort bereitzustellen, wenn Ihr primärer Standort nicht mehr in der Lage ist, die Workload auszuführen. Die häufigsten Wiederherstellungsziele sind RTO und RPO, wie in REL13-BP01 Definieren von Wiederherstellungszielen bei Ausfällen und Datenverlusten besprochen.
Eine DR-Strategie, die mehrere Availability Zones (AZs) innerhalb eines einzigen AWS-Region umfasst, kann Katastrophenereignisse wie Brände, Überschwemmungen und größere Stromausfälle abfedern. Wenn es erforderlich ist, einen Schutz gegen ein unwahrscheinliches Ereignis zu implementieren, das verhindert, dass Ihre Workload in einer bestimmten AWS-Region ausgeführt werden kann, können Sie eine DR-Strategie verwenden, die mehrere Regionen nutzt.
Wenn Sie eine DR-Strategie für mehrere Regionen entwickeln, sollten Sie eine der folgenden Strategien wählen. Sie sind in aufsteigender Reihenfolge nach Kosten und Komplexität und in absteigender Reihenfolge nach RTO und RPO aufgeführt. Die Wiederherstellungsregion bezieht sich auf eine andere AWS-Region als die primäre Region, die für Ihre Workload verwendet wird.
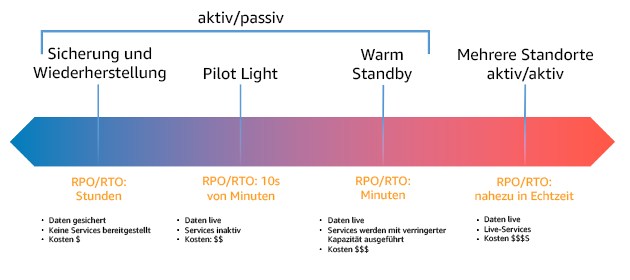
Abbildung 17: Strategien für die Notfallwiederherstellung (Disaster Recovery, DR)
-
Sicherung und Wiederherstellung (RPO in Stunden, RTO in 24 Stunden oder weniger): Sichern Sie Ihre Daten und Anwendungen in der Wiederherstellungsregion. Die Verwendung automatisierter oder kontinuierlicher Backups ermöglicht eine zeitpunktbezogene Wiederherstellung (PITR), wodurch das RPO in einigen Fällen auf bis zu 5 Minuten gesenkt werden kann. Im Falle eines Notfalls stellen Sie Ihre Infrastruktur bereit (wobei Sie Infrastruktur als Code verwenden, um das RTO zu verkürzen), stellen Ihren Code bereit und stellen die gesicherten Daten wieder her, um eine Wiederherstellung nach einem Notfall in der Wiederherstellungsregion zu erfahren.
-
Pilot Light (RPO in Minuten, RTO in 10-Minuten-Intervallen): Stellen Sie eine Kopie Ihrer Kern-Workload-Infrastruktur in der Wiederherstellungsregion bereit. Replizieren Sie Ihre Daten in die Wiederherstellungsregion und erstellen Sie dort Sicherungskopien der Daten. Ressourcen, die zur Unterstützung der Datenreplikation und -sicherung erforderlich sind, wie Datenbanken und Objektspeicher, sind immer eingeschaltet. Andere Elemente wie Anwendungsserver oder Serverless-Datenverarbeitung werden nicht bereitgestellt, sondern können bei Bedarf mit der erforderlichen Konfiguration und dem Anwendungscode erstellt werden.
-
Warm Standby (RPO in Sekunden, RTO in Minuten): Eine herunterskalierte, aber voll funktionsfähige Version Ihrer Workload wird dauerhaft in der Wiederherstellungsregion ausgeführt. Geschäftskritische Systeme sind vollständig dupliziert und ständig aktiv, aber mit herunterskalierter Flotte. Die Daten werden repliziert und sind in der Wiederherstellungsregion live. Wenn eine Wiederherstellung erforderlich ist, wird das System zur Bewältigung der Produktionslast schnell hochskaliert. Je höher die Skalierung des Warm Standby, desto geringer ist die Abhängigkeit von RTO und Steuerebene. Bei vollständiger Skalierung wird dies als Hot Standby bezeichnet.
-
Regionsübergreifend (Multi-Site) Aktiv/Aktiv (RPO nahe Null, RTO potenziell Null): Ihre Workload wird auf mehrere AWS-Regionen verteilt und stellt aktiv Datenverkehr daraus aus. Bei dieser Strategie müssen Sie die Daten zwischen den Regionen synchronisieren. Mögliche Konflikte, die durch Schreibvorgänge auf denselben Datensatz in zwei verschiedenen regionalen Repliken verursacht werden, müssen vermieden oder behandelt werden, was sehr komplex sein kann. Die Datenreplikation ist nützlich für die Datensynchronisation und schützt Sie vor einigen Arten von Notfällen, aber sie schützt Sie nicht vor Datenbeschädigung oder -zerstörung, es sei denn, Ihre Lösung umfasst auch Optionen für eine zeitpunktbezogene Wiederherstellung.
Anmerkung
Der Unterschied zwischen Pilot Light und Warm Standby kann schwer zu überblicken sein. Beide beinhalten eine Umgebung in Ihrer Wiederherstellungsregion mit Kopien der Assets Ihrer Primärregion. Der Unterschied besteht darin, dass Pilot Light keine Anfragen bearbeiten kann, ohne dass zuvor zusätzliche Maßnahmen ergriffen werden, während Warm Standby den Datenverkehr (mit reduzierter Kapazität) sofort bearbeiten kann. Bei Pilot Light müssen Sie die Server einschalten, möglicherweise zusätzliche (nicht zum Kerngeschäft gehörende) Infrastruktur bereitstellen und die Leistung hochskalieren, während Sie bei Warm-Standby nur die Leistung hochskalieren müssen (alles ist bereits bereitgestellt und läuft). Wählen Sie je nach RTO- und RPO-Anforderungen zwischen diesen Varianten.
Wenn die Kosten eine Rolle spielen und Sie ähnliche RPO- und RTO-Ziele wie bei der Warm-Standby-Strategie erreichen möchten, könnten Sie cloudnative Lösungen wie AWS Elastic Disaster Recovery in Betracht ziehen, die den Pilot-Light-Ansatz verfolgen und bessere RPO- und RTO-Ziele bieten.
Implementierungsschritte
-
Bestimmen Sie eine DR-Strategie, die die Wiederherstellungsanforderungen für diese Workload erfüllt.
Die Wahl einer DR-Strategie ist eine Abwägung zwischen der Reduzierung von Ausfallzeiten und Datenverlusten (RTO und RPO) und den Kosten und der Komplexität der Implementierung der Strategie. Sie sollten vermeiden, eine Strategie zu verfolgen, die strikter ist als nötig, da dies unnötige Kosten verursacht.
Im folgenden Diagramm hat das Unternehmen beispielsweise sein maximal zulässiges RTO sowie die Grenze der Ausgaben für seine Strategie zur Wiederherstellung von Diensten festgelegt. In Anbetracht der Ziele des Unternehmens erfüllen die DR-Strategien Pilot Light oder Warm Standby sowohl die RTO- als auch die Kostenkriterien.
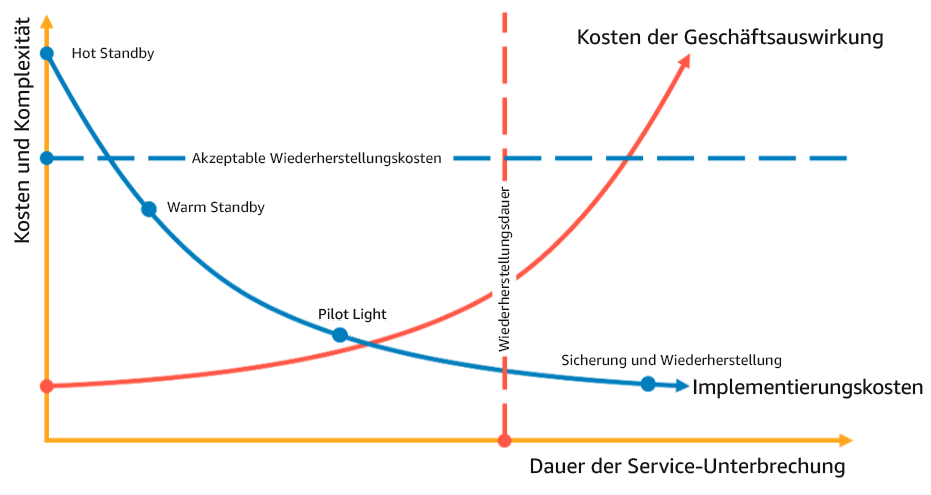
Abbildung 18: Auswahl einer DR-Strategie auf der Grundlage von RTO und Kosten
Weitere Informationen finden Sie unter Geschäftsfortführungsplan.
-
Sehen Sie sich anhand der Muster an, wie die gewählte DR-Strategie umgesetzt werden kann.
In diesem Schritt geht es darum, zu verstehen, wie Sie die gewählte Strategie umsetzen wollen. Die Strategien werden durch die Verwendung von AWS-Regionen als primäre und Wiederherstellungsstandort erläutert. Sie können jedoch auch Availability Zones innerhalb einer einzigen Region als DR-Strategie verwenden, die Elemente mehrerer dieser Strategien nutzt.
In den folgenden Schritten können Sie die Strategie auf Ihre spezifische Workload anwenden.
Backup und Wiederherstellung
Backup und Wiederherstellung ist die einfachste Strategie zur Implementierung, erfordert jedoch mehr Zeit- und Arbeitsaufwand bei der Wiederherstellung der Workload, was zu einem höheren RTO und RPO führt. Es ist eine gute Vorgehensweise, immer Sicherungskopien Ihrer Daten zu erstellen und diese auf einen anderen Standort (z. B. einen anderen AWS-Region) zu kopieren.
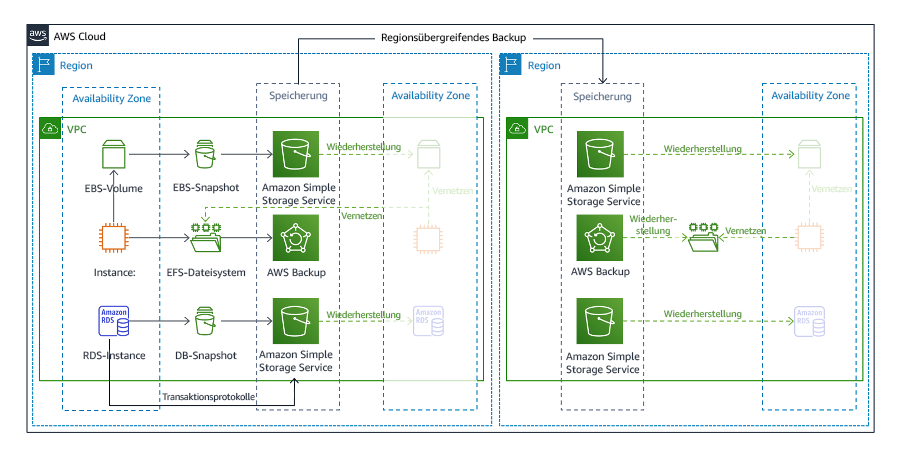
Abbildung 19: Backup- und Wiederherstellungsarchitektur
Weitere Informationen zu dieser Strategie finden Sie unter Architektur für die Notfallwiederherstellung in AWS, Teil II: Sicherung und Wiederherstellung mit Rapid Recovery
. Pilot light
Beim Pilot-Light-Ansatz replizieren Sie die Daten von Ihrer primären Region in Ihre Wiederherstellungsregion. Die Kernressourcen, die für die Workload-Infrastruktur verwendet werden, werden in der Wiederherstellungsregion bereitgestellt, jedoch werden noch zusätzliche Ressourcen und Abhängigkeiten benötigt, um diesen Stack funktionsfähig zu machen. In Abbildung 20 werden zum Beispiel keine Datenverarbeitungs-Instances bereitgestellt.
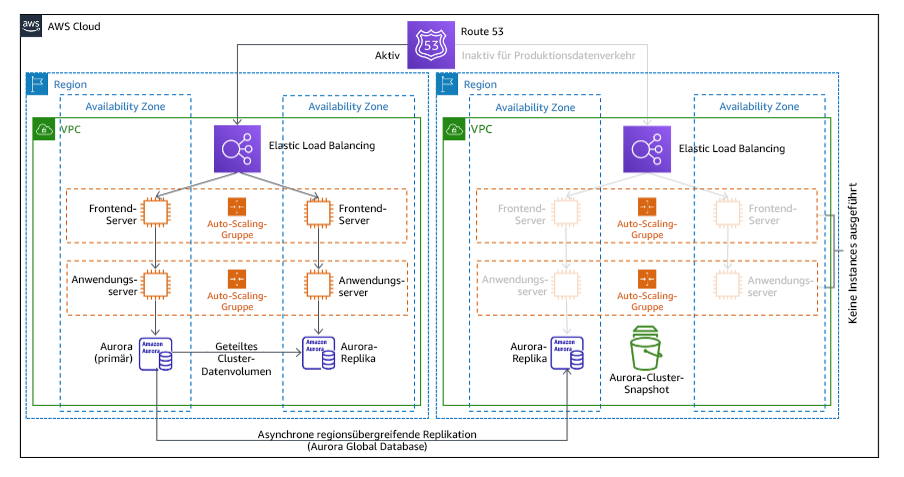
Abbildung 20: Pilot-Light-Architektur
Weitere Informationen zu dieser Strategie finden Sie unter Architektur für die Notfallwiederherstellung in AWS, Teil III: Pilot Light und Warm Standby
. Warmer Bereitschaftsmodus
Beim Warm-Standby-Ansatz wird sichergestellt, dass eine herunterskalierte, aber voll funktionsfähige Kopie Ihrer Produktionsumgebung in einer anderen Region vorhanden ist. Dieser Ansatz erweitert das Konzept des Pilot Light und verkürzt die Zeit bis zur Wiederherstellung, da die Workload in einer anderen Region ständig präsent ist. Wenn die Wiederherstellungsregion mit voller Kapazität bereitgestellt wird, wird dies als Hot Standby bezeichnet.
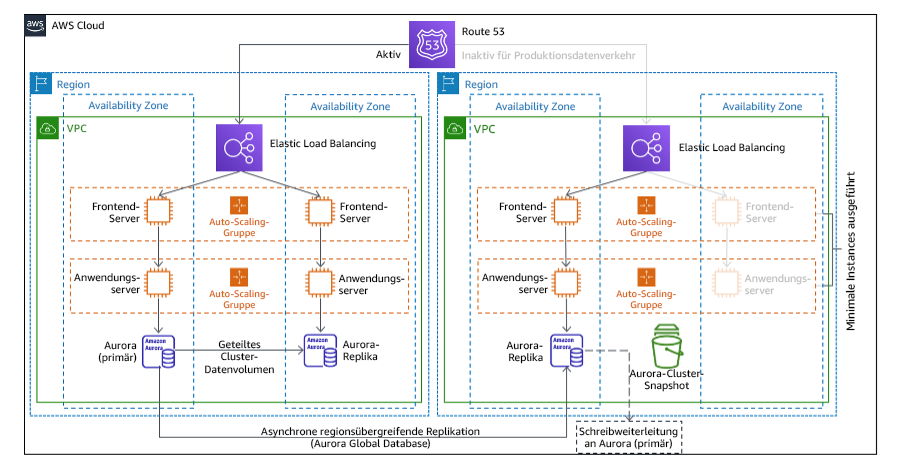
Abbildung 21: Warm-Standby-Architektur
Der Einsatz von Warm Standby oder Pilot Light erfordert ein Hochskalieren der Ressourcen in der Wiederherstellungsregion. Um zu überprüfen, ob bei Bedarf Kapazität verfügbar ist, sollten Sie die Nutzung von Kapazitätsreservierungen für EC2-Instances in Betracht ziehen. Wenn Sie AWS Lambda verwenden, kann die bereitgestellte Parallelität Laufzeitumgebungen bereitstellen, damit sie sofort auf die Aufrufe Ihrer Funktion reagieren können.
Weitere Informationen zu dieser Strategie finden Sie unter Architektur für die Notfallwiederherstellung in AWS, Teil III: Pilot Light und Warm Standby
. Multi-Site Aktiv/Aktiv
Im Rahmen einer Multi-Site Aktiv/Aktiv-Strategie können Sie Ihre Workload in mehreren Regionen gleichzeitig ausführen. Multi-Site Aktiv/Aktiv bedient den Datenverkehr aus allen Regionen, in denen es eingesetzt wird. Diese Strategie kann zur Erhöhung der Verfügbarkeit oder bei der Bereitstellung einer Workload für eine globale Zielgruppe verwendet werden (um den Endpunkt näher an die Benutzer zu bringen und/oder um Stacks bereitzustellen, die für die Zielgruppe in dieser Region lokalisiert sind). Wenn die Workload in einer der AWS-Regionen, in denen sie bereitgestellt wird, nicht unterstützt werden kann, wird diese Region evakuiert und die verbleibenden Regionen werden zur Aufrechterhaltung der Verfügbarkeit genutzt. Multi-Site Aktiv/Aktiv ist die betrieblich komplexeste der DR-Strategien und sollte nur dann gewählt werden, wenn die Geschäftsanforderungen dies erfordern.
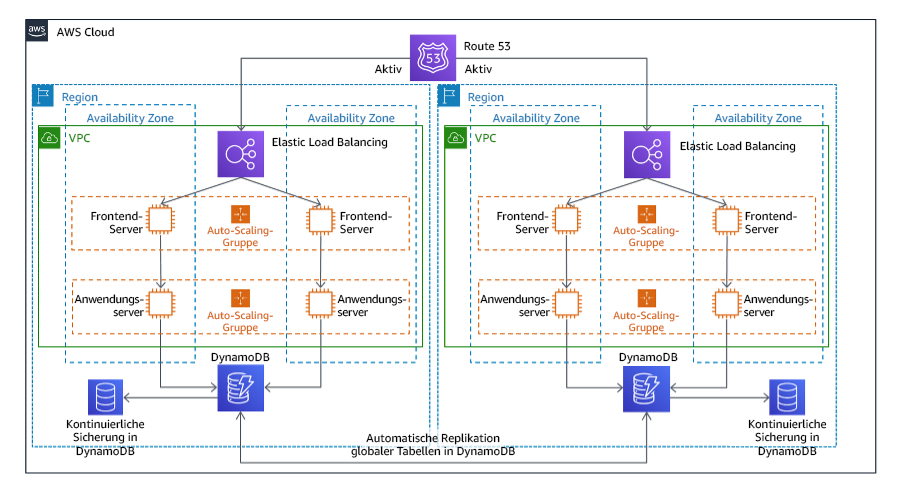
Abbildung 22: Multi-Site Aktiv/Aktiv-Architektur
Weitere Informationen zu dieser Strategie finden Sie unter Architektur für die Notfallwiederherstellung in AWS, Teil IV: Multi-Site Aktiv/Aktiv
. AWS Elastic Disaster Recovery
Wenn Sie für die Notfallwiederherstellung die Pilot-Light- oder Warm-Standby-Strategie in Betracht ziehen, könnte AWS Elastic Disaster Recovery einen alternativen Ansatz mit verbesserten Vorteilen bieten. Elastic Disaster Recovery kann ein ähnliches RPO- und RTO-Ziel wie Warm Standby bieten, behält aber den kostengünstigen Ansatz von Pilot Light bei. Elastic Disaster Recovery repliziert Ihre Daten von Ihrer primären Region auf Ihre Wiederherstellungsregion und nutzt dabei die kontinuierliche Datensicherung, um ein RPO im Sekundenbereich und ein RTO im Minutenbereich zu erreichen. In der Wiederherstellungsregion werden nur die für die Replikation der Daten erforderlichen Ressourcen bereitgestellt, was die Kosten ähnlich wie bei der Pilot-Light-Strategie niedrig hält. Bei Verwendung von Elastic Disaster Recovery koordiniert und orchestriert der Service die Wiederherstellung von Datenverarbeitungs-Ressourcen, wenn die Initiierung als Teil eines Failover oder Drills erfolgt.
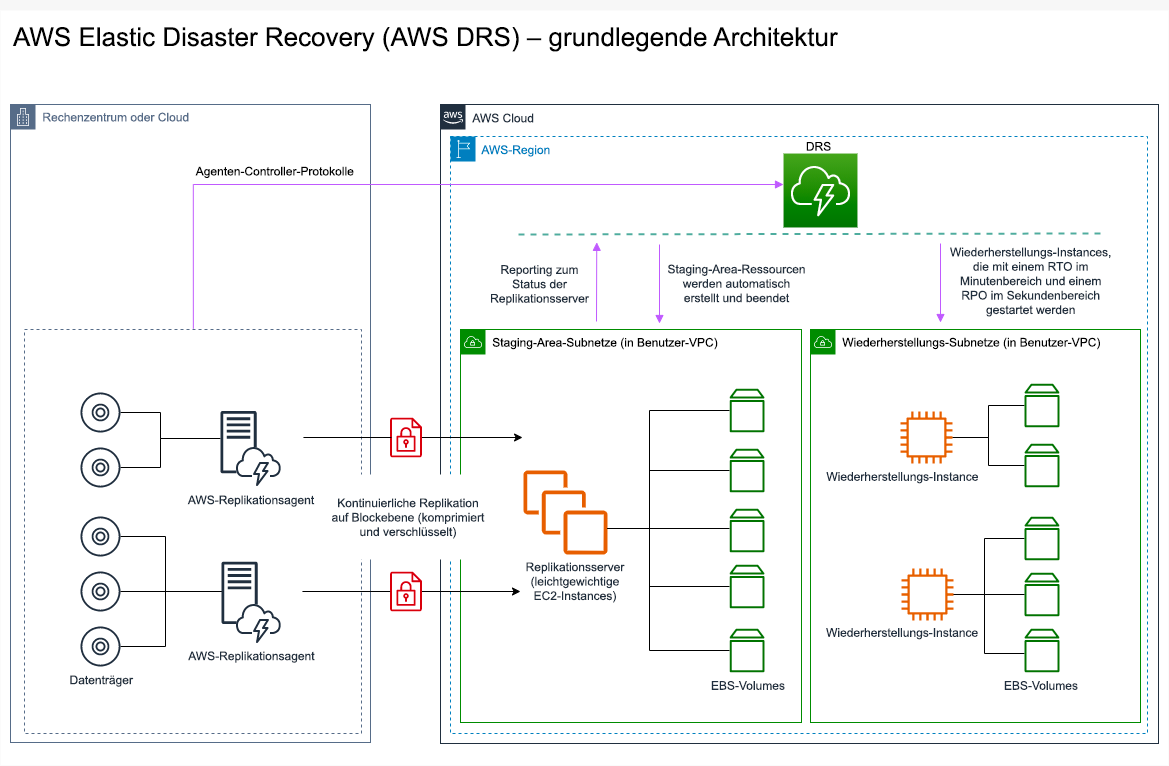
Abbildung 23: AWS Elastic Disaster Recovery-Architektur
Zusätzliche Methoden zum Schutz von Daten
Bei allen Strategien müssen Sie sich auch gegen einen Datennotfall wappnen. Kontinuierliche Datenreplikation schützt Sie vor einigen Arten von Notfällen, aber sie schützt Sie möglicherweise nicht vor Datenbeschädigung oder -zerstörung, es sei denn, Ihre Strategie umfasst auch die Versionsverwaltung gespeicherter Daten oder Optionen für eine zeitpunktbezogene Wiederherstellung. Sie müssen auch die replizierten Daten in der Wiederherstellungssite sichern, um zusätzlich zu den Replikaten zeitpunktgenaue Sicherungen zu erstellen.
Verwendung mehrerer Availability Zones (AZs) innerhalb einer einzigen AWS-Region
Wenn Sie mehrere AZs in einer einzigen Region verwenden, nutzt Ihre DR-Implementierung mehrere Elemente der oben genannten Strategien. Zunächst müssen Sie eine Hochverfügbarkeitsarchitektur (High Availability, HA) mit mehreren AZs erstellen, wie in Abbildung 23 dargestellt. Diese Architektur verwendet einen Multi-Site Aktiv/Aktiv-Ansatz, da die Amazon EC2-Instances und der Elastic Load Balancer über Ressourcen verfügen, die in mehreren AZs bereitgestellt werden und Anfragen aktiv bearbeiten. Die Architektur demonstriert auch Hot Standby, d. h. bei einem Ausfall der primären Amazon RDS-Instance (oder der AZ selbst) wird die Standby-Instance zur primären Instance hochgestuft.
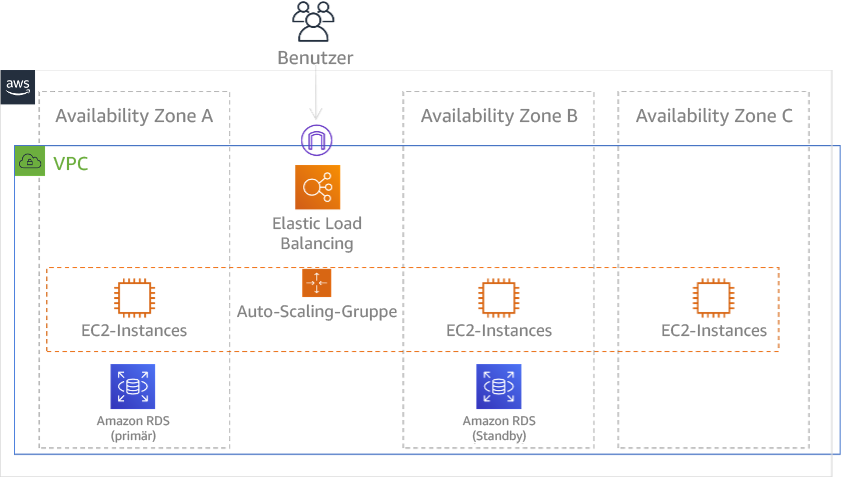
Abbildung 24: Multi-AZ-Architektur
Zusätzlich zu dieser HA-Architektur müssen Sie Backups aller Daten hinzufügen, die für die Ausführung Ihrer Workloads erforderlich sind. Dies ist besonders wichtig für Daten, die auf eine einzelne Zone beschränkt sind, etwa Amazon-EBS-Volumes oder Amazon-Redshift-Cluster. Wenn eine AZ ausfällt, müssen Sie diese Daten in einer anderen AZ wiederherstellen. Wenn möglich, sollten Sie auch Datensicherungen auf einen anderen AWS-Region kopieren, um eine zusätzliche Sicherheit zu gewährleisten.
Ein weniger verbreiteter alternativer Ansatz für einzelne Regionen, die Multi-AZ-Notfallwiederherstellung, wird im Blogbeitrag Entwickeln hoch resilienter Anwendungen mit Amazon Application Recovery Controller, Teil 1: Stack für eine einzelne Region
beschrieben. Hier besteht die Strategie darin, so viel Isolation wie möglich zwischen den AZs aufrechtzuerhalten, ähnlich wie bei den Regionen. Bei dieser alternativen Strategie können Sie sich für einen Aktiv/Aktiv- oder Aktiv/Passiv-Ansatz entscheiden. Anmerkung
Für einige Workloads gibt es gesetzliche Vorschriften im Hinblick auf die Datenresidenz. Wenn dies auf Ihre Workload in einer Region zutrifft, in der es derzeit nur eine AWS-Region gibt, dann ist die Multi-Region für Ihre geschäftlichen Anforderungen nicht geeignet. Multi-AZ-Strategien bieten einen guten Schutz gegen die meisten Notfälle.
-
Bewerten Sie vor dem Failover (während des normalen Betriebs) die Ressourcen Ihrer Workloads und deren Konfiguration in der Wiederherstellungsregion.
Verwenden Sie für Infrastruktur- und AWS-Ressourcen Infrastruktur als Code, etwa AWS CloudFormation
oder Tools von Drittanbietern wie Hashicorp Terraform. Um die Bereitstellung über mehrere Konten und Regionen hinweg mit einer einzigen Operation durchzuführen, können Sie AWS CloudFormation StackSets verwenden. Bei Multi-Site-Aktiv/Aktiv- und Hot-Standby-Strategien verfügt die in Ihrer Wiederherstellungsregion bereitgestellte Infrastruktur über dieselben Ressourcen wie Ihre Primärregion. Bei den Strategien Pilot Light und Warm Standby sind zusätzliche Maßnahmen erforderlich, um die Infrastruktur produktionsreif zu machen. Mithilfe von CloudFormation-Parametern und bedingter Logik können Sie mit einer einzigen Vorlage steuern, ob ein bereitgestellter Stack aktiv oder im Standby-Modus ist. Wenn Sie Elastic Disaster Recovery verwenden, repliziert und orchestriert der Service die Wiederherstellung von Anwendungskonfigurationen und Datenverarbeitungs-Ressourcen. Alle DR-Strategien erfordern, dass Datenquellen innerhalb der AWS-Region gesichert werden und diese Backups anschließend in die Wiederherstellungsregion kopiert werden. AWS Backup
bietet eine zentrale Ansicht, in der Sie Backups für diese Ressourcen konfigurieren, planen und überwachen können. Für Pilot Light, Warm Standby und Multi-Site Aktiv/Aktiv sollten Sie auch Daten aus der primären Region auf Datenressourcen in der Wiederherstellungsregion replizieren, etwa Amazon Relational Database Service (Amazon RDS) -DB-Instances oder Amazon DynamoDB -Tabellen. Diese Datenressourcen sind daher aktiv und bereit, Anfragen in der Wiederherstellungsregion zu bedienen. Weitere Informationen darüber, wie AWS-Services in verschiedenen Regionen funktionieren, finden Sie in der Blogserie Erstellen einer regionsübergreifenden Anwendung mit AWS
. -
Ermitteln und implementieren Sie, wie Sie Ihre Wiederherstellungsregion bei Bedarf (im Notfall) auf ein Failover vorbereiten.
Bei Multi-Site Aktiv/Aktiv bedeutet Failover, dass eine Region evakuiert wird und die verbleibenden aktiven Regionen genutzt werden. Im Allgemeinen sind diese Regionen bereit, Datenverkehr aufzunehmen. Bei den Strategien Pilot Light und Warm Standby müssen Ihre Wiederherstellungsmaßnahmen die fehlenden Ressourcen bereitstellen, z. B. die EC2-Instances in Abbildung 20, sowie alle anderen fehlenden Ressourcen.
Bei allen oben genannten Strategien müssen Sie möglicherweise schreibgeschützte Instances von Datenbanken zur primären Lese-/Schreib-Instance machen.
Bei der Sicherung und Wiederherstellung werden durch die Wiederherstellung von Daten aus der Sicherung Ressourcen für diese Daten wie EBS-Volumes, RDS-DB-Instances und DynamoDB-Tabellen erstellt. Außerdem müssen Sie die Infrastruktur wiederherstellen und Code bereitstellen. Sie können AWS Backup nutzen, um Daten in der Wiederherstellungsregion wiederherzustellen. Weitere Details finden Sie unter REL09-BP01 Ermitteln und Sichern aller zu sichernden Daten oder Reproduzieren der Daten aus Quellen. Der Wiederaufbau der Infrastruktur umfasst die Erstellung von Ressourcen wie EC2-Instances zusätzlich zur Amazon Virtual Private Cloud (Amazon VPC)
, zu Subnetzen und zu benötigten Sicherheitsgruppen. Sie können einen Großteil des Wiederherstellungsprozesses automatisieren. Wie das geht, erfahren Sie in diesem Blogbeitrag . -
Ermitteln und implementieren Sie, wie Sie den Datenverkehr bei Bedarf (im Notfall) zum Failover umleiten.
Dieser Failover-Vorgang kann entweder automatisch oder manuell eingeleitet werden. Ein automatisch eingeleiteter Failover auf der Grundlage von Zustandsprüfungen oder Alarmen ist mit Vorsicht zu genießen, da ein unnötiger Failover (Fehlalarm) Kosten wie Nichtverfügbarkeit und Datenverlust verursacht. Daher wird häufig ein manuell initiierter Failover verwendet. In diesem Fall sollten Sie die Schritte für den Failover dennoch automatisieren, sodass die manuelle Auslösung wie ein Knopfdruck wirkt.
Bei der Inanspruchnahme von AWS-Services gibt es mehrere Optionen für die Verwaltung des Datenverkehrs zu berücksichtigen. Eine Option ist die Verwendung von Amazon Route 53.
Mit Amazon Route 53 können Sie mehrere IP-Endpunkte in einem oder mehreren AWS-Regionen mit einem Route-53-Domainnamen verknüpfen. Um ein manuell eingeleitetes Failover zu implementieren, können Sie Amazon Application Recovery Controller verwenden, das eine hochverfügbare Datenebenen-API zur Umleitung des Datenverkehrs in die Wiederherstellungsregion bereitstellt. Verwenden Sie bei der Implementierung von Failover Vorgänge auf der Datenebene und vermeiden Sie solche auf der Steuerebene, wie in REL11-BP04 Verlassen Sie sich bei der Wiederherstellung auf die Datenebene und nicht auf die Steuerebene beschrieben. Weitere Informationen zu diesen und anderen Optionen finden Sie in diesem Abschnitt des Whitepapers zur Notfallwiederherstellung.
-
Entwerfen Sie einen Plan für das Failback Ihrer Workload.
Failback bedeutet, dass Sie den Workload-Betrieb in der primären Region wieder aufnehmen, nachdem ein Notfallereignis abgeklungen ist. Die Bereitstellung von Infrastruktur und Code für die primäre Region erfolgt im Allgemeinen in denselben Schritten wie ursprünglich, wobei Infrastruktur als Code und Code-Bereitstellungspipelines verwendet werden. Die Herausforderung beim Failback ist die Wiederherstellung von Datenspeichern und die Sicherstellung ihrer Konsistenz mit der in Betrieb befindlichen Wiederherstellungsregion.
Im ausgefallenen Zustand sind die Datenbanken in der Wiederherstellungsregion aktiv und verfügen über die aktuellen Daten. Ziel ist es dann, eine erneute Synchronisierung von der Wiederherstellungsregion mit der primären Region vorzunehmen, um sicherzustellen, dass diese auf dem neuesten Stand ist.
Einige AWS-Services werden das automatisch tun. Wenn Sie globale Amazon DynamoDB-Tabellen
verwenden, setzt DynamoDB die Propagierung aller ausstehenden Schreibvorgänge fort, sobald die Tabelle wieder online ist, auch wenn sie in der primären Region nicht mehr verfügbar war. Wenn Sie Amazon Aurora Global Database und ein verwaltetes geplantes Failover verwenden, wird die vorhandene Replikationstopologie der globalen Aurora-Datenbank beibehalten. Daher wird die ehemalige Lese-/Schreib-Instance in der primären Region zu einem Replikat und erhält Aktualisierungen von der Wiederherstellungsregion. In Fällen, in denen dies nicht automatisch geschieht, müssen Sie die Datenbank in der primären Region als Replikat der Datenbank in der Wiederherstellungsregion neu einrichten. In vielen Fällen bedeutet dies, dass die alte primäre Datenbank gelöscht und neue Replikate erstellt werden müssen.
Wenn Sie nach einem Failover in Ihrer Wiederherstellungsregion weiterarbeiten können, sollten Sie diese zur neuen Primärregion machen. Sie würden trotzdem alle oben genannten Schritte durchführen, um die ehemalige Primärregion in eine Wiederherstellungsregion zu verwandeln. Einige Unternehmen führen eine planmäßige Rotation durch und tauschen ihre Primär- und Wiederherstellungsregionen in regelmäßigen Abständen aus (z. B. alle drei Monate).
Alle für Failover und Failback erforderlichen Schritte sollten in einem Playbook festgehalten werden, das allen Teammitgliedern zur Verfügung steht und regelmäßig überprüft wird.
Wenn Sie Elastic Disaster Recovery verwenden, hilft der Service bei der Orchestrierung und Automatisierung des Failback-Prozesses. Weitere Informationen finden Sie unter Durchführen eines Failbacks.
Aufwand für den Implementierungsplan: Hoch
Ressourcen
Zugehörige bewährte Methoden:
Zugehörige Dokumente:
-
Notfallwiederherstellung von Workloads in AWS: Wiederherstellung in der Cloud (AWS-Whitepaper)
-
Entwickeln einer Multi-Region-Serverless-Backend-Lösung, die aktiv/aktiv ist
-
APN-Partner: Partner, die Sie bei der Notfallwiederherstellung unterstützen können
-
AWS Marketplace: Für die Notfallwiederherstellung geeignete Produkte
Zugehörige Videos:
