Working with DB instance read replicas
A read replica is a read-only copy of a DB instance. You can reduce the load on your primary DB instance by routing queries from your applications to the read replica. In this way, you can elastically scale out beyond the capacity constraints of a single DB instance for read-heavy database workloads.
To create a read replica from a source DB instance, Amazon RDS uses the built-in replication features of the DB engine. For information about using read replicas with a specific engine, see the following sections:
After you create a read replica from a source DB instance, the source becomes the primary DB instance. When you make updates to the primary DB instance, Amazon RDS copies them asynchronously to the read replica. The following diagram shows a source DB instance replicating to a read replica in a different Availability Zone (AZ). Clients have read/write access to the primary DB instance and read-only access to the replica.
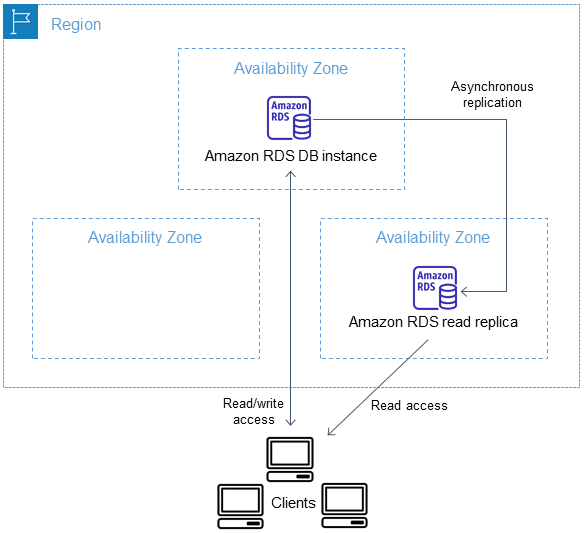
Read replicas are billed as standard DB instances at the same rates as the DB instance class used for the replica. You aren't charged for the data transfer incurred in replicating data between the source DB instance and a read replica within the same AWS Region. For more information, see Cross-Region replication costs and DB instance billing for Amazon RDS .
Topics
Overview of Amazon RDS read replicas
The following sections discuss DB instance read replicas. For information about Multi-AZ DB cluster read replicas, see Working with Multi-AZ DB cluster read replicas for Amazon RDS.
Topics
Use cases for read replicas
Deploying one or more read replicas for a given source DB instance might make sense in a variety of scenarios, including the following:
-
Scaling beyond the compute or I/O capacity of a single DB instance for read-heavy database workloads. You can direct this excess read traffic to one or more read replicas.
-
Serving read traffic while the source DB instance is unavailable. In some cases, your source DB instance might not be able to take I/O requests, for example due to I/O suspension for backups or scheduled maintenance. In these cases, you can direct read traffic to your read replicas. For this use case, keep in mind that the data on the read replica might be "stale" because the source DB instance is unavailable.
-
Business reporting or data warehousing scenarios where you might want business reporting queries to run against a read replica, rather than your production DB instance.
-
Implementing disaster recovery. You can promote a read replica to a standalone instance as a disaster recovery solution if the primary DB instance fails.
How read replicas work
When you create a read replica, you specify an existing DB instance as the source. Then Amazon RDS takes a snapshot of the source instance and creates a read-only instance from the snapshot. Amazon RDS then uses the asynchronous replication method for the DB engine to update the read replica whenever there is a change to the primary DB instance.
The read replica operates as a DB instance that allows only read-only connections. Exceptions are the RDS for Db2 and the RDS for Oracle DB engines, which support replica databases in standby mode and mounted mode, respectively. A standby replica and mounted replica don't accept user connections and so can't serve read-only workloads. The primary use for standby replicas and mounted replicas is cross-Region disaster recovery. For more information, see Working with replicas for Amazon RDS for Db2 and Working with read replicas for Amazon RDS for Oracle.
Applications connect to a read replica just as they do to any DB instance. Amazon RDS replicates all databases from the source DB instance.
You must manually create read replicas. RDS doesn't support autoscaling of read replicas, which is the automatic add or removing of read replicas as read demand changes.
Read replicas in a Multi-AZ deployment
You can configure a read replica for a DB instance that also has a standby replica configured for high availability in a Multi-AZ deployment. Replication with the standby replica is synchronous. Unlike a read replica, a standby replica can't serve read traffic.
In the following scenario, clients have read/write access to a primary DB instance in one AZ. The primary instance copies updates asynchronously to a read replica in a second AZ and also copies them synchronously to a standby replica in a third AZ. Clients have read access only to the read replica.
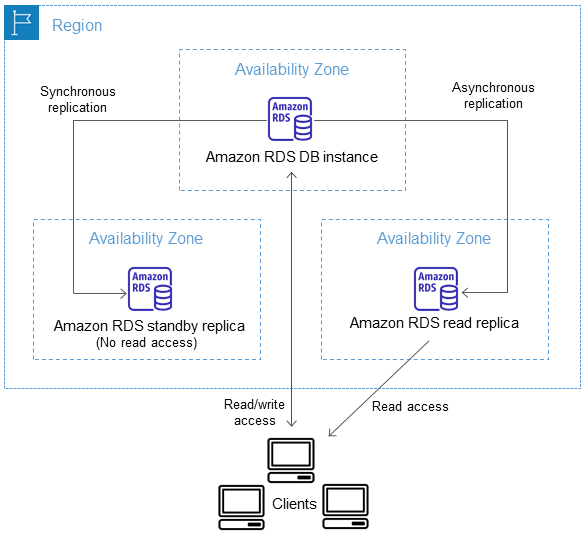
For more information about high availability and standby replicas, see Configuring and managing a Multi-AZ deployment for Amazon RDS.
Cross-Region read replicas
In some cases, a read replica resides in a different AWS Region from its primary DB instance. In these cases, Amazon RDS sets up a secure communications channel between the primary DB instance and the read replica. Amazon RDS establishes any AWS security configurations needed to enable the secure channel, such as adding security group entries. For more information about cross-Region read replicas, see Creating a read replica in a different AWS Region.
The information in this chapter applies to creating Amazon RDS read replicas either in the same AWS Region as the source DB instance, or in a separate AWS Region. The following information doesn't apply to setting up replication with an instance that is running on an Amazon EC2 instance or that is on-premises.
Read replica storage types
By default, a read replica is created with the same storage type as the source DB instance. However, you can create a read replica that has a different storage type from the source DB instance based on the options listed in the following table.
| Source DB instance storage type | Source DB instance storage allocation | Read replica storage type options |
|---|---|---|
| Provisioned IOPS | 100 GiB–64 TiB | Provisioned IOPS, General Purpose, Magnetic |
| General Purpose | 100 GiB–64 TiB | Provisioned IOPS, General Purpose, Magnetic |
| General Purpose | <100 GiB | General Purpose, Magnetic |
| Magnetic | 100 GiB–6 TiB | Provisioned IOPS, General Purpose, Magnetic |
| Magnetic | <100 GiB | General Purpose, Magnetic |
Note
When you increase the allocated storage of a read replica, it must be by at least 10 percent. If you try to increase the value by less than 10 percent, you get an error.
Restrictions for creating a replica from a replica
Amazon RDS doesn't support circular replication. You can't configure a DB instance to serve as a
replication source for an existing DB instance. You can only create a new read replica from an
existing DB instance. For example, if MySourceDBInstance replicates to
ReadReplica1, you can't configure
ReadReplica1 to replicate back to
MySourceDBInstance.
For RDS for MariaDB and RDS for MySQL, and for certain versions of RDS for PostgreSQL, you can
create a read replica from an existing read replica. For example, you can create new
read replica ReadReplica2 from existing replica
ReadReplica1. For RDS for Db2, RDS for Oracle, and RDS for SQL Server, you
can't create a read replica from an existing read replica.
Considerations when deleting replicas
RDS doesn't support autoscaling of read replicas. Thus, RDS won't increase the number of replicas when demand increases or decrease the number of replicas when demand decreases. If you no longer need read replicas, manually delete them using the same mechanisms for deleting a DB instance. If you delete a source DB instance without deleting its read replicas in the same AWS Region, each replica is promoted to a standalone DB instance.
For information about deleting a DB instance, see Deleting a DB instance. For information about read replica promotion, see Promoting a read replica to be a standalone DB instance. For information related to deleting the source DB instance for a cross-Region read replica, see Cross-Region replication considerations.
