Las traducciones son generadas a través de traducción automática. En caso de conflicto entre la traducción y la version original de inglés, prevalecerá la version en inglés.
Desarrolle asistentes de chat de IA generativos avanzados mediante el uso de RAG y solicitudes ReAct
Praveen Kumar Jeyarajan, Shuai Cao, Noah Hamilton, Kiowa Jackson, Jundong Qiao y Kara Yang, de Amazon Web Services
Resumen
Una empresa típica tiene el 70 por ciento de sus datos atrapados en sistemas aislados. Puede utilizar asistentes generativos basados en el chat y basados en la inteligencia artificial para obtener información y relaciones entre estos silos de datos mediante interacciones en lenguaje natural. Para aprovechar al máximo la IA generativa, los resultados deben ser fiables, precisos e incluir los datos corporativos disponibles. El éxito de los asistentes basados en el chat depende de lo siguiente:
Modelos de IA generativa (como Anthropic Claude 2)
Vectorización de fuentes de datos
Técnicas de razonamiento avanzadas, como el ReAct marco
, para impulsar el modelo
Este patrón proporciona enfoques de recuperación de datos de fuentes de datos como los depósitos de Amazon Simple Storage Service (Amazon S3), AWS Glue y Amazon Relational Database Service (Amazon RDS). El valor se obtiene de esos datos intercalando la generación aumentada de recuperación (RAG) con los métodos. chain-of-thought Los resultados permiten mantener conversaciones complejas con asistentes por chat que se basan en la totalidad de los datos almacenados en su empresa.
Este patrón utiliza los SageMaker manuales de Amazon y las tablas de datos de precios como ejemplo para explorar las capacidades de un asistente generativo basado en el chat de IA. Crearás un asistente basado en el chat que ayude a los clientes a evaluar el SageMaker servicio respondiendo a preguntas sobre los precios y las capacidades del servicio. La solución utiliza una biblioteca Streamlit para crear la aplicación frontend y el LangChain marco para desarrollar el backend de la aplicación con la tecnología de un gran modelo de lenguaje (LLM).
Las consultas al asistente basado en el chat se responden con una clasificación inicial de intenciones para redirigirlas a uno de los tres posibles flujos de trabajo. El flujo de trabajo más sofisticado combina una orientación de asesoramiento general con un análisis de precios complejo. Puede adaptar el patrón para que se adapte a los casos de uso empresariales, corporativos e industriales.
Requisitos previos y limitaciones
Requisitos previos
Instalación y configuración de la interfaz de línea de comandos de AWS (AWS CLI)
Instalación y configuración del kit de herramientas AWS Cloud Development Kit (AWS CDK) 2.114.1 o posterior
Familiaridad básica con Python y AWS CDK
Git
instalado Python 3.11 o posterior
instalado y configurado (para obtener más información, consulte la sección Herramientas) Una cuenta de AWS activa iniciada mediante AWS CDK
El acceso a los modelos Amazon Titan y Anthropic Claude está habilitado en el servicio Amazon Bedrock
Credenciales de seguridad de AWS, incluida
AWS_ACCESS_KEY_ID, correctamente configuradas en su entorno de terminal
Limitaciones
LangChain no es compatible con todos los LLM para la transmisión. Los modelos Anthropic Claude son compatibles, pero los modelos de AI21 Labs no.
Esta solución se implementa en una única cuenta de AWS.
Esta solución solo se puede implementar en las regiones de AWS en las que estén disponibles Amazon Bedrock y Amazon Kendra. Para obtener información sobre la disponibilidad, consulte la documentación de Amazon Bedrock y Amazon Kendra.
Versiones de producto
Python versión 3.11 o posterior
Streamlit, versión 1.30.0 o posterior
Streamlit-Chat versión 0.1.1 o posterior
LangChain versión 0.1.12 o posterior
AWS CDK versión 2.132.1 o posterior
Arquitectura
Pila de tecnología de destino
Amazon Athena
Amazon Bedrock
Amazon Elastic Container Service (Amazon ECS)
AWS Glue
AWS Lambda
Amazon S3
Amazon Kendra
Elastic Load Balancing
Arquitectura de destino
El código de AWS CDK implementará todos los recursos necesarios para configurar la aplicación de asistente basada en chat en una cuenta de AWS. La aplicación de asistente basada en el chat que se muestra en el siguiente diagrama está diseñada para responder a las consultas SageMaker relacionadas de los usuarios. Los usuarios se conectan a través de un Application Load Balancer a una VPC que contiene un clúster de Amazon ECS que aloja la aplicación Streamlit. Una función Lambda de orquestación se conecta a la aplicación. Las fuentes de datos del bucket S3 proporcionan datos a la función Lambda a través de Amazon Kendra y AWS Glue. La función Lambda se conecta a Amazon Bedrock para responder a las consultas (preguntas) de los usuarios asistentes basados en el chat.
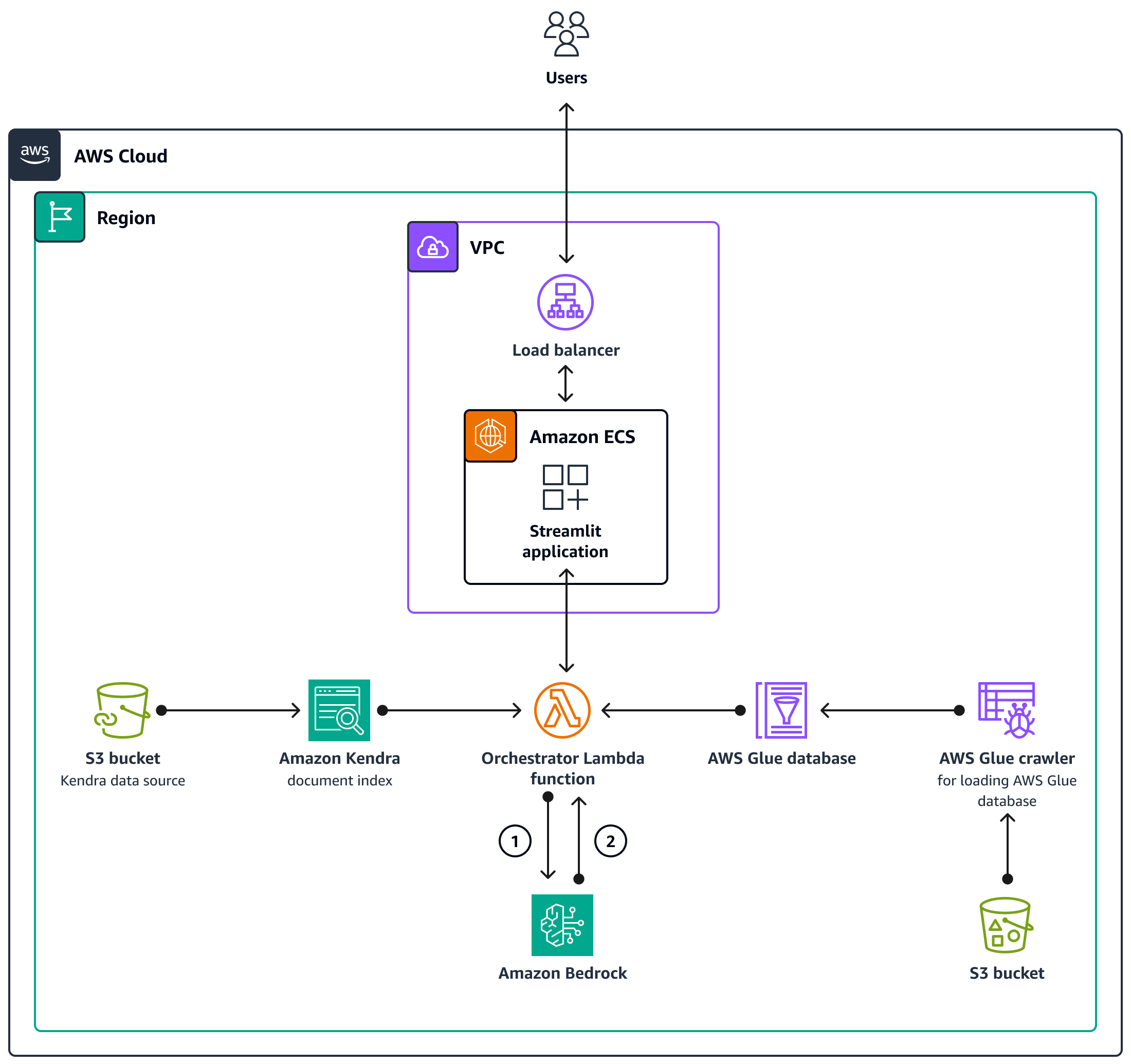
La función Lambda de orquestación envía la solicitud de solicitud LLM al modelo Amazon Bedrock (Claude 2).
Amazon Bedrock devuelve la respuesta LLM a la función Lambda de orquestación.
Flujo lógico dentro de la función Lambda de orquestación
Cuando los usuarios hacen una pregunta a través de la aplicación Streamlit, esta invoca directamente la función Lambda de orquestación. El siguiente diagrama muestra el flujo lógico cuando se invoca la función Lambda.
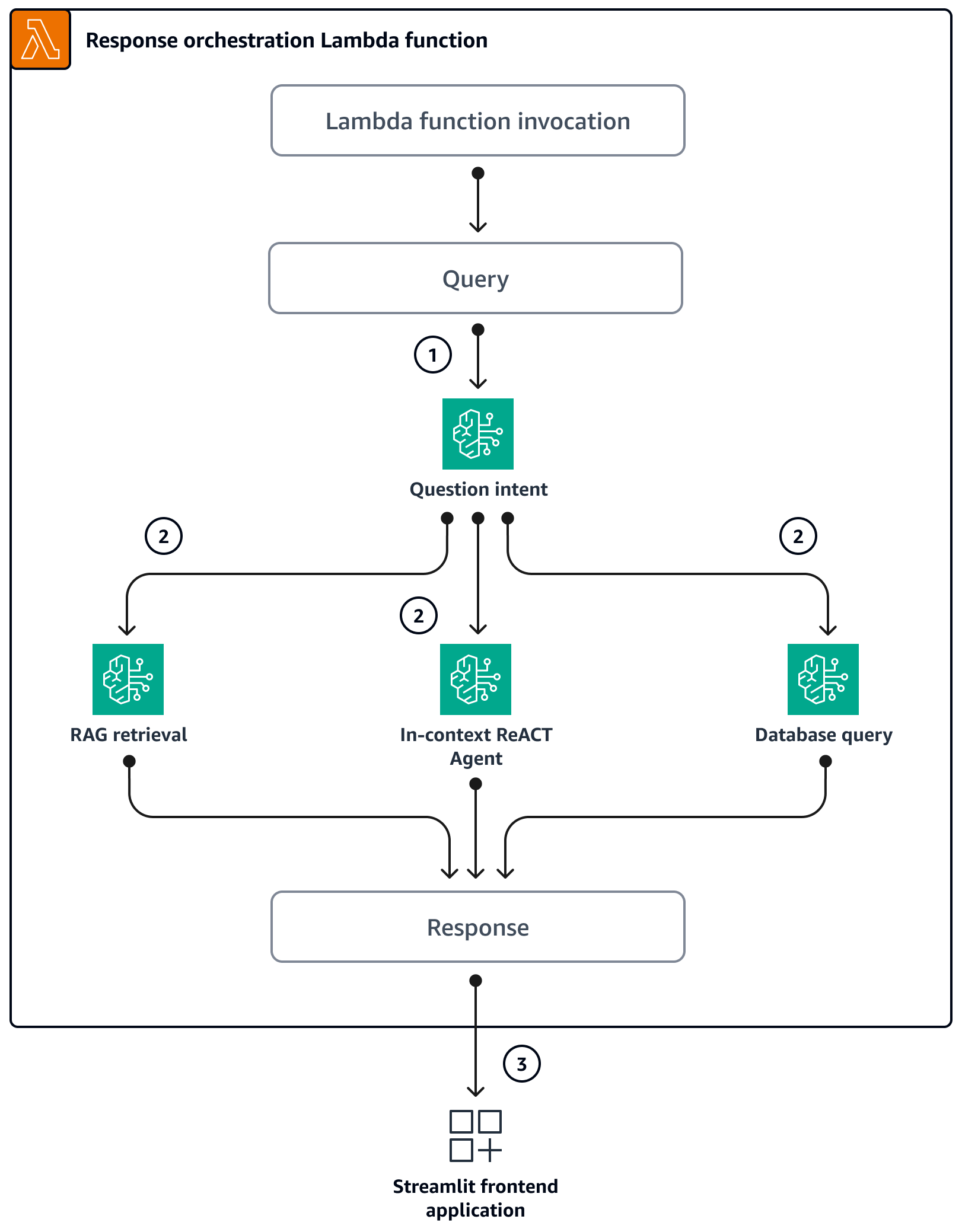
Paso 1: La entrada
query(pregunta) se clasifica en una de las tres intenciones:Preguntas de SageMaker orientación general
Preguntas generales SageMaker sobre precios (formación/inferencia)
Preguntas complejas relacionadas con los precios SageMaker
Paso 2: La entrada
queryinicia uno de los tres servicios:RAG Retrieval service, que recupera el contexto relevante de la base de datos vectorial de AmazonKendra y llama al LLM a través de Amazon Bedrock para resumir el contexto recuperado como respuesta. Database Query service, que utiliza el LLM, los metadatos de la base de datos y las filas de muestra de las tablas relevantes para convertir la entrada en una consulta SQL.queryEl servicio Database Query ejecuta la consulta SQL en la base de datos de SageMaker precios a través de Amazon Athenay resume los resultados de la consulta como respuesta. In-context ReACT Agent service, que divide la entradaqueryen varios pasos antes de proporcionar una respuesta. El agente utilizaRAG Retrieval serviceyDatabase Query servicecomo herramientas para recuperar información relevante durante el proceso de razonamiento. Una vez completados los procesos de razonamiento y acción, el agente genera la respuesta final como respuesta.
Paso 3: La respuesta de la función Lambda de orquestación se envía a la aplicación Streamlit como salida.
Herramientas
Servicios de AWS
Amazon Athena es un servicio interactivo de consultas que le permite analizar datos directamente en Amazon Simple Storage Service (Amazon S3) usando SQL estándar.
Amazon Bedrock es un servicio totalmente gestionado que pone a su disposición modelos básicos de alto rendimiento (FMs) de las principales empresas emergentes de IA y Amazon a través de una API unificada.
AWS Cloud Development Kit (AWS CDK) es un marco de desarrollo de software que le ayuda a definir y aprovisionar la infraestructura de la nube de AWS en código.
La interfaz de la línea de comandos de AWS (AWS CLI) es una herramienta de código abierto que le permite interactuar con los servicios de AWS mediante comandos en su intérprete de comandos de línea de comandos.
Amazon Elastic Container Service (Amazon ECS) es un servicio de administración de contenedores escalable y rápido que ayuda a ejecutar, detener y administrar contenedores en un clúster.
AWS Glue es un servicio de extracción, transformación y carga (ETL) completamente administrado. Ayuda a clasificar, limpiar, enriquecer y mover datos de forma fiable entre almacenes de datos y flujos de datos. Este patrón emplea un rastreador de AWS Glue y una tabla del catálogo de datos de AWS Glue.
Amazon Kendra es un servicio de búsqueda inteligente que utiliza el procesamiento del lenguaje natural y algoritmos avanzados de aprendizaje automático para devolver respuestas específicas a las preguntas de búsqueda a partir de sus datos.
AWS Lambda es un servicio de computación que ayuda a ejecutar código sin necesidad de aprovisionar ni administrar servidores. Ejecuta el código solo cuando es necesario y amplía la capacidad de manera automática, por lo que solo pagará por el tiempo de procesamiento que utilice.
Amazon Simple Storage Service (Amazon S3) es un servicio de almacenamiento de objetos basado en la nube que le ayuda a almacenar, proteger y recuperar cualquier cantidad de datos.
Elastic Load Balancing (ELB) distribuye el tráfico entrante de aplicaciones o redes entre varios destinos. Por ejemplo, puede distribuir el tráfico entre instancias, contenedores y direcciones IP de Amazon Elastic Compute Cloud (Amazon EC2) en una o más zonas de disponibilidad.
Repositorio de código
El código de este patrón está disponible en el GitHub genai-bedrock-chatbot
El repositorio de código contiene los siguientes archivos y carpetas:
assetscarpeta: los activos estáticos, el diagrama de arquitectura y el conjunto de datos públicocode/lambda-containerfolder: el código de Python que se ejecuta en la función Lambdacode/streamlit-appfolder: el código Python que se ejecuta como imagen del contenedor en Amazon ECStestsfolder: los archivos de Python que se ejecutan para realizar pruebas unitarias de las construcciones de AWS CDKcode/code_stack.py— El CDK de AWS construye los archivos Python que se utilizan para crear recursos de AWSapp.py— Los archivos Python de la pila de CDK de AWS que se utilizan para implementar los recursos de AWS en la cuenta de AWS de destinorequirements.txt— La lista de todas las dependencias de Python que se deben instalar para AWS CDKrequirements-dev.txt— La lista de todas las dependencias de Python que se deben instalar para que AWS CDK ejecute el conjunto de pruebas unitariascdk.json– El archivo de entrada que proporciona los valores necesarios para activar los recursos
Nota: El código CDK de AWS utiliza estructuras de nivel 3 (capa 3) y políticas de AWS Identity and Access Management (IAM) administradas por AWS para implementar la solución. |
|---|
Prácticas recomendadas
El ejemplo de código que se proporciona aquí es únicamente para una demostración proof-of-concept (PoC) o piloto. Si desea llevar el código a producción, asegúrese de seguir las siguientes prácticas recomendadas:
Configure la supervisión y las alertas para las funciones de Lambda de AWS. Para obtener más información, consulte Supervisión y solución de problemas de funciones de Lambda. Para obtener más información sobre las prácticas recomendadas generales en el uso de funciones de Lambda, consulte la documentación de AWS.
Epics
| Tarea | Descripción | Habilidades requeridas |
|---|---|---|
Exporte las variables de la cuenta y la región de AWS en las que se implementará la pila. | Para proporcionar las credenciales de AWS para AWS CDK mediante variables de entorno, ejecute los siguientes comandos.
| DevOps ingeniero, AWS DevOps |
Configure el perfil de AWS CLI. | Para configurar el perfil de AWS CLI para la cuenta, siga las instrucciones de la documentación de AWS. | DevOps ingeniero, AWS DevOps |
| Tarea | Descripción | Habilidades requeridas |
|---|---|---|
Clone el repositorio en su máquina local. | Para clonar el repositorio, ejecuta el siguiente comando en tu terminal.
| DevOps ingeniero, AWS DevOps |
Configure el entorno virtual de Python e instale las dependencias necesarias. | Para configurar y activar el entorno virtual de Python, ejecute el siguiente comando.
Para configurar las dependencias necesarias, ejecute el siguiente comando.
| DevOps ingeniero, AWS DevOps |
Configure el entorno de AWS CDK y sintetice el código de AWS CDK. |
| DevOps ingeniero, AWS DevOps |
| Tarea | Descripción | Habilidades requeridas |
|---|---|---|
Proporcione el acceso al modelo Claude. | Para habilitar el acceso al modelo Anthropic Claude en su cuenta de AWS, siga las instrucciones de la documentación de Amazon Bedrock. | AWS DevOps |
Implementar recursos en la cuenta. | Para implementar recursos en la cuenta de AWS mediante la CDK de AWS, haga lo siguiente:
Tras una implementación correcta, puede acceder a la aplicación de asistente basada en el chat mediante la URL proporcionada en la sección de CloudFormation resultados. | AWS DevOps, DevOps ingeniero |
Ejecute el rastreador de AWS Glue y cree la tabla del catálogo de datos. | El rastreador de AWS Glue se usa para mantener el esquema de datos dinámico. La solución crea y actualiza las particiones en la tabla del catálogo de datos de AWS Glue mediante la ejecución del rastreador a petición. Una vez copiados los archivos del conjunto de datos CSV en el depósito de S3, ejecute el rastreador AWS Glue y cree el esquema de tablas del catálogo de datos para realizar las pruebas:
notaEl código de AWS CDK configura el rastreador AWS Glue para que se ejecute bajo demanda, pero también puede programarlo para que se ejecute periódicamente. | DevOps ingeniero, AWS DevOps |
Inicie la indexación de documentos. | Una vez copiados los archivos en el bucket de S3, utilice Amazon Kendra para rastrearlos e indexarlos:
| AWS DevOps, DevOps ingeniero |
| Tarea | Descripción | Habilidades requeridas |
|---|---|---|
Elimine los recursos de AWS. | Después de probar la solución, limpie los recursos:
| DevOps ingeniero, AWS DevOps |
Solución de problemas
| Problema | Solución |
|---|---|
AWS CDK devuelve errores. | Para obtener ayuda con los errores de AWS CDK, consulte Solución de problemas comunes de AWS CDK. |
Recursos relacionados
Información adicional
Comandos de AWS CDK
Cuando trabaje con AWS CDK, recuerde los siguientes comandos útiles:
Muestra todas las pilas de la aplicación
cdk lsEmite la plantilla de AWS CloudFormation sintetizada
cdk synthImplementa la pila en la cuenta y región de AWS predeterminadas
cdk deployCompara la pila implementada con el estado actual
cdk diffAbre la documentación de AWS CDK
cdk docsElimina la CloudFormation pila y elimina los recursos desplegados por AWS
cdk destroy
