Les traductions sont fournies par des outils de traduction automatique. En cas de conflit entre le contenu d'une traduction et celui de la version originale en anglais, la version anglaise prévaudra.
Exporter
Dans le flux Data Wrangler, vous pouvez exporter une partie ou la totalité des transformations que vous avez effectuées dans les pipelines de traitement des données.
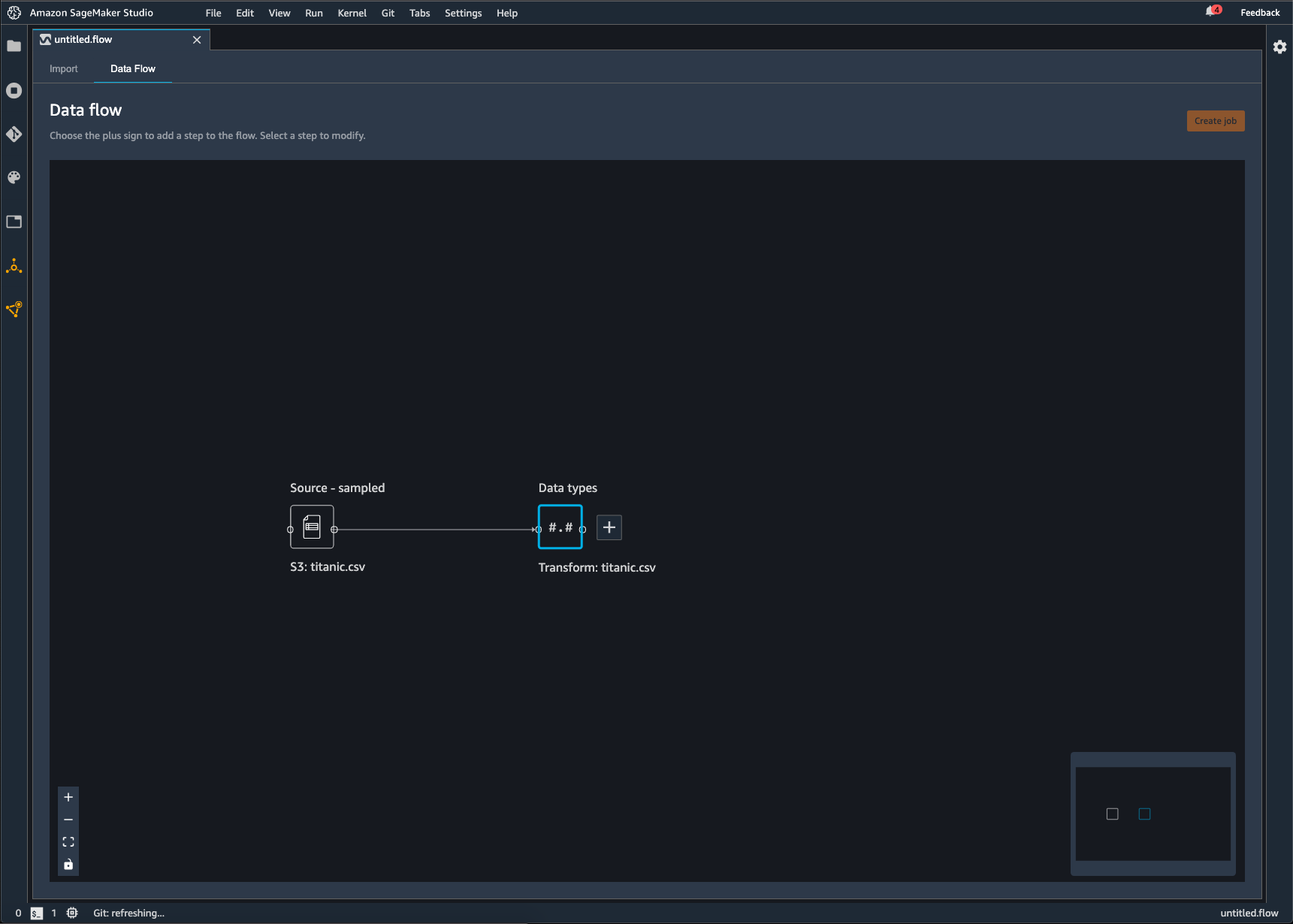
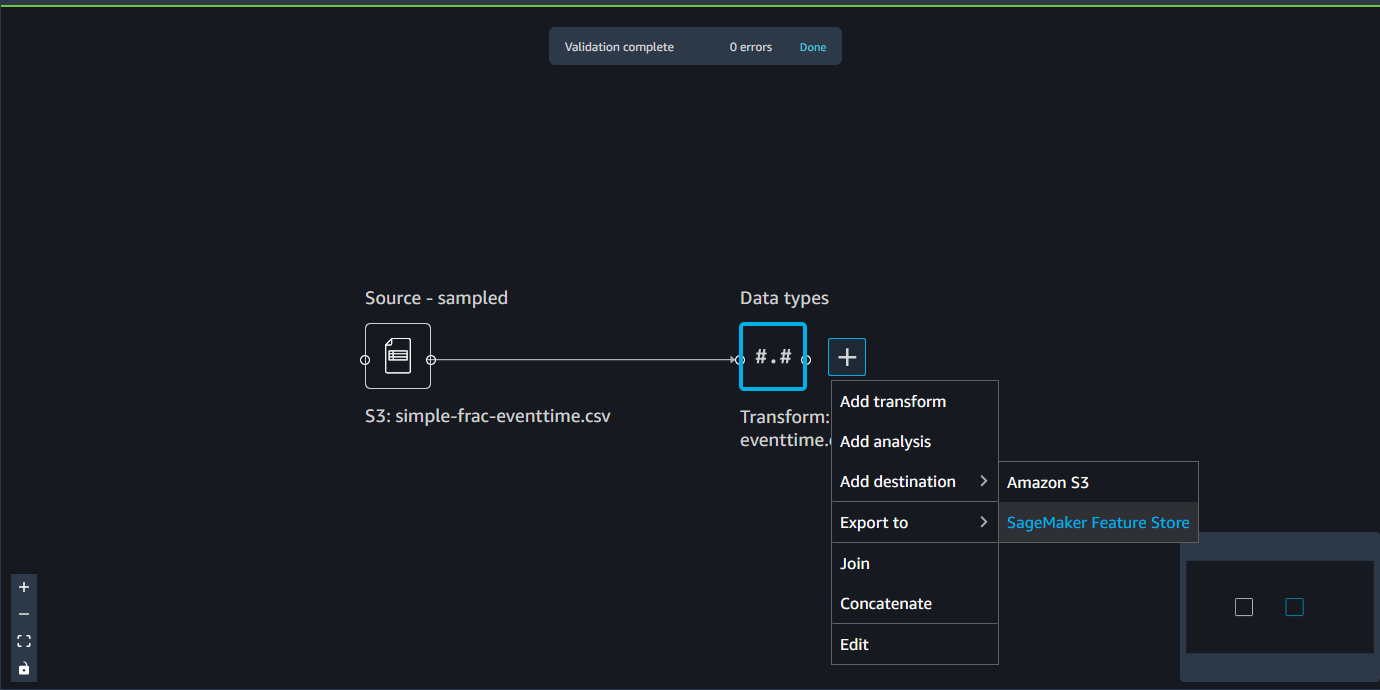
Un flux Data Wrangler est une série d'étapes de préparation des données que vous avez effectuées sur vos données. Lors de la préparation des données, vous effectuez une ou plusieurs transformations de vos données. Chaque transformation est effectuée à l'aide d'une étape de transformation. Le flux comporte une série de nœuds qui représentent l'importation des données et les transformations effectuées. Pour obtenir un exemple de nœuds, consultez l'image suivante.
L'image précédente montre un flux Data Wrangler avec deux nœuds. Le nœud Source - sampled (Source – Échantillonnée) affiche la source de données à partir de laquelle vous avez importé vos données. Le nœud Data types (Types de données) indique que Data Wrangler a effectué une transformation pour convertir le jeu de données en un format utilisable.
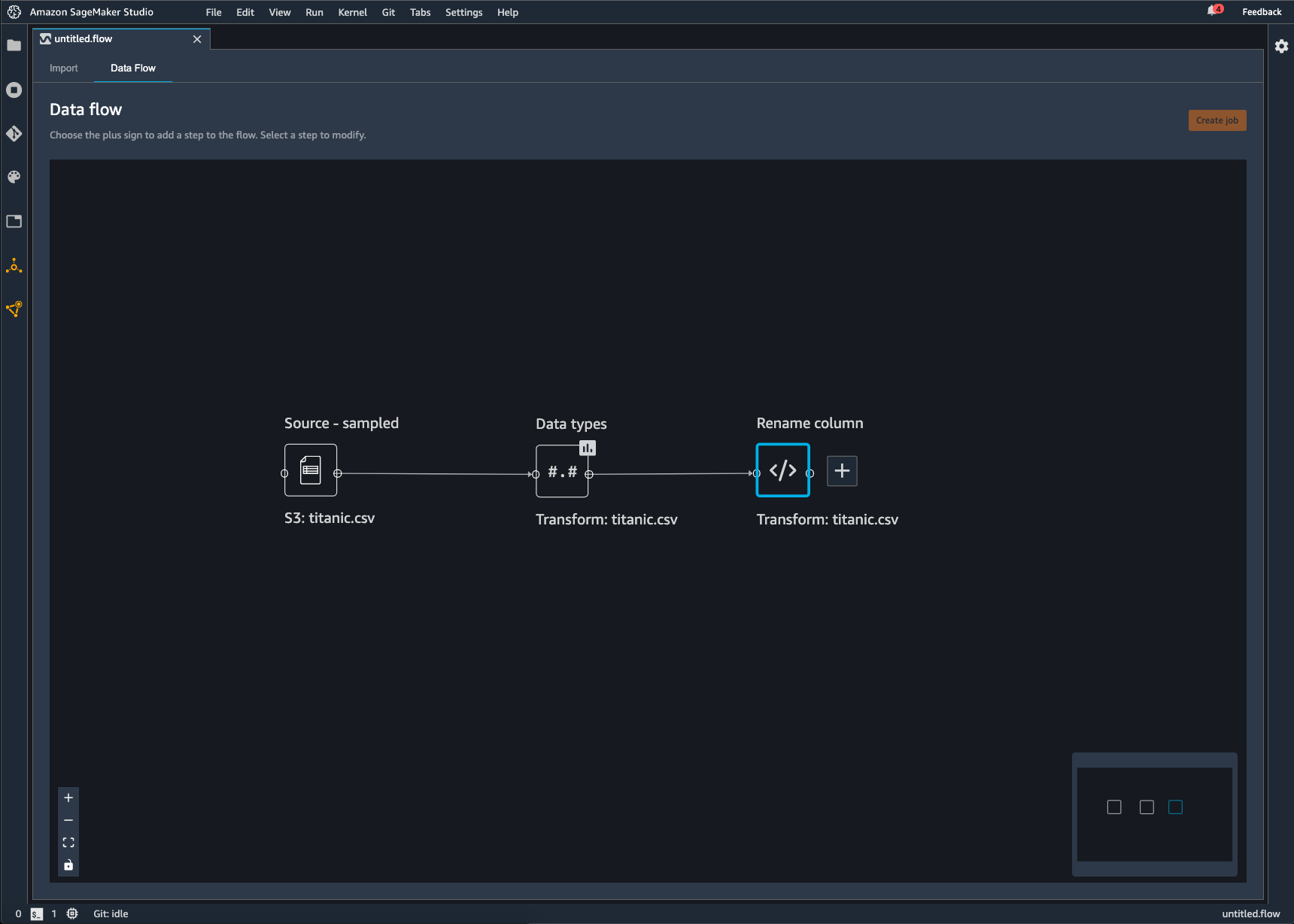
Chaque transformation que vous ajoutez au flux Data Wrangler s'affiche sous la forme d'un nœud supplémentaire. Pour plus d'informations sur les transformations que vous pouvez ajouter, consultez Transformation de données. L'image suivante représente un flux Data Wrangler avec un nœud Rename-column (Renommer colonne) pour modifier le nom d'une colonne dans un jeu de données.
Vous pouvez exporter vos transformations de données vers les éléments suivants :
Nous vous recommandons d'utiliser la politique AmazonSageMakerFullAccess gérée par IAM pour AWS autoriser l'utilisation de Data Wrangler. Si vous n'utilisez pas cette politique gérée, vous pouvez utiliser une politique IAM donnant à Data Wrangler l'accès à un compartiment Amazon S3. Pour plus d'informations sur la politique, consultez Sécurité et autorisations.
Lorsque vous exportez votre flux de données, les AWS ressources que vous utilisez vous sont facturées. Vous pouvez utiliser des identifications d'allocation des coûts pour organiser et gérer les coûts de ces ressources. Vous créez ces balises pour votre profil utilisateur et Data Wrangler les applique automatiquement aux ressources utilisées pour exporter le flux de données. Pour plus d'informations, consultez Utilisation des balises de répartition des coûts.
Exporter vers Amazon S3
Data Wrangler vous permet d'exporter les données vers un emplacement dans un compartiment Amazon S3. Vous pouvez spécifier l'emplacement à l'aide de l'une des méthodes suivantes :
-
Destination node (Nœud de destination) : emplacement où Data Wrangler stocke les données une fois qu'il les a traitées.
-
Export to (Exporter vers) : exporte les données résultant d'une transformation vers Amazon S3.
-
Export data (Exporter des données) : pour les petits jeux de données, permet d'exporter rapidement les données que vous avez transformées.
Utilisez les sections suivantes pour en savoir plus sur chacune de ces méthodes.
- Destination Node
-
Si vous souhaitez générer sur Amazon S3 une série avec les étapes de traitement des données que vous avez effectuées, vous devez créer un nœud de destination. Un nœud de destination indique à Data Wrangler où stocker les données après leur traitement. Une fois que vous avez créé un nœud de destination, vous devez créer une tâche de traitement pour générer les données. Une tâche de traitement est une tâche SageMaker de traitement Amazon. Lorsque vous utilisez un nœud de destination, Data Wrangler exécute les ressources de calcul nécessaires pour générer les données que vous avez transformées dans Amazon S3.
Vous pouvez utiliser un nœud de destination pour exporter une partie ou la totalité des transformations que vous avez effectuées dans le flux Data Wrangler.
Vous pouvez utiliser plusieurs nœuds de destination pour exporter différentes transformations ou différents ensembles de transformations. L'exemple suivant illustre deux nœuds de destination dans un seul flux Data Wrangler.
Vous pouvez utiliser la procédure suivante pour créer des nœuds de destination et les exporter vers un compartiment Amazon S3.
Pour exporter le flux de données, vous devez créer des nœuds de destination et une tâche Data Wrangler pour exporter les données. La création d'une tâche Data Wrangler lance une tâche SageMaker de traitement pour exporter votre flux. Vous pouvez choisir les nœuds de destination à exporter après les avoir créés.
Vous pouvez choisir Create job (Créer une tâche) dans le flux Data Wrangler pour afficher les instructions relatives à l'utilisation d'une tâche de traitement.
Utilisez la procédure suivante pour créer des nœuds de destination.
-
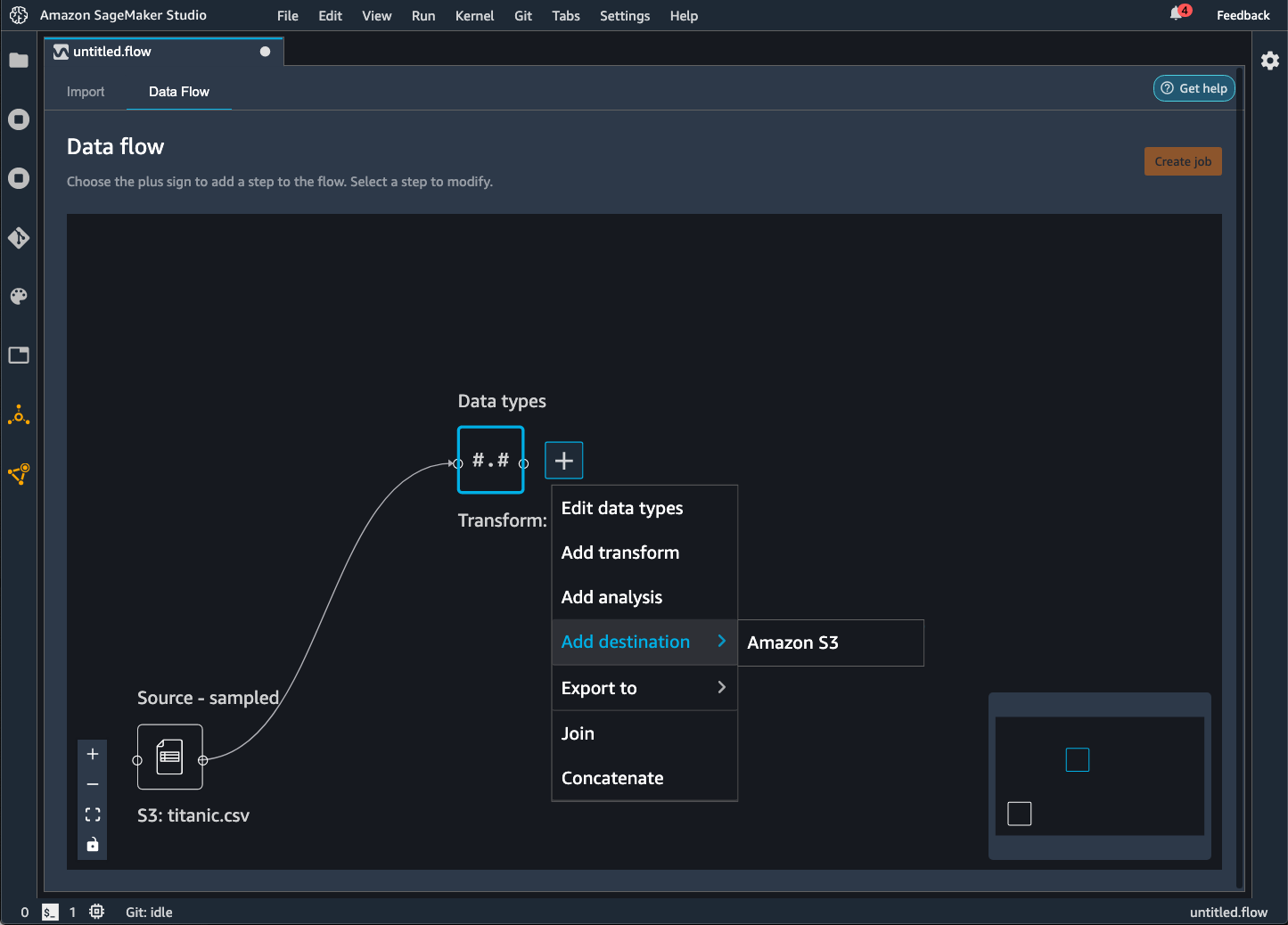
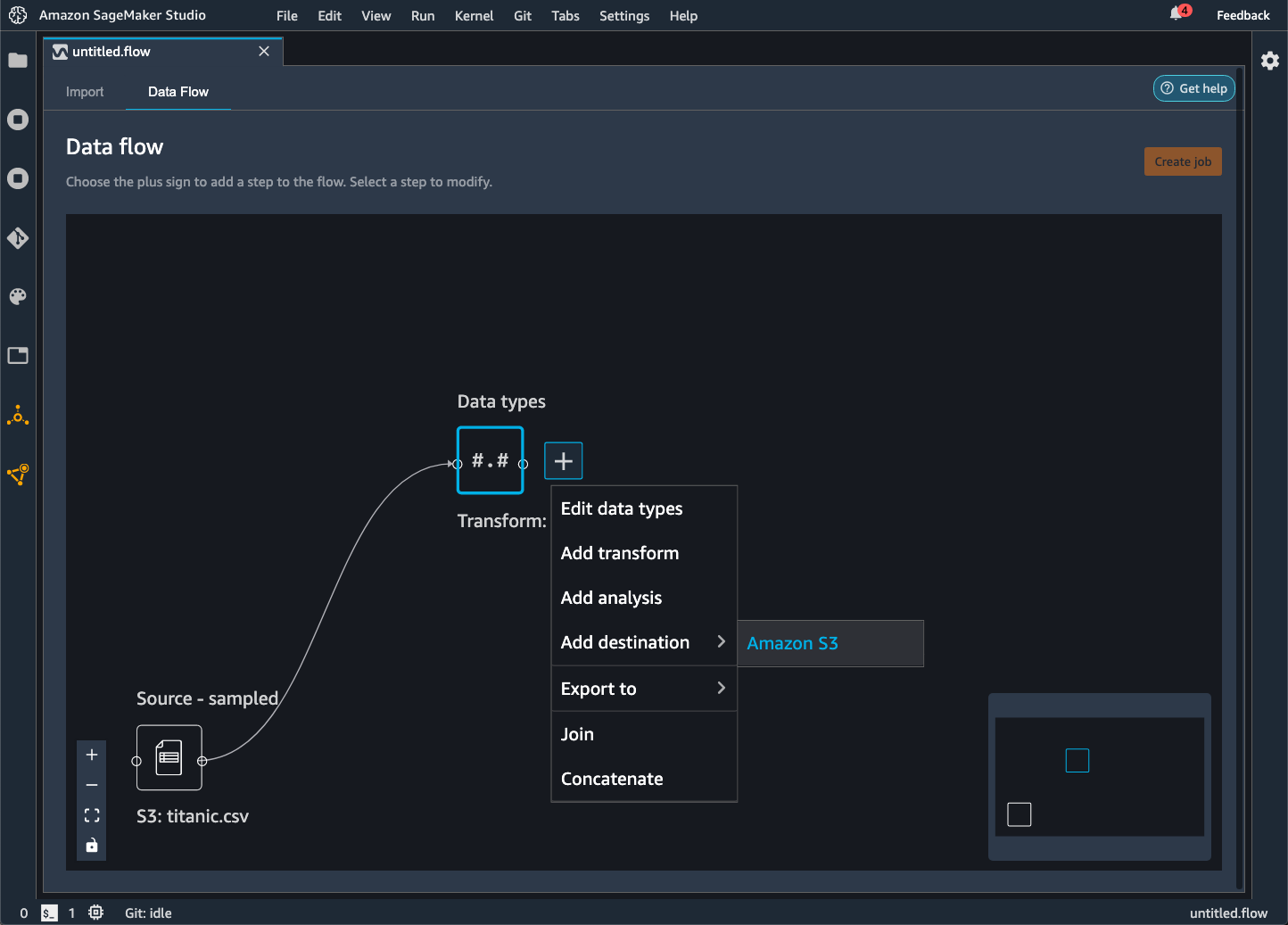
Cliquez sur l'icône + à côté des nœuds représentant les transformations à exporter.
-
Choisissez Add destination (Ajouter une destination).
-
Choisissez Amazon S3.
-
Spécifiez les champs suivants.
-
Dataset name (Nom du jeu de données) : nom que vous spécifiez pour le jeu de données que vous exportez.
-
File type (Type de fichier) : format du fichier que vous exportez.
-
Délimiteur (fichiers CSV et Parquet uniquement) : valeur utilisée pour séparer les autres valeurs.
-
Compression (fichiers CSV et Parquet uniquement) : méthode de compression utilisée pour réduire la taille du fichier. Vous pouvez utiliser les méthodes de compression suivantes :
-
(Facultatif) Amazon S3 location (Emplacement Amazon S3) : emplacement S3 que vous utilisez pour générer les fichiers.
-
(Facultatif) Number of partitions (Nombre de partitions) : nombre de jeux de données que vous écrivez en sortie de la tâche de traitement.
-
(Facultatif) Partition by column (Partition par colonne) : écrit toutes les données avec la même valeur unique à partir de la colonne.
-
(Facultatif) Paramètres d'inférence : la sélection de Générer des artefacts d'inférence applique toutes les transformations que vous avez utilisées dans le flux Data Wrangler aux données entrant dans votre pipeline d'inférence. Le modèle de votre pipeline fait des prédictions sur les données transformées.
-
Choisissez Add destination (Ajouter une destination).
Utilisez la procédure suivante pour créer une tâche de traitement.
Créez une tâche à partir de la page Data flow (Flux de données) et choisissez les nœuds de destination que vous souhaitez exporter.
Vous pouvez choisir Create job (Créer une tâche) dans le flux Data Wrangler pour afficher les instructions relatives à la création d'une tâche de traitement.
-
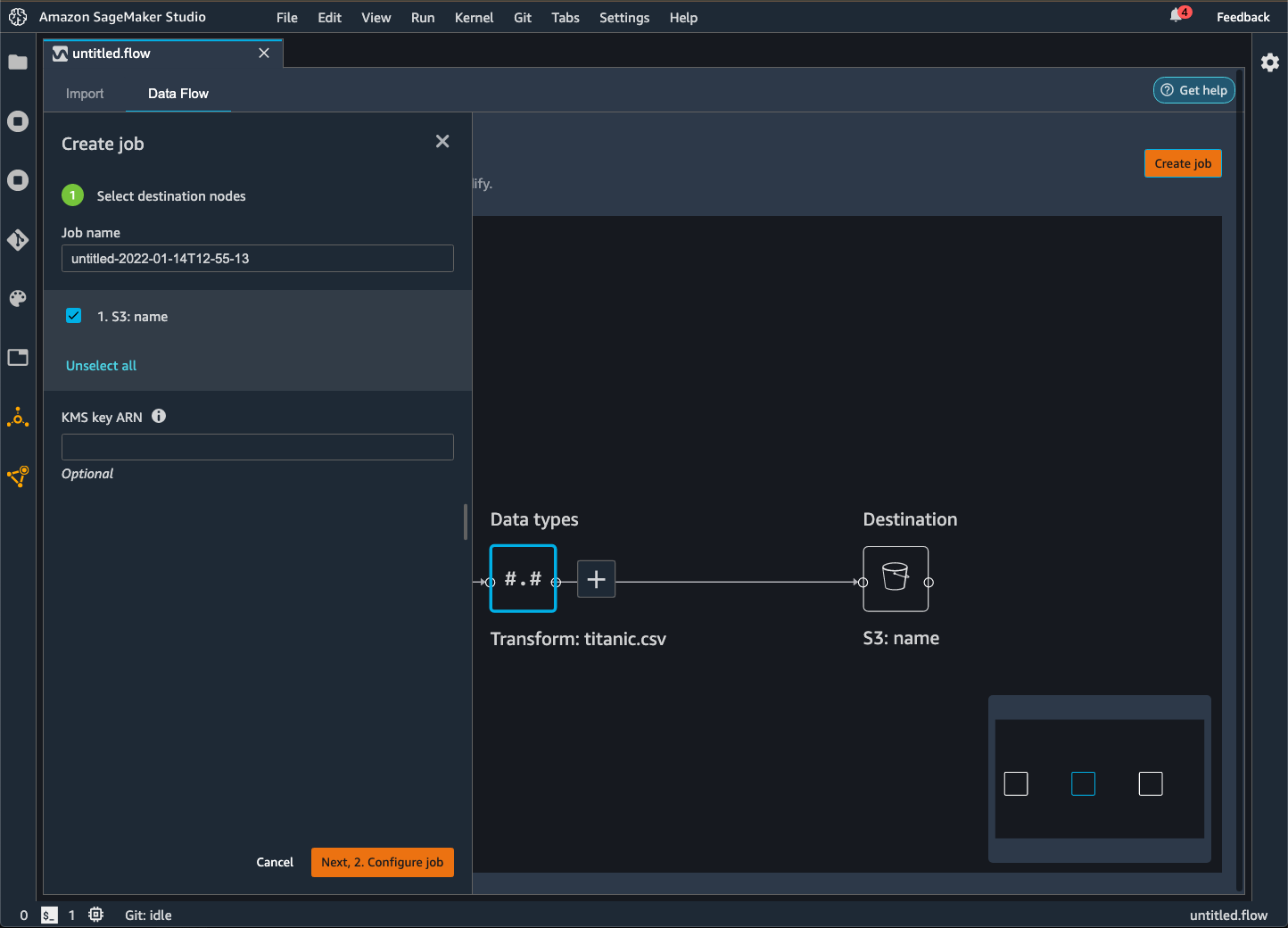
Choisissez Create job (Créer une tâche). L'image suivante représente le panneau qui s'affiche lorsque vous sélectionnez Create job (Créer une tâche).
-
Pour Job name (Nom de la tâche), indiquez le nom de la tâche d'exportation.
-
Choisissez les nœuds de destination que vous souhaitez exporter.
-
(Facultatif) Spécifiez un ARN AWS KMS clé. Une AWS KMS clé est une clé cryptographique que vous pouvez utiliser pour protéger vos données. Pour plus d'informations sur AWS KMS les clés, consultez AWS Key Management Service.
-
(Facultatif) Sous Trained parameters (Paramètres entraînés), choisissez Refit (Adapter) si vous avez effectué les opérations suivantes :
Pour plus d'informations sur l'adaptation des transformations que vous avez effectuées sur l'ensemble d'un jeu de données, consultez Adaptez les transformations à la totalité du jeu de données et exportez-les.
Pour les données image, Data Wrangler exporte les transformations que vous avez apportées à toutes les images. Le réajustement des transformations ne s'applique pas à votre cas d'utilisation.
-
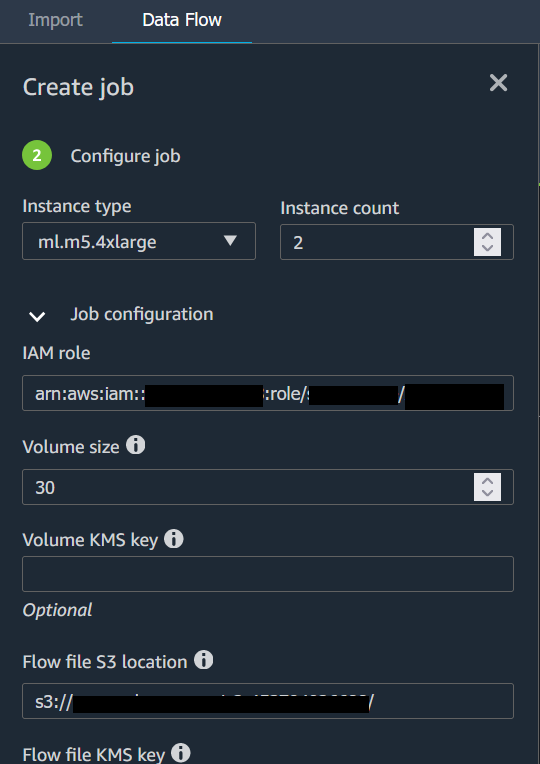
Choisissez Configure job (Configurer la tâche). L'image suivante illustre la page Configure job (Configurer la tâche).
-
(Facultatif) Configurez la tâche Data Wrangler. Vous pouvez réaliser les configurations suivantes :
-
Cliquez sur Exécuter.
- Export to
-
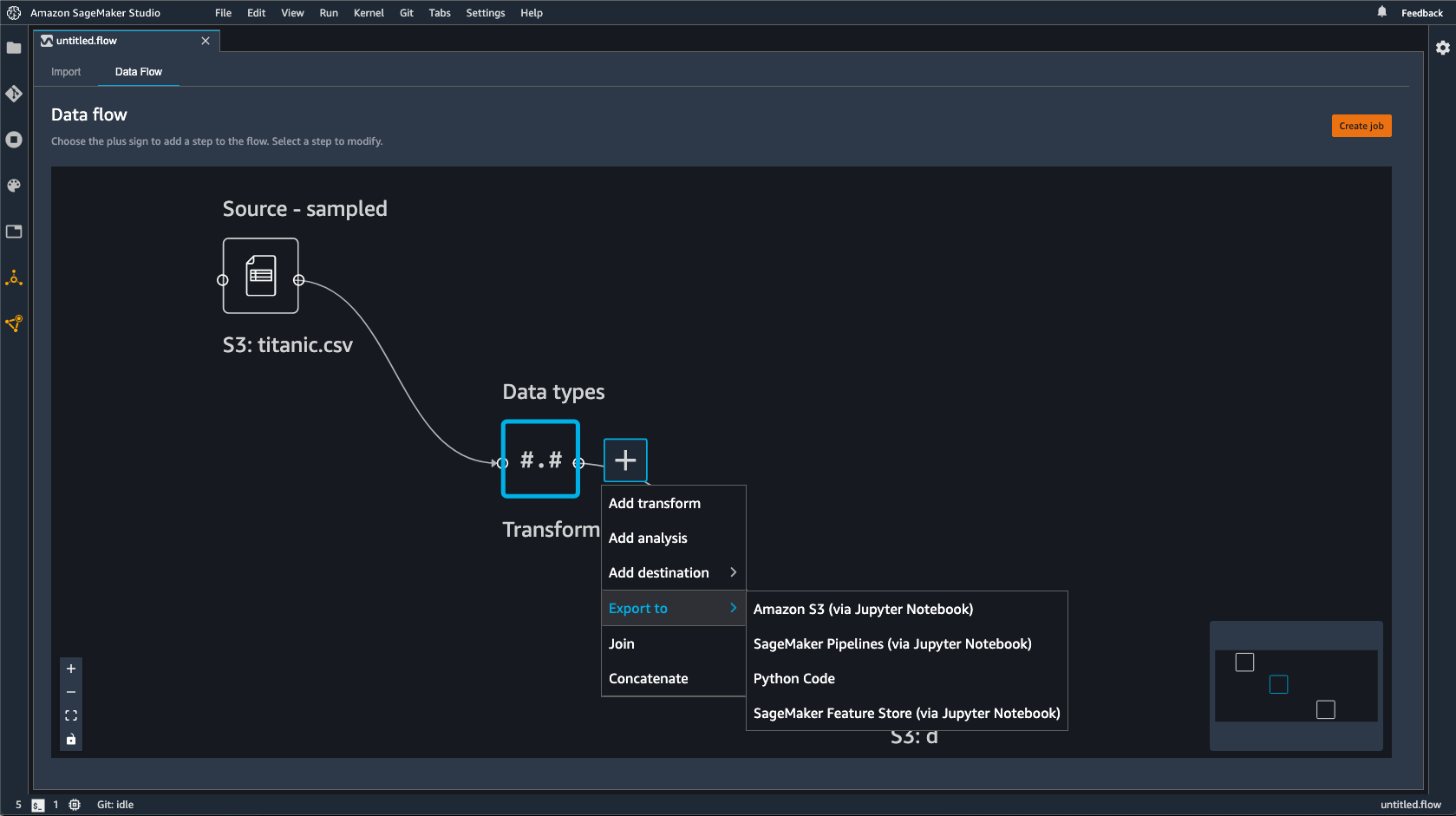
Au lieu d'utiliser un nœud de destination, vous pouvez utiliser l'option Export to (Exporter vers) afin d'exporter le flux Data Wrangler vers Amazon S3 à l'aide d'un bloc-notes Jupyter. Vous pouvez choisir n'importe quel nœud de données dans le flux Data Wrangler et l'exporter. L'exportation du nœud de données exporte la transformation que le nœud représente et les transformations qui la précèdent.
Suivez la procédure suivante pour générer un bloc-notes Jupyter et l'exécuter pour exporter le flux Data Wrangler vers Amazon S3.
-
Cliquez sur l'icône + en regard du nœud que vous souhaitez exporter.
-
Choisissez Export to (Exporter vers).
-
Choisissez Amazon S3 (via Jupyter Notebook) (Amazon S3 (via un bloc-notes Jupyter)).
-
Exécutez le bloc-notes Jupyter.
Lorsque vous exécutez le bloc-notes, il exporte votre flux de données (fichier .flow) de la même manière Région AWS que le flux Data Wrangler.
Le bloc-notes propose des options que vous pouvez utiliser pour configurer la tâche de traitement et les données qu'elle génère.
Nous vous fournissons des configurations de tâche pour configurer la sortie de vos données. En ce qui concerne les options de partitionnement et de mémoire du pilote, nous vous recommandons vivement de ne pas spécifier de configuration, à moins que vous ne connaissiez déjà ces options.
Sous Job Configurations (Configurations de la tâche), vous pouvez configurer les éléments suivants :
-
output_content_type : type de contenu du fichier de sortie. Utilise CSV comme format par défaut, mais vous pouvez spécifierParquet.
-
delimiter : caractère utilisé pour séparer les valeurs dans le jeu de données lors de l'écriture dans un fichier CSV.
-
compression : si cette option est définie, le fichier de sortie est compressé. Utilise gzip comme format de compression par défaut.
-
num_partitions : nombre de partitions ou de fichiers que Data Wrangler écrit en sortie.
-
partition_by : noms des colonnes que vous utilisez pour partitionner la sortie.
Pour remplacer le format du fichier de sortie CSV par Parquet, remplacez la valeur "CSV" par "Parquet". Pour les autres champs précédents, supprimez le commentaire des lignes contenant les champs que vous souhaitez spécifier.
Sous (Optional) Configure Spark Cluster Driver Memory [(Facultatif) Configurer la mémoire du pilote du cluster Spark], vous pouvez configurer les propriétés Spark pour la tâche, telles que la mémoire du pilote Spark, dans le dictionnaire config.
Ce qui suit montre le dictionnaire config.
config = json.dumps({
"Classification": "spark-defaults",
"Properties": {
"spark.driver.memory": f"{driver_memory_in_mb}m",
}
})
Pour appliquer la configuration à la tâche de traitement, supprimez le commentaire des lignes suivantes :
# data_sources.append(ProcessingInput(
# source=config_s3_uri,
# destination="/opt/ml/processing/input/conf",
# input_name="spark-config",
# s3_data_type="S3Prefix",
# s3_input_mode="File",
# s3_data_distribution_type="FullyReplicated"
# ))
- Export data
-
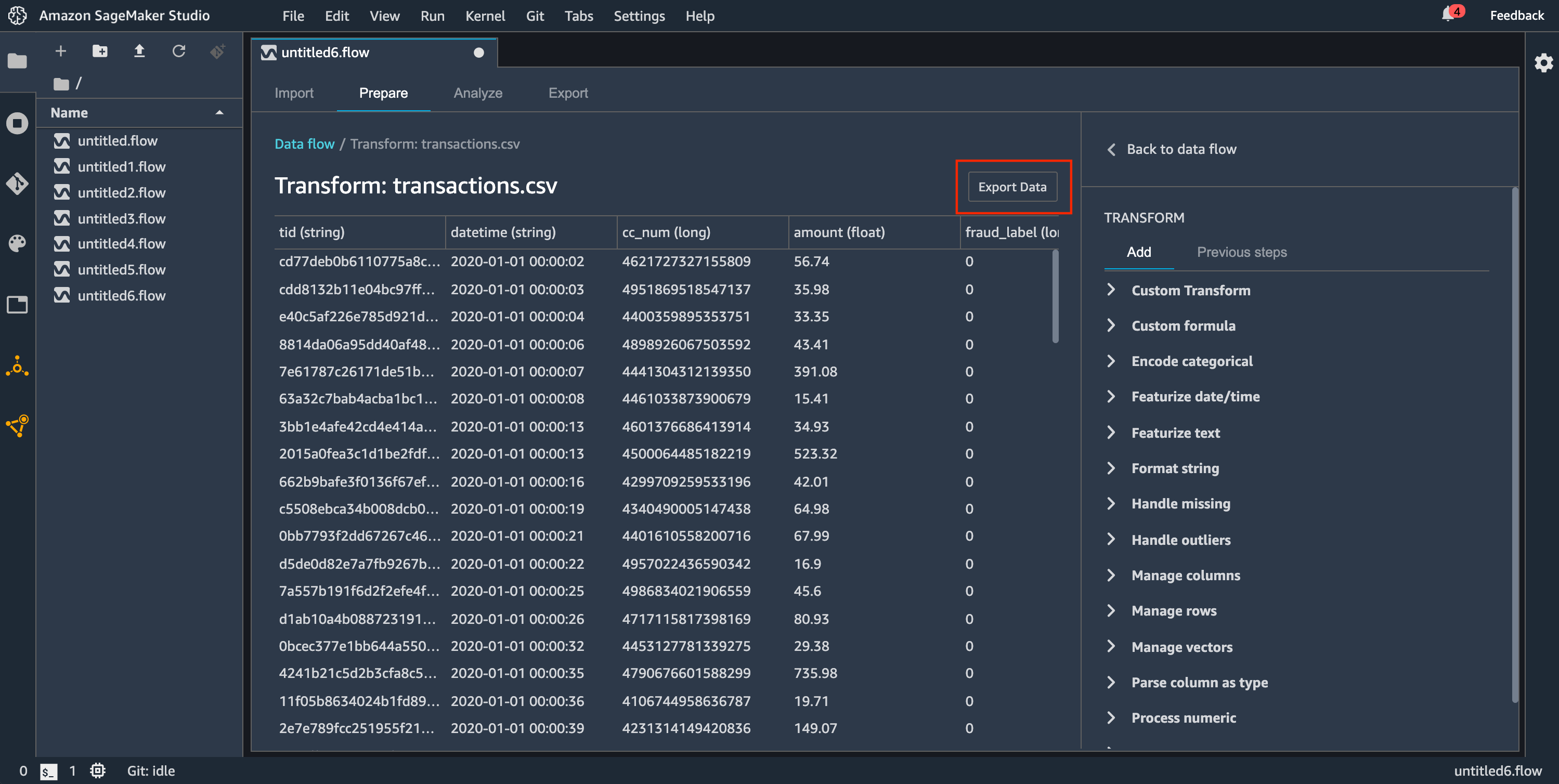
Si vous souhaitez exporter rapidement une transformation d'un petit jeu de données, vous pouvez utiliser la méthode Export data (Exporter des données). Si vous choisissez Export data (Exporter des données), Data Wrangler travaille de manière synchrone pour exporter les données que vous avez transformées vers Amazon S3. Vous ne pouvez pas utiliser Data Wrangler tant qu'il n'a pas fini d'exporter vos données, à moins que vous annuliez l'opération.
Pour plus d'informations sur l'utilisation de la méthode Export data (Exporter des données) dans le flux Data Wrangler, consultez la procédure suivante.
Pour utiliser la méthode Export data (Exporter des données) :
-
Choisissez un nœud dans le flux Data Wrangler en l'ouvrant (en double-cliquant dessus).
-
Configurez la façon dont vous souhaitez exporter les données.
-
Choisissez Export data (Exporter des données).
Lorsque vous exportez le flux de données vers un compartiment Amazon S3, Data Wrangler stocke une copie du fichier de flux dans le compartiment S3. Il stocke le fichier de flux avec le préfixe data_wrangler_flows. Si vous utilisez le compartiment Amazon S3 par défaut pour stocker vos fichiers de flux, il utilise la convention de dénomination suivante : sagemaker-region-account
number. Par exemple, si votre numéro de compte est 111122223333 et que vous utilisez Studio Classic dans us-east-1, vos ensembles de données importés sont stockés dans. sagemaker-us-east-1-111122223333 Dans cet exemple, les fichiers .flow créés dans la région us-east-1 sont stockés dans s3://sagemaker-region-account
number/data_wrangler_flows/.
Exportation vers des pipelines
Lorsque vous souhaitez créer et déployer des flux de travail d'apprentissage automatique (ML) à grande échelle, vous pouvez utiliser Pipelines pour créer des flux de travail qui gèrent et déploient des tâches d' SageMaker IA. Avec Pipelines, vous pouvez créer des flux de travail qui gèrent la préparation de vos données d' SageMaker IA, la formation des modèles et les tâches de déploiement de modèles. Vous pouvez utiliser les algorithmes propriétaires proposés par l' SageMaker IA en utilisant Pipelines. Pour plus d'informations sur les pipelines, consultez la section SageMaker Pipelines.
Lorsque vous exportez une ou plusieurs étapes de votre flux de données vers Pipelines, Data Wrangler crée un bloc-notes Jupyter que vous pouvez utiliser pour définir, instancier, exécuter et gérer un pipeline.
Utiliser un bloc-notes Jupyter pour créer un pipeline
Utilisez la procédure suivante pour créer un bloc-notes Jupyter afin d'exporter votre flux Data Wrangler vers Pipelines.
Utilisez la procédure suivante pour générer un bloc-notes Jupyter et l'exécuter pour exporter votre flux Data Wrangler vers Pipelines.
-
Cliquez sur l'icône + en regard du nœud que vous souhaitez exporter.
-
Choisissez Export to (Exporter vers).
-
Choisissez Pipelines (via Jupyter Notebook).
-
Exécutez le bloc-notes Jupyter.
Vous pouvez utiliser le bloc-notes Jupyter produit par Data Wrangler pour définir un pipeline. Le pipeline comprend des étapes de traitement des données définies par le flux Data Wrangler.
Vous pouvez ajouter des étapes supplémentaires à votre pipeline en ajoutant des étapes à la liste steps dans le code suivant, dans le bloc-notes :
pipeline = Pipeline(
name=pipeline_name,
parameters=[instance_type, instance_count],
steps=[step_process], #Add more steps to this list to run in your Pipeline
)
Pour plus d'informations sur la définition de pipelines, consultez la section Définir un pipeline d' SageMaker IA.
Exporter vers un point de terminaison d'inférence
Utilisez votre flux Data Wrangler pour traiter les données au moment de l'inférence en créant un pipeline d'inférence série SageMaker AI à partir de votre flux Data Wrangler. Un pipeline d'inférence est une série d'étapes qui permettent à un modèle entraîné de faire des prédictions sur de nouvelles données. Un pipeline d'inférence en série intégré à Data Wrangler transforme les données brutes et les fournit au modèle de machine learning à des fins de prédiction. Vous créez, exécutez et gérez le pipeline d'inférence à partir d'un bloc-notes Jupyter dans Studio Classic. Pour plus d'informations sur l'accès au bloc-notes, consultez Utiliser un bloc-notes Jupyter pour créer un point de terminaison d'inférence.
Dans le bloc-notes, vous pouvez soit entraîner un modèle de machine learning, soit en spécifier un que vous avez déjà entraîné. Vous pouvez soit utiliser Amazon SageMaker Autopilot, soit entraîner le modèle XGBoost à l'aide des données que vous avez transformées dans votre flux Data Wrangler.
Le pipeline permet d'effectuer des inférences par lots ou en temps réel. Vous pouvez également ajouter le flux Data Wrangler au SageMaker Model Registry. Pour plus d'informations sur les modèles d'hébergement, veuillez consulter Points de terminaison multi-modèles.
Vous ne pouvez pas exporter votre flux Data Wrangler vers un point de terminaison d'inférence s'il comporte les transformations suivantes :
-
Joindre
-
Concaténer
-
Regrouper par
Si vous devez utiliser les transformations précédentes pour préparer vos données, suivez la procédure suivante.
Pour préparer vos données à l'inférence à l'aide de transformations non prises en charge
-
Créez un flux Data Wrangler.
-
Appliquez les transformations précédentes qui ne sont pas prises en charge.
-
Exportez les données vers un compartiment Amazon S3.
-
Créez un flux Data Wrangler distinct.
-
Importez les données que vous avez exportées à partir du flux précédent.
-
Appliquez les transformations restantes.
-
Créez un pipeline d'inférence en série à l'aide du bloc-notes Jupyter que nous fournissons.
Pour en savoir plus sur l'export de vos données vers un compartiment Amazon S3, consultez Exporter vers Amazon S3. Pour en savoir plus sur l'ouverture du bloc-notes Jupyter utilisé pour créer le pipeline d'inférence en série, consultez Utiliser un bloc-notes Jupyter pour créer un point de terminaison d'inférence.
Data Wrangler ignore les transformations qui suppriment les données au moment de l'inférence. Par exemple, Data Wrangler ignore la transformation Handle Missing Values (Gestion des valeurs manquantes) si vous utilisez la configuration Supprimer les valeurs manquantes.
Si vous avez réajusté les transformations à l'ensemble de votre jeu de données, elles sont répercutées sur votre pipeline d'inférence. Par exemple, si vous avez utilisé la valeur médiane pour imputer les valeurs manquantes, la valeur médiane issue du réajustement de la transformation est appliquée à vos demandes d'inférence. Vous pouvez soit modifier les transformations de votre flux Data Wrangler lorsque vous utilisez le bloc-notes Jupyter, soit lorsque vous exportez vos données vers un pipeline d'inférence. Pour en savoir plus sur le réajustement des transformations, consultez Adaptez les transformations à la totalité du jeu de données et exportez-les.
Le pipeline d'inférence en série prend en charge les types de données suivants pour les chaînes d'entrée et de sortie. Chaque type de données est soumis à un ensemble d'exigences.
Types de données pris en charge
-
text/csv : le type de données pour les chaînes CSV
-
La chaîne ne peut pas comporter d'en-tête.
-
Les fonctionnalités utilisées pour le pipeline d'inférence doivent être dans le même ordre que les fonctionnalités du jeu de données d'entraînement.
-
Il doit y avoir une virgule entre les fonctionnalités.
-
Les enregistrements doivent être délimités par un caractère de saut de ligne.
Voici un exemple de chaîne CSV correctement formatée que vous pouvez fournir dans une demande d'inférence.
abc,0.0,"Doe, John",12345\ndef,1.1,"Doe, Jane",67890
-
application/json : le type de données pour les chaînes JSON
-
Les fonctionnalités utilisées dans le jeu de données pour le pipeline d'inférence doivent être dans le même ordre que les fonctionnalités du jeu de données d'entraînement.
-
Les données doivent avoir un schéma spécifique. Vous définissez le schéma comme un objet instances unique doté d'un ensemble de features. Chaque objet features représente une observation.
Voici un exemple de chaîne JSON correctement formatée que vous pouvez fournir dans une demande d'inférence.
{
"instances": [
{
"features": ["abc", 0.0, "Doe, John", 12345]
},
{
"features": ["def", 1.1, "Doe, Jane", 67890]
}
]
}
Utiliser un bloc-notes Jupyter pour créer un point de terminaison d'inférence
Utilisez la procédure suivante pour exporter le flux Data Wrangler afin de créer un pipeline d'inférence.
Pour créer un pipeline d'inférence à l'aide d'un bloc-notes Jupyter, procédez comme suit.
-
Cliquez sur l'icône + en regard du nœud que vous souhaitez exporter.
-
Choisissez Export to (Exporter vers).
-
Choisissez SageMaker AI Inference Pipeline (via Jupyter Notebook).
-
Exécutez le bloc-notes Jupyter.
Lorsque vous exécutez le bloc-notes Jupyter, il crée un artefact de flux d'inférence. Un artefact de flux d'inférence est un fichier de flux Data Wrangler contenant des métadonnées supplémentaires utilisées pour créer le pipeline d'inférence en série. Le nœud que vous exportez englobe toutes les transformations des nœuds précédents.
Data Wrangler a besoin de l'artefact du flux d'inférence pour exécuter le pipeline d'inférence. Vous ne pouvez pas utiliser votre propre fichier de flux comme artefact. Vous devez le créer à l'aide de la procédure précédente.
Exporter vers du code Python
Pour exporter toutes les étapes du flux de données vers un fichier Python que vous pouvez intégrer manuellement à n'importe quel flux de travail de traitement de données, utilisez la procédure suivante.
Suivez la procédure suivante pour générer et exécuter un bloc-notes Jupyter pour exporter le flux Data Wrangler vers du code Python.
-
Cliquez sur l'icône + en regard du nœud que vous souhaitez exporter.
-
Choisissez Export to (Exporter vers).
-
Choisissez Python Code (Code Python).
-
Exécutez le bloc-notes Jupyter.
Vous devrez peut-être configurer le script Python pour qu'il s'exécute dans votre pipeline. Par exemple, si vous utilisez un environnement Spark, assurez-vous que vous exécutez le script depuis un environnement autorisé à accéder aux AWS ressources.
Exporter vers Amazon SageMaker Feature Store
Vous pouvez utiliser Data Wrangler pour exporter les fonctionnalités que vous avez créées vers Amazon SageMaker Feature Store. Une fonctionnalité est une colonne dans votre jeu de données. Feature Store est un magasin centralisé pour les fonctionnalités et leurs métadonnées associées. Vous pouvez utiliser Feature Store pour créer, partager et gérer des données organisées pour le développement du machine learning (ML). Les magasins centralisés rendent vos données plus faciles à découvrir et à réutiliser. Pour plus d'informations sur le Feature Store, consultez Amazon SageMaker Feature Store.
Un concept de base dans Feature Store est un groupe de fonctionnalités. Un groupe de fonctionnalités désigne un ensemble de fonctionnalités, leurs enregistrements (observations) et les métadonnées associées. Il s'apparente à une table dans une base de données.
Vous pouvez utiliser Data Wrangler pour effectuer l'une des opérations suivantes :
-
Mettez à jour un groupe de fonctionnalités existant avec de nouveaux enregistrements. Un enregistrement est une observation dans le jeu de données.
-
Créez un nouveau groupe de fonctionnalités à partir d'un nœud dans votre flux Data Wrangler. Data Wrangler ajoute les observations de vos jeux de données en tant qu'enregistrements dans votre groupe de fonctionnalités.
Si vous mettez à jour un groupe de fonctionnalités existant, le schéma de votre jeu de données doit correspondre au schéma du groupe de fonctionnalités. Tous les enregistrements du groupe de fonctionnalités sont remplacés par les observations de votre jeu de données.
Vous pouvez utiliser un bloc-notes Jupyter ou un nœud de destination pour mettre à jour votre groupe de fonctionnalités avec les observations du jeu de données.
Si vos groupes de fonctionnalités au format de tableau Iceberg disposent d'une clé de chiffrement de boutique hors ligne personnalisée, assurez-vous d'accorder à l'IAM que vous utilisez pour la tâche Amazon SageMaker Processing les autorisations nécessaires pour l'utiliser. Vous devez au minimum lui accorder les autorisations nécessaires pour chiffrer les données que vous écrivez dans Amazon S3. Pour accorder les autorisations, donnez au rôle IAM la possibilité d'utiliser le GenerateDataKey. Pour plus d'informations sur l'octroi aux rôles IAM de l'autorisation d'utiliser des AWS KMS clés, voir https://docs.aws.amazon.com/kms/latest/developerguide/key-policies.html
- Destination Node
-
Si vous souhaitez transmettre une série d'étapes de traitement des données que vous avez effectuées à un groupe de fonctionnalités, vous pouvez créer un nœud de destination. Lorsque vous créez et exécutez un nœud de destination, Data Wrangler met à jour un groupe de fonctionnalités avec vos données. Vous pouvez également créer un nouveau groupe de fonctionnalités à partir de l'interface utilisateur du nœud de destination. Une fois que vous avez créé un nœud de destination, vous devez créer une tâche de traitement pour générer les données. Une tâche de traitement est une tâche SageMaker de traitement Amazon. Lorsque vous utilisez un nœud de destination, Data Wrangler exécute les ressources de calcul nécessaires pour générer les données que vous avez transformées pour obtenir le groupe de fonctionnalités.
Vous pouvez utiliser un nœud de destination pour exporter une partie ou la totalité des transformations que vous avez effectuées dans le flux Data Wrangler.
Utilisez la procédure suivante pour créer un nœud de destination afin de mettre à jour un groupe de fonctionnalités avec les observations de votre jeu de données.
Pour mettre à jour un groupe de fonctionnalités en utilisant un nœud de destination, procédez comme suit.
Vous pouvez choisir Create job (Créer une tâche) dans le flux Data Wrangler pour afficher les instructions relatives à l'utilisation d'une tâche de traitement pour mettre à jour le groupe de fonctionnalités.
-
Sélectionnez le symbole + à côté du nœud contenant le jeu de données que vous souhaitez exporter.
-
Sous Ajouter une destination, choisissez SageMaker AI Feature Store.
-
Choisissez (double-cliquez sur) le groupe de fonctionnalités. Data Wrangler vérifie si le schéma du groupe de fonctionnalités correspond au schéma des données que vous utilisez pour mettre à jour le groupe de fonctionnalités.
-
(Facultatif) Sélectionnez Export to offline store only (Exporter vers le magasin hors ligne uniquement) pour les groupes de fonctionnalités qui ont à la fois un magasin en ligne et un magasin hors ligne. Cette option ne met à jour le magasin hors ligne qu'avec les observations de votre jeu de données.
-
Après que Data Wrangler a validé le schéma de votre jeu de données, choisissez Add (Ajouter).
Utilisez la procédure suivante pour créer un groupe de fonctionnalités avec les données de votre jeu de données.
Vous pouvez enregistrer votre groupe de fonctionnalités de l'une des manières suivantes :
-
En ligne : cache à faible latence et haute disponibilité pour un groupe de fonctionnalités, qui permet la recherche en temps réel d'enregistrements. Le magasin en ligne permet d'accéder rapidement à la dernière valeur d'un enregistrement dans un groupe de fonctionnalités.
-
Hors ligne : stocke les données de votre groupe de fonctionnalités dans un compartiment Amazon S3. Vous pouvez stocker vos données hors ligne lorsque vous n'avez pas besoin de lectures à faible latence (inférieure à une seconde). Vous pouvez utiliser un magasin hors ligne pour les fonctionnalités utilisées dans l'exploration des données, l'entraînement des modèles et l'inférence par lots.
-
En ligne et hors ligne : stocke vos données à la fois dans un magasin en ligne et dans un magasin hors ligne.
Pour créer un groupe de fonctionnalités à l'aide d'un nœud de destination, procédez comme suit.
-
Sélectionnez le symbole + à côté du nœud contenant le jeu de données que vous souhaitez exporter.
-
Sous Ajouter une destination, choisissez SageMaker AI Feature Store.
-
Choisissez Create Feature Group (Créer un groupe de fonctionnalités).
-
Dans la boîte de dialogue suivante, si votre ensemble de données ne comporte pas de colonne d'heure d'événement, sélectionnez Créer une colonne EventTime « ».
-
Choisissez Next (Suivant).
-
Sélectionnez Copy JSON Schema (Copier le schéma JSON). Lorsque vous créez un groupe de fonctionnalités, vous collez le schéma dans les définitions de fonctionnalités.
-
Sélectionnez Create (Créer).
-
Pour Feature group name (Nom du groupe de fonctionnalités), spécifiez un nom pour votre groupe de fonctionnalités.
-
Dans le champ Description (optional) [Description (facultatif)], indiquez une description pour faciliter la découverte de votre groupe de fonctionnalités.
-
Pour créer un groupe de fonctionnalités pour un magasin en ligne, procédez comme suit.
-
Sélectionnez Enable storage online (Activer le stockage en ligne).
-
Pour la clé de chiffrement de la boutique en ligne, spécifiez une clé de chiffrement AWS gérée ou votre propre clé de chiffrement.
-
Pour créer un groupe de fonctionnalités pour un magasin hors ligne, procédez comme suit.
-
Sélectionnez Enable storage offline (Activer le stockage hors ligne). Spécifiez des valeurs pour les champs suivants :
-
S3 bucket name (Nom du compartiment S3) : nom du compartiment Amazon S3 qui stocke le groupe de fonctionnalités.
-
(Optional) Dataset directory name [(Facultatif) Nom du répertoire du jeu de données] : préfixe Amazon S3 que vous utilisez pour stocker le groupe de fonctionnalités.
-
IAM Role ARN (ARN du rôle IAM) : rôle IAM qui a accès à Feature Store.
-
Table Format (Format de tableau) : format de tableau de votre magasin hors ligne. Vous pouvez spécifier Glue ou Iceberg. Glue est le format par défaut.
-
Offline store encryption key (Clé de chiffrement du magasin hors ligne) : par défaut, Feature Store utilise une clé gérée par AWS Key Management Service , mais vous pouvez utiliser ce champ pour spécifier une clé de votre choix.
-
Spécifiez des valeurs pour les champs suivants :
-
S3 bucket name (Nom du compartiment S3) : le nom du compartiment qui stocke le groupe de fonctionnalités.
-
(Optional) Dataset directory name [(Facultatif) Nom du répertoire du jeu de données] : le préfixe Amazon S3 que vous utilisez pour stocker le groupe de fonctionnalités.
-
IAM Role ARN (ARN du rôle IAM) : le rôle IAM qui a accès à Feature Store.
-
Offline store encryption key (Clé de chiffrement du magasin hors ligne) : par défaut, Feature Store utilise une clé gérée par AWS , mais vous pouvez utiliser ce champ pour spécifier une clé de votre choix.
-
Choisissez Continue (Continuer).
-
Choisissez JSON.
-
Supprimez les crochets d'espace réservé dans la fenêtre.
-
Collez le texte JSON de l'étape 6.
-
Choisissez Continue (Continuer).
-
Pour RECORD IDENTIFIER FEATURE NAME (NOM DE LA FONCTIONNALITÉ DE L'IDENTIFIANT D'ENREGISTREMENT), choisissez la colonne de votre jeu de données qui possède des identifiants uniques pour chaque enregistrement de votre jeu de données.
-
Pour EVENT TIME FEATURE NAME (NOM DE LA FONCTIONNALITÉ D'HEURE DE L'ÉVÉNEMENT), choisissez la colonne contenant les valeurs d'horodatage.
-
Choisissez Continue (Continuer).
-
(Facultatif) Ajoutez des balises pour faciliter la découverte de votre groupe de fonctionnalités.
-
Choisissez Continue (Continuer).
-
Choisissez Create Feature Group (Créer un groupe de fonctions).
-
Revenez à votre flux Data Wrangler et cliquez sur l'icône d'actualisation à côté de la barre de recherche Feature Group (Groupe de fonctionnalités).
Si vous avez déjà créé un nœud de destination pour un groupe de fonctionnalités dans un flux, vous ne pouvez pas créer un autre nœud de destination pour le même groupe de fonctionnalités. Si vous souhaitez créer un autre nœud de destination pour le même groupe de fonctionnalités, vous devez créer un autre fichier de flux.
Utilisez la procédure suivante pour créer une tâche Data Wrangler.
Créez une tâche à partir de la page Data flow (Flux de données) et choisissez les nœuds de destination que vous souhaitez exporter.
-
Choisissez Create job (Créer une tâche). L'image suivante représente le panneau qui s'affiche lorsque vous sélectionnez Create job (Créer une tâche).
-
Pour Job name (Nom de la tâche), indiquez le nom de la tâche d'exportation.
-
Choisissez les nœuds de destination que vous souhaitez exporter.
-
(Facultatif) Pour la clé KMS en sortie, spécifiez un ARN, un ID ou un alias de AWS KMS clé. Une clé KMS est une clé de chiffrement. Vous pouvez utiliser la clé pour chiffrer les données de sortie de la tâche. Pour plus d'informations sur AWS KMS les clés, consultez AWS Key Management Service.
-
L'image suivante montre la page Configure job (Configurer la tâche) avec l'onglet Job configuration (Configuration de la tâche) ouvert.
(Facultatif) Sous Trained parameters (Paramètres entraînés), choisissez Refit (Adapter) si vous avez effectué les opérations suivantes :
Pour plus d'informations sur l'adaptation des transformations que vous avez effectuées sur l'ensemble d'un jeu de données, consultez Adaptez les transformations à la totalité du jeu de données et exportez-les.
-
Choisissez Configure job (Configurer la tâche).
-
(Facultatif) Configurez la tâche Data Wrangler. Vous pouvez réaliser les configurations suivantes :
-
Cliquez sur Exécuter.
- Jupyter notebook
-
Utilisez la procédure suivante pour exporter un bloc-notes Jupyter vers Amazon SageMaker Feature Store.
Utilisez la procédure suivante pour générer un bloc-notes Jupyter et l'exécuter pour exporter votre flux Data Wrangler vers Feature Store.
-
Cliquez sur l'icône + en regard du nœud que vous souhaitez exporter.
-
Choisissez Export to (Exporter vers).
-
Choisissez Amazon SageMaker Feature Store (via Jupyter Notebook).
-
Exécutez le bloc-notes Jupyter.
L'exécution d'un bloc-notes Jupyter exécute également une tâche Data Wrangler. L'exécution d'une tâche Data Wrangler démarre une tâche de traitement par SageMaker IA. La tâche de traitement intègre le flux dans un référentiel Feature Store en ligne et hors ligne.
Le rôle IAM que vous utilisez pour exécuter ce cahier doit avoir les politiques gérées AWS suivantes attachées : AmazonSageMakerFullAccess et AmazonSageMakerFeatureStoreAccess.
Vous ne devez activer qu'un seul Feature Store en ligne ou hors ligne lorsque vous créez un groupe de fonctions. Vous pouvez également activer les deux. Pour désactiver la création du magasin en ligne, définissez EnableOnlineStore sur False :
# Online Store Configuration
online_store_config = {
"EnableOnlineStore": False
}
Le bloc-notes utilise les noms et les types de colonnes du dataframe que vous exportez pour créer un schéma de groupe de fonctions, qui est utilisé pour créer un groupe de fonctions. Un groupe de fonctions est un groupe défini dans le Feature Store pour décrire un enregistrement. Le groupe de fonctions définit la structure et les fonctions qu'il contient. La définition d'un groupe de fonctions est composée d'une liste de fonctions, d'un nom de fonction d'identifiant d'enregistrement, d'un nom de fonction d'heure d'événement et de configurations pour son magasin en ligne et son magasin hors ligne.
Chaque fonction d'un groupe de fonctions peut avoir l'un des types suivants : String (Chaîne), Fractional (Fractionnel) ou Integral (Intégral). Si une colonne de la trame de données exportée n'est pas l'un de ces types, elle est définie par défaut sur String.
Voici un exemple de schéma de groupe de fonctions.
column_schema = [
{
"name": "Height",
"type": "long"
},
{
"name": "Input",
"type": "string"
},
{
"name": "Output",
"type": "string"
},
{
"name": "Sum",
"type": "string"
},
{
"name": "Time",
"type": "string"
}
]
En outre, vous devez spécifier un nom d'identifiant d'enregistrement et un nom de fonction d'heure d'événement :
-
Le nom de l'identifiant d'enregistrement est le nom de la fonction dont la valeur identifie de manière unique un enregistrement défini dans le Feature Store. Seul le dernier enregistrement par valeur d'identifiant est stocké dans le magasin en ligne. Le nom de la fonction de l'identifient d'enregistrement doit être l'un des noms des définitions de la fonction.
-
Le nom de la fonction du moment de l'événement est le nom de la fonction qui stocke le paramètre EventTime d'un enregistrement dans un groupe de fonctions. EventTime est un moment où se produit un nouvel événement qui correspond à la création ou à la mise à jour d'un enregistrement dans une fonction. Tous les enregistrements du groupe de fonctions doivent avoir un EventTime correspondant.
Le bloc-notes utilise ces configurations pour créer un groupe fonctions, traiter vos données à l'échelle, puis intégrer les données traitées dans vos Feature Store en ligne et hors ligne. Pour en savoir plus, veuillez consulter Sources de données et intégration.
Le bloc-notes utilise ces configurations pour créer un groupe de fonctions, traiter vos données à l'échelle, puis intégrer les données traitées dans vos Feature Store en ligne et hors ligne. Pour en savoir plus, veuillez consulter Sources de données et intégration.
Lorsque vous importez des données, Data Wrangler utilise un échantillon des données pour appliquer les codages. Par défaut, Data Wrangler utilise les 50 000 premières lignes comme échantillon, mais vous pouvez importer la totalité du jeu de données ou utiliser une autre méthode d'échantillonnage. Pour plus d'informations, veuillez consulter Importer.
Les transformations suivantes utilisent vos données pour créer une colonne dans le jeu de données :
Si vous avez utilisé l'échantillonnage pour importer vos données, les transformations précédentes utilisent uniquement les données de l'échantillon pour créer la colonne. La transformation peut ne pas avoir utilisé toutes les données pertinentes. Par exemple, si vous utilisez la transformation Encode Categorical (Encodage catégoriel), il peut y avoir une catégorie de l'ensemble du jeu de données qui n'était pas présente dans l'échantillon.
Vous pouvez utiliser un nœud de destination ou un bloc-notes Jupyter pour adapter les transformations à la totalité du jeu de données. Lorsque Data Wrangler exporte les transformations du flux, il crée une tâche de SageMaker traitement. Une fois cette tâche de traitement terminée, Data Wrangler enregistre les fichiers suivants dans l'emplacement Amazon S3 par défaut ou dans un emplacement S3 que vous spécifiez :
Vous pouvez ouvrir un fichier de flux Data Wrangler dans Data Wrangler et appliquer les transformations à un autre jeu de données. Par exemple, si vous avez appliqué les transformations à un jeu de données d'entraînement, vous pouvez ouvrir et utiliser le fichier de flux Data Wrangler pour appliquer les transformations à un jeu de données utilisé pour l'inférence.
Pour plus d'informations sur l'utilisation des nœuds de destination pour adapter les transformations et les exporter, consultez les pages suivantes :
Utilisez la procédure suivante pour exécuter un bloc-notes Jupyter afin d'adapter les transformations et d'exporter les données.
Pour exécuter un bloc-notes Jupyter, adapter les transformations et exporter le flux Data Wrangler, procédez comme suit.
-
Cliquez sur l'icône + en regard du nœud que vous souhaitez exporter.
-
Choisissez Export to (Exporter vers).
-
Choisissez l'emplacement vers lequel vous souhaitez exporter les données.
-
Pour l'objet refit_trained_params, définissez refit sur True.
-
Pour le champ output_flow, spécifiez le nom du fichier de flux de sortie contenant les transformations adaptées.
-
Exécutez le bloc-notes Jupyter.
Création d'un calendrier pour traiter automatiquement les nouvelles données
Si vous traitez des données régulièrement, vous pouvez créer un calendrier pour exécuter automatiquement la tâche de traitement. Par exemple, vous créez une planification qui exécute automatiquement une tâche de traitement lorsque vous recevez de nouvelles données. Pour plus d'informations sur ces processus, veuillez consulter Exporter vers Amazon S3 et Exporter vers Amazon SageMaker Feature Store.
Lorsque vous créez une tâche, vous devez spécifier un rôle IAM autorisé à la créer. Par défaut, le rôle IAM que vous utilisez pour accéder à Data Wrangler est le SageMakerExecutionRole.
Les autorisations suivantes permettent à Data Wrangler d'accéder aux tâches de traitement EventBridge et EventBridge de les exécuter :
-
Ajoutez la politique AWS gérée suivante au rôle d'exécution Amazon SageMaker Studio Classic qui fournit à Data Wrangler les autorisations d'utilisation : EventBridge
arn:aws:iam::aws:policy/AmazonEventBridgeFullAccess
Pour plus d'informations sur la stratégie, consultez la section Politiques AWS gérées pour EventBridge.
-
Ajoutez la stratégie suivante au rôle IAM que vous spécifiez lorsque vous créez une tâche dans Data Wrangler :
- JSON
-
-
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Action": "sagemaker:StartPipelineExecution",
"Resource": "arn:aws:sagemaker:us-east-1:111122223333:pipeline/data-wrangler-*"
}
]
}
Si vous utilisez le rôle IAM par défaut, vous ajoutez la politique précédente au rôle d'exécution Amazon SageMaker Studio Classic.
Ajoutez la politique de confiance suivante au rôle pour EventBridge permettre de l'assumer.
{
"Effect": "Allow",
"Principal": {
"Service": "events.amazonaws.com"
},
"Action": "sts:AssumeRole"
}
Lorsque vous créez un planning, Data Wrangler crée un eventRule in. EventBridge Des frais vous sont facturés à la fois pour les règles d'événement que vous créez et pour les instances utilisées pour exécuter la tâche de traitement.
Pour plus d'informations sur EventBridge les tarifs, consultez EventBridge les tarifs Amazon. Pour plus d'informations sur le traitement des tarifs des offres d'emploi, consultez Amazon SageMaker Pricing.
Vous pouvez définir une planification à l'aide d'une des méthodes suivantes :
Les sections suivantes fournissent des procédures sur la création de tâches.
- CRON
-
Utilisez la procédure suivante pour créer un calendrier à l'aide d'une expression CRON.
Pour spécifier un calendrier à l'aide d'une expression CRON, procédez comme suit.
-
Ouvrez votre flux Data Wrangler.
-
Choisissez Créer une tâche.
-
(Facultatif) Pour la clé KMS de sortie, spécifiez une AWS KMS clé pour configurer la sortie de la tâche.
-
Choisissez Next (Suivant), 2. Sélectionnez Configure job (Configurer la tâche).
-
Sélectionnez Associate Schedules (Horaires associés).
-
Choisissez Create a new schedule (Créer une planification).
-
Dans le champ Schedule Name (Nom de la planification), indiquez le nom de la planification.
-
Pour Run Frequency (Fréquence d'exécution), choisissez CRON.
-
Spécifiez une expression CRON valide.
-
Choisissez Créer.
-
(Facultatif) Choisissez Add another schedule (Ajouter une autre planification) pour exécuter la tâche selon une autre planification.
Vous pouvez associer un maximum de deux planifications. Les planifications sont indépendantes et ne s'influencent pas mutuellement, sauf si les heures se chevauchent.
-
Sélectionnez l'une des méthodes suivantes :
-
Schedule and run now (Planifier et exécuter maintenant) : Data Wrangler exécute la tâche immédiatement et l'exécute ensuite selon les planifications.
-
Schedule only (Planifier uniquement) : Data Wrangler exécute la tâche uniquement selon les planifications que vous spécifiez.
-
Cliquez sur Run (Exécuter).
- RATE
-
Utilisez la procédure suivante pour créer un calendrier à l'aide d'une expression RATE.
Pour spécifier un calendrier à l'aide d'une expression CRON, procédez comme suit.
-
Ouvrez votre flux Data Wrangler.
-
Choisissez Créer une tâche.
-
(Facultatif) Pour la clé KMS de sortie, spécifiez une AWS KMS clé pour configurer la sortie de la tâche.
-
Choisissez Next (Suivant), 2. Sélectionnez Configure job (Configurer la tâche).
-
Sélectionnez Associate Schedules (Horaires associés).
-
Choisissez Create a new schedule (Créer une planification).
-
Dans le champ Schedule Name (Nom de la planification), indiquez le nom de la planification.
-
Pour Run Frequency (Fréquence d'exécution), choisissez Rate (Taux).
-
Pour Value (Valeur), spécifiez un entier.
-
Pour Unit (Unité), sélectionnez l'une des options suivantes :
-
Choisissez Créer.
-
(Facultatif) Choisissez Add another schedule (Ajouter une autre planification) pour exécuter la tâche selon une autre planification.
Vous pouvez associer un maximum de deux planifications. Les planifications sont indépendantes et ne s'influencent pas mutuellement, sauf si les heures se chevauchent.
-
Sélectionnez l'une des méthodes suivantes :
-
Schedule and run now (Planifier et exécuter maintenant) : Data Wrangler exécute la tâche immédiatement et l'exécute ensuite selon les planifications.
-
Schedule only (Planifier uniquement) : Data Wrangler exécute la tâche uniquement selon les planifications que vous spécifiez.
-
Cliquez sur Run (Exécuter).
- Recurring
-
Utilisez la procédure suivante pour créer une planification qui exécute une tâche de manière récurrente.
Pour spécifier un calendrier à l'aide d'une expression CRON, procédez comme suit.
-
Ouvrez votre flux Data Wrangler.
-
Choisissez Créer une tâche.
-
(Facultatif) Pour la clé KMS de sortie, spécifiez une AWS KMS clé pour configurer la sortie de la tâche.
-
Choisissez Next (Suivant), 2. Sélectionnez Configure job (Configurer la tâche).
-
Sélectionnez Associate Schedules (Horaires associés).
-
Choisissez Create a new schedule (Créer une planification).
-
Dans le champ Schedule Name (Nom de la planification), indiquez le nom de la planification.
-
Dans le champ Run Frequency (Fréquence d'exécution), assurez-vous que l'option Recurring (Récurrent) est sélectionnée par défaut.
-
Dans le champ Every x hours (Toutes les x heures), spécifiez la fréquence horaire à laquelle la tâche s'exécute au cours de la journée. Les valeurs valides sont des nombres entiers compris entre 1 et 23.
-
Pour On days (Journées), choisissez l'une des options suivantes :
-
Every Day (Tous les jours)
-
Weekends (Le week-end)
-
Weekdays (Jours de la semaine)
-
Select Days (Certains jours)
-
(Facultatif) Si vous avez sélectionné Select Days (Certains jours), choisissez les jours de la semaine où la tâche doit s'exécuter.
La planification est réinitialisée tous les jours. Si vous planifiez une tâche pour qu'elle s'exécute toutes les cinq heures, elle s'exécute aux heures suivantes au cours de la journée :
-
00:00
-
05:00
-
10 h 00
-
15h00
-
20h00
-
Choisissez Créer.
-
(Facultatif) Choisissez Add another schedule (Ajouter une autre planification) pour exécuter la tâche selon une autre planification.
Vous pouvez associer un maximum de deux planifications. Les planifications sont indépendantes et ne s'influencent pas mutuellement, sauf si les heures se chevauchent.
-
Sélectionnez l'une des méthodes suivantes :
-
Schedule and run now (Planifier et exécuter maintenant) : Data Wrangler exécute la tâche immédiatement et l'exécute ensuite selon les planifications.
-
Schedule only (Planifier uniquement) : Data Wrangler exécute la tâche uniquement selon les planifications que vous spécifiez.
-
Cliquez sur Run (Exécuter).
- Specific time
-
Utilisez la procédure suivante pour créer une planification qui exécute une tâche à des heures spécifiques.
Pour spécifier un calendrier à l'aide d'une expression CRON, procédez comme suit.
-
Ouvrez votre flux Data Wrangler.
-
Choisissez Créer une tâche.
-
(Facultatif) Pour la clé KMS de sortie, spécifiez une AWS KMS clé pour configurer la sortie de la tâche.
-
Choisissez Next (Suivant), 2. Sélectionnez Configure job (Configurer la tâche).
-
Sélectionnez Associate Schedules (Horaires associés).
-
Choisissez Create a new schedule (Créer une planification).
-
Dans le champ Schedule Name (Nom de la planification), indiquez le nom de la planification.
-
Choisissez Créer.
-
(Facultatif) Choisissez Add another schedule (Ajouter une autre planification) pour exécuter la tâche selon une autre planification.
Vous pouvez associer un maximum de deux planifications. Les planifications sont indépendantes et ne s'influencent pas mutuellement, sauf si les heures se chevauchent.
-
Sélectionnez l'une des méthodes suivantes :
-
Schedule and run now (Planifier et exécuter maintenant) : Data Wrangler exécute la tâche immédiatement et l'exécute ensuite selon les planifications.
-
Schedule only (Planifier uniquement) : Data Wrangler exécute la tâche uniquement selon les planifications que vous spécifiez.
-
Cliquez sur Run (Exécuter).
Vous pouvez utiliser Amazon SageMaker Studio Classic pour afficher les tâches dont l'exécution est planifiée. Vos tâches de traitement s'exécutent dans Pipelines. Chaque tâche de traitement possède son propre pipeline. Elle s'exécute en tant qu'étape de traitement dans le pipeline. Vous pouvez consulter les planifications que vous avez créées dans un pipeline. Pour plus d'informations sur l'affichage d'un pipeline, veuillez consulter Afficher les détails d'un pipeline.
Utilisez la procédure suivante pour afficher les tâches que vous avez planifiées.
Pour afficher les tâches que vous avez planifiées, procédez comme suit.
-
Ouvrez Amazon SageMaker Studio Classic.
-
Canalisations ouvertes
-
Consultez les pipelines des tâches que vous avez créées.
Le pipeline qui exécute la tâche utilise le nom de la tâche en tant que préfixe. Par exemple, si vous avez créé une tâche nommée housing-data-feature-enginnering, le nom du pipeline est data-wrangler-housing-data-feature-engineering.
-
Choisissez le pipeline contenant votre tâche.
-
Consultez l'état des pipelines. Les pipelines dont le champ Status (État) indique Succeeded (Réussi) ont correctement exécuté la tâche de traitement.
Pour arrêter l'exécution de la tâche de traitement, procédez comme suit :
Pour arrêter l'exécution d'une tâche de traitement, supprimez la règle d'événement qui spécifie la planification. La suppression d'une règle d'événement arrête l'exécution de toutes les tâches associées à la planification. Pour plus d'informations sur la suppression d'une règle, consultez la section Désactivation ou suppression d'une EventBridge règle Amazon.
Vous pouvez également arrêter et supprimer les pipelines associés aux planifications. Pour plus d'informations sur l'arrêt d'un pipeline, consultez StopPipelineExecution. Pour plus d'informations sur la suppression d'un pipeline, consultez DeletePipeline.