Les traductions sont fournies par des outils de traduction automatique. En cas de conflit entre le contenu d'une traduction et celui de la version originale en anglais, la version anglaise prévaudra.
Importer
Vous pouvez utiliser Amazon SageMaker Data Wrangler pour importer des données à partir des sources de données suivantes : Amazon Simple Storage Service (Amazon S3), Amazon Athena, Amazon Redshift et Snowflake. Le jeu de données que vous importez peut contenir jusqu'à 1 000 colonnes.
Certaines sources de données vous permettent d'ajouter plusieurs connexions de données :
-
Vous pouvez vous connecter à plusieurs clusters Amazon Redshift. Chaque cluster devient une source de données.
-
Vous pouvez interroger n'importe quelle base de données Athena de votre compte pour importer des données à partir de cette base de données.
Lorsque vous importez un jeu de données à partir d'une source de données, il apparaît dans votre flux de données. Data Wrangler déduit automatiquement le type de données de chaque colonne de votre jeu de données. Pour modifier ces types, sélectionnez l'étape Data types (Types de données) et sélectionnez Edit data types (Modifier les types de données).
Lorsque vous importez des données depuis Athena ou Amazon Redshift, les données importées sont automatiquement stockées dans le compartiment AI S3 SageMaker par défaut de AWS la région dans laquelle vous utilisez Studio Classic. En outre, Athena stocke les données que vous prévisualisez dans Data Wrangler dans ce compartiment. Pour en savoir plus, veuillez consulter la section Stockage des données importées.
Important
Le compartiment Amazon S3 par défaut peut ne pas avoir les paramètres de sécurité les moins permissifs, tels que la politique de compartiment et le chiffrement côté serveur (SSE). Nous vous recommandons vivement d'ajouter une politique de compartiment pour restreindre l'accès aux jeux de données importés dans Data Wrangler.
Important
En outre, si vous utilisez la politique gérée pour l' SageMaker IA, nous vous recommandons vivement de la limiter à la politique la plus restrictive qui vous permet de réaliser votre cas d'utilisation. Pour de plus amples informations, veuillez consulter Accorder à un rôle IAM l'autorisation d'utiliser Data Wrangler.
Toutes les sources de données, à l'exception d'Amazon Simple Storage Service (Amazon S3) nécessitent que vous spécifiiez une requête SQL pour importer vos données. Pour chaque requête, vous devez spécifier les informations suivantes :
-
Data catalog (Catalogue de données)
-
Database (Base de données)
-
Tableau
Vous pouvez spécifier le nom de la base de données ou du catalogue de données dans les menus déroulants ou dans la requête. Voici quelques exemples de requêtes :
-
select * from- Pour son exécution, la requête n'utilise aucun élément spécifié dans les menus déroulants de l'interface utilisateur (UI). Elle interrogeexample-data-catalog-name.example-database-name.example-table-nameexample-table-namedansexample-database-namedansexample-data-catalog-name. -
select * from- La requête utilise le catalogue de données que vous avez spécifié dans le menu déroulant Data catalog (Catalogue de données) pour s'exécuter. Elle interrogeexample-database-name.example-table-nameexample-table-namedansexample-database-namedans le catalogue de données que vous avez spécifié. -
select * from- La requête vous oblige à sélectionner des champs pour les menus déroulants Data catalog (Catalogue de données) et Database name (Nom de la base de données). Elle interrogeexample-table-nameexample-table-namedans le catalogue de données que vous avez spécifié.
La liaison entre Data Wrangler et la source de données est une connexion. Elle vous permet d'importer des données à partir de votre source de données.
Il existe les types de connexions suivants :
-
Direct (Directe)
-
Cataloged (Cataloguée)
Data Wrangler a toujours accès aux données les plus récentes via une connexion directe. Si les données de la source de données ont été mises à jour, vous pouvez utiliser la connexion pour importer les données. Par exemple, si quelqu'un ajoute un fichier à l'un de vos compartiments Amazon S3, vous pouvez importer le fichier.
Une connexion cataloguée est le résultat d'un transfert de données. Les données de la connexion cataloguée ne contiennent pas nécessairement les données les plus récentes. Par exemple, vous pouvez configurer un transfert de données entre Salesforce et Amazon S3. Si les données Salesforce sont mises à jour, vous devez les transférer à nouveau. Vous pouvez automatiser le processus de transfert des données. Pour plus d'informations sur les rôles d'utilisateur, veuillez consulter Importer des données à partir de plateformes de logiciel en tant que service (SaaS).
Importer des données depuis Amazon S3
Vous pouvez utiliser Amazon Simple Storage Service (Amazon S3) pour stocker et récupérer n'importe quelle quantité de données, à tout moment, de n'importe où sur le Web. Vous pouvez accomplir ces tâches à l' AWS Management Console aide de l'interface Web simple et intuitive et de l'API Amazon S3. Si vous avez stocké votre jeu de données localement, nous vous recommandons de l'ajouter à un compartiment S3 pour l'importer dans Data Wrangler. Pour savoir comment procéder, consultez la rubrique Chargement d'un objet dans un compartiment dans le Guide de l'utilisateur Amazon Simple Storage Service.
Data Wrangler utilise S3 Select
Important
Si vous envisagez d'exporter un flux de données et de lancer une tâche Data Wrangler, d'ingérer des données dans un feature SageMaker store d'intelligence artificielle ou de créer un pipeline d' SageMaker intelligence artificielle, sachez que ces intégrations nécessitent que les données d'entrée Amazon S3 soient situées dans la même région. AWS
Important
Si vous importez un fichier CSV, assurez-vous qu'il répond aux exigences suivantes :
-
Tout registre dans votre jeu de données ne peut pas dépasser une ligne.
-
La barre oblique inverse (
\) est le seul caractère d'échappement valide. -
Votre jeu de données doit utiliser l'un des délimiteurs suivants :
-
Virgule –
, -
Deux-points –
: -
Point-virgule –
; -
Barre verticale –
| -
Tab –
[TAB]
-
Pour économiser de l'espace, vous pouvez importer des fichiers CSV compressés.
Data Wrangler vous permet d'importer l'intégralité du jeu de données ou d'en échantillonner une partie. Pour Amazon S3, il fournit les options d'échantillonnage suivantes :
-
None (Aucun) : importez l'intégralité du jeu de données.
-
First K (K premières lignes) : échantillonnez les K premières lignes du jeu de données, où K est un entier que vous spécifiez.
-
Randomized (Aléatoire) : prélève un échantillon aléatoire d'une taille que vous spécifiez.
-
Stratified (Stratifié) : prélève un échantillon aléatoire stratifié. Un échantillon stratifié conserve le rapport des valeurs dans une colonne.
Une fois que vous avez importé vos données, vous pouvez également utiliser le transformateur d'échantillonnage pour prélever un ou plusieurs échantillons de votre jeu de données. Pour plus d'informations sur le transformateur d'échantillonnage, consultez Echantillonnage.
Vous pouvez utiliser l'un des identificateurs de ressources suivants pour importer vos données :
-
Une URI Amazon S3 utilisant un compartiment Amazon S3 ou un point d'accès Amazon S3
-
Un alias de points d'accès Amazon S3
-
Une Amazon Resource Name (ARN) utilisant un point d'accès Amazon S3 ou un compartiment Amazon S3
Les points d'accès Amazon S3 sont appelés points de terminaison réseau attachés aux compartiments. Chaque point d'accès dispose d'autorisations et de contrôles réseau que vous pouvez configurer. Pour plus d'informations sur les points d'accès, consultez Gestion de l'accès aux données avec les points d'accès Amazon S3.
Important
Si vous utilisez un Amazon Resource Name (ARN) pour importer vos données, il doit s'agir d'une ressource située dans le même nom Région AWS que celui que vous utilisez pour accéder à Amazon SageMaker Studio Classic.
Vous pouvez importer un seul fichier ou plusieurs fichiers en tant que jeu de données. Vous pouvez utiliser l'opération d'importation de plusieurs fichiers lorsque vous disposez d'un jeu de données partitionné dans des fichiers distincts. Elle prend tous les fichiers d'un répertoire Amazon S3 et les importe en tant que jeu de données unique. Pour plus d'informations sur les types de fichiers que vous pouvez importer et sur la façon de les importer, reportez-vous aux sections suivantes.
Vous pouvez également utiliser des paramètres pour importer un sous-ensemble de fichiers correspondant à un modèle. Les paramètres vous permettent de sélectionner de manière plus sélective les fichiers à importer. Pour commencer à utiliser des paramètres, modifiez la source de données et appliquez-les au chemin que vous utilisez pour importer les données. Pour de plus amples informations, veuillez consulter Réutilisation de flux de données pour différents jeux de données.
Importer des données depuis Athena
Utilisez Amazon Athena pour importer vos données depuis Amazon Simple Storage Service (Amazon S3) dans Data Wrangler. Dans Athena, vous écrivez des requêtes SQL standard pour sélectionner les données que vous importez depuis Amazon S3. Pour plus d'informations, consultez Qu'est-ce que Amazon Athena ?.
Vous pouvez utiliser le AWS Management Console pour configurer Amazon Athena. Vous devez créer au moins une base de données dans Athena avant de commencer à exécuter des requêtes. Pour plus d'informations sur la mise en route avec Athena, consultez Démarrer.
Athena est directement intégré à Data Wrangler. Vous pouvez écrire des requêtes Athena sans avoir à quitter l'interface utilisateur de Data Wrangler.
En plus d'écrire des requêtes Athena simples dans Data Wrangler, vous pouvez également utiliser :
-
Groupes de travail Athena pour la gestion des résultats des requêtes. Pour plus d'informations sur les groupes de travail, consultez Gestion des résultats de requêtes.
-
Configurations du cycle de vie pour définir les périodes de conservation des données. Pour plus d'informations sur la conservation des données, consultez Définition de la durée de conservation des données.
Interroger Athena dans Data Wrangler
Note
Data Wrangler ne prend pas en charge les requêtes fédérées.
Si vous l'utilisez AWS Lake Formation avec Athena, assurez-vous que vos autorisations IAM de Lake Formation ne remplacent pas les autorisations IAM pour la base de données. sagemaker_data_wrangler
Data Wrangler vous permet d'importer l'intégralité du jeu de données ou d'en échantillonner une partie. Pour Athena, il fournit les options d'échantillonnage suivantes :
-
None (Aucun) : importez l'intégralité du jeu de données.
-
First K (K premières lignes) : échantillonnez les K premières lignes du jeu de données, où K est un entier que vous spécifiez.
-
Randomized (Aléatoire) : prélève un échantillon aléatoire d'une taille que vous spécifiez.
-
Stratified (Stratifié) : prélève un échantillon aléatoire stratifié. Un échantillon stratifié conserve le rapport des valeurs dans une colonne.
La procédure suivante montre comment importer un jeu de données d'Athena dans Data Wrangler.
Pour importer un jeu de données dans Data Wrangler à partir d'Athena
-
Connectez-vous à Amazon SageMaker AI Console
. -
Choisissez Studio.
-
Choisissez Launch app (Lancer l'application).
-
Dans la liste déroulante, sélectionnez Studio.
-
Choisissez l'icône d'accueil.
-
Choisissez Data (Données).
-
Choisissez Data Wrangler.
-
Choisissez Import data (Importer les données).
-
Sous Available (Disponible), sélectionnez Amazon Athena.
-
Pour Catalogue de données, choisissez un catalogue de données.
-
Utilisez la liste déroulante Database (Base de données) pour sélectionner la base de données que vous souhaitez interroger. Lorsque vous sélectionnez une base de données, vous pouvez prévisualiser toutes les tables de votre base de données en utilisant les Tables listées sous Details (Détails).
-
(Facultatif) Choisissez Advanced configuration (Configuration avancée).
-
Choisissez un Workgroup (Groupe de travail).
-
Si votre groupe de travail n'a pas appliqué l'emplacement de sortie Amazon S3 ou si vous n'avez pas utilisé un groupe de travail, spécifiez une valeur pour Emplacement Amazon S3 des résultats des requêtes.
-
(Facultatif) Pour la zone Data retention period (Durée de conservation des données), cochez la case permettant de définir une durée de conservation des données et spécifiez le nombre de jours pendant lesquels les données doivent être stockées avant leur suppression.
-
(Facultatif) Par défaut, Data Wrangler enregistre la connexion. Vous pouvez choisir de désélectionner la case à cocher et de ne pas enregistrer la connexion.
-
-
Pour Sampling (Échantillonnage), choisissez une méthode d'échantillonnage. Choisissez None (Aucun) pour désactiver l'échantillonnage.
-
Saisissez votre requête dans l'éditeur de requête et utilisez le bouton Run (Exécuter) pour l'exécuter. Après une requête réussie, vous pouvez prévisualiser votre résultat sous l'éditeur.
Note
Les données Salesforce utilisent le type
timestamptz. Si vous interrogez la colonne d'horodatage que vous avez importée dans Athena depuis Salesforce, convertissez les données de la colonne au typetimestamp. La requête suivante convertit la colonne d'horodatage au type approprié.# cast column timestamptz_col as timestamp type, and name it as timestamp_col select cast(timestamptz_col as timestamp) as timestamp_col from table -
Pour importer les résultats de votre requête, sélectionnez Import (Importer).
Une fois que vous avez terminé la procédure précédente, le jeu de données que vous avez interrogé et importé apparaît dans le flux Data Wrangler.
Par défaut, Data Wrangler enregistre les paramètres de connexion en tant que nouvelle connexion. Lorsque vous importez vos données, la requête que vous avez déjà spécifiée apparaît sous la forme d'une nouvelle connexion. Les connexions enregistrées stockent des informations sur les groupes de travail Athena et les compartiments Amazon S3 que vous utilisez. Lorsque vous vous reconnectez à la source de données, vous pouvez choisir la connexion enregistrée.
Gestion des résultats de requêtes
Data Wrangler prend en charge l'utilisation de groupes de travail Athena pour gérer les résultats de requête dans un compte AWS . Vous pouvez spécifier un emplacement de sortie Amazon S3 pour chaque groupe de travail. Vous pouvez également spécifier si la sortie de la requête peut être envoyée à différents emplacements Amazon S3. Pour plus d'informations, veuillez consulter Utilisation des groupes de travail pour contrôler l'accès aux requêtes et les coûts.
Votre groupe de travail peut-être configuré pour appliquer l'emplacement de sortie des requêtes Amazon S3. Vous ne pouvez pas modifier l'emplacement de sortie des résultats de la requête pour ces groupes de travail.
Si vous n'utilisez pas de groupe de travail ou si vous ne spécifiez pas d'emplacement de sortie pour vos requêtes, Data Wrangler utilise le bucket Amazon S3 par défaut dans la même AWS région que celle dans laquelle se trouve votre instance Studio Classic pour stocker les résultats des requêtes Athena. Il crée des tables temporaires dans cette base de données pour déplacer la sortie de la requête vers ce compartiment Amazon S3. Il supprime ces tables une fois les données importées, mais la base de données sagemaker_data_wrangler persiste. Pour en savoir plus, veuillez consulter la section Stockage des données importées.
Pour utiliser les groupes de travail Athena, configurez la politique IAM qui donne accès aux groupes de travail. Si vous utilisez un SageMaker AI-Execution-Role, nous vous recommandons d'ajouter la politique au rôle. Pour plus d'informations sur les politiques IAM pour les groupes de travail, consultez Politiques IAM pour l'accès aux groupes de travail. Pour obtenir des exemples de politiques de groupe de travail, consultez Exemples de politiques de groupe de travail.
Définition de la durée de conservation des données
Data Wrangler définit automatiquement une durée de conservation des données pour les résultats de la requête. Les résultats sont supprimés une fois cette durée écoulée. Par exemple, la durée de conservation par défaut est de cinq jours. Les résultats de la requête sont supprimés au bout de cinq jours. Cette configuration est conçue pour vous aider à nettoyer les données que vous n'utilisez plus. Le nettoyage de vos données empêche les utilisateurs non autorisés d'y accéder. Il permet également de contrôler les coûts de stockage de vos données sur Amazon S3.
Si vous ne définissez pas de durée de conservation, c'est la configuration du cycle de vie d'Amazon S3 qui détermine la durée de stockage des objets. La politique de conservation des données que vous avez spécifiée pour la configuration du cycle de vie supprime tous les résultats de requête antérieurs à la configuration du cycle de vie que vous avez spécifiée. Pour en savoir plus, consultez Définition d'une configuration de cycle de vie sur un compartiment.
Data Wrangler utilise des configurations de cycle de vie Amazon S3 pour gérer la conservation et l'expiration des données. Vous devez accorder à votre rôle d'exécution Amazon SageMaker Studio Classic IAM les autorisations nécessaires pour gérer les configurations du cycle de vie des compartiments. Procédez comme suit pour accorder des autorisations.
Pour accorder les autorisations de gestion de la configuration du cycle de vie, procédez comme suit.
-
Connectez-vous à la console IAM AWS Management Console et ouvrez-la à https://console.aws.amazon.com/iam/
l'adresse. -
Sélectionnez Roles (Rôles).
-
Dans la barre de recherche, spécifiez le rôle d'exécution Amazon SageMaker AI utilisé par Amazon SageMaker Studio Classic.
-
Choisissez le rôle.
-
Choisissez Add permissions (Ajouter des autorisations).
-
Choisissez Create inline policy (Créer une politique en ligne).
-
Pour Service, spécifiez S3 et choisissez-le.
-
Dans la section Lire, choisissez GetLifecycleConfiguration.
-
Dans la section Écrire, choisissez PutLifecycleConfiguration.
-
Pour Resources (Ressources), choisissez Specific (Spécifique).
-
Pour Actions, sélectionnez l'icône en forme de flèche en regard de Permissions management (Gestion des autorisations).
-
Sélectionnez PutResourcePolicy.
-
Pour Resources (Ressources), choisissez Specific (Spécifique).
-
Cochez la case en regard de Any in this account (N'importe quelle ressource dans ce compte).
-
Choisissez Review policy (Examiner une politique).
-
Pour Name (Nom), spécifiez un nom.
-
Sélectionnez Create policy (Créer la stratégie).
Importer des données depuis Amazon Redshift
Amazon Redshift est un service d’entrepôt des données entièrement géré dans le cloud. La première étape pour créer un entrepôt de données consiste à lancer un ensemble de nœuds, appelé cluster Amazon Redshift. Après avoir alloué votre cluster, vous pouvez charger votre jeu de données, puis effectuer des requêtes d'analyse de données.
Vous pouvez vous connecter à un ou plusieurs clusters Amazon Redshift et les interroger dans Data Wrangler. Pour utiliser cette option d'importation, vous devez créer au moins un cluster dans Amazon Redshift. Pour savoir comment procéder, veuillez consulter Démarrer avec Amazon Redshift.
Vous pouvez afficher les résultats de votre requête Amazon Redshift dans l'un des emplacements suivants :
-
Compartiment Amazon S3 par défaut
-
Emplacement de sortie Amazon S3 que vous spécifiez
Vous pouvez importer l'intégralité du jeu de données ou en échantillonner une partie. Pour Amazon Redshift, il fournit les options d'échantillonnage suivantes :
-
None (Aucun) : importez l'intégralité du jeu de données.
-
First K (K premières lignes) : échantillonnez les K premières lignes du jeu de données, où K est un entier que vous spécifiez.
-
Randomized (Aléatoire) : prélève un échantillon aléatoire d'une taille que vous spécifiez.
-
Stratified (Stratifié) : prélève un échantillon aléatoire stratifié. Un échantillon stratifié conserve le rapport des valeurs dans une colonne.
Le compartiment Amazon S3 par défaut se trouve dans la même AWS région que celle dans laquelle se trouve votre instance Studio Classic pour stocker les résultats des requêtes Amazon Redshift. Pour de plus amples informations, veuillez consulter Stockage des données importées.
Pour le compartiment Amazon S3 par défaut ou le compartiment que vous spécifiez, vous disposez des options de chiffrement suivantes :
-
Le chiffrement AWS côté service par défaut avec une clé gérée Amazon S3 (SSE-S3)
-
Une clé AWS Key Management Service (AWS KMS) que vous spécifiez
Une AWS KMS clé est une clé de chiffrement que vous créez et gérez. Pour plus d'informations sur les clés KMS, consultez AWS Key Management Service.
Vous pouvez spécifier une AWS KMS clé en utilisant l'ARN de la clé ou l'ARN de votre AWS compte.
Si vous utilisez la politique gérée par IAMAmazonSageMakerFullAccess, pour accorder à un rôle l'autorisation d'utiliser Data Wrangler dans Studio Classic, votre nom d'utilisateur de base de données doit comporter le préfixe. sagemaker_access
Découvrez comment ajouter un nouveau cluster à l'aide des procédures suivantes.
Note
Data Wrangler utilise l'API de données Amazon Redshift avec des informations d'identification temporaires. Pour en savoir plus sur cette API, consultez Utilisation de l'API de données Amazon Redshift dans le Guide de la gestion du cluster Amazon Redshift.
Pour vous connecter à un cluster Amazon Redshift
-
Connectez-vous à Amazon SageMaker AI Console
. -
Choisissez Studio.
-
Choisissez Launch app (Lancer l'application).
-
Dans la liste déroulante, sélectionnez Studio.
-
Choisissez l'icône d'accueil.
-
Choisissez Data (Données).
-
Choisissez Data Wrangler.
-
Choisissez Import data (Importer les données).
-
Sous Available (Disponible), sélectionnez Amazon Athena.
-
Choisissez Amazon Redshift.
-
Choisissez Temporary credentials (IAM) (Informations d'identification temporaires (IAM)) pour Type.
-
Saisissez un Connection Name (Nom de la connexion). Il s'agit d'un nom utilisé par Data Wrangler pour identifier cette connexion.
-
Saisissez le Cluster Identifier (Identifiant du cluster) pour spécifier à quel cluster vous souhaitez vous connecter. Remarque : saisissez uniquement l'identifiant de cluster et non le point de terminaison complet du cluster Amazon Redshift.
-
Saisissez le Database Name (Nom de base de données) de la base de données à laquelle vous souhaitez vous connecter.
-
Saisissez un Database User (Utilisateur de base de données) pour identifier l'utilisateur que vous souhaitez utiliser pour vous connecter à la base de données.
-
Pour UNLOAD IAM Role (Rôle IAM de DÉCHARGEMENT), saisissez l'ARN de rôle IAM du rôle que le cluster Amazon Redshift doit assumer pour déplacer et écrire des données dans Amazon S3. Pour plus d'informations sur ce rôle, consultez la section Autoriser Amazon Redshift à accéder à AWS d'autres services en votre nom dans le guide de gestion Amazon Redshift.
-
Sélectionnez Connect (Connexion).
-
(Facultatif) Pour Amazon S3 output location (Emplacement de sortie Amazon S3), spécifiez l'URI S3 pour stocker les résultats de la requête.
-
(Facultatif) Pour KMS key ID (ID de clé KMS), spécifiez l'ARN de la clé AWS KMS ou de l'alias. L'image suivante montre où vous pouvez trouver l'une ou l'autre clé dans la AWS Management Console.
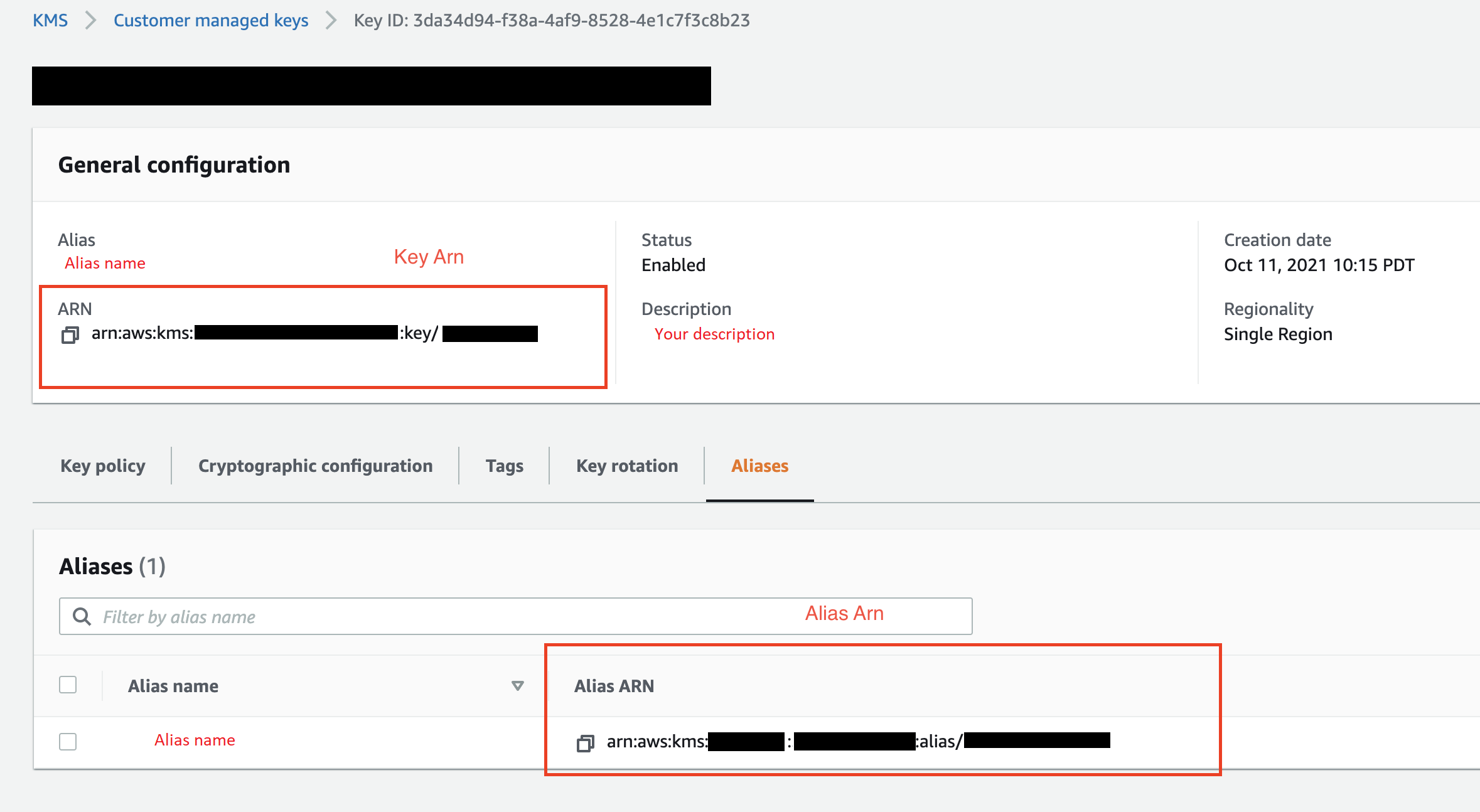
L'image suivante montre tous les champs de la procédure précédente.

Une fois votre connexion établie avec succès, elle apparaît en tant que source de données sous Data Import (Importation de données). Sélectionnez cette source de données pour interroger votre base de données et importer des données.
Pour interroger et importer des données à partir d'Amazon Redshift
-
Sélectionnez la connexion à partir de laquelle vous souhaitez effectuer une requête dans Data Source (Sources de données).
-
Sélectionnez un Scheme (Schéma). Pour en savoir plus sur les schémas Amazon Redshift, consultez la rubrique Schémas dans le Guide du développeur de la base de données Amazon Redshift.
-
(Facultatif) Sous Advanced configuration (Configuration avancée), spécifiez la méthode Sampling (Échantillonnage) que vous souhaitez utiliser.
-
Entrez votre requête dans l'éditeur de requête, puis choisissez Run (Exécuter) pour exécuter la requête. Après une requête réussie, vous pouvez prévisualiser votre résultat sous l'éditeur.
-
Sélectionnez Import dataset (Importer un jeu de données) pour importer le jeu de données interrogé.
-
Saisissez un Dataset name (Nom de jeu de données). Si vous ajoutez un Dataset name (Nom de jeu de données) qui contient des espaces, ces derniers sont remplacés par des traits de soulignement lorsque votre jeu de données est importé.
-
Choisissez Ajouter.
Pour modifier un jeu de données, procédez comme suit.
-
Accédez à votre flux Data Wrangler.
-
Cliquez sur le signe + à côté de Source - Sampled (Source - Échantillonnée).
-
Modifiez les données que vous importez.
-
Choisissez Apply (Appliquer)
Importer des données depuis Amazon EMR
Vous pouvez utiliser Amazon EMR comme source de données pour votre flux Amazon SageMaker Data Wrangler. Amazon EMR est une plateforme de cluster gérée que vous pouvez utiliser pour traiter et analyser de grandes quantités de données. Pour plus d'informations sur Amazon EMR, veuillez consulter Qu'est-ce qu'Amazon EMR ?. Pour importer un jeu de données à partir d'EMR, vous devez vous y connecter et l'interroger.
Important
Vous devez remplir les conditions suivantes pour vous connecter à un cluster Amazon EMR :
Prérequis
-
Configurations réseau
-
Vous disposez d'un Amazon VPC dans la région que vous utilisez pour lancer Amazon SageMaker Studio Classic et Amazon EMR.
-
Amazon EMR et Amazon SageMaker Studio Classic doivent tous deux être lancés dans des sous-réseaux privés. Ils peuvent se trouver dans le même sous-réseau ou dans des sous-réseaux différents.
-
Amazon SageMaker Studio Classic doit être en mode VPC uniquement.
Pour en savoir plus sur la création d'un VPC, veuillez consulter Créer un VPC.
Pour plus d'informations sur la création d'un VPC, voir Connecter les blocs-notes classiques de SageMaker Studio dans un VPC à des ressources externes.
-
Les clusters Amazon EMR que vous exécutez doivent se trouver dans le même VPC Amazon.
-
Les clusters Amazon EMR et Amazon VPC doivent se trouver dans le même compte. AWS
-
Vos clusters Amazon EMR exécutent Hive ou Presto.
-
Les clusters Hive doivent autoriser le trafic entrant en provenance des groupes de sécurité Studio Classic sur le port 10000.
-
Les clusters Presto doivent autoriser le trafic entrant en provenance des groupes de sécurité Studio Classic sur le port 8889.
Note
Le numéro de port est différent pour les clusters Amazon EMR utilisant des rôles IAM. Accédez à la fin de la section des conditions préalables pour plus d'informations.
-
-
-
SageMaker Studio classique
-
Amazon SageMaker Studio Classic doit exécuter Jupyter Lab version 3. Pour plus d'informations sur la mise à jour de la version de Jupyter Lab, veuillez consulter Afficher et mettre à jour la JupyterLab version d'une application depuis la console.
-
Amazon SageMaker Studio Classic possède un rôle IAM qui contrôle l'accès des utilisateurs. Le rôle IAM par défaut que vous utilisez pour exécuter Amazon SageMaker Studio Classic ne comporte aucune politique vous permettant d'accéder aux clusters Amazon EMR. Vous devez attacher la politique d'octroi d'autorisations au rôle IAM. Pour de plus amples informations, veuillez consulter Configurer la liste des clusters Amazon EMR.
-
La politique IAM suivante
secretsmanager:PutResourcePolicydoit également être liée au rôle IAM. -
Si vous utilisez un domaine Studio Classic que vous avez déjà créé, assurez-vous qu'il
AppNetworkAccessTypeest en mode VPC uniquement. Pour plus d'informations sur la mise à jour d'un domaine pour utiliser le mode VPC uniquement, veuillez consulter Arrêter et mettre à jour SageMaker Studio Classic.
-
-
Clusters Amazon EMR
-
Hive ou Presto doit être installé sur votre cluster.
-
Amazon EMR doit être à la version 5.5.0 ou ultérieure.
Note
Amazon EMR prend en charge la terminaison automatique. La terminaison automatique empêche le fonctionnement des clusters inactifs, ce qui permet de réaliser des économies. Les versions qui prennent en charge la terminaison automatique sont les suivantes :
-
Pour les versions 6.x, version 6.1.0 ou ultérieure.
-
Pour les versions 5.x, version 5.30.0 ou ultérieure.
-
-
-
Clusters Amazon EMR utilisant des rôles d'exécution IAM
-
Utilisez les pages suivantes pour configurer les rôles d'exécution IAM pour le cluster Amazon EMR. Vous devez activer le chiffrement en transit lorsque vous utilisez des rôles d'exécution :
-
Vous devez utiliser Lake Formation comme outil de gouvernance pour les données de vos bases de données. Vous devez également utiliser un filtrage de données externe pour le contrôle d'accès.
-
Pour plus d'informations sur Lake Formation, voir Qu'est-ce que c'est AWS Lake Formation ?
-
Pour plus d'informations sur l'intégration de Lake Formation dans Amazon EMR, consultez Intégration de services tiers avec Lake Formation.
-
-
Le cluster doit être d'une version 6.9.0 ou ultérieure.
-
Accès à AWS Secrets Manager. Pour plus d'informations sur Secrets Manager, consultez Qu'est-ce que AWS Secrets Manager ?
-
Les clusters Hive doivent autoriser le trafic entrant en provenance des groupes de sécurité Studio Classic sur le port 10000.
-
Un Amazon VPC est un réseau virtuel isolé logiquement des autres réseaux du cloud. AWS Amazon SageMaker Studio Classic et votre cluster Amazon EMR n'existent qu'au sein d'Amazon VPC.
Suivez la procédure suivante pour lancer Amazon SageMaker Studio Classic dans un Amazon VPC.
Pour lancer Studio Classic dans un VPC, procédez comme suit.
-
Accédez à la console SageMaker AI à l'adresse https://console.aws.amazon.com/sagemaker/
. -
Choisissez Launch SageMaker Studio Classic.
-
Choisissez Standard setup (Configuration standard).
-
Pour Rôle d'exécution par défaut, choisissez le rôle IAM pour configurer Studio Classic.
-
Choisissez le VPC sur lequel vous avez lancé les clusters Amazon EMR.
-
Dans Subnet (Sous-réseau), choisissez un sous-réseau privé.
-
Dans Groupe(s) de sécurité, spécifiez les groupes de sécurité que vous utilisez pour contrôler les échanges entre vos VPC.
-
Choisissez VPC Only (VPC uniquement).
-
(Facultatif) AWS utilise une clé de chiffrement par défaut. Vous pouvez spécifier une clé AWS Key Management Service pour chiffrer vos données.
-
Choisissez Suivant.
-
Sous Studio settings (Paramètres Studio), choisissez les configurations qui vous conviennent le mieux.
-
Choisissez Next pour ignorer les paramètres du SageMaker canevas.
-
Choisissez Next pour ignorer les RStudio paramètres.
Si vous n'avez pas de cluster Amazon EMR déjà prêt, procédez comme suit pour en créer un. Pour plus d'informations sur Amazon EMR, veuillez consulter Qu'est-ce qu'Amazon EMR ?.
Pour créer un cluster, procédez comme suit.
-
Accédez à AWS Management Console.
-
Dans la barre de recherche, spécifiez
Amazon EMR. -
Choisissez Créer un cluster.
-
Pour Cluster name (Nom du cluster), saisissez le nom de votre cluster.
-
Dans Release (Version), sélectionnez la version du cluster.
Note
Amazon EMR prend en charge la terminaison automatique pour les versions suivantes :
-
Pour les versions 6.x, version 6.1.0 ou ultérieure
-
Pour les versions 5.x, version 5.30.0 ou ultérieure
La terminaison automatique empêche le fonctionnement des clusters inactifs, ce qui permet de réaliser des économies.
-
-
(Facultatif) Pour Applications, choisissez Presto.
-
Choisissez l'application que vous exécutez sur le cluster.
-
Sous Networking (Mise en réseau), dans Hardware configuration (Configuration matérielle), spécifiez les paramètres de configuration matérielle.
Important
Pour la mise en réseau, choisissez le VPC qui exécute Amazon SageMaker Studio Classic et choisissez un sous-réseau privé.
-
Sous Security and access (Sécurité et accès), définissez les paramètres de sécurité.
-
Choisissez Créer.
Pour consulter un didacticiel sur la création d'un cluster Amazon EMR, veuillez consulter Démarrer avec Amazon EMR. Pour plus d'informations sur les bonnes pratiques de configuration d'un cluster, veuillez consulter Considérations et bonnes pratiques.
Note
Pour des raisons de sécurité optimales, Data Wrangler ne peut se connecter qu'à des VPCs sous-réseaux privés. Vous ne pouvez pas vous connecter au nœud principal sauf si vous l'utilisez AWS Systems Manager pour vos instances Amazon EMR. Pour plus d'informations, veuillez consulter Sécuriser l'accès aux clusters EMR à l'aide de AWS Systems Manager
Vous pouvez actuellement utiliser les méthodes suivantes pour accéder à un cluster Amazon EMR :
-
Pas d'authentification
-
Protocole LDAP (Lightweight Directory Access Protocol)
-
IAM (rôle d'exécution)
Le fait de ne pas utiliser l'authentification ou le protocole LDAP peut vous obliger à créer plusieurs clusters et profils d' EC2 instance Amazon. Si vous êtes administrateur, vous devrez peut-être fournir différents niveaux d'accès aux données aux groupes d'utilisateurs. Ces méthodes peuvent entraîner une surcharge administrative qui complique la gestion de vos utilisateurs.
Nous vous recommandons d'utiliser un rôle d'exécution IAM qui permet à plusieurs utilisateurs de se connecter au même cluster Amazon EMR. Un rôle d'exécution est un rôle IAM que vous pouvez attribuer à un utilisateur qui se connecte à un cluster Amazon EMR. Vous pouvez configurer le rôle IAM d'exécution pour qu'il dispose d'autorisations spécifiques à chaque groupe d'utilisateurs.
Utilisez les sections suivantes pour créer un cluster Presto ou Hive Amazon EMR avec LDAP activé.
Utilisez les sections suivantes pour utiliser l'authentification LDAP pour les clusters Amazon EMR que vous avez déjà créés.
Utilisez la procédure suivante pour importer des données à partir d'un cluster.
Pour importer des données à partir d'un cluster, procédez comme suit.
-
Ouvrez un flux Data Wrangler.
-
Choisissez Create Connection (Créer une connexion).
-
Choisissez Amazon EMR.
-
Effectuez l’une des actions suivantes :
-
(Facultatif) Pour Secrets ARN, spécifiez l'ARN (Amazon Resource Number) de la base de données au sein du cluster. Les secrets offrent une sécurité supplémentaire. Pour plus d'informations sur les secrets, voir Qu'est-ce que c'est AWS Secrets Manager ? Pour plus d'informations sur la création d'un secret pour votre cluster, veuillez consulter Création d'un AWS Secrets Manager secret pour votre cluster.
Important
Vous devez spécifier un secret si vous utilisez un rôle d'exécution IAM pour l'authentification.
-
Dans le tableau déroulant, choisissez un cluster.
-
-
Choisissez Suivant.
-
Pour Sélectionner un point de terminaison pour le
example-cluster-namecluster, choisissez un moteur de requête. -
(Facultatif) Sélectionnez Save connection (Enregistrer la connexion).
-
Choisissez Next, select login (Ensuite, sélectionner la connexion) et choisissez l'une des options suivantes :
-
No authentication (Pas d'authentification)
-
LDAP
-
IAM
-
-
Pour Se connecter au
example-cluster-namecluster, spécifiez le nom d'utilisateur et le mot de passe du cluster. -
Choisissez Se connecter.
-
Dans l'éditeur de requêtes, spécifiez une requête SQL.
-
Cliquez sur Exécuter.
-
Choisissez Importer.
Création d'un AWS Secrets Manager secret pour votre cluster
Si vous utilisez un rôle d'exécution IAM pour accéder à votre cluster Amazon EMR, vous devez stocker les informations d'identification que vous utilisez pour accéder à Amazon EMR en tant que secret Secrets Manager. Vous stockez toutes les informations d'identification que vous utilisez pour accéder au cluster dans le secret.
Vous devez conserver les informations suivantes dans le secret :
-
Point de terminaison JDBC :
jdbc:hive2:// -
Nom DNS : nom DNS de votre cluster Amazon EMR. Il s'agit soit du point de terminaison du nœud primaire, soit du nom d'hôte.
-
Port :
8446
Vous pouvez également enregistrer les informations supplémentaires suivantes dans le secret :
-
Rôle IAM : rôle IAM que vous utilisez pour accéder au cluster. Data Wrangler utilise votre rôle d'exécution SageMaker AI par défaut.
-
Chemin truststore : par défaut, Data Wrangler crée un chemin truststore pour vous. Vous pouvez également utiliser votre propre chemin truststore. Pour plus d'informations sur les chemins Truststore, consultez la section Chiffrement en transit en HiveServer 2.
-
Mot de passe truststore : par défaut, Data Wrangler crée un mot de passe truststore pour vous. Vous pouvez également utiliser votre propre chemin truststore. Pour plus d'informations sur les chemins Truststore, consultez la section Chiffrement en transit en HiveServer 2.
Utilisez la procédure ci-dessous pour stocker les informations d'identification dans un secret Secrets Manager.
Pour stocker vos informations d'identification en tant que secret, procédez comme suit.
-
Accédez à AWS Management Console.
-
Dans la barre de recherche, spécifiez Secrets Manager.
-
Sélectionnez AWS Secrets Manager.
-
Choisissez Store a new secret (Stocker un nouveau secret).
-
Pour Secret type (Type de secret), choisissez Other type of secret (Autre type de secret).
-
Sous Paires clé/valeur, sélectionnez Texte brut.
-
Pour les clusters exécutant Hive, vous pouvez utiliser le modèle suivant pour l'authentification IAM.
{"jdbcURL": "" "iam_auth": {"endpoint": "jdbc:hive2://", #required "dns": "ip-xx-x-xxx-xxx.ec2.internal", #required "port": "10000", #required "cluster_id": "j-xxxxxxxxx", #required "iam_role": "arn:aws:iam::xxxxxxxx:role/xxxxxxxxxxxx", #optional "truststore_path": "/etc/alternatives/jre/lib/security/cacerts", #optional "truststore_password": "changeit" #optional }}Note
Après avoir importé vos données, vous leur appliquez des transformations. Vous exportez ensuite les données que vous avez transformées vers un emplacement spécifique. Si vous utilisez un bloc-notes Jupyter pour exporter vos données transformées vers Amazon S3, vous devez utiliser le chemin truststore spécifié dans l'exemple précédent.
Un secret Secrets Manager enregistre l'URL JDBC du cluster Amazon EMR en tant que secret. L'utilisation d'un secret est plus sûre que la saisie directe de vos informations d'identification.
Utilisez la procédure suivante pour enregistrer l'URL JDBC en tant que secret.
Pour enregistrer l'URL JDBC en tant que secret, procédez comme suit.
-
Accédez à AWS Management Console.
-
Dans la barre de recherche, spécifiez Secrets Manager.
-
Sélectionnez AWS Secrets Manager.
-
Choisissez Store a new secret (Stocker un nouveau secret).
-
Pour Secret type (Type de secret), choisissez Other type of secret (Autre type de secret).
-
Pour les Key/value pairs (Paires clé/valeur), spécifiez
jdbcURLen tant que clé et une URL JDBC valide en tant que valeur.Le format d'une URL JDBC valide varie selon que vous utilisez l'authentification et que vous utilisez Hive ou Presto comme moteur de requête. La liste suivante indique les formats d'URL JBDC valides pour les différentes configurations possibles.
-
Hive, aucune authentification :
jdbc:hive2://emr-cluster-master-public-dns:10000/; -
Hive, authentification LDAP :
jdbc:hive2://emr-cluster-master-public-dns-name:10000/;AuthMech=3;UID=david;PWD=welcome123; -
Pour Hive avec SSL activé, le format d'URL JDBC dépend de l'utilisation ou non d'un fichier keystore Java pour la configuration TLS. Le fichier keystore Java permet de vérifier l'identité du nœud principal du cluster Amazon EMR. Pour utiliser un fichier keystore Java, générez-le sur un cluster EMR et chargez-le dans Data Wrangler. Pour générer un fichier, utilisez la commande suivante sur le cluster Amazon EMR,
keytool -genkey -alias hive -keyalg RSA -keysize 1024 -keystore hive.jks. Pour plus d'informations sur l'exécution de commandes sur un cluster Amazon EMR, veuillez consulter Sécuriser l'accès aux clusters EMR à l'aide de AWS Systems Manager. Pour charger un fichier, cliquez sur la flèche vers le haut dans le menu de navigation de gauche de l'interface utilisateur de Data Wrangler. Voici les formats d'URL JDBC valides pour Hive avec SSL activé :
-
Sans fichier keystore Java :
jdbc:hive2://emr-cluster-master-public-dns:10000/;AuthMech=3;UID=user-name;PWD=password;SSL=1;AllowSelfSignedCerts=1; -
Avec un fichier keystore Java -
jdbc:hive2://emr-cluster-master-public-dns:10000/;AuthMech=3;UID=user-name;PWD=password;SSL=1;SSLKeyStore=/home/sagemaker-user/data/Java-keystore-file-name;SSLKeyStorePwd=Java-keystore-file-passsword;
-
-
Presto, aucune authentification — jdbc:presto : //:8889/ ;
emr-cluster-master-public-dns -
Pour Presto avec l'authentification LDAP et SSL activés, le format d'URL JDBC dépend de l'utilisation ou non d'un fichier keystore Java pour la configuration TLS. Le fichier keystore Java permet de vérifier l'identité du nœud principal du cluster Amazon EMR. Pour utiliser un fichier keystore Java, générez-le sur un cluster EMR et chargez-le dans Data Wrangler. Pour charger un fichier, cliquez sur la flèche vers le haut dans le menu de navigation de gauche de l'interface utilisateur de Data Wrangler. Pour plus d'informations sur la création d'un fichier keystore Java pour Presto, veuillez consulter Fichier keystore Java pour TLS
. Pour plus d'informations sur l'exécution de commandes sur un cluster Amazon EMR, veuillez consulter Sécuriser l'accès aux clusters EMR à l'aide de AWS Systems Manager . -
Sans fichier keystore Java :
jdbc:presto://emr-cluster-master-public-dns:8889/;SSL=1;AuthenticationType=LDAP Authentication;UID=user-name;PWD=password;AllowSelfSignedServerCert=1;AllowHostNameCNMismatch=1; -
Avec un fichier keystore Java -
jdbc:presto://emr-cluster-master-public-dns:8889/;SSL=1;AuthenticationType=LDAP Authentication;SSLTrustStorePath=/home/sagemaker-user/data/Java-keystore-file-name;SSLTrustStorePwd=Java-keystore-file-passsword;UID=user-name;PWD=password;
-
-
Vous pouvez rencontrer des problèmes au cours du processus d'importation de données à partir d'un cluster Amazon EMR. Pour obtenir des informations sur la résolution de ces problèmes, veuillez consulter Résolution de problèmes avec Amazon EMR.
Importer des données depuis Databricks (JDBC)
Vous pouvez utiliser Databricks comme source de données pour votre flux Amazon SageMaker Data Wrangler. Pour importer un jeu de données à partir de Databricks, utilisez la fonctionnalité d'importation JDBC (Java Database Connectivity) pour accéder à votre base de données Databricks. Une fois que vous avez accès à la base de données, spécifiez une requête SQL pour obtenir les données et les importer.
Nous supposons que vous disposez d'un cluster Databricks en cours d'exécution et que vous y avez configuré votre pilote JDBC. Pour plus d'informations, consultez les pages suivantes de la documentation Databricks :
Data Wrangler enregistre votre URL JDBC dans. AWS Secrets Manager Vous devez autoriser votre rôle d'exécution Amazon SageMaker Studio Classic IAM à utiliser Secrets Manager. Procédez comme suit pour accorder des autorisations.
Pour accorder des autorisations à Secrets Manager, procédez comme suit.
-
Connectez-vous à la console IAM AWS Management Console et ouvrez-la à https://console.aws.amazon.com/iam/
l'adresse. -
Sélectionnez Roles (Rôles).
-
Dans la barre de recherche, spécifiez le rôle d'exécution Amazon SageMaker AI utilisé par Amazon SageMaker Studio Classic.
-
Choisissez le rôle.
-
Choisissez Add permissions (Ajouter des autorisations).
-
Choisissez Create inline policy (Créer une politique en ligne).
-
Pour Service, spécifiez Secrets Manager et choisissez-le.
-
Pour Actions, sélectionnez l'icône en forme de flèche en regard de Permissions management (Gestion des autorisations).
-
Sélectionnez PutResourcePolicy.
-
Pour Resources (Ressources), choisissez Specific (Spécifique).
-
Cochez la case en regard de Any in this account (N'importe quelle ressource dans ce compte).
-
Choisissez Review policy (Examiner une politique).
-
Pour Name (Nom), spécifiez un nom.
-
Sélectionnez Create policy (Créer la stratégie).
Vous pouvez utiliser des partitions pour importer vos données plus rapidement. Les partitions permettent à Data Wrangler de traiter les données en parallèle. Par défaut, Data Wrangler utilise 2 partitions. Dans la plupart des cas d'utilisation, 2 partitions offrent des vitesses de traitement des données quasi optimales.
Si vous choisissez de spécifier plus de 2 partitions, vous pouvez également spécifier une colonne pour partitionner les données. Le type des valeurs de la colonne doit être numérique ou date.
Nous vous recommandons d'utiliser des partitions uniquement si vous comprenez la structure des données et la manière dont elles sont traitées.
Vous pouvez importer l'intégralité du jeu de données ou en échantillonner une partie. Pour une base de données Databricks, il fournit les options d'échantillonnage suivantes :
-
None (Aucun) : importez l'intégralité du jeu de données.
-
First K (K premières lignes) : échantillonnez les K premières lignes du jeu de données, où K est un entier que vous spécifiez.
-
Randomized (Aléatoire) : prélève un échantillon aléatoire d'une taille que vous spécifiez.
-
Stratified (Stratifié) : prélève un échantillon aléatoire stratifié. Un échantillon stratifié conserve le rapport des valeurs dans une colonne.
Procédez comme suit pour importer vos données à partir d'une base de données Databricks.
Pour importer des données depuis Databricks, procédez comme suit.
-
Connectez-vous à Amazon SageMaker AI Console
. -
Choisissez Studio.
-
Choisissez Launch app (Lancer l'application).
-
Dans la liste déroulante, sélectionnez Studio.
-
Dans l'onglet Import data (Importation de données) de votre flux Data Wrangler, choisissez Databricks.
-
Spécifiez les champs suivants :
-
Dataset name (Nom du jeu de données) : nom que vous souhaitez utiliser pour le jeu de données de votre flux Data Wrangler.
-
Driver (Pilote) : com.simba.spark.jdbc.Driver.
-
JDBC URL (URL JDBC) – URL de la base de données Databricks. Le format de l'URL peut varier d'une instance Databricks à l'autre. Pour plus d'informations sur la recherche de l'URL et sur la spécification des paramètres qu'elle contient, consultez Paramètres de configuration et de connexion JDBC
. Voici un exemple de formatage d'une URL : jdbc:spark ://aws-sagemaker-datawrangler.cloud.databricks.com:443/default ; TransportMode=HTTP ; ssl=1 ; HttpPath= /3122619508517275/0909-200301-cut318 ; =3 ; UID= ; PWD=. sql/protocolv1/o AuthMech tokenpersonal-access-tokenNote
Vous pouvez spécifier un ARN secret contenant l'URL JDBC au lieu de spécifier l'URL JDBC elle-même. Le secret doit contenir une paire clé-valeur au format suivant :
jdbcURL:. Pour plus d'informations, consultez Qu'est-ce que Secrets Manager ?.JDBC-URL
-
-
Spécifiez une instruction SQL SELECT.
Note
Data Wrangler ne prend pas en charge les expressions de table communes (CTE) ou les tables temporaires au sein d'une requête.
-
Pour Sampling (Échantillonnage), choisissez une méthode d'échantillonnage.
-
Cliquez sur Exécuter.
-
(Facultatif) Pour PREVIEW (APERÇU), choisissez la roue dentée pour ouvrir Partition settings (Paramètres de partition).
-
Spécifiez le nombre de partitions. Vous pouvez partitionner par colonne si vous spécifiez le nombre de partitions :
-
Enter number of partitions (Saisissez le nombre de partitions) : spécifiez une valeur supérieure à 2.
-
(Facultatif) Partition by column (Partitionner par colonne) : renseignez les champs suivants. Vous ne pouvez partitionner par colonne que si vous avez spécifié une valeur dans le champ Enter number of partitions (Saisissez le nombre de partitions).
-
Select column (Sélectionner la colonne) – Sélectionnez la colonne que vous utilisez pour la partition de données. Le type de données de la colonne doit être numérique ou date.
-
Upper bound (Limite supérieure) – À partir des valeurs de la colonne que vous avez spécifiée, la limite supérieure est la valeur que vous utilisez dans la partition. La valeur que vous spécifiez ne modifie pas les données que vous importez. Elle n'affecte que la vitesse d'importation. Pour obtenir les meilleures performances, spécifiez une limite supérieure proche du maximum de la colonne.
-
Lower bound (Limite inférieure) – À partir des valeurs de la colonne que vous avez spécifiée, la limite inférieure est la valeur que vous utilisez dans la partition. La valeur que vous spécifiez ne modifie pas les données que vous importez. Elle n'affecte que la vitesse d'importation. Pour obtenir les meilleures performances, spécifiez une limite inférieure proche du minimum de la colonne.
-
-
-
-
Choisissez Import (Importer).
Importer des données depuis Salesforce Data Cloud
Vous pouvez utiliser Salesforce Data Cloud comme source de données dans Amazon SageMaker Data Wrangler pour préparer les données de votre Salesforce Data Cloud à des fins d'apprentissage automatique.
Avec Salesforce Data Cloud comme source de données dans Data Wrangler, vous pouvez vous connecter rapidement à vos données Salesforce sans écrire une seule ligne de code. Vous pouvez joindre vos données Salesforce à des données provenant de toute autre source de données Data Wrangler.
Une fois connecté au cloud de données, vous pouvez effectuer les opérations suivantes :
-
Visualiser vos données à l'aide de visualisations intégrées
-
Comprendre les données et identifier les erreurs potentielles et les valeurs extrêmes
-
Transformer les données grâce à plus de 300 transformations intégrées
-
Exporter les données que vous avez transformées
Configuration d'administrateur
Important
Avant de commencer, assurez-vous que vos utilisateurs exécutent Amazon SageMaker Studio Classic version 1.3.0 ou ultérieure. Pour plus d'informations sur la vérification de la version de Studio Classic et sa mise à jour, consultezPréparez les données ML avec Amazon SageMaker Data Wrangler.
Lorsque vous configurez l'accès à Salesforce Data Cloud, vous devez effectuer les tâches suivantes :
-
Obtenir l'URL de votre domaine Salesforce. Salesforce désigne également l'URL du domaine comme l'URL de votre organisation.
-
Obtenir des OAuth informations d'identification auprès de Salesforce.
-
Obtenir l'URL d'autorisation et l'URL du jeton pour votre domaine Salesforce.
-
Création d'un AWS Secrets Manager secret avec la OAuth configuration.
-
Créer une configuration du cycle de vie que Data Wrangler utilise pour lire les informations d'identification contenues dans le secret.
-
Permettre à Data Wrangler de lire le secret.
Après avoir effectué les tâches précédentes, vos utilisateurs peuvent se connecter au Salesforce Data Cloud à l'aide de OAuth.
Note
Vos utilisateurs peuvent rencontrer des problèmes une fois que vous avez tout configuré. Pour en savoir plus sur la résolution des problèmes, consultez Résolution des problèmes avec Salesforce.
Pour obtenir l'URL du domaine, procédez comme suit.
-
Accédez à la page de connexion de Salesforce.
-
Pour Recherche rapide, spécifiez Mon domaine.
-
Copiez la valeur de URL actuelle de Mon domaine dans un fichier texte.
-
Ajoutez
https://au début de l'URL.
Après avoir obtenu l'URL du domaine Salesforce, vous pouvez utiliser la procédure suivante pour obtenir les informations d'identification de connexion auprès de Salesforce et autoriser Data Wrangler à accéder à vos données Salesforce.
Pour obtenir les informations d'identification de connexion auprès de Salesforce et donner l'accès à Data Wrangler, procédez comme suit.
-
Accédez à l'URL de votre domaine Salesforce et connectez-vous à votre compte.
-
Choisissez l’icône d’engrenage.
-
Dans la barre de recherche qui apparaît, spécifiez Gestionnaire d'applications.
-
Sélectionnez Nouvelle application connectée.
-
Spécifiez les champs suivants :
-
Nom de l'application connectée : vous pouvez spécifier n'importe quel nom, mais nous vous recommandons de choisir un nom qui inclut Data Wrangler. Par exemple, vous pouvez spécifier Intégration de Salesforce Data Cloud Data Wrangler.
-
Nom de l'API : utilisez la valeur par défaut.
-
Adresse e-mail de contact : spécifiez votre adresse e-mail.
-
Sous le titre API (Activer OAuth les paramètres), cochez la case pour activer OAuth les paramètres.
-
Pour l'URL de rappel, spécifiez l'URL Amazon SageMaker Studio Classic. Pour obtenir l'URL de Studio Classic, accédez-y à partir du AWS Management Console et copiez-la.
-
-
Sous Étendue OAuth sélectionnée, déplacez ce qui suit de la liste Étendue disponible OAuth vers Étendue sélectionnée OAuth :
-
Gérez les données utilisateur via APIs (
api) -
Exécuter les demandes à tout moment (
refresh_token,offline_access) -
Exécuter des requêtes SQL ANSI sur les données Salesforce Data Cloud (
cdp_query_api) -
Gérer les données de profil de Salesforce Customer Data Platform (
cdp_profile_api)
-
-
Choisissez Enregistrer. Après avoir enregistré vos modifications, Salesforce ouvre une nouvelle page.
-
Choisissez Continue
-
Accédez à Clé et secret du consommateur.
-
Choisissez Gérer les informations du consommateur. Salesforce vous redirige vers une nouvelle page où vous devrez peut-être passer une authentification à deux facteurs.
-
Important
Copiez la clé du consommateur et le secret du consommateur dans un éditeur de texte. Vous avez besoin de ces informations pour connecter le cloud de données à Data Wrangler.
-
Revenez à Gérer les applications connectées.
-
Accédez à Nom de l'application connectée et au nom de votre application.
-
Choisissez Gérer.
-
Sélectionnez Modifier les politiques.
-
Modifiez Relaxation d'IP pour Assouplir les restrictions d'IP.
-
Choisissez Enregistrer.
-
Une fois que vous avez autorisé l'accès à votre Salesforce Data Cloud, vous devez fournir des autorisations à vos utilisateurs. Procédez comme suit pour leur accorder des autorisations.
Pour fournir des autorisations à vos utilisateurs, procédez comme suit.
-
Accédez à la page d'accueil de la configuration.
-
Dans la barre de navigation de gauche, recherchez Utilisateurs et choisissez l'élément de menu Utilisateurs.
-
Choisissez le lien hypertexte avec votre nom d'utilisateur.
-
Accédez à Attributions d'un jeu d'autorisations.
-
Choisissez Modifier les attributions.
-
Ajoutez les autorisations suivantes :
-
Administrateur de la plateforme de données client
-
Spécialiste en connaissance des données de la plateforme de données client
-
-
Choisissez Enregistrer.
Une fois que vous avez obtenu les informations relatives à votre domaine Salesforce, vous devez obtenir l'URL d'autorisation et l'URL du jeton pour le AWS Secrets Manager secret que vous créez.
Suivez la procédure ci-dessous pour obtenir l'URL d'autorisation et l'URL du jeton.
Pour obtenir l'URL d'autorisation et l'URL du jeton
-
Accédez à l'URL de votre domaine Salesforce.
-
Utilisez l'une des méthodes suivantes pour obtenir le URLs. Si vous utilisez une distribution Linux avec
curletjqinstallés, nous vous recommandons d'utiliser la méthode qui ne fonctionne que sous Linux.-
(Linux uniquement) Spécifiez la commande suivante dans votre terminal.
curlsalesforce-domain-URL/.well-known/openid-configuration | \ jq '. | { authorization_url: .authorization_endpoint, token_url: .token_endpoint }' | \ jq '. += { identity_provider: "SALESFORCE", client_id: "example-client-id", client_secret: "example-client-secret" }' -
-
Accédez à
example-org-URL/.well-known/openid-configuration -
Copiez
authorization_endpointettoken_endpointdans un éditeur de texte. -
Créez l'objet JSON suivant :
{ "identity_provider": "SALESFORCE", "authorization_url": "example-authorization-endpoint", "token_url": "example-token-endpoint", "client_id": "example-consumer-key", "client_secret": "example-consumer-secret" }
-
-
Après avoir créé l'objet OAuth de configuration, vous pouvez créer un AWS Secrets Manager secret qui le stocke. Utilisez la procédure suivante pour créer le secret.
Pour créer un secret, procédez comme suit.
-
Accédez à la console AWS Secrets Manager
. -
Choisissez Stocker un secret.
-
Sélectionnez Autre type de secret.
-
Sous Paires clé/valeur, sélectionnez Texte brut.
-
Remplacez le JSON vide par les paramètres de configuration suivants.
{ "identity_provider": "SALESFORCE", "authorization_url": "example-authorization-endpoint", "token_url": "example-token-endpoint", "client_id": "example-consumer-key", "client_secret": "example-consumer-secret" } -
Choisissez Suivant.
-
Dans Nom du secret, spécifiez le nom du secret.
-
Sous Balises, choisissez Ajouter.
-
Pour Clé, spécifiez sagemaker:partner. Pour Valeur, nous vous recommandons de spécifier une valeur qui pourrait être utile pour votre cas d'utilisation. Toutefois, vous pouvez spécifier ce que vous voulez.
Important
Vous devez créer la clé. Vous ne pouvez pas importer vos données depuis Salesforce sans la créer.
-
-
Choisissez Suivant.
-
Choisissez Stocker.
-
Choisissez le secret que vous avez créé.
-
Prenez en compte les champs suivants :
-
L'Amazon Resource Name (ARN) du secret
-
Le nom du secret
-
Après avoir créé le secret, vous devez ajouter des autorisations permettant à Data Wrangler de le lire. Procédez comme suit pour ajouter des autorisations.
Pour ajouter des autorisations de lecture pour Data Wrangler, procédez comme suit.
-
Accédez à la console Amazon SageMaker AI
. -
Choisissez des domaines.
-
Choisissez le domaine que vous utilisez pour accéder à Data Wrangler.
-
Choisissez votre Profil utilisateur.
-
Sous Détails, recherchez le Rôle d'exécution. Son ARN est au format suivant :
arn:aws:iam::111122223333:role/. Notez le rôle d'exécution de l' SageMaker IA. Dans l'ARN, c'est tout ce qui suitexample-rolerole/. -
Accédez à la Console IAM
. -
Dans la barre de recherche Search IAM, spécifiez le nom du rôle d'exécution SageMaker AI.
-
Choisissez le rôle.
-
Choisissez Add permissions (Ajouter des autorisations).
-
Choisissez Create inline policy (Créer une politique en ligne).
-
Choisissez l’onglet JSON.
-
Spécifiez la politique suivante dans l'éditeur.
-
Choisissez Review Policy (Examiner une stratégie).
-
Pour Name (Nom), spécifiez un nom.
-
Sélectionnez Create policy (Créer la stratégie).
Une fois que vous avez autorisé Data Wrangler à lire le secret, vous devez ajouter une configuration du cycle de vie utilisant votre secret Secrets Manager à votre profil utilisateur Amazon SageMaker Studio Classic.
Utilisez la procédure suivante pour créer une configuration de cycle de vie et l'ajouter au profil Studio Classic.
Pour créer une configuration de cycle de vie et l'ajouter au profil Studio Classic, procédez comme suit.
-
Accédez à la console Amazon SageMaker AI.
-
Choisissez des domaines.
-
Choisissez le domaine que vous utilisez pour accéder à Data Wrangler.
-
Choisissez votre Profil utilisateur.
-
Si vous voyez les applications suivantes, supprimez-les :
-
KernelGateway
-
JupyterKernel
Note
La suppression des applications met à jour Studio Classic. Les mises à jour peuvent prendre un certain temps.
-
-
Pendant que vous attendez que les mises à jour soient effectuées, choisissez Configurations de cycle de vie.
-
Assurez-vous que la page sur laquelle vous vous trouvez indique les configurations du cycle de vie de Studio Classic.
-
Choisissez Create configuration (Créer une configuration).
-
Assurez-vous qu'Application Jupyter Server a été sélectionnée.
-
Choisissez Suivant.
-
Pour Nom, spécifiez un nom pour la configuration.
-
Pour Scripts, spécifiez le script suivant :
#!/bin/bash set -eux cat > ~/.sfgenie_identity_provider_oauth_config <<EOL { "secret_arn": "secrets-arn-containing-salesforce-credentials" } EOL -
Sélectionnez Envoyer.
-
Dans la barre de navigation de gauche, sélectionnez les domaines.
-
Choisissez votre domaine.
-
Choisissez Environment (Environnement).
-
Sous Configurations du cycle de vie pour les applications personnelles de Studio Classic, sélectionnez Attacher.
-
Sélectionnez Configuration existante.
-
Sous Configurations du cycle de vie de Studio Classic, sélectionnez la configuration du cycle de vie que vous avez créée.
-
Choisissez Attacher au domaine.
-
Cochez la case à côté de la configuration du cycle de vie que vous avez attachée.
-
Sélectionnez Définir comme valeur par défaut.
Vous pouvez rencontrer des problèmes lors de la configuration de votre cycle de vie. Pour en savoir plus sur leur débogage, consultez Débogage des configurations de cycle de vie.
Guide des scientifiques des données
Utilisez ce qui suit pour connecter Salesforce Data Cloud et accéder à vos données dans Data Wrangler.
Important
Votre administrateur doit utiliser les informations des sections précédentes pour configurer Salesforce Data Cloud. Si vous rencontrez des problèmes, contactez-les pour obtenir de l'aide.
Pour ouvrir Studio Classic et vérifier sa version, consultez la procédure suivante.
-
Suivez les étapes ci-dessous Prérequis pour accéder à Data Wrangler via Amazon SageMaker Studio Classic.
-
À côté de l'utilisateur que vous souhaitez utiliser pour lancer Studio Classic, sélectionnez Lancer l'application.
-
Choisissez Studio.
Pour créer un jeu de données dans Data Wrangler à partir des données de Salesforce Data Cloud
-
Connectez-vous à Amazon SageMaker AI Console
. -
Choisissez Studio.
-
Choisissez Launch app (Lancer l'application).
-
Dans la liste déroulante, sélectionnez Studio.
-
Choisissez l'icône d'accueil.
-
Choisissez Data (Données).
-
Choisissez Data Wrangler.
-
Choisissez Import data (Importer les données).
-
Sous Disponible, choisissez Salesforce Data Cloud.
-
Dans Nom de la connexion, spécifiez le nom de votre connexion à Salesforce Data Cloud.
-
Pour URL de l'org, spécifiez l'URL de l'organisation dans votre compte Salesforce. Vous pouvez obtenir l'URL auprès de vos administrateurs.
-
Choisissez Se connecter.
-
Spécifiez vos informations d'identification pour vous connecter à Salesforce.
Vous pouvez commencer à créer un jeu de données à partir des données de Salesforce Data Cloud une fois que vous vous y êtes connecté.
Après avoir sélectionné une table, vous pouvez écrire des requêtes et les exécuter. La sortie de votre requête s'affichera sous Résultats de la requête.
Une fois que vous avez réglé la sortie de votre requête, vous pouvez l'importer dans un flux Data Wrangler pour effectuer des transformations de données.
Après avoir créé un jeu de données, accédez à l'écran Flux de données pour commencer à transformer vos données.
Importer des données depuis Snowflake
Vous pouvez utiliser Snowflake comme source de données dans Data Wrangler pour préparer SageMaker les données dans Snowflake à des fins d'apprentissage automatique.
Avec Snowflake comme source de données dans Data Wrangler, vous pouvez vous connecter rapidement à Snowflake sans écrire une seule ligne de code. Vous pouvez joindre vos données dans Snowflake à des données provenant de toute autre source de données Data Wrangler.
Une fois connecté, vous pouvez interroger de manière interactive les données stockées dans Snowflake, transformer les données avec plus de 300 transformations de données préconfigurées, comprendre les données et identifier les erreurs potentielles et les valeurs extrêmes grâce à un ensemble de modèles de visualisation préconfigurés robustes, identifier rapidement les incohérences dans votre flux de préparation des données, et diagnostiquer les problèmes avant que les modèles soient déployés en production. Enfin, vous pouvez exporter votre flux de travail de préparation des données vers Amazon S3 pour l'utiliser avec d'autres fonctionnalités d' SageMaker intelligence artificielle telles qu'Amazon SageMaker Autopilot, Amazon SageMaker Feature Store et Amazon Pipelines. SageMaker
Vous pouvez chiffrer le résultat de vos requêtes à l'aide d'une AWS Key Management Service clé que vous avez créée. Pour plus d'informations sur AWS KMS, voir AWS Key Management Service.
Guide de l'administrateur
Important
Pour en savoir plus sur le contrôle d'accès détaillé et les bonnes pratiques, veuillez consulter la rubrique Contrôle d'accès de sécurité
Cette section est destinée aux administrateurs Snowflake qui configurent l'accès à Snowflake depuis Data Wrangler. SageMaker
Important
Vous êtes responsable de la gestion et de la surveillance du contrôle d'accès dans Snowflake. Data Wrangler n'ajoute pas de couche de contrôle d'accès par rapport à Snowflake.
Le contrôle d'accès inclut les éléments suivants :
-
Les données auxquelles un utilisateur accède
-
(Facultatif) L'intégration du stockage qui permet à Snowflake d'écrire les résultats des requêtes dans un compartiment Amazon S3
-
Les requêtes qu'un utilisateur peut exécuter
(Facultatif) Configurer les autorisations d'importation de données Snowflake
Par défaut, Data Wrangler interroge les données dans Snowflake sans en créer de copie dans un emplacement Amazon S3. Utilisez les informations suivantes si vous configurez une intégration de stockage avec Snowflake. Vos utilisateurs peuvent utiliser une intégration de stockage pour stocker les résultats de leurs requêtes dans un emplacement Amazon S3.
Vos utilisateurs peuvent avoir différents niveaux d'accès aux données sensibles. Pour une sécurité optimale des données, fournissez à chaque utilisateur sa propre intégration de stockage. Chaque intégration de stockage doit avoir sa propre politique de gouvernance des données.
Cette fonction n'est actuellement pas disponible dans les régions d'adhésion.
Snowflake a besoin des autorisations suivantes sur un compartiment et un répertoire S3 pour pouvoir accéder aux fichiers du répertoire :
-
s3:GetObject -
s3:GetObjectVersion -
s3:ListBucket -
s3:ListObjects -
s3:GetBucketLocation
Créer une politique IAM
Vous devez créer une politique IAM pour configurer les autorisations d'accès permettant à Snowflake de charger et de décharger des données depuis un compartiment Amazon S3.
Le document de politique JSON que vous utilisez pour créer la politique est le suivant :
# Example policy for S3 write access # This needs to be updated { "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Action": [ "s3:PutObject", "s3:GetObject", "s3:GetObjectVersion", "s3:DeleteObject", "s3:DeleteObjectVersion" ], "Resource": "arn:aws:s3:::bucket/prefix/*" }, { "Effect": "Allow", "Action": [ "s3:ListBucket" ], "Resource": "arn:aws:s3:::bucket/", "Condition": { "StringLike": { "s3:prefix": ["prefix/*"] } } } ] }
Pour obtenir des informations et des procédures relatives à la création de politiques à l'aide de documents de politique, consultez Création de politiques IAM.
Pour une documentation qui fournit une vue d'ensemble de l'utilisation des autorisations IAM avec Snowflake, consultez les ressources suivantes :
Pour accorder à l'intégration de stockage l'autorisation d'utiliser le rôle Snowflake du scientifique des données, vous devez exécuter GRANT USAGE ON INTEGRATION
integration_name TO snowflake_role;.
-
integration_nameest le nom de votre intégration de stockage. -
snowflake_roleest le nom du rôle Snowflakepar défaut donné au scientifique des données.
Configuration de Snowflake Access OAuth
Au lieu de demander à vos utilisateurs d'entrer directement leurs informations d'identification dans Data Wrangler, vous pouvez leur demander d'utiliser un fournisseur d'identité pour accéder à Snowflake. Vous trouverez ci-dessous des liens vers la documentation Snowflake qui répertorient les fournisseurs d'identité pris en charge par Data Wrangler.
Utilisez la documentation des liens précédents pour configurer l'accès à votre fournisseur d'identité. Les informations et les procédures dans cette section vous aident à comprendre comment utiliser correctement la documentation pour accéder à Snowflake dans Data Wrangler.
Votre fournisseur d'identité doit reconnaître Data Wrangler en tant qu'application. Pour enregistrer Data Wrangler comme application dans le fournisseur d'identité, procédez comme suit :
-
Sélectionnez la configuration qui lance le processus d'enregistrement de Data Wrangler en tant qu'application.
-
Fournissez aux utilisateurs du fournisseur d'identité l'accès à Data Wrangler.
-
Activez l'authentification OAuth du client en stockant les informations d'identification du client sous forme de AWS Secrets Manager secret.
-
Spécifiez une URL de redirection au format suivant : https ://
domain-ID.studio.Région AWS.sagemaker. aws/jupyter/default/labImportant
Vous spécifiez l'ID de domaine Amazon SageMaker AI Région AWS que vous utilisez pour exécuter Data Wrangler.
Important
Vous devez enregistrer une URL pour chaque domaine Amazon SageMaker AI et pour chaque domaine Région AWS où vous exécutez Data Wrangler. Les utilisateurs d'un domaine pour Région AWS lesquels aucune redirection n'est URLs configurée ne pourront pas s'authentifier auprès du fournisseur d'identité pour accéder à la connexion Snowflake.
-
Assurez-vous que le code d'autorisation et les types d'octroi de jetons d'actualisation sont autorisés pour l'application Data Wrangler.
Au sein de votre fournisseur d'identité, vous devez configurer un serveur qui envoie OAuth des jetons à Data Wrangler au niveau de l'utilisateur. Le serveur envoie les jetons avec Snowflake comme public.
Snowflake utilise le concept de rôles distincts des rôles utilisés par les rôles IAM. AWS Vous devez configurer le fournisseur d'identité pour qu'il utilise n'importe quel rôle afin d'utiliser le rôle par défaut associé au compte Snowflake. Par exemple, si un utilisateur a le rôle systems administrator par défaut dans son profil Snowflake, la connexion entre Data Wrangler et Snowflake utilise systems administrator comme rôle.
Suivez la procédure ci-dessous pour configurer le serveur.
Pour configurer le serveur, procédez comme suit. Vous travaillez dans Snowflake pour toutes les étapes sauf la dernière.
-
Commencez à configurer le serveur ou l'API.
-
Configurez le serveur d'autorisation pour utiliser le code d'autorisation et actualiser les types d'octroi de jetons.
-
Spécifiez la durée de vie du jeton d'accès.
-
Définissez le délai d'inactivité du jeton d'actualisation. Le délai d'inactivité est la durée au cours de laquelle le jeton d'actualisation expire s'il n'est pas utilisé.
Note
Si vous planifiez des tâches dans Data Wrangler, nous recommandons que le délai d'inactivité soit supérieur à la fréquence de la tâche de traitement. Dans le cas contraire, certaines tâches de traitement risquent d'échouer car le jeton d'actualisation a expiré avant qu'elles n'aient pu être exécutées. Lorsque le jeton d'actualisation expire, l'utilisateur doit s'authentifier à nouveau en accédant à la connexion qu'il a établie avec Snowflake via Data Wrangler.
-
Spécifiez
session:role-anycomme nouvelle portée.Note
Pour Azure AD, copiez l'identifiant unique de la portée. Data Wrangler vous demande de lui fournir l'identifiant.
-
Important
Dans l'intégration OAuth de sécurité externe pour Snowflake, activez.
external_oauth_any_role_mode
Important
Data Wrangler ne prend pas en charge la rotation des jetons d'actualisation. L'utilisation de jetons d'actualisation en rotation peut entraîner des échecs d'accès ou la nécessité pour les utilisateurs de se connecter fréquemment.
Important
Si le jeton d'actualisation expire, vos utilisateurs doivent s'authentifier à nouveau en accédant à la connexion qu'ils ont établie avec Snowflake via Data Wrangler.
Après avoir configuré le OAuth fournisseur, vous fournissez à Data Wrangler les informations dont il a besoin pour se connecter au fournisseur. Vous pouvez utiliser la documentation de votre fournisseur d'identité pour obtenir des valeurs pour les champs suivants :
-
URL du jeton : URL du jeton que le fournisseur d'identité envoie à Data Wrangler.
-
URL d'autorisation : URL du serveur d'autorisation du fournisseur d'identité.
-
ID client : ID du fournisseur d'identité.
-
Secret du client : secret que seul le serveur d'autorisation ou l'API reconnaît.
-
(Azure AD uniquement) Les informations d'identification du OAuth scope que vous avez copiées.
Vous stockez les champs et les valeurs dans un AWS Secrets Manager secret et vous les ajoutez à la configuration du cycle de vie Amazon SageMaker Studio Classic que vous utilisez pour Data Wrangler. Une configuration du cycle de vie est un script shell. Utilisez-la pour rendre l'Amazon Resource Name (ARN) du secret accessible à Data Wrangler. Pour plus d'informations sur la création de secrets, voir Déplacer des secrets codés en dur vers AWS Secrets Manager. Pour plus d'informations sur l'utilisation des configurations de cycle de vie dans Studio Classic, consultezUtilisez les configurations du cycle de vie pour personnaliser Studio Classic.
Important
Avant de créer un secret Secrets Manager, assurez-vous que le rôle d'exécution SageMaker AI que vous utilisez pour Amazon SageMaker Studio Classic est autorisé à créer et à mettre à jour des secrets dans Secrets Manager. Pour plus d'informations sur l'ajout d'autorisations, consultez Exemple : Autorisation de créer des secrets.
Pour Okta et Ping Federate, le secret doit avoir le format suivant :
{ "token_url":"https://identityprovider.com/oauth2/example-portion-of-URL-path/v2/token", "client_id":"example-client-id", "client_secret":"example-client-secret", "identity_provider":"OKTA"|"PING_FEDERATE", "authorization_url":"https://identityprovider.com/oauth2/example-portion-of-URL-path/v2/authorize" }
Pour Azure AD, le format du secret est le suivant :
{ "token_url":"https://identityprovider.com/oauth2/example-portion-of-URL-path/v2/token", "client_id":"example-client-id", "client_secret":"example-client-secret", "identity_provider":"AZURE_AD", "authorization_url":"https://identityprovider.com/oauth2/example-portion-of-URL-path/v2/authorize", "datasource_oauth_scope":"api://appuri/session:role-any)" }
Vous devez disposer d'une configuration du cycle de vie qui utilise le secret Secrets Manager que vous avez créé. Vous pouvez soit créer la configuration du cycle de vie, soit en modifier une qui a déjà été créée. La configuration doit utiliser le script suivant.
#!/bin/bash set -eux ## Script Body cat > ~/.snowflake_identity_provider_oauth_config <<EOL { "secret_arn": "example-secret-arn" } EOL
Pour en savoir plus sur les configurations du cycle de vie, consultez Création et association d'une configuration de cycle de vie. Au cours du processus de configuration, procédez comme suit :
-
Définissez le type d'application de la configuration sur
Jupyter Server. -
Associez la configuration au domaine Amazon SageMaker AI qui contient vos utilisateurs.
-
Exécutez la configuration par défaut. Il doit s'exécuter chaque fois qu'un utilisateur se connecte à Studio Classic. Dans le cas contraire, les informations d'identification enregistrées dans la configuration ne seront pas accessibles à vos utilisateurs lorsqu'ils utiliseront Data Wrangler.
-
La configuration du cycle de vie crée un fichier portant le nom
snowflake_identity_provider_oauth_configdans le dossier de base de l'utilisateur. Le fichier contient le secret Secrets Manager. Assurez-vous qu'il se trouve dans le dossier de base de l'utilisateur chaque fois que l'instance du serveur Jupyter est initialisée.
Connectivité privée entre Data Wrangler et Snowflake via AWS PrivateLink
Cette section explique comment AWS PrivateLink établir une connexion privée entre Data Wrangler et Snowflake. Les étapes sont expliquées dans les sections suivantes.
Création d'un VPC
Si vous n'avez pas de VPC configuré, suivez les instructions Create a new VPC (Créer un VPC) pour en créer un.
Une fois que vous avez choisi le VPC que vous souhaitez utiliser pour établir une connexion privée, fournissez les informations d'identification suivantes à votre administrateur Snowflake pour activer AWS PrivateLink :
-
ID du VPC
-
AWS ID de compte
-
URL de votre compte correspondant que vous utilisez pour accéder à Snowflake.
Important
Comme indiqué dans la documentation de Snowflake, l'activation de votre compte Snowflake peut prendre jusqu'à deux jours ouvrés.
Configurer l'intégration Snowflake AWS PrivateLink
Une fois AWS PrivateLink activé, récupérez la AWS PrivateLink configuration de votre région en exécutant la commande suivante dans une feuille de calcul Snowflake. Connectez-vous à votre console Snowflake et, sous Worksheets (Feuilles de calcul), saisissez les éléments suivants : select
SYSTEM$GET_PRIVATELINK_CONFIG();
-
Récupérez les valeurs pour les éléments suivants :
privatelink-account-name,privatelink_ocsp-url,privatelink-account-urletprivatelink_ocsp-urlde l'objet JSON résultant. Des exemples de chaque valeur sont repris dans l'extrait suivant. Conservez-les en vue d'une utilisation ultérieure.privatelink-account-name: xxxxxxxx.region.privatelink privatelink-vpce-id: com.amazonaws.vpce.region.vpce-svc-xxxxxxxxxxxxxxxxx privatelink-account-url: xxxxxxxx.region.privatelink.snowflakecomputing.com privatelink_ocsp-url: ocsp.xxxxxxxx.region.privatelink.snowflakecomputing.com -
Accédez à votre AWS console et accédez au menu VPC.
-
Dans le volet latéral gauche, cliquez sur le lien Endpoints (Points de terminaison) pour accéder à la configuration VPC Endpoints (Points de terminaison d'un VPC).
Une fois là, sélectionner Create Endpoint (Créer un point de terminaison).
-
Sélectionnez la case d'option pour Find service by name (Rechercher un service par nom), comme illustré dans la capture d'écran suivante.
-
Dans le champ Service Name (Nom du service), collez la valeur pour
privatelink-vpce-idque vous avez récupérée à l'étape précédente et sélectionnez Verify (Vérifier).Si la connexion est établie, une alerte verte indiquant Service name found (Nom du service trouvé) s'affiche sur votre écran et les options VPCet Subnet (Sous-réseau) sont développées automatiquement, comme illustré dans la capture d'écran suivante. Selon la région ciblée, l'écran résultant peut afficher un autre nom de région AWS .

-
Sélectionnez le même ID de VPC que celui que vous avez envoyé à Snowflake depuis la liste déroulante VPC.
-
Si vous n'avez pas encore créé de sous-réseau, suivez l'ensemble d'instructions suivant lié à la création d'un sous-réseau.
-
Sélectionnez Subnets (Sous-réseaux) depuis la liste déroulante VPC. Sélectionnez ensuite Create subnet (Créer un sous-réseau) et suivez les invites pour créer un sous-ensemble dans votre VPC. Assurez-vous de sélectionner l'ID du VPC que vous avez envoyé à Snowflake.
-
Sous Security Group Configuration (Configuration du groupe de sécurité), sélectionnez Create New Security Group (Créer un nouveau groupe de sécurité) pour ouvrir l'écran par défaut Security Group (Groupe de sécurité) dans un nouvel onglet. Dans ce nouvel onglet, sélectionnez Create Security Group (Créer un groupe de sécurité).
-
Donnez un nom au nouveau groupe de sécurité (comme
datawrangler-doc-snowflake-privatelink-connection) et une description. Assurez-vous de sélectionner l'ID de VPC que vous avez utilisé lors des étapes précédentes. -
Ajoutez deux règles pour autoriser le trafic depuis votre VPC vers ce point de terminaison de VPC.
Accédez à votre VPC sous Votre VPCs dans un onglet séparé, et récupérez le bloc CIDR pour votre VPC. Puis, sélectionnez Add Rule (Ajouter une règle) dans la section Inbound Rules (Règles entrantes). Sélectionnez
HTTPSpour le type, laissez la Source sur Custom (Personnalisé) dans la forme, et collez la valeur extraite de l'appeldescribe-vpcsprécédent (comme10.0.0.0/16). -
Sélectionnez Create Security Group (Créer un groupe de sécurité). Récupérez le Security Group ID (ID du groupe de sécurité) du groupe de sécurité que vous venez de créer (comme
sg-xxxxxxxxxxxxxxxxx). -
Dans l'écran de configuration VPC Endpoint (Point de terminaison de VPC), supprimez le groupe de sécurité par défaut. Collez l'ID du groupe de sécurité dans le champ de recherche et cochez la case.

-
Sélectionnez Create Endpoint (Créer un point de terminaison).
-
Si la création du point de terminaison est réussie, vous voyez apparaître une page contenant un lien vers la configuration de votre point de terminaison de VPC, spécifié par l'ID du VPC. Cliquez sur le lien pour afficher la configuration dans son intégralité.

Récupérez l'enregistrement le plus haut dans la liste des noms DNS. Il peut être différencié des autres noms DNS, car il inclut uniquement le nom de la région (comme
us-west-2), et aucune lettre pour la zone de disponibilité (commeus-west-2a). Conservez-le en vue d'une utilisation ultérieure.
Configurer le DNS pour les points de terminaison Snowflake dans votre VPC
Cette section explique comment configurer le DNS pour les points de terminaison Snowflake dans votre VPC. Cela permet à votre VPC de résoudre les requêtes vers le point de terminaison Snowflake AWS PrivateLink .
-
Accédez au menu Route 53
dans votre AWS console. -
Sélectionnez l'option Hosted Zones (Zones hébergées) (si nécessaire, développez le menu de gauche pour trouver cette option).
-
Choisissez Create Hosted Zone (Créer une zone hébergée).
-
Dans le champ Domain name (Nom de domaine), référencez la valeur qui avait été stockée pour
privatelink-account-urldans les étapes précédentes. Dans ce champ, votre ID de compte Snowflake est supprimé du nom du DNS et utilise uniquement la valeur commençant par l'identificateur de région. Un Resource Record Set (Jeu d'enregistrements de ressources) est également créé ultérieurement pour le sous-domaine, commeregion.privatelink.snowflakecomputing.com. -
Sélectionnez la case d'option pour Private Hosted Zone (Zone hébergée privée) dans la section Type. Votre code de région peut ne pas être
us-west-2. Faites référence au nom DNS qui vous a été renvoyé par Snowflake.
-
Dans la section VPCs à associer à la zone hébergée, sélectionnez la région dans laquelle se trouve votre VPC et l'ID de VPC utilisé lors des étapes précédentes.

-
Choisissez Create Hosted Zone (Créer une zone hébergée).
-
-
Ensuite, créez deux enregistrements, un pour
privatelink-account-urlet un pourprivatelink_ocsp-url.-
Dans le menu Hosted Zone (Zone hébergée), choisissez Create Record Set (Créer un jeu d'enregistrements).
-
Sous Record name (Nom de l'enregistrement), saisissez votre ID de compte Snowflake uniquement (les 8 premiers caractères dans
privatelink-account-url). -
Sous Record type (Type d'enregistrement), sélectionnez CNAME.
-
Sous Value (Valeur), saisissez le nom DNS du point de terminaison de VPC régional que vous avez récupéré à la dernière étape de la section Configurer l'intégration Snowflake AWS PrivateLink .

-
Choisissez Create records (Créer des registres).
-
Répétez les étapes précédentes pour l'enregistrement OCSP que nous avons noté comme
privatelink-ocsp-url, en commençant parocspjusqu'à l'ID Snowflake à 8 caractères pour le nom de l'enregistrement (commeocsp.xxxxxxxx).
-
-
Configurer le point de terminaison entrant du résolveur Route 53 pour votre VPC
Cette section explique comment configurer les points de terminaison entrants des résolveurs Route 53 pour votre VPC.
-
Accédez au menu Route 53
dans votre AWS console. -
Dans le volet de gauche de la section Security (Sécurité), sélectionnez l'option Security Groups (Groupes de sécurité).
-
-
Sélectionnez Create Security Group (Créer un groupe de sécurité).
-
Fournissez un nom pour votre groupe de sécurité (comme
datawranger-doc-route53-resolver-sg) et une description. -
Sélectionnez l'ID de VPC utilisé lors des étapes précédentes.
-
Créez des règles qui autorisent le DNS sur UDP et TCP à partir du bloc d'adresse CIDR VPC.

-
Sélectionnez Create Security Group (Créer un groupe de sécurité). Notez le Security Group ID (ID du groupe de sécurité), car il ajoute une règle pour autoriser le trafic vers le groupe de sécurité de point de terminaison de VPC.
-
-
Accédez au menu Route 53
dans votre AWS console. -
Dans la section Resolver (Résolveur), sélectionnez l'option Inbound Endpoint (Point de terminaison entrant).
-
-
Choisissez Create inbound endpoint (Créer un point de terminaison entrant).
-
Donnez un nom au point de terminaison.
-
Depuis la liste déroulante VPC in the Region (VPC dans la région), sélectionnez l'ID de VPC que vous avez utilisé dans toutes les étapes précédentes.
-
Dans la liste déroulante Security group for this endpoint (Groupe de sécurité pour ce point de terminaison), sélectionnez l'ID du groupe de sécurité de l'étape 2 de cette section.
-
Dans la section IP Address (Adresse IP), sélectionnez une zone de disponibilité, sélectionnez un sous-réseau, et laissez la case d'option pour Use an IP address that is selected automatically (Utiliser une adresse IP sélectionnée automatiquement) sélectionnée pour chaque adresse IP.
-
Sélectionnez Envoyer.
-
-
Sélectionnez le Inbound endpoint (Point de terminaison entrant) après sa création.
-
Une fois le point de terminaison entrant créé, notez les deux adresses IP des résolveurs.

SageMaker Points de terminaison VPC AI
Cette section explique comment créer des points de terminaison VPC pour les applications suivantes : Amazon SageMaker Studio Classic, SageMaker Notebooks, l' SageMaker API, SageMaker Runtime Runtime et Amazon SageMaker Feature Store Runtime.
Créer un groupe de sécurité qui est appliqué à tous les points de terminaison.
-
Accédez au EC2 menu
de la AWS console. -
Sélectionnez l'option Security groups (Groupes de sécurité) dans la section Network & Security (Réseau et sécurité).
-
Sélectionnez Create security group (Créer un groupe de sécurité).
-
Fournissez un nom (comme
datawrangler-doc-sagemaker-vpce-sg) et une description au groupe de sécurité. Une règle est ajoutée ultérieurement pour autoriser le trafic HTTPS depuis SageMaker AI vers ce groupe.
Création des points de terminaison
-
Accédez au menu VPC
de la AWS console. -
Sélectionnez l'option Endpoints (Points de terminaison).
-
Choisissez Créer un point de terminaison.
-
Recherchez le service en saisissant son nom dans le champ Search (Recherche).
-
Dans la liste déroulante VPC, sélectionnez le VPC dans lequel votre connexion Snowflake existe. AWS PrivateLink
-
Dans la section Sous-réseaux, sélectionnez les sous-réseaux qui ont accès à la connexion PrivateLink Snowflake.
-
Laissez la case Enable DNS Name (Activer le nom DNS) sélectionnée.
-
Dans la section Security Groups (Groupes de sécurité), sélectionnez le groupe de sécurité créé dans la section précédente.
-
Choisissez Créer un point de terminaison.
Configuration de Studio Classic et de Data Wrangler
Cette section explique comment configurer Studio Classic et Data Wrangler.
-
Configurez le groupe de sécurité.
-
Accédez au EC2 menu Amazon dans la AWS console.
-
Sélectionnez l'option Security Groups (Groupes de sécurité) dans la section Network & Security (Réseau et sécurité).
-
Sélectionnez Create Security Group (Créer un groupe de sécurité).
-
Fournissez un nom (comme
datawrangler-doc-sagemaker-studio) et une description à votre groupe de sécurité. -
Créez les règles entrantes suivantes.
-
La connexion HTTPS au groupe de sécurité que vous avez configuré pour la PrivateLink connexion Snowflake que vous avez créée à l'étape Configurer l'intégration PrivateLink Snowflake.
-
La connexion HTTP au groupe de sécurité que vous avez configuré pour la PrivateLink connexion Snowflake que vous avez créée à l'étape Configurer l'intégration PrivateLink Snowflake.
-
Le groupe de sécurité UDP et TCP pour DNS (port 53) vers le groupe de sécurité de point de terminaison entrant du résolveur Route 53 que vous créez à l'étape 2 de Configuration du point de terminaison entrant du résolveur Route 53 pour votre VPC.
-
-
Cliquez sur le bouton Create Security Group (Créer un groupe de sécurité) dans le coin inférieur droit.
-
-
Configurez Studio Classic.
-
Accédez au menu SageMaker AI de la AWS console.
-
Sur la console de gauche, sélectionnez l'option SageMaker AI Studio Classic.
-
Si aucun domaine n'est configuré, le menu Get Started (Démarrer) apparaît.
-
Sélectionnez l'option Standard Setup (Configuration standard) dans le menu Get Started (Démarrer).
-
Sous Authentication method (Méthode d'authentification), sélectionnez AWS Identity and Access Management (IAM).
-
Depuis le menu Permissions (Autorisations), vous pouvez créer un nouveau rôle ou utiliser un rôle préexistant, selon votre cas d'utilisation.
-
Si vous avez choisi Create a new role (Créer un nouveau rôle), vous avez la possibilité de fournir un nom de compartiment S3, et une politique est générée pour vous.
-
Si vous disposez déjà d'un rôle créé avec des autorisations pour les compartiments S3 auxquels vous devez accéder, sélectionnez-le dans la liste déroulante. Ce rôle doit être associé à la politique
AmazonSageMakerFullAccess.
-
-
Sélectionnez la liste déroulante Réseau et stockage pour configurer le VPC, la sécurité et les SageMaker sous-réseaux utilisés par l'IA.
-
Sous VPC, sélectionnez le VPC dans lequel votre connexion Snowflake existe. PrivateLink
-
Sous Sous-réseau (s), sélectionnez les sous-réseaux qui ont accès à la connexion PrivateLink Snowflake.
-
Sous Accès réseau pour Studio Classic, sélectionnez VPC uniquement.
-
Sous Security Group(s) (Groupe[s] de sécurité), sélectionnez le groupe de sécurité que vous avez créé à l'étape 1.
-
-
Sélectionnez Submit (Envoyer).
-
-
Modifiez le groupe de sécurité SageMaker AI.
-
Créez les règles entrantes suivantes :
-
Port 2049 vers les groupes de sécurité NFS entrants et sortants créés automatiquement par SageMaker AI à l'étape 2 (les noms des groupes de sécurité contiennent l'ID de domaine Studio Classic).
-
Accès à tous les ports TCP pour lui-même (requis pour SageMaker AI pour VPC uniquement).
-
-
-
Modifiez les groupes de sécurité des points de terminaison VPC :
-
Accédez au EC2 menu Amazon dans la AWS console.
-
Localisez le groupe de sécurité que vous avez créé à l'étape précédente.
-
Ajoutez une règle de trafic entrant autorisant le trafic HTTPS à partir du groupe de sécurité créé à l'étape 1.
-
-
Créez un profil utilisateur.
-
Dans le panneau de configuration de SageMaker Studio Classic, choisissez Ajouter un utilisateur.
-
Indiquez un nom d'utilisateur.
-
Pour Execution role (Rôle d'exécution), choisissez de créer un rôle ou d'en utiliser un existant.
-
Si vous avez choisi Create a new role (Créer un nouveau rôle), vous avez la possibilité de fournir un nom de compartiment Amazon S3, et une politique est générée pour vous.
-
Si vous disposez déjà d'un rôle créé avec des autorisations sur les compartiments Amazon S3 auxquels vous devez accéder, sélectionnez-le dans la liste déroulante. Ce rôle doit être associé à la politique
AmazonSageMakerFullAccess.
-
-
Sélectionnez Envoyer.
-
-
Créez un flux de données (suivez le Guide du scientifique des données repris dans une section précédente).
-
Lorsque vous ajoutez une connexion Snowflake, entrez la valeur de
privatelink-account-name(à partir de l'étape Configurer l' PrivateLinkintégration Snowflake) dans le champ du nom du compte Snowflake (alphanumérique), au lieu du nom de compte Snowflake ordinaire. Tout le reste est laissé inchangé.
-
Fournir des informations au scientifique des données
Fournissez au data scientist les informations dont il a besoin pour accéder à Snowflake depuis Amazon SageMaker AI Data Wrangler.
Important
Vos utilisateurs doivent exécuter Amazon SageMaker Studio Classic version 1.3.0 ou ultérieure. Pour plus d'informations sur la vérification de la version de Studio Classic et sa mise à jour, consultezPréparez les données ML avec Amazon SageMaker Data Wrangler.
-
Pour permettre à votre data scientist d'accéder à Snowflake depuis SageMaker Data Wrangler, fournissez-lui l'un des éléments suivants :
-
Pour l'Authentification de base, un nom de compte Snowflake, un nom d'utilisateur et un mot de passe.
-
Pour OAuth, un nom d'utilisateur et un mot de passe dans le fournisseur d'identité.
-
Pour ARN, l'Amazon Resource Name (ARN) du secret Secrets Manager.
-
Un secret créé avec AWS Secrets Manager et l'ARN du secret. Utilisez la procédure ci-dessous pour créer le secret pour Snowflake si vous choisissez cette option.
Important
Si vos scientifiques des données utilisent l'option Informations d'identification Snowflake [Nom d'utilisateur et mot de passe] pour s'y connecter, notez que Secrets Manager permet de stocker les informations d'identification dans un secret. Secrets Manager procède à une rotation des secrets dans le cadre d'un plan de sécurité des bonnes pratiques. Le secret créé dans Secrets Manager n'est accessible qu'avec le rôle Studio Classic configuré lorsque vous configurez un profil utilisateur Studio Classic. Cela nécessite que vous ajoutiez cette autorisation à la politique associée à votre rôle Studio Classic.
secretsmanager:PutResourcePolicyNous vous recommandons vivement de définir la politique des rôles de manière à utiliser différents rôles pour différents groupes d'utilisateurs de Studio Classic. Vous pouvez ajouter des autorisations supplémentaires basées sur les ressources pour les secrets de Secrets Manager. Veuillez consulter la politique Gestion de politique de secret pour connaître les clés de condition que vous pouvez utiliser.
Pour plus d'informations sur la création d'un secret, consultez Création d'un secret. Vous êtes facturés pour les secrets que vous créez.
-
-
(Facultatif) Fournissez au scientifique des données le nom de l'intégration de stockage que vous avez créée à l'aide de la procédure suivante : Créer une intégration de stockage dans le cloud dans Snowflake
. Il s'agit du nom de la nouvelle intégration, appelée integration_namedans la commande SQLCREATE INTEGRATIONque vous avez exécutée, et qui est affichée dans l'extrait suivant :CREATE STORAGE INTEGRATION integration_name TYPE = EXTERNAL_STAGE STORAGE_PROVIDER = S3 ENABLED = TRUE STORAGE_AWS_ROLE_ARN = 'iam_role' [ STORAGE_AWS_OBJECT_ACL = 'bucket-owner-full-control' ] STORAGE_ALLOWED_LOCATIONS = ('s3://bucket/path/', 's3://bucket/path/') [ STORAGE_BLOCKED_LOCATIONS = ('s3://bucket/path/', 's3://bucket/path/') ]
Guide des scientifiques des données
Utilisez ce qui suit pour connecter Salesforce et accéder à vos données dans Data Wrangler.
Important
Votre administrateur doit utiliser les informations des sections précédentes pour configurer Snowflake. Si vous rencontrez des problèmes, contactez-les pour obtenir de l'aide.
Vous pouvez vous connecter à Snowflake de l'une des manières suivantes :
-
En spécifiant vos informations d'identification Snowflake (nom du compte, nom d'utilisateur et mot de passe) dans Data Wrangler.
-
En fournissant l'Amazon Resource Name (ARN) du secret contenant les informations d'identification.
-
Utilisation d'un standard ouvert pour le fournisseur de délégation d'accès (OAuth) qui se connecte à Snowflake. Votre administrateur peut vous donner accès à l'un des OAuth fournisseurs suivants :
Discutez avec votre administrateur de la méthode à utiliser pour vous connecter à Snowflake.
Les sections suivantes contiennent des informations sur la façon dont vous pouvez vous connecter à Snowflake à l'aide des méthodes précédentes.
Vous pouvez commencer le processus d'importation de vos données depuis Snowflake une fois que vous vous y êtes connecté.
Dans Data Wrangler, vous pouvez consulter vos entrepôts des données, vos bases de données et vos schémas, ainsi que l'icône en forme d'œil avec laquelle vous pouvez prévisualiser votre table. Une fois que vous avez sélectionné l'icône Aperçu de la table, l'aperçu du schéma de cette table est généré. Vous devez sélectionner un entrepôt avant de pouvoir prévisualiser une table.
Important
Si vous importez un jeu de données avec des colonnes de type TIMESTAMP_TZ ou TIMESTAMP_LTZ, ajoutez ::string aux noms de colonnes de votre requête. Pour plus d'informations, consultez Procédure : décharger les données TIMESTAMP_TZ et TIMESTAMP_LTZ dans un fichier Parquet
Après avoir sélectionné un entrepôt des données, une base de données et un schéma, vous pouvez écrire des requêtes et les exécuter. La sortie de votre requête s'affichera sous Résultats de la requête.
Une fois que vous avez réglé la sortie de votre requête, vous pouvez l'importer dans un flux Data Wrangler pour effectuer des transformations de données.
Après avoir importé vos données, accédez à votre flux Data Wrangler et commencez à y ajouter des transformations. Pour une liste des transformations disponibles, consultez Transformation de données.
Importer des données à partir de plateformes de logiciel en tant que service (SaaS)
Vous pouvez utiliser Data Wrangler pour importer des données à partir de plus de 40 plateformes de logiciel en tant que service (SaaS). Pour importer vos données depuis votre plateforme SaaS, vous ou votre administrateur devez utiliser Amazon AppFlow pour transférer les données de la plateforme vers Amazon S3 ou Amazon Redshift. Pour plus d'informations sur Amazon AppFlow, consultez Qu'est-ce qu'Amazon AppFlow ? Si vous n'avez pas besoin d'utiliser Amazon Redshift, nous vous recommandons de transférer les données vers Amazon S3 pour simplifier le processus.
Data Wrangler prend en charge le transfert de données à partir des plateformes SaaS suivantes :
-
Surveiller
La liste précédente contient des liens vers des informations supplémentaires sur la configuration de votre source de données. Vous ou votre administrateur pouvez consulter les liens précédents après avoir lu les informations suivantes.
Lorsque vous accédez à l'onglet Import (Importer) de votre flux Data Wrangler, les sources de données s'affichent dans les sections suivantes :
-
Disponible
-
Configurer des sources de données
Vous pouvez vous connecter à des sources de données sous Available (Disponible) sans avoir besoin d'une configuration supplémentaire. Vous pouvez choisir la source de données et importer vos données.
Sources de données sous Configuration des sources de données, vous ou votre administrateur devez utiliser Amazon AppFlow pour transférer les données de la plateforme SaaS vers Amazon S3 ou Amazon Redshift. Pour plus d'informations sur les transferts, veuillez consulter Utiliser Amazon AppFlow pour transférer vos données.
Une fois le transfert de données effectué, la plateforme SaaS apparaît en tant que source de données sous Available (Disponible). Vous pouvez la choisir et importer les données que vous avez transférées dans Data Wrangler. Les données que vous avez transférées apparaissent sous forme de tables que vous pouvez interroger.
Utiliser Amazon AppFlow pour transférer vos données
Amazon AppFlow est une plateforme que vous pouvez utiliser pour transférer des données de votre plateforme SaaS vers Amazon S3 ou Amazon Redshift sans avoir à écrire de code. Pour effectuer un transfert de données, utilisez la AWS Management Console.
Important
Vous devez vous assurer d'avoir configuré les autorisations nécessaires pour effectuer un transfert de données. Pour de plus amples informations, veuillez consulter AppFlow Autorisations Amazon.
Après avoir ajouté des autorisations, vous pouvez transférer les données. Au sein d'Amazon AppFlow, vous créez un flux pour transférer les données. Un flux est une série de configurations. Vous pouvez l'utiliser pour spécifier si vous exécutez le transfert de données selon un calendrier ou si vous partitionnez les données dans des fichiers distincts. Après avoir configuré le flux, vous pouvez l'exécuter pour transférer les données.
Pour plus d'informations sur la création d'un flux, consultez Création de flux dans Amazon AppFlow. Pour plus d'informations sur l'exécution d'un flux, consultez Activer un AppFlow flux Amazon.
Une fois les données transférées, utilisez la procédure suivante pour accéder aux données dans Data Wrangler.
Important
Avant d'essayer d'accéder à vos données, assurez-vous que votre rôle IAM respecte la politique suivante :
Par défaut, le rôle IAM que vous utilisez pour accéder à Data Wrangler est le SageMakerExecutionRole. Pour plus d'informations sur l'ajout de politiques, veuillez consulter Ajouter des autorisations d'identité IAM (console).
Pour vous connecter à une source de données, procédez comme suit.
-
Connectez-vous à Amazon SageMaker AI Console
. -
Choisissez Studio.
-
Choisissez Launch app (Lancer l'application).
-
Dans la liste déroulante, sélectionnez Studio.
-
Choisissez l'icône d'accueil.
-
Choisissez Data (Données).
-
Choisissez Data Wrangler.
-
Choisissez Import data (Importer les données).
-
Sous Available (Disponible), sélectionnez la source de données.
-
Dans le champ Name (Nom), spécifiez le nom de la connexion.
-
(Facultatif) Choisissez Advanced configuration (Configuration avancée).
-
Choisissez un Workgroup (Groupe de travail).
-
Si votre groupe de travail n'a pas appliqué l'emplacement de sortie Amazon S3 ou si vous n'avez pas utilisé un groupe de travail, spécifiez une valeur pour Emplacement Amazon S3 des résultats des requêtes.
-
(Facultatif) Pour la zone Data retention period (Durée de conservation des données), cochez la case permettant de définir une durée de conservation des données et spécifiez le nombre de jours pendant lesquels les données doivent être stockées avant leur suppression.
-
(Facultatif) Par défaut, Data Wrangler enregistre la connexion. Vous pouvez choisir de désélectionner la case à cocher et de ne pas enregistrer la connexion.
-
-
Choisissez Se connecter.
-
Spécifiez une requête.
Note
Pour vous aider à définir une requête, vous pouvez sélectionner un tableau dans le panneau de navigation de gauche. Data Wrangler affiche le nom et un aperçu du tableau. Choisissez l'icône en regard du nom du tableau pour copier son nom. Vous pouvez utiliser le nom du tableau dans la requête.
-
Cliquez sur Exécuter.
-
Choisissez Import query (Importer une requête).
-
Dans Dataset name (Nom du jeu de données), indiquez le nom du jeu de données.
-
Choisissez Ajouter.
Lorsque vous accédez à l'écran Import data (Importer des données), vous pouvez voir la connexion que vous avez créée. Vous pouvez utiliser la connexion pour importer davantage de données.
Stockage des données importées
Important
Nous vous recommandons vivement de suivre les bonnes pratiques en matière de protection de votre compartiment Amazon S3 en suivant les bonnes pratiques de sécurité.
Lorsque vous interrogez des données depuis Amazon Athena ou Amazon Redshift, le jeu de données interrogé est automatiquement stocké dans Amazon S3. Les données sont stockées dans le compartiment SageMaker AI S3 par défaut de la AWS région dans laquelle vous utilisez Studio Classic.
Les compartiments S3 par défaut ont la convention de dénomination suivante : sagemaker-. Par exemple, si votre numéro de compte est 111122223333 et que vous utilisez Studio Classic dansregion-account
numberus-east-1, vos ensembles de données importés sont stockés dans 111122223333. sagemaker-us-east-1-
Les flux Data Wrangler dépendent de cet emplacement de jeu de données Amazon S3, vous ne devez donc pas modifier ce jeu de données dans Amazon S3 lorsque vous utilisez un flux dépendant. Si vous modifiez cet emplacement S3 et que vous souhaitez continuer à utiliser votre flux de données, vous devez supprimer tous les objets dans trained_parameters dans votre fichier .flow. Pour ce faire, téléchargez le fichier .flow depuis Studio Classic et supprimez toutes les entrées pour chaque instance detrained_parameters. Lorsque vous avez terminé, trained_parameters doit être un objet JSON vide :
"trained_parameters": {}
Lorsque vous exportez et utilisez votre flux de données pour traiter vos données, le fichier .flow que vous exportez fait référence à ce jeu de données dans Amazon S3. Consultez les sections suivantes pour en apprendre plus.
Stockage d'importation Amazon Redshift
Data Wrangler stocke les ensembles de données résultant de votre requête dans un fichier Parquet de votre bucket SageMaker AI S3 par défaut.
Ce fichier est stocké sous le préfixe (répertoire) suivant : redshift/ uuid /data/, où se uuid trouve un identifiant unique créé pour chaque requête.
Par exemple, si votre compartiment par défaut estsagemaker-us-east-1-111122223333, un seul ensemble de données demandé par Amazon Redshift se trouve dans s3 ://-1-111122223333/redshift/ /data/. sagemaker-us-east uuid
Stockage d'importation Amazon Athena
Lorsque vous interrogez une base de données Athena et importez un jeu de données, Data Wrangler stocke le jeu de données, ainsi qu'un sous-ensemble de ce jeu de données, ou preview files (aperçu des fichiers), dans Amazon S3.
Le jeu de données que vous importez en sélectionnant Import dataset (Importer un jeu de données) est stocké au format Parquet dans Amazon S3.
Les fichiers d'aperçu sont écrits au format CSV lorsque vous cliquez sur Run (Exécuter) sur l'écran d'importation Athena et contiennent jusqu'à 100 lignes de votre jeu de données interrogé.
L'ensemble de données que vous interrogez se trouve sous le préfixe (répertoire) : athena/ uuid /data/, où se uuid trouve un identifiant unique créé pour chaque requête.
Par exemple, si votre bucket par défaut estsagemaker-us-east-1-111122223333, un seul ensemble de données interrogé par Athena se trouve dans /athena/ /data/. s3://sagemaker-us-east-1-111122223333 uuid example_dataset.parquet
Le sous-ensemble du jeu de données stocké pour prévisualiser les fichiers de données dans Data Wrangler est stocké sous le préfixe athena/.
