REL13-BP02 Utiliser des stratégies de reprise définies pour répondre aux objectifs de reprise
Définissez une stratégie de reprise après sinistre qui répond aux objectifs de reprise de votre charge de travail. Choisissez une stratégie telle que : sauvegarde et restauration, mode secours (actif/passif) ou actif/actif.
Résultat escompté : pour chaque charge de travail, il existe une stratégie de reprise après sinistre définie et implémentée qui permet à cette charge de travail d’atteindre les objectifs de reprise. Les stratégies de reprise après sinistre entre les charges de travail utilisent des modèles réutilisables (comme les stratégies décrites précédemment).
Anti-modèles courants :
-
Mettre en œuvre des procédures de récupération incohérentes pour les charges de travail avec des objectifs de reprise après sinistre similaires.
-
Conserver l’implémentation ad hoc de la stratégie de reprise après sinistre lorsqu’un sinistre se produit.
-
Ne pas avoir de plan de reprise après sinistre.
-
Être dépendant des opérations du plan de contrôle pendant la récupération.
Avantages liés au respect de cette bonne pratique :
-
L’utilisation de stratégies de reprise définies vous permet d’utiliser des outils et des procédures de test courantes.
-
L’utilisation de stratégies de reprise définies améliore le partage des connaissances entre les équipes et la mise en œuvre de la reprise après sinistre sur les charges de travail qu’elles possèdent.
Niveau d’exposition au risque si cette bonne pratique n’est pas respectée : élevé. Sans une stratégie de reprise après sinistre planifiée, mise en œuvre et testée, il est peu probable que vous atteigniez vos objectifs de reprise en cas de sinistre.
Directives d’implémentation
Une stratégie de reprise après sinistre repose sur la capacité à rétablir votre charge de travail sur un site de reprise si votre emplacement principal ne parvient plus à exécuter cette charge de travail. Les objectifs de récupération les plus courants sont le RTO et le RPO, comme indiqué dans REL13-BP01 Définir les objectifs de reprise en termes de durée d’indisponibilité et de perte de données.
Une stratégie de reprise après sinistre sur plusieurs zones de disponibilité (AZ) au sein d’une seule Région AWS peut vous prémunir contre les événements catastrophiques tels que les incendies, les inondations et les pannes de courant majeures. S’il est nécessaire de mettre en œuvre une protection contre un événement improbable qui empêcherait votre charge de travail de s’exécuter dans une Région AWS donnée, optez pour une stratégie de reprise après sinistre qui utilise plusieurs régions.
Lors de la conception d’une stratégie de reprise après sinistre dans plusieurs régions, vous devez choisir l’une des approches suivantes. Elles sont classées par ordre croissant de coût et de complexité, et par ordre décroissant de RTO et RPO. La région de restauration fait référence à une région Région AWS autre que la région principale utilisée pour votre charge de travail.
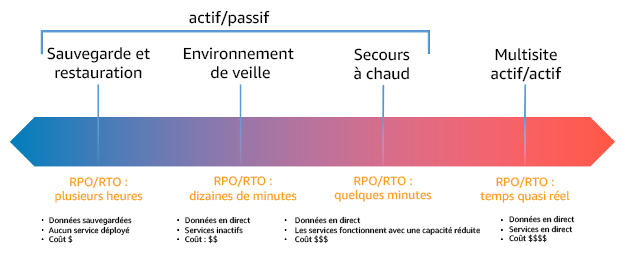
Figure 17 : stratégies de reprise après sinistre
-
Sauvegarde et restauration (RPO en heures, RTO de 24 heures maximum) : sauvegardez vos données et applications dans la région de reprise après sinistre. L’utilisation de sauvegardes automatisées ou continues permet une reprise ponctuelle (PITR), ce qui peut réduire le RPO à seulement 5 minutes dans certains cas. En cas de sinistre, vous déployez votre infrastructure (en utilisant l’infrastructure en tant que code pour réduire le RTO), déployez votre code et restaurez les données sauvegardées pour vous remettre d’un sinistre dans la région de reprise.
-
Veilleuse (RPO de quelques minutes, RTO de dizaines de minutes) : allouez une copie de votre infrastructure de charge de travail principale dans la région de reprise. Répliquez vos données dans la région de reprise et créez-y des sauvegardes. Les ressources requises pour prendre en charge la réplication et la sauvegarde des données, telles que les bases de données et le stockage d’objets, sont toujours actives. D’autres éléments tels que les serveurs d’applications ou le calcul sans serveur ne sont pas déployés, mais peuvent être créés si nécessaire avec la configuration et le code d’application requis.
-
Secours semi-automatique (RPO de quelques secondes, RTO de quelques minutes) : maintenez une version réduite verticalement d’une charge de travail entièrement fonctionnelle qui s’exécute toujours dans la région de reprise. Les systèmes stratégiques sont entièrement dupliqués et sont toujours opérationnels, mais avec une flotte réduite verticalement. Les données sont répliquées dans la région de reprise et y sont hébergées. Lorsque vient le moment de la reprise, le système est rapidement mis à l’échelle pour gérer la charge de production. Plus l’échelle du secours à chaud est élevée, plus la dépendance au RTO et au plan de contrôle est faible. Lorsqu’elle est entièrement mise à l’échelle, on parle de veille permanente.
-
Multi-région (multi-site) active-active (RPO proche de zéro, RTO potentiellement nul) : votre charge de travail est déployée et dessert activement le trafic à partir de plusieurs Régions AWS. Cette stratégie vous oblige à synchroniser les données entre les régions. Il est important d’éviter ou de gérer les éventuels conflits causés par des écritures sur le même enregistrement dans deux réplicas régionaux différents, ce qui peut être complexe. La réplication des données est utile pour la synchronisation des données et vous protège contre certains types de sinistres. Toutefois, elle ne vous protège pas contre la corruption ou la destruction des données à moins que votre solution n’inclue également des options de récupération ponctuelle.
Note
La différence entre l’environnement en veille et le secours à chaud est parfois difficile à cerner. Ces deux stratégies incluent un environnement dans votre région de reprise avec des copies des ressources de votre région principale. L’environnement en veille diffère en ce qu’il ne peut pas traiter les demandes sans qu’une action supplémentaire soit entreprise au préalable, tandis que le secours à chaud peut gérer le trafic (à des niveaux de capacité réduits) immédiatement. L’environnement en veille vous oblige à allumer des serveurs, à déployer éventuellement une infrastructure supplémentaire (non essentielle) et à augmenter verticalement, tandis que le secours à chaud nécessite uniquement une augmentation verticale (tout est déjà déployé et en cours d’exécution). Choisissez entre ces options en fonction de vos besoins en matière de RTO et de RPO.
Si le coût est un problème et que vous souhaitez atteindre des objectifs de RPO et RTO similaires à ceux définis dans la stratégie de secours à chaud, vous pouvez envisager des solutions natives du cloud, comme AWS Elastic Disaster Recovery, qui adoptent l’approche de l’environnement de veille et offrent des objectifs de RPO et RTO améliorés.
Étapes d’implémentation
-
Déterminez une stratégie de reprise après sinistre qui répond aux exigences de récupération pour cette charge de travail.
Le choix d’une stratégie de reprise après sinistre vise à trouver un juste milieu entre la réduction des temps d’arrêt et de la perte de données (RTO et RPO) et le coût et la complexité liées à la mise en œuvre de cette stratégie. Évitez de mettre en œuvre une stratégie plus stricte que nécessaire, car cela entraînerait des coûts inutiles.
Par exemple, dans le diagramme suivant, l’entreprise a déterminé son RTO maximal autorisé ainsi que la limite de dépenses possible pour sa stratégie de restauration de service. Compte tenu des objectifs de l’entreprise, les stratégies de reprise après sinistre en veille et secours à chaud satisfont à la fois aux critères de RTO et de coût.
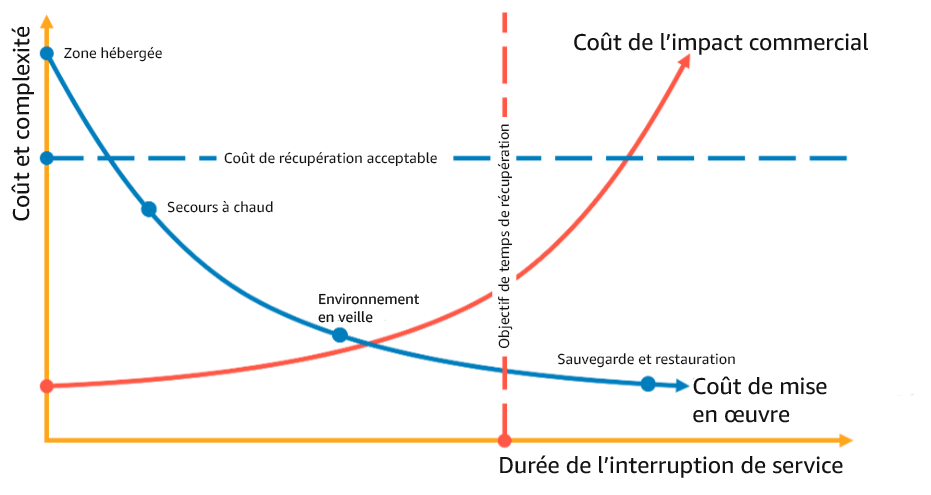
Figure 18 : choix d’une stratégie de reprise après sinistre basée sur le RTO et le coût
Pour en savoir plus, consultez Plan de continuité d’activité (BCP).
-
Passez en revue les modèles de mise en œuvre de la stratégie de reprise après sinistre sélectionnée.
Cette étape consiste à comprendre comment mettre en œuvre la stratégie sélectionnée. Les stratégies reposent sur l’utilisation de Régions AWS comme site principal et site de reprise. Cependant, vous pouvez également choisir d’utiliser des zones de disponibilité dans une seule région comme stratégie de reprise après sinistre, ce qui permet d’exploiter des éléments de plusieurs de ces stratégies.
Dans les étapes suivantes, vous pouvez appliquer la stratégie à votre charge de travail spécifique.
Sauvegarde et restauration
Sauvegarde et restauration est la stratégie la moins complexe à mettre en œuvre, mais nécessite plus de temps et d’efforts pour la restauration de la charge de travail, ce qui entraîne un RTO et un RPO plus élevés. Il est conseillé de toujours faire des sauvegardes de vos données et de les copier sur un autre site (comme une autre Région AWS).
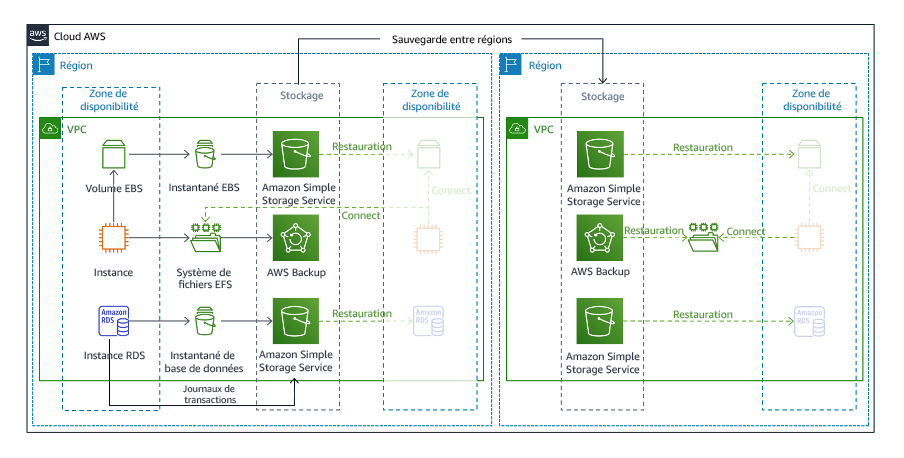
Figure 19 : architecture de sauvegarde et de restauration
Pour en savoir plus sur cette stratégie, consultezArchitecture de reprise après sinistre (DR) sur AWS, partie 2 : sauvegarde et restauration avec récupération rapide
. Veilleuse
L’approche de veilleuse, vous permet de répliquer vos données depuis la région principale vers la région de reprise. Les ressources principales utilisées pour l’infrastructure de charge de travail sont déployées dans la région de reprise, mais des ressources supplémentaires et toutes les dépendances sont toujours nécessaires pour en faire une pile fonctionnelle. Par exemple, dans la figure 20, aucune instance de calcul n’est déployée.
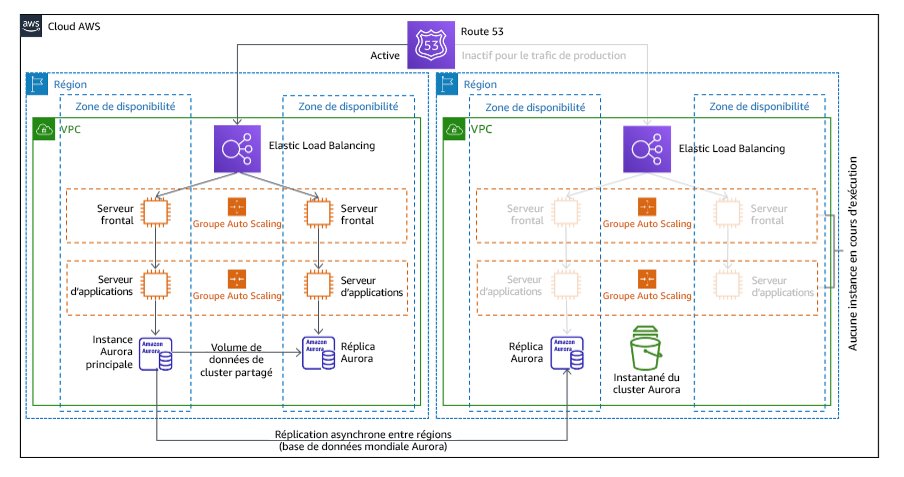
Figure 20 : architecture avec environnement en veille
Pour en savoir plus sur cette stratégie, consultez Architecture de reprise après sinistre sur AWS, partie 3 : environnement en veille et secours à chaud
. Secours semi-automatique
L’approche du secours semi-automatique consiste à s’assurer qu’il existe une copie réduite verticalement, mais entièrement fonctionnelle, de votre environnement de production dans une autre région. Cette approche étend le concept d’environnement en veille et réduit le temps de récupération, car votre charge de travail reste active dans une autre région. Si la région de reprise est déployée à pleine capacité, on parle de veille permanente.
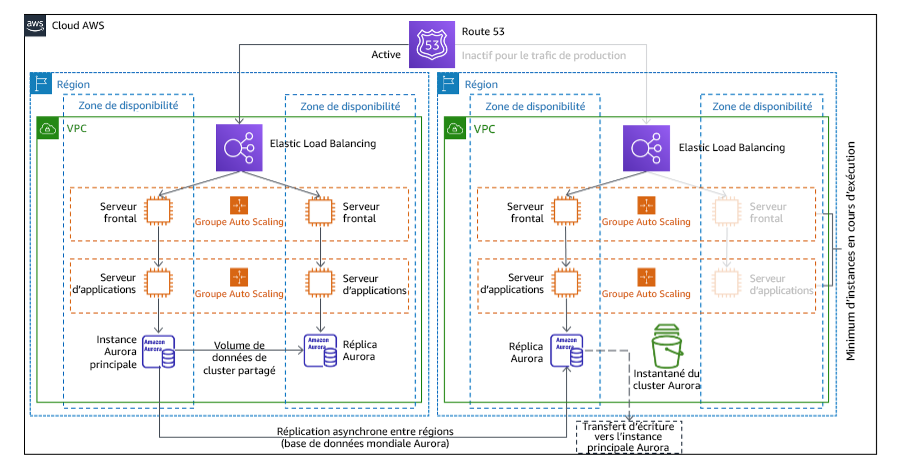
Figure 21 : Architecture de secours à chaud
L’utilisation du secours à chaud ou de l’environnement en veille nécessite une augmentation verticale des ressources dans la région de reprise. Pour vérifier que la capacité est disponible en cas de besoin, envisagez de l’utiliser pour les réservations de capacité pour les instances EC2. Si vous utilisez AWS Lambda, la simultanéité provisionnée peut fournir des environnements d’exécution afin qu’ils soient prêts à répondre immédiatement aux invocations de votre fonction.
Pour plus de détails sur cette stratégie, consultez Architecture de reprise après sinistre sur AWS, partie 3 : environnement en veille et secours à chaud
. Multisite actif/actif
Vous pouvez exécuter votre charge de travail simultanément dans plusieurs régions dans le cadre d’une stratégie multisite active/active. Une stratégie multisite actif/actif dessert le trafic de toutes les régions dans lesquelles il est déployé. Les clients peuvent sélectionner cette stratégie pour des raisons autres que la reprise après sinistre. Elle peut être utilisée pour augmenter la disponibilité ou lors du déploiement d’une charge de travail auprès d’une audience mondiale (pour rapprocher le point de terminaison des utilisateurs et/ou déployer des piles localisées pour l’audience de cette région). En tant que stratégie de reprise après sinistre, si la charge de travail ne peut pas être prise en charge dans l’une des Régions AWS vers lesquelles elle est déployée, cette région est évacuée, et les régions restantes sont utilisées pour assurer la disponibilité. La stratégie de reprise après sinistre multisite actif/actif est la plus complexe sur le plan opérationnel et ne doit être sélectionnée que lorsque les besoins de l’entreprise l’exigent.
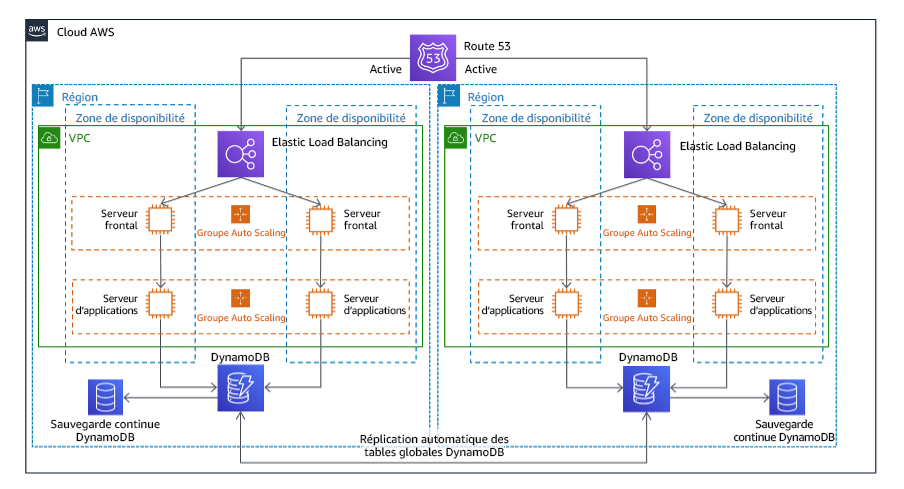
Figure 22 : architecture multisite de type actif/actif
Pour en savoir plus sur cette stratégie, consultez Architecture de reprise après sinistre sur AWS, partie 4 : multisite actif/actif
. AWS Elastic Disaster Recovery
Si vous envisagez d’adopter une stratégie de veilleuse ou de secours à chaud pour la reprise après sinistre, AWS Elastic Disaster Recovery peut proposer une autre approche offrant de meilleurs avantages. Elastic Disaster Recovery peut offrir un objectif de RPO et de RTO similaire à celui du mode de secours à chaud, tout en conservant l’approche peu coûteuse de la veilleuse. Elastic Disaster Recovery réplique vos données de votre région principale vers votre région de reprise, en utilisant une protection continue des données pour atteindre un RPO mesuré en secondes et un RTO mesurable en minutes. Seules les ressources nécessaires à la réplication des données sont déployées dans la région de reprise, ce qui permet de limiter les coûts, à l’instar de la stratégie de l’environnement de veille. En cas d’utilisation de Elastic Disaster Recovery, le service coordonne et orchestre la récupération des ressources informatiques lorsqu’elle est initiée dans le cadre d’un basculement ou d’une opération.
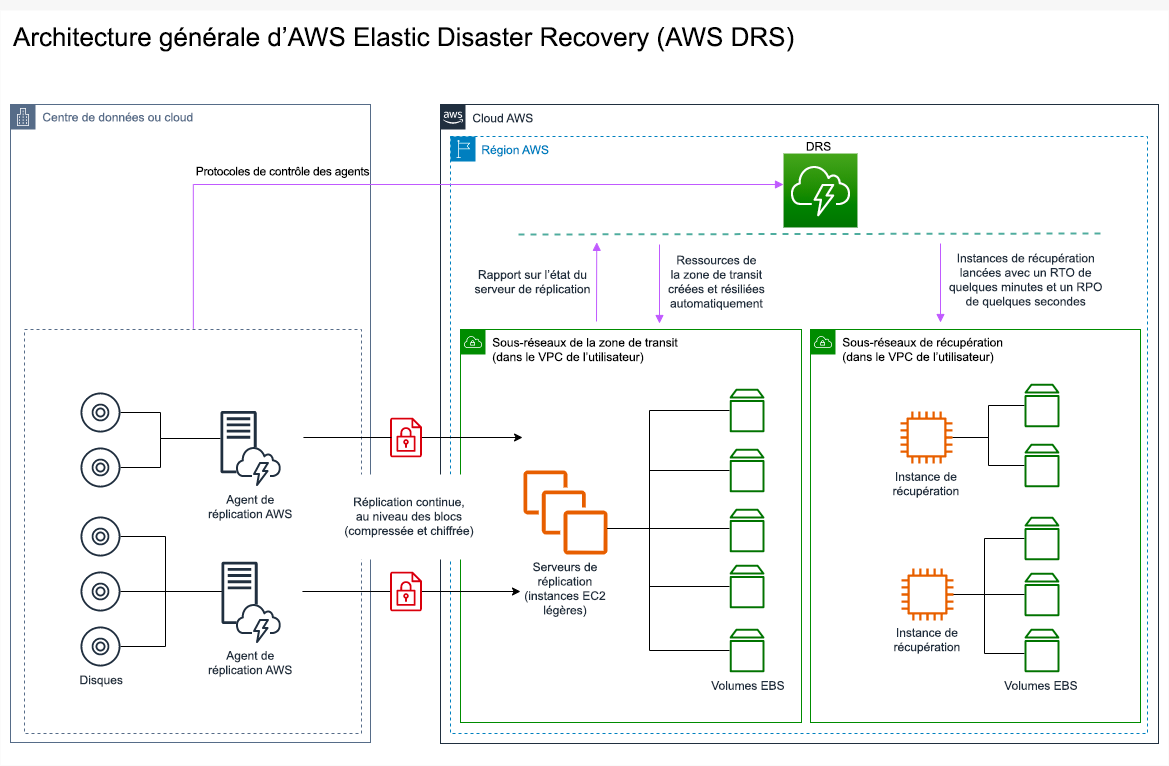
Figure 23 : architecture AWS Elastic Disaster Recovery
Pratiques supplémentaires de protection des données
Avec toutes les stratégies, vous devez également vous prémunir contre les catastrophes liées aux données. La réplication continue des données vous protège contre certains types de sinistres, mais ne vous protège pas toujours contre la corruption ou la destruction des données, à moins que votre stratégie n’inclue également la gestion des versions des données stockées ou des options de récupération ponctuelle. Vous devez également sauvegarder les données répliquées sur le site de reprise pour créer des sauvegardes ponctuelles en plus des réplicas.
Utilisation de plusieurs zones de disponibilité (AZ) dans une seule Région AWS
Lorsque vous utilisez plusieurs AZ dans une même région, l’implémentation de la reprise après sinistre exploite plusieurs éléments des stratégies ci-dessus. Vous devez d’abord créer une architecture haute disponibilité (HA), en utilisant plusieurs AZ, comme illustré à la figure 23. Cette architecture utilise une approche multisite actif/actif, car les instances Amazon EC2 et Elastic Load Balancer disposent de ressources déployées dans plusieurs zones de disponibilité, ce qui permet de traiter activement les demandes. L’architecture fait également appel au mode de veille permanente : en cas de défaillance de l’instance Amazon RDS principale (ou de l’AZ elle-même), l’instance de secours est promue en instance principale.
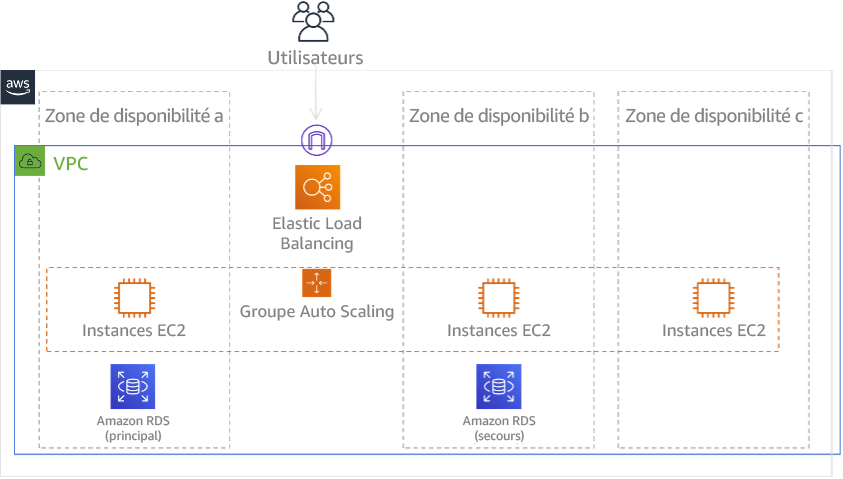
Figure 24 : architecture de multi-AZ
En plus de cette architecture haute disponibilité, vous devez ajouter des sauvegardes de toutes les données requises pour exécuter votre charge de travail. Une telle mesure est particulièrement importante pour les données limitées à une seule zone, telles que les volumes Amazon EBS ou les clusters Amazon Redshift. Si une zone de disponibilité tombe en panne, vous devrez restaurer ces données dans une autre zone de disponibilité. Dans la mesure du possible, vous devez également copier les sauvegardes de données dans une autre Région AWS comme couche de protection supplémentaire.
Une approche alternative moins courante à la reprise après sinistre multi-AZ à une seule région est illustrée dans le billet de blog intitulé Création d’applications hautement résilientes à l’aide d’Amazon Application Recovery Controller, partie 1 : pile dans une seule région
. Dans ce cas, la stratégie consiste à maintenir autant que possible l’isolement entre les zones de disponibilité, à l’instar du fonctionnement des régions. Avec cette stratégie alternative, vous pouvez choisir une approche active/active ou active/passive. Note
Certaines charges de travail sont soumises à des exigences réglementaires en matière de résidence des données. Si cela s’applique à votre charge de travail dans une localité qui n’a actuellement qu’une seule Région AWS, plusieurs régions ne répondront pas aux besoins de votre entreprise. Les stratégies multi-AZ assurent une bonne protection contre la plupart des catastrophes.
-
Évaluez les ressources de votre charge de travail et déterminez quelle sera leur configuration dans la région de reprise avant le basculement (pendant le fonctionnement normal).
Pour l’infrastructure et les ressources AWS, utilisez l’infrastructure sous forme de code tel que AWS CloudFormation
ou des outils tiers tels que Hashicorp Terraform. Pour un déploiement sur plusieurs comptes et régions en une seule opération, vous pouvez utiliser AWS CloudFormation StackSets. Pour les stratégies « Multisite actif/actif » et « Veille permanente », l’infrastructure déployée dans la région de reprise dispose des mêmes ressources que la région principale. Pour les stratégies « Environnement en veille » et « Secours à chaud », l’infrastructure déployée nécessitera des actions supplémentaires pour être prête pour la production. À l’aide des paramètres et de la logique conditionnelle de CloudFormation, vous pouvez contrôler si une pile déployée est active ou en veille avec un seul modèle . En utilisant Elastic Disaster Recovery, le service répliquera et orchestrera la restauration des configurations d’applications et des ressources informatiques. Toutes les stratégies de reprise après sinistre nécessitent que les sources de données soient sauvegardées dans la Région AWS, puis que ces sauvegardes soient copiées dans la région de restauration. AWS Backup
fournit une vue centralisée dans laquelle vous pouvez configurer, planifier et surveiller les sauvegardes de ces ressources. Pour les stratégies « Environnement en veille », « Secours à chaud » et « Multisite actif/actif », vous devez également répliquer les données de la région principale vers les ressources de données de la région de reprise, telles que des instances de base de données Amazon Relational Database Service (Amazon RDS) ou les tables Amazon DynamoDB . Ces ressources de données sont donc actives et prêtes à répondre aux demandes dans la région de reprise. Pour en savoir plus sur le fonctionnement des services AWS dans les différentes régions, consultez cette série de blogs sur la création d’une application multi-régionale avec des services AWS
. -
Déterminez et mettez en œuvre la manière dont vous préparerez votre région de reprise pour le basculement en cas de besoin (lors d’un sinistre).
Pour la stratégie multisite actif/actif, le basculement consiste à évacuer une région et à s’appuyer sur les régions actives restantes. En général, ces régions sont prêtes à accepter du trafic. Pour les stratégies « Environnement en veille » et « Secours à chaud », vos actions de reprise devront déployer les ressources manquantes, telles que les instances EC2 de la figure 20, ainsi que toute autre ressource manquante.
Pour toutes les stratégies ci-dessus, vous devrez peut-être promouvoir les instances en lecture seule des bases de données au rang d’instances principales en lecture/écriture.
Pour la sauvegarde et la restauration, la restauration des données à partir de la sauvegarde crée des ressources pour ces données, telles que des volumes EBS, des instances de base de données RDS et des tables DynamoDB. Vous devez également restaurer l’infrastructure et déployer le code. Vous pouvez utiliser AWS Backup pour restaurer les données dans la région de reprise. Pour plus d’informations, consultez REL09-BP01 Identifier et sauvegarder toutes les données qui doivent être sauvegardées, ou reproduire les données à partir de sources. La reconstruction de l’infrastructure inclut la création de ressources telles que des instances EC2 en plus du Virtual Private Cloud (VPC) Amazon
, des sous-réseaux et des groupes de sécurité nécessaires. Vous pouvez automatiser une grande partie du processus de restauration. Pour savoir comment procéder, consultez ce billet de blog . -
Déterminez et mettez en œuvre la manière dont vous redirigerez le trafic vers le basculement en cas de besoin (lors d’un sinistre).
Cette opération de basculement peut être lancée automatiquement ou manuellement. Le basculement lancé automatiquement sur la base de la surveillance de l’état ou d’alarmes doit être utilisé avec prudence, car un basculement inutile (fausse alerte) entraînerait des coûts tels que l’indisponibilité et la perte de données. Le basculement manuel est donc souvent utilisé. Dans ce cas, nous vous conseillons tout de même d’automatiser les étapes de basculement, de sorte que vous n’ayez à appuyer que sur un bouton pour lancer le basculement.
Il existe plusieurs options de gestion du trafic à prendre en compte lors de l’utilisation des services AWS. L’une des options consiste à utiliser Amazon Route 53
. Amazon Route 53 vous permet d’associer plusieurs points de terminaison IP dans une ou plusieurs Régions AWS avec un nom de domaine Route 53. Pour mettre en œuvre le basculement initié manuellement, vous pouvez utiliser Amazon Application Recovery Controller , qui fournit une API de plan de données hautement disponible pour rediriger le trafic vers la région de récupération. Lors de la mise en œuvre du basculement, utilisez les opérations du plan de données et évitez celles du plan de contrôle, comme décrit dans REL11-BP04 S'appuyer sur le plan de données et non sur le plan de contrôle lors de la restauration. Pour en savoir plus à ce sujet et sur d’autres options, consultez cette section du livre blanc sur la reprise après sinistre.
-
Élaborez un plan pour déterminer la façon dont votre charge de travail se rétablira.
Failback consiste à renvoyer l’exploitation de la charge de travail à la région principale, après qu’un événement de sinistre s’est atténué. La mise en service de l’infrastructure et du code dans la région principale suit généralement les mêmes étapes que celles utilisées initialement. Elle s’appuie notamment sur l’infrastructure en tant que code et les pipelines de déploiement de code. Le défi posé par failback consiste à restaurer les magasins de données et à garantir leur cohérence avec la région de reprise en cours d’exécution.
Lors de l’état de basculement, les bases de données de la région de reprise sont actives et disposent des données à jour. L’objectif est alors de resynchroniser les données de la région de reprise vers la région principale, en s’assurant qu’elle est à jour.
Certains services AWS effectuent cette opération automatiquement. Si vous utilisez des tables globales Amazon DynamoDB
, même si la table de la région principale devenait indisponible, DynamoDB reprendrait la propagation de toutes les écritures en attente lorsqu’elle se reconnecterait. Si vous utilisez Amazon Aurora Global Database et que vous utilisez un basculement planifié géré, la topologie de réplication existante de la base de données globale Aurora est conservée. Par conséquent, l’ancienne instance en lecture/écriture de la région principale deviendra un réplica et recevra les mises à jour de la région de reprise. Dans les cas où cela n’est pas automatique, vous devrez rétablir la base de données dans la région principale en tant que réplica de la base de données dans la région de reprise. Dans de nombreux cas, cela implique la suppression de l’ancienne base de données principale et la création de nouveaux réplicas.
Après un basculement, si vous pouvez poursuivre l’exécution dans la région de reprise, envisagez d’en faire la nouvelle région principale. Vous devriez alors suivre toutes les étapes ci-dessus pour convertir l’ancienne région principale en région de reprise. Certaines organisations effectuent une rotation planifiée, en échangeant périodiquement leurs régions principale et de reprise (par exemple tous les trois mois).
Toutes les étapes nécessaires au basculement et au rétablissement doivent être conservées dans un playbook accessible à tous les membres de l’équipe et révisé périodiquement.
En utilisant Elastic Disaster Recovery, le service permettra d’orchestrer et d’automatiser le processus de failback. Pour en savoir plus, consultez la section Réalisation d’un failback.
Niveau d’effort du plan d’implémentation : élevé
Ressources
Bonnes pratiques associées :
Documents connexes :
-
Blog d’architecture AWS : série sur la reprise après sinistre
-
Reprise après sinistre des charges de travail sur AWS : reprise dans le cloud (livre blanc AWS)
-
Créer une solution dorsale active-active sans serveur sur plusieurs régions en une heure
-
Solution dorsale sans serveur sur plusieurs régions – rechargé
-
Partenaire APN : partenaires pouvant faciliter la reprise après sinistre
-
AWS Marketplace : produits pouvant être utilisés pour la reprise après sinistre
Vidéos connexes :
