Le traduzioni sono generate tramite traduzione automatica. In caso di conflitto tra il contenuto di una traduzione e la versione originale in Inglese, quest'ultima prevarrà.
Capacità 2. Fornire accesso, utilizzo e implementazione sicuri alle tecniche generative AI RAG
Il diagramma seguente illustra i servizi AWS consigliati per l'account Generative AI for retrieval augmented generation (RAG). Lo scopo di questo scenario è proteggere la funzionalità RAG.
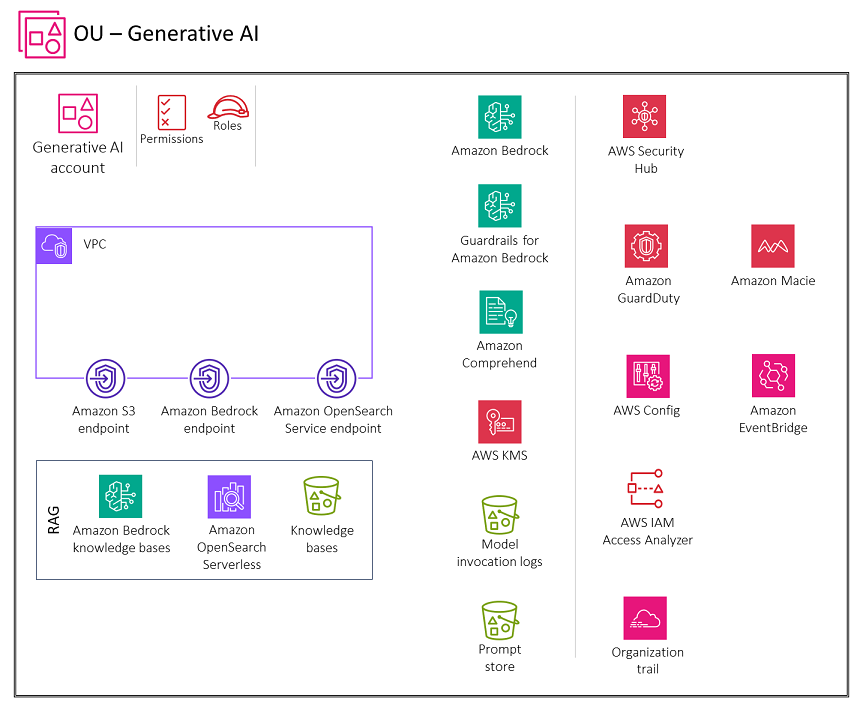
L'account Generative AI include i servizi necessari per archiviare gli incorporamenti in un database vettoriale, archiviare le conversazioni per gli utenti e mantenere un archivio tempestivo, oltre a una suite di servizi di sicurezza necessari per implementare barriere di sicurezza e una governance centralizzata della sicurezza. È necessario creare endpoint gateway Amazon S3 per i log di invocazione del modello, il prompt store e i bucket di origine dei dati della knowledge base in Amazon S3 a cui l'ambiente VPC è configurato per accedere. È inoltre necessario creare un endpoint CloudWatch Logs gateway per i CloudWatch log a cui l'ambiente VPC è configurato per accedere.
Rationale
Retrieval Augmented Generation (RAG)
Quando concedi agli utenti l'accesso alle knowledge base di Amazon Bedrock, devi tenere conto di queste considerazioni chiave sulla sicurezza:
-
Accesso sicuro all'invocazione del modello, alle knowledge base, alla cronologia delle conversazioni e al prompt store
-
Crittografia delle conversazioni, prompt store e knowledge base
-
Avvisi relativi a potenziali rischi per la sicurezza, come l'inserimento tempestivo o la divulgazione di informazioni sensibili
La sezione successiva illustra queste considerazioni sulla sicurezza e la funzionalità di intelligenza artificiale generativa.
Considerazioni di natura progettuale
Ti consigliamo di evitare di personalizzare un FM con dati sensibili (consulta la sezione sulla personalizzazione del modello di intelligenza artificiale generativa più avanti in questa guida). Utilizzate invece la tecnica RAG per interagire con informazioni sensibili. Questo metodo offre diversi vantaggi:
-
Controllo e visibilità più rigorosi. Mantenendo i dati sensibili separati dal modello, è possibile esercitare maggiore controllo e visibilità sulle informazioni sensibili. I dati possono essere facilmente modificati, aggiornati o rimossi secondo necessità, il che contribuisce a garantire una migliore governance dei dati.
-
Mitigazione della divulgazione di informazioni sensibili. RAG consente interazioni più controllate con i dati sensibili durante l'invocazione del modello. Questo aiuta a ridurre il rischio di divulgazione involontaria di informazioni sensibili, che potrebbe verificarsi se i dati fossero incorporati direttamente nei parametri del modello.
-
Flessibilità e adattabilità. La separazione dei dati sensibili dal modello offre maggiore flessibilità e adattabilità. Man mano che i requisiti relativi ai dati o le normative cambiano, le informazioni sensibili possono essere aggiornate o modificate senza la necessità di riqualificare o ricostruire l'intero modello linguistico.
Basi di conoscenza di Amazon Bedrock
Puoi utilizzare le knowledge base di Amazon Bedrock per creare applicazioni RAG connettendoti FMs alle tue fonti di dati in modo sicuro ed efficiente. Questa funzionalità utilizza Amazon OpenSearch Serverless come archivio vettoriale per recuperare in modo efficiente le informazioni pertinenti dai tuoi dati. I dati vengono quindi utilizzati dall'FM per generare risposte. I dati vengono sincronizzati da Amazon S3 alla knowledge base e
Considerazioni relative alla sicurezza
I carichi di lavoro generativi AI RAG affrontano rischi unici, tra cui l'esfiltrazione di dati dalle fonti di dati RAG e l'avvelenamento delle fonti di dati RAG con iniezioni tempestive di malware da parte di attori delle minacce. Le knowledge base di Amazon Bedrock offrono solidi controlli di sicurezza per la protezione dei dati, il controllo degli accessi, la sicurezza della rete, la registrazione e il monitoraggio e la convalida di input/output che possono aiutare a mitigare questi rischi.
Correzioni
Protezione dei dati
Crittografa i dati inattivi della tua knowledge base utilizzando una chiave gestita dal cliente AWS Key Management Service (AWS KMS) che crei, possiedi e gestisci. Quando configuri un processo di inserimento dati per la tua knowledge base, crittografa il lavoro con una chiave gestita dal cliente. Se decidi di consentire ad Amazon Bedrock di creare un archivio vettoriale in Amazon OpenSearch Service per la tua knowledge base, Amazon Bedrock può passare una chiave AWS KMS di tua scelta ad Amazon Service per la crittografia. OpenSearch
Puoi crittografare le sessioni in cui generi risposte interrogando una knowledge base con una chiave AWS KMS. Archivia le fonti di dati per la tua knowledge base nel tuo bucket S3. Se crittografi le tue fonti di dati in Amazon S3 con una chiave gestita dal cliente, allega una policy al tuo ruolo di servizio della Knowledge Base. Se l'archivio vettoriale che contiene la tua knowledge base è configurato con un segreto di AWS Secrets Manager, crittografa il segreto con una chiave gestita dal cliente.
Per ulteriori informazioni e le politiche da utilizzare, consulta la sezione Crittografia delle risorse della knowledge base nella documentazione di Amazon Bedrock.
Identity and Access Management
Crea un ruolo di servizio personalizzato per le knowledge base per Amazon Bedrock seguendo il principio del privilegio minimo. Crea una relazione di fiducia che consenta ad Amazon Bedrock di assumere questo ruolo e creare e gestire basi di conoscenza. Allega le seguenti politiche di identità al ruolo del servizio Knowledge base personalizzato:
-
Autorizzazioni per accedere ai modelli Amazon Bedrock
-
Autorizzazioni per accedere alle fonti di dati in Amazon S3
-
Autorizzazioni per accedere al tuo database vettoriale in Service OpenSearch
-
Autorizzazioni per accedere al cluster di database Amazon Aurora (opzionale)
-
Autorizzazioni per accedere a un database vettoriale configurato con un segreto di AWS Secrets Manager (opzionale)
-
Autorizzazioni per AWS a gestire una chiave AWS KMS per lo storage temporaneo dei dati durante l'ingestione dei dati
-
Autorizzazioni per AWS a gestire un'origine dati dall'account AWS di un altro utente (opzionale).
Le knowledge base supportano configurazioni di sicurezza per configurare policy di accesso ai dati per la tua knowledge base e policy di accesso alla rete per la tua knowledge base Amazon OpenSearch Serverless privata. Per ulteriori informazioni, consulta Creare una knowledge base e Ruoli di servizio nella documentazione di Amazon Bedrock.
Convalida di input e output
La convalida degli input è fondamentale per le knowledge base di Amazon Bedrock. Usa la protezione da malware in Amazon S3 per scansionare i file alla ricerca di contenuti dannosi prima di caricarli su un'origine dati. Per ulteriori informazioni, consulta il post sul blog di AWS Integrating Malware Scanning in Your Data Ingestion Pipeline with Antivirus for Amazon
Identifica e filtra le potenziali iniezioni immediate nei caricamenti degli utenti verso fonti di dati della knowledge base. Inoltre, rileva e oscura le informazioni di identificazione personale (PII) come altro controllo di convalida degli input nella pipeline di ingestione dei dati. Amazon Comprehend può aiutare a rilevare e redigere i dati PII nei caricamenti degli utenti su fonti di dati della knowledge base. Per ulteriori informazioni, consulta Rilevamento delle entità PII nella documentazione di Amazon Comprehend.
Ti consigliamo inoltre di utilizzare Amazon Macie per rilevare e generare avvisi su potenziali dati sensibili nelle fonti di dati della knowledge base, per migliorare la sicurezza e la conformità complessive. Implementa Guardrails for Amazon Bedrock per contribuire a far rispettare le politiche sui contenuti, bloccare input/output non sicuri e controllare il comportamento del modello in base ai tuoi requisiti.
Servizi AWS consigliati
Amazon OpenSearch Serverless
Amazon OpenSearch Serverless è una configurazione on-demand con scalabilità automatica per Amazon Service. OpenSearch Una raccolta OpenSearch Serverless è un OpenSearch cluster che ridimensiona la capacità di calcolo in base alle esigenze dell'applicazione. Le knowledge base di Amazon Bedrock utilizzano Amazon OpenSearch Serverless per gli incorporamenti
Implementa l'autenticazione e l'autorizzazione avanzate per il tuo archivio vettoriale Serverless. OpenSearch Implementa il principio del privilegio minimo, che concede solo le autorizzazioni necessarie a utenti e ruoli.
Con il controllo dell'accesso ai dati in OpenSearch Serverless, puoi consentire agli utenti di accedere a raccolte e indici indipendentemente dai meccanismi di accesso o dalle fonti di rete. Le autorizzazioni di accesso vengono gestite tramite politiche di accesso ai dati, che si applicano alle raccolte e alle risorse indicizzate. Quando utilizzate questo modello, verificate che l'applicazione diffonda l'identità dell'utente alla knowledge base e che la knowledge base applichi i controlli di accesso basati sui ruoli o sugli attributi. Ciò si ottiene configurando il ruolo del servizio della Knowledge Base secondo il principio del privilegio minimo e controllando rigorosamente l'accesso al ruolo.
OpenSearch Serverless supporta la crittografia lato server con AWS KMS per proteggere i dati inattivi. Usa una chiave gestita dal cliente per crittografare quei dati. Per consentire la creazione di una chiave AWS KMS per lo storage temporaneo di dati durante il processo di acquisizione della fonte di dati, allega una policy alle tue knowledge base per il ruolo di servizio Amazon Bedrock.
L'accesso privato può applicarsi a uno o entrambi i seguenti elementi: endpoint VPC OpenSearch gestiti senza server e servizi AWS supportati come Amazon Bedrock. Usa AWS PrivateLink per creare una connessione privata tra il tuo VPC e i servizi endpoint OpenSearch Serverless. Utilizza le regole delle policy di rete per specificare l'accesso ad Amazon Bedrock.
Monitora OpenSearch Serverless utilizzando Amazon CloudWatch, che raccoglie dati grezzi e li elabora in metriche leggibili quasi in tempo reale. OpenSearch Serverless è integrato con AWS CloudTrail, che acquisisce le chiamate API per OpenSearch Serverless come eventi. OpenSearch Il servizio si integra con Amazon EventBridge per informarti di determinati eventi che influiscono sui tuoi domini. I revisori di terze parti possono valutare la sicurezza e la conformità di OpenSearch Serverless come parte di più programmi di conformità AWS.
Amazon S3
Archivia le fonti di dati per la tua knowledge base in un bucket S3. Se hai crittografato le tue fonti di dati in Amazon S3 utilizzando una chiave AWS KMS personalizzata (consigliata), allega una policy al tuo ruolo di servizio della Knowledge Base. Usa la protezione da malware in Amazon S3
Amazon Comprehend
Amazon Comprehend utilizza l'elaborazione del linguaggio naturale (NLP) per estrarre informazioni dal contenuto dei documenti. Puoi usare Amazon Comprehend per rilevare e redigere le entità PII in documenti di testo in inglese o spagnolo. Integra Amazon Comprehend nella tua pipeline di inserimento dei dati
Amazon S3 consente di crittografare i documenti di input durante la creazione di analisi del testo, modellazione di argomenti o job Amazon Comprehend personalizzati. Amazon Comprehend si integra con AWS KMS per crittografare i dati nel volume di storage per i lavori Start* e Create* e crittografa i risultati di output dei job Start* utilizzando una chiave gestita dal cliente. Ti consigliamo di utilizzare le chiavi di contesto aws: SourceArn e aws: SourceAccount global condition nelle politiche delle risorse per limitare le autorizzazioni che Amazon Comprehend fornisce a un altro servizio alla risorsa. Usa AWS PrivateLink per creare una connessione privata tra il tuo VPC e i servizi endpoint Amazon Comprehend. Implementa politiche basate sull'identità per Amazon Comprehend con il principio del privilegio minimo. Amazon Comprehend è integrato con AWS CloudTrail, che acquisisce le chiamate API per Amazon Comprehend come eventi. I revisori di terze parti possono valutare la sicurezza e la conformità di Amazon Comprehend nell'ambito di più programmi di conformità AWS.
Amazon Macie
Macie può aiutarti a identificare i dati sensibili nelle tue knowledge base che vengono archiviati come fonti di dati, registri di invocazione dei modelli e archivio di prompt in bucket S3. Per le migliori pratiche di sicurezza di Macie, consulta la sezione Macie precedente di questa guida.
AWS KMS
Utilizza le chiavi gestite dai clienti per crittografare quanto segue: processi di inserimento dati per la tua knowledge base, il database vettoriale di Amazon OpenSearch Service, sessioni in cui generi risposte interrogando una knowledge base, log di invocazione dei modelli in Amazon S3 e il bucket S3 che ospita le fonti di dati.
Usa Amazon CloudWatch e Amazon CloudTrail come spiegato nella precedente sezione sull'inferenza del modello.
