Le traduzioni sono generate tramite traduzione automatica. In caso di conflitto tra il contenuto di una traduzione e la versione originale in Inglese, quest'ultima prevarrà.
Connessione alle origini dati
In Amazon SageMaker Canvas, puoi importare dati da una posizione esterna al tuo file system locale tramite un AWS servizio, una piattaforma SaaS o altri database utilizzando connettori JDBC. Ad esempio, magari vuoi importare tabelle da un data warehouse in Amazon Redshift o importare i dati di Google Analytics.
Quando esegui il flusso di lavoro di importazione per importare dati nell'applicazione Canvas, è possibile scegliere l'origine dei dati e selezionare i dati che desideri importare. Per alcune origine dati, come Snowflake e Amazon Redshift, devi specificare le tue credenziali e aggiungere una connessione all'origine dati.
Il seguente screenshot mostra la barra degli strumenti dell'origine dati nel flusso di lavoro di importazione, con tutte le origini dati disponibili evidenziate. È possibile importare dati solo dalle origini dati disponibili. Contatta l'amministratore se l'origine dati desiderata non è disponibile.

Le seguenti sezioni forniscono informazioni su come stabilire connessioni a origini dati esterne e importare dati da esse. Consulta innanzitutto la sezione seguente per determinare quali autorizzazioni sono necessarie per importare dati dalla tua origine dati.
Autorizzazioni
Esamina le seguenti informazioni per assicurarti di disporre delle autorizzazioni necessarie per importare dati dalla tua origine dati:
Amazon S3: è possibile importare dati da qualsiasi bucket Amazon S3, a condizione che l'utente disponga delle autorizzazioni di accesso al bucket. Per ulteriori informazioni sull'utilizzo di AWS IAM per controllare l'accesso ai bucket Amazon S3, consulta Gestione delle identità e degli accessi in Amazon S3 nella Amazon S3 User Guide.
Amazon Athena: se disponi della AmazonSageMakerFullAccesspolicy e della AmazonSageMakerCanvasFullAccesspolicy allegate al ruolo di esecuzione del tuo utente, puoi interrogarlo AWS Glue Data Catalog con Amazon Athena. Se fai parte di un gruppo di lavoro Athena, assicurati che l'utente Canvas disponga delle autorizzazioni per eseguire le query Athena sui dati. Per ulteriori informazioni, consulta la sezione Using workgroups for running queries nella Guida per l'utente di Amazon Athena.
Amazon DocumentDB: puoi importare dati da qualsiasi database Amazon DocumentDB purché disponga delle credenziali (nome utente e password) per la connessione al database e disponga delle autorizzazioni Canvas di base minime associate al ruolo di esecuzione dell'utente. Per ulteriori informazioni sulle autorizzazioni Canvas, consulta. Prerequisiti per la configurazione di Amazon Canvas SageMaker
Amazon Redshift: per concederti le autorizzazioni necessarie per importare dati da Amazon Redshift, consulta Grant Users Permissions to Import Amazon Redshift Data.
Amazon RDS: se hai la AmazonSageMakerCanvasFullAccesspolicy associata al ruolo di esecuzione del tuo utente, potrai accedere ai tuoi database Amazon RDS da Canvas.
Piattaforme SaaS: se disponi della AmazonSageMakerFullAccesspolicy e della AmazonSageMakerCanvasFullAccesspolicy allegate al ruolo di esecuzione dell'utente, disponi delle autorizzazioni necessarie per importare dati dalle piattaforme SaaS. Per ulteriori informazioni sulla connessione a un connettore SaaS specifico, consulta Usa connettori SaaS con Canvas.
Connettori JDBC: per le fonti di database come Databricks, MySQL o MariaDB, devi abilitare l'autenticazione di nome utente e password sul database di origine prima di tentare la connessione da Canvas. Se ti connetti a un database Databricks, devi disporre dell'URL JDBC che contiene le credenziali necessarie.
Connect a un database archiviato in AWS
Potresti voler importare i dati che hai archiviato in AWS. Puoi importare dati da Amazon S3, utilizzare Amazon Athena per interrogare un database in AWS Glue Data Catalog, importare dati da Amazon RDS o stabilire una connessione a un database Amazon Redshift fornito (non Redshift Serverless).
È possibile creare più connessioni a Amazon Redshift. Per Amazon Athena, è possibile accedere a qualsiasi database che hai nel tuo AWS Glue Data Catalog. Per Amazon S3, è possibile importare dati da un bucket purché si disponga delle autorizzazioni necessarie.
Consulta le sezioni seguenti per informazioni dettagliate.
Connessione ai dati in Amazon S3, Amazon Athena o Amazon RDS
Amazon S3: è possibile importare dati da qualsiasi bucket Amazon S3, a condizione che l'utente disponga delle autorizzazioni di accesso al bucket.
Per Amazon RDS, se hai la AmazonSageMakerCanvasFullAccesspolicy associata al tuo ruolo utente, potrai importare dati dai tuoi database Amazon RDS in Canvas.
Per importare dati da un bucket Amazon S3 o eseguire query e importare tabelle di dati con Amazon Athena, consulta Creazione di un set di dati. È possibile importare solo dati tabulari da Amazon Athena e importare dati tabulari e di immagini da Amazon S3.
Connect a un database Amazon DocumentDB
Amazon DocumentDB è un servizio di database di documenti completamente gestito e senza server. Puoi importare dati di documenti non strutturati archiviati in un database Amazon DocumentDB SageMaker in Canvas come set di dati tabulare e quindi creare modelli di apprendimento automatico con i dati.
Importante
Il tuo dominio SageMaker AI deve essere configurato in modalità solo VPC per aggiungere connessioni ad Amazon DocumentDB. Puoi accedere ai cluster Amazon DocumentDB solo nello stesso Amazon VPC dell'applicazione Canvas. Inoltre, Canvas può connettersi solo a cluster Amazon DocumentDB abilitati per TLS. Per ulteriori informazioni su come configurare Canvas in modalità solo VPC, consulta. Configura Amazon SageMaker Canvas in un VPC senza accesso a Internet
Per importare dati dai database Amazon DocumentDB, è necessario disporre delle credenziali per accedere al database Amazon DocumentDB e specificare nome utente e password durante la creazione di una connessione al database. Puoi configurare autorizzazioni più granulari e limitare l'accesso modificando le autorizzazioni utente di Amazon DocumentDB. Per ulteriori informazioni sul controllo degli accessi in Amazon DocumentDB, consulta Database Access Using Role-Based Access Control nella Amazon DocumentDB Developer Guide.
Quando importi da Amazon DocumentDB, Canvas converte i dati non strutturati in un set di dati tabulare mappando i campi alle colonne di una tabella. Vengono create tabelle aggiuntive per ogni campo complesso (o struttura annidata) nei dati, in cui le colonne corrispondono ai sottocampi del campo complesso. Per informazioni più dettagliate su questo processo ed esempi di conversione dello schema, consulta la pagina Amazon DocumentDB JDBC Driver
Canvas può stabilire una connessione solo a un singolo database in Amazon DocumentDB. Per importare dati da un database diverso, devi creare una nuova connessione.
Puoi importare dati da Amazon DocumentDB in Canvas utilizzando i seguenti metodi:
-
Creazione di un set di dati. Puoi importare i dati di Amazon DocumentDB e creare un set di dati tabulare in Canvas. Se scegli questo metodo, assicurati di seguire la procedura di importazione dei dati tabulari.
-
Crea un flusso di dati. Puoi creare una pipeline di preparazione dei dati in Canvas e aggiungere il tuo database Amazon DocumentDB come origine dati.
Per procedere con l'importazione dei dati, segui la procedura per uno dei metodi collegati nell'elenco precedente.
Quando raggiungi il passaggio di scelta di un'origine dati in uno dei due flussi di lavoro (passaggio 6 per la creazione di un set di dati o passaggio 8 per la creazione di un flusso di dati), procedi come segue:
Per Data Source, apri il menu a discesa e scegli DocumentDB.
Scegli Aggiungi connessione.
-
Nella finestra di dialogo, specifica le tue credenziali Amazon DocumentDB:
Inserisci un Nome della connessione. Si tratta di un nome usato da Canvas per identificare questa connessione.
Per Cluster, seleziona il cluster in Amazon DocumentDB che memorizza i tuoi dati. Canvas compila automaticamente il menu a discesa con i cluster Amazon DocumentDB nello stesso VPC dell'applicazione Canvas.
Inserisci il nome utente per il tuo cluster Amazon DocumentDB.
Inserisci la password per il tuo cluster Amazon DocumentDB.
Inserisci il nome del database a cui desideri connetterti.
-
L'opzione di preferenza Read determina da quali tipi di istanze del cluster Canvas legge i dati. Selezionare uno dei seguenti:
Preferito secondario: per impostazione predefinita, Canvas legge dalle istanze secondarie del cluster, ma se un'istanza secondaria non è disponibile, Canvas legge da un'istanza principale.
Secondario: Canvas legge solo dalle istanze secondarie del cluster, il che impedisce alle operazioni di lettura di interferire con le normali operazioni di lettura e scrittura del cluster.
-
Scegli Aggiungi connessione. L'immagine seguente mostra la finestra di dialogo con i campi precedenti per una connessione Amazon DocumentDB.
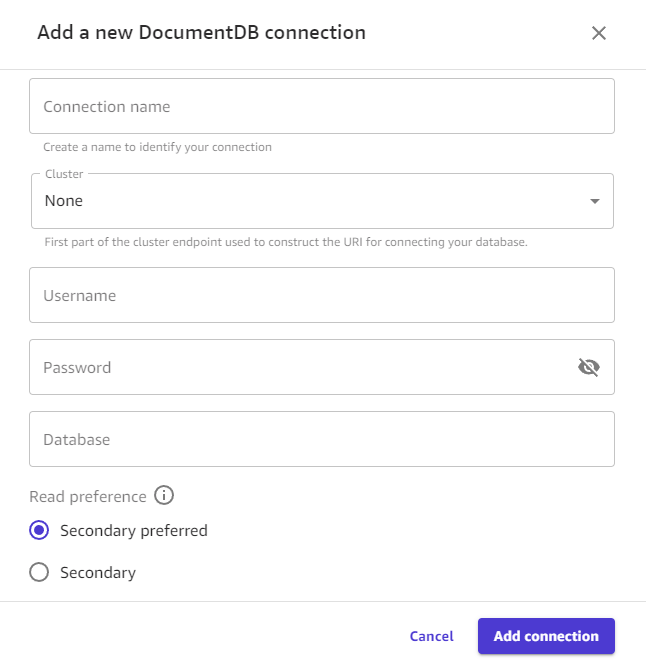
Ora dovresti disporre di una connessione Amazon DocumentDB e puoi utilizzare i dati di Amazon DocumentDB in Canvas per creare un set di dati o un flusso di dati.
Connessione a un database Amazon Redshift
È possibile importare dati da Amazon Redshift, un data warehouse in cui la tua organizzazione conserva i propri dati. Prima di poter importare dati da Amazon Redshift, al ruolo AWS IAM utilizzato deve essere associata la policy AmazonRedshiftFullAccess gestita. Per istruzioni su come collegare la policy, consulta Concedere agli utenti le autorizzazioni per importare dati Amazon Redshift.
Per importare dati da Amazon Redshift, effettua le seguenti operazioni:
-
Crea una connessione a un database Amazon Redshift.
-
Scegli i dati che stai importando.
-
Importa i dati.
Puoi utilizzare l'editor di Amazon Redshift per trascinare i set di dati nel riquadro di importazione e importarli in Canvas. SageMaker Per un maggiore controllo sui valori restituiti nel set di dati, è possibile utilizzare quanto segue:
-
Query SQL
-
Join
Con le query SQL, puoi personalizzare il modo in cui importi i valori nel set di dati. Ad esempio, è possibile specificare le colonne restituite nel set di dati o l'intervallo di valori per una colonna.
È possibile utilizzare join per combinare più set di dati di Amazon Redshift in un set di dati singolo. È possibile trascinare i tuoi set di dati da Amazon Redshift nel pannello che ti dà la possibilità di collegare i set di dati.
È possibile utilizzare l'editor SQL per modificare il set di dati che hai collegato e convertire il set di dati collegati in un nodo singolo. È possibile collegare un altro set di dati al nodo. Puoi importare i dati che hai selezionato in SageMaker Canvas.
Utilizza la procedura seguente per importare dati da Amazon Redshift.
Nell'applicazione SageMaker Canvas, vai alla pagina Datasets.
Scegli Importa dati e dal menu a discesa scegli Tabulare.
-
Inserisci un nome per il set di dati, quindi scegli Crea.
Per Origine dati, apri il menu a discesa e scegli Redshift.
-
Scegli Aggiungi connessione.
-
Nella finestra di dialogo, specifica le credenziali Amazon Redshift:
-
Per Metodo di autenticazione, scegli IAM.
-
Inserisci l'identificatore del cluster per specificare a quale cluster vuoi collegarti. Inserisci solo l'identificatore del cluster e non l'endpoint completo del cluster Amazon Redshift.
-
Inserisci il Nome del database a cui desideri collegarti.
-
Inserisci un utente del database per identificare l'utente che desideri utilizzare per collegarti al database.
-
Per ARN, inserisci l'ARN del ruolo IAM che il cluster Amazon Redshift dovrebbe assumere per spostare e scrivere dati su Amazon S3. Per ulteriori informazioni su questo ruolo, consulta Autorizzazione di Amazon Redshift ad accedere ad AWS altri servizi per tuo conto nella Amazon Redshift Management Guide.
-
Inserisci un Nome della connessione. Si tratta di un nome usato da Canvas per identificare questa connessione.
-
-
Dalla scheda contenente il nome della connessione, trascina il file .csv che stai importando nel pannello Trascina e rilascia la tabella da importare.
-
Facoltativo: trascina le tabelle aggiuntive nel pannello di importazione. È possibile utilizzare la GUI per collegare le tabelle. Per una maggiore specificità nei tuoi join, scegli Modifica in SQL.
-
Facoltativo: se utilizzi SQL per interrogare i dati, è possibile scegliere Contesto per aggiungere contesto alla connessione specificando i valori per quanto segue:
-
Warehouse
-
Database
-
Schema
-
-
Scegli Importa dati.
L'immagine seguente mostra un esempio di campi specificati per una connessione Amazon Redshift.

L'immagine seguente mostra la pagina utilizzata per combinare set di dati in Amazon Redshift.
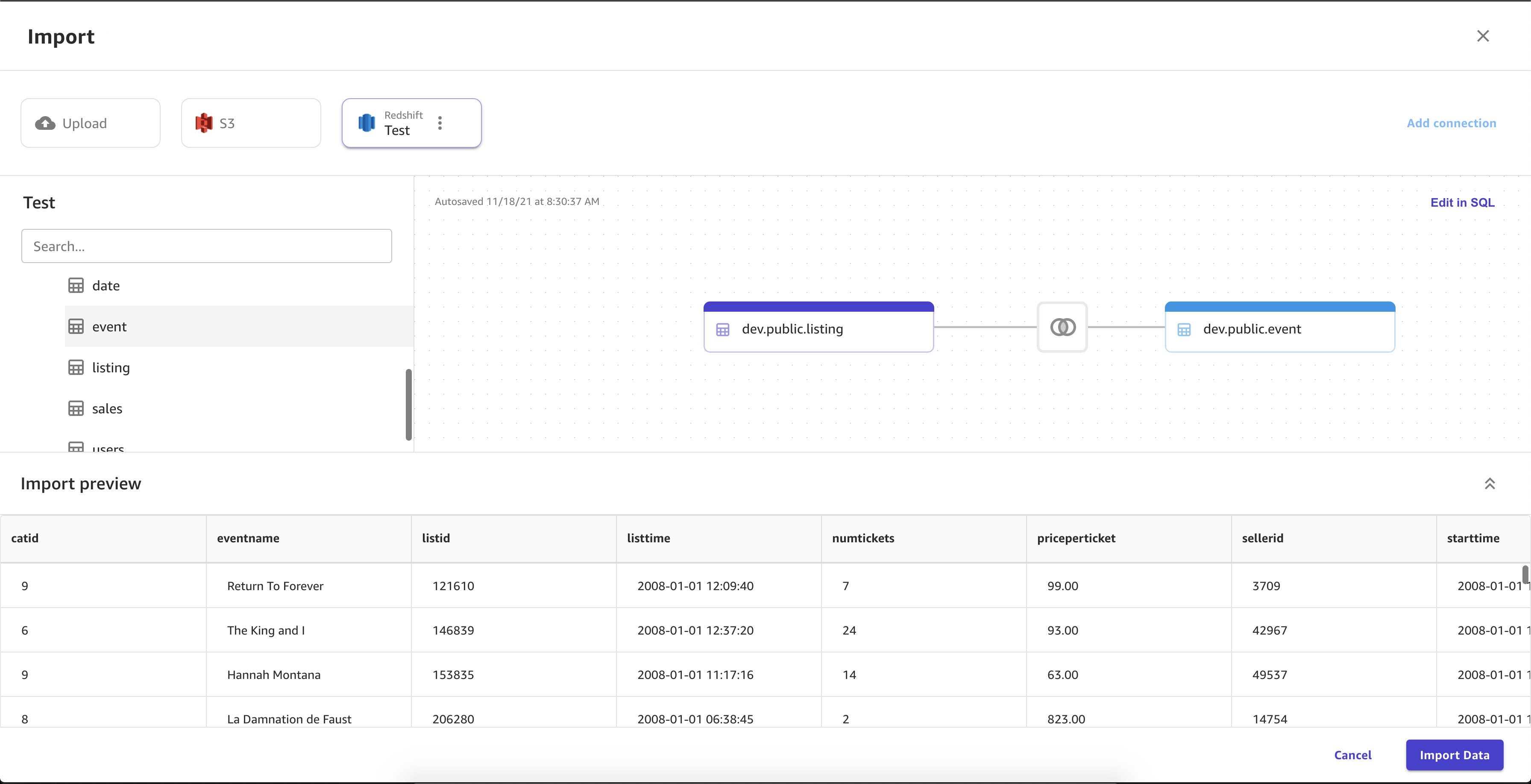
L'immagine seguente mostra una query SQL utilizzata per modificare un join in Amazon Redshift.

Connettiti ai tuoi dati con connettori JDBC
Con JDBC, puoi connetterti ai tuoi database da fonti come Databricks, MySQL, SQLServer PostgreSQL, MariaDB, Amazon RDS e Amazon Aurora.
Devi assicurarti di avere le credenziali e le autorizzazioni necessarie per creare la connessione da Canvas.
Per Databricks, devi fornire un URL JDBC. La formattazione dell'URL può variare tra le istanze di Databricks. Per informazioni su come trovare l'URL e specificare i parametri al suo interno, consulta JDBC configuration and connection parameters
nella documentazione di Databricks. Di seguito è riportato un esempio di formato dell'URL: jdbc:spark://aws-sagemaker-datawrangler.cloud.databricks.com:443/default;transportMode=http;ssl=1;httpPath=sql/protocolv1/o/3122619508517275/0909-200301-cut318;AuthMech=3;UID=token;PWD=personal-access-tokenPer altre origini di database, devi impostare l'autenticazione con nome utente e password, quindi specificare tali credenziali quando ci si connette al database da Canvas.
Inoltre, l'origine dati deve essere accessibile tramite la rete Internet pubblica oppure, se l'applicazione Canvas è in esecuzione solo in modalità VPC, l'origine dati deve essere eseguita nello stesso VPC. Per ulteriori informazioni sulla configurazione di un database Amazon RDS in un VPC, consulta Amazon VPC VPCs e Amazon RDS nella Amazon RDS User Guide.
Dopo aver configurato le credenziali dell'origine dati, è possibile accedere all'applicazione Canvas e creare una connessione all'origine dati. Specifica le tue credenziali (o, per Databricks, l'URL) durante la creazione della connessione.
Connect a fonti di dati con OAuth
Canvas supporta l'utilizzo OAuth come metodo di autenticazione per la connessione ai dati in Snowflake e Salesforce Data Cloud. OAuth
Nota
È possibile stabilire una sola OAuth connessione per ogni fonte di dati.
Per autorizzare la connessione, è necessario seguire la configurazione iniziale descritta in Configura le connessioni alle sorgenti dati con OAuth.
Dopo aver impostato le OAuth credenziali, puoi effettuare le seguenti operazioni per aggiungere una connessione Snowflake o Salesforce Data Cloud con: OAuth
Accedi all'applicazione Canvas.
Crea un set di dati tabulare. Quando ti viene richiesto di caricare dati, scegli il cloud dei dati Snowflake o Salesforce come origine dati.
Crea una nuova connessione alla tua origine dati nel cloud dei dati Snowflake o Salesforce. Specificate OAuth come metodo di autenticazione e inserite i dettagli della connessione.
Ora dovresti essere in grado di importare dati dai tuoi database nel cloud dei dati Snowflake o Salesforce.
Connessione a una piattaforma SaaS
È possibile importare dati da Snowflake e oltre 40 altre piattaforme SaaS esterne. Per l'elenco completo dei connettori, consulta la tabella su Importazione di dati.
Nota
È possibile importare solo dati tabulari, come tabelle di dati, da piattaforme SaaS.
Utilizzo di Snowflake con Canvas
Snowflake è un servizio di archiviazione e analisi dei dati e puoi importare i tuoi dati da Snowflake in Canvas. SageMaker Per ulteriori informazioni su Snowflake, consulta la documentazione di Snowflake
È possibile importare i dati dal tuo account Snowflake eseguendo le seguenti operazioni:
-
Crea una connessione al database Snowflake.
-
Scegli i dati da importare trascinando la tabella dal menu di navigazione a sinistra all'editor.
-
Importa i dati.
Puoi utilizzare l'editor Snowflake per trascinare i set di dati nel riquadro di importazione e importarli in Canvas. SageMaker Per un maggiore controllo sui valori restituiti nel set di dati, è possibile utilizzare quanto segue:
-
Query SQL
-
Join
Con le query SQL, puoi personalizzare il modo in cui importi i valori nel set di dati. Ad esempio, è possibile specificare le colonne restituite nel set di dati o l'intervallo di valori per una colonna.
È possibile combinare più set di dati Snowflake in un singolo set di dati prima di importarli in Canvas utilizzando SQL o l'interfaccia Canvas. È possibile trascinare i tuoi set di dati da Snowflake nel pannello che ti dà la possibilità di collegare i set di dati, oppure puoi modificare i join in SQL e convertire l'SQL in un nodo singolo. È possibile unire altri nodi al nodo che hai convertito. Ora è possibile combinare i set di dati che hai collegato in un nodo singolo e collegare i nodi a un set di dati Snowflake diverso. Infine, è possibile importare i dati che hai selezionato in Canvas.
Utilizza la seguente procedura per importare dati da Snowflake ad Amazon SageMaker Canvas.
Nell'applicazione SageMaker Canvas, vai alla pagina Datasets.
Scegli Importa dati e dal menu a discesa scegli Tabulare.
-
Inserisci un nome per il set di dati, quindi scegli Crea.
Per Origine dati, apri il menu a discesa e scegli Snowflake.
-
Scegli Aggiungi connessione.
-
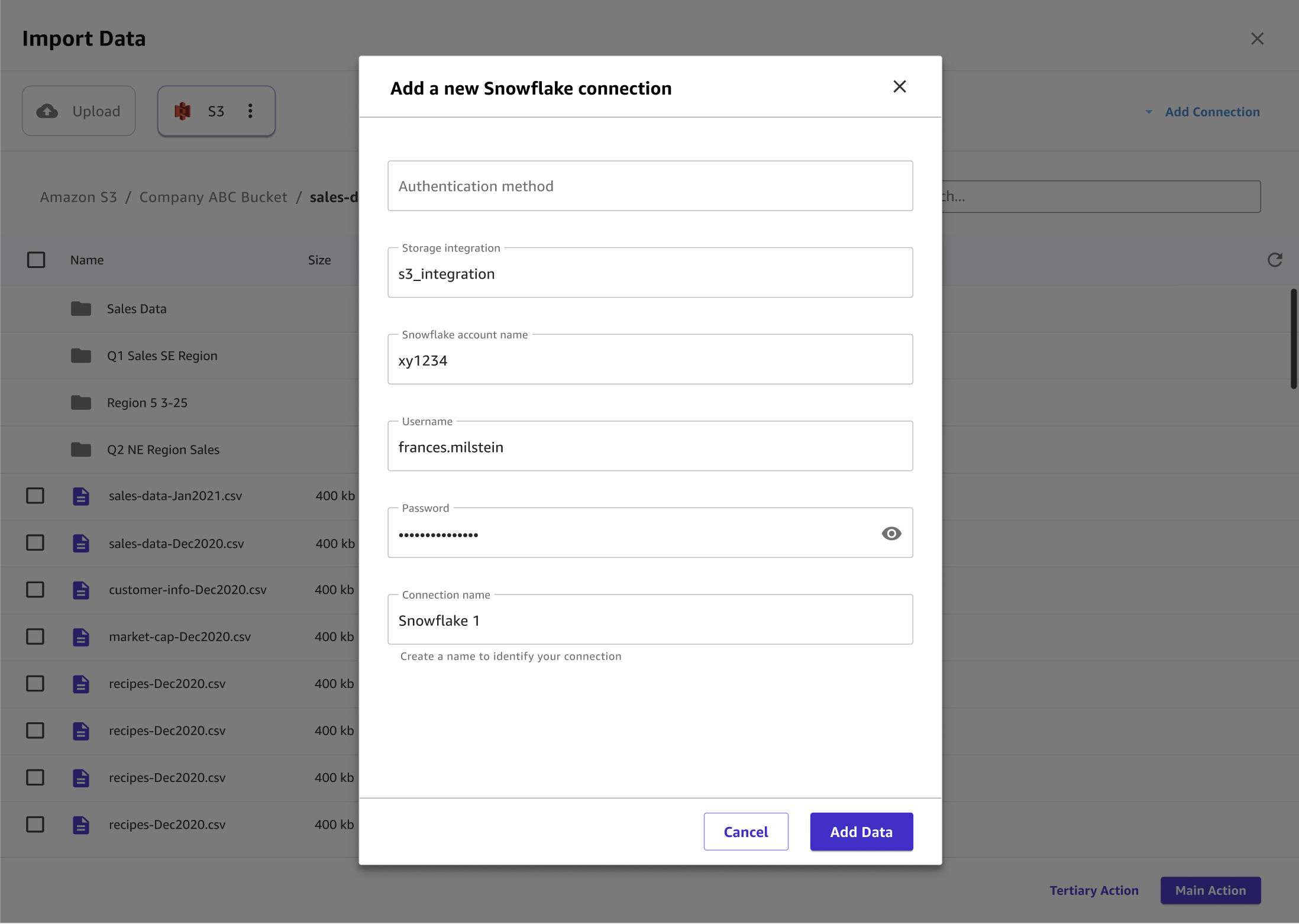
Nella finestra di dialogo Aggiungi una nuova connessione Snowflake, specifica le tue credenziali Snowflake. Per il metodo di autenticazione, scegli una delle seguenti opzioni:
Basic: nome utente e password: fornisci l'ID, il nome utente e la password del tuo account Snowflake.
-
ARN: per una migliore protezione delle tue credenziali Snowflake, fornisci l'ARN di un segreto che contiene le tue credenziali. AWS Secrets Manager Per ulteriori informazioni, consulta Creare un AWS Secrets Manager segreto nella Guida per l'utente.AWS Secrets Manager
Le credenziali Snowflake del tuo segreto devono essere archiviate nel seguente formato JSON:
{"accountid": "ID", "username": "username", "password": "password"} OAuth— OAuth consente l'autenticazione senza fornire una password ma richiede una configurazione aggiuntiva. Per ulteriori informazioni sulla configurazione delle OAuth credenziali per Snowflake, consulta. Configura le connessioni alle sorgenti dati con OAuth
-
Scegli Aggiungi connessione.
-
Dalla scheda contenente il nome della connessione, trascina il file .csv che stai importando nel pannello Trascina e rilascia la tabella da importare.
-
Facoltativo: trascina le tabelle aggiuntive nel pannello di importazione. È possibile utilizzare l'interfaccia utente per collegare le tabelle. Per una maggiore specificità nei tuoi join, scegli Modifica in SQL.
-
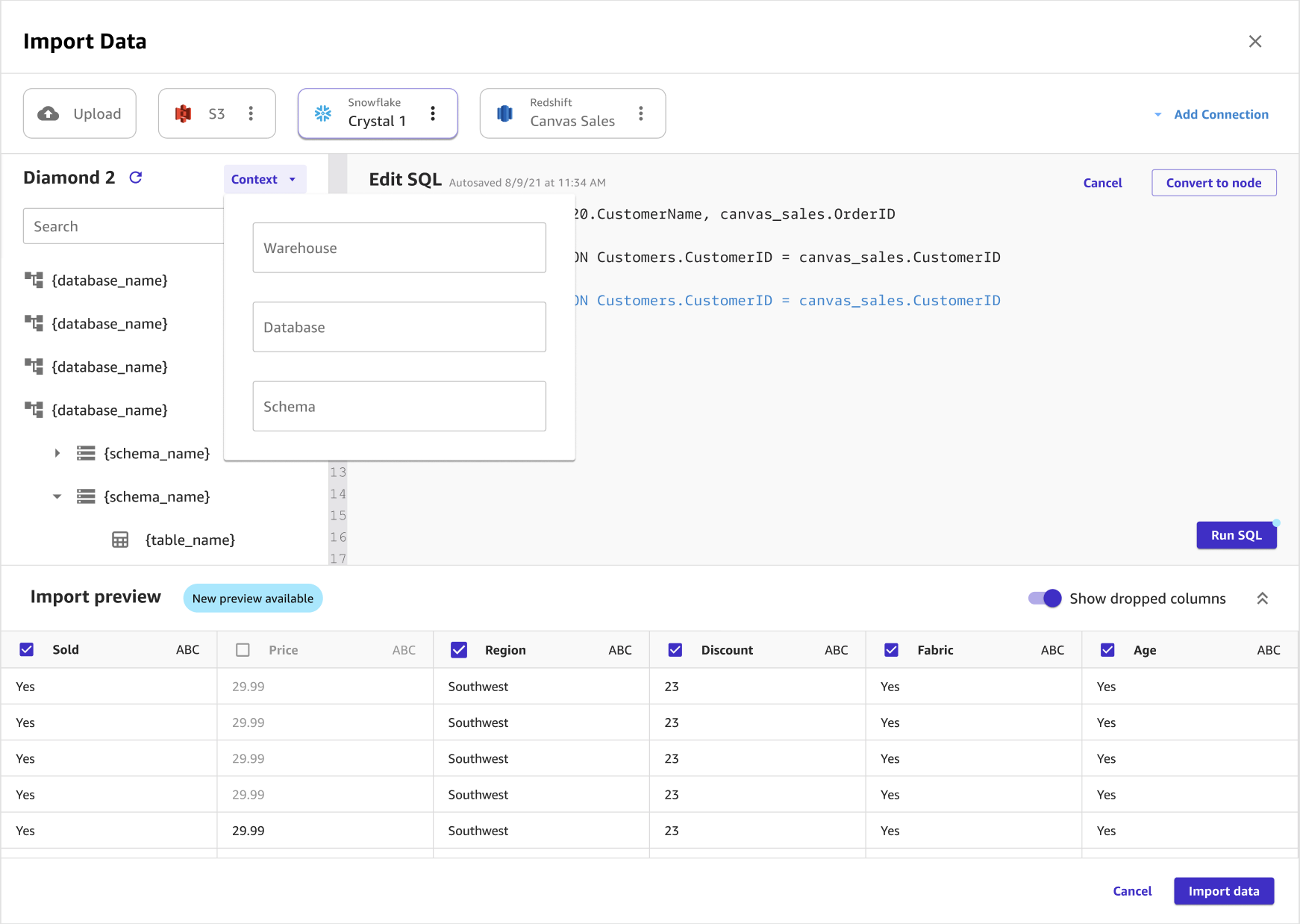
Facoltativo: se utilizzi SQL per interrogare i dati, è possibile scegliere Contesto per aggiungere contesto alla connessione specificando i valori per quanto segue:
-
Warehouse
-
Database
-
Schema
L'aggiunta di contesto a una connessione semplifica la specificazione di query future.
-
-
Scegli Importa dati.
L'immagine seguente mostra un esempio di campi specificati per una connessione Snowflake.
L'immagine seguente mostra la pagina utilizzata per aggiungere contesto a una connessione.
L'immagine seguente mostra la pagina utilizzata per combinare set di dati in Snowflake.
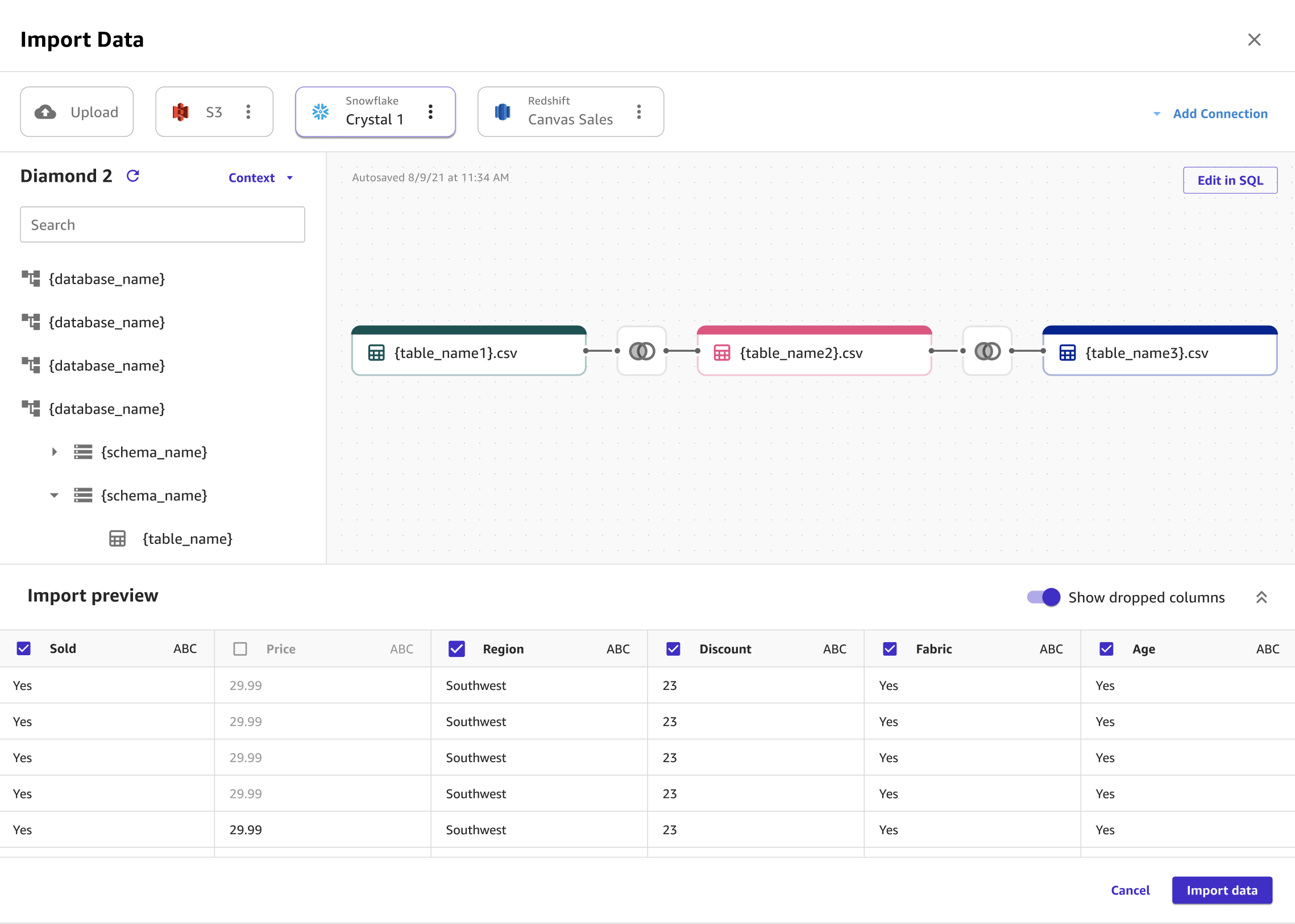
L'immagine seguente mostra una query SQL utilizzata per modificare un join in Snowflake.

Usa connettori SaaS con Canvas
Nota
Per le piattaforme SaaS oltre a Snowflake, è possibile avere solo una connessione per origine dati.
Prima di poter importare dati da una piattaforma SaaS, l'amministratore deve autenticarsi e creare una connessione all'origine dati. Per ulteriori informazioni su come gli amministratori possono creare una connessione con una piattaforma SaaS, consulta Managing Amazon connections nella AppFlow AppFlow Amazon User Guide.
Se sei un amministratore che inizia a usare Amazon AppFlow per la prima volta, consulta la sezione Guida introduttiva nella Amazon AppFlow User Guide.
Per importare dati da una piattaforma SaaS, è possibile seguire la procedure Importazione dei dati tabulari standard, che mostra come importare set di dati tabulari in Canvas.
