Le traduzioni sono generate tramite traduzione automatica. In caso di conflitto tra il contenuto di una traduzione e la versione originale in Inglese, quest'ultima prevarrà.
Esporta
Nel flusso di Data Wrangler, puoi esportare alcune o tutte le trasformazioni che hai apportato alle tue pipeline di elaborazione dati.
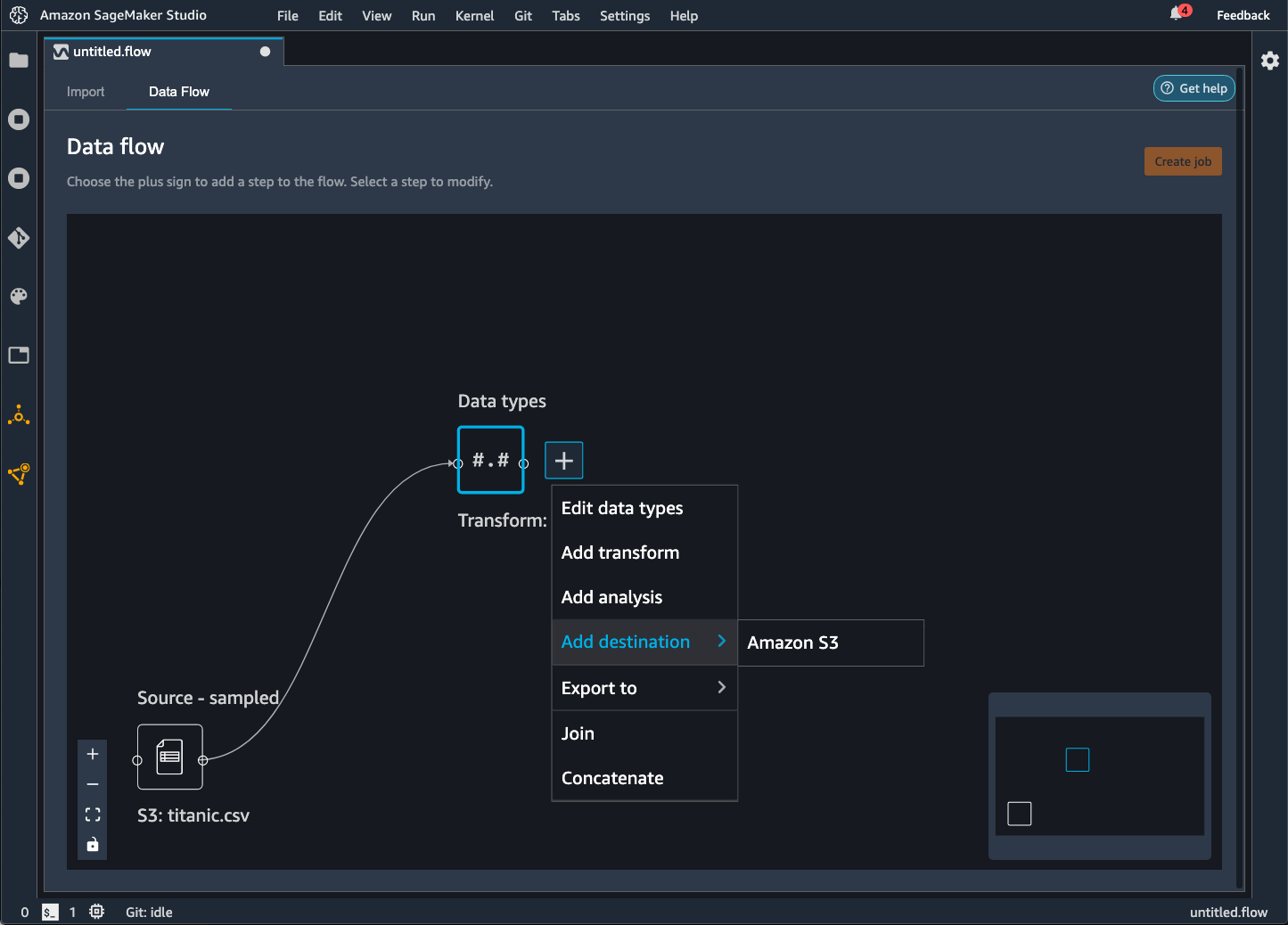
Un flusso di Data Wrangler è la serie di fasi di preparazione dei dati che hai eseguito sui dati. Nella preparazione dei dati, esegui una o più trasformazioni dei dati. Ogni trasformazione viene eseguita utilizzando una fase di trasformazione. Il flusso ha una serie di nodi che rappresentano l'importazione dei dati e le trasformazioni che hai eseguito. Per un esempio di nodi, vedere la seguente immagine.
L'immagine precedente mostra un flusso di Data Wrangler con due nodi. Il nodo Source - sampled (Origine - campionato) mostra l'origine dati da cui hai importato i dati. Il nodo Data types (Tipi di dati) indica che Data Wrangler ha eseguito una trasformazione per convertire il set di dati in un formato utilizzabile.
Ogni trasformazione che aggiungi al flusso di Data Wrangler viene visualizzata come un nodo aggiuntivo. Per ulteriori informazioni sulle trasformazioni che è possibile aggiungere, consulta Trasformazione dei dati. L'immagine seguente mostra un flusso di Data Wrangler con un nodo Rename-column (Rinomina colonna) per modificare il nome di una colonna in un set di dati.
Puoi esportare le trasformazioni dei dati nei seguenti modi:
Ti consigliamo di utilizzare la policy AmazonSageMakerFullAccess gestita da IAM per concedere l' AWS autorizzazione all'uso di Data Wrangler. Se non utilizzi la policy gestita, puoi utilizzare una policy IAM che fornisce a Data Wrangler l'accesso a un bucket Amazon S3. Per ulteriori informazioni sulla policy, consulta Sicurezza e autorizzazioni.
Quando esporti il flusso di dati, ti vengono addebitate le AWS risorse che utilizzi. Puoi utilizzare i tag di allocazione dei costi per organizzare e gestire i costi di tali risorse. Quando crei questi tag per il tuo profilo utente Data Wrangler li applica automaticamente alle risorse utilizzate per esportare il flusso di dati. Per ulteriori informazioni, consulta Utilizzo dei tag per l'allocazione dei costi.
Esportazione in Amazon S3
Data Wrangler ti offre la possibilità di esportare i dati in una posizione all'interno di un bucket Amazon S3. È possibile specificare la posizione utilizzando uno dei seguenti metodi:
-
Destination node (Nodo di destinazione): dove Data Wrangler archivia i dati dopo averli elaborati.
-
Export to (Esporta in): esporta i dati risultanti da una trasformazione in Amazon S3.
-
Export data (Esporta dati): per set di dati di piccole dimensioni, puoi esportare rapidamente i dati che hai trasformato.
Per ulteriori informazioni su ciascuno di questi metodi utilizza le seguenti sezioni.
- Destination Node
-
Se desideri inviare una serie di fasi di elaborazione dati che hai eseguito su Amazon S3, crea un nodo di destinazione. Un nodo di destinazione indica a Data Wrangler dove archiviare i dati dopo averli elaborati. Dopo aver creato un nodo di destinazione, crea un processo di elaborazione per l'output dei dati. Un processo di elaborazione è un processo di SageMaker elaborazione di Amazon. Quando utilizzi un nodo di destinazione, questo esegue le risorse di calcolo necessarie per generare i dati che hai trasformato in Amazon S3.
Puoi utilizzare un nodo di destinazione per esportare alcune delle trasformazioni o tutte le trasformazioni che hai apportato nel flusso di Data Wrangler.
Puoi utilizzare più nodi di destinazione per esportare diverse trasformazioni o set di trasformazioni. L'esempio seguente mostra due nodi di destinazione in un singolo flusso di Data Wrangler.
Puoi utilizzare la procedura seguente per creare nodi di destinazione ed esportarli in un bucket Amazon S3.
Per esportare il flusso di dati, crea nodi di destinazione e un processo Data Wrangler per esportare i dati. La creazione di un processo Data Wrangler avvia un processo di SageMaker elaborazione per esportare il flusso. È possibile scegliere i nodi di destinazione che si desidera esportare dopo averli creati.
Puoi selezionare Crea processo nel flusso di Data Wrangler per visualizzare le istruzioni per utilizzare un processo di elaborazione.
per creare i nodi di destinazione, utilizza la procedura seguente.
-
Seleziona il segno + accanto ai nodi che rappresentano le trasformazioni che desideri esportare.
-
Seleziona Aggiungi destinazione.
-
Seleziona Amazon S3.
-
Specifica i seguenti campi.
-
Nome del set di dati: il nome specificato per il set di dati che stai esportando.
-
Tipo di file: il formato del file che stai esportando.
-
Delimitatore (solo file CSV e Parquet): il valore utilizzato per separare altri valori.
-
Compressione (solo file CSV e Parquet): il metodo di compressione utilizzato per ridurre le dimensioni del file. È possibile utilizzare i seguenti metodi di compressione:
-
(Facoltativo) Posizione Amazon S3: la posizione S3 che stai utilizzando per l'output dei file.
-
(Facoltativo) Numero di partizioni: il numero di set di dati che stai scrivendo come output del processo di elaborazione.
-
(Facoltativo) Partizione per colonna: scrive tutti i dati con lo stesso valore univoco della colonna.
-
(Facoltativo) Parametri di inferenza: la selezione di Genera artefatto di inferenza applica tutte le trasformazioni utilizzate nel flusso di Data Wrangler ai dati che entrano nella pipeline di inferenza. Il modello della pipeline effettua previsioni sui dati trasformati.
-
Seleziona Aggiungi destinazione.
Per creare un processo di elaborazione, utilizza la procedura seguente.
Crea un processo dalla pagina Flusso di dati e seleziona i nodi di destinazione che desideri esportare.
Puoi selezionare Crea processo nel flusso di Data Wrangler per visualizzare le istruzioni per la creazione di un processo di elaborazione.
-
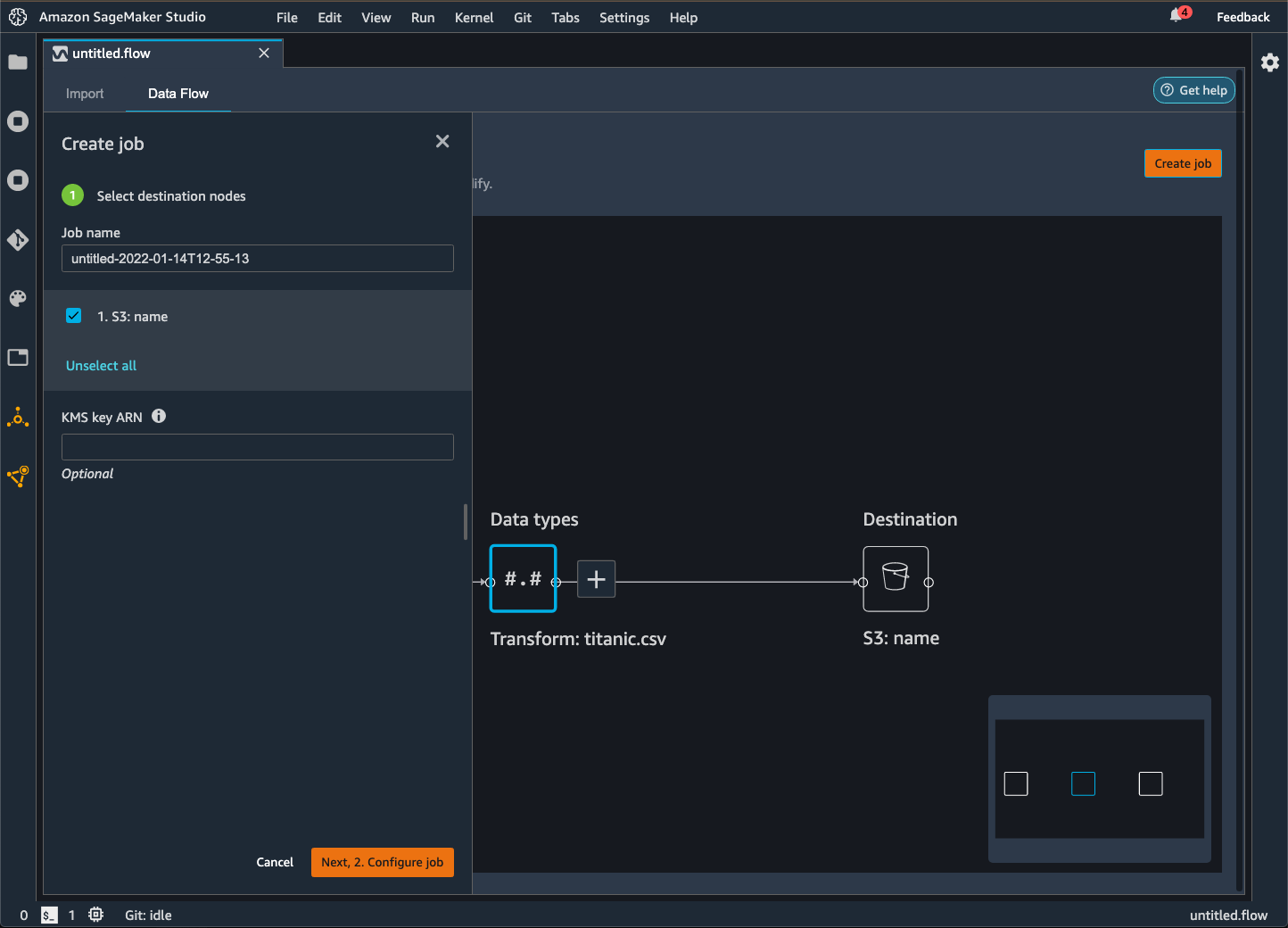
Scegli Crea processo. L'immagine seguente mostra il riquadro che appare dopo aver selezionato Crea processo.
-
Per Nome del processo, specifica il nome del processo di esportazione.
-
Seleziona i nodi di destinazione da esportare.
-
(Facoltativo) Specificate un AWS KMS ARN per la chiave. Una AWS KMS chiave è una chiave crittografica che puoi usare per proteggere i tuoi dati. Per ulteriori informazioni sulle AWS KMS chiavi, vedere AWS Key Management Service.
-
(Facoltativo) In Parametri addestrati, seleziona Riadatta se hai fatto quanto segue:
Per ulteriori informazioni sull'adattamento delle trasformazioni che hai apportato a un intero set di dati, consulta Adatta le trasformazioni all'intero set di dati ed esportarle.
Per quanto riguarda i dati delle immagini, Data Wrangler esporta le trasformazioni che hai apportato a tutte le immagini. L'adattamento delle trasformazioni non è applicabile al tuo caso d'uso.
-
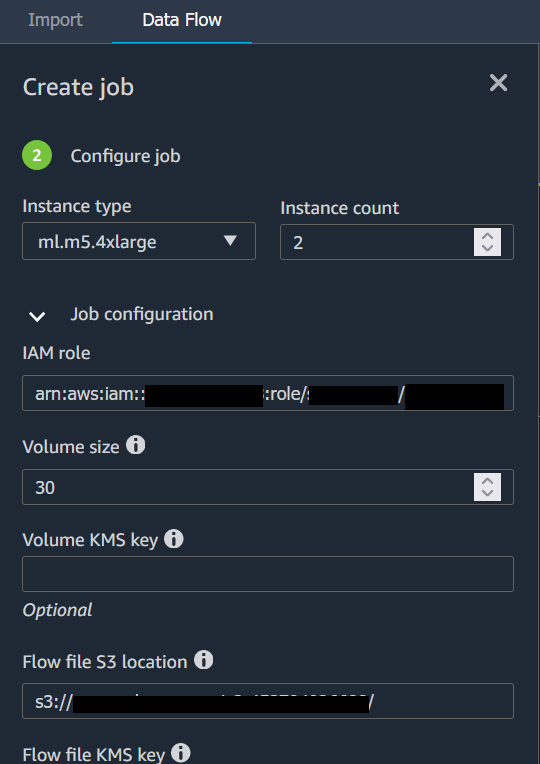
Seleziona Configura processo. L'immagine seguente mostra la pagina Configura processo.
-
(Facoltativo) Configura il processo Data Wrangler. È possibile utilizzare le seguenti configurazioni:
-
Configurazione dei processi
-
Configurazione della memoria Spark
-
Configurazione della rete
-
Tag
-
Parametri
-
Associa pianificazioni
-
Seleziona Esegui.
- Export to
-
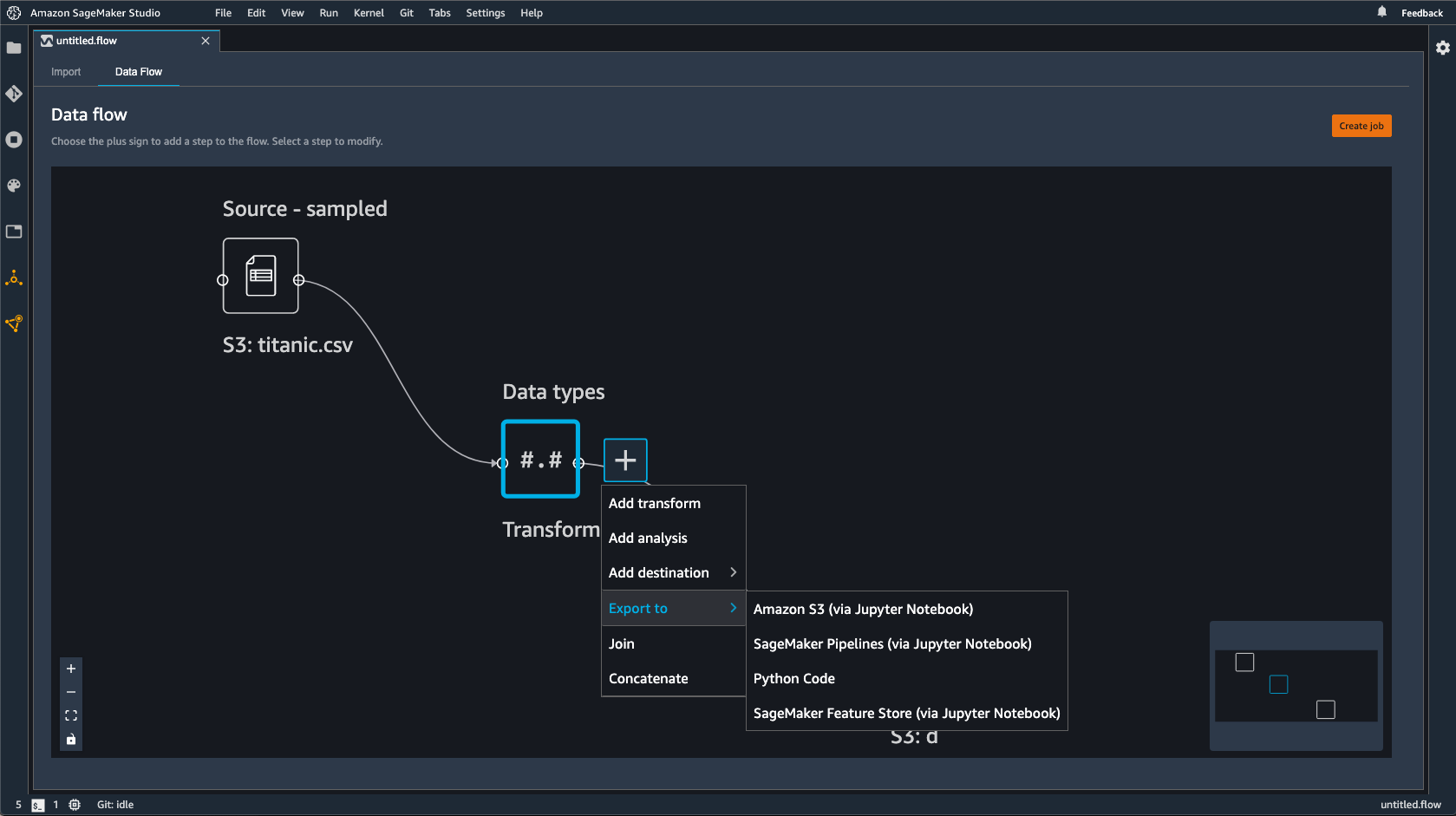
In alternativa all'utilizzo di un nodo di destinazione, puoi utilizzare l'opzione Esporta in per esportare il flusso di Data Wrangler su Amazon S3 utilizzando un notebook Jupyter. Puoi scegliere qualsiasi nodo di dati nel flusso di Data Wrangler ed esportarlo. L'esportazione del nodo di dati esporta la trasformazione che il nodo rappresenta e le trasformazioni che la precedono.
Utilizza la seguente procedura per generare un notebook Jupyter ed eseguirlo per esportare il flusso di Data Wrangler in Amazon S3.
-
Seleziona la + accanto al nodo che desideri esportare.
-
Seleziona Export to.
-
Seleziona Amazon S3 (tramite notebook Jupyter).
-
Esegui il notebook Jupyter
Quando si esegue il notebook, il notebook esporta il flusso di dati (file.flow) nello stesso Regione AWS modo in cui viene esportato il flusso Data Wrangler.
Il notebook offre opzioni che è possibile utilizzare per configurare il processo di elaborazione e i dati che emette.
Ti forniamo configurazioni di processo per configurare l'output dei tuoi dati. Per quanto riguarda le opzioni di partizionamento e memoria dei driver, si consiglia vivamente di non specificare una configurazione a meno che non si sia già a conoscenza di esse.
In Configurazione dei processi, puoi configurare quanto segue:
-
output_content_type – Il tipo di contenuto del file di output. Viene utilizzato CSV come formato predefinito, ma è possibile specificare Parquet.
-
delimiter— Il carattere utilizzato per separare i valori nel set di dati durante la scrittura su un file CSV.
-
compression – Se impostato, comprime il file di output. Usa GZIP per impostazione predefinita.
-
num_partitions – Il numero di partizioni o file che Data Wrangler scrive come output.
-
partition_by – I nomi delle colonne utilizzate per partizionare l'output.
Per modificare il formato del file di output da CSV a Parquet, modifica il valore da "CSV" a "Parquet" Per gli altri campi precedenti, decommenta le righe contenenti i campi che desideri specificare.
In (Facoltativo) Configura la memoria del driver del cluster Spark puoi configurare le proprietà Spark per il processo, come la memoria del driver Spark, nel dizionario config.
Di seguito viene illustrato il dizionario config.
config = json.dumps({
"Classification": "spark-defaults",
"Properties": {
"spark.driver.memory": f"{driver_memory_in_mb}m",
}
})
Per applicare la configurazione al processo di elaborazione, decommenta le seguenti righe:
# data_sources.append(ProcessingInput(
# source=config_s3_uri,
# destination="/opt/ml/processing/input/conf",
# input_name="spark-config",
# s3_data_type="S3Prefix",
# s3_input_mode="File",
# s3_data_distribution_type="FullyReplicated"
# ))
- Export data
-
Se hai una trasformazione su un piccolo set di dati che desideri esportare rapidamente, puoi utilizzare il metodo Export data (Esporta dati). Quando inizi a selezionare Esporta dati, Data Wrangler lavora in modo sincrono per esportare i dati che hai trasformato in Amazon S3. Non puoi utilizzare Data Wrangler finché non termina l'esportazione dei dati o non annulli l'operazione.
Per informazioni sull'utilizzo del metodo Esporta dati nel flusso di Data Wrangler, consulta la procedura seguente.
Per utilizzare il metodo Esporta dati:
-
Seleziona un nodo nel flusso di Data Wrangler aprendolo (facendo doppio clic su di esso).
-
Configura il modo in cui desideri esportare i dati.
-
Seleziona Esporta dati.
Quando esporti il flusso di dati in un bucket Amazon S3, Data Wrangler archivia una copia del file di flusso nel bucket S3. Memorizza il file di flusso con il prefisso data_wrangler_flows. Se utilizzi il bucket Amazon S3 predefinito per archiviare i tuoi file di flusso, utilizza la seguente convenzione di denominazione: sagemaker-region-account
number Ad esempio, se il numero dell'account è 111122223333 e si utilizza Studio Classic in us-east-1, i set di dati importati vengono archiviati in. sagemaker-us-east-1-111122223333 In questo esempio, i tuoi file di flusso creati in us-east-1 vengono archiviati in s3://sagemaker-region-account
number/data_wrangler_flows/.
Esporta in Pipelines
Se desideri creare e implementare flussi di lavoro di machine learning (ML) su larga scala, puoi utilizzare Pipelines per creare flussi di lavoro che gestiscono e implementano lavori di intelligenza artificiale. SageMaker Con Pipelines, puoi creare flussi di lavoro che gestiscono la preparazione dei dati di SageMaker intelligenza artificiale, la formazione dei modelli e i lavori di implementazione dei modelli. Puoi utilizzare gli algoritmi proprietari offerti dall' SageMaker intelligenza artificiale utilizzando Pipelines. Per ulteriori informazioni sulle pipeline, consulta Pipelines. SageMaker
Quando esporti uno o più passaggi dal flusso di dati a Pipelines, Data Wrangler crea un notebook Jupyter che puoi utilizzare per definire, istanziare, eseguire e gestire una pipeline.
Per creare una pipeline usare un notebook Jupyter
Utilizza la seguente procedura per creare un notebook Jupyter per esportare il flusso di Data Wrangler in Pipelines.
Utilizzate la seguente procedura per generare un notebook Jupyter ed eseguirlo per esportare il flusso di Data Wrangler in Pipelines.
-
Seleziona la + accanto al nodo che desideri esportare.
-
Seleziona Esporta in.
-
Scegli Pipelines (tramite Jupyter Notebook).
-
Esecuzione del notebook Jupyter
Per definire una pipeline è possibile utilizzare il notebook Jupyter prodotto da Data Wrangler. La pipeline include le fasi di elaborazione dati definite dal flusso di Data Wrangler.
Puoi aggiungere ulteriori fasi alla tua pipeline aggiungendo fasi all'elenco steps nel seguente codice del notebook:
pipeline = Pipeline(
name=pipeline_name,
parameters=[instance_type, instance_count],
steps=[step_process], #Add more steps to this list to run in your Pipeline
)
Per ulteriori informazioni sulla definizione delle pipeline, consulta Define AI Pipeline. SageMaker
Esportazione in un endpoint di inferenza
Usa il tuo flusso Data Wrangler per elaborare i dati al momento dell'inferenza creando una pipeline di inferenza seriale SageMaker AI dal tuo flusso Data Wrangler. Una pipeline di inferenza è una serie di fasi che si traducono in un modello addestrato che effettua previsioni su nuovi dati. Una pipeline di inferenza seriale all'interno di Data Wrangler trasforma i dati grezzi e li fornisce al modello di machine learning per una previsione. Puoi creare, eseguire e gestire la pipeline di inferenza da un notebook Jupyter all'interno di Studio Classic. Per ulteriori informazioni sull’accesso al notebook, consultare Utilizza un notebook Jupyter per creare un endpoint di inferenza.
All'interno del notebook, puoi addestrare un modello di machine learning o specificarne uno che hai già addestrato. Puoi utilizzare Amazon SageMaker Autopilot o XGBoost addestrare il modello utilizzando i dati che hai trasformato nel flusso di Data Wrangler.
La pipeline offre la possibilità di eseguire inferenze in batch o in tempo reale. Puoi anche aggiungere il flusso Data Wrangler a Model Registry. SageMaker Per ulteriori informazioni sui modelli di hosting, consulta Endpoint multi-modello.
Non è possibile esportare il flusso di Data Wrangler su un endpoint di inferenza se presenta le seguenti trasformazioni:
-
Join
-
Concatenazione
-
Gruppo da
Se per preparare i dati è necessario utilizzare le trasformazioni precedenti, utilizza la procedura seguente.
Per preparare i dati per l'inferenza con trasformazioni non supportate
-
Crea un flusso di Data Wrangler.
-
Applica le trasformazioni precedenti non supportate.
-
Esporta i dati in un bucket Amazon S3.
-
Crea un flusso di Data Wrangler separato.
-
Importa i dati che hai esportato dal flusso precedente.
-
Applica le trasformazioni rimanenti.
-
Crea una pipeline di inferenza seriale utilizzando il notebook Jupyter che forniamo.
Per informazioni sull'esportazione dei dati in un bucket Amazon S3 consulta Esportazione in Amazon S3. Per informazioni sull'apertura del notebook Jupyter utilizzato per creare la pipeline di inferenza seriale, consulta Utilizza un notebook Jupyter per creare un endpoint di inferenza.
Data Wrangler ignora le trasformazioni che rimuovono i dati al momento dell'inferenza. Ad esempio, Data Wrangler ignora la trasformazione Gestisci valori mancanti se si utilizza la configurazione Drop mancante.
Se hai effettuato l'adattamento delle trasformazioni all'intero set di dati, le trasformazioni vengono trasferite alla tua pipeline di inferenza. Ad esempio, se hai utilizzato il valore mediano per imputare i valori mancanti, il valore mediano ottenuto dall'adattamento della trasformazione viene applicato alle tue richieste di inferenza. Puoi scegliere di effettuare l'adattamento delle trasformazioni dal flusso di Data Wrangler quando utilizzi il notebook Jupyter o quando esporti i dati in una pipeline di inferenza. Per informazioni sull'adattamento delle trasformazioni, consulta Adatta le trasformazioni all'intero set di dati ed esportarle.
La pipeline di inferenza seriale supporta i seguenti tipi di dati per le stringhe di input e output. Ogni tipo di dati ha una serie di requisiti.
Tipi di dati supportati
-
text/csv – il tipo di dati per le stringhe CSV
-
La stringa non può avere un'intestazione.
-
Le funzionalità utilizzate per la pipeline di inferenza devono essere nello stesso ordine delle funzionalità nel set di dati di addestramento.
-
Tra le funzionalità deve esserci una virgola come delimitatore.
-
I record devono essere delimitati da un carattere ritorno a capo.
Di seguito è riportato un esempio di una stringa CSV in formato valido che è possibile fornire in una richiesta di inferenza.
abc,0.0,"Doe, John",12345\ndef,1.1,"Doe, Jane",67890
-
application/json – il tipo di dati per le stringhe JSON
-
Le funzionalità utilizzate nel set di dati per la pipeline di inferenza devono essere nello stesso ordine delle funzionalità nel set di dati di addestramento.
-
I dati devono avere uno schema specifico. Lo schema viene definito come un singolo oggetto instances con un set di features. Ogni oggetto features rappresenta un'osservazione.
Di seguito è riportato un esempio di una stringa JSON in formato valido che è possibile fornire in una richiesta di inferenza.
{
"instances": [
{
"features": ["abc", 0.0, "Doe, John", 12345]
},
{
"features": ["def", 1.1, "Doe, Jane", 67890]
}
]
}
Utilizza un notebook Jupyter per creare un endpoint di inferenza
Utilizza la seguente procedura per esportare il flusso di Data Wrangler per creare una pipeline di inferenza.
Per creare una pipeline di inferenza utilizzando un notebook Jupyter, procedi come segue.
-
Seleziona la + accanto al nodo che desideri esportare.
-
Seleziona Esporta in.
-
Scegli SageMaker AI Inference Pipeline (tramite Jupyter Notebook).
-
Esecuzione del notebook Jupyter
Quando si esegue il notebook Jupyter, viene creato un artefatto del flusso di inferenza. Un artefatto del flusso di inferenza è un file di flusso di Data Wrangler con metadati aggiuntivi utilizzati per creare la pipeline di inferenza seriale. Il nodo che stai esportando include tutte le trasformazioni dei nodi precedenti.
Data Wrangler ha bisogno dell'artefatto del flusso di inferenza per eseguire la pipeline di inferenza. Non puoi usare il tuo file di flusso come artefatto. È necessario crearlo utilizzando la procedura precedente.
Esportazione in codice Python
Per esportare tutte le fasi del flusso di dati in un file Python che puoi integrare manualmente in qualsiasi flusso di lavoro di elaborazione dati, usa la procedura seguente.
Utilizza la seguente procedura per generare un notebook Jupyter ed eseguirlo per esportare il flusso di Data Wrangler in codice Python.
-
Seleziona la + accanto al nodo che desideri esportare.
-
Seleziona Export to.
-
Seleziona Python Code (Codice Python).
-
Esecuzione del notebook Jupyter
Per farlo eseguire nella pipeline potrebbe essere necessario configurare lo script Python. Ad esempio, se utilizzi un ambiente Spark, assicurati di eseguire lo script da un ambiente che dispone del permesso di accedere alle risorse. AWS
Esporta su Amazon SageMaker Feature Store
Puoi utilizzare Data Wrangler per esportare le funzionalità che hai creato su Amazon SageMaker Feature Store. Una funzionalità è una colonna nel set di dati. L'archivio funzionalità è un archivio centralizzato delle funzionalità e i relativi metadati associati. Puoi utilizzare l'archivio funzionalità per creare, condividere e gestire dati curati per lo sviluppo del machine learning (ML). Gli archivi centralizzati rendono i dati più reperibili e riutilizzabili. Per ulteriori informazioni su Feature Store, consulta Amazon SageMaker Feature Store.
Un concetto fondamentale nell'archivio funzionalità è un gruppo di funzionalità. Un gruppo di funzionalità è una raccolta di funzionalità con i relativi record (osservazioni) e i metadati associati. È simile a una tabella in un database.
È possibile utilizzare Data Wrangler per eseguire una delle operazioni seguenti:
-
Aggiornare un gruppo di funzionalità esistente con nuovi record. Un record è un'osservazione nel set di dati.
-
Creare un nuovo gruppo di funzionalità da un nodo del flusso di Data Wrangler. Data Wrangler aggiunge le osservazioni dai tuoi set di dati come record nel tuo gruppo di funzionalità.
Se stai aggiornando un gruppo di funzionalità esistente, lo schema del set di dati deve corrispondere allo schema del gruppo di funzionalità. Tutti i record del gruppo di funzionalità vengono sostituiti con le osservazioni nel set di dati.
Per aggiornare il gruppo di funzionalità con le osservazioni nel set di dati è possibile utilizzare un notebook Jupyter o un nodo di destinazione.
Se i tuoi gruppi di funzionalità con il formato di tabella Iceberg dispongono di una chiave di crittografia dell'archivio offline personalizzata, assicurati di concedere all'IAM che stai utilizzando per il job Amazon SageMaker Processing le autorizzazioni per utilizzarla. Come minimo, devi concedere le autorizzazioni per crittografare i dati che stai scrivendo in Amazon S3. Per concedere le autorizzazioni, consenti al ruolo IAM di utilizzare. GenerateDataKey Per ulteriori informazioni sulla concessione ai ruoli IAM delle autorizzazioni per l'uso delle chiavi, consulta AWS KMS https://docs.aws.amazon.com/kms/latest/developerguide/key-policies.html
- Destination Node
-
Se vuoi inviare a un gruppo di funzionalità una serie di fasi di elaborazione dati che hai eseguito, puoi creare un nodo di destinazione. Quando crei ed esegui un nodo di destinazione, Data Wrangler aggiorna un gruppo di funzionalità con i tuoi dati. È inoltre possibile creare un nuovo gruppo di funzionalità dall'interfaccia utente del nodo di destinazione. Dopo aver creato un nodo di destinazione, crea un processo di elaborazione per l'output dei dati. Un processo di elaborazione è un processo di SageMaker elaborazione di Amazon. Quando utilizzi un nodo di destinazione, questo esegue le risorse di calcolo necessarie per generare i dati che hai trasformato in gruppo di funzionalità.
Puoi utilizzare un nodo di destinazione per esportare alcune delle trasformazioni o tutte le trasformazioni che hai apportato nel flusso di Data Wrangler.
Utilizza la seguente procedura per creare un nodo di destinazione per aggiornare un gruppo di funzionalità con le osservazioni del set di dati.
Per aggiornare un gruppo di funzionalità utilizzando un nodo di destinazione, effettua le seguenti operazioni.
Puoi selezionare Crea processo nel flusso di Data Wrangler per visualizzare le istruzioni sull'utilizzo di un processo di elaborazione per aggiornare il gruppo di funzionalità.
-
Seleziona il simbolo + accanto al nodo contenente il set di dati che desideri esportare.
-
In Aggiungi destinazione, scegli SageMaker AI Feature Store.
-
Fai (doppio clic) sul gruppo di funzionalità. Data Wrangler per aggiornare il gruppo di funzionalità verifica se lo schema del gruppo di funzionalità corrisponde allo schema dei dati che stai utilizzando.
-
(Facoltativo) seleziona Esporta solo su archivio offline per i gruppi di funzionalità che dispongono sia di un archivio online che di un archivio offline. Questa opzione aggiorna l'archivio offline solo con le osservazioni del tuo set di dati.
-
Dopo che Data Wrangler ha convalidato lo schema del set di dati, seleziona Aggiungi.
Utilizza la procedura seguente per creare un nuovo gruppo di funzionalità con i dati del set di dati.
È possibile archiviare il gruppo di funzionalità in uno dei seguenti modi:
-
Online: cache a bassa latenza e alta disponibilità per un gruppo di funzionalità che fornisce la ricerca in tempo reale dei record. L’archivio online consente di accedere rapidamente al valore più recente di un record in un gruppo di funzionalità.
-
Offline: archivia i dati per il gruppo di funzionalità in un bucket Amazon S3. Puoi archiviare i dati offline quando non hai bisogno di letture a bassa latenza (inferiori al secondo). Puoi utilizzare un archivio offline per le funzionalità utilizzate nell'esplorazione dei dati, nell'addestramento dei modelli e nell'inferenza batch.
-
Sia online che offline: archivia i dati sia in un archivio online che in un archivio offline.
Per creare un gruppo di funzionalità utilizzando un nodo di destinazione, effettua le seguenti operazioni.
-
Seleziona il simbolo + accanto al nodo contenente il set di dati che desideri esportare.
-
In Aggiungi destinazione, scegli SageMaker AI Feature Store.
-
Seleziona Crea gruppo di funzionalità.
-
Nella finestra di dialogo seguente, se il set di dati non ha una colonna relativa all'ora dell'evento, seleziona Crea la colonna EventTime "».
-
Scegli Next (Successivo).
-
Seleziona Copia schema JSON. Quando crei un gruppo di funzionalità, incolla lo schema nelle definizioni delle funzionalità.
-
Scegli Create (Crea).
-
Per Nome del gruppo di funzionalità, specifica un nome per il gruppo di funzionalità.
-
Per Descrizione (opzionale), specificare una descrizione per rendere il gruppo di funzionalità più individuabile.
-
Per creare un gruppo di funzionalità per un archivio online, procedi come indicato di seguito.
-
Seleziona Abilita archiviazione online
-
Per la chiave di crittografia del negozio online, specifica una chiave di crittografia AWS gestita o una chiave di crittografia personalizzata.
-
Per creare un gruppo di funzionalità per un archivio offline, procedi come indicato di seguito.
-
Seleziona Abilita archiviazione offline. Specifica i valori per i seguenti campi:
-
S3 bucket name: il nome del bucket Amazon S3 in cui è archiviato il gruppo di funzionalità.
-
(Facoltativo) Nome della directory del set di dati: il prefisso Amazon S3 che utilizzi per archiviare il gruppo di funzionalità.
-
ARN del ruolo IAM: Il ruolo IAM che ha accesso a Feature Store.
-
Formato della tabella: il formato della tabella del tuo archivio offline. È possibile specificare Glue o Iceberg. Glue è il formato predefinito.
-
Chiave di crittografia dell’archivio offline: per impostazione predefinita, l'Archivio funzionalità utilizza una chiave gestita AWS Key Management Service , ma puoi utilizzare il campo per specificare una chiave personalizzata.
-
Specifica i valori per i seguenti campi:
-
Nome del bucket S3: il nome del bucket che archivia il gruppo di funzionalità.
-
(Facoltativo) Nome della directory del set di dati: il prefisso Amazon S3 che utilizzi per archiviare il gruppo di funzionalità.
-
ARN del ruolo IAM: Il ruolo IAM che ha accesso a Feature Store.
-
Chiave di crittografia dell’archivio offline: per impostazione predefinita, l'Archivio funzionalità utilizza una chiave gestita AWS , ma puoi utilizzare il campo per specificare una chiave personalizzata.
-
Scegli Continua.
-
Scegli JSON.
-
Rimuovi le parentesi segnaposto nella finestra.
-
Incolla il testo JSON dalla fase 6.
-
Scegli Continua.
-
Per NOME DELLA FUNZIONALITÀ DELL’IDENTIFICATORE DEL RECORD, scegli la colonna del set di dati che contiene identificatori univoci per ogni record del set di dati.
-
Per NOME DELLA FUNZIONALITÀ DELL’ORA DELL’EVENTO, scegli la colonna con i valori del timestamp.
-
Scegli Continua.
-
(Facoltativo) Assegna tag per rendere il gruppo di funzionalità più individuabile.
-
Scegli Continua.
-
Seleziona Crea gruppo di funzionalità.
-
Torna al flusso di Data Wrangler e seleziona l'icona di aggiornamento accanto alla barra di ricerca Gruppo di funzionalità.
Se hai già creato un nodo di destinazione per un gruppo di funzionalità all'interno di un flusso, non puoi creare un altro nodo di destinazione per lo stesso gruppo di funzionalità. Se desideri creare un altro nodo di destinazione per lo stesso gruppo di funzionalità, dove creare un altro file di flusso.
Usa la procedura seguente per creare un processo Data Wrangler.
Crea un processo dalla pagina Flusso di dati e seleziona i nodi di destinazione che desideri esportare.
-
Scegli Crea processo. L'immagine seguente mostra il riquadro che appare dopo aver selezionato Crea processo.
-
Per Nome del processo, specifica il nome del processo di esportazione.
-
Seleziona i nodi di destinazione da esportare.
-
(Facoltativo) Per Output KMS Key, specificate un ARN, ID o alias di una chiave. AWS KMS Una chiave KMS è una chiave crittografica. È possibile utilizzare la chiave per crittografare i dati di output del processo. Per ulteriori informazioni sulle AWS KMS chiavi, vedere. AWS Key Management Service
-
L'immagine seguente mostra la pagina Configura processo con la scheda Configurazione dei processi aperta.
(Facoltativo) In Parametri addestrati, seleziona Riadatta se hai fatto quanto segue:
Per ulteriori informazioni sull'adattamento delle trasformazioni che hai apportato a un intero set di dati, consulta Adatta le trasformazioni all'intero set di dati ed esportarle.
-
Seleziona Configura processo.
-
(Facoltativo) Configura il processo Data Wrangler. È possibile utilizzare le seguenti configurazioni:
-
Configurazione dei processi
-
Configurazione della memoria Spark
-
Configurazione della rete
-
Tag
-
Parametri
-
Associa pianificazioni
-
Seleziona Esegui.
- Jupyter notebook
-
Usa la seguente procedura su un notebook Jupyter per esportarlo su Amazon SageMaker Feature Store.
Utilizza la seguente procedura per generare un notebook Jupyter ed eseguirlo per esportare il flusso di Data Wrangler in Archivio funzionalità.
-
Seleziona la + accanto al nodo che desideri esportare.
-
Seleziona Esporta in.
-
Scegli Amazon SageMaker Feature Store (tramite Jupyter Notebook).
-
Esecuzione del notebook Jupyter
L'esecuzione di un notebook Jupyter esegue un processo Data Wrangler. L'esecuzione di un processo Data Wrangler avvia un processo di elaborazione AI. SageMaker Il processo di elaborazione inserisce il flusso in un archivio funzionalità online e offline.
Il ruolo IAM utilizzato per eseguire questo notebook deve avere collegate le seguenti policy gestite AWS : AmazonSageMakerFullAccess e AmazonSageMakerFeatureStoreAccess.
È solamente necessario abilitare un solo archivio funzionalità online o offline quando si crea un gruppo di funzionalità. È inoltre possibile abilitarli entrambi. Per disabilitare la creazione dell’archivio online, imposta EnableOnlineStore suFalse:
# Online Store Configuration
online_store_config = {
"EnableOnlineStore": False
}
Il notebook utilizza i nomi e i tipi di colonna del dataframe esportato per creare uno schema di gruppi di funzionalità, che viene utilizzato per creare un gruppo di funzionalità. Un gruppo di funzionalità è definito nell’archivio funzionalità per descrivere un record. Il gruppo di funzionalità definisce lo schema e le funzionalità contenute nel gruppo di funzionalità. Una definizione di gruppo di funzionalità è composta da un elenco di funzionalità, un nome della funzionalità identificatore del record, un nome della funzionalità dell'ora dell'evento e configurazioni per il relativo archivio online e archivio offline.
Ogni funzionalità di un gruppo di funzionalità può avere uno dei seguenti tipi: Stringa, Frazionario o Integrale. Se una colonna nel dataframe esportato non è di questi tipi, il valore predefinito è. String
Di seguito è riportato un esempio di schema di gruppo di funzionalità.
column_schema = [
{
"name": "Height",
"type": "long"
},
{
"name": "Input",
"type": "string"
},
{
"name": "Output",
"type": "string"
},
{
"name": "Sum",
"type": "string"
},
{
"name": "Time",
"type": "string"
}
]
Inoltre, devi specificare il nome dell'identificatore del record e il nome della funzionalità dell'ora dell'evento:
-
Il nome dell’identificatore del record è il nome della funzionalità il cui valore identifica in modo univoco un record definito nell'archivio delle caratteristiche. Nell'archivio online viene memorizzato solo l'ultimo record per valore identificativo. Il nome della funzionalità dell'identificatore del record deve essere uno dei nomi delle definizioni delle funzionalità.
-
Il nome della funzionalità dell'ora dell'evento è il nome della funzionalità che memorizza EventTime di un record in un gruppo di funzionalità. Un EventTime è un punto nel tempo in cui si verifica un nuovo evento che corrisponde alla creazione o all'aggiornamento di un record in una funzionalità. Tutti i record del gruppo di funzionalità devono avere un corrispondente EventTime.
Il notebook utilizza queste configurazioni per creare un gruppo di funzionalità, elaborare i dati su larga scala e quindi inserire i dati elaborati nell’archivio funzionalità online e offline. Per ulteriori informazioni, consulta Origine dati e inserimento.
Il notebook utilizza queste configurazioni per creare un gruppo di funzionalità, elaborare i dati su larga scala e quindi inserire i dati elaborati nell’archivio funzionalità online e offline. Per ulteriori informazioni, consulta Origine dati e inserimento.
Quando si importano dati, per applicare le codifiche Data Wrangler utilizza un campione di dati. Per impostazione predefinita, Data Wrangler utilizza le prime 50.000 righe come campione, ma è possibile importare l'intero set di dati o utilizzare un metodo di campionamento diverso. Per ulteriori informazioni, consulta Importa.
Le seguenti trasformazioni utilizzano i dati per creare una colonna nel set di dati:
Se per importare i dati hai usato il campionamento, per creare la colonna le trasformazioni precedenti utilizzano solo i dati del campione. La trasformazione potrebbe non aver utilizzato tutti i dati pertinenti. Ad esempio, se utilizzi la trasformazione Codifica categorica, potrebbe esserci una categoria nel set di dati che non è presente nel campione.
Per adattare le trasformazioni all'intero set di dati è possibile utilizzare un nodo di destinazione o un notebook Jupyter. Quando Data Wrangler esporta le trasformazioni nel flusso, crea un processo di elaborazione. SageMaker Al termine del processo di elaborazione, Data Wrangler salva i seguenti file nella posizione Amazon S3 predefinita o in una posizione S3 specificata dall'utente:
È possibile aprire un file di flusso di Data Wrangler all'interno di Data Wrangler e applicare le trasformazioni a un set di dati diverso. Ad esempio, se hai applicato le trasformazioni a un set di dati di addestramento, puoi aprire e utilizzare il file di flusso di Data Wrangler per applicare le trasformazioni a un set di dati utilizzato per l'inferenza.
Per informazioni sull'utilizzo dei nodi di destinazione per adattare le trasformazioni e l'esportazione, consulta le seguenti pagine:
Utilizza la seguente procedura per eseguire un notebook Jupyter per adattare le trasformazioni ed esportare i dati.
Per eseguire un notebook Jupyter e adattare le trasformazioni ed esportare il flusso di Data Wrangler, procedi come segue.
-
Seleziona la + accanto al nodo che desideri esportare.
-
Seleziona Esporta in.
-
Seleziona la posizione in cui esportare i dati.
-
Per l'oggetto refit_trained_params, imposta refit su True
-
Per il campo output_flow, specifica il nome del file di flusso di output con le trasformazioni adattate.
-
Esecuzione del notebook Jupyter
Creare una pianificazione per elaborare automaticamente i nuovi dati
Se elabori i dati periodicamente, puoi creare una pianificazione per eseguire automaticamente il processo di elaborazione. Ad esempio, è possibile creare una pianificazione che esegue automaticamente un processo di elaborazione quando si ottengono nuovi dati. Per ulteriori informazioni su questi processi di elaborazione, consulta Esportazione in Amazon S3 e Esporta su Amazon SageMaker Feature Store.
Quando crei un processo, devi specificare un ruolo IAM con le autorizzazioni per creare il processo. Per impostazione predefinita, il ruolo IAM che utilizzi per accedere a Data Wrangler è il. SageMakerExecutionRole
Le seguenti autorizzazioni consentono a Data Wrangler di accedere EventBridge e di eseguire processi di elaborazione: EventBridge
-
Aggiungi la seguente policy AWS gestita al ruolo di esecuzione di Amazon SageMaker Studio Classic che fornisce a Data Wrangler le autorizzazioni per l'uso: EventBridge
arn:aws:iam::aws:policy/AmazonEventBridgeFullAccess
Per ulteriori informazioni sulla politica, consulta le politiche AWS gestite per. EventBridge
-
Aggiungi la policy seguente al ruolo IAM che hai specificato quando hai creato un processo in Data Wrangler:
- JSON
-
-
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Action": "sagemaker:StartPipelineExecution",
"Resource": "arn:aws:sagemaker:us-east-1:111122223333:pipeline/data-wrangler-*"
}
]
}
Se utilizzi il ruolo IAM predefinito, aggiungi la policy precedente al ruolo di esecuzione di Amazon SageMaker Studio Classic.
Aggiungi la seguente politica di fiducia al ruolo per EventBridge consentirne l'assunzione.
{
"Effect": "Allow",
"Principal": {
"Service": "events.amazonaws.com"
},
"Action": "sts:AssumeRole"
}
Quando crei una pianificazione, Data Wrangler crea un eventRule ingresso. EventBridge Ti vengono addebitati costi sia per le regole degli eventi che crei sia per le istanze utilizzate per eseguire il processo di elaborazione.
Per informazioni sui EventBridge prezzi, consulta la pagina EventBridge dei prezzi di Amazon. Per informazioni sui prezzi dei lavori di elaborazione, consulta Amazon SageMaker Pricing.
Puoi impostare una pianificazione utilizzando uno dei seguenti metodi:
-
Espressioni CRON
Data Wrangler non supporta le seguenti espressioni:
-
Espressioni della FREQUENZA
-
Ricorrente: per l'esecuzione del processo Imposta un intervallo orario o giornaliero.
-
Ora specifica: per l'esecuzione del processo imposta giorni e orari specifici.
Nelle sezioni seguenti vengono descritte le procedure per creare processi.
- CRON
-
Utilizza la procedura seguente per creare una pianificazione con un'espressione CRON.
Per specificare una pianificazione con un'espressione CRON, effettua le seguenti operazioni.
-
Apri il flusso di Data Wrangler.
-
Scegli Crea processo.
-
(Facoltativo) Per la chiave Output KMS, specifica una AWS KMS chiave per configurare l'output del lavoro.
-
Seleziona Successivo, 2. Configura processo.
-
Seleziona Associa pianificazioni.
-
Seleziona Crea nuova pianificazione.
-
Per Nome della pianificazione, specifica il nome della pianificazione.
-
Per Frequenza di esecuzione, seleziona CRON.
-
Specifica un'espressione CRON valida.
-
Scegli Create (Crea).
-
(Facoltativo) seleziona Aggiungi un’altra pianificazione per eseguire il lavoro in base a una pianificazione aggiuntiva.
È possibile associare un massimo di due pianificazioni. Le pianificazioni sono indipendenti e non si influenzano tra loro a meno che i tempi non si sovrappongano.
-
Seleziona una delle seguenti opzioni:
-
Pianifica ed esegui ora: Data Wrangler, il processo viene eseguito immediatamente e successivamente viene eseguito secondo le pianificazioni.
-
Solo pianificazione: Data Wrangler, il processo viene eseguito solo in base alle pianificazioni specificate.
-
Seleziona Esegui
- RATE
-
Utilizza la procedura seguente per creare una pianificazione con un'espressione della FREQUENZA.
Per specificare una pianificazione con un'espressione della FREQUENZA, effettua le seguenti operazioni.
-
Apri il flusso di Data Wrangler.
-
Scegli Crea processo.
-
(Facoltativo) Per la chiave Output KMS, specifica una AWS KMS chiave per configurare l'output del lavoro.
-
Seleziona Successivo, 2. Configura processo.
-
Seleziona Associa pianificazioni.
-
Seleziona Crea nuova pianificazione.
-
Per Nome della pianificazione, specifica il nome della pianificazione.
-
Per Frequenza di esecuzione, seleziona Frequenza.
-
Per Valore, specifica un numero intero.
-
Per Unità, seleziona una delle opzioni seguenti:
-
Scegli Create (Crea).
-
(Facoltativo) seleziona Aggiungi un’altra pianificazione per eseguire il lavoro in base a una pianificazione aggiuntiva.
È possibile associare un massimo di due pianificazioni. Le pianificazioni sono indipendenti e non si influenzano tra loro a meno che i tempi non si sovrappongano.
-
Seleziona una delle seguenti opzioni:
-
Pianifica ed esegui ora: Data Wrangler, il processo viene eseguito immediatamente e successivamente viene eseguito secondo le pianificazioni.
-
Solo pianificazione: Data Wrangler, il processo viene eseguito solo in base alle pianificazioni specificate.
-
Seleziona Esegui
- Recurring
-
Utilizza la procedura seguente per creare una pianificazione che esegua un processo su base ricorrente.
Per specificare una pianificazione con un'espressione CRON, effettua le seguenti operazioni.
-
Apri il flusso di Data Wrangler.
-
Scegli Crea processo.
-
(Facoltativo) Per la chiave Output KMS, specifica una AWS KMS chiave per configurare l'output del lavoro.
-
Seleziona Successivo, 2. Configura processo.
-
Seleziona Associa pianificazioni.
-
Seleziona Crea nuova pianificazione.
-
Per Nome della pianificazione, specifica il nome della pianificazione.
-
Per Frequenza di esecuzione, assicurati che l'opzione Ricorrente sia selezionata per impostazione predefinita.
-
Per Ogni x ore, specifica la frequenza oraria di esecuzione del processo durante il giorno. I valori validi sono numeri interi compresi nell'intervallo tra 1 e 23.
-
Per In giorni, seleziona una delle seguenti opzioni:
-
Ogni giorno
-
Fine settimana
-
Giorni della settimana
-
Seleziona giorni
-
(Facoltativo) Se hai selezionato Seleziona giorni, seleziona i giorni della settimana in cui eseguire il processo.
La pianificazione viene ripristinata ogni giorno. Se pianifichi l'esecuzione di un processo ogni cinque ore, questo viene eseguito nelle seguenti ore del giorno:
-
00:00
-
05:00
-
10:00
-
15:00
-
20:00
-
Scegli Create (Crea).
-
(Facoltativo) seleziona Aggiungi un’altra pianificazione per eseguire il lavoro in base a una pianificazione aggiuntiva.
È possibile associare un massimo di due pianificazioni. Le pianificazioni sono indipendenti e non si influenzano tra loro a meno che i tempi non si sovrappongano.
-
Seleziona una delle seguenti opzioni:
-
Pianifica ed esegui ora: Data Wrangler, il processo viene eseguito immediatamente e successivamente viene eseguito secondo le pianificazioni.
-
Solo pianificazione: Data Wrangler, il processo viene eseguito solo in base alle pianificazioni specificate.
-
Seleziona Esegui
- Specific time
-
Utilizzare la procedura seguente per creare una pianificazione che esegua un processo a orari specifici.
Per specificare una pianificazione con un'espressione CRON, effettua le seguenti operazioni.
-
Apri il flusso di Data Wrangler.
-
Scegli Crea processo.
-
(Facoltativo) Per la chiave Output KMS, specificate una AWS KMS chiave per configurare l'output del lavoro.
-
Seleziona Successivo, 2. Configura processo.
-
Seleziona Associa pianificazioni.
-
Seleziona Crea nuova pianificazione.
-
Per Nome della pianificazione, specifica il nome della pianificazione.
-
Scegli Create (Crea).
-
(Facoltativo) seleziona Aggiungi un’altra pianificazione per eseguire il lavoro in base a una pianificazione aggiuntiva.
È possibile associare un massimo di due pianificazioni. Le pianificazioni sono indipendenti e non si influenzano tra loro a meno che i tempi non si sovrappongano.
-
Seleziona una delle seguenti opzioni:
-
Pianifica ed esegui ora: Data Wrangler, il processo viene eseguito immediatamente e successivamente viene eseguito secondo le pianificazioni.
-
Solo pianificazione: Data Wrangler, il processo viene eseguito solo in base alle pianificazioni specificate.
-
Seleziona Esegui
Puoi utilizzare Amazon SageMaker Studio Classic per visualizzare i processi pianificati per l'esecuzione. I tuoi processi di elaborazione vengono eseguiti all'interno di Pipelines. Ogni processo di elaborazione ha una propria pipeline. Viene eseguito come fase di elaborazione all'interno della pipeline. All'interno di una pipeline puoi visualizzare le pianificazioni che hai creato. Per informazioni sulla visualizzazione di una pipeline, consulta Visualizza i dettagli di una pipeline.
Per visualizzare i processi pianificati utilizza la procedura seguente.
Per visualizzare i processi che hai programmato, procedi come segue.
-
Apri Amazon SageMaker Studio Classic.
-
Pipeline aperte
-
Visualizza le pipeline dei lavori che hai creato.
La pipeline che esegue il processo utilizza il nome del processo come prefisso. Ad esempio, se hai creato un processo denominato housing-data-feature-enginnering, il nome della pipeline sarà data-wrangler-housing-data-feature-engineering
-
Selezionare la pipeline contenente il tuo processo.
-
Visualizza lo stato delle pipeline. Le pipeline con stato Riuscito hanno eseguito correttamente il processo di elaborazione.
Per interrompere l'esecuzione del processo di elaborazione, effettua le seguenti operazioni:
Per interrompere l'esecuzione di un processo di elaborazione, elimina la regola di evento che specifica la pianificazione. L'eliminazione di una regola di evento interrompe l'esecuzione di tutti i processi associati alla pianificazione. Per informazioni sull'eliminazione di una regola, consulta Disabilitazione o eliminazione di una regola Amazon. EventBridge
Puoi anche interrompere ed eliminare le pipeline associate alle pianificazioni. Per informazioni sull'arresto di una pipeline, consulta. StopPipelineExecution Per informazioni sull'eliminazione di una pipeline, vedere. DeletePipeline