Per funzionalità simili a Amazon Timestream for, prendi in considerazione Amazon Timestream LiveAnalytics per InfluxDB. Offre un'acquisizione semplificata dei dati e tempi di risposta alle query di una sola cifra di millisecondi per analisi in tempo reale. Scopri di più qui.
Le traduzioni sono generate tramite traduzione automatica. In caso di conflitto tra il contenuto di una traduzione e la versione originale in Inglese, quest'ultima prevarrà.
Architettura
Amazon Timestream for Live Analytics è stato progettato da zero per raccogliere, archiviare ed elaborare dati di serie temporali su larga scala. La sua architettura serverless supporta sistemi di acquisizione, archiviazione ed elaborazione delle query di dati completamente disaccoppiati, scalabili in modo indipendente. Questo design semplifica ogni sottosistema, facilitando il raggiungimento di un'affidabilità incrollabile, l'eliminazione dei colli di bottiglia legati alla scalabilità e la riduzione delle possibilità di guasti di sistema correlati. Ciascuno di questi fattori diventa più importante man mano che il sistema cresce.
Argomenti

Scrivi l'architettura
Durante la scrittura di dati di serie temporali, Amazon Timestream for Live Analytics indirizza le scritture per una tabella, una partizione, a un'istanza di storage di memoria con tolleranza ai guasti che elabora scritture di dati ad alto throughput. L'archivio di memoria a sua volta raggiunge la durabilità in un sistema di storage separato che replica i dati su tre zone di disponibilità (). AZs La replica si basa sul quorum in modo tale che la perdita di nodi o di un'intera zona di disponibilità non comprometta la disponibilità di scrittura. Quasi in tempo reale, altri nodi di storage in memoria si sincronizzano con i dati per rispondere alle richieste. Il lettore replica anche i nodi, per garantire un' AZs elevata disponibilità di lettura.
Timestream for Live Analytics supporta la scrittura dei dati direttamente nell'archivio magnetico, per applicazioni che generano dati in arrivo tardivo con un throughput inferiore. I dati in arrivo tardivo sono dati con un timestamp precedente all'ora corrente. Analogamente alle scritture ad alta velocità nell'archivio di memoria, i dati scritti nell'archivio magnetico vengono replicati su tre unità AZs e la replica si basa sul quorum.
Indipendentemente dal fatto che i dati vengano scritti nella memoria o nell'archivio magnetico, Timestream for Live Analytics indicizza e partiziona automaticamente i dati prima di scriverli sullo storage. Una singola tabella Timestream for Live Analytics può avere centinaia, migliaia o addirittura milioni di partizioni. Le singole partizioni non comunicano direttamente tra loro e non condividono alcun dato (architettura shared-nothing). Invece, il partizionamento di una tabella viene tracciato tramite un servizio di tracciamento e indicizzazione delle partizioni ad alta disponibilità. Ciò fornisce un'altra separazione delle preoccupazioni progettata specificamente per ridurre al minimo l'effetto dei guasti nel sistema e rendere molto meno probabili i guasti correlati.
Architettura di storage
Quando i dati vengono archiviati in Timestream for Live Analytics, i dati vengono organizzati in ordine temporale e temporale in base agli attributi di contesto scritti con i dati. Avere uno schema di partizionamento che divida lo «spazio» oltre al tempo è importante per scalare in modo massiccio un sistema di serie temporali. Questo perché la maggior parte dei dati delle serie temporali viene scritta all'ora corrente o in prossimità di essa. Di conseguenza, il partizionamento basato solo sul tempo non consente di distribuire bene il traffico di scrittura o di eliminare efficacemente i dati al momento dell'interrogazione. Questo è importante per l'elaborazione di serie temporali su scala estrema e ha consentito a Timestream for Live Analytics di scalare ordini di grandezza superiori rispetto agli altri principali sistemi attualmente disponibili in modalità serverless. Le partizioni risultanti vengono chiamate «tessere» perché rappresentano divisioni di uno spazio bidimensionale (progettate per avere dimensioni simili). Le tabelle Timestream per Live Analytics iniziano come una singola partizione (riquadro), quindi si suddividono nella dimensione spaziale in base alla velocità di trasmissione. Quando i riquadri raggiungono una certa dimensione, vengono suddivisi nella dimensione temporale per ottenere un migliore parallelismo di lettura man mano che la dimensione dei dati aumenta.
Timestream for Live Analytics è progettato per gestire automaticamente il ciclo di vita dei dati delle serie temporali. Timestream for Live Analytics offre due archivi di dati: un archivio in memoria e un archivio magnetico conveniente. Supporta anche la configurazione di policy a livello di tabella per trasferire automaticamente i dati tra gli archivi. Le scritture dei dati ad alta velocità in entrata arrivano nell'archivio di memoria, dove i dati sono ottimizzati per le scritture, nonché le letture eseguite all'ora corrente per alimentare la dashboard e inviare avvisi di tipo query. Una volta trascorso il periodo di tempo principale necessario per le scritture, gli avvisi e la creazione di dashboard, i dati possono fluire automaticamente dall'archivio di memoria all'archivio magnetico per ottimizzare i costi. Timestream for Live Analytics consente di impostare una politica di conservazione dei dati nell'archivio di memoria per questo scopo. Le scritture dei dati per i dati in arrivo tardivo vengono scritte direttamente nell'archivio magnetico.
Una volta che i dati sono disponibili nell'archivio magnetico (a causa della scadenza del periodo di conservazione dell'archivio di memoria o a causa delle scritture dirette nell'archivio magnetico), vengono riorganizzati in un formato altamente ottimizzato per letture di dati di grandi volumi. L'archivio magnetico ha anche una politica di conservazione dei dati che può essere configurata se esiste una soglia temporale in cui i dati superano la loro utilità. Quando i dati superano l'intervallo di tempo definito per la politica di conservazione degli archivi magnetici, vengono rimossi automaticamente. Pertanto, con Timestream for Live Analytics, a parte alcune configurazioni, la gestione del ciclo di vita dei dati avviene senza problemi dietro le quinte.
Architettura delle interrogazioni
Le query Timestream for Live Analytics sono espresse in una grammatica SQL con estensioni per il supporto specifico delle serie temporali (tipi di dati e funzioni specifici delle serie temporali), quindi la curva di apprendimento è semplice per gli sviluppatori che già conoscono SQL. Le query vengono quindi elaborate da un motore di query adattivo e distribuito che utilizza i metadati del servizio di tracciamento e indicizzazione dei riquadri per accedere e combinare senza problemi i dati tra gli archivi di dati al momento dell'emissione della query. Ciò garantisce un'esperienza molto apprezzata dai clienti, in quanto riduce molte delle complessità di Rube Goldberg in un'astrazione di database semplice e familiare.
Le query vengono eseguite da una flotta di lavoratori dedicata, in cui il numero di lavoratori arruolati per eseguire una determinata query è determinato dalla complessità della query e dalla dimensione dei dati. Le prestazioni per query complesse su set di dati di grandi dimensioni sono ottenute attraverso un parallelismo massiccio, sia sulla flotta di esecuzione delle query che sui parchi di storage del sistema. La capacità di analizzare enormi quantità di dati in modo rapido ed efficiente è uno dei maggiori punti di forza di Timestream for Live Analytics. Una singola query che viene eseguita su terabyte o addirittura petabyte di dati potrebbe avere migliaia di macchine che lavorano su tutte contemporaneamente.
Architettura cellulare
Per garantire che Timestream for Live Analytics possa offrire una scalabilità praticamente infinita per le vostre applicazioni, garantendo contemporaneamente una disponibilità del 99,99%, il sistema è progettato anche utilizzando un'architettura cellulare. Invece di ridimensionare il sistema nel suo insieme, Timestream for Live Analytics si segmenta in più copie più piccole di se stesso, denominate celle. Ciò consente di testare le cellule su vasta scala e impedisce che un problema di sistema in una cella influisca sull'attività di qualsiasi altra cella in una determinata regione. Sebbene Timestream for Live Analytics sia progettato per supportare più celle per regione, considera il seguente scenario fittizio, in cui ci sono 2 celle in una regione.
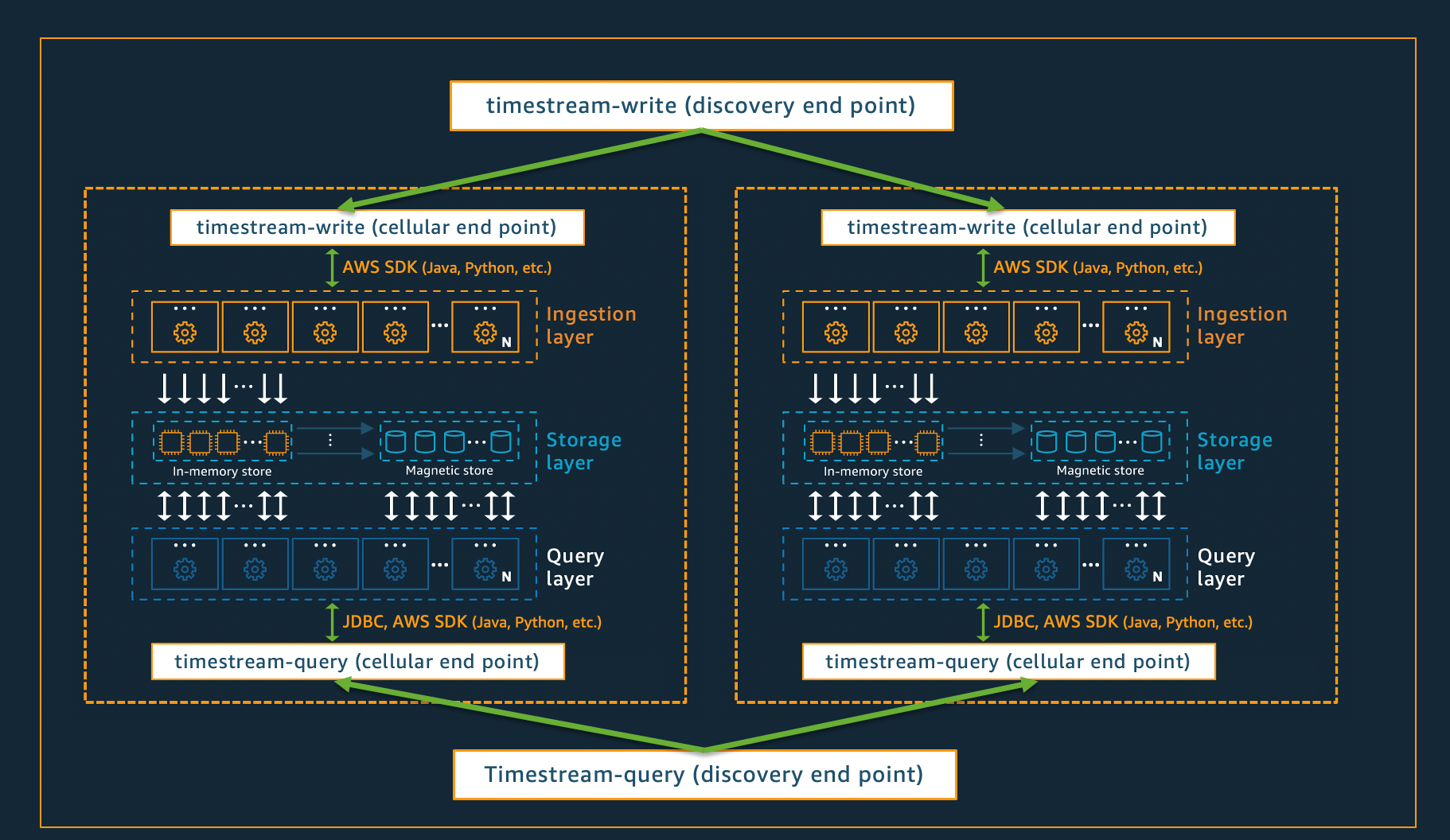
Nello scenario illustrato sopra, l'inserimento dei dati e le richieste di query vengono prima elaborate dall'endpoint di rilevamento rispettivamente per l'ingestione e l'interrogazione dei dati. Quindi, l'endpoint di rilevamento identifica la cella contenente i dati del cliente e indirizza la richiesta all'endpoint di acquisizione o interrogazione appropriato per quella cella. Quando si utilizza SDKs, queste attività di gestione degli endpoint vengono gestite in modo trasparente per te.
Nota
Quando utilizzi gli endpoint VPC con Timestream for Live Analytics o accedi direttamente alle operazioni dell'API REST per Timestream for Live Analytics, dovrai interagire direttamente con gli endpoint cellulari. Per indicazioni su come eseguire questa operazione, consulta VPC Endpoints per istruzioni su come configurare gli endpoint VPC e Endpoint Discovery Pattern per istruzioni sull'invocazione diretta delle operazioni dell'API REST.
