Aurora MySQL で Amazon Aurora 機械学習を使用する
Aurora MySQL DB クラスターで Amazon Aurora 機械学習を使用することで、必要に応じて Amazon Bedrock、Amazon Comprehend、または Amazon SageMaker AI を使用できます。それぞれが異なる機械学習のユースケースをサポートしています。
Aurora 機械学習 を Aurora MySQL で使用するための要件
AWS 機械学習サービスは、お客様の本番環境で設定し、実行するマネージドサービスです。Aurora 機械学習は、Amazon Bedrock、Amazon Comprehend、SageMaker AI の統合をサポートしています。Aurora MySQL DB クラスターを設定して Aurora 機械学習を使用開始する前に、次の要件と前提条件を理解していることを確認してください。
-
機械学習サービスは、お使いの Aurora MySQL DB クラスターと同じ AWS リージョン で実行する必要があります。別のリージョンにある Aurora MySQL DB クラスターからの機械学習サービスは使用できません。
-
Aurora MySQL DB クラスターが Amazon Bedrock、Amazon Comprehend または SageMaker AI サービスとは異なる仮想パブリッククラウド (VPC) にある場合、VPC のセキュリティグループが対象の Aurora 機械学習サービスへのアウトバウンド接続を許可する必要があります。詳細については、「Amazon VPC ユーザーガイド」の「セキュリティグループを使用して AWS リソースへのトラフィックを制御する」を参照してください。
-
そのクラスターで Aurora 機械学習を使用する場合は、Aurora MySQL の下位バージョンを実行している Aurora クラスターをサポートされている上位バージョンにアップグレードできます。詳細については、「Amazon Aurora MySQL のデータベースエンジンの更新」を参照してください。
-
Aurora MySQL DB クラスターは、カスタム DB クラスターパラメータグループを使用する必要があります。使用する各 Aurora 機械学習サービスの設定プロセスの最後で、サービス用に作成された関連する IAM ロールの Amazon リソースネーム (ARN) を追加します。事前に Aurora MySQL 用のカスタム DB クラスターパラメータグループを作成し、それを使用するように Aurora MySQL DB クラスターを設定することで、設定プロセスの最後に変更できるようにしておくことをお勧めします。
-
SageMaker AI の場合
-
推論に使用する機械学習コンポーネントが設定され、使用できる状態になっている必要があります。Aurora MySQL DB クラスターの設定プロセス時に、SageMaker AI エンドポイントの ARN を用意する必要があります。SageMaker AI と連携してモデルを準備し、その他のタスクを処理するのは、チームのデータサイエンティストが最も適任だと考えられます。Amazon SageMaker AI を使い始めるには、「Get Started with Amazon SageMaker AI」を参照してください。推論とエンドポイントの詳細については、「リアルタイム推論」を参照してください。
-
SageMaker AI を独自のトレーニングデータで使用するには、Aurora MySQL の設定の一部として、Aurora 機械学習用に Amazon S3 バケットを設定する必要があります。これを行うには、SageMaker AI の統合設定の場合と同じ一般的なプロセスに従います。このオプションの設定プロセスの概要については、「SageMaker AI に Amazon S3 を使用するように Aurora MySQL DB クラスターを設定する (オプション)」を参照してください。
-
-
Aurora グローバルデータベースでは、Aurora グローバルデータベースを構成するすべての AWS リージョン で使用する Aurora 機械学習サービスを設定します。例えば、Aurora グローバルデータベースで Aurora 機械学習を SageMaker AI によって使用する場合は、すべての AWS リージョンにある Aurora MySQL DB クラスターごとに次のことを行います。
-
同じ SageMaker AI トレーニングモデルとエンドポイントで、Amazon SageMaker AI サービスを設定します。これらには同じ名前を使用する必要があります。
-
「Aurora 機械学習を使用するように Aurora MySQL DB クラスターを設定する」の説明のとおりに IAM ロールを作成します。
-
すべての AWS リージョン にある 各 Aurora MySQL DB クラスターのパラメータグループに、IAM ロールの ARN を追加します。
これらのタスクでは、Aurora グローバルデータベースを構成するすべての AWS リージョン にある Aurora MySQL のバージョンで Aurora 機械学習を利用できる必要があります。
-
利用可能なリージョンとバージョン
利用できる機能とそのサポートは、各 Aurora データベースエンジンの特定のバージョン、および AWS リージョン によって異なります。
-
Amazon Comprehend と Amazon SageMaker AI を利用できる Aurora MySQL のバージョンとリージョンの詳細については、「Aurora MySQL を使用した Aurora Machine Learning」を参照してください。
-
Amazon Bedrock は Aurora MySQL バージョン 3.06 以降でのみサポートされています。
Amazon Bedrock で利用できるリージョンについては、「Amazon Bedrock ユーザーガイド」の「Model support by AWS リージョン」を参照してください。
Aurora MySQL で Aurora 機械学習を使用する場合にサポートされている機能と制限事項
Aurora MySQL を Aurora 機械学習と合わせて使用する場合、次の制限事項が適用されます。
-
Aurora 機械学習の拡張機能は、ベクトルインターフェイスをサポートしていません。
-
Aurora 機械学習の統合は、トリガーで使用した場合はサポートされません。
Aurora 機械学習の関数はバイナリロギング (バイナリログ) レプリケーションと互換性がありません。
-
設定
--binlog-format=STATEMENTは、Aurora Machine Learning 関数の呼び出しに対して例外をスローします。 -
Aurora の機械学習関数はすべて非決定的であり、非決定的なストアド関数がこの binlog 形式と互換性がないためです。
詳細については、MySQL ドキュメントの「バイナリログ形式
」を参照してください。 -
-
常に生成される列を持つテーブルを呼び出すストアド関数はサポートされていません。これはすべての Aurora MySQL ストアド関数に適用されます。このカラムタイプの詳細については、MySQL ドキュメントの「CREATE TABLE と生成された列
」を参照してください。 -
Amazon Bedrock の関数は
RETURNS JSONをサポートしていません。必要に応じて、TEXTからJSONに変換するのにCONVERTまたはCASTを使用できます。 -
Amazon Bedrock はバッチリクエストをサポートしていません。
-
Aurora MySQL は、
ContentTypeのtext/csv値を介して、カンマ区切り値 (CSV) 形式を読み書きする SageMaker AI エンドポイントをサポートしています。この形式は以下の組み込みの SageMaker AI アルゴリズムで受け入れられています。-
線形学習
-
ランダムカットフォレスト
-
XGBoost
これらのアルゴリズムの詳細については、「Amazon SageMaker デベロッパーガイド」の「Choose an Algorithm」を参照してください。
-
Aurora 機械学習を使用するように Aurora MySQL DB クラスターを設定する
以下のトピックでは、これらの Aurora 機械学習サービスごとに個別の設定手順を参照できます。
トピック
Amazon Bedrock を使用するための Aurora MySQL DB クラスターのセットアップ
Aurora 機械学習では、Aurora MySQL DB クラスターが Amazon Bedrock サービスにアクセスして使用できるように、AWS Identity and Access Management (IAM) ロールとポリシーに依存します。以下の手順では、DB クラスターを Amazon Bedrock と統合できるように IAM アクセス許可ポリシーとロールを作成します。
IAM ポリシーを作成するには
AWS Management Console にサインインして、IAM コンソール (https://console.aws.amazon.com/iam/
) を開きます。 -
ナビゲーションペインで、[ポリシー] を選択します。
-
[ポリシーの作成] を選択します。
-
[アクセス許可を指定] ページの [サービスの選択] で、[Bedrock] を選択します。
Amazon Bedrock のアクセス許可が表示されます。
-
[読み取り] を展開し、[InvokeModel] を選択します。
-
[リソース] で [すべて] を選択します。
[アクセス許可を指定] ページは次の図のようになるはずです。
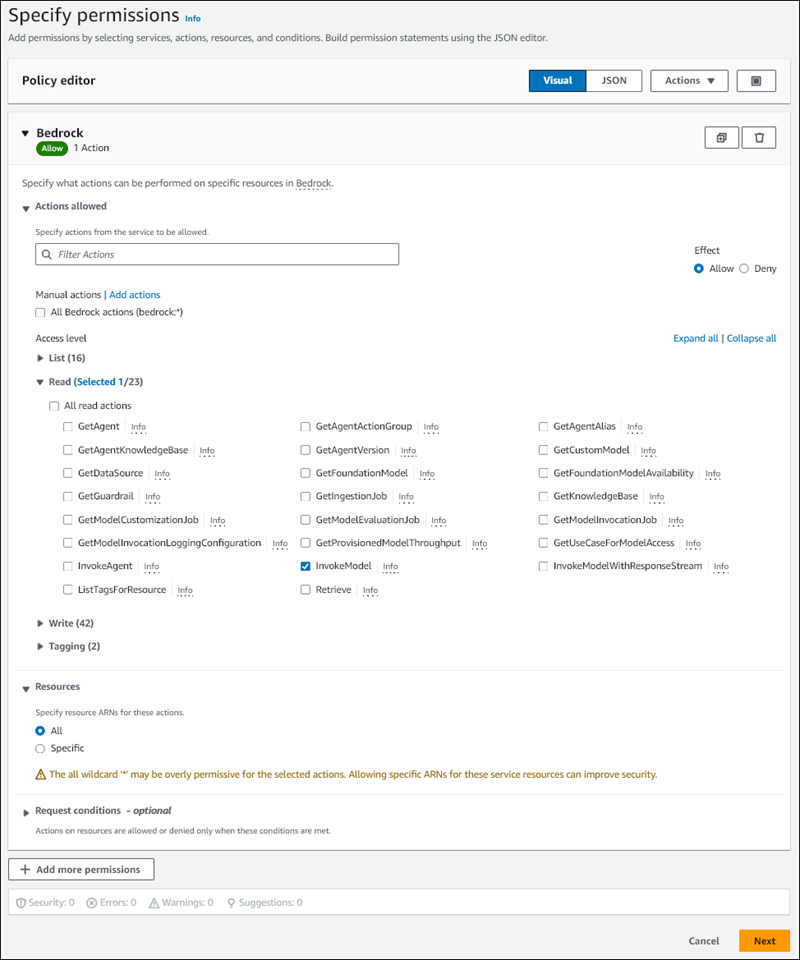
-
[Next] を選択します。
-
[レビューして作成] ページで、
BedrockInvokeModelなど、ポリシーに名前を入力します。 -
ポリシーを確認してから、[ポリシーを作成] を選択します。
次に、Amazon Bedrock のアクセス許可ポリシーを使用する IAM ロールを作成します。
IAM ロールを作成するには
AWS Management Console にサインインして、IAM コンソール (https://console.aws.amazon.com/iam/
) を開きます。 -
ナビゲーションペインで [ロール] を選択します。
-
[ロールの作成] を選択します。
-
[信頼されたエンティティを選択] ページの [ユースケース] で [RDS] を選択します。
-
[RDS - データベースにロールを追加] を選択し、[次へ] を選択します。
-
[アクセス許可を追加] ページの [アクセス許可ポリシー] で、作成した IAM ポリシーを選択し、[次へ] を選択します。
-
[名前、確認および作成] ページで、
ams-bedrock-invoke-model-roleなど、ロールに名前を入力します。ロールは以下の図ようになるはずです。
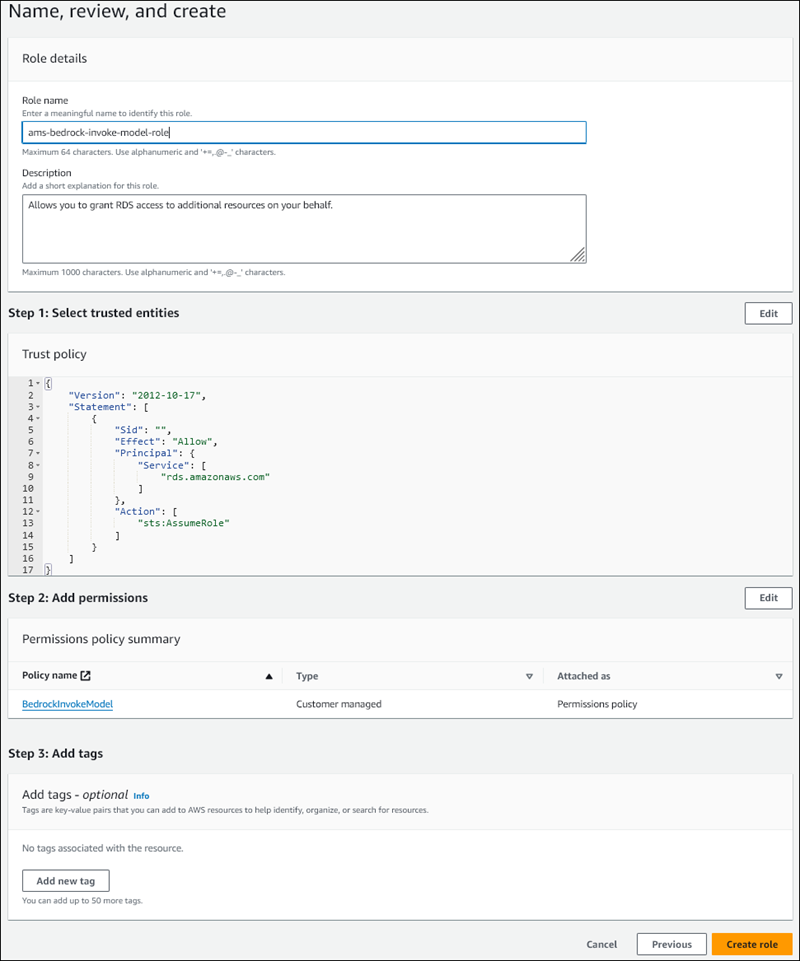
-
ロールを確認し、[ロールを作成] を選択します。
次に、Amazon Bedrock の IAM ロールを DB クラスターに関連付けます。
IAM ロールを DB クラスターと関連付けるには
AWS Management Console にサインインし、Amazon RDS コンソール https://console.aws.amazon.com/rds/
を開きます。 -
ナビゲーションペインから [Databases (データベース)] を選択します。
-
Amazon Bedrock サービスに接続する Aurora MySQL DB クラスターを選択します。
-
[Connectivity & security (接続とセキュリティ)] タブを選択します。
-
[IAM ロールの管理] セクションで、[このクラスターに追加する IAM を選択] を選択します。
-
作成した IAM を選択し、[ロールを追加] を選択します。
IAM ロールは DB クラスターに関連付けられます。最初は [保留中] というステータスで、次に [アクティブ] になります。プロセスが完了すると、このクラスターの現在の IAM ロールリストにロールが表示されます。
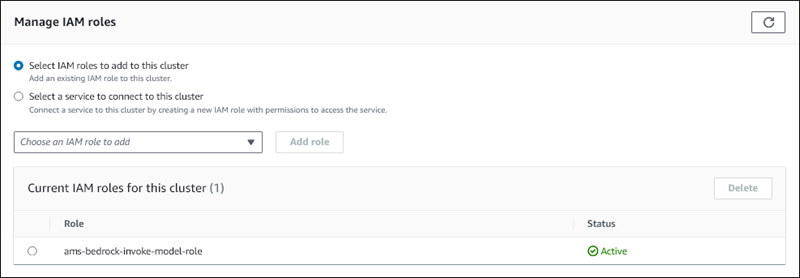
Aurora MySQL DB クラスターに関連付けられているカスタム DB クラスターのパラメータグループの aws_default_bedrock_role パラメータにこの IAM ロールの ARN を追加する必要があります。Aurora MySQL DB クラスターでカスタム DB クラスターパラメータグループを使用していない場合は、Aurora MySQL DB クラスターで使用するパラメータグループを作成して、統合を完了させる必要があります。詳細については、「Amazon Aurora DB クラスターの DB クラスターパラメータグループ」を参照してください。
DB クラスターパラメータを設定するには
-
Amazon RDS コンソールで、Aurora MySQL DB クラスターの [Configuration] (設定) タブを開きます。
-
クラスター用に設定された DB クラスターパラメータグループを検索します。リンクを選択してカスタム DB クラスターパラメータグループを開き、[編集] を選択します。
-
DB クラスターパラメータグループから
aws_default_bedrock_roleパラメータを検索します。 -
[値] フィールドで、IAM ロールの ARN を入力します。
-
[Save changes] (変更の保存) を選択して設定を保存します。
-
このパラメータ設定を有効にするために、Aurora MySQL DB クラスターのプライマリインスタンスを再起動します。
Amazon Bedrock の IAM 統合が完了しました。データベースユーザーに Aurora 機械学習へのアクセスを許可する で Amazon Bedrock を使用するために Aurora MySQL DB クラスターのセットアップを継続します。
Amazon Comprehend を使用するように Aurora MySQL DB クラスターを設定する
Aurora 機械学習では、Aurora MySQL DB クラスターが Amazon Comprehend サービスにアクセスして使用できるように、AWS Identity and Access Management ロールとポリシーに依存します。以下の手順では、クラスターで Amazon Comprehend を使用できるように、IAM ロールとポリシーを自動的に作成します。
Amazon Comprehend を使用するように Aurora MySQL DB クラスターを設定には
AWS Management Console にサインインし、Amazon RDS コンソール https://console.aws.amazon.com/rds/
を開きます。 -
ナビゲーションペインから [Databases (データベース)] を選択します。
-
Amazon Comprehend サービスに接続する Aurora MySQL DB クラスターを選択します。
-
[Connectivity & security (接続とセキュリティ)] タブを選択します。
-
[IAM ロールの管理] セクションまでスクロールして、[このクラスターに接続するサービスを選択] を選択します。
-
メニューから [Amazon Comprehend]を選択し、[サービスを接続] を選択します。
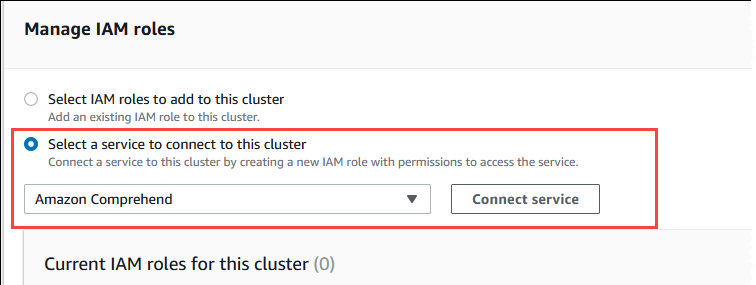
[Connect cluster to Amazon Comprehend] (クラスターを Amazon Comprehend に接続する) ダイアログには、追加情報は必要ありません。ただし、Aurora と Amazon Comprehend の統合が現在プレビュー中であることを通知するメッセージが表示される場合があります。次に進む前に、そのメッセージを必ずお読みください。続行しない場合は、[キャンセル] を選択できます。
[Connect service] (サービスに接続する) を選択して統合プロセスを完了します。
Aurora は IAM ロールを作成します。また、Aurora MySQL DB クラスターが Amazon Comprehend サービスを使用することを許可するポリシーを作成し、そのポリシーをロールにアタッチします。プロセスが完了すると、次の画像に示すように、このクラスターの現在の IAM ロールリストにロールが表示されます。
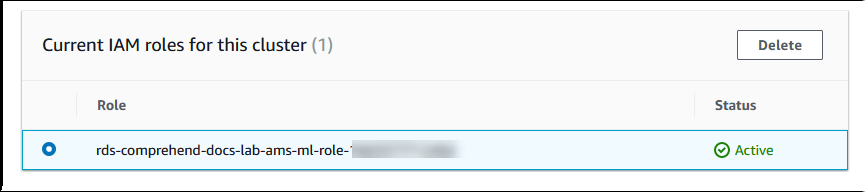
Aurora MySQL DB クラスターに関連付けられているカスタム DB クラスターのパラメータグループの
aws_default_comprehend_roleパラメータにこの IAM ロールの ARN を追加する必要があります。Aurora MySQL DB クラスターでカスタム DB クラスターパラメータグループを使用していない場合は、Aurora MySQL DB クラスターで使用するパラメータグループを作成して、統合を完了させる必要があります。(詳しくは、「Amazon Aurora DB クラスターの DB クラスターパラメータグループ」を参照してください。)カスタム DB クラスターパラメータグループを作成し、Aurora MySQL DB クラスターに関連付けると、以下の手順の実行を継続できます。
クラスターがカスタム DB クラスターパラメータグループを使用している場合は、以下のようにします。
Amazon RDS コンソールで、Aurora MySQL DB クラスターの [Configuration] (設定) タブを開きます。
-
クラスター用に設定された DB クラスターパラメータグループを検索します。リンクを選択してカスタム DB クラスターパラメータグループを開き、[編集] を選択します。
DB クラスターパラメータグループから
aws_default_comprehend_roleパラメータを検索します。[値] フィールドで、IAM ロールの ARN を入力します。
[Save changes] (変更の保存) を選択して設定を保存します。次の画像に、その例が示されています。
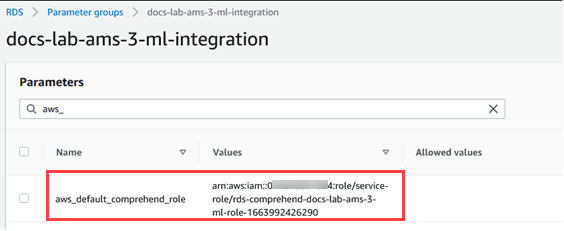
このパラメータ設定を有効にするために、Aurora MySQL DB クラスターのプライマリインスタンスを再起動します。
Amazon Comprehend の IAM 統合が完了しました。適切なデータベースユーザーにアクセス権を付与して、Amazon Comprehend と連携するように Aurora MySQL DB クラスターの設定を続けてください。
SageMaker AI を使用するように Aurora MySQL DB クラスターを設定する
以下の手順では、Aurora MySQL DB クラスターで SageMaker AI を使用できるように、IAM ロールとポリシーを自動的に作成します。この手順を実行する前に、SageMaker AI エンドポイントが使用可能であることを確認し、必要なときに入力できるようにしてください。通常、チームのデータサイエンティストによって Aurora MySQL DB クラスターから使用できるエンドポイントを作成する作業を行います。こうしたエンドポイントは SageMaker AI コンソール
SageMaker AI を使用するように Aurora MySQL DB クラスターを設定するには
AWS Management Console にサインインし、Amazon RDS コンソール https://console.aws.amazon.com/rds/
を開きます。 -
Amazon RDS のナビゲーションメニューから [データベース] を選択して、SageMaker AI サービスに接続する Aurora MySQL DB クラスターを選択します。
-
[Connectivity & security (接続とセキュリティ)] タブを選択します。
-
[Manage IAM roles] (IAM ロールの管理) セクションまでスクロールして、[Select a service to connect to this cluster] (このクラスターに接続するサービスの選択) を選択します。セレクタから [SageMaker AI] を選択します。
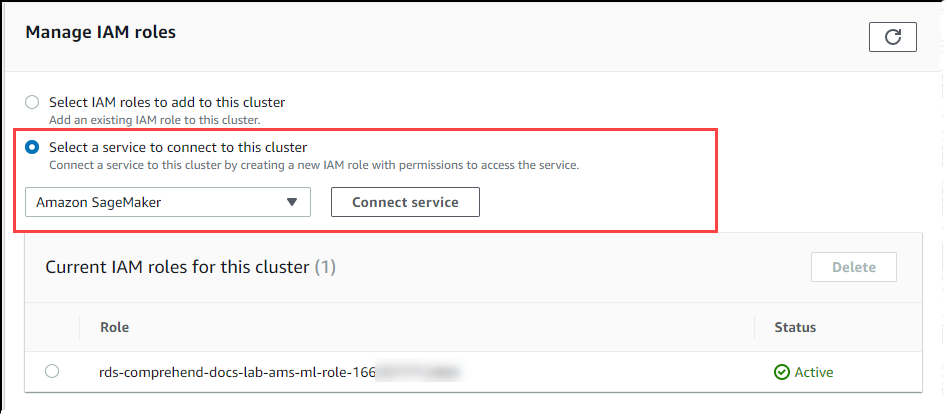
[Connect service (サービスの接続)] を選択します。
[クラスターを SageMaker AI に接続する] ダイアログで、SageMaker AI エンドポイントの ARN を入力します。
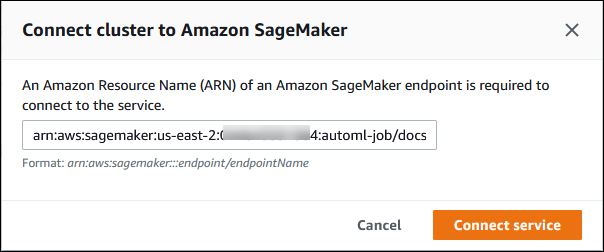
-
Aurora は IAM ロールを作成します。また、Aurora MySQL DB クラスターが SageMaker AI サービスを使用することを許可するポリシーを作成し、そのポリシーをロールにアタッチします。プロセスが完了すると、このクラスターの現在の IAM ロールリストにロールが表示されます。
IAM コンソール (https://console.aws.amazon.com/iam/
) を開きます。 AWS Identity and Access Management ナビゲーションメニューの [Access management] (アクセス管理) セクションから [Roles] (ロール) を選択します。
リストの中からロールを検索します。その名前は、次のパターンを使用しています。
rds-sagemaker-your-cluster-name-role-auto-generated-digitsロールの [Summary] (概要) ページを開いて ARN を検索します。ARN をメモするか、コピーウィジェットでコピーします。
Amazon RDS コンソール (https://console.aws.amazon.com/rds/
) を開きます。 Aurora MySQL DB クラスターを選択して、その [Configuration] (設定) タブを選択します。
DB クラスターパラメータグループを検索し、リンクを選択してカスタム DB クラスターパラメータグループを開きます。
aws_default_sagemaker_roleパラメータを検索し、[Value] (値) フィールドに IAM ロールの ARN を入力して、[Save] (保存) で設定を保存します。このパラメータ設定を有効にするために、Aurora MySQL DB クラスターのプライマリインスタンスを再起動します。
IAM の設定が完了しました。適切なデータベースユーザーにアクセス権を付与して、SageMaker AI と連携するように Aurora MySQL DB クラスターの設定を続けてください。
構築済みの SageMaker AI コンポーネントを使用せず、SageMaker AI モデルをトレーニングに使用する場合は、次の「SageMaker AI に Amazon S3 を使用するように Aurora MySQL DB クラスターを設定する (オプション)」の説明のように Amazon S3 バケットを Aurora MySQL DB クラスターに追加する必要もあります。
SageMaker AI に Amazon S3 を使用するように Aurora MySQL DB クラスターを設定する (オプション)
SageMaker AI が提供する構築済みコンポーネントを使用せず、独自のモデルで SageMaker AI を使用するには、Aurora MySQL DB クラスターが使用する Amazon S3 バケットを設定する必要があります。Amazon S3 バケットの作成の詳細については、Amazon Simple Storage Service ユーザーガイドの「バケットの作成」を参照してください。
SageMaker AI に Amazon S3 バケットを使用するように Aurora MySQL DB クラスターを設定するには
AWS Management Console にサインインし、Amazon RDS コンソール https://console.aws.amazon.com/rds/
を開きます。 -
Amazon RDS のナビゲーションメニューから [データベース] を選択して、SageMaker AI サービスに接続する Aurora MySQL DB クラスターを選択します。
-
[Connectivity & security (接続とセキュリティ)] タブを選択します。
-
[Manage IAM roles] (IAM ロールの管理) セクションまでスクロールして、[Select a service to connect to this cluster] (このクラスターに接続するサービスの選択) を選択します。セレクタから [Amazon S3] を選択します。
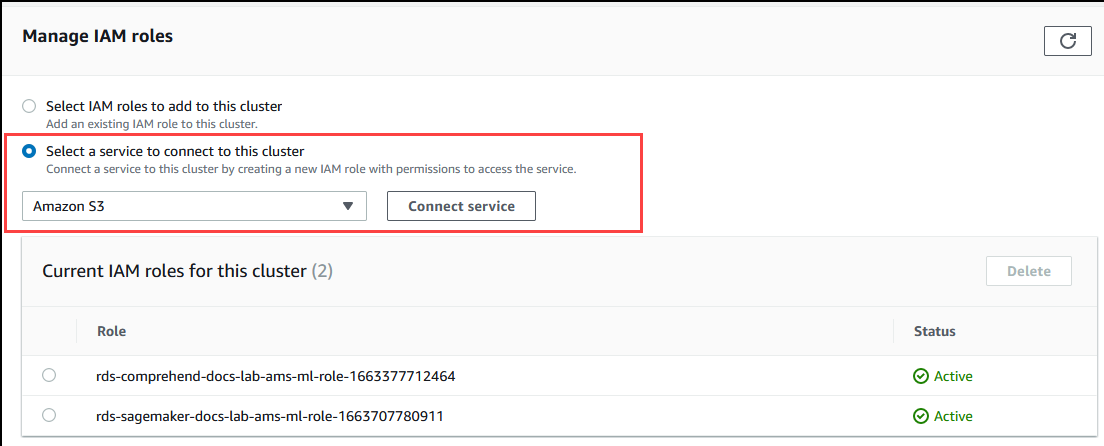
[Connect service (サービスの接続)] を選択します。
[クラスターを Amazon S3 に接続する] ダイアログで、以下の画像のように Amazon S3 バケットの ARN を入力します。
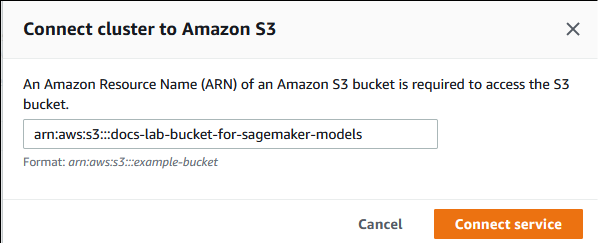
[Connect service] (サービスに接続する) を選択してこのプロセスを完了します。
SageMaker で Amazon S3 バケットを使用する方法の詳細については、「Amazon SageMaker AI デベロッパーガイド」の「Specify an Amazon S3 Bucket to Upload Training Datasets and Store Output Data」を参照してください。SageMaker AI の使用方法の詳細については、「Amazon SageMaker AI デベロッパーガイド」の「Get Started with Amazon SageMaker AI Notebook Instances」を参照してください。
データベースユーザーに Aurora 機械学習へのアクセスを許可する
データベースユーザーには、Aurora 機械学習の関数を呼び出すアクセス許可を付与する必要があります。権限の付与方法は、以下の説明のように、Aurora MySQL DB クラスターに使用する MySQL のバージョンによって異なります。その方法は、Aurora MySQL DB クラスターが使用する MySQL のバージョンによって異なります。
Aurora MySQL バージョン 3 (MySQL 8.0 互換) の場合、データベースユーザーに適切なデータベースロールを付与する必要があります。詳細については、「MySQL 8.0 リファレンスマニュアル」の「ロールの使用
」を参照してください。 Aurora MySQL バージョン 2 (MySQL 5.7 互換) の場合、データベースユーザーに権限が付与されます。詳細は、「MySQL 5.7 リファレンスマニュアル」の「アクセスコントロールおよびアカウントマネジメント
」を参照してください。
次の表は、データベースユーザーが機械学習の関数を使用するために必要なロールと権限を示しています。
| Aurora MySQL バージョン 3 (ロール) | Aurora MySQL バージョン 2 (権限) |
|---|---|
|
AWS_BEDROCK_ACCESS |
– |
|
AWS_COMPREHEND_ACCESS |
INVOKE COMPREHEND |
|
AWS_SAGEMAKER_ACCESS |
INVOKE SAGEMAKER |
Amazon Bedrock の関数へのアクセスの付与
データベースユーザーが Amazon Bedrock の関数にアクセスできるようにするには、次の SQL ステートメントを使用します。
GRANT AWS_BEDROCK_ACCESS TOuser@domain-or-ip-address;
データベースユーザーには、Amazon Bedrock と連携するために作成した関数の EXECUTE アクセス許可も付与する必要があります。
GRANT EXECUTE ON FUNCTIONdatabase_name.function_nameTOuser@domain-or-ip-address;
最後に、データベースユーザーは各自のロールを AWS_BEDROCK_ACCESS に設定する必要があります。
SET ROLE AWS_BEDROCK_ACCESS;
これで Amazon Bedrock の関数が使用可能になりました。
Amazon Comprehend 関数へのアクセスを許可する
データベースユーザーが Amazon Comprehend 関数にアクセスできるようにするには、Aurora MySQL バージョンに適合した適切なステートメントを使用します。
Aurora MySQL バージョン 3 (MYSQL 8.0 互換)
GRANT AWS_COMPREHEND_ACCESS TOuser@domain-or-ip-address;Aurora MySQL バージョン 2 (MYSQL 5.7 互換)
GRANT INVOKE COMPREHEND ON *.* TOuser@domain-or-ip-address;
Amazon Comprehend 関数が使用可能になりました。使用例については、「Aurora MySQL DB クラスターで Amazon Comprehend を使用する」を参照してください。
SageMaker AI 関数へのアクセス権の付与
データベースユーザーが SageMaker AI 関数にアクセスできるようにするには、Aurora MySQL バージョンに適合した適切なステートメントを使用します。
Aurora MySQL バージョン 3 (MYSQL 8.0 互換)
GRANT AWS_SAGEMAKER_ACCESS TOuser@domain-or-ip-address;Aurora MySQL バージョン 2 (MYSQL 5.7 互換)
GRANT INVOKE SAGEMAKER ON *.* TOuser@domain-or-ip-address;
データベースユーザーには、SageMaker AI と連携するために作成した関数の EXECUTE 権限も付与する必要があります。SageMaker AI エンドポイントのサービスを呼び出すために、db1.anomoly_score と db2.company_forecasts という 2 つの関数を作成したとします。以下の例に示すように EXECUTE 権限を付与します。
GRANT EXECUTE ON FUNCTION db1.anomaly_score TOuser1@domain-or-ip-address1; GRANT EXECUTE ON FUNCTION db2.company_forecasts TOuser2@domain-or-ip-address2;
これで SageMaker AI 関数が使用できるようになりました。使用例については、「Aurora MySQL DB クラスターで SageMaker AI を使用する」を参照してください。
Aurora MySQL DB クラスターでの Amazon Bedrock の使用
Amazon Bedrock を使用するには、モデルを呼び出すユーザー定義関数 (UDF) を Aurora MySQL データベースに作成します。詳細については、「Amazon Bedrock ユーザーガイド」の「Amazon Bedrock でサポートされているモデル」を参照してください。
UDF は次の構文を使用します。
CREATE FUNCTIONfunction_name(argumenttype) [DEFINER = user] RETURNSmysql_data_type[SQL SECURITY {DEFINER | INVOKER}] ALIAS AWS_BEDROCK_INVOKE_MODEL MODEL ID 'model_id' [CONTENT_TYPE 'content_type'] [ACCEPT 'content_type'] [TIMEOUT_MStimeout_in_milliseconds];
-
Amazon Bedrock の関数は
RETURNS JSONをサポートしていません。必要に応じて、TEXTからJSONに変換するのにCONVERTまたはCASTを使用できます。 -
CONTENT_TYPEまたはACCEPTを指定しなかった場合、デフォルトはapplication/jsonです。 -
TIMEOUT_MSを指定しなかった場合、aurora_ml_inference_timeoutの値が使用されます。
例えば、次の UDF は Amazon Titan Text Express モデルを呼び出します。
CREATE FUNCTION invoke_titan (request_body TEXT) RETURNS TEXT ALIAS AWS_BEDROCK_INVOKE_MODEL MODEL ID 'amazon.titan-text-express-v1' CONTENT_TYPE 'application/json' ACCEPT 'application/json';
DB ユーザーがこの関数を使用できるようにするには、次の SQL コマンドを使用します。
GRANT EXECUTE ON FUNCTIONdatabase_name.invoke_titan TOuser@domain-or-ip-address;
これで、以下の例に示されているように、ユーザーは他の関数と同様に invoke_titan を呼び出すことができます。Amazon Titan のテキストモデルに従って、リクエスト本文をフォーマットしてください。
CREATE TABLE prompts (request varchar(1024)); INSERT INTO prompts VALUES ( '{ "inputText": "Generate synthetic data for daily product sales in various categories - include row number, product name, category, date of sale and price. Produce output in JSON format. Count records and ensure there are no more than 5.", "textGenerationConfig": { "maxTokenCount": 1024, "stopSequences": [], "temperature":0, "topP":1 } }'); SELECT invoke_titan(request) FROM prompts; {"inputTextTokenCount":44,"results":[{"tokenCount":296,"outputText":" ```tabular-data-json { "rows": [ { "Row Number": "1", "Product Name": "T-Shirt", "Category": "Clothing", "Date of Sale": "2024-01-01", "Price": "$20" }, { "Row Number": "2", "Product Name": "Jeans", "Category": "Clothing", "Date of Sale": "2024-01-02", "Price": "$30" }, { "Row Number": "3", "Product Name": "Hat", "Category": "Accessories", "Date of Sale": "2024-01-03", "Price": "$15" }, { "Row Number": "4", "Product Name": "Watch", "Category": "Accessories", "Date of Sale": "2024-01-04", "Price": "$40" }, { "Row Number": "5", "Product Name": "Phone Case", "Category": "Accessories", "Date of Sale": "2024-01-05", "Price": "$25" } ] } ```","completionReason":"FINISH"}]}
使用する他のモデルについては、リクエスト本文をそのモデルに合わせて適切にフォーマットしてください。詳細については、「Amazon Bedrock ユーザーガイド」の「基盤モデルの推論パラメータ」を参照してください。
Aurora MySQL DB クラスターで Amazon Comprehend を使用する
Aurora MySQL の場合、Aurora 機械学習には Amazon Comprehend とテキストデータを操作するために、次のような 2 つの組み込み関数が用意されています。分析するテキスト (input_data) と言語 (language_code) を指定します。
- aws_comprehend_detect_sentiment
-
この関数は、テキストの感情的な姿勢がポジティブ、中立、ネガティブ、または混合かを識別します。この関数のリファレンスドキュメントは次のとおりです。
aws_comprehend_detect_sentiment( input_text, language_code [,max_batch_size] )詳細については、「Amazon Comprehend デベロッパーガイド」の「感情」を参照してください。
- aws_comprehend_detect_sentiment_confidence
-
この関数は、特定のテキストについて検出された感情の信頼度を測定します。aws_comprehend_detect_sentiment 関数によってテキストに割り当てられた感情の信頼度を示す値 (タイプ
double) を返します。信頼度は 0 ~ 1 の間の統計的メトリクスです。信頼度が高いほど、その結果に与える重みが増えます。関数のドキュメントの概要は次のとおりです。aws_comprehend_detect_sentiment_confidence( input_text, language_code [,max_batch_size] )
いずれの関数 (aws_comprehend_detect_sentiment_confidence、aws_comprehend_detect_sentiment) において、指定がない場合は max_batch_size にはデフォルト値である 25 を使用します。バッチサイズは常に 0 より大きい必要があります。max_batch_size を使用すると、Amazon Comprehend 関数呼び出しのパフォーマンスを調整しやすくなります。バッチサイズを大きくすると、Aurora MySQL DB クラスターでのメモリ使用量が増えるため、パフォーマンスが加速します。(詳しくは、「Aurora MySQL で Aurora 機械学習を使用した場合のパフォーマンスに関する考慮事項」を参照してください。)
Amazon Comprehend の感情検出関数のパラメータと戻り値のタイプについては、「DetectSentiment」を参照してください。
例: Amazon Comprehend 関数を使用する簡単なクエリ
ここでは、この 2 つの関数を呼び出して、サポートチームに対する顧客満足度を確認する簡単なクエリの例を示します。ヘルプをリクエストするたびに顧客からのフィードバックを保存するデータベーステーブル (support) があるとします。このクエリ例では、両方の組み込み関数をテーブルの feedback 列のテキストに適用し、結果を出力します。この関数によって返される信頼値は、0.0 ~ 1.0 の間の倍数です。出力の読みやすさを向上させるため、このクエリでは小数点以下を 6 桁に丸めて結果を出力します。比較しやすいように、このクエリでは信頼度が最も高い結果から降順で結果をソートします。
SELECT feedback AS 'Customer feedback', aws_comprehend_detect_sentiment(feedback, 'en') AS Sentiment, ROUND(aws_comprehend_detect_sentiment_confidence(feedback, 'en'), 6) AS Confidence FROM support ORDER BY Confidence DESC;+----------------------------------------------------------+-----------+------------+ | Customer feedback | Sentiment | Confidence | +----------------------------------------------------------+-----------+------------+ | Thank you for the excellent customer support! | POSITIVE | 0.999771 | | The latest version of this product stinks! | NEGATIVE | 0.999184 | | Your support team is just awesome! I am blown away. | POSITIVE | 0.997774 | | Your product is too complex, but your support is great. | MIXED | 0.957958 | | Your support tech helped me in fifteen minutes. | POSITIVE | 0.949491 | | My problem was never resolved! | NEGATIVE | 0.920644 | | When will the new version of this product be released? | NEUTRAL | 0.902706 | | I cannot stand that chatbot. | NEGATIVE | 0.895219 | | Your support tech talked down to me. | NEGATIVE | 0.868598 | | It took me way too long to get a real person. | NEGATIVE | 0.481805 | +----------------------------------------------------------+-----------+------------+ 10 rows in set (0.1898 sec)
例: 特定の信頼度を超えるテキストの平均感情を判別する。
一般的な Amazon Comprehend クエリは、感情が特定の値であり、かつ信頼レベルが特定の数値より大きい行を検索します。例えば、次のクエリは、データベース内のドキュメントの平均感情を判別する方法を示しています。クエリでは、評価の信頼度が 80% 以上のドキュメントのみが考慮されます。
SELECT AVG(CASE aws_comprehend_detect_sentiment(productTable.document, 'en') WHEN 'POSITIVE' THEN 1.0 WHEN 'NEGATIVE' THEN -1.0 ELSE 0.0 END) AS avg_sentiment, COUNT(*) AS total FROM productTable WHERE productTable.productCode = 1302 AND aws_comprehend_detect_sentiment_confidence(productTable.document, 'en') >= 0.80;
Aurora MySQL DB クラスターで SageMaker AI を使用する
Aurora MySQL DB クラスターから SageMaker AI 関数を使用するには、SageMaker AI エンドポイントとその推論機能への呼び出しを埋め込むストアド関数を作成する必要があります。そのためには、Aurora MySQL DB クラスターの他の処理タスクと同じように MySQL の CREATE FUNCTION を使用します。
推論のために SageMaker AI にデプロイされたモデルを使用するには、ストアド関数の MySQL データ定義言語 (DDL) ステートメントを使用して、ユーザー定義関数を作成します。各ストアド関数は、モデルをホストする SageMaker AI エンドポイントを表します。そのような関数を定義するときには、モデルへの入力パラメータ、呼び出す特定の SageMaker AI エンドポイント、および戻り値の型を指定します。この関数は、モデルを入力パラメータに適用した後、SageMaker AI エンドポイントによって計算された推論を返します。
すべての Aurora 機械学習ストアド関数が、数値型または VARCHAR を返します。BIT 以外の数値型を使用できます。JSON、BLOB、TEXT、DATE などの型は使用できません。
以下の例は、SageMaker AI を操作するための CREATE FUNCTION 構文を示しています。
CREATE FUNCTION function_name (
arg1 type1,
arg2 type2, ...)
[DEFINER = user]
RETURNS mysql_type
[SQL SECURITY { DEFINER | INVOKER } ]
ALIAS AWS_SAGEMAKER_INVOKE_ENDPOINT
ENDPOINT NAME 'endpoint_name'
[MAX_BATCH_SIZE max_batch_size];
これは通常の CREATE FUNCTION DDL ステートメントの拡張です。SageMaker AI 関数を定義する CREATE FUNCTION ステートメントでは、関数本体を指定しません。代わりに、関数本体が通常実行されるキーワード ALIAS を指定します。Aurora 機械学習は現在、この拡張構文の aws_sagemaker_invoke_endpoint のみをサポートしています。endpoint_name パラメータを指定する必要があります。SageMaker AI エンドポイントは、モデルごとに異なる特性を持つことができます。
注記
CREATE FUNCTION の詳細については、「MySQL 8.0 リファレンスマニュアルの」の「CREATE PROCEDURE および CREATE FUNCTION ステートメント
max_batch_size パラメータはオプションです。デフォルトでは、最大バッチサイズは 10,000 です。このパラメータを関数で使用すると、SageMaker AI へのバッチリクエストで処理される入力の最大数を制限できます。max_batch_size パラメータを使用すると、大きすぎる入力によって引き起こされるエラーを回避したり、SageMaker AI からレスポンスが返される時間を短縮したりすることができます。このパラメータは、SageMaker AI リクエスト処理に使用される内部バッファのサイズに影響します。max_batch_size に指定する値が大きすぎると、DB インスタンスでかなりの規模のメモリオーバーヘッドが発生する可能性があります。
MANIFEST の設定はデフォルト値 OFF のままにすることをお勧めします。MANIFEST ON オプションを使用できますが、一部の SageMaker AI 機能では、このオプションでエクスポートされた CSV を直接使用できません。マニフェスト形式は、SageMaker AI から期待されるマニフェスト形式と互換性がありません。
SageMaker AI モデルごとに個別のストアド関数を作成します。エンドポイントが特定のモデルに関連付けられ、各モデルは異なるパラメータを受け入れるため、このように関数をモデルにマッピングする必要があります。モデル入力とモデル出力タイプに SQL タイプを使用すると、AWS サービス間でデータをやり取りするタイプ変換エラーを回避できます。モデルを適用できるユーザーを制御できます。また、ランタイム特性を制御するには、最大バッチサイズを表すパラメータを指定します。
現在、すべての Aurora 機械学習関数に NOT DETERMINISTIC プロパティがあります。このプロパティを明示的に指定しなかった場合は、Aurora によって自動的に NOT DETERMINISTIC に設定されます。この要件は、データベースに通知せずに SageMaker AI モデルを変更できることで実現しています。その場合、Aurora 機械学習関数を呼び出すと、単一のトランザクション内の同じ入力に対して異なる結果が返される可能性があります。
CONTAINS SQL ステートメントで、特性 NO SQL、READS SQL DATA、MODIFIES SQL DATA、または CREATE
FUNCTION を使用することはできません。
以下は、SageMaker AI エンドポイントを呼び出して異常を検出する使用例です。SageMaker AI エンドポイント random-cut-forest-model があります。対応するモデルは、random-cut-forest アルゴリズムによって既にトレーニングされています。モデルは、入力ごとに異常スコアを返します。この例は、スコアが平均スコアから 3 スタンダード偏差 (約 99.9 パーセンタイル) より大きいデータポイントを示しています。
CREATE FUNCTION anomaly_score(value real) returns real
alias aws_sagemaker_invoke_endpoint endpoint name 'random-cut-forest-model-demo';
set @score_cutoff = (select avg(anomaly_score(value)) + 3 * std(anomaly_score(value)) from nyc_taxi);
select *, anomaly_detection(value) score from nyc_taxi
where anomaly_detection(value) > @score_cutoff;
文字列を返す SageMaker AI 関数の文字セット要件
文字列値を返す SageMaker AI 関数の戻り値の型として、文字セット utf8mb4 を指定することをお勧めします。それが実用的でない場合は、文字セット utf8mb4 で表される値を保持できるよう、戻り値の型に十分な長さの文字列長を使用します。次の例は、関数の文字セット utf8mb4 を宣言する方法を示しています。
CREATE FUNCTION my_ml_func(...) RETURNS VARCHAR(5) CHARSET utf8mb4 ALIAS ...現在、文字列を返す各 SageMaker AI 関数は、戻り値に文字セット utf8mb4 を使用します。SageMaker AI 関数がその戻り値の型に対して暗黙的または明示的に異なる文字セットを宣言している場合でも、戻り値はこの文字セットを使用します。SageMaker AI 関数が戻り値に別の文字セットを宣言している場合、長さが十分でないテーブル列に格納すると、返されたデータが暗黙的に切り捨てられる可能性があります。例えば、DISTINCT 句を含むクエリは、テンポラリテーブルを作成します。したがって、クエリ実行中に文字列が内部的に処理される方法が原因で、SageMaker AI 関数の結果が切り捨てられる場合があります。
SageMaker AI モデルトレーニング用のデータを Amazon S3 にエクスポートする (高度)
提供されているいくつかのアルゴリズムを使用して、Aurora 機械学習と SageMaker AI を使い始めることをお勧めします。また、チームのデータサイエンティストが、SQL コードで使用できる SageMaker AI エンドポイントを提供することをお勧めします。以下に、独自の Amazon S3 バケットを独自の SageMaker AI モデルと Aurora MySQL DB クラスターで使用する方法についての最低限必要な情報を示します。
機械学習は、トレーニングと推論という 2 つの主要な手順で構成されます。SageMaker AI モデルをトレーニングするには、データを Amazon S3 バケットにエクスポートします。Amazon S3 バケットは、モデルをデプロイする前にトレーニングする目的で SageMaker AI ノートブックインスタンスによって使用されます。SELECT INTO OUTFILE S3 ステートメントを使用すると、Aurora MySQL DB クラスターからデータをクエリし、Amazon S3 バケットに保存されているテキストファイルに直接保存できます。これにより、ノートブックインスタンスは、トレーニングのために Amazon S3 バケットからデータを消費します。
Aurora 機械学習は、Aurora MySQL の既存の SELECT INTO OUTFILE 構文を拡張して、データを CSV 形式にエクスポートします。生成された CSV ファイルは、トレーニング目的で、この形式を必要とするモデルで直接使用できます。
SELECT * INTO OUTFILE S3 's3_uri' [FORMAT {CSV|TEXT} [HEADER]] FROM table_name;このエクステンションは、スタンダードの CSV 形式をサポートしています。
-
TEXT形式は、既存の MySQL エクスポート形式と同じです。これがデフォルトの形式です。 -
CSV形式は、RFC-4180の仕様に従って新しく導入された形式です。 -
オプションのキーワード
HEADERを指定すると、出力ファイルに 1 つのヘッダー行が含まれます。ヘッダー行のラベルは、SELECTステートメントの列名に対応します。 -
キーワード
CSVおよびHEADERを引き続き識別子として使用できます。
SELECT INTO の拡張構文と文法は次のとおりです。
INTO OUTFILE S3 's3_uri'
[CHARACTER SET charset_name]
[FORMAT {CSV|TEXT} [HEADER]]
[{FIELDS | COLUMNS}
[TERMINATED BY 'string']
[[OPTIONALLY] ENCLOSED BY 'char']
[ESCAPED BY 'char']
]
[LINES
[STARTING BY 'string']
[TERMINATED BY 'string']
]
Aurora MySQL で Aurora 機械学習を使用した場合のパフォーマンスに関する考慮事項
Amazon Bedrock、Amazon Comprehend、SageMaker AI サービスは、Aurora 機械学習の関数によって呼び出された際には、ほとんどの作業を行います。つまり、これらのリソースを必要に応じて個別にスケーリングできることになります。Aurora MySQL DB クラスターでは、関数呼び出しを最大限効率的に行うことができます。以下に、Aurora 機械学習を使用する際に注意すべきパフォーマンスに関する考慮事項をいくつか示します。
モデルとプロンプト
Amazon Bedrock を使用する場合のパフォーマンスは、使用するモデルとプロンプトに大きく依存します。ユースケースに最適なモデルとプロンプトを選択します。
クエリキャッシュ
Aurora MySQL クエリキャッシュは、Aurora 機械学習関数では機能しません。Aurora MySQL は、Aurora 機械学習関数を呼び出す SQL ステートメントのクエリ結果を、クエリキャッシュに保存しません。
Aurora 機械学習関数呼び出しのバッチ最適化
Aurora クラスターの影響を受ける可能性がある Aurora 機械学習のパフォーマンスの主な側面は、Aurora 機械学習ストアド関数を呼び出すためのバッチモード設定です。通常、機械学習関数はかなりのオーバーヘッドを必要とするため、行ごとに外部サービスを個別に呼び出すことは現実的ではありません。Aurora 機械学習では、多くの行の外部 Aurora 機械学習サービスへの呼び出しを 1 つのバッチに結合することで、このオーバーヘッドを最小限に抑えることができます。Aurora 機械学習は、すべての入力行に対する応答を受け取り、その応答を一度に 1 行ずつ実行中のクエリに返送します。この最適化により、結果を変更せずに Aurora クエリのスループットとレイテンシーが改善されます。
SageMaker AI エンドポイントに接続されている Aurora ストアド関数を作成するときに、バッチサイズパラメータを定義します。このパラメータは、基礎となる SageMaker AI の呼び出しごとに転送される行数に影響します。多数の行を処理するクエリの場合、行ごとに個別の SageMaker AI 呼び出しを行うオーバーヘッドが大規模化する可能性があります。ストアドプロシージャによって処理されるデータセットが大きいほど、バッチサイズを大きくすることができます。
バッチモードの最適化を SageMaker AI 関数に適用できる場合は、EXPLAIN PLAN ステートメントによって生成されたクエリプランを確認することで判断できます。この場合、実行計画の extra 列には Batched machine learning が含まれます。次の例は、バッチモードを使用する SageMaker AI 関数の呼び出しを示しています。
mysql> CREATE FUNCTION anomaly_score(val real) returns real alias aws_sagemaker_invoke_endpoint endpoint name 'my-rcf-model-20191126';
Query OK, 0 rows affected (0.01 sec)
mysql> explain select timestamp, value, anomaly_score(value) from nyc_taxi;
+----+-------------+----------+------------+------+---------------+------+---------+------+------+----------+--------------------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+----------+------------+------+---------------+------+---------+------+------+----------+--------------------------+
| 1 | SIMPLE | nyc_taxi | NULL | ALL | NULL | NULL | NULL | NULL | 48 | 100.00 | Batched machine learning |
+----+-------------+----------+------------+------+---------------+------+---------+------+------+----------+--------------------------+
1 row in set, 1 warning (0.01 sec)
組み込みの Amazon Comprehend 関数の 1 つを呼び出す場合、バッチサイズを制御するには、オプションの max_batch_size パラメータを指定します。このパラメータは、各バッチで処理される input_text 値の最大数を制限します。複数の項目を一度に送信することにより、Aurora と Amazon Comprehend 間の往復回数を減らします。バッチサイズの制限は、LIMIT 句を使用したクエリなどで役立ちます。max_batch_size に小さい値を使用することで、入力テキストより Amazon Comprehend を呼び出す回数が増えるのを回避できます。
Aurora 機械学習関数を評価するためのバッチ最適化は、以下の場合に適用されます。
-
選択リストまたは
SELECTステートメントのWHERE句に含まれる関数呼び出し。 -
INSERTおよびREPLACEステートメントのVALUESリストに含まれる関数呼び出し。 -
UPDATEステートメントのSET値の SageMaker AI 関数。INSERT INTO MY_TABLE (col1, col2, col3) VALUES (ML_FUNC(1), ML_FUNC(2), ML_FUNC(3)), (ML_FUNC(4), ML_FUNC(5), ML_FUNC(6)); UPDATE MY_TABLE SET col1 = ML_FUNC(col2), SET col3 = ML_FUNC(col4) WHERE ...;
Aurora 機械学習のモニタリング
次の例に示すように、複数のグローバル変数をクエリすることで、Aurora 機械学習のバッチオペレーションをモニタリングできます。
show status like 'Aurora_ml%';
このステータス変数をリセットするには、FLUSH STATUS ステートメントを使用します。したがって、可変の最後のリセット以降のすべての数値は、合計、平均などを表します。
Aurora_ml_logical_request_cnt-
前回のステータスリセット以降、DB インスタンスが Aurora 機械学習サービスに送信されると評価した論理リクエストの数。バッチ処理が使用されているかどうかによっては、この値が
Aurora_ml_actual_request_cntより高くなることがあります。 Aurora_ml_logical_response_cnt-
DB インスタンスのユーザーが実行するすべてのクエリで、Aurora MySQL が Aurora 機械学習サービスから受け取るレスポンスの集計カウント。
Aurora_ml_actual_request_cnt-
DB インスタンスのユーザーによって実行されたすべてのクエリで、Aurora MySQL が Aurora 機械学習サービスに対して行ったリクエストの集計カウント。
Aurora_ml_actual_response_cnt-
DB インスタンスのユーザーが実行するすべてのクエリで、Aurora MySQL が Aurora 機械学習サービスから受け取るレスポンスの集計カウント。
Aurora_ml_cache_hit_cnt-
DB インスタンスのユーザーが実行したすべてのクエリで、Aurora MySQL が Aurora 機械学習サービスから受け取る内部キャッシュヒットの集計カウント。
Aurora_ml_retry_request_cnt-
前回のステータスリセット以降、DB インスタンスが Aurora 機械学習サービスに送信した再試行リクエストの数。
Aurora_ml_single_request_cnt-
DB インスタンスのユーザーが実行するすべてのクエリで、非バッチモードで評価される Aurora 機械学習の関数の集計カウント。
Aurora 機械学習機能から呼び出される SageMaker AI オペレーションのパフォーマンスのモニタリングについては、「Monitor Amazon SageMaker AI」を参照してください。
