翻訳は機械翻訳により提供されています。提供された翻訳内容と英語版の間で齟齬、不一致または矛盾がある場合、英語版が優先します。
チュートリアル: Amazon EMR の使用開始
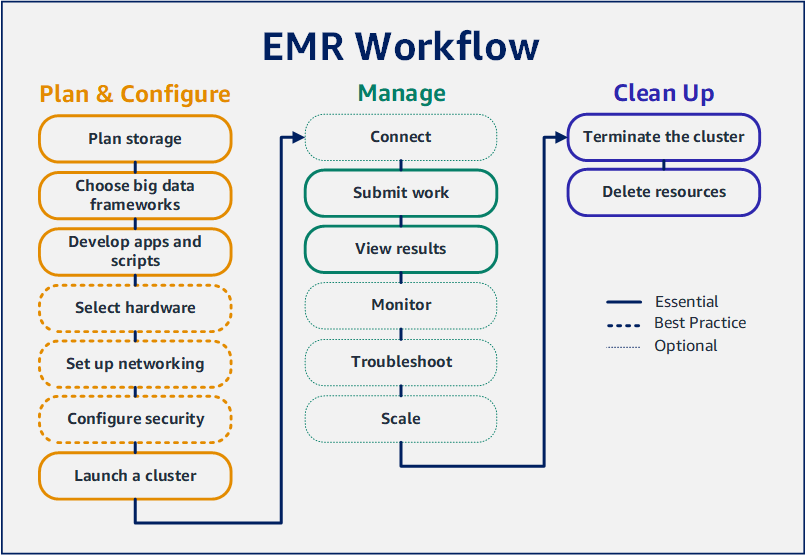
Amazon EMR クラスターを迅速にセットアップし、Spark アプリケーションを実行するワークフローについて、順を追って説明します。
Amazon EMR クラスターを設定する
Amazon EMR を使用すると、ビッグデータフレームワークを使用してデータを処理および分析するクラスターをわずか数分でセットアップできます。このチュートリアルでは、Spark を使用してサンプルクラスターを起動する方法と、Amazon S3 バケットに格納された単純な PySpark スクリプトを実行する方法について説明します。計画と設定、管理、およびクリーンアップという 3 つの主要なワークフローカテゴリにおける Amazon EMR の必須タスクを取り上げます。
チュートリアルの途中には詳細なトピックへのリンクがあります。また、「次のステップ」セクションに追加手順の概要が記載されています。ご質問や不明点がある場合は、ディスカッションフォーラム
前提条件
-
Amazon EMR クラスターを起動する前に、「Amazon EMR を設定する前に」のタスクを完了していることを確認してください。
コスト
-
作成するサンプルクラスターは、ライブ環境で実行されます。クラスターには最低料金が発生します。追加料金が発生しないように、このチュートリアルの最後の手順で必ずクリーンアップタスクを完了してください。料金は、Amazon EMR の料金に従って秒単位で発生します。料金はリージョンによっても異なります。詳細については、「Amazon EMR の料金
」を参照してください。 -
Amazon S3 に保存する小さなファイルについて、最低料金が発生する場合があります。 AWS 無料利用枠の使用制限内であれば、Amazon S3 の一部またはすべての料金が免除される場合があります。詳細については、「Amazon S3 の料金
」と「AWS 無料利用枠 」を参照してください。
ステップ 1: データリソースを構成して、Amazon EMR クラスターを起動する
Amazon EMR 用のストレージを準備する
Amazon EMR を使用するときに、入力データ、出力データ、およびログファイルの保存先をさまざまなファイルシステムから選択できます。このチュートリアルでは、EMRFS を使用して S3 バケットにデータを保存します。EMRFS は、Amazon S3 に対する通常のファイルの読み書きを可能にする Hadoop ファイルシステムの実装です。詳細については、「Amazon EMR でのストレージおよびファイルシステムの使用」を参照してください。
このチュートリアル用にバケットを作成するには、「Amazon Simple Storage Service ユーザーガイド」の「S3 バケットを作成する方法」に従ってください。Amazon EMR クラスターを起動する予定のリージョンと同じ AWS リージョンにバケットを作成します。たとえば、米国西部 (オレゴン) の us-west-2 です。
Amazon EMR で使用するバケットとフォルダには次の制限があります。
-
名前に使用できるのは、小文字、数字、ピリオド (.)、およびハイフン (-) のみです。
-
名前の末尾を数字にすることはできません。
-
バケット名はすべての AWS アカウントで一意である必要があります。
-
出力フォルダは空である必要があります。
Amazon EMR の入力データを使用してアプリケーションを準備する
Amazon EMR のアプリケーションを準備する最も一般的な方法は、アプリケーションとその入力データを Amazon S3 にアップロードすることです。次に、クラスターに作業内容を送信するときに、スクリプトとデータを保存する Amazon S3 の場所を指定します。
このステップでは、サンプルの PySpark スクリプトを Amazon S3 バケットにアップロードします。使用する PySpark スクリプトは用意されています。このスクリプトは食品施設の検査データを処理し、S3 バケットに結果ファイルを返します。結果ファイルには、「赤」タイプの違反が最も多い上位 10 施設がリストされます。
PySpark スクリプトで処理するサンプル入力データも Amazon S3 にアップロードします。入力データは、ワシントン州キング郡にある保健局の 2006~2020 年の検査結果の修正版です。詳細については、「King County Open Data: Food Establishment Inspection Data
name,inspection_result,inspection_closed_business,violation_type,violation_points 100 LB CLAM,Unsatisfactory,FALSE,BLUE,5 100 PERCENT NUTRICION,Unsatisfactory,FALSE,BLUE,5 7-ELEVEN #2361-39423A,Complete,FALSE,,0
EMR 用の PySpark スクリプト例を準備するには
-
以下のコード例を任意のエディタの新しいファイルにコピーします。
import argparse from pyspark.sql import SparkSession def calculate_red_violations(data_source, output_uri): """ Processes sample food establishment inspection data and queries the data to find the top 10 establishments with the most Red violations from 2006 to 2020. :param data_source: The URI of your food establishment data CSV, such as 's3://amzn-s3-demo-bucket/food-establishment-data.csv'. :param output_uri: The URI where output is written, such as 's3://amzn-s3-demo-bucket/restaurant_violation_results'. """ with SparkSession.builder.appName("Calculate Red Health Violations").getOrCreate() as spark: # Load the restaurant violation CSV data if data_source is not None: restaurants_df = spark.read.option("header", "true").csv(data_source) # Create an in-memory DataFrame to query restaurants_df.createOrReplaceTempView("restaurant_violations") # Create a DataFrame of the top 10 restaurants with the most Red violations top_red_violation_restaurants = spark.sql("""SELECT name, count(*) AS total_red_violations FROM restaurant_violations WHERE violation_type = 'RED' GROUP BY name ORDER BY total_red_violations DESC LIMIT 10""") # Write the results to the specified output URI top_red_violation_restaurants.write.option("header", "true").mode("overwrite").csv(output_uri) if __name__ == "__main__": parser = argparse.ArgumentParser() parser.add_argument( '--data_source', help="The URI for you CSV restaurant data, like an S3 bucket location.") parser.add_argument( '--output_uri', help="The URI where output is saved, like an S3 bucket location.") args = parser.parse_args() calculate_red_violations(args.data_source, args.output_uri) -
health_violations.pyという名前でファイルを保存します。 -
health_violations.pyを、このチュートリアル用に作成した Amazon S3 のバケットにアップロードします。手順については、「Amazon Simple Storage Service ユーザーガイド」の「バケットにオブジェクトをアップロードする」を参照してください。
EMR 用のサンプル入力データを準備するには
-
zip ファイル food_establishment_data.zip をダウンロードします。
-
food_establishment_data.zipを解凍し、ご使用のマシンにfood_establishment_data.csvとして保存します。 -
この CSV ファイル を、このチュートリアル用に作成した S3 バケットにアップロードします。手順については、「Amazon Simple Storage Service ユーザーガイド」の「バケットにオブジェクトをアップロードする」を参照してください。
EMR 用データのセットアップに関する詳細は、「Amazon EMR で処理する入力データを準備する」を参照してください。
Amazon EMR クラスターを起動する
ストレージの場所とアプリケーションを準備したら、サンプルの Amazon EMR クラスターを起動できます。このステップでは、最新の Amazon EMR リリースバージョンを使用して、Apache Spark クラスターを起動します。
ステップ 2: 作業を Amazon EMR クラスターに送信する
作業を送信して結果を表示する
クラスターを起動したら、データを処理して分析するために、実行中のクラスターに作業を送信できます。作業は、ステップとして Amazon EMR クラスターに送信します。ステップとは、1 つ以上のアクションで構成される作業の単位です。たとえば、値の計算や、データの転送と処理のためにステップを送信することが考えられます。ステップは、クラスターの起動時にも、実行中のクラスターに対しても送信できます。チュートリアルのこの部分では、実行中のクラスターにステップとして health_violations.py を送信します。ステップの詳細については、「作業を Amazon EMR クラスターに送信する」を参照してください。
ステップのライフサイクルに関する詳細は、「ステップの実行によるデータの処理」を参照してください。
結果を表示する
ステップが正常に実行されると、Amazon S3 の出力フォルダで出力結果を表示できます。
health_violations.py の結果を表示するには
Amazon S3 コンソール (https://console.aws.amazon.com/s3/
) を開きます。 -
[バケット名] を選択し、次に、ステップの送信時に指定した出力フォルダを選択します。例えば、
amzn-s3-demo-bucketとmyOutputFolder。 -
出力フォルダーに次の項目が表示されることを確認します。
-
_SUCCESSという名前の小さなサイズのオブジェクト。 -
結果が含まれている、プレフィックス
part-で始まる CSV ファイル。
-
-
結果を含むオブジェクトを選択し、[ダウンロード] をクリックして結果をローカルファイルシステムに保存します。
-
任意のエディタで、結果を開きます。出力ファイルには、赤の違反が最も多い上位 10 施設がリストされます。出力ファイルには、各施設に対する赤の違反の総数も表示されます。
health_violations.py結果の例を次に示します。name, total_red_violations SUBWAY, 322 T-MOBILE PARK, 315 WHOLE FOODS MARKET, 299 PCC COMMUNITY MARKETS, 251 TACO TIME, 240 MCDONALD'S, 177 THAI GINGER, 153 SAFEWAY INC #1508, 143 TAQUERIA EL RINCONSITO, 134 HIMITSU TERIYAKI, 128
Amazon EMR クラスターの出力に関する詳細は、「Amazon EMR クラスター出力の場所を設定する」を参照してください。
Amazon EMR を使用する際に、ログファイルの読み取り、クラスターのデバッグ、または Spark シェルなどの CLI ツールの使用のために、実行中のクラスターへの接続が必要になることがあります。Amazon EMR では、Secure Shell (SSH) プロトコルを使用してクラスターに接続できます。このセクションでは、SSH の設定、クラスターへの接続、および Spark のログファイルの表示を行う方法について説明します。クラスターへの接続に関する詳細は、「Amazon EMR クラスターノードへのアクセス認証」を参照してください。
クラスターへの SSH 接続を許可する
クラスターに接続する前に、インバウンド SSH 接続を許可するようにクラスターセキュリティグループを変更する必要があります。Amazon EC2 セキュリティグループは、クラスターへのインバウンドトラフィックとアウトバウンドトラフィックを制御する仮想ファイアウォールとして機能します。このチュートリアルのためにクラスターを作成したとき、Amazon EMR によって次のセキュリティグループが作成されました。
- ElasticMapReduce-master
-
プライマリノードに関連付けられているデフォルトの Amazon EMR マネージドセキュリティグループ。Amazon EMR クラスターでは、プライマリノードは、クラスターを管理する Amazon EC2 インスタンスです。
- ElasticMapReduce-slave
-
コアノードとタスクノードに関連付けられているデフォルトのセキュリティグループ。
を使用してクラスターに接続する AWS CLI
AWS CLIを使用すると、オペレーティングシステムに関係なく、クラスターへの SSH 接続を作成できます。
を使用してクラスターに接続し、ログファイルを表示するには AWS CLI
-
次のコマンドを使用して、クラスターへの SSH 接続を開きます。
<mykeypair.key>を、キーペアファイルの完全修飾パスとファイル名に置き換えてください。例えば、C:\Users\<username>\.ssh\mykeypair.pem。aws emr ssh --cluster-id<j-2AL4XXXXXX5T9>--key-pair-file<~/mykeypair.key> -
/mnt/var/log/sparkに移動して、クラスターのマスターノード上の Spark ログにアクセスします。次に、その場所にあるファイルを表示します。マスターノード上の追加のログファイルのリストについては、「プライマリノードのログファイルを表示する」を参照してください。cd /mnt/var/log/spark ls
EC2 上の Amazon EMR は、 Amazon SageMaker AI Unified Studio でサポートされているコンピューティングタイプでもあります。 Amazon SageMaker AI Unified Studio の EC2 リソースで EMR を使用および管理する方法については、EC2 での Amazon EMR の管理」を参照してください。
ステップ 3: Amazon EMR リソースをクリーンアップする
クラスターを終了する
クラスターに作業を送信し、PySpark アプリケーションの結果を表示したので、クラスターを終了できます。クラスターを終了すると、クラスターに関連付けられているすべての Amazon EMR 料金と Amazon EC2 インスタンスが停止します。
クラスターを終了しても、Amazon EMR ではクラスターに関するメタデータが 2 か月間無料で保持されます。アーカイブされたメタデータは、新しいジョブのためのクラスターのクローン作成や、参照目的でのクラスター設定への再アクセスに便利です。メタデータには、クラスターが S3 に書き込むデータや、クラスターの HDFS に格納されるデータは含まれません。
注記
クラスターを終了した後に、Amazon EMR コンソールでリストビューからクラスターを削除することはできません。Amazon EMR によってメタデータがクリアされると、終了したクラスターがコンソールから消えます。
S3 リソースを削除する
追加料金が発生しないように、Amazon S3 バケットを削除する必要があります。バケットを削除すると、このチュートリアル用のすべての Amazon S3 リソースが削除されます。バケットに含まれている内容は次のとおりです。
-
PySpark スクリプト
-
入力データセット
-
出力結果フォルダ
-
ログファイルフォルダ
PySpark スクリプトや出力を別の場所に保存した場合は、格納したファイルを削除するために追加の手順が必要になる場合があります。
注記
バケットを削除する前に、クラスターを終了する必要があります。そうしないと、バケットを空にできない可能性があります。
バケットを削除するには、「Amazon Simple Storage Service ユーザーガイド」の「S3 バケットを削除する方法」に従ってください。
次のステップ
これで、最初の Amazon EMR クラスターの起動を最初から最後まで実行しました。ビッグデータアプリケーションの準備と送信、結果の表示、クラスターの終了などの、必須 EMR タスクも完了しました。
以降のトピックでは、Amazon EMR ワークフローをカスタマイズする方法について詳しく説明します。
Amazon EMR のビッグデータアプリケーションについて調べる
「Amazon EMR リリース ガイド」で、クラスターにインストールできるビッグデータアプリケーションを確認し、比較します。リリースガイドには、各 EMR リリースバージョンの詳細と、Amazon EMR で Spark や Hadoop などのフレームワークを使用するためのヒントが記載されています。
クラスターのハードウェア、ネットワーク、およびセキュリティを計画する
このチュートリアルでは、詳細オプションを設定せずにシンプルな EMR クラスターを作成しました。詳細オプションでは、Amazon EC2 インスタンスタイプ、クラスターネットワーク、およびクラスターセキュリティを指定できます。要件を満たすクラスターの計画と起動に関する詳細は、「Amazon EMR クラスターの計画、設定、起動」と「Amazon EMR でのセキュリティ」を参照してください。
クラスターを管理する
「Amazon EMR クラスターの管理」で、実行中のクラスターの操作について詳しく説明しています。クラスターを管理するために、クラスターに接続し、ステップをデバッグし、クラスターのアクティビティと状態を追跡できます。EMR マネージドスケーリングを使用して、ワークロードの需要に応じてクラスターリソースを調整することもできます。
別のインターフェースを使用する
Amazon EMR コンソールに加えて、、ウェブサービス API AWS Command Line Interface、またはサポートされている多数の AWS SDKs のいずれかを使用して Amazon EMR を管理できます。詳細については、「管理インターフェイス」を参照してください。
Amazon EMR クラスターにインストールされているアプリケーションと、さまざまな方法でやり取りすることもできます。Apache Hadoop のようないくつかのアプリケーションでは、表示可能なウェブインターフェイスを公開しています。詳細については、「Amazon EMR クラスターでホストされているウェブインターフェイスを表示する」を参照してください。
EMR テクニカルブログを参照する
新しい Amazon EMR 機能のサンプルチュートリアルと詳細な技術説明については、「AWS Big Data Blog
