翻訳は機械翻訳により提供されています。提供された翻訳内容と英語版の間で齟齬、不一致または矛盾がある場合、英語版が優先します。
アカウント間で Amazon Redshift クラスターから Amazon S3 にデータをアンロードする
Andrew Kamel、Amazon Web Services
概要
アプリケーションをテストするときは、テスト環境に本稼働データを含めると便利です。本番データを使用すると、開発中のアプリケーションをより正確に評価できます。
このパターンは、本番環境の Amazon Redshift クラスターから、Amazon Web Services () の開発環境の Amazon Simple Storage Service (Amazon S3) バケットにデータを抽出しますAWS。
このパターンは、以下を含む DEV アカウントと PROD アカウントの両方のセットアップをステップスルーします。
必要なリソース
AWS Identity and Access Management (IAM) ロール
Amazon Redshift 接続をサポートするサブネット、セキュリティグループ、仮想プライベートクラウド (VPC) のネットワーク調整
アーキテクチャをテストするための Python ランタイムを使用する AWS Lambda 関数の例
Amazon Redshift クラスターへのアクセスを許可するために、パターンは AWS Secrets Manager を使用して関連する認証情報を保存します。利点は、Amazon Redshift クラスターの場所を知ることなく、Amazon Redshift クラスターに直接接続するために必要なすべての情報があることです。さらに、シークレットの使用をモニタリングできます。
Secrets Manager に保存されているシークレットには、Amazon Redshift クラスターのホスト、データベース名、ポート、および関連する認証情報が含まれます。
このパターンを使用する際のセキュリティ上の考慮事項については、「ベストプラクティス」セクションを参照してください。
前提条件と制限
前提条件
PROD アカウントで実行されている Amazon Redshift クラスター
DEV アカウントと PROD アカウント間の VPC ピアリングと、それに応じて調整されたルートテーブル
両方のピア接続された VPCs で有効になっている DNS ホスト名と DNS 解決
機能制限
クエリするデータの量によっては、Lambda 関数がタイムアウトすることがあります。
実行に最大 Lambda タイムアウト (15 分) よりも時間がかかる場合は、Lambda コードに非同期アプローチを使用します。このパターンのコード例では、Python 用の psycopg2
ライブラリを使用していますが、現在非同期処理をサポートしていません。 一部の AWS のサービス は では使用できません AWS リージョン。リージョンの可用性については、AWS のサービス 「リージョン別
」を参照してください。特定のエンドポイントについては、「サービスエンドポイントとクォータ」ページを参照して、サービスのリンクを選択します。
アーキテクチャ
次の図は、DEV アカウントと PROD アカウントを使用したターゲットアーキテクチャを示しています。
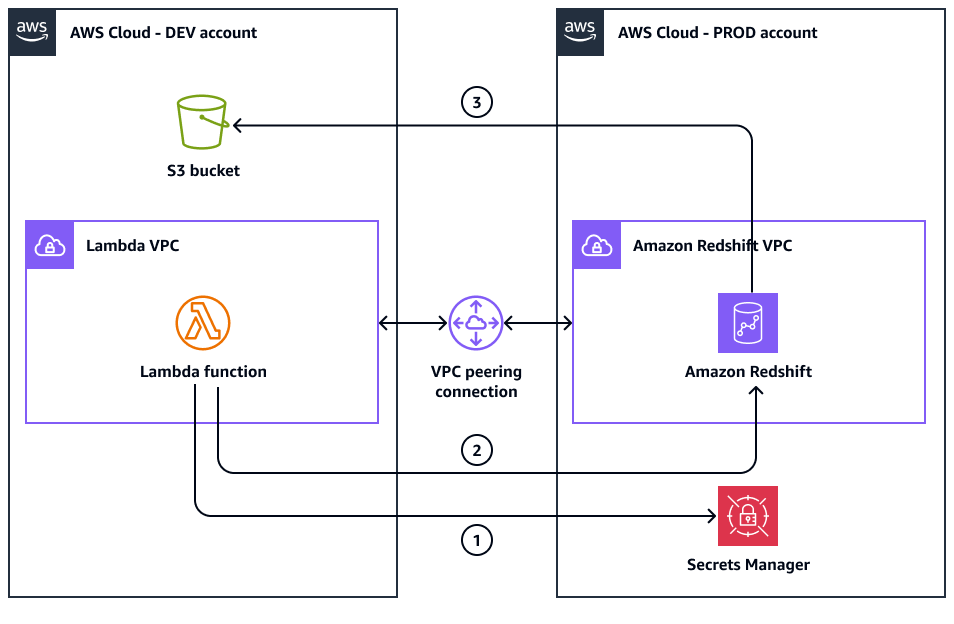
この図表は、次のワークフローを示しています:
DEV アカウントの Lambda 関数は、PROD アカウントの Secrets Manager の Amazon Redshift 認証情報にアクセスするために必要な IAM ロールを引き受けます。
次に、Lambda 関数は Amazon Redshift クラスターシークレットを取得します。
DEV アカウントの Lambda 関数は、この情報を使用して、ピア接続された VPCs を介して PROD アカウントの Amazon Redshift クラスターに接続します。
次に、Lambda 関数はアンロードコマンドを送信して、PROD アカウントの Amazon Redshift クラスターをクエリします。
PROD アカウントの Amazon Redshift クラスターは、DEV アカウントの S3 バケットにアクセスするための関連する IAM ロールを引き受けます。
Amazon Redshift クラスターは、クエリされたデータを DEV アカウントの S3 バケットにアンロードします。
Amazon Redshift からのデータのクエリ
次の図は、Amazon Redshift 認証情報を取得して Amazon Redshift クラスターに接続するために使用するロールを示しています。ワークフローは Lambda 関数によって開始されます。
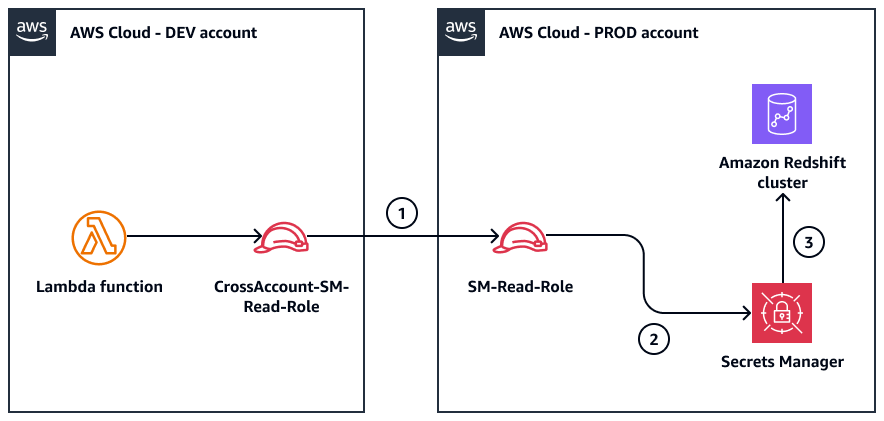
この図表は、次のワークフローを示しています:
CrossAccount-SM-Read-RoleDEV アカウントの は、PRODSM-Read-Roleアカウントの を引き受けます。SM-Read-Roleロールは、アタッチされたポリシーを使用して Secrets Manager からシークレットを取得します。認証情報は、Amazon Redshift クラスターへのアクセスに使用されます。
Amazon S3 へのデータのアップロード
次の図は、データを抽出して Amazon S3 にアップロードするためのクロスアカウント読み取り/書き込みプロセスを示しています。ワークフローは Lambda 関数によって開始されます。パターンは Amazon Redshift の IAM ロールを連鎖します。Amazon Redshift クラスターから送信されるアンロードコマンドは、 を引き受けCrossAccount-S3-Write-Role、次に を引き受けますS3-Write-Role。このロールの連鎖により、Amazon Redshift は Amazon S3 にアクセスできます。
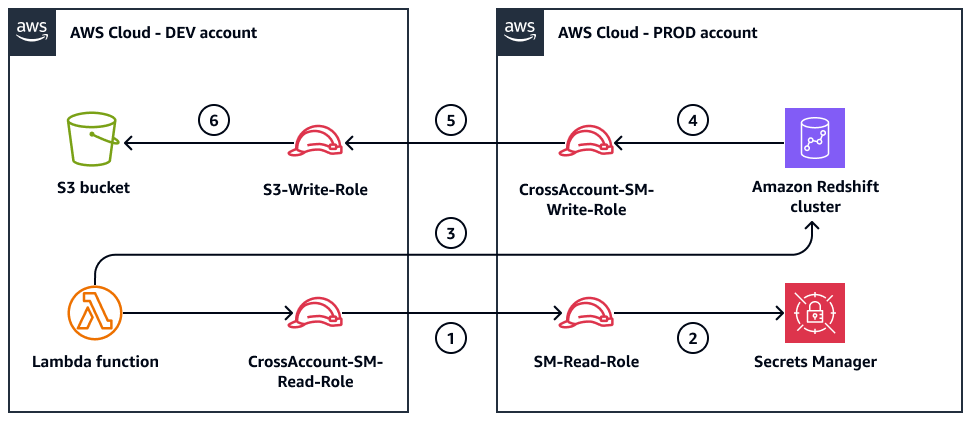
ワークフローには以下のステップが含まれます。
CrossAccount-SM-Read-RoleDEV アカウントの は、PRODSM-Read-Roleアカウントの を引き受けます。は、Secrets Manager から Amazon Redshift 認証情報
SM-Read-Roleを取得します。Lambda 関数は Amazon Redshift クラスターに接続し、クエリを送信します。
Amazon Redshift クラスターは を引き受けます
CrossAccount-S3-Write-Role。は、DEV アカウントの を
CrossAccount-S3-Write-Role引き受けS3-Write-Roleます。クエリ結果は、DEV アカウントの S3 バケットにアンロードされます。
ツール
AWS のサービス
AWS Key Management Service (AWS KMS) は、データの保護に役立つ暗号化キーの作成と制御に役立ちます。
AWS Lambda は、サーバーのプロビジョニングや管理を行うことなくコードを実行できるコンピューティングサービスです。必要に応じてコードを実行し、自動的にスケーリングするため、課金は実際に使用したコンピューティング時間に対してのみ発生します。
Amazon Redshift は、 クラウド内でのフルマネージド型、ペタバイト規模のデータウェアハウスサービスです。
AWS Secrets Manager を使用すると、コード内のハードコードされた認証情報 (パスワードを含む) を Secrets Manager への API コールで置き換えて、プログラムでシークレットを取得することができます。
Amazon Simple Storage Service (Amazon S3) は、データ量にかかわらず、保存、保護、取得する上で役立つクラウドベースのオブジェクトストレージサービスです。
コードリポジトリ
このパターンのコードは、GitHub unload-redshift-to-s3-python
ベストプラクティス
セキュリティに関する免責事項
このソリューションを実装する前に、以下の重要なセキュリティ上の推奨事項を考慮してください。
開発アカウントと本番稼働用アカウントを接続すると、スコープが拡大し、全体的なセキュリティ体制が低下する可能性があることに注意してください。このソリューションを一時的にのみデプロイし、必要なデータを抽出してから、デプロイされたリソースをすぐに破棄することをお勧めします。リソースを破棄するには、Lambda 関数を削除し、このソリューション用に作成された IAM ロールとポリシーを削除し、アカウント間で付与されたネットワークアクセスを取り消す必要があります。
本番環境から開発環境にデータをコピーする前に、セキュリティチームとコンプライアンスチームに相談してください。個人を特定できる情報 (PII)、保護対象医療情報 (PHI)、その他の機密データや規制対象データは、通常、この方法でコピーしないでください。公開されている非機密情報 (たとえば、ショップのフロントエンドからの公開株式データ) のみをコピーします。可能な限り本番データを使用するのではなく、データのトークン化または匿名化、または合成テストデータの生成を検討してください。AWS セキュリティ原則の 1 つは、ユーザーをデータから遠ざけることです。つまり、デベロッパーは本番稼働用アカウントでオペレーションを実行しないでください。
本番環境の Amazon Redshift クラスターからデータを読み取ることができるため、開発アカウントの Lambda 関数へのアクセスを制限します。
本番環境の中断を回避するには、次の推奨事項を実装します。
テストおよび開発アクティビティには、別の専用開発アカウントを使用します。
厳格なネットワークアクセスコントロールを実装し、アカウント間のトラフィックを必要なもののみに制限します。
本番環境とデータソースへのアクセスをモニタリングおよび監査します。
関連するすべてのリソースとサービスに対して、最小特権のアクセスコントロールを実装します。
AWS Secrets Manager シークレットや IAM ロールのアクセスキーなどの認証情報を定期的に確認して更新します。
この記事で使用されているサービスについては、次のセキュリティドキュメントを参照してください。
本番稼働用データとリソースにアクセスする場合、セキュリティが最優先事項です。常にベストプラクティスに従い、最小特権のアクセスコントロールを実装し、セキュリティ対策を定期的に見直して更新します。
エピック
| タスク | 説明 | 必要なスキル |
|---|---|---|
Amazon Redshift クラスターのシークレットを作成します。 | Amazon Redshift クラスターのシークレットを作成するには、次の手順を実行します。
| DevOps エンジニア |
Secrets Manager にアクセスするためのロールを作成します。 | ロールを作成するには、以下を実行します。
| DevOps エンジニア |
| タスク | 説明 | 必要なスキル |
|---|---|---|
S3 バケットにアクセスするためのロールを作成します。 | S3 バケットにアクセスするためのロールを作成するには、次の手順を実行します。
| DevOps エンジニア |
Amazon Redshift ロールを作成します。 | Amazon Redshift ロールを作成するには、以下を実行します。
| DevOps エンジニア |
| タスク | 説明 | 必要なスキル |
|---|---|---|
Lambda 関数をデプロイします。 | ピア接続された VPC に Lambda 関数をデプロイするには、次の手順を実行します。
| DevOps エンジニア |
| タスク | 説明 | 必要なスキル |
|---|---|---|
必要なリソースをインポートします。 | 必要なリソースをインポートするには、次のコマンドを実行します。
| アプリ開発者 |
Lambda ハンドラー関数を実行します。 | Lambda 関数は、クロスアカウントアクセスと一時的な認証情報管理に AWS Security Token Service (AWS STS) を使用します。関数は AssumeRole API オペレーションを使用して、IAM Lambda 関数を実行するには、次のサンプルコードを使用します。
| アプリ開発者 |
シークレットを取得します。 | Amazon Redshift シークレットを取得するには、次のサンプルコードを使用します。
| アプリ開発者 |
アンロードコマンドを実行します。 | S3 バケットにデータをアンロードするには、次のサンプルコードを使用します。
| アプリ開発者 |
| タスク | 説明 | 必要なスキル |
|---|---|---|
Lambda 関数を削除します。 | 予期しないコストが発生しないようにするには、リソースと DEV アカウントと PROD アカウント間の接続を削除します。 Lambda 関数を削除するには、次の手順を実行します。
| DevOps エンジニア |
IAM ロールとポリシーを削除します。 | DEV アカウントと PROD アカウントから IAM ロールとポリシーを削除します。 DEV アカウントで、次の操作を行います。
PROD アカウントで、次の操作を行います。
| DevOps エンジニア |
Secrets Manager でシークレットを削除します。 | シークレットを削除するには、次の手順を実行します。
| DevOps エンジニア |
VPC ピアリングとセキュリティグループのルールを削除します。 | VPC ピアリングとセキュリティグループのルールを削除するには、次の手順を実行します。
| DevOps エンジニア |
S3 バケットからデータを削除します。 | Amazon S3 からデータを削除するには、次の手順を実行します。
| DevOps エンジニア |
AWS KMS キーをクリーンアップします。 | 暗号化用のカスタム AWS KMS キーを作成した場合は、次の操作を行います。
| DevOps エンジニア |
Amazon CloudWatch logsを確認して削除します。 | CloudWatch ログを削除するには、次の手順を実行します。
| DevOps エンジニア |
関連リソース
追加情報
Amazon Redshift から Amazon S3 にデータをアンロードした後、Amazon Athena を使用してデータを分析できます。
Amazon Athena はビッグデータクエリサービスであり、大量のデータにアクセスする必要がある場合に便利です。サーバーやデータベースをプロビジョニングしなくても Athena を使用できます。Athena は複雑なクエリをサポートしており、さまざまなオブジェクトで実行できます。
ほとんどの と同様に AWS のサービス、Athena を使用する主な利点は、複雑さを増すことなくクエリを実行する方法に大きな柔軟性があることです。Athena を使用すると、データ型を変更せずに、CSV や JSON などのさまざまなデータ型を Amazon S3 でクエリできます。外部を含むさまざまなソースからデータをクエリできます AWS。Athena は、サーバーを管理する必要がないため、複雑さを軽減します。Athena は、クエリを実行する前にデータをロードまたは変更することなく、Amazon S3 から直接データを読み取ります。
