Cost-effectively ingest IoT data directly into Amazon S3 using AWS IoT Greengrass
Sebastian Viviani and Rizwan Syed, Amazon Web Services
Summary
This pattern shows you how to cost-effectively ingest Internet of Things (IoT) data directly into an Amazon Simple Storage Service (Amazon S3) bucket by using an AWS IoT Greengrass Version 2 device. The device runs a custom component that reads the IoT data and saves the data in persistent storage (that is, a local disk or volume). Then, the device compresses the IoT data into an Apache Parquet file and uploads the data periodically to an S3 bucket.
The amount and speed of IoT data that you ingest is limited only by your edge hardware capabilities and network bandwidth. You can use Amazon Athena to cost-effectively analyze your ingested data. Athena supports compressed Apache Parquet files and data visualization by using Amazon Managed Grafana.
Prerequisites and limitations
Prerequisites
An active AWS account
An edge gateway that runs on AWS IoT Greengrass Version 2 and collects data from sensors (The data sources and the data collection process are beyond the scope of this pattern, but you can use nearly any type of sensor data. This pattern uses a local MQTT
broker with sensors or gateways that publish data locally.) AWS IoT Greengrass component, roles, and SDK dependencies
A stream manager component to upload the data to the S3 bucket
AWS SDK for Java
, AWS SDK for JavaScript , or AWS SDK for Python (Boto3) to run the APIs
Limitations
The data in this pattern isn’t uploaded in real time to the S3 bucket. There is a delay period, and you can configure the delay period. Data is buffered temporarily in the edge device and then uploaded once the period expires.
The SDK is available only in Java, Node.js, and Python.
Architecture
Target technology stack
Amazon S3
AWS IoT Greengrass
MQTT broker
Stream manager component
Target architecture
The following diagram shows an architecture designed to ingest IoT sensor data and store that data in an S3 bucket.
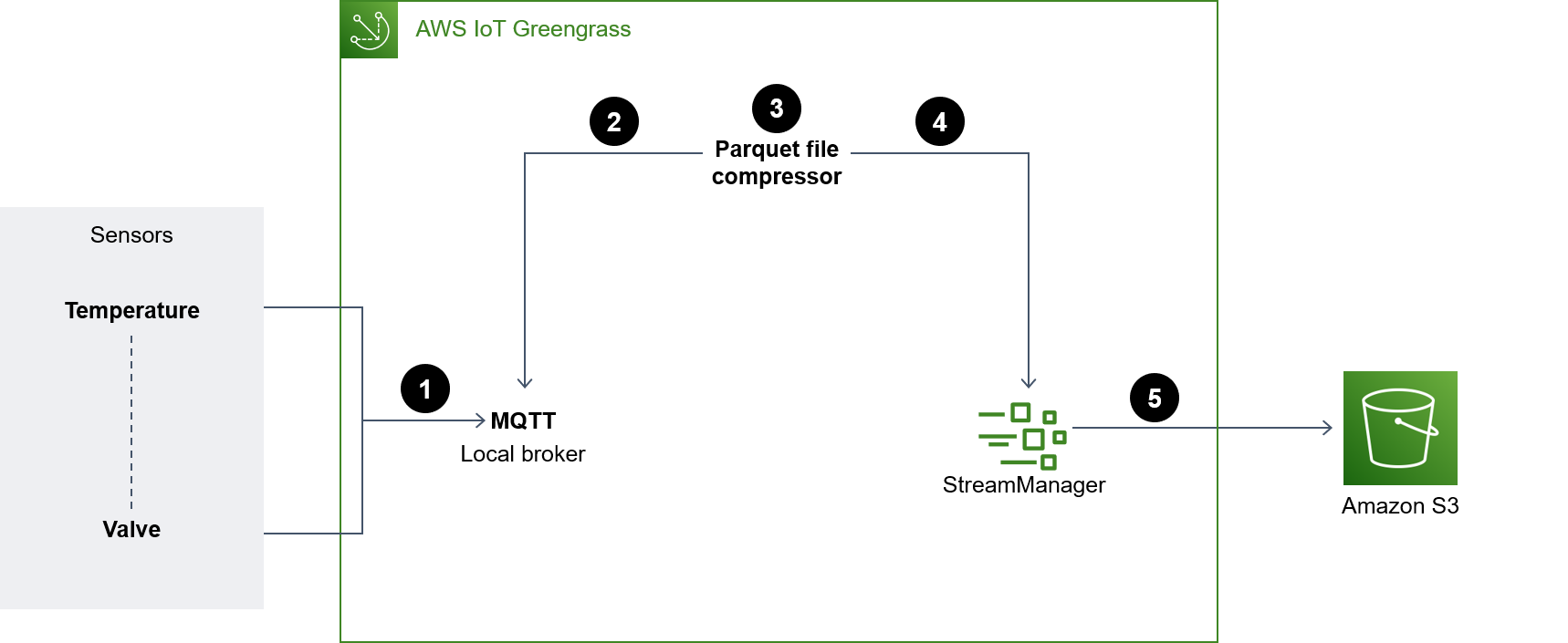
The diagram shows the following workflow:
Multiple sensors (for example, temperature and valve) updates are published to a local MQTT broker.
The Parquet file compressor that's subscribed to these sensors updates topics and receives these updates.
The Parquet file compressor stores the updates locally.
After the period lapses, the stored files are compressed into Parquet files and passed on to the stream manager to get uploaded to the specified S3 bucket.
The stream manager uploads the Parquet files to the S3 bucket.
Note
The stream manager (StreamManager) is a managed component. For examples of how to export data to Amazon S3, see Stream manager in the AWS IoT Greengrass documentation. You can use a local MQTT broker as a component or another broker like Eclipse Mosquitto
Tools
AWS tools
Amazon Athena is an interactive query service that helps you analyze data directly in Amazon S3 by using standard SQL.
Amazon Simple Storage Service (Amazon S3) is a cloud-based object storage service that helps you store, protect, and retrieve any amount of data.
AWS IoT Greengrass is an open source IoT edge runtime and cloud service that helps you build, deploy, and manage IoT applications on your devices.
Other tools
Apache Parquet
is an open-source column-oriented data file format designed for storage and retrieval. MQTT (Message Queuing Telemetry Transport) is a lightweight messaging protocol that's designed for constrained devices.
Best practices
Use the right partition format for uploaded data
There are no specific requirements for the root prefix names in the S3 bucket (for example, "myAwesomeDataSet/" or "dataFromSource"), but we recommend that you use a meaningful partition and prefix so that it's easy to understand the purpose of the dataset.
We also recommend that you use the right partitioning in Amazon S3 so that the queries run optimally on the dataset. In the following example, the data is partitioned in HIVE format so that the amount of data scanned by each Athena query is optimized. This improves performance and reduces cost.
s3://<ingestionBucket>/<rootPrefix>/year=YY/month=MM/day=DD/HHMM_<suffix>.parquet
Epics
| Task | Description | Skills required |
|---|---|---|
Create an S3 bucket. |
| App developer |
Add IAM permissions to the S3 bucket. | To grant users write access to the S3 bucket and prefix that you created earlier, add the following IAM policy to your AWS IoT Greengrass role:
For more information, see Creating an IAM policy to access Amazon S3 resources in the Aurora documentation. Next, update the resource policy (if needed) for the S3 bucket to allow write access with the correct AWS principals. | App developer |
| Task | Description | Skills required |
|---|---|---|
Update the recipe of the component. | Update the component configuration when you create a deployment based on the following example:
Replace | App developer |
Create the component. | Do one of the following:
| App developer |
Update the MQTT client. | The sample code doesn't use authentication because the component connects locally to the broker. If your scenario differs, update the MQTT client section as needed. Additionally, do the following:
| App developer |
| Task | Description | Skills required |
|---|---|---|
Update the deployment of the core device. | If the deployment of the AWS IoT Greengrass Version 2 core device already exists, revise the deployment. If the deployment doesn't exist, create a new deployment. To give the component the correct name, update the log manager configuration for the new component (if needed) based on the following:
Finally, complete the revision of the deployment for your AWS IoT Greengrass core device. | App developer |
| Task | Description | Skills required |
|---|---|---|
Check the logs for the AWS IoT Greengrass volume. | Check for the following:
| App developer |
Check the S3 bucket. | Verify if the data is being uploaded to the S3 bucket. You can see the files being uploaded at every period. You can also verify if the data is uploaded to the S3 bucket by querying the data in the next section. | App developer |
| Task | Description | Skills required |
|---|---|---|
Create a database and table. |
| App developer |
Grant Athena access to the data. |
| App developer |
Troubleshooting
| Issue | Solution |
|---|---|
MQTT client fails to connect |
|
MQTT client fails to subscribe | Validate the permissions on the MQTT broker. If you have an MQTT broker from AWS, see MQTT 3.1.1 broker (Moquette) and MQTT 5 broker (EMQX). |
Parquet files don't get created |
|
Objects are not uploaded to the S3 bucket |
|
Related resources
DataFrame
(Pandas documentation) Apache Parquet Documentation
(Parquet documentation) Develop AWS IoT Greengrass components (AWS IoT Greengrass Developer Guide, Version 2)
Deploy AWS IoT Greengrass components to devices (AWS IoT Greengrass Developer Guide, Version 2)
Interact with local IoT devices (AWS IoT Greengrass Developer Guide, Version 2)
MQTT 3.1.1 broker (Moquette) (AWS IoT Greengrass Developer Guide, Version 2)
MQTT 5 broker (EMQX) (AWS IoT Greengrass Developer Guide, Version 2)
Additional information
Cost analysis
The following cost analysis scenario demonstrates how the data ingestion approach covered in this pattern can impact data ingestion costs in the AWS Cloud. The pricing examples in this scenario are based on prices at the time of publication. Prices are subject to change. Additionally, your costs may vary depending on your AWS Region, AWS service quotas, and other factors related to your cloud environment.
Input signal set
This analysis uses the following set of input signals as the basis for comparing IoT ingestion costs with other available alternatives.
Number of signals | Frequency | Data per signal |
|---|---|---|
125 | 25 Hz | 8 bytes |
In this scenario, the system receives 125 signals. Each signal is 8 bytes and occurs every 40 milliseconds (25 Hz). These signals could come individually or grouped in a common payload. You have the option to split and pack these signals based on your needs. You can also determine the latency. Latency consists of the time period for receiving, accumulating, and ingesting the data.
For comparison purposes, the ingestion operation for this scenario is based in the us-east-1 AWS Region. The cost comparison applies to AWS services only. Other costs, like hardware or connectivity, are not factored into the analysis.
Cost comparisons
The following table shows the monthly cost in US dollars (USD) for each ingestion method.
Method | Monthly cost |
|---|---|
AWS IoT SiteWise* | 331.77 USD |
AWS IoT SiteWise Edge with data processing pack (keeping all data at the edge) | 200 USD |
AWS IoT Core and Amazon S3 rules for accessing raw data | 84.54 USD |
Parquet file compression at the edge and uploading to Amazon S3 | 0.5 USD |
*Data must be downsampled to comply with service quotas. This means there is some data loss with this method.
Alternative methods
This section shows the equivalent costs for the following alternative methods:
AWS IoT SiteWise – Each signal must be uploaded in an individual message. Therefore, the total number of messages per month is 125×25×3600×24×30, or 8.1 billion messages per month. However, AWS IoT SiteWise can handle only 10 data points per second per property. Assuming the data is downsampled to 10 Hz, the number of messages per month is reduced to 125×10×3600×24×30, or 3.24 billion. If you use the publisher component that packs measurements in groups of 10 (at 1 USD per million messages), then you get a monthly cost of 324 USD per month. Assuming that each message is 8 bytes (1 Kb/125), that’s 25.92 Gb of data storage. This adds a monthly cost of 7.77 USD per month. The total cost for the first month is 331.77 USD and increases by 7.77 USD every month.
AWS IoT SiteWise Edge with data processing pack, including all models and signals fully processed at the edge (that is, no cloud ingestion) – You can use the data processing pack as an alternative to reduce costs and to configure all the models that get calculated at the edge. This can work just for storage and visualization, even if no real calculation is performed. In this case, it’s necessary to use powerful hardware for the edge gateway. There is a fixed cost of 200 USD per month.
Direct ingestion to AWS IoT Core by MQTT and an IoT rule to store the raw data in Amazon S3 – Assuming all the signals are published in a common payload, the total number of messages published to AWS IoT Core is 25×3600×24×30, or 64.8 million per month. At 1 USD per million messages, that’s a monthly cost of 64.8 USD per month. At 0.15 USD per million rule activations and with one rule per message, that adds a monthly cost of 19.44 USD per month. At a cost of 0.023 USD per Gb of storage in Amazon S3, that adds another 1.5 USD per month (increasing every month to reflect the new data). The total cost for the first month is 84.54 USD and increases by 1.5 USD every month.
Compressing data at the edge in a Parquet file and uploading to Amazon S3 (proposed method) – The compression ratio depends on the type of data. With the same industrial data tested for MQTT, the total output data for a full month is 1.2 Gb. This costs 0.03 USD per month. Compression ratios (using random data) described in other benchmarks are on the order of 66 percent (closer to a worst-case scenario). The total data is 21 Gb and costs 0.5 USD per month.
Parquet file generator
The following code example shows the structure of a Parquet file generator that's written in Python. The code example is for illustration purposes only and won’t work if pasted into your environment.
import queue import paho.mqtt.client as mqtt import pandas as pd #queue for decoupling the MQTT thread messageQueue = queue.Queue() client = mqtt.Client() streammanager = StreamManagerClient() def feederListener(topic, message): payload = { "topic" : topic, "payload" : message, } messageQueue.put_nowait(payload) def on_connect(client_instance, userdata, flags, rc): client.subscribe("#",qos=0) def on_message(client, userdata, message): feederListener(topic=str(message.topic), message=str(message.payload.decode("utf-8"))) filename = "tempfile.parquet" streamname = "mystream" destination_bucket= "amzn-s3-demo-bucket" keyname="mykey" period= 60 client.on_connect = on_connect client.on_message = on_message streammanager.create_message_stream( MessageStreamDefinition(name=streamname, strategy_on_full=StrategyOnFull.OverwriteOldestData) ) while True: try: message = messageQueue.get(timeout=myArgs.mqtt_timeout) except (queue.Empty): logger.warning("MQTT message reception timed out") currentTimestamp = getCurrentTime() if currentTimestamp >= nextUploadTimestamp: df = pd.DataFrame.from_dict(accumulator) df.to_parquet(filename) s3_export_task_definition = S3ExportTaskDefinition(input_url=filename, bucket=destination_bucket, key=key_name) streammanager.append_message(streamname, Util.validate_and_serialize_to_json_bytes(s3_export_task_definition)) accumulator = {} nextUploadTimestamp += period else: accumulator.append(message)
