REL13-BP02 Usar estratégias de recuperação definidas para cumprir os objetivos de recuperação
Defina uma estratégia de recuperação de desastres (DR) que cumpra os objetivos de recuperação da workload. Escolha uma estratégia como backup e restauração, standby (ativa/passiva) ou ativa/ativa.
Resultado desejado: para cada workload, há uma estratégia de DR definida e implementada que permite que a workload alcance os objetivos de DR. As estratégias de DR entre workloads fazem uso de padrões reutilizáveis (como as estratégias descritas anteriormente).
Práticas comuns que devem ser evitadas:
-
Implementar procedimentos de recuperação inconsistentes para workloads com objetivos de DR semelhantes.
-
Deixar que a estratégia de DR seja implementada ad hoc quando um desastre ocorrer.
-
Não ter um plano para a recuperação de desastres.
-
Depender das operações do ambiente de gerenciamento durante a recuperação.
Benefícios de implementar esta prática recomendada:
-
O uso de estratégias de recuperação definidas permite que você adote ferramentas comuns e procedimentos de teste.
-
Usar estratégias de recuperação definidas melhora o compartilhamento de conhecimento entre as equipes e a implementação da DR nas workloads pertencentes a elas.
Nível de risco exposto se esta prática recomendada não for estabelecida: Alto. Sem uma estratégia de DR planejada, implementada e testada, é improvável que você cumpra os objetivos de recuperação em caso de desastre.
Orientação para implementação
Uma estratégia de DR depende da capacidade de manter a workload em um site de recuperação se o local primário não puder executar a workload. Os objetivos de recuperação mais comuns são o RTO e o RPO, conforme discutido em REL13-BP01 Definir os objetivos de recuperação para tempo de inatividade e perda de dados.
Uma estratégia de DR em várias zonas de disponibilidade (AZs) em uma única Região da AWS pode fornecer mitigação contra eventos de desastre, como incêndios, inundações e grandes interrupções de energia. Se implementar proteção contra um evento improvável que impeça a execução da workload em determinada Região da AWS for um requisito, você poderá optar por uma estratégia de DR que use várias regiões.
Ao arquitetar uma estratégia de DR em várias regiões, é necessário escolher uma das estratégias a seguir. Elas são listadas em ordem crescente de custo e complexidade e em ordem decrescente de RTO e RPO. Região de recuperação se refere a uma Região da AWS diferente da principal usada para sua workload.

Figura 17: Estratégias de recuperação de desastres (DR)
-
Backup e restauração (RPO em horas, RTO em 24 horas ou menos): faça backup de seus dados e aplicações na região de recuperação. O uso de backups automatizados ou contínuos permitirá a recuperação para um ponto no tempo (PITR), o que pode reduzir o RPO para até cinco minutos em alguns casos. Em caso de desastre, você implantará a infraestrutura (usando a infraestrutura como código para reduzir o RTO), implantará o código e restaurará os dados salvos para se recuperar de um desastre na região de recuperação.
-
Luz piloto (RPO em minutos, RTO em dezenas de minutos): provisione uma cópia da sua infraestrutura principal de workload na região de recuperação. Replique seus dados na região de recuperação e crie backups deles nessa região. Os recursos necessários para permitir a replicação e o backup, como bancos de dados e armazenamento de objetos, estão sempre ativos. Outros elementos, como servidores de aplicações ou computação com tecnologia sem servidor, não são implantados. No entanto, eles podem ser criados com a configuração e o código da aplicação necessários.
-
Standby passivo (RPO em segundos, RTO em minutos): mantenha uma versão em escala vertical reduzida, mas totalmente funcional, da workload sempre em execução na região de recuperação. Os sistemas críticos para os negócios são totalmente duplicados e estão sempre ativados, mas com uma frota reduzida. Os dados são replicados e residem na região de recuperação. No momento da recuperação, a escala do sistema é aumentada vertical e rapidamente para processar a carga de produção. Quanto mais a escala do standby passivo for aumentada verticalmente, menor será a dependência do RTO e do ambiente de gerenciamento. Quando totalmente dimensionado, isso é conhecido como standby a quente.
-
Ativo-ativo em várias regiões (vários sites) (RPO próximo de zero, RTO potencialmente zero): sua workload é implantada e atende ativamente ao tráfego de várias Regiões da AWS. Essa estratégia exige que você sincronize os dados entre regiões. É necessário evitar ou lidar com possíveis conflitos causados por gravações no mesmo registro em duas réplicas regionais diferentes, o que pode ser complexo. A replicação de dados é útil para a sincronização de dados e protegerá você contra alguns tipos de desastre, mas não contra corrupção ou destruição de dados, a menos que sua solução também inclua opções para recuperação a um ponto anterior no tempo.
nota
Às vezes, a diferença entre luz-piloto e standby passivo pode ser difícil de entender. Ambos incluem um ambiente na região de recuperação com cópias dos ativos da região primária. A diferença é que a luz piloto não pode processar solicitações sem primeiro realizar uma ação adicional, enquanto o standby passivo pode processar o tráfego (em níveis de capacidade reduzidos) imediatamente. A abordagem de luz piloto exigirá que você ative os servidores, possivelmente implante infraestrutura adicional (não essencial) e aumente a escala verticalmente. Já o standby passivo exige apenas que você aumente a escala verticalmente (tudo já está implantado e em execução). Escolha entre ambas as opções com base nas suas necessidades de RTO e RPO.
Quando o custo é uma preocupação e você deseja alcançar objetivos de RPO e RTO semelhantes, conforme definido na estratégia de standby passivo, é possível considerar soluções nativas da nuvem, como AWS Elastic Disaster Recovery, que adota a abordagem de luz piloto e oferece metas de RPO e RTO aprimoradas.
Etapas de implementação
-
Determine uma estratégia de recuperação de desastres que satisfaça os requisitos de recuperação dessa workload.
Escolher uma estratégia de recuperação de desastres é uma troca entre reduzir o tempo de inatividade e a perda de dados (RTO e RPO) e o custo e a complexidade da implementação da estratégia. Você deve evitar implementar uma estratégia mais rigorosa do que necessário, pois isso resulta em custos desnecessários.
Por exemplo, no diagrama a seguir, a empresa determinou o RTO máximo permitido e o orçamento limite da estratégia de restauração de serviço. Considerando os objetivos empresariais, as estratégias de recuperação de desastres de luz-piloto e standby passivo atenderão tanto ao RTO quanto aos critérios de custo.
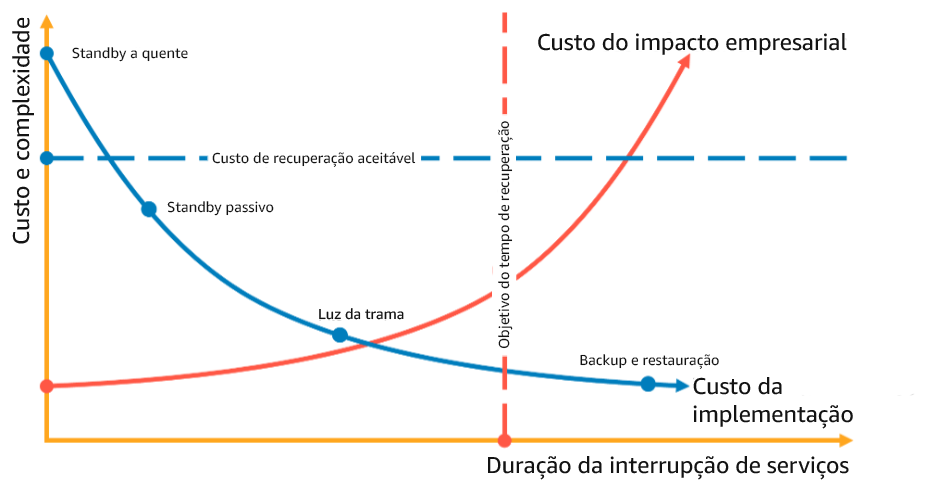
Figura 18: Escolher uma estratégia de recuperação de desastres com base no RTO e no custo
Para saber mais, consulte Plano de continuidade de negócios (BCP).
-
Analise os padrões de como a estratégia de recuperação de desastres selecionada pode ser implementada.
O objetivo dessa etapa é entender como implementar a estratégia selecionada. As estratégias são explicadas usando as Regiões da AWS como locais primários e de recuperação. No entanto, também é possível optar por usar as zonas de disponibilidade em uma única região como sua estratégia de recuperação de desastres, a qual faz uso de elementos de várias dessas estratégias.
Nas etapas a seguir, é possível aplicar a estratégia para sua workload específica.
Backup e restauração
Backup e restauração é a estratégia menos complexa de implementar, mas exigirá mais tempo e esforços para restaurar a workload, resultando em maior RTO e RPO. É uma boa prática sempre fazer backups dos dados e copiá-los para outro local (como outra Região da AWS).
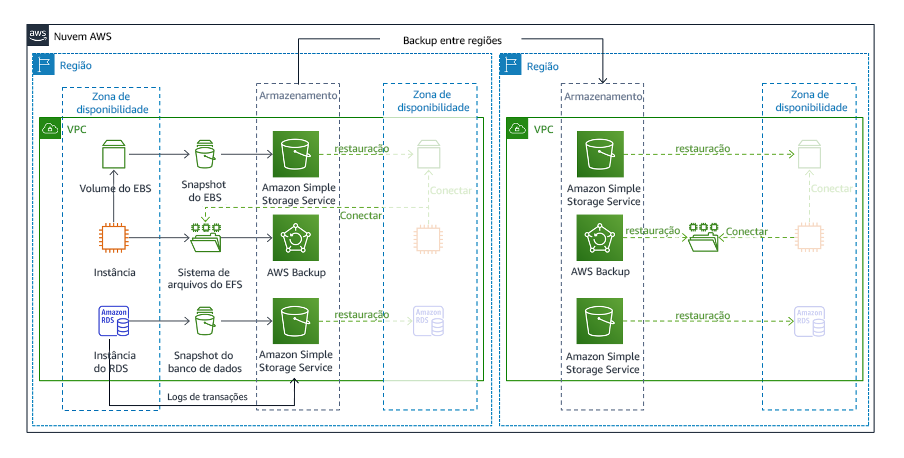
Figura 19: Arquitetura de backup e restauração
Para obter mais detalhes sobre essa estratégia, consulte Arquitetura de recuperação de desastres (DR) na AWS, Parte II: backup e restauração com recuperação rápida
. Luz piloto
Com a abordagem luz piloto, você replica seus dados da região principal para a região de recuperação. Os principais recursos usados para a infraestrutura da workload são implantados na região de recuperação. No entanto, recursos adicionais e as dependências ainda são necessários para tornar a pilha funcional. Por exemplo, na Figura 20, nenhuma instância de computação é implantada.
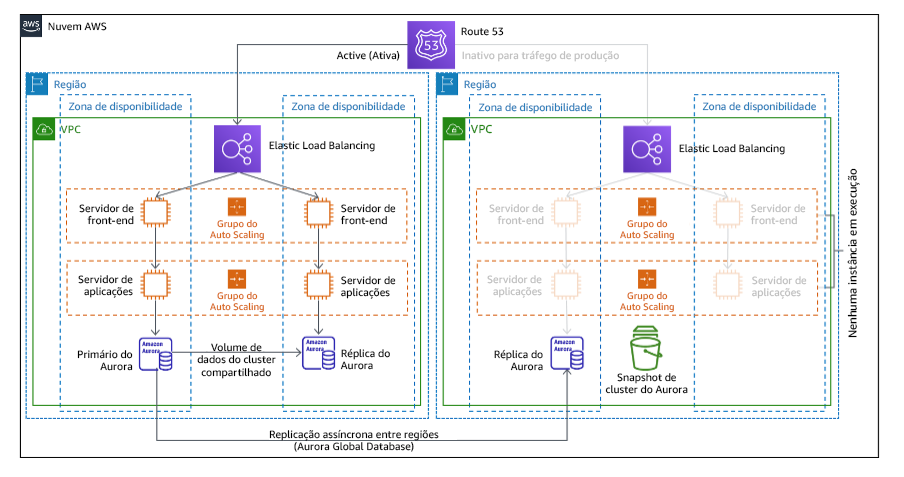
Figura 20: Arquitetura de luz piloto
Para obter mais detalhes sobre essa estratégia, consulte Arquitetura de recuperação de desastres (DR) na AWS, parte III: luz piloto e standby passivo
. Standby passivo
A abordagem de standby passivo envolve garantir que haja uma cópia reduzida, mas totalmente funcional, do seu ambiente de produção em outra região. Essa abordagem estende o conceito de luz piloto e diminui o tempo de recuperação, já que a workload está sempre ativa em outra região. Se a região de recuperação for implantada com capacidade total, isso será conhecido como standby a quente.
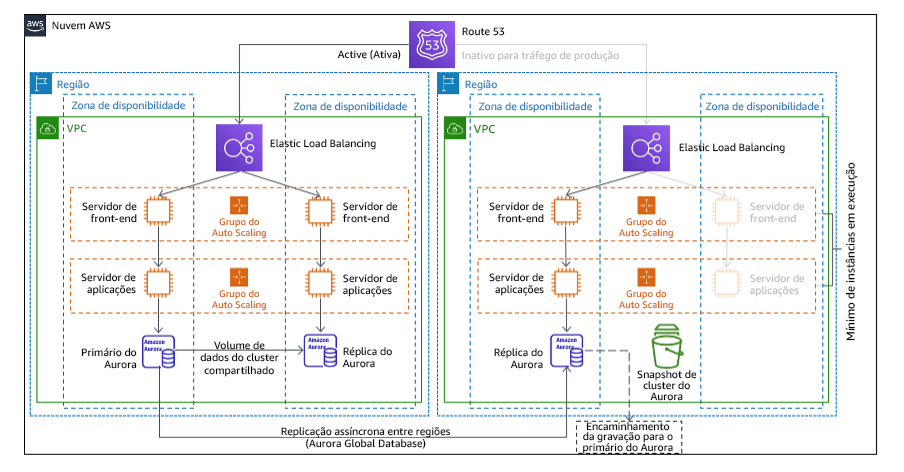
Figura 21: Arquitetura de standby passivo
O uso de standby passivo ou luz piloto requer que a escala dos recursos seja aumentada verticalmente na região de recuperação. Para verificar se a capacidade está disponível quando necessário, considere o uso de reservas de capacidade para instâncias do EC2. Quando o AWS Lambda é usado, a simultaneidade provisionada pode fornecer ambientes de runtime para que eles estejam preparados para responder imediatamente às invocações da sua função.
Para obter mais detalhes sobre essa estratégia, consulte Arquitetura de recuperação de desastres (DR) na AWS, parte III: luz piloto e standby passivo
. Multissite ativa/ativa
Você pode executar sua workload simultaneamente em várias regiões como parte de uma estratégia multissite ativa/ativa. A estratégia multissite ativa-ativa atende ao tráfego de todas as regiões onde está implantada. Os clientes podem selecionar essa estratégia para outros fins além da recuperação de desastres. Ela pode ser usada para aumentar a disponibilidade ou ao implantar uma workload para um público global (a fim de aproximar o endpoint dos usuários e/ou implantar pilhas localizadas para o público nessa região). Como uma estratégia de DR, se a workload não for compatível com uma das Regiões da AWS onde está implantada, essa região será evacuada e as regiões restantes serão usadas para manter a disponibilidade. A multissite ativa/ativa é a estratégia de DR mais complexa operacionalmente e deve ser selecionada apenas quando os requisitos empresariais exigirem.
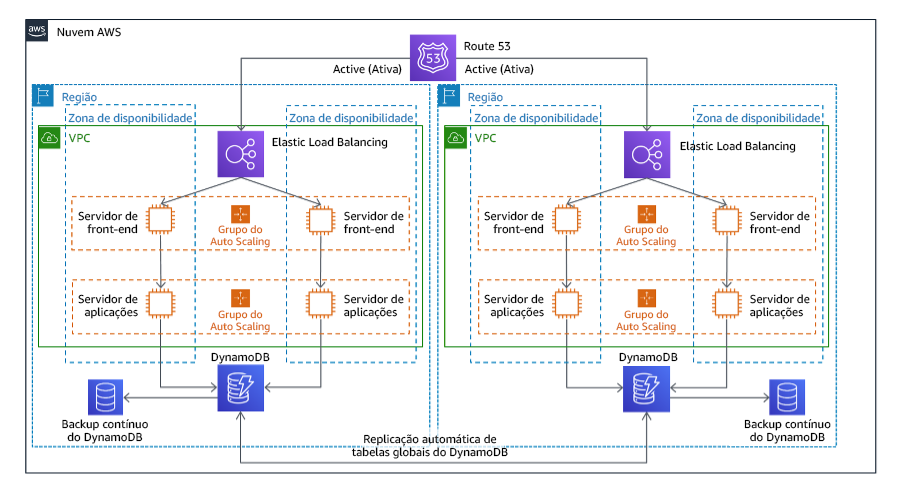
Figura 22: Arquitetura multissite ativa/ativa
Para obter mais detalhes sobre essa estratégia, consulte Arquitetura de recuperação de desastres (DR) na AWS, Parte IV: multissite ativa/ativa
AWS Elastic Disaster Recovery
Se você está considerando a estratégia de luz piloto ou standby passivo para recuperação de desastres, o AWS Elastic Disaster Recovery pode fornecer uma abordagem alternativa com benefícios aprimorados. O Elastic Disaster Recovery pode oferecer uma meta de RPO e RTO semelhante ao standby passivo, mas mantendo a abordagem de baixo custo da luz piloto. O Elastic Disaster Recovery replica os dados da sua região primária para sua região de recuperação usando proteção contínua de dados para obter um RPO medido em segundos e um RTO que pode ser medido em minutos. Somente os recursos necessários para replicar os dados são implantados na região de recuperação, o que mantém os custos baixos, semelhante à estratégia de luz piloto. Quando o Elastic Disaster Recovery é usado, o serviço coordena e orquestra a recuperação de recursos de computação quando iniciado como parte de um failover ou de uma simulação.

Figura 23: Arquitetura do AWS Elastic Disaster Recovery
Práticas adicionais para proteger dados
Com todas as estratégias, você também deve mitigar as consequências de um desastre de dados. A replicação contínua de dados protege você contra alguns tipos de desastre, mas não contra corrompimento ou destruição de dados, a menos que sua solução também inclua o versionamento de dados armazenados ou opções para recuperação a um ponto anterior no tempo. Você também deve fazer backup dos dados replicados no local de recuperação para criar backups pontuais além das réplicas.
Usar várias zonas de disponibilidade (AZs) em uma única Região da AWS
Ao utilizar várias AZs em uma única região, a implementação de DR usa vários elementos das estratégias acima. Primeiro, você deve criar uma arquitetura de alta disponibilidade (HA), usando várias AZs, conforme mostrado na Figura 23. Essa arquitetura faz uso de uma multissite ativa/ativa, já que as instâncias do Amazon EC2 e o Elastic Load Balancer têm recursos implantados em várias AZs, processando ativamente as solicitações. A arquitetura também demonstra o standby a quente, em que, se a instância primária do Amazon RDS falhar (ou a própria AZ falhar), a instância em espera será promovida para primária.

Figura 24: Arquitetura Multi-AZ
Além da arquitetura de alta disponibilidade, é necessário adicionar backups de todos os dados necessários para executar a workload. Isso é especialmente importante para dados restritos a uma única zona, como volumes do Amazon EBS ou clusters do Amazon Redshift. Se uma AZ falhar, você precisará restaurar esses dados para outra AZ. Sempre que possível, copie os backups de dados para outra Região da AWS como uma camada adicional de proteção.
Uma abordagem alternativa menos comum para uma única região, a recuperação de desastres multi-AZ é ilustrada na publicação do blog Building highly resilient applications using Amazon Application Recovery Controller, Part 1: Single-Region stack
. Aqui, a estratégia é manter o máximo de isolamento possível entre as AZs, da mesma forma que as regiões operam. Ao usar esta estratégia alternativa, você pode escolher uma abordagem ativa/ativa ou ativa/passiva. nota
Algumas workloads têm requisitos regulatórios de residência de dados. Se isso se aplicar à sua workload em uma localidade que atualmente tem apenas uma Região da AWS, a opção de multirregiões não atenderá às suas necessidades empresariais. As estratégias Multi-AZ fornecem boa proteção contra a maioria dos desastres.
-
Avalie os recursos da sua workload e qual será sua configuração na região de recuperação antes do failover (durante a operação normal).
Para infraestrutura e recursos da AWS, use infraestrutura como código como o AWS CloudFormation
ou ferramentas de terceiros como o Hashicorp Terraform. Para implantar em várias contas e regiões com uma única operação, é possível usar o AWS CloudFormation StackSets. Para estratégias multissite ativa/ativa e standby a quente, a infraestrutura implantada na região de recuperação tem os mesmos recursos que a região primária. Para as estratégias de luz piloto e standby passivo, a infraestrutura implantada exigirá ações adicionais para ficar pronta para produção. Usando os parâmetros e a lógica condicional do CloudFormation, é possível controlar se uma pilha implantada está ativa ou em espera com um único modelo . Quando o Elastic Disaster Recovery é usado, o serviço replica e orquestra a restauração de configurações da aplicação e os recursos de computação. Todas as estratégias de recuperação de desastres exigem que as fontes de dados sejam copiadas para backup dentro da Região da AWS e que esses backups sejam copiados para a região de recuperação. O AWS Backup
fornece uma visão centralizada na qual é possível configurar, programar e monitorar backups desses recursos. Para luz piloto, standby passivo e multissite ativa/ativa, também é necessário replicar dados da região principal para recursos de dados na região de recuperação, como instâncias de banco de dados do Amazon Relational Database Service (Amazon RDS) ou tabelas do Amazon DynamoDB . Esses recursos de dados estão ativos e prontos para atender a solicitações na região de recuperação. Para saber mais sobre como os serviços da AWS operam entre regiões, consulte esta série de blogs sobre como Criar aplicações multirregiões com serviços da AWS
. -
Determine e implemente como você preparará sua região de recuperação para failover quando necessário (durante um evento de desastre).
Para multissite ativa/ativa, failover significa evacuar uma região e confiar nas regiões ativas restantes. No geral, essas regiões estão prontas para aceitar tráfego. Para as estratégias de luz piloto e standby passivo, as ações de recuperação precisarão implantar os recursos ausentes, como as instâncias do EC2 na Figura 20, além de quaisquer outros recursos ausentes.
Para todas as estratégias acima, talvez seja necessário promover instâncias somente leitura de bancos de dados para transformá-las na instância primária de leitura/gravação.
Para backup e restauração, a restauração de dados do backup cria recursos para esses dados, como volumes do EBS, instâncias de banco de dados do RDS e tabelas do DynamoDB. Você também precisa restaurar a infraestrutura e implantar o código. É possível usar o AWS Backup para restaurar dados na região de recuperação. Consulte REL09-BP01 Identificar e fazer backup de todos os dados que precisam de backup ou reproduzir os dados das fontes para obter mais detalhes. A reconstrução da infraestrutura inclui a criação de recursos como instâncias do EC2, além da Amazon Virtual Private Cloud (Amazon VPC)
, sub-redes e grupos de segurança necessários. É possível automatizar grande parte do processo de restauração. Para saber como, consulte esta postagem do blog . -
Determine e implemente como você preparará sua região de recuperação para failover quando necessário (durante um evento de desastre).
Essa operação de failover pode ser iniciada de forma manual ou automática. O failover iniciado automaticamente com base em verificações de integridade ou alarmes deve ser usado com cautela, pois um failover desnecessário (alarme falso) resulta em custos como indisponibilidade e perda de dados. Portanto, o failover iniciado manualmente é usado com frequência. Nesse caso, você ainda deve automatizar as etapas para failover para que a inicialização manual ocorra com o apertar um botão.
Há várias opções de gerenciamento de tráfego a serem consideradas ao usar os serviços da AWS. Uma opção é usar o Amazon Route 53
. Ao usar o Amazon Route 53, você pode associar vários endpoints de IP em uma ou mais Regiões da AWS a um nome de domínio do Route 53. Para implementar o failover iniciado manualmente, é possível usar o Amazon Application Recovery Controller , que fornece uma API de plano de dados altamente disponível destinada a redirecionar o tráfego para a região de recuperação. Ao implementar o failover, use as operações do plano de dados e evite as do ambiente de gerenciamento, conforme descrito em REL11-BP04 Confiar no plano de dados, e não no ambiente de gerenciamento, durante a recuperação. Para saber mais sobre essa e outras opções, consulte esta seção do whitepaper de recuperação de desastres.
-
Crie um plano de como será failback da workload.
O failback é quando a operação da workload retorna para a região primária após o término de um evento de desastre. O provisionamento de infraestrutura e código para a região primária geralmente segue as mesmas etapas que foram usadas inicialmente, contando com a infraestrutura como código e pipelines de implantação de código. O desafio com o failback é restaurar os datastores e garantir sua consistência com a região de recuperação em operação.
No estado de failover, os bancos de dados na região de recuperação estão ativos e têm dados atualizados. O objetivo é ressincronizar da região de recuperação para a região primária, garantindo que ela permaneça atualizada.
Alguns serviços da AWS fazem isso automaticamente. Se estiver usando tabelas globais do Amazon DynamoDB
, mesmo que a tabela na região primária tenha se tornado indisponível, o DynamoDB retomará a propagação de todas as gravações pendentes assim que ela retornar online. Se estiver usando o Amazon Aurora Global Database e usando failover planejado gerenciado, a topologia de replicação existente do banco de dados global do Aurora será mantida. Portanto, a antiga instância de leitura/gravação na região primária se tornará uma réplica e receberá atualizações da região de recuperação. Nos casos em que isso não é automático, será necessário restabelecer o banco de dados na região primária como uma réplica do banco de dados na região de recuperação. Em muitos casos, isso envolverá a exclusão do banco de dados primário antigo e a criação de outras réplicas.
Após um failover, se você puder continuar a execução na região de recuperação, considere torná-la a nova região primária. Você ainda seguiria todas as etapas acima para transformar a antiga região primária em uma região de recuperação. Algumas organizações praticam uma rotação agendada, trocando as regiões primárias e de recuperação periodicamente (por exemplo, a cada três meses).
Todas as etapas necessárias para failover e failback devem ser mantidas em um playbook disponível para todos os membros da equipe e que seja revisado periodicamente.
Ao usar o Elastic Disaster Recovery, o serviço auxiliará na orquestração e automatização do processo de failback. Para obter mais detalhes, consulte Como executar um failback.
Nível de esforço do plano de implementação: Alto
Recursos
Práticas recomendadas relacionadas:
Documentos relacionados:
-
Blog de arquitetura da AWS: série de recuperação de desastres
-
Recuperação de desastres de workloads na AWS: recuperação na nuvem (whitepaper da AWS)
-
Criar uma solução de backend multirregiões ativa-ativa sem servidor em uma hora
-
Parceiro da APN: parceiros que podem ajudar com a recuperação de desastres
-
AWS Marketplace: produtos que podem ser usados para recuperação de desastres
Vídeos relacionados:
